
Curso
Fundamentos de probabilidad en R
4 h
42.2K
Al crear modelos basados en el aprendizaje automático, evaluar el rendimiento de un modelo es tan importante como entrenarlo. Aunque la precisión suele ser la métrica predeterminada, puede resultar engañosa, especialmente en conjuntos de datos desequilibrados en los que hay una clase que domina los datos.
La puntuación F1 es la media armónica de la precisión y la recuperación. Equilibra la compensación entre falsos positivos y falsos negativos, y proporciona una medida más precisa del rendimiento del modelo.
En aplicaciones como la detección de fraudes, el diagnóstico médico, el filtrado de spam y la detección de fallos, la precisión por sí sola no basta para ofrecer una visión completa. Un modelo puede alcanzar una gran precisión, pero si no detecta casos críticos poco frecuentes, puede que esté haciendo más daño que bien. La puntuación F1 cubre este riesgo. Si aún eres nuevo en el campo de las métricas de evaluación, es posible que desees explorar los conceptos básicos en Fundamentos del machine learning en Python antes de continuar.
La puntuación F1 mide el equilibrio entre la precisión y la recuperación de un modelo. Va de 0 a 1, donde 1 indica una precisión y una recuperación perfectas, y 0 implica un rendimiento deficiente.
La puntuación F1 combina ambos en una sola cifra, penalizando a los modelos que funcionan bien en uno pero no en el otro. Por ejemplo, uno que recuerde muy bien pero no sea muy preciso puede detectar correctamente todos los casos positivos, pero dar demasiados falsos positivos. La medida F1 garantiza que ambas medidas se tomen conjuntamente.
La fórmula de la puntuación F1 es:
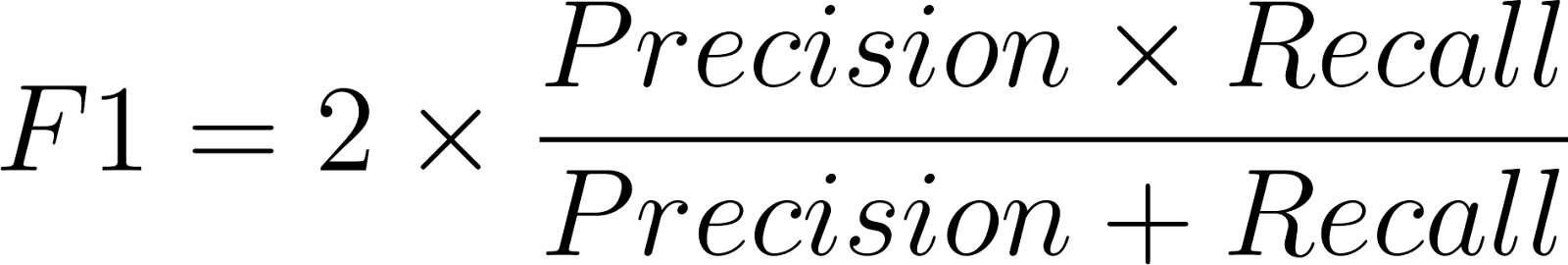
Donde la precisión se define de la siguiente manera:
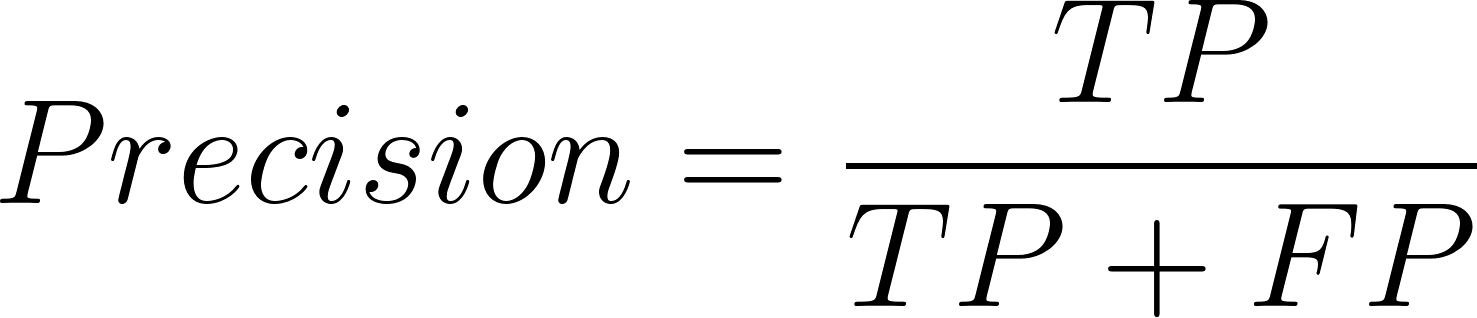
Y la ecuación para el recuerdo es:
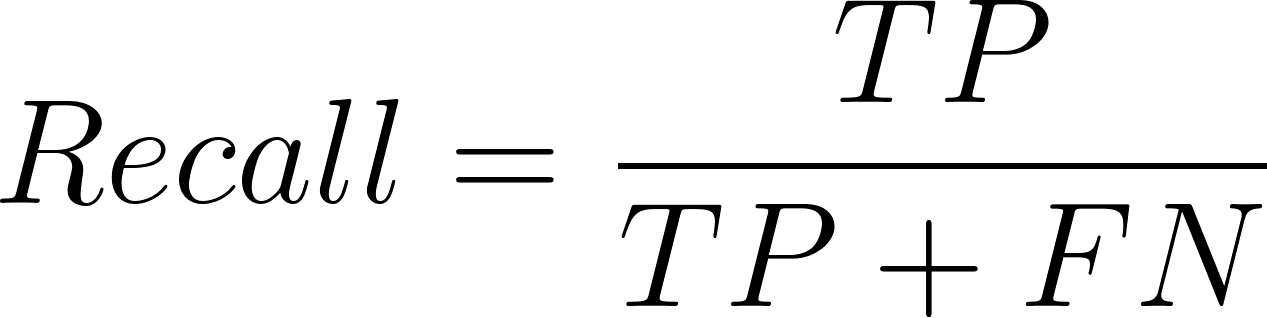
Aquí, TP = verdaderos positivos (VP), FP = falsos positivos (FP) y FN = falsos negativos (FN).
Se utiliza la media armónica en lugar de la media aritmética porque la primera penaliza las grandes diferencias. En caso de alta precisión pero baja recuperación (o viceversa), la puntuación F1 descenderá significativamente, lo que reflejará un desequilibrio.
La precisión determina las predicciones correctas del total de predicciones:
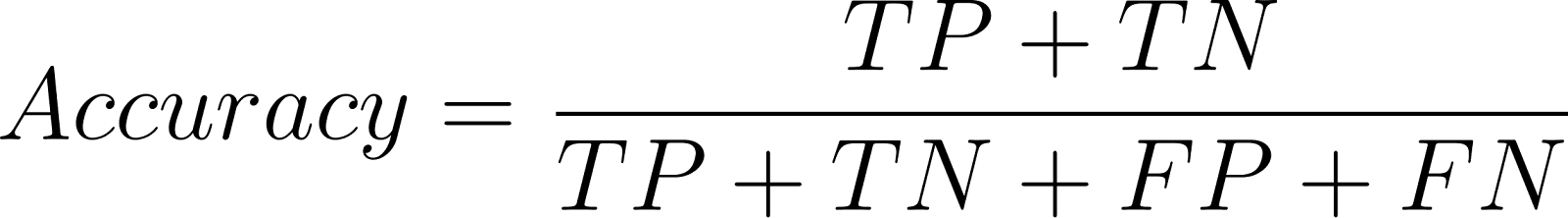
Aunque es útil para conjuntos con equilibrio de clases, la precisión puede ser engañosa en problemas con desequilibrio de clases.
Ejemplo:
Si un sistema de filtrado de spam contiene un 90 % de mensajes spam y un 10 % de mensajes que no son spam, un clasificador ingenuo que clasifica todos los correos electrónicos como «spam» obtiene una precisión del 90 %, pero nunca clasifica correctamente los correos electrónicos que no son spam. Eso no sirve de nada en la práctica.
En este caso, la medida F1 es más precisa, ya que tiene en cuenta el coste de los falsos positivos y los falsos negativos, algo que la precisión no hace.
En la clasificación binaria, la puntuación F1 se calcula en relación con la clase positiva. Por ejemplo, en las pruebas médicas, la clase positiva podría representar «presencia de enfermedad».
En problemas multiclase, las puntuaciones F1 se amplíanutilizando métodos de promediado:
|
Método |
Descripción |
Mejor para |
|
Macro |
Calcula F1 de forma independiente para cada clase y, a continuación, obtiene la media. |
Conjuntos de datos equilibrados, con la misma ponderación para todas las clases. |
|
Ponderado |
Promedios de puntuaciones F1 ponderadas por el soporte de clase (número de muestras por clase). |
Conjuntos de datos desequilibrados. |
|
Micro |
Agrega las contribuciones de todas las clases para calcular un F1 global. |
Situaciones en las que el rendimiento general es más importante. |
Esta flexibilidad hace que la puntuación F1sea aplicable a una amplia variedad de problemas de clasificación.
La biblioteca scikit-learn incluye funciones sencillas para calcular la puntuación F1.
Comienza evaluando un problema sencillo de clasificación binaria en el que las predicciones son 0 o 1. La función f1_score() calcula la puntuación F1 directamente utilizando las etiquetas verdaderas y predichas.
from sklearn.metrics import f1_score
# True labels
y_true = [0, 1, 1, 1, 0, 1, 0, 1]
# Predicted labels
y_pred = [0, 1, 0, 1, 0, 1, 1, 1]
# Calculate F1 Score
print("F1 Score:", round(f1_score(y_true, y_pred, average='binary'),2))F1 Score: 0.8A continuación, puedes ampliar el mismo enfoque a problemas multiclase, en los que el modelo predice más de dos clases. El parámetro « average » controla cómo se agregan las puntuaciones F1 entre clases; las opciones más comunes son « 'macro' », « 'micro' » y « 'weighted' ».
from sklearn.metrics import f1_score, classification_report
y_true = [0, 1, 2, 2, 0, 1, 2, 1, 2]
y_pred = [0, 2, 1, 2, 0, 0, 2, 1, 2]
# Macro, Micro, Weighted F1
print("Macro F1:", round(f1_score(y_true, y_pred, average='macro'),2))
print("Micro F1:", round(f1_score(y_true, y_pred, average='micro'),2))
print("Weighted F1:", round(f1_score(y_true, y_pred, average='weighted'),2))
# Detailed report
print(classification_report(y_true, y_pred))Macro F1: 0.65
Micro F1: 0.67
Weighted F1: 0.64
precision recall f1-score support
0 0.67 1.00 0.80 2
1 0.50 0.33 0.40 3
2 0.75 0.75 0.75 4
accuracy 0.67 9
macro avg 0.64 0.69 0.65 9
weighted avg 0.65 0.67 0.64 9Cuando calculamos F1 o Fβ en la clasificación multiclase o multietiqueta, debemos decidir cómo promediar las puntuaciones entre las diferentes clases. El parámetro average en scikit-learn ofrece varias opciones:
El binario se utiliza en el caso de dos clases. Nos centramos en la clase positiva y calculamos principalmente precision, recall y F1 para esa clase.
Micro implica agregar las contribuciones de todas las clases y luego promediarlas para calcular la métrica promedio. En la práctica, suma el total de verdaderos positivos, falsos negativos y falsos positivos de todas las clases y, a continuación, calcula la precisión, la recuperación y el F1 basándose en estas sumas. El micropromedio aporta valor al permitir ver el rendimiento general independientemente del desequilibrio entre clases.
Macro: Calculamos la métrica para cada clase y luego hacemos un promedio sin ponderar. Esto no proporciona un trato igualitario a todas las clases y, por lo tanto, es razonable si todas las clases tienen la misma importancia, incluso si el conjunto de datos está desequilibrado.
La ponderación es similar a la macro, pero no otorga el mismo peso a cada clase. Pesa las puntuaciones según el número de instancias verdaderas por clase. Esto implica que las clases más grandes cuentan más en la puntuación final. El promedio ponderado es útil cuando buscamos una visión equilibrada sin ignorar la distribución de clases.
Muestras: Se utiliza en problemas con múltiples etiquetas, en los que una muestra puede pertenecer a más de una clase. Aquí, la métrica se calcula para cada instancia y luego se promedia entre todas las instancias.
Estas opciones de promediado nos permiten adaptar la puntuación F1 o Fβ al escenario del problema. Por ejemplo, si clasificamos enfermedades raras para las que las clases minoritarias son de suma importancia, lo adecuado sería utilizar macro o Fβ, donde β > 1. Pero si lo que buscamos es la precisión por clases en todas las clases, el promedio micro o ponderado ofrece una imagen más precisa.
Para necesidades más sofisticadas, scikit-learn también proporciona fbeta_score(), que generaliza F1. Una comprensión más profunda de estas herramientas e es forma parte del programa de científico de machine learning en Python.
La puntuación Fβ generaliza la puntuación F1 dependiendo de si lo que más te interesa es la precisión o la recuperación:
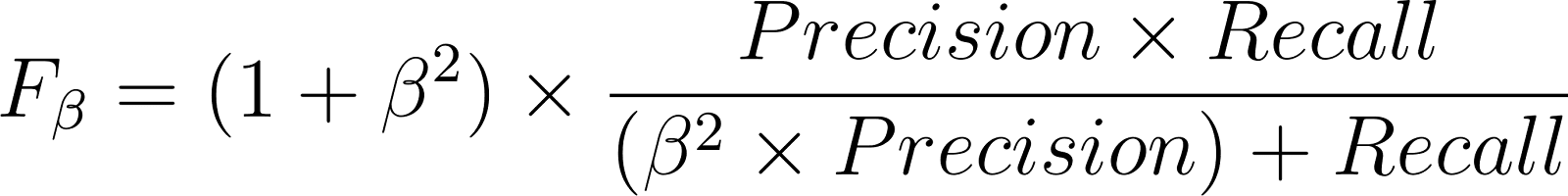
Supongamos un conjunto de datos médicos en el que solo el 5 % de los pacientes padecen diabetes. Un modelo que ha sido entrenado para la detección de diabetes puede tener una precisión del 95 %. Pero esta precisión del 95 % se puede conseguir fácilmente prediciendo siempre «sin diabetes» para todo el mundo, lo que hace que este modelo sea inútil.
En su lugar, utilicemos la puntuación F1 para medir el modelo.
from sklearn.metrics import f1_score, fbeta_score, confusion_matrix
# Suppose these are results from a diabetes detection model
y_true = [0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1] # true outcomes
y_pred = [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1] # model predictions
print("Accuracy:", round((sum([yt == yp for yt, yp in zip(y_true, y_pred)]) / len(y_true)),2))
print("F1 Score:", round(f1_score(y_true, y_pred),2))
print("F2 Score (recall-focused):", round(fbeta_score(y_true, y_pred, beta=2),2))Accuracy: 0.88
F1 Score: 0.8
F2 Score (recall-focused): 0.71¿Por qué elegir F1 o F2 aquí?
En este caso de uso, la recuperación es valiosa, ya que un diagnóstico erróneo puede cambiar la vida. Por lo tanto, la puntuación F2 es más adecuada, ya que otorga mayor importancia a la recuperación.
Esto demuestra cómo la familia de métricas F1 proporciona una medida más práctica y útil que la precisión en casos de uso clínico.
La puntuación F1 nos recuerda que la evaluación de modelos es más que un juego de números. Se trata realmente de comprender las ventajas e inconvenientes que hay detrás de cada predicción. Esto es importante porque, en aplicaciones de la vida real, pasar por alto un caso crítico puede tener graves consecuencias.
A medida que continúes creando y perfeccionando modelos, desarrollar una intuición para métricas como F1 te ayudará a tomar decisiones más conscientes del contexto en lo que respecta al rendimiento. Para profundizar tus habilidades en la aplicación de estos conceptos a conjuntos de datos reales, echa un vistazo al programa de científico de machine learning con Python, donde aprenderás a evaluar, ajustar e implementar modelos de forma eficaz en una variedad de casos de uso.
Aprende con DataCamp
Curso
Curso
Curso
blog
Zoumana Keita
14 min
blog
Stanislav Karzhev
9 min
Tutorial
Richmond Alake
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Adam Shafi
