
Curso
Fundamentos de Probabilidade em R
4 h
42.2K
Ao criar modelos baseados em ML, avaliar o desempenho de um modelo é tão importante quanto treiná-lo. Embora a precisão seja frequentemente a métrica padrão, ela pode ser enganosa, especialmente em conjuntos de dados desequilibrados, nos quais uma classe domina os dados.
A pontuação F1 é a média harmônica da precisão e da recuperação. Ele equilibra a relação entre falsos positivos e falsos negativos e oferece uma medida mais precisa do desempenho do modelo.
Em aplicações como detecção de fraudes, diagnósticos médicos, filtragem de spam e detecção de falhas, a precisão por si só não é suficiente para contar toda a história. Um modelo pode ter uma precisão alta, mas se não conseguir detectar casos críticos raros, pode acabar fazendo mais mal do que bem. A pontuação F1 cobre esse risco. Se você ainda é novo no mundo das métricas de avaliação, talvez seja uma boa ideia dar uma olhada nos conceitos básicos em Fundamentos de machine learning em Python antes de continuarmos.
A pontuação F1 mede o equilíbrio entre precisão e recuperação para um modelo. Ele varia de 0 a 1, onde 1 mostra precisão e recuperação perfeitas, e 0 significa um desempenho ruim.
A pontuação F1 junta os dois em um único número, pegando pesado com os modelos que mandam bem em um, mas não no outro. Por exemplo, um que se lembra muito bem, mas não é muito preciso, pode pegar todos os casos positivos corretamente, mas dar muitos falsos positivos. A medida F1 garante que as duas medidas sejam tomadas juntas.
A fórmula da pontuação F1 é:
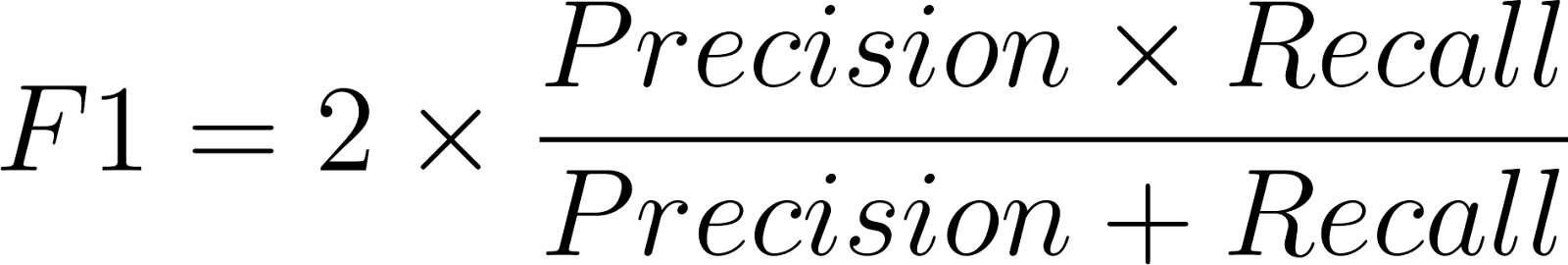
Onde precisão é definida assim:
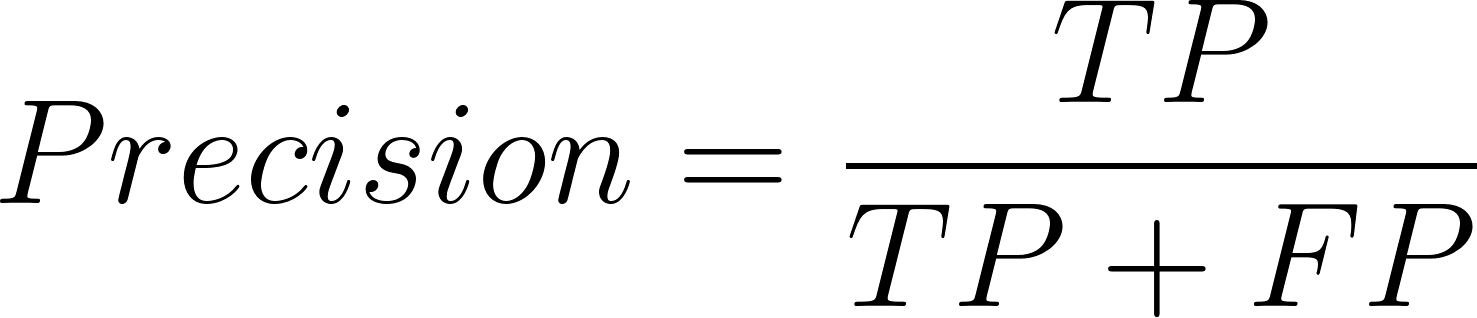
E a fórmula para o recall é:
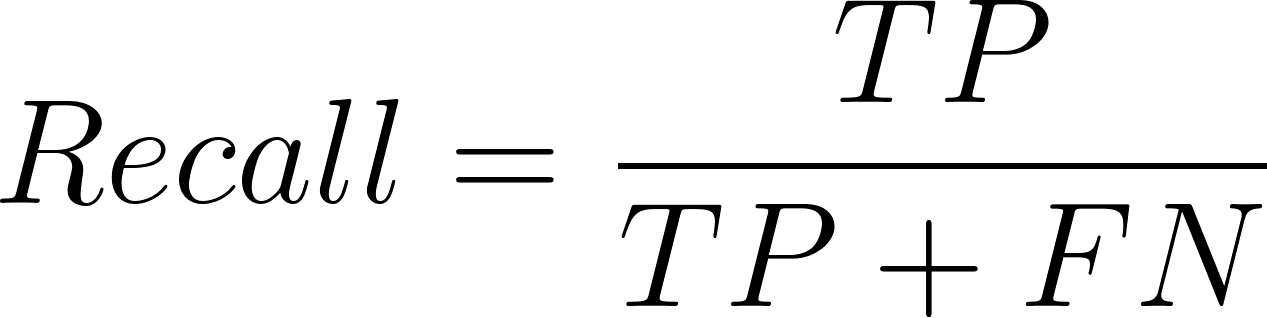
Aqui, TP = Verdadeiros Positivos, FP = Falsos Positivos e FN = Falsos Negativos.
A média harmônica é usada em vez da média aritmética porque a primeira penaliza grandes diferenças. Se a precisão for alta, mas a recuperação for baixa (ou vice-versa), a pontuação F1 vai cair bastante, mostrando um desequilíbrio.
A precisão determina as previsões corretas do total de previsões:
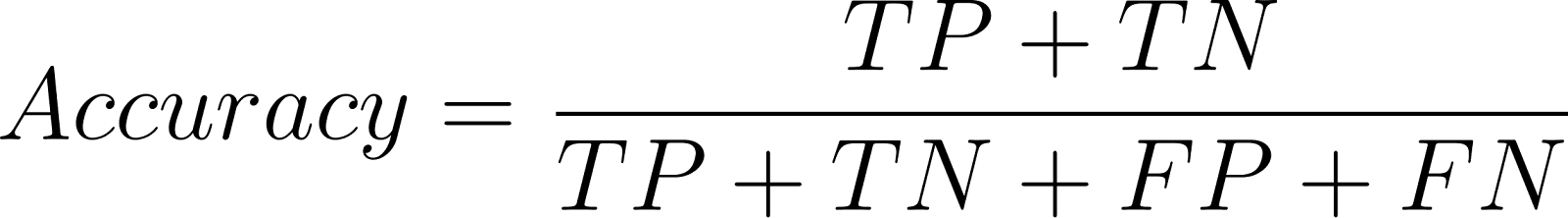
Embora seja boa para conjuntos com classes equilibradas, a precisão pode ser enganosa em problemas com classes desequilibradas.
Exemplo:
Se um sistema de filtragem de spam contém 90% de spam e 10% de mensagens que não são spam, um classificador simples que classifica todos os e-mails como “spam” tem 90% de precisão, mas nunca classifica corretamente os e-mails que não são spam. Isso não adianta nada na prática.
Aqui, a medida F1 é mais precisa, pois leva em conta o custo dos falsos positivos e falsos negativos, o que a precisão não faz.
Na classificação binária, a pontuação F1 é calculada em relação à classe positiva. Por exemplo, em testes médicos, a classe positiva pode significar “doença presente”.
Em problemas multiclasse, as pontuações F1 são ampliadasusando métodos de média:
|
Método |
Descrição |
Melhor para |
|
Macro |
Calcula o F1 de forma independente para cada classe e, em seguida, calcula a média. |
Conjuntos de dados equilibrados, com peso igual para todas as classes. |
|
Ponderado |
Médias das pontuações F1 ponderadas pelo suporte da classe (número de amostras por classe). |
Conjuntos de dados desequilibrados. |
|
Micro |
Agrega as contribuições de todas as classes para calcular um F1 global. |
Situações em que o desempenho geral é mais importante. |
Essa flexibilidade faz com que a pontuação F1seja útil em vários problemas de classificação.
A biblioteca scikit-learn tem funções simples pra calcular a pontuação F1.
Comece avaliando um problema simples de classificação binária, em que as previsões são 0 ou 1. A função f1_score() calcula a pontuação F1 diretamente usando os rótulos verdadeiros e previstos.
from sklearn.metrics import f1_score
# True labels
y_true = [0, 1, 1, 1, 0, 1, 0, 1]
# Predicted labels
y_pred = [0, 1, 0, 1, 0, 1, 1, 1]
# Calculate F1 Score
print("F1 Score:", round(f1_score(y_true, y_pred, average='binary'),2))F1 Score: 0.8Depois, dá pra usar a mesma abordagem pra problemas multiclasse, onde o modelo prevê mais de duas classes. O parâmetro average controla como as pontuações F1 são agregadas entre as classes — as opções comuns incluem 'macro', 'micro' e 'weighted'.
from sklearn.metrics import f1_score, classification_report
y_true = [0, 1, 2, 2, 0, 1, 2, 1, 2]
y_pred = [0, 2, 1, 2, 0, 0, 2, 1, 2]
# Macro, Micro, Weighted F1
print("Macro F1:", round(f1_score(y_true, y_pred, average='macro'),2))
print("Micro F1:", round(f1_score(y_true, y_pred, average='micro'),2))
print("Weighted F1:", round(f1_score(y_true, y_pred, average='weighted'),2))
# Detailed report
print(classification_report(y_true, y_pred))Macro F1: 0.65
Micro F1: 0.67
Weighted F1: 0.64
precision recall f1-score support
0 0.67 1.00 0.80 2
1 0.50 0.33 0.40 3
2 0.75 0.75 0.75 4
accuracy 0.67 9
macro avg 0.64 0.69 0.65 9
weighted avg 0.65 0.67 0.64 9Quando calculamos o F1 ou o Fβ em uma classificação com várias classes ou vários rótulos, precisamos decidir como calcular a média das pontuações entre as diferentes classes. O parâmetro médio no scikit-learn tem algumas opções:
O binário é usado quando tem duas classes. A gente foca na classe positiva e calcula principalmente precision, recall e F1 para essa classe.
Micro envolve juntar as contribuições de todas as classes e, em seguida, calcular a média delas para chegar na métrica média. Na prática, soma o total de verdadeiros positivos, falsos negativos e falsos positivos em todas as classes e, em seguida, calcula a precisão, a recuperação e o F1 com base nessas somas. A micro-média agrega valor ao permitir ver o desempenho geral, independentemente do desequilíbrio entre as classes.
Macro: A gente calcula a métrica para cada classe e, em seguida, faz a média sem ponderar. Isso não dá o mesmo tratamento para todas as classes e, por isso, faz sentido se todas as classes tiverem a mesma importância, mesmo que o conjunto de dados esteja desequilibrado.
Ponderado é parecido com macro, mas não dá o mesmo peso para cada classe. Ele pondera as pontuações pelo número de instâncias verdadeiras por classe. Isso quer dizer que as aulas maiores contam mais na nota final. A média ponderada é útil quando a gente quer ter uma visão equilibrada sem deixar de lado a distribuição das classes.
Amostras: É usado em problemas com várias etiquetas, onde uma amostra pode pertencer a mais de uma classe. Aqui, a métrica é calculada para cada instância e, em seguida, calculada a média entre todas as instâncias.
Essas opções de média nos permitem adaptar a pontuação F1 ou Fβ ao cenário do problema. Por exemplo, se a gente estiver classificando doenças raras para as quais as classes minoritárias são super importantes, macro ou Fβ, onde β > 1, seria o mais adequado. Mas se a precisão em todas as classes é o que estamos procurando, a média micro ou ponderada dá uma visão melhor.
Para necessidades mais sofisticadas, o scikit-learn também oferece o fbeta_score(), que generaliza o F1. Uma compreensão mais profunda dessas ferramentas de faz parte do programa de Cientista de Machine Learning em Python.
A pontuação Fβ generaliza a pontuação F1 dependendo se a precisão ou a recuperação é a principal preocupação:
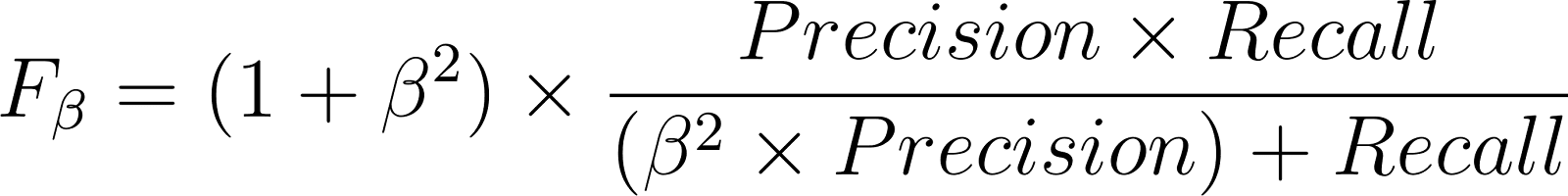
Imagina um conjunto de dados médicos em que só 5% dos pacientes têm diabetes de verdade. Um modelo treinado para detectar diabetes pode ter uma precisão de 95%. Mas essa precisão de 95% pode ser facilmente alcançada prevendo sempre “sem diabetes” para todo mundo, o que torna esse modelo inútil.
Em vez disso, vamos usar a pontuação F1 para avaliar o modelo.
from sklearn.metrics import f1_score, fbeta_score, confusion_matrix
# Suppose these are results from a diabetes detection model
y_true = [0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1] # true outcomes
y_pred = [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1] # model predictions
print("Accuracy:", round((sum([yt == yp for yt, yp in zip(y_true, y_pred)]) / len(y_true)),2))
print("F1 Score:", round(f1_score(y_true, y_pred),2))
print("F2 Score (recall-focused):", round(fbeta_score(y_true, y_pred, beta=2),2))Accuracy: 0.88
F1 Score: 0.8
F2 Score (recall-focused): 0.71Por que escolher F1 ou F2 aqui?
Nesse caso, a lembrança é importante, pois um diagnóstico errado pode mudar a vida de alguém. A pontuação F2 é, portanto, mais adequada, pois dá mais peso à recuperação.
Isso mostra como a família de métricas F1 oferece uma medida mais prática e útil do que a precisão em casos de uso clínico.
A pontuação F1 nos lembra que a avaliação do modelo é mais do que um jogo de números. É realmente uma questão de entender as vantagens e desvantagens por trás de cada previsão. Isso é importante porque, em aplicações da vida real, deixar passar um caso crítico pode ter consequências graves.
À medida que você continua construindo e refinando modelos, desenvolver uma intuição para métricas como F1 vai te ajudar a fazer escolhas mais conscientes sobre o desempenho. Para aprofundar suas habilidades na aplicação desses conceitos de a conjuntos de dados reais, confira o programa de Cientista de Machine Learning com Python, onde você aprenderá a avaliar, ajustar e implantar modelos de maneira eficaz em uma variedade de casos de uso.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
5 min
blog
Stanislav Karzhev
9 min
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani

