
programa
Desarrollo de aplicaciones de IA
21 h
Google DeepMind acaba de lanzar Gemma 3, la siguiente iteración de sus modelos de código abierto. Gemma 3 está diseñado para funcionar directamente en dispositivos de bajos recursos, como teléfonos y ordenadores portátiles. Estos modelos están optimizados para un rendimiento rápido en una sola GPU o TPU y vienen en varios tamaños para adaptarse a las diferentes necesidades de hardware.
En este tutorial, te explicaré paso a paso cómo configurar y ejecutar Gemma 3 localmente utilizando Ollama. Una vez hecho esto, te mostraré cómo puedes utilizar Gemma 3 y Python para construir un asistente de archivos.
Ejecutar localmente un gran modelo lingüístico (LLM) como Gemma 3 tiene varias ventajas clave:
Ollama es una plataforma disponible para Windows, Mac y Linux que permite ejecutar y distribuir modelos de IA, facilitando a los desarrolladores la integración de estos modelos en sus proyectos. Lo utilizaremos para descargar y ejecutar Gemma 3 localmente.
El primer paso es descargarlo e instalarlo desde la web oficial de Ollama.
Al instalarlo, asegúrate de instalar la línea de comandos:
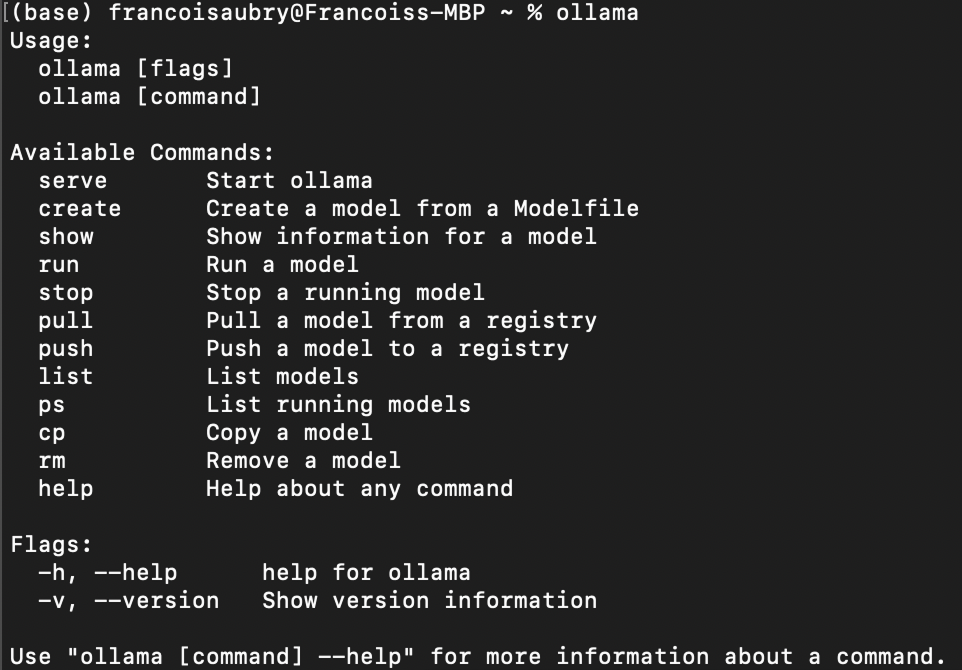
Tras completar la instalación, podemos comprobar que se ha instalado correctamente utilizando el comando ollama en el terminal. Éste es el resultado:
Para descargar un modelo con Ollama, utiliza el comando pull:
ollama pull <model_name>:<model_version>La lista de modelos disponibles se encuentra en Biblioteca de Ollama.
Gemma 3, en concreto, dispone de cuatro modelos: 1b, 4b, 12b, y 27b, donde b significa mil millones, en referencia al número de parámetros del modelo.
Por ejemplo, para descargar gemma3 con los parámetros 1b, utilizamos el comando:
ollama pull gemma3:1bSi no especificamos la versión del modelo, se descargará por defecto el modelo 4b:
ollama pull gemma3Podemos listar los modelos que tenemos localmente utilizando el siguiente comando:
ollama listEn mi caso, la salida muestra que tengo dos modelos:
NAME ID SIZE MODIFIED
gemma3:1b 2d27a774bc62 815 MB 38 seconds ago
gemma3:latest c0494fe00251 3.3 GB 22 minutes ago Podemos utilizar Ollama para chatear con una modelo utilizando el comando run:
ollama run gemma3
Ten en cuenta que si utilizamos el comando run con un modelo que no hemos descargado, se descargará automáticamente mediante pull.
Para utilizar Gemma 3 con Python necesitamos ejecutarlo en segundo plano. Podemos hacerlo utilizando el comando serve:
ollama serveSi obtienes el siguiente error al ejecutar el comando, probablemente significa que Ollama ya se está ejecutando:
Error: listen tcp 127.0.0.1:11434: bind: address already in useEste error puede producirse cuando Ollama sigue ejecutándose en segundo plano.
Ollama ofrece un paquete Python para conectar fácilmente con los modelos que se ejecutan en nuestro ordenador.
Utilizaremos Anaconda para configurar un entorno Python y añadir las dependencias necesarias. Hacerlo así ayuda a evitar posibles problemas con otros paquetes de Python que ya tengamos.
Una vez instalado Anaconda, podemos configurar el entorno utilizando el comando
conda create -n gemma3-demo -y python=3.9Este comando configura un entorno llamado gemma3-demo utilizando la versión de Python 3.9. La opción -y hace que todas las preguntas durante la configuración se respondan automáticamente con un sí.
A continuación, activamos el entorno utilizando:
conda activate gemma3-demoPor último, instalamos el paquete ollama mediante el comando
pip install ollamaHe aquí cómo podemos enviar un mensaje a Gemma 3 utilizando Python:
from ollama import chat
response = chat(
model="gemma3",
messages=[
{
"role": "user",
"content": "Why is the sky blue?",
},
],
)
print(response.message.content)Dependiendo de tu hardware, el modelo puede tardar un poco en responder, así que ten paciencia al ejecutar el script.
Anteriormente vimos que gemma3 se refiere por defecto a gemma3:4b. Así que cuando especifiquemos model="gemma3" como modelo, ése será el que se utilizará.
Para utilizar otro modelo -por ejemplo, el modelo 1B- debemos pasar el argumento model=”gemma3:1b” en su lugar (siempre que lo hayamos extraído previamente mediante el comando ollama pull gemma3:1b ). Para listar los modelos disponibles, podemos utilizar el comando ollama list.
Si queremos transmitir la respuesta palabra por palabra, podemos utilizar stream=True e imprimir la respuesta trozo por trozo:
from ollama import chat
stream = chat(
model="gemma3",
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)Esto proporciona una mejor experiencia al usuario, ya que no tiene que esperar a que se genere la respuesta completa.
Para saber más sobre el paquete ollama, consulta su documentación.
En esta sección, aprenderemos a construir un script en Python que nos permita hacer preguntas sobre el contenido de un archivo de texto directamente desde el terminal. Este script será útil para tareas como comprobar si hay errores en un archivo de código o consultar información de cualquier documento.
Nuestro objetivo es crear una herramienta de línea de comandos utilizando Python que lea un archivo de texto y utilice Gemma 3 para responder a preguntas relacionadas con su contenido. Aquí tienes la guía paso a paso para conseguirlo:
En primer lugar, tenemos que configurar el script de Python con las importaciones necesarias y la estructura básica:
import sys
from ollama import chat
def ask_questions_from_file(file_path):
# Read the content of the text file
with open(file_path, "r") as file:
content = file.read()
# Loop to keep asking questions
while True:
question = input("> ")
print()
if question.lower() == "exit":
break
# Use Gemma 3 to get answers
stream = chat(
model="gemma3",
messages=[
{"role": "user", "content": content},
{"role": "user", "content": question},
],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python ask_file.py <path_to_text_file>")
else:
file_path = sys.argv[1]
ask_questions_from_file(file_path)La funcionalidad principal está encapsulada en la función ask_questions_from_file(). Esta función toma una ruta de archivo como argumento y comienza abriendo y leyendo el contenido del archivo de texto especificado. Este contenido se utilizará como información de base para responder a las preguntas.
Una vez cargado el contenido del archivo, el script entra en un bucle en el que nos pide continuamente que introduzcamos preguntas. Cuando escribimos una pregunta, el script envía el contenido del archivo junto con nuestra pregunta al modelo Gemma 3, que procesa esta información para generar una respuesta.
La interacción con el modelo tiene lugar mediante un mecanismo de streaming, que permite mostrar las respuestas en tiempo real a medida que se generan. Si escribimos exit, el bucle se rompe y el script deja de ejecutarse.
Al final del script, hay una comprobación para asegurar que el script se ejecuta correctamente con un argumento de la línea de comandos, que debe ser la ruta al archivo de texto. Si no se proporciona el argumento, muestra un mensaje de uso para orientarnos sobre la forma correcta de ejecutar el script. Esta configuración nos permite dirigir el script eficazmente desde la línea de comandos.
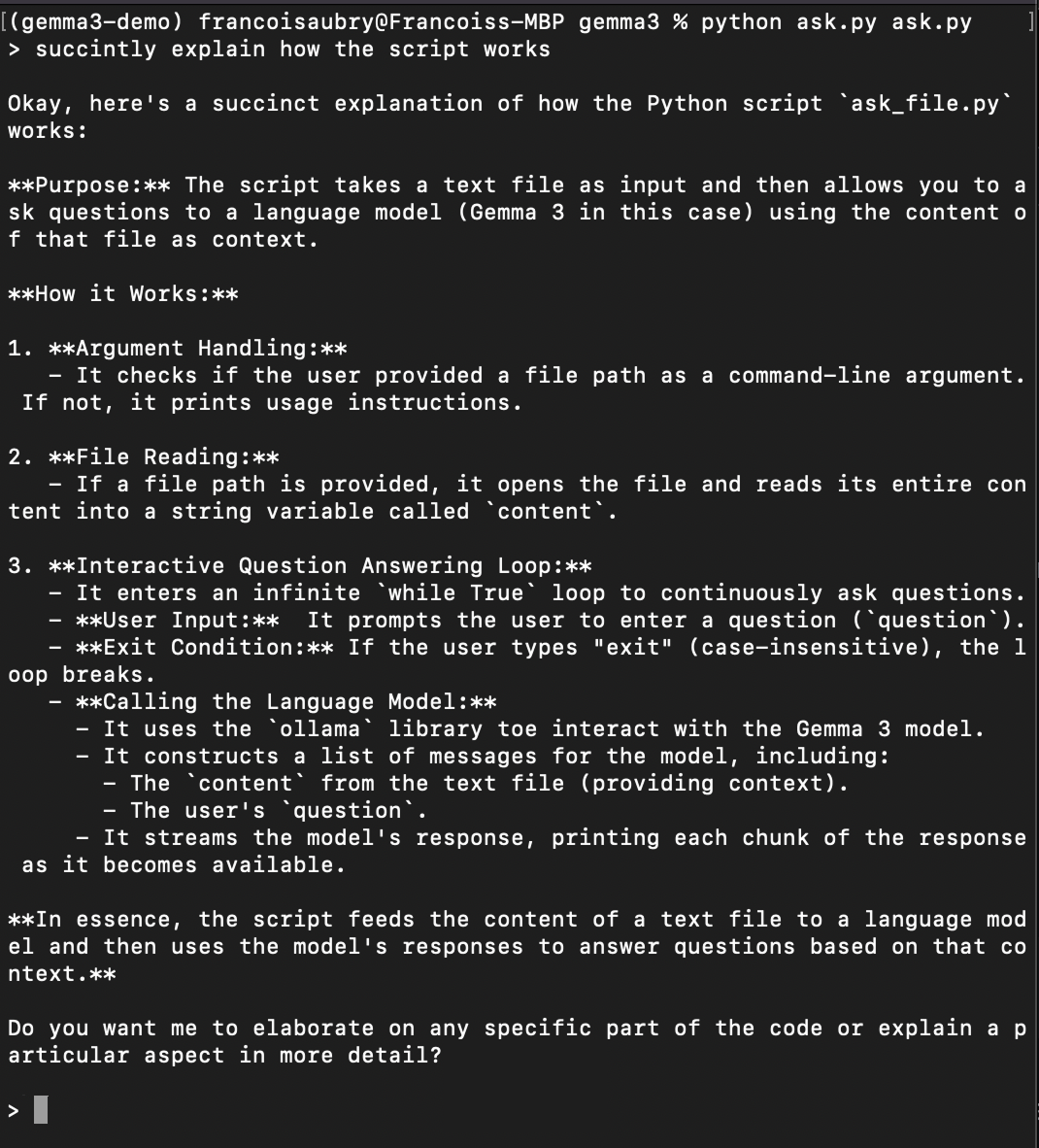
Guarda el código anterior en un archivo llamado, por ejemplo, ask.py. Para probar el script, ejecuta el comando
python ask.py ask.pyEsto ejecutará el script para que se haga preguntas sobre sí mismo (por eso ask.py aparece dos veces en el comando anterior). Aquí tienes un ejemplo de cómo pedirle que te explique cómo funciona el guión:
Hemos configurado con éxito y aprendido a ejecutar Gemma 3 localmente utilizando Ollama y Python. Este enfoque garantiza la privacidad de nuestros datos, ofrece una baja latencia, proporciona opciones de personalización y puede suponer un ahorro de costes. Los pasos que hemos seguido no se limitan a Gemma 3, también pueden aplicarse a otros modelos alojados en Ollama.
Si queremos mejorar la funcionalidad de nuestro script, podríamos, por ejemplo, ampliar sus capacidades para manejar PDFs. La mejor manera de hacerlo sería utilizar el Mistral OCR API. Podemos convertir archivos PDF en texto, lo que permite a nuestro script responder a preguntas sobre PDF, haciéndolo aún más versátil y potente.
Con estas herramientas, ahora estamos equipados para explorar e interactuar con grandes modelos desde nuestros propios dispositivos.
Aprende IA con estos cursos
programa
Curso
Curso
Tutorial
Ryan Ong
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita


