
Programa
Desenvolvedor Python
28 h
Ferramentas tradicionais de extração de PDF, como pypdf ou PDFMiner, fornecem o texto bruto, mas perdem a estrutura do documento. As tabelas ficam com o texto todo misturado, os cabeçalhos se misturam com o conteúdo do corpo e as imagens somem. Para os sistemas RAG, esses dados confusos significam uma recuperação ruim e respostas pouco confiáveis. Docling é um kit de ferramentas de código aberto da IBM Research que usa modelos de visão computacional para entender o layout dos documentos, mantendo tabelas, imagens, títulos e estrutura. Ele processa documentos até 30 vezes mais rápido do que os métodos tradicionais baseados em OCR e funciona localmente no seu computador.
Neste tutorial, vamos usar o Docling para criar um Assistente de Inteligência Documental — um aplicativo web Streamlit que permite carregar documentos, visualizar sua estrutura e fazer perguntas usando um chatbot com tecnologia RAG. Você vai aprender a processar documentos em vários formatos com o Docling, extrair e mostrar tabelas e imagens, criar um armazenamento vetorial com o ChromaDB e fazer um agente conversacional com o LangGraph. No final, você vai ter um aplicativo que transforma documentos complexos em dados estruturados e permite responder perguntas de forma inteligente.
Pré-visualização do aplicativo:
Visualização da estrutura do documento:
Antes de começar este tutorial, você deve ter:
Habilidades técnicas: Conhecimento das classes, decoradores, dicas de tipo e gerenciadores de contexto do Python. Vamos usar operações assíncronas e padrões de fábrica em todo o processo. É preciso entender como os grandes modelos de linguagem funcionam com prompts, tokens e embeddings. Conhecer sistemas de geração aumentada por recuperação e bancos de dados vetoriais ajuda, mas não é necessário — vamos explicar os conceitos básicos à medida que avançamos.
Configuração de desenvolvimento: Python 3.10 ou superior com pip para gerenciamento de pacotes. Recomenda-se um editor de código como o VS Code. Você vai precisar de uma chave API OpenAI de platform.openai.com — o processamento custa aproximadamente US$ 0,10–0,20 por documento.
Compromisso de tempo: Reserve de 60 a 90 minutos para concluir o tutorial, incluindo a leitura das explicações, a escrita do código e o teste do aplicativo. Esse tutorial pressupõe conhecimentos intermediários de Python.
A maioria das ferramentas de processamento de documentos trata os PDFs como arquivos de imagem ou fluxos de texto. Eles ou fazem OCR em todas as páginas ou extraem texto simples sem entender o que estão lendo. A Docling tem uma abordagem diferente. É um kit de ferramentas de código aberto da IBM Research que usa modelos de visão computacional para entender a estrutura dos documentos da mesma forma que um ser humano faria.
Quando você coloca um documento no Docling, dois modelos de IA analisam ele:
Esses modelos entendem que um documento não é só um monte de texto. Tem hierarquia, relações e significado.
Essa compreensão estrutural é importante para os sistemas RAG. Quando você está criando aplicativos de geração aumentada por recuperação, a qualidade do processamento do seu documento afeta diretamente a precisão da recuperação. Se a extração do PDF transformar uma tabela financeira em texto confuso, sua pesquisa vetorial vai trazer resultados inúteis. O Docling mantém a estrutura, então, quando você divide e incorpora seus documentos, você trabalha com dados limpos e organizados.
O Docling já vem pronto pra usar com vários formatos de documentos:
Você também pode ativar o OCR para documentos digitalizados usando mecanismos como EasyOCR, Tesseract ou RapidOCR. O kit de ferramentas exporta para vários formatos, incluindo Markdown (ótimo para LLMs), JSON (para pipelines de dados estruturados) e DocTags (um formato que captura elementos complexos, como equações matemáticas e blocos de código).
Além da flexibilidade de formatos, o Docling oferece vantagens de desempenho. O processamento tradicional de documentos com OCR é lento porque trata cada página como uma imagem que precisa de reconhecimento de caracteres. O Docling pula essa etapa para documentos digitais, oferecendo um processamento muito mais rápido. Ele roda localmente em hardware comum, então você não paga custos de API nem envia documentos confidenciais para serviços de terceiros. A velocidade de processamento varia de acordo com a complexidade do documento, o número de páginas e as especificações do hardware, com um desempenho típico que varia de menos de um segundo a vários segundos por página em hardware moderno.
A IBM continuou melhorando as capacidades do Docling. Eles lançaram Granite-Docling, um modelo de linguagem visual com 258 milhões de parâmetros que se destaca em layouts complexos e oferece suporte multilingue experimental (com o inglês como idioma principal e suporte inicial para árabe, chinês e japonês). O kit de ferramentas agora também suporta a extração de imagens com resolução configurável, que usaremos em nosso aplicativo para exibir imagens reais de PDFs junto com seu conteúdo de texto.
Para o nosso caso de uso, o Docling faz sentido porque precisamos de dados estruturados, não só texto bruto. Se você só precisa extrair texto básico, ferramentas mais simples como o pypdf podem ser suficientes. Mas, como estamos criando um aplicativo de IA que processa documentos para análise e conversação, o processamento sensível à estrutura do Docling é a melhor escolha. É super útil quando você tá trabalhando com documentos técnicos, artigos de pesquisa ou relatórios comerciais, onde as tabelas e o layout são importantes.
Antes de começarmos a construir o processador de documentos, você precisa configurar a estrutura do seu projeto e instalar os pacotes necessários. Essa seção fala sobre a configuração inicial: criar diretórios, instalar dependências e configurar suas chaves de API.
Comece criando um novo diretório para o seu projeto:
mkdir docling-demo
cd docling-demoDentro desse diretório, crie uma pasta src/ para seus módulos Python:
mkdir src
touch src/__init__.pyO arquivo __init__.py diz ao Python que src/ é um pacote, permitindo importações como from src.document_processor import DocumentProcessor.
A estrutura do seu projeto:
docling-demo/
├── src/
│ └── __init__.pyCrie um arquivo requirements.txt na raiz do seu projeto:
docling>=2.55.0
langchain-docling>=0.1.0
langchain>=0.3.0
langchain-openai>=0.2.0
langgraph>=0.2.0
langchain-chroma>=0.1.0
streamlit>=1.28.0
streamlit-extras>=0.7.0
python-dotenv>=1.0.0
chromadb>=0.4.22
tiktoken>=0.5.0
pandas>=2.0.0
numpy<2 A restrição numpy<2 existe porque as dependências do Docling (TensorFlow e Transformers) precisam do NumPy 1.x.
Instale os pacotes:
pip install -r requirements.txtA primeira instalação leva alguns minutos porque o Docling baixa modelos de IA pré-treinados (cerca de 500 MB). Esses modelos cuidam da análise do layout e do reconhecimento da estrutura das tabelas. Eles ficam guardados localmente, então as próximas execuções são mais rápidas.
Crie um arquivo ` .env ` para guardar sua chave API OpenAI:
OPENAI_API_KEY=your-openai-api-key-herePega sua chave API em platform.openai.com. Você vai precisar disso para incorporações e para o agente de chat.
Crie um modelo .env.example:
OPENAI_API_KEY=your-openai-api-key-hereAdicione um .gitignore para evitar o envio de dados confidenciais:
# Environment variables
.env
# Python
__pycache__/
*.py[cod]
*.so
venv/
*.egg-info/
# Chroma
chroma_db/Crie um arquivo chamado ` app.py ` na raiz do seu projeto. Vamos criar esse arquivo aos poucos ao longo do tutorial. Por enquanto, adicione as importações e configurações básicas:
import streamlit as st
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Page configuration
st.set_page_config(
page_title="Document Intelligence Assistant",
page_icon="📄",
layout="wide"
)
st.title("Document Intelligence Assistant")
st.write("Application setup complete. We'll build the functionality next.")Teste sua configuração:
streamlit run app.pyO Streamlit abre uma janela do navegador em http://localhost:8501 mostrando sua página básica.
A estrutura final do seu projeto (antes de adicionarmos novos scripts nas próximas seções):
docling-demo/
├── .env
├── .env.example
├── .gitignore
├── requirements.txt
├── app.py
└── src/
└── __init__.pyCom o ambiente pronto, podemos criar o processador de documentos que usa o Docling para extrair a estrutura dos arquivos enviados.
Observação: As seções abaixo vão dividir os scripts do aplicativo em partes. Então, pra ter uma visão geral e acompanhar tudo com facilidade, a gente recomenda abrir o repositório GitHub desse projeto em uma aba separada.
📄 Script completo: src/document_processor.py
O processador de documentos é onde o Docling faz o seu trabalho. Esse componente pega os arquivos enviados e transforma-os em dados estruturados que podemos usar tanto para RAG quanto para visualização. Precisamos de dois resultados desse processo: texto markdown limpo para o armazenamento vetorial e o objeto de documento Docling original que mantém todas as informações estruturais, como tabelas e imagens.
Vamos criar isso fazendo um novo arquivo chamado document_processor.py no seu diretório src/. Vamos criar uma classe DocumentProcessor que configura o pipeline de processamento do Docling e cuida dos uploads de arquivos.
O Docling permite que você controle como ele processa documentos por meio de opções de pipeline. Para PDFs, você pode ativar o OCR para documentos digitalizados, ativar o reconhecimento da estrutura da tabela e extrair imagens:
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from langchain_core.documents import Document
class DocumentProcessor:
def __init__(self):
# Configure pipeline options for PDF processing
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2.0
Criamos um objeto ` PdfPipelineOptions ` para configurar como o Docling processa arquivos PDF. Cada opção controla uma capacidade de processamento específica: do_ocr permite o reconhecimento óptico de caracteres para documentos digitalizados, do_table_structure ativa a detecção e análise de tabelas, generate_picture_images instrui o Docling a extrair imagens incorporadas como objetos PIL e images_scale define o multiplicador de resolução para imagens extraídas.
# Initialize converter with PDF options
self.converter = DocumentConverter(
format_options={InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)}
)O mecanismo de processamento de imagens ( DocumentConverter ) é o principal mecanismo de processamento do Docling. Inicializamos com nossas opções de pipeline de PDF envolvidas em um objeto ` PdfFormatOption `, que associa essas configurações especificamente aos arquivos de entrada PDF.
Vamos ver o que cada opção de pipeline faz. A flag do_ocr ativa o reconhecimento óptico de caracteres. Ao processar PDFs digitais com camadas de texto incorporadas, o Docling pula automaticamente o OCR para economizar tempo. Para documentos digitalizados ou imagens com texto, essa configuração diz ao Docling para usar modelos de visão para extrair o texto.
A opção ` do_table_structure ` permite reconhecer a estrutura da tabela. Sem isso, as tabelas são extraídas como texto simples, com a formatação perdida. Com ele ativado, o Docling usa seu modelo de IA TableFormer para identificar linhas, colunas, cabeçalhos e relações entre células. Essa representação estruturada permite exportar tabelas como DataFrame do pandas posteriormente, mantendo o formato tabular.
Definir generate_picture_images como True permite a extração de imagens. Por padrão, o Docling só registra a localização das imagens, sem extrair as imagens propriamente ditas. Ao ativar isso, você terá objetos de imagem PIL que podem ser exibidos na sua interface do usuário ou processados com modelos de visão. O parâmetro “ images_scale ” controla a resolução da extração — um valor de 2,0 dobra a resolução para uma melhor qualidade ao exibir imagens ou executar análises adicionais.
Com o pipeline configurado, podemos adicionar o método que processa os arquivos enviados pelo Streamlit. Esse método lida com os objetos de arquivo do Streamlit, salva-os temporariamente, executa a conversão do Docling e retorna tanto o markdown para RAG quanto os documentos do Docling para visualização:
import os
import tempfile
from typing import List, Any
def process_uploaded_files(self, uploaded_files) -> tuple[List[Document], List[Any]]:
documents = []
docling_docs = []
temp_dir = tempfile.mkdtemp()
try:
for uploaded_file in uploaded_files:
# Save uploaded file to temporary location
temp_file_path = os.path.join(temp_dir, uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
O Streamlit disponibiliza os arquivos enviados como objetos de arquivo na memória, mas o Docling precisa dos arquivos reais no disco para processar. A gente cria um diretório temporário e coloca cada arquivo enviado nele, mantendo o nome original do arquivo.
# Process the document with Docling
result = self.converter.convert(temp_file_path)
# Export to markdown
markdown_content = result.document.export_to_markdown()A chamada converter.convert() executa todo o pipeline de análise de documentos do Docling. Ele identifica o layout do documento, aplica OCR se necessário, detecta tabelas e imagens e cria uma representação estruturada. Espere de 20 a 30 segundos para o processamento sem extração de imagens ou de 40 a 60 segundos com imagens ativadas.
Depois que a conversão estiver pronta, a gente exporta pro formato markdown, que gera um texto limpo e fácil de usar com o LLM, mantendo a formatação correta — os cabeçalhos continuam sendo cabeçalhos, as listas ficam organizadas e as tabelas viram tabelas markdown.
# Create LangChain document
doc = Document(
page_content=markdown_content,
metadata={
"filename": uploaded_file.name,
"file_type": uploaded_file.type,
"source": uploaded_file.name,
}
)
documents.append(doc)
# Store the Docling document for structure visualization
docling_docs.append({
"filename": uploaded_file.name,
"doc": result.document
})Criamos duas representações de cada documento processado. O objeto LangChain Document tem o texto markdown como page_content com metadados associados — isso vai para o armazenamento vetorial para RAG. O objeto de documento Docling original é guardado separadamente com seu nome de arquivo, mantendo todas as informações estruturais (tabelas, imagens, hierarquia) para visualização posterior.
finally:
import shutil
shutil.rmtree(temp_dir)
return documents, docling_docs
O bloco ` finally ` garante que os arquivos temporários sejam limpos, independentemente do sucesso ou falha do processamento. A gente devolve uma tupla com as duas representações do documento: Documentos LangChain para o sistema RAG e documentos Docling para visualização da estrutura.
O processador de documentos já está pronto. Depois, vamos criar a interface Streamlit que permite que os usuários enviem arquivos e vejam o status do processamento.
📄 Roteiro completo: src/structure_visualizer.py
Agora que podemos processar documentos com o Docling, precisamos de uma maneira de visualizar o que foi extraído. O objeto de documento Docling bruto tem um monte de informações estruturais (títulos, tabelas, imagens e metadados), mas não é muito fácil de usar na sua forma original. Vamos criar uma camada de visualização que transforma esses dados em uma interface interativa com quatro visualizações: um painel de resumo, um esboço hierárquico, tabelas interativas e imagens extraídas.
Crie um novo arquivo chamado structure_visualizer.py no diretório src/. Esse componente vai analisar a estrutura do documento do Docling e organizá-lo para exibição.
Comece criando uma classe que envolva um documento Docling e forneça métodos para extrair diferentes elementos estruturais:
from typing import List, Dict, Any
import pandas as pd
from docling_core.types.doc import DoclingDocument
class DocumentStructureVisualizer:
def __init__(self, docling_document: DoclingDocument):
self.doc = docling_document
O inicializador pega um objeto DoclingDocument (o mesmo objeto que o DocumentConverter.convert() devolve). Esse objeto tem tudo que o Docling pegou do documento. O atributo texts tem todos os elementos de texto com seus rótulos e posições, tables guarda os dados das tabelas com informações de estrutura, pictures armazena metadados de imagem e dados reais de imagem, e pages dá informações sobre o nível da página.
Os documentos têm uma estrutura que vai além dos parágrafos. Os títulos criam uma hierarquia que ajuda os leitores a navegar pelo conteúdo. Veja como extrair essa hierarquia:
def get_document_hierarchy(self) -> List[Dict[str, Any]]:
hierarchy = []
if not hasattr(self.doc, "texts") or not self.doc.texts:
return hierarchy
for item in self.doc.texts:
label = getattr(item, "label", None)
if label and "header" in label.lower():
text = getattr(item, "text", "")
prov = getattr(item, "prov", [])
page_no = prov[0].page_no if prov else None
hierarchy.append({
"type": label,
"text": text,
"page": page_no,
"level": self._infer_heading_level(label)
})
return hierarchyA gente percorre todos os itens de texto no documento, filtrando aqueles com rótulos que têm header. Cada item de texto tem um atributo " label " que o Docling atribui durante a análise do layout. Os rótulos comuns incluem section_header, page_header, title e o normal text. O atributo prov (abreviação de proveniência) tem informações de posicionamento, incluindo em qual página o elemento aparece. A gente pega o texto do título, o número da página e descobre o nível hierárquico a partir do tipo de rótulo.
Quando você mostra o esboço, o nível do título decide o recuo. Um método auxiliar mapeia os tipos de rótulos para níveis numéricos:
def _infer_heading_level(self, label: str) -> int:
if "title" in label.lower():
return 1
elif "section" in label.lower():
return 2
elif "subsection" in label.lower():
return 3
else:
return 4Isso cria uma hierarquia em que os títulos dos documentos são o nível 1, os cabeçalhos das seções são o nível 2, as subseções são o nível 3 e quaisquer outros cabeçalhos são, por padrão, o nível 4.
Com a hierarquia do documento extraída, vamos lidar com as tabelas. Diferente da extração simples de texto, que transforma tabelas em sequências confusas, o Docling mantém a estrutura delas como uma das suas características mais valiosas:
def get_tables_info(self) -> List[Dict[str, Any]]:
tables_info = []
if not hasattr(self.doc, "tables") or not self.doc.tables:
return tables_info
for i, table in enumerate(self.doc.tables, 1):
try:
df = table.export_to_dataframe(doc=self.doc)
prov = getattr(table, "prov", [])
page_no = prov[0].page_no if prov else None
caption_text = getattr(table, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
tables_info.append({
"table_number": i,
"page": page_no,
"caption": caption,
"dataframe": df,
"shape": df.shape,
"is_empty": df.empty
})
except Exception as e:
print(f"Warning: Could not process table {i}: {e}")
continue
return tables_infoO método ` table.export_to_dataframe(doc=self.doc) ` transforma a representação da tabela do Docling em um DataFrame do pandas. A gente pega as legendas e os números das páginas, quando dá.
Além das tabelas, o Docling consegue extrair dados reais de imagens de documentos. Esse é um recurso mais recente que vai além de só programar as posições das imagens — ele pega os bytes reais da imagem pra você poder exibi-los. (A gente ativou isso nas opções do pipeline do processador de documentos.)
def get_pictures_info(self) -> List[Dict[str, Any]]:
pictures_info = []
if not hasattr(self.doc, "pictures") or not self.doc.pictures:
return pictures_info
for i, pic in enumerate(self.doc.pictures, 1):
prov = getattr(pic, "prov", [])
if prov:
page_no = prov[0].page_no
bbox = prov[0].bbox
caption_text = getattr(pic, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
pil_image = None
try:
if hasattr(pic, "image") and pic.image is not None:
if hasattr(pic.image, "pil_image"):
pil_image = pic.image.pil_image
except Exception as e:
print(f"Warning: Could not extract image {i}: {e}")
pictures_info.append({
"picture_number": i,
"page": page_no,
"caption": caption,
"pil_image": pil_image,
"bounding_box": {
"left": bbox.l,
"top": bbox.t,
"right": bbox.r,
"bottom": bbox.b
} if bbox else None
})
return pictures_infoCada imagem tem informações de proveniência, incluindo o número da página e as coordenadas da caixa delimitadora. A caixa delimitadora define a posição da imagem na página usando coordenadas esquerda, superior, direita e inferior.
Quando a extração de imagem está ativada, o objeto imagem tem um atributo image que contém os dados reais da imagem. A gente acessa a imagem PIL através de picture.image.pil_image, que retorna um objeto PIL Image que o Streamlit pode mostrar direto com st.image(). O bloco try-except lida com casos em que a extração da imagem falha ou não foi ativada, voltando a mostrar apenas os metadados.
O visualizador precisa de mais um método: um resumo de alto nível que dê aos usuários uma visão geral da estrutura do documento:
def get_document_summary(self) -> Dict[str, Any]:
pages = getattr(self.doc, "pages", {})
texts = getattr(self.doc, "texts", [])
tables = getattr(self.doc, "tables", [])
pictures = getattr(self.doc, "pictures", [])
text_types = {}
for item in texts:
label = getattr(item, "label", "unknown")
text_types[label] = text_types.get(label, 0) + 1
return {
"name": self.doc.name,
"num_pages": len(pages) if pages else 0,
"num_texts": len(texts),
"num_tables": len(tables),
"num_pictures": len(pictures),
"text_types": text_types
}Contamos o número de páginas, elementos de texto, tabelas e imagens no documento. O dicionário “ text_types ” divide os elementos do texto por seus rótulos, mostrando quantos títulos, cabeçalhos, parágrafos e outros elementos o Docling identificou. Isso dá aos usuários uma ideia rápida da estrutura e complexidade do documento.
Com o visualizador pronto, vamos integrá-lo ao Streamlit com quatro guias: Resumo, Hierarquia, tabelas e Imagens.
def render_structure_viz():
st.title("📊 Document Structure")
if not st.session_state.docling_docs:
st.info("👈 Please upload and process your documents first!")
return
doc_names = [doc["filename"] for doc in st.session_state.docling_docs]
selected_doc_name = st.selectbox("Select document to analyze:", doc_names)
selected_doc_data = next(
(doc for doc in st.session_state.docling_docs if doc["filename"] == selected_doc_name),
None
)
if not selected_doc_data:
return
visualizer = DocumentStructureVisualizer(selected_doc_data["doc"])
tab1, tab2, tab3, tab4 = st.tabs(["📑 Summary", "🏗️ Hierarchy", "📊 Tables", "🖼️ Images"])Criamos um menu suspenso para permitir que os usuários selecionem qual documento analisar (útil quando vários arquivos são carregados). Depois de pegar o documento Docling selecionado do estado da sessão, instanciamos o visualizador e criamos quatro guias para diferentes visualizações.
with tab1:
st.subheader("Document Summary")
summary = visualizer.get_document_summary()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Pages", summary["num_pages"])
with col2:
st.metric("Tables", summary["num_tables"])
with col3:
st.metric("Images", summary["num_pictures"])
with col4:
st.metric("Text Items", summary["num_texts"])
st.subheader("Content Types")
text_types_df = pd.DataFrame([
{"Type": k, "Count": v}
for k, v in sorted(summary["text_types"].items(), key=lambda x: -x[1])
])
st.dataframe(text_types_df, use_container_width=True)
with tab2:
st.subheader("Document Hierarchy")
hierarchy = visualizer.get_document_hierarchy()
if hierarchy:
for item in hierarchy:
indent = " " * (item["level"] - 1)
st.markdown(f"{indent}**{item['text']}** _(Page {item['page']})_")
else:
st.info("No hierarchical structure detected")
with tab3:
st.subheader("Tables")
tables_info = visualizer.get_tables_info()
if tables_info:
for table_data in tables_info:
st.markdown(f"### Table {table_data['table_number']} (Page {table_data['page']})")
if table_data["caption"]:
st.caption(table_data["caption"])
if not table_data["is_empty"]:
st.dataframe(table_data["dataframe"], use_container_width=True)
else:
st.info("Table is empty")
st.divider()
else:
st.info("No tables found in this document")
with tab4:
st.subheader("Images")
pictures_info = visualizer.get_pictures_info()
if pictures_info:
for pic_data in pictures_info:
st.markdown(f"**Image {pic_data['picture_number']}** (Page {pic_data['page']})")
if pic_data["caption"]:
st.caption(pic_data["caption"])
if pic_data["pil_image"] is not None:
st.image(pic_data["pil_image"], use_container_width=True)
else:
st.info("Image data not available")
if pic_data["bounding_box"]:
bbox = pic_data["bounding_box"]
with st.expander("📐 Position Details"):
st.text(
f"Position: ({bbox['left']:.1f}, {bbox['top']:.1f}) - "
f"({bbox['right']:.1f}, {bbox['bottom']:.1f})"
)
st.divider()
else:
st.info("No images found in this document")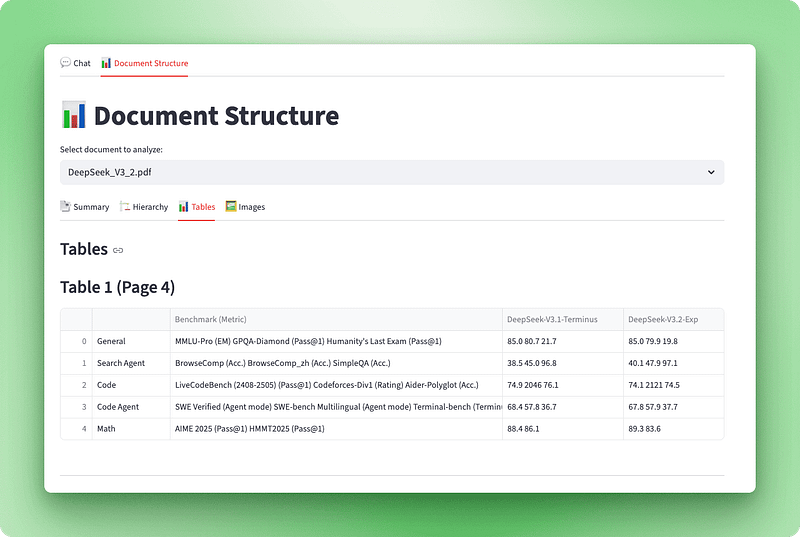
O visualizador de estrutura está pronto. Os usuários podem fazer upload de um documento e ver imediatamente sua anatomia — quantas páginas, tabelas e imagens ele contém, sua estrutura hierárquica com títulos e seções, tabelas interativas que podem ser exploradas e as imagens reais extraídas do documento. Essa transparência ajuda os usuários a entender o que o Docling extraiu e cria confiança no sistema.
Com o processamento e a visualização de documentos funcionando, podemos construir o sistema RAG que permite responder perguntas sobre esses documentos processados.
📄 Scripts completos: src/vectorstore.py | src/tools.py
Com o processamento e a visualização dos documentos concluídos, podemos criar os recursos de perguntas e respostas. O RAG (Retrieval Augmented Generation) permite que os usuários façam perguntas sobre seus documentos. O sistema transforma documentos em embeddings, guarda eles num banco de dados vetorial e pega os trechos relevantes pra responder perguntas.
Essa seção fala sobre duas coisas: um gerenciador de armazenamento vetorial que divide e incorpora documentos e uma ferramenta de pesquisa que pega as informações relevantes.
O armazenamento vetorial é onde ficam as incorporações de documentos. Quando os usuários fazem uma pergunta, a gente procura nesta loja por trechos relevantes e os passa para o LLM como contexto.
Crie um arquivo chamado ` vectorstore.py ` na sua pasta ` src/ `:
from typing import List
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import ChromaEssas importações trazem componentes LangChain para manipulação de documentos, divisão de texto, geração de embeddings e armazenamento vetorial ChromaDB. Veja como eles funcionam juntos:
class VectorStoreManager:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)Inicializamos dois componentes principais. O modelo OpenAI text-embedding-3-small transforma texto em vetores. É menor e mais rápido que text-embedding-3-large, o que é importante quando se incorpora centenas de blocos. O RecursiveCharacterTextSplitter divide os documentos em blocos de 1000 caracteres com sobreposição de 100 caracteres, garantindo que as informações importantes nas bordas dos blocos não sejam cortadas no meio da frase.
1000 caracteres equilibram precisão e contexto — trechos menores permitem uma recuperação precisa, mas perdem o contexto, enquanto trechos maiores preservam o contexto, mas diluem a relevância.
Adicione o método chunking:
def chunk_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents into smaller chunks for better retrieval."""
chunks = self.text_splitter.split_documents(documents)
return chunksO divisor lida com metadados automaticamente, mantendo as informações dos documentos originais. Cada fragmento sabe de qual arquivo veio, o que é importante quando o agente cita fontes nas respostas.
Agora, vamos adicionar o método que cria o armazenamento vetorial:
def create_vectorstore(self, chunks: List[Document]) -> Chroma:
"""Create a Chroma vector store from document chunks."""
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
collection_name="documents"
)
return vectorstoreO ChromaDB cuida do trabalho pesado. Ele incorpora cada fragmento usando nosso modelo de incorporação e armazena os vetores na memória. Quando você faz uma busca por similaridade, o ChromaDB calcula a similaridade coseno entre o vetor de consulta e todos os vetores do documento, mostrando os resultados mais parecidos.
Com o armazenamento vetorial pronto para lidar com incorporações, precisamos dar ao agente uma maneira de consultá-lo. Ferramentas são funções que o LLM pode chamar quando precisa de informações que não possui.
Crie um arquivo chamado ` tools.py ` na sua pasta ` src/ `:
from typing import Annotated
from langchain_core.tools import tool
def create_search_tool(vectorstore):
"""Create a search tool that has access to the vector store."""Essa função de fábrica usa um padrão de fechamento: ela recebe um armazenamento vetorial e devolve uma ferramenta que pode pesquisá-lo. A ferramenta mantém o acesso ao armazenamento vetorial sem precisar de variáveis globais.
@tool
def search_documents(query: Annotated[str, "The search query or question about the documents"]) -> str:
"""Search the uploaded documents for relevant information."""O decorador ` @tool ` transforma essa função em uma ferramenta LangChain que o agente pode chamar. A dica de tipo Annotated descreve o parâmetro, ajudando o LLM a entender o que passar ao chamar a ferramenta.
try:
results = vectorstore.similarity_search(query, k=8)
if not results:
return "No relevant information found in the documents for this query."A gente pega 8 pedaços parecidos (k=8) do armazenamento vetorial. Isso dá ao LLM contexto suficiente sem sobrecarregá-lo com informações desnecessárias. O número certo depende do tipo de documento — documentos técnicos com muita informação podem funcionar melhor com menos partes (k=4-6), enquanto documentos narrativos podem se beneficiar de mais partes (k=10-12).
context_parts = []
for i, doc in enumerate(results, 1):
source = doc.metadata.get("filename", doc.metadata.get("source", "Unknown source"))
content = doc.page_content.strip()
context_parts.append(
f"[Source {i}: {source}]\n"
f"Content: {content}\n"
)
return "\n---\n".join(context_parts)A gente formata cada pedaço com o nome do arquivo original e depois junta tudo com separadores. O LLM pega esse contexto estruturado e usa ele para gerar respostas enquanto cita as fontes.
except Exception as e:
return f"Error searching documents: {str(e)}"
return search_documentsO tratamento de erros garante que o agente receba uma mensagem clara se a pesquisa falhar, em vez de travar. A função retorna a ferramenta configurada pronta para o agente usar.
A loja de vetores e a ferramenta de pesquisa já estão prontas. Depois, vamos criar o agente LangGraph que coordena a recuperação e a geração para responder às perguntas dos usuários.
📄 Script completo: src/agent.py
A ferramenta de pesquisa pode consultar o armazenamento vetorial, mas precisa de um coordenador inteligente. O agente LangGraph decide quando pesquisar, interpreta os resultados e gera respostas em linguagem natural. Também vamos implementar streaming para mostrar o progresso em tempo real.
O agente recebe perguntas, decide quando procurar nos documentos e gera respostas com base no contexto que encontrou.
Crie um arquivo chamado ` agent.py ` na sua pasta ` src/ `:
from typing import List
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaverImportamos componentes para o manuseio de ferramentas, modelos de chat da OpenAI, implementação do agente ReAct da LangGraph e memória de conversação.
SYSTEM_PROMPT = """You are a helpful document intelligence assistant. You have access to documents that have been uploaded and processed.
GUIDELINES:
- Use the search_documents tool to find relevant information
- Keep it simple: one well-crafted search is usually sufficient
- Only search again if the first results are clearly incomplete
- Provide clear, accurate answers based on the document contents
- Always cite your sources with filenames
- If information isn't found, say so clearly
- Be concise but thorough
When answering:
1. Search the documents with a focused query
2. Synthesize a clear answer from the results
3. Include source citations (filenames)
4. Only search again if absolutely necessary
"""
def create_documentation_agent(tools: List[BaseTool], model_name: str = "gpt-4o-mini"):
"""Create a document intelligence assistant agent using LangGraph."""
llm = ChatOpenAI(model=model_name, temperature=0)
memory = MemorySaver()Usamos gpt-4o-mini em vez de gpt-5 porque é mais rápido e barato, além de lidar bem com perguntas e respostas sobre documentos. A temperatura é definida como 0 para respostas consistentes e factuais. O MemorySaver dá ao agente uma memória de conversação, para que ele se lembre das trocas anteriores dentro de uma sessão.
agent = create_react_agent(
llm,
tools=tools,
prompt=SYSTEM_PROMPT,
checkpointer=memory
)
return agentO create_react_agent da LangGraph usa o padrão ReAct (raciocínio + ação). O agente pensa no que precisa fazer, age usando ferramentas, observa os resultados e repete até chegar a uma resposta. Esse padrão funciona bem para o RAG porque o agente pode decidir quando pesquisar e como usar o contexto recuperado.
O agente agora pode pesquisar e gerar respostas, mas os usuários não devem ficar esperando 10 segundos olhando para uma tela em branco enquanto ele trabalha. O streaming mostra o progresso em tempo real — primeiro aparece um indicador de “pensando”, depois “procurando” e, por fim, a resposta aparece caractere por caractere.
Atualize sua função ` render_chat() ` em ` app.py ` para terminar o tratamento da resposta que marcamos com TODO anteriormente:
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)A gente adiciona a mensagem do usuário ao histórico da conversa e mostra na interface do chat.
with st.chat_message("assistant"):
status_placeholder = st.empty()
message_placeholder = st.empty()
try:
config = {"configurable": {"thread_id": "document_chat"}}Criamos espaços reservados para o indicador de status e a mensagem de resposta. A configuração inclui um ID de thread que o LangGraph usa para manter a memória da conversa ao longo das rodadas.
def generate_response():
"""Generator that yields tokens from LangGraph stream."""
status_placeholder.markdown("🤔 **Thinking...**")
first_content_token = True
tool_call_detected = False
final_answer_started = FalseEssa função geradora processa a saída de fluxo do LangGraph. A gente programa o estado com sinalizadores pra mostrar mensagens de status apropriadas conforme o agente avança no fluxo de trabalho.
for msg, metadata in st.session_state.agent.stream(
{"messages": [HumanMessage(content=prompt)]},
config=config,
stream_mode="messages",
):
langgraph_node = metadata.get("langgraph_node", "")O parâmetro ` stream_mode="messages" ` nos dá tokens LLM reais conforme eles são gerados, não só os resultados finais. O LangGraph manda eventos durante toda a execução do agente — quando ele começa a pensar, quando chama ferramentas e quando gera texto.
if "tools" in langgraph_node.lower() or "tool" in langgraph_node.lower():
if not tool_call_detected:
status_placeholder.markdown("🔍 **Searching documents...**")
tool_call_detected = True
continue
if "agent" in langgraph_node.lower() and hasattr(msg, "content"):
content = msg.content
if content:
if first_content_token:
status_placeholder.markdown("💬 **Generating answer...**")
first_content_token = False
final_answer_started = True
if final_answer_started:
yield contentQuando o nó do agente começa a gerar a resposta final, atualizamos o status e começamos a produzir tokens de conteúdo. Cada token é mostrado na hora, criando um efeito de digitação suave.
status_placeholder.empty()
with message_placeholder.container():
full_response = st.write_stream(generate_response())Depois que o streaming terminar, a gente vai tirar o indicador de status. O Streamlit's st.write_stream() cuida da exibição token por token automaticamente, juntando tokens e atualizando a interface do usuário sem problemas. O resultado é uma experiência de chat que parece responsiva e dá aos usuários a certeza de que o sistema está funcionando.
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error generating response: {str(e)}")Salvamos a resposta completa ao histórico de mensagens e lidamos com quaisquer erros que ocorram durante a transmissão.
O sistema RAG está pronto. Agora, os usuários podem enviar documentos, processá-los com o Docling, explorar sua estrutura e ter conversas naturais sobre o conteúdo. O agente faz buscas de forma inteligente, cita fontes e transmite respostas para uma experiência tranquila.
Seu Assistente de Inteligência Documental está pronto. Antes de implantar ou compartilhar, você deve testar o aplicativo para ver se tudo está funcionando direitinho.
Inicie o aplicativo a partir da raiz do seu projeto:
streamlit run app.pyO Streamlit vai abrir uma janela do navegador em http://localhost:8501. Você deve ver a barra lateral com controles de upload e duas guias na área principal.
Carregue um documento PDF de amostra com tabelas e imagens para testar todas as capacidades de processamento:
Fique de olho nos indicadores de processamento:
Quando estiver tudo pronto, você vai ver “✅ Pronto para conversar!” na seção de status.
Vá para a aba “Estrutura do documento” pra conferir se o Docling extraiu tudo direitinho:
Se as tabelas aparecerem vazias ou as imagens não aparecerem, dá uma olhada se você ativou do_table_structure=True e generate_picture_images=True nas opções do pipeline.
Volte para a guia “Chat” e teste o agente com estas perguntas de exemplo:
Boas perguntas iniciais:
Perguntas específicas sobre o documento (ajuste de acordo com o seu documento):
Perguntas de acompanhamento para testar a memória da conversa:
Procure respostas diretas no seu documento com citações de fontes, tokens de streaming contínuo e indicadores de status (“Pensando...”, “Pesquisando documentos...”, “Gerando resposta...”). Fique atento a respostas genéricas que não estão no seu documento, citações de fontes ausentes, respostas lentas sem indicadores de status ou erros sobre chaves API ausentes.
Erro “Não existe nenhum módulo chamado ‘docling’”
pip install docling langchain langchain-openai langchain-chroma langgraph streamlit streamlit-extras pandas python-dotenv
Erro “Chave API OpenAI não encontrada”
Verifique se o arquivo .env existe com OPENAI_API_KEY=your-key-here
Reinicie o Streamlit
O processamento demora mais de 60 segundos.
O agente dá respostas genéricas.
As tabelas aparecem como DataFrames vazios
Confirme do_table_structure=True em PdfPipelineOptions
Tenta um PDF diferente com tabelas nativas.
O aplicativo já está validado e pronto para ser usado. Você pode testá-lo com seus próprios documentos ou disponibilizá-lo para outras pessoas usarem.
Agora você tem um Assistente de Inteligência de Documentos que funciona e processa PDFs, documentos do Word, apresentações do PowerPoint e arquivos HTML, mantendo a estrutura deles. O Docling pega textos, tabelas, tabelas e a hierarquia do documento, que você pode ver usando abas interativas. O sistema RAG, junto com o ChromaDB e o LangGraph, permite perguntas e respostas conversacionais com citações de fontes transmitidas em tempo real. Isso mostra como o processamento de documentos com reconhecimento de estrutura melhora a qualidade da recuperação em comparação com a extração básica de texto. O código-fonte completo está disponível no repositório GitHub.
Essa base abre várias possibilidades de extensão:
Para uma exploração mais profunda dos sistemas RAG e das aplicações LLM, nossa Engenharia de IA O programa aborda os conceitos e padrões que você usou aqui.
Aprenda com o DataCamp
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Matt Crabtree
Tutorial
Ryan Ong
Tutorial
Kurtis Pykes

