
Cursus
Développer des applications d'IA
21 h
Google DeepMind vient de publier Gemma 3, la prochaine itération de ses modèles open-source. Gemma 3 est conçu pour fonctionner directement sur des appareils à faibles ressources comme les téléphones et les ordinateurs portables. Ces modèles sont optimisés pour des performances rapides sur un seul GPU ou TPU et sont disponibles en différentes tailles pour répondre à différents besoins matériels.
Dans ce tutoriel, je vais vous expliquer pas à pas comment configurer et exécuter Gemma 3 localement à l'aide d'Ollama. Une fois que nous aurons fait cela, je vous montrerai comment vous pouvez utiliser Gemma 3 et Python pour construire un assistant de fichiers.
L'exécution locale d'un grand modèle linguistique (LLM) tel que Gemma 3 présente plusieurs avantages majeurs :
Ollama est une plateforme disponible pour Windows, Mac et Linux qui permet d'exécuter et de distribuer des modèles d'IA, facilitant ainsi l'intégration de ces modèles dans les projets des développeurs. Nous l'utiliserons pour télécharger et exécuter Gemma 3 localement.
La première étape consiste à le télécharger et à l'installer à partir du le site officiel d'Ollama.
Lors de l'installation, assurez-vous d'installer la ligne de commande :
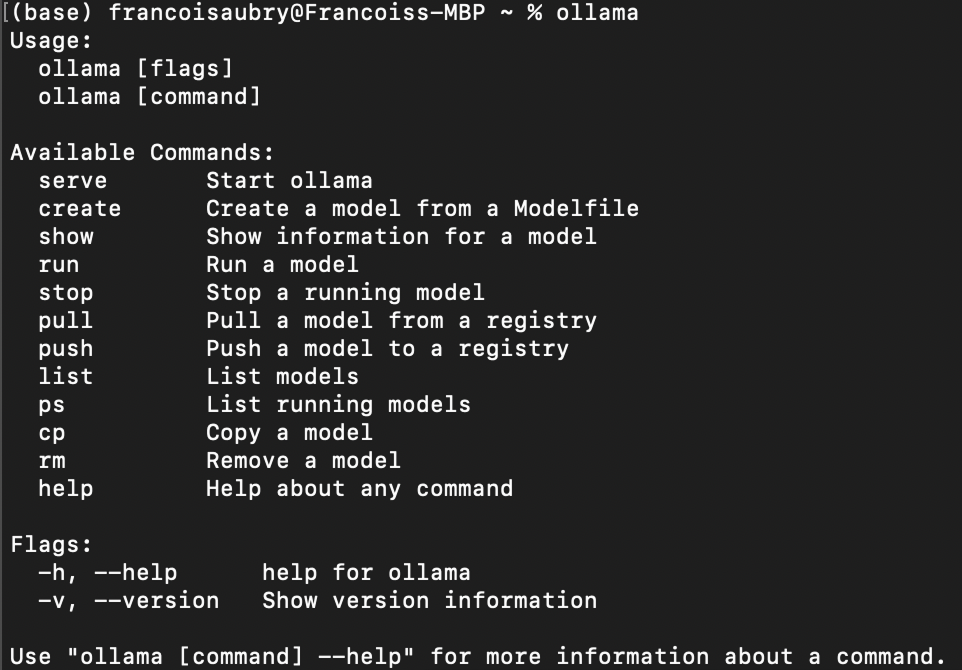
Une fois l'installation terminée, nous pouvons vérifier qu'elle s'est déroulée correctement à l'aide de la commande ollama dans le terminal. Voici ce que devrait être le résultat :
Pour télécharger un modèle avec Ollama, utilisez la commande pull:
ollama pull <model_name>:<model_version>La liste des modèles disponibles se trouve dans la la bibliothèque d'Ollama.
Gemma 3Gemma 3, en particulier, dispose de quatre modèles : 1b 4b , 12b, et 27b, où b signifie milliard, c'est-à-dire le nombre de paramètres dans le modèle.
Par exemple, pour télécharger gemma3 avec les paramètres 1b, nous utilisons la commande :
ollama pull gemma3:1bSi vous ne spécifiez pas la version du modèle, le modèle 4b sera téléchargé par défaut :
ollama pull gemma3Nous pouvons lister les modèles dont nous disposons localement en utilisant la commande suivante :
ollama listDans mon cas, le résultat montre que j'ai deux modèles :
NAME ID SIZE MODIFIED
gemma3:1b 2d27a774bc62 815 MB 38 seconds ago
gemma3:latest c0494fe00251 3.3 GB 22 minutes ago Nous pouvons utiliser Ollama pour discuter avec un modèle à l'aide de la commande run:
ollama run gemma3
Notez que si nous utilisons la commande run avec un modèle que nous n'avons pas téléchargé, il sera téléchargé automatiquement à l'aide de pull.
Pour utiliser Gemma 3 avec Python, nous devons l'exécuter en arrière-plan. Nous pouvons le faire en utilisant la commande serve:
ollama serveSi vous obtenez l'erreur suivante lors de l'exécution de la commande, cela signifie probablement qu'Ollama est déjà en cours d'exécution :
Error: listen tcp 127.0.0.1:11434: bind: address already in useCette erreur peut se produire lorsque Ollama continue à fonctionner en arrière-plan.
Ollama propose un package Python pour se connecter facilement avec les modèles qui tournent sur notre ordinateur.
Nous utiliserons Anaconda pour mettre en place un environnement Python et ajouter les dépendances nécessaires. Cette façon de procéder permet d'éviter d'éventuels problèmes avec d'autres paquets Python que nous pourrions déjà avoir.
Une fois Anaconda installé, nous pouvons configurer l'environnement en utilisant la commande :
conda create -n gemma3-demo -y python=3.9Cette commande met en place un environnement appelé gemma3-demo utilisant la version de Python 3.9. L'option -y permet de répondre automatiquement par l'affirmative à toutes les questions posées lors de l'installation.
Ensuite, nous activons l'environnement à l'aide de :
conda activate gemma3-demoEnfin, nous installons le paquet ollama à l'aide de la commande :
pip install ollamaVoici comment nous pouvons envoyer un message à Gemma 3 en utilisant Python :
from ollama import chat
response = chat(
model="gemma3",
messages=[
{
"role": "user",
"content": "Why is the sky blue?",
},
],
)
print(response.message.content)En fonction de votre matériel, le modèle peut mettre un certain temps à répondre, soyez donc patient lors de l'exécution du script.
Nous avons vu précédemment que gemma3 renvoie par défaut à gemma3:4b. Ainsi, lorsque nous spécifions model="gemma3" comme modèle, c'est celui-ci qui sera utilisé.
Pour utiliser un autre modèle, par exemple le modèle 1B, il faut passer l'argument model=”gemma3:1b” à la place (à condition de l'avoir tiré au préalable à l'aide de la commande ollama pull gemma3:1b ). Pour dresser la liste des modèles disponibles, nous pouvons utiliser la commande ollama list.
Si vous souhaitez lire la réponse mot par mot, vous pouvez utiliser stream=True et imprimer la réponse morceau par morceau :
from ollama import chat
stream = chat(
model="gemma3",
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)L'utilisateur bénéficie ainsi d'une meilleure expérience, car il n'a pas à attendre que la réponse complète soit générée.
Pour en savoir plus sur le paquetage ollama, consultez leur documentation.
Dans cette section, nous apprenons à construire un script Python qui nous permet de poser des questions sur le contenu d'un fichier texte directement depuis le terminal. Ce script sera utile pour des tâches telles que la recherche de bogues dans un fichier de code ou l'interrogation d'informations à partir de n'importe quel document.
Notre objectif est de créer un outil en ligne de commande utilisant Python qui lit un fichier texte et utilise Gemma 3 pour répondre aux questions liées à son contenu. Voici le guide étape par étape pour y parvenir :
Tout d'abord, nous devons configurer le script Python avec les importations nécessaires et la structure de base :
import sys
from ollama import chat
def ask_questions_from_file(file_path):
# Read the content of the text file
with open(file_path, "r") as file:
content = file.read()
# Loop to keep asking questions
while True:
question = input("> ")
print()
if question.lower() == "exit":
break
# Use Gemma 3 to get answers
stream = chat(
model="gemma3",
messages=[
{"role": "user", "content": content},
{"role": "user", "content": question},
],
stream=True,
)
for chunk in stream:
print(chunk["message"]["content"], end="", flush=True)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python ask_file.py <path_to_text_file>")
else:
file_path = sys.argv[1]
ask_questions_from_file(file_path)La fonctionnalité principale est encapsulée dans la fonction ask_questions_from_file(). Cette fonction prend un chemin de fichier comme argument et commence par ouvrir et lire le contenu du fichier texte spécifié. Ce contenu sera utilisé comme information de base pour répondre aux questions.
Une fois le contenu du fichier chargé, le script entre dans une boucle où il nous invite continuellement à saisir des questions. Lorsque nous tapons une question, le script envoie le contenu du fichier ainsi que notre question au modèle Gemma 3, qui traite ces informations pour générer une réponse.
L'interaction avec le modèle se fait par le biais d'un mécanisme de flux, qui permet d'afficher les réponses en temps réel, au fur et à mesure qu'elles sont générées. Si nous tapons exit, la boucle est interrompue et le script s'arrête.
À la fin du script, une vérification est effectuée pour s'assurer que le script est exécuté correctement avec un argument de ligne de commande, qui doit être le chemin d'accès au fichier texte. Si l'argument n'est pas fourni, il affiche un message d'utilisation pour nous guider sur la manière correcte d'exécuter le script. Cette configuration nous permet de diriger efficacement le script à partir de la ligne de commande.
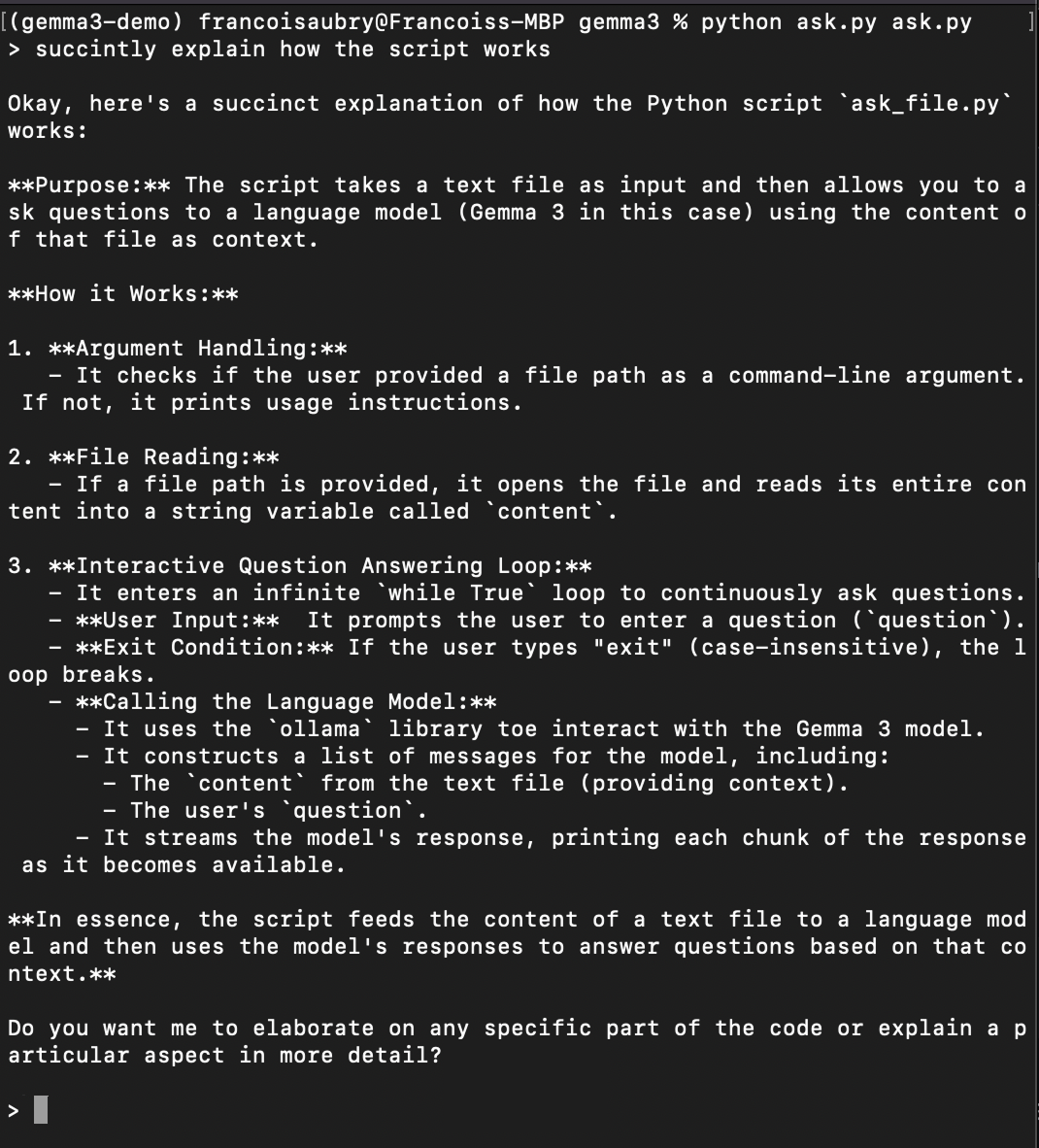
Enregistrez le code ci-dessus dans un fichier nommé, par exemple, ask.py. Pour tester le script, exécutez la commande :
python ask.py ask.pyCela permet au script de se poser des questions sur lui-même (c'est pourquoi ask.py apparaît deux fois dans la commande ci-dessus). Voici un exemple de demande d'explication du fonctionnement du script :
Nous avons réussi à mettre en place et à apprendre à faire fonctionner Gemma 3 localement en utilisant Ollama et Python. Cette approche garantit la confidentialité de nos données, offre une faible latence, propose des options de personnalisation et peut permettre de réaliser des économies. Les étapes que nous avons abordées ne se limitent pas à Gemma 3 : elles peuvent également être appliquées à d'autres modèles hébergés sur Ollama.
Si nous voulons améliorer la fonctionnalité de notre script, nous pouvons, par exemple, étendre ses capacités à la gestion des PDF. La meilleure façon d'y parvenir est d'utiliser le logiciel Mistral OCR DE MISTRAL. Nous pouvons convertir les fichiers PDF en texte, ce qui permet à notre script de répondre à des questions sur les PDF, le rendant ainsi encore plus polyvalent et puissant.
Grâce à ces outils, nous sommes désormais en mesure d'explorer et d'interagir avec de grands modèles à partir de nos propres appareils.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach