
Kurs
Grundlagen der Wahrscheinlichkeit mit R
4 Std.
42.2K
Beim Erstellen von ML-basierten Modellen ist es genauso wichtig, die Leistung eines Modells zu checken wie es zu trainieren. Genauigkeit ist zwar oft die Standardmetrik, kann aber irreführend sein, vor allem bei unausgewogenen Datensätzen, bei denen eine Klasse die Daten dominiert.
Der F1-Score ist der harmonische Mittelwert aus Präzision und Recall. Es schafft einen Ausgleich zwischen falsch positiven und falsch negativen Ergebnissen und liefert eine genauere Messung der Modellleistung.
Bei Sachen wie Betrugserkennung, medizinischer Diagnose, Spam-Filterung und Fehlererkennung reicht Genauigkeit allein nicht aus, um das ganze Bild zu zeigen. Ein Modell kann zwar eine hohe Genauigkeit haben, aber wenn es seltene kritische Fälle nicht erkennt, kann es mehr schaden als nützen. Der F1-Score deckt dieses Risiko ab. Wenn du dich mit Bewertungsmetriken noch nicht so gut auskennst, solltest du dir vielleicht erst mal die Grundlagen in „Machine Learning Fundamentals in Python“ anschauen, bevor wir weitermachen.
Der F1-Score zeigt an, wie gut die Genauigkeit und der Rückruf eines Modells zusammenpassen. Der Wert liegt zwischen 0 und 1, wobei 1 für perfekte Genauigkeit und Wiederauffindbarkeit steht und 0 für schlechte Leistung.
Der F1-Score macht aus beidem eine einzige Zahl und bestraft Modelle, die bei einem gut abschneiden, beim anderen aber nicht. Zum Beispiel könnte jemand, der sich super erinnert, aber nicht so genau ist, alle positiven Fälle richtig erkennen, aber zu viele falsche positive Ergebnisse liefern. Die F1-Maßnahme stellt sicher, dass beide Maßnahmen zusammen durchgeführt werden.
Die Formel für den F1-Score lautet:
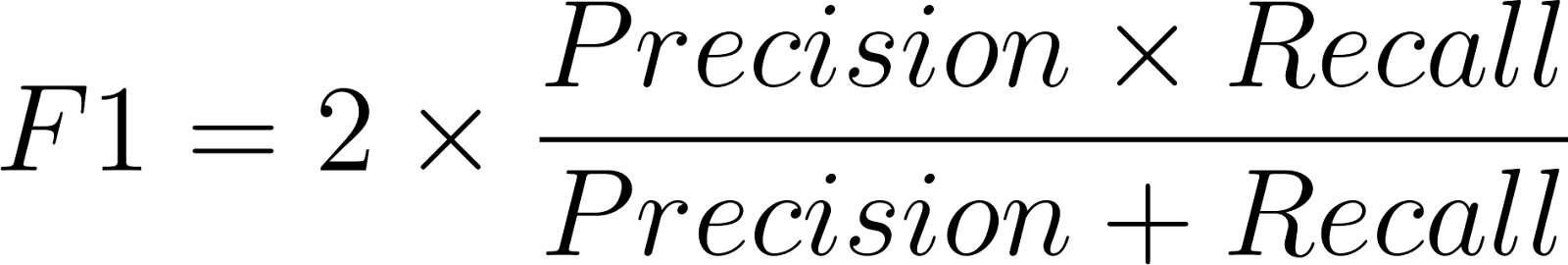
Wo Präzision so definiert ist:
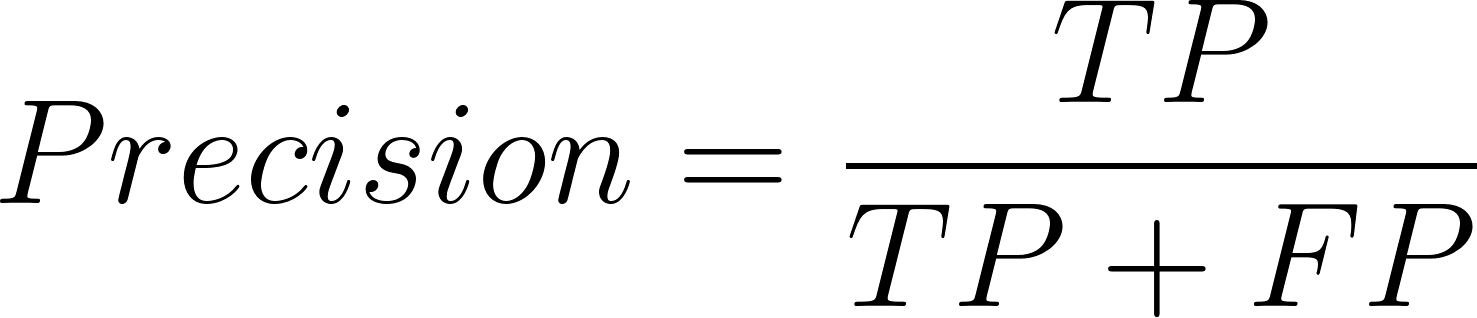
Und die Formel für die Erinnerung lautet:
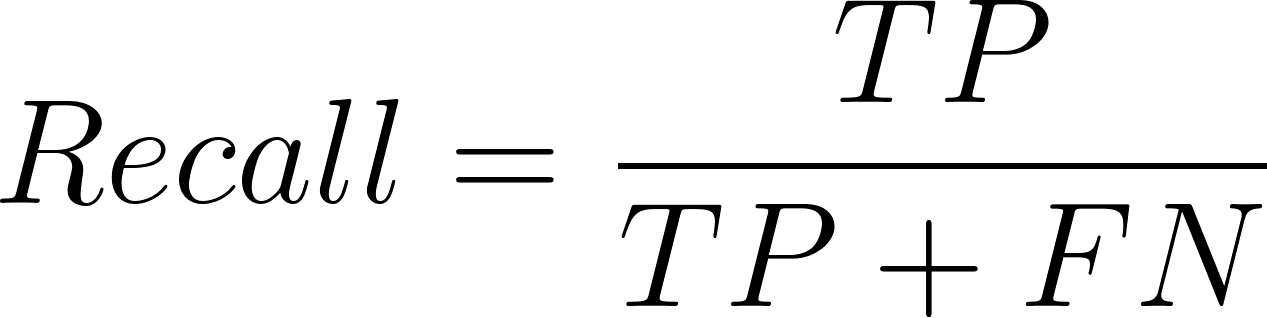
Hier bedeutet TP = True Positives (echte Positive), FP = False Positives (falsche Positive) und FN = False Negatives (falsche Negative).
Man nimmt den harmonischen Mittelwert statt dem arithmetischen Mittelwert, weil der erstere große Unterschiede stärker bestraft. Wenn die Genauigkeit hoch, aber die Trefferquote niedrig ist (oder umgekehrt), sinkt der F1-Score deutlich, was ein Ungleichgewicht zeigt.
Die Genauigkeit bestimmt, wie viele Vorhersagen von allen richtig sind:
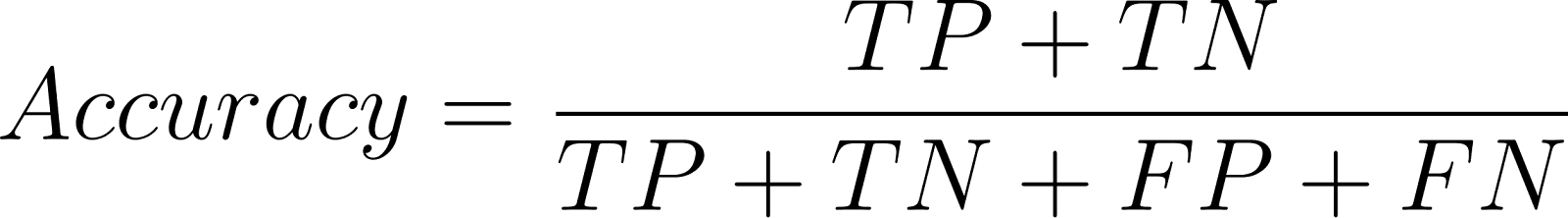
Obwohl Genauigkeit für klassenausgeglichene Datensätze gut ist, kann sie bei klassenungleichen Problemen irreführend sein.
Beispiel:
Wenn ein Spam-Filtersystem 90 % Spam- und 10 % Nicht-Spam-Nachrichten enthält, erreicht ein einfacher Klassifikator, der alle E-Mails als „Spam” einstuft, eine Genauigkeit von 90 %, klassifiziert aber Nicht-Spam-E-Mails nie richtig. Das bringt in der Praxis nichts.
Hier ist der F1-Wert genauer, weil er die Kosten von falsch positiven und falsch negativen Ergebnissen berücksichtigt, was bei der Genauigkeit nicht der Fall ist.
Bei der binären Klassifizierung wird der F1-Score im Verhältnis zur positiven Klasse berechnet. Bei medizinischen Tests könnte die positive Klasse zum Beispiel „Krankheit vorhanden“ bedeuten.
Bei Multiklassenproblemen werden die F1-Wertemit Hilfe von Mittelwertbildungsmethoden erweitert:
|
Methode |
Beschreibung |
Best für |
|
Macro |
Berechnet F1 für jede Klasse einzeln und macht dann den Durchschnitt. |
Ausgewogene Datensätze, gleiche Gewichtung für alle Klassen. |
|
Gewichtet |
Durchschnittliche F1-Werte, gewichtet nach Klassenunterstützung (Anzahl der Proben pro Klasse). |
Unausgewogene Datensätze. |
|
Micro |
Sammelt die Beiträge aller Klassen, um einen globalen F1-Wert zu berechnen. |
Situationen, in denen die Gesamtleistung wichtiger ist. |
Diese Flexibilität macht den F1-Scorefür viele verschiedene Klassifizierungsprobleme einsetzbar.
Die Bibliothek „ scikit-learn “ hat einfache Funktionen, um den F1-Score zu berechnen.
Fang damit an, ein einfaches binäres Klassifizierungsproblem zu checken, bei dem die Vorhersagen entweder 0 oder 1 sind. Die Funktion „ f1_score() “ berechnet den F1-Score direkt anhand der echten und der vorhergesagten Labels.
from sklearn.metrics import f1_score
# True labels
y_true = [0, 1, 1, 1, 0, 1, 0, 1]
# Predicted labels
y_pred = [0, 1, 0, 1, 0, 1, 1, 1]
# Calculate F1 Score
print("F1 Score:", round(f1_score(y_true, y_pred, average='binary'),2))F1 Score: 0.8Als Nächstes kannst du denselben Ansatz auf Multiklassenprobleme ausweiten, bei denen das Modell mehr als zwei Klassen vorhersagt. Der Parameter „ average “ bestimmt, wie F1-Werte über Klassen hinweg zusammengefasst werden – gängige Optionen sind „ 'macro' “, „ 'micro' “ und „ 'weighted' “.
from sklearn.metrics import f1_score, classification_report
y_true = [0, 1, 2, 2, 0, 1, 2, 1, 2]
y_pred = [0, 2, 1, 2, 0, 0, 2, 1, 2]
# Macro, Micro, Weighted F1
print("Macro F1:", round(f1_score(y_true, y_pred, average='macro'),2))
print("Micro F1:", round(f1_score(y_true, y_pred, average='micro'),2))
print("Weighted F1:", round(f1_score(y_true, y_pred, average='weighted'),2))
# Detailed report
print(classification_report(y_true, y_pred))Macro F1: 0.65
Micro F1: 0.67
Weighted F1: 0.64
precision recall f1-score support
0 0.67 1.00 0.80 2
1 0.50 0.33 0.40 3
2 0.75 0.75 0.75 4
accuracy 0.67 9
macro avg 0.64 0.69 0.65 9
weighted avg 0.65 0.67 0.64 9Wenn wir bei der Multi-Class- oder Multi-Label-Klassifizierung den F1 oder Fβ berechnen, müssen wir uns überlegen, wie wir die Scores über verschiedene Klassen hinweg mitteln. Der Parameter „average“ in scikit-learn hat ein paar Optionen:
Binär wird bei zwei Klassen benutzt. Wir konzentrieren uns auf die positive Klasse und berechnen hauptsächlich precision, recall und F1 für diese Klasse.
Bei der Mikroaggregation werden die Beiträge aller Klassen zusammengefasst und dann gemittelt, um den Durchschnittswert zu berechnen. In der Praxis werden die echten Positiven, falschen Negativen und falschen Positiven über alle Klassen hinweg addiert und dann werden Präzision, Recall und F1 anhand dieser Summen berechnet. Die Mikro-Mittelwertbildung ist super, um die Gesamtleistung zu sehen, egal wie unausgewogen die Klassen sind.
Macro: Wir berechnen die Metrik für jede Klasse und machen dann einen ungewichteten Durchschnitt. Das ist keine gleiche Behandlung aller Klassen und daher okay, wenn alle Klassen gleich wichtig sind, auch wenn der Datensatz unausgewogen ist.
Gewichtet ist ähnlich wie Makro, aber es gibt nicht jeder Klasse das gleiche Gewicht. Es gewichtet die Punktzahlen nach der Anzahl der echten Instanzen pro Klasse. Das heißt, dass größere Klassen in der Endnote mehr zählen. Gewichtete Durchschnittswerte sind nützlich, wenn wir eine ausgewogene Sichtweise suchen, ohne die Klassenverteilung zu ignorieren.
Beispiele: Es wird bei Multi-Label-Problemen benutzt, wo eine Probe zu mehr als einer Klasse gehören kann. Hier wird die Metrik für jede Instanz berechnet und dann über alle Instanzen gemittelt.
Mit diesen Optionen zur Mittelwertbildung können wir den F1- oder Fβ-Score an das jeweilige Problem anpassen. Wenn wir zum Beispiel seltene Krankheiten klassifizieren, bei denen Minderheitenklassen super wichtig sind, wäre Makro oder Fβ, wobei β > 1, genau das Richtige. Wenn wir aber die Genauigkeit über alle Klassen hinweg wollen, dann gibt uns die Mikro- oder gewichtete Mittelwertbildung ein besseres Bild.
Für anspruchsvollere Anforderungen bietet scikit-learn auch „ fbeta_score() “ an, das F1 verallgemeinert. Ein tieferes Verständnis solcher Tools zur maschinellen Lern s ist Teil des Lernpfads als Machine Learning Scientist in Python.
Der Fβ-Score ist eine Erweiterung des F1-Scores, je nachdem, ob Genauigkeit oder Recall wichtiger ist:
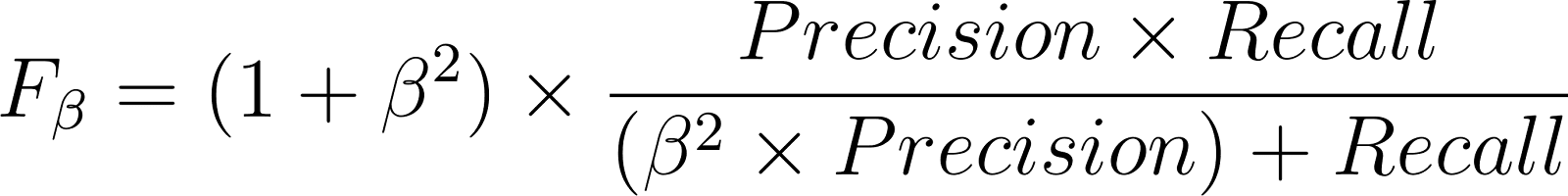
Nimm mal an, wir haben einen medizinischen Datensatz, in dem nur 5 % der Patienten wirklich Diabetes haben. Ein Modell, das für die Erkennung von Diabetes trainiert wurde, kann eine Genauigkeit von 95 % haben. Aber diese 95 % Genauigkeit kann man leicht erreichen, indem man bei allen Leuten einfach „kein Diabetes“ sagt, was das Modell dann nutzlos macht.
Stattdessen messen wir das Modell mit dem F1-Score.
from sklearn.metrics import f1_score, fbeta_score, confusion_matrix
# Suppose these are results from a diabetes detection model
y_true = [0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1] # true outcomes
y_pred = [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1] # model predictions
print("Accuracy:", round((sum([yt == yp for yt, yp in zip(y_true, y_pred)]) / len(y_true)),2))
print("F1 Score:", round(f1_score(y_true, y_pred),2))
print("F2 Score (recall-focused):", round(fbeta_score(y_true, y_pred, beta=2),2))Accuracy: 0.88
F1 Score: 0.8
F2 Score (recall-focused): 0.71Warum solltest du dich hier für F1 oder F2 entscheiden?
In diesem Fall ist die Erinnerung echt wichtig, weil eine verpasste Diagnose das Leben verändern kann. Der F2-Score ist also passender, weil er dem Recall mehr Gewicht gibt.
Das zeigt, wie die F1-Metrikfamilie in klinischen Anwendungsfällen ein praktischeres und besser nutzbares Maß als die Genauigkeit bietet.
Der F1-Score zeigt uns, dass die Modellbewertung mehr als nur ein Zahlenspiel ist. Es geht echt darum, die Kompromisse hinter jeder Prognose zu verstehen. Das ist wichtig, weil es in der Praxis echt schlimme Folgen haben kann, wenn man einen wichtigen Fall übersieht.
Wenn du weiter Modelle entwickelst und verfeinerst, hilft dir das Entwickeln eines Gespürs für Metriken wie F1 dabei, kontextbewusstere Entscheidungen über die Leistung zu treffen. Wenn du deine Fähigkeiten in der Anwendung dieser Konzepte des maschinellen Lernens auf echte Datensätze vertiefen möchtest, schau dir den Lernpfad „ Scientist mit Python” an. Dort lernst du, wie du Modelle in verschiedenen Anwendungsfällen effektiv bewerten, optimieren und einsetzen kannst.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Stephen Gruppetta
Tutorial
Allan Ouko

