
Programa
Desenvolvimento de aplicativos de IA
21 h
O Google DeepMind acaba de lançar o Gemma 3, a próxima iteração de seus modelos de código aberto. O Gemma 3 foi projetado para ser executado diretamente em dispositivos com poucos recursos, como telefones e laptops. Esses modelos são otimizados para desempenho rápido em uma única GPU ou TPU e vêm em vários tamanhos para atender a diferentes necessidades de hardware.
Neste tutorial, explicarei passo a passo como você pode configurar e executar o Gemma 3 localmente usando o Ollama. Depois de fazermos isso, mostrarei como você pode usar o Gemma 3 e o Python para criar um assistente de arquivo.
A execução local de um modelo de linguagem grande (LLM), como o Gemma 3, traz vários benefícios importantes:
A Ollama é uma plataforma disponível para Windows, Mac e Linux que suporta a execução e a distribuição de modelos de IA, facilitando aos desenvolvedores a integração desses modelos em seus projetos. Vamos usá-lo para baixar e executar o Gemma 3 localmente.
A primeira etapa é fazer o download e instalá-lo no site oficial da Ollama.
Ao instalá-lo, certifique-se de instalar a linha de comando:
Após concluir a instalação, podemos verificar se ela foi instalada corretamente usando o comando ollama no terminal. Aqui está o resultado que você deve obter:
Para fazer download de um modelo com o Ollama, use o comando pull:
ollama pull <model_name>:<model_version>A lista de modelos disponíveis pode ser encontrada em biblioteca da Ollama.
Gemma 3O Gemma 3 , em particular, tem quatro modelos disponíveis: 1b 4b , 12b, e 27b, em que b significa bilhão, referindo-se ao número de parâmetros no modelo.
Por exemplo, para fazer o download de gemma3 com os parâmetros de 1b, usamos o comando:
ollama pull gemma3:1bSe não especificarmos a versão do modelo, o download do modelo 4b será feito por padrão:
ollama pull gemma3Podemos listar os modelos que temos localmente usando o seguinte comando:
ollama listNo meu caso, a saída mostra que tenho dois modelos:
NAME ID SIZE MODIFIED
gemma3:1b 2d27a774bc62 815 MB 38 seconds ago
gemma3:latest c0494fe00251 3.3 GB 22 minutes ago Você pode usar o Ollama para conversar com um modelo usando o comando run:
ollama run gemma3
Observe que se usarmos o comando run com um modelo que não foi baixado, ele será baixado automaticamente usando pull.
Para usar o Gemma 3 com Python, você precisa executá-lo em segundo plano. Você pode fazer isso usando o comando serve:
ollama serveSe você receber o seguinte erro ao executar o comando, isso provavelmente significa que o Ollama já está em execução:
Error: listen tcp 127.0.0.1:11434: bind: address already in useEsse erro pode ocorrer quando o Ollama continua sendo executado em segundo plano.
Ollama oferece um pacote Python para que você se conecte facilmente aos modelos em execução em nosso computador.
Usaremos o Anaconda para configurar um ambiente Python e adicionar as dependências necessárias. Fazendo dessa forma, você evita possíveis problemas com outros pacotes Python que já possamos ter.
Quando o Anaconda estiver instalado, você poderá configurar o ambiente usando o comando:
conda create -n gemma3-demo -y python=3.9Esse comando configura um ambiente chamado gemma3-demo usando a versão do Python 3.9. A opção -y garante que todas as perguntas durante a configuração sejam automaticamente respondidas com sim.
Em seguida, ativamos o ambiente usando:
conda activate gemma3-demoPor fim, instalamos o pacote ollama usando o comando:
pip install ollamaAqui está como você pode enviar uma mensagem para o Gemma 3 usando Python:
from ollama import chat
response = chat(
model="gemma3",
messages=[
{
"role": "user",
"content": "Why is the sky blue?",
},
],
)
print(response.message.content)Dependendo do seu hardware, o modelo pode demorar um pouco para responder, portanto, seja paciente ao executar o script.
Vimos anteriormente que gemma3 se refere a gemma3:4b por padrão. Portanto, quando especificamos model="gemma3" como o modelo, é esse que será usado.
Para usar outro modelo - digamos, o modelo 1B -, precisamos passar o argumento model=”gemma3:1b” (desde que o tenhamos obtido anteriormente usando o comando ollama pull gemma3:1b ). Para listar os modelos disponíveis, você pode usar o comando ollama list.
Se quisermos transmitir a resposta palavra por palavra, podemos usar o endereço stream=True e imprimir a resposta por partes:
from ollama import chat
stream = chat(
model="gemma3",
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)Isso proporciona uma experiência melhor para o usuário, pois ele não precisa esperar que a resposta completa seja gerada.
Para saber mais sobre o pacote ollama, você pode consultar a documentação sua documentação.
Nesta seção, aprenderemos a criar um script Python que nos permite fazer perguntas sobre o conteúdo de um arquivo de texto diretamente do terminal. Esse script será útil para tarefas como a verificação de erros em um arquivo de código ou a consulta de informações de qualquer documento.
Nosso objetivo é criar uma ferramenta de linha de comando usando Python que leia um arquivo de texto e use o Gemma 3 para responder a perguntas relacionadas ao seu conteúdo. Aqui está o guia passo a passo para você conseguir isso:
Primeiro, precisamos configurar o script Python com as importações necessárias e a estrutura básica:
import sys
from ollama import chat
def ask_questions_from_file(file_path):
# Read the content of the text file
with open(file_path, "r") as file:
content = file.read()
# Loop to keep asking questions
while True:
question = input("> ")
print()
if question.lower() == "exit":
break
# Use Gemma 3 to get answers
stream = chat(
model="gemma3",
messages=[
{"role": "user", "content": content},
{"role": "user", "content": question},
],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python ask_file.py <path_to_text_file>")
else:
file_path = sys.argv[1]
ask_questions_from_file(file_path)A funcionalidade principal está encapsulada na função ask_questions_from_file(). Essa função usa um caminho de arquivo como argumento e começa abrindo e lendo o conteúdo do arquivo de texto especificado. Esse conteúdo será usado como informação básica para responder às perguntas.
Depois que o conteúdo do arquivo é carregado, o script entra em um loop em que nos solicita continuamente a inserção de perguntas. Quando digitamos uma pergunta, o script envia o conteúdo do arquivo junto com a nossa pergunta para o modelo Gemma 3, que processa essas informações para gerar uma resposta.
A interação com o modelo ocorre por meio de um mecanismo de streaming, permitindo que as respostas sejam exibidas em tempo real à medida que são geradas. Se digitarmos exit, o loop será interrompido e o script deixará de ser executado.
No final do script, há uma verificação para garantir que o script esteja sendo executado corretamente com um argumento de linha de comando, que deve ser o caminho para o arquivo de texto. Se o argumento não for fornecido, ele exibirá uma mensagem de uso para nos orientar sobre a maneira correta de executar o script. Essa configuração nos permite direcionar o script de forma eficaz a partir da linha de comando.
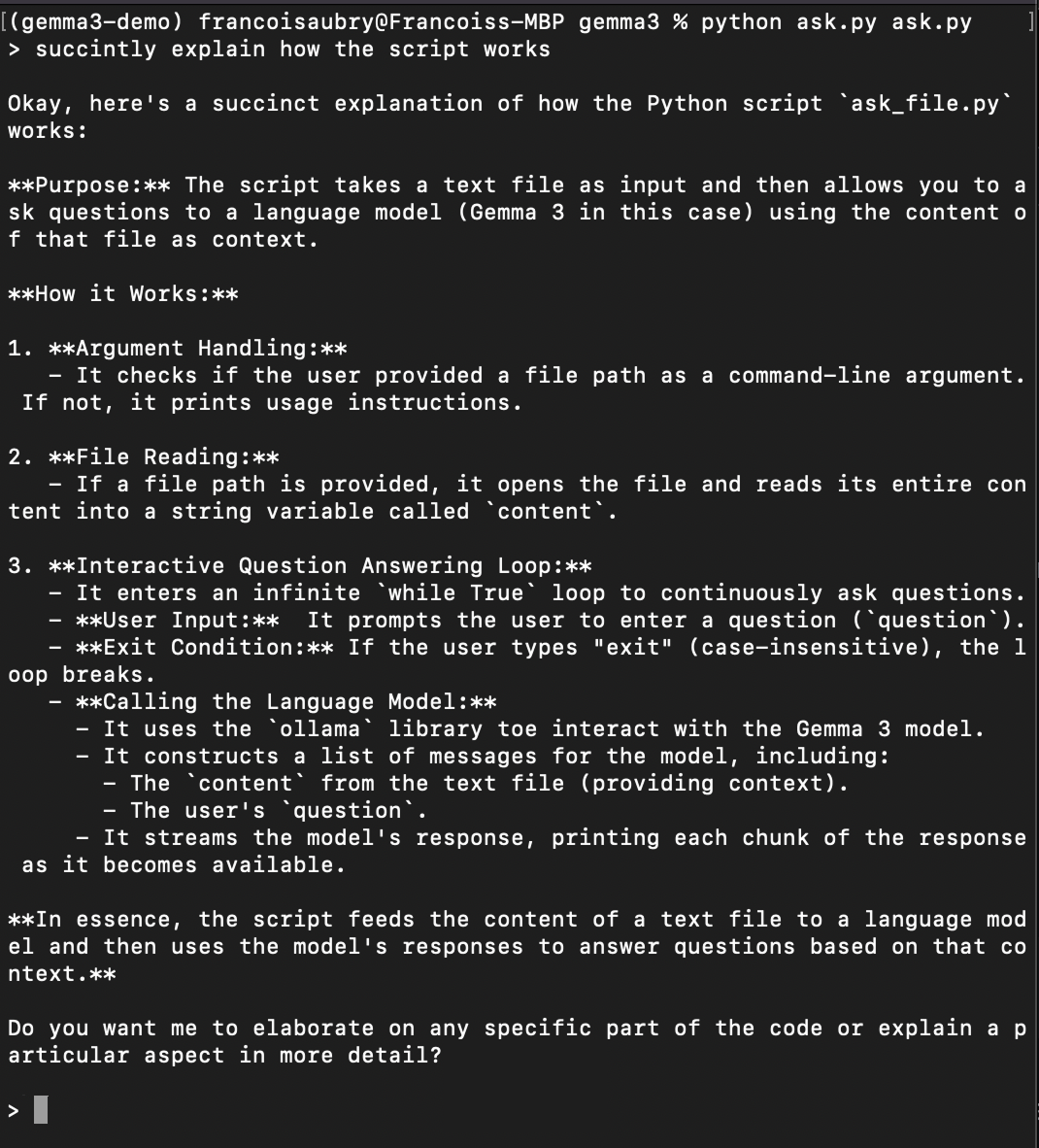
Salve o código acima em um arquivo chamado, por exemplo, ask.py. Para testar o script, execute o comando:
python ask.py ask.pyIsso executará o script para fazer perguntas sobre ele mesmo (é por isso que ask.py aparece duas vezes no comando acima). Aqui está um exemplo de como você pode pedir que ele explique como o script funciona:
Você conseguiu configurar e aprender a executar o Gemma 3 localmente usando Ollama e Python. Essa abordagem garante a privacidade de nossos dados, oferece baixa latência, oferece opções de personalização e pode levar à economia de custos. As etapas que abordamos não se limitam apenas ao Gemma 3 - elas também podem ser aplicadas a outros modelos hospedados no Ollama.
Se quisermos melhorar a funcionalidade do nosso script, poderemos, por exemplo, estender seus recursos para lidar com PDFs. A melhor maneira de fazer isso seria usar o Mistral OCR DA MISTRAL. Podemos converter arquivos PDF em texto, permitindo que nosso script responda a perguntas sobre PDFs, tornando-o ainda mais versátil e avançado.
Com essas ferramentas, agora estamos equipados para explorar e interagir com modelos grandes diretamente de nossos próprios dispositivos.
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial

