
Kurs
Arbeiten mit der OpenAI-API
3 Std.
144.8K
OpenAI has quietly released GPT-5.1-Codex to the developer platform, and developers are already calling it the best coding model available today. Unlike earlier Codex versions, GPT-5.1-Codex is engineered for real software engineering, long-running reasoning, and tool-using agents.
In this tutorial, we will build a complete GitHub Issue Analyzer Agent using OpenAI Agents and GPT-5.1 Codex.
Our agent will:
This agent behaves like a senior engineer, researching, reading, reasoning, and planning before writing anything. You can check out our separate guide on GPT-5.1 to see what else is new.
GPT-5.1 Codex is a specialized version of GPT-5.1, built for long-running, agentic coding tasks rather than just snippet autocompletion. It is purpose-built for real software engineering and agentic workflows, which makes it the perfect engine behind our Issue-to-Plan automation workflow.
Unlike general models, Codex understands codebases the way a senior engineer does; it reads issues, reasons about the architecture, identifies the right directories, and only inspects the files that truly matter. This makes the agent faster, smarter, and far more cost-efficient.
Codex is optimized for long-running, agentic coding tasks. It integrates naturally with developer tools like the GitHub CLI and Firecrawl API, allowing our agent to fetch issues, explore project structures online, read specific files, and gather documentation as needed. It follows instructions closely, produces clean and reliable analysis, and adapts its reasoning effort so it can move quickly on simple tasks while going deeper on more complex ones.
By combining strong code understanding with tool-aware reasoning, GPT-5.1 Codex gives our agent the ability to turn a GitHub issue into an accurate, actionable engineering plan, without scanning the entire repo or hallucinating code. It is the backbone of the workflow because it brings the engineering intuition, structure, and precision that the project depends on.
Before diving into the project, let’s make sure your environment is ready. You will need Git installed on your machine. If you are not sure, just run git --version to confirm. You will also need an OpenAI Developer Platform account with at least $6 in credit so the API calls can run without interruptions.
Next, get the free Firecrawl account and set your API keys as environment variables. These are what allow your analyzer to talk to OpenAI and Firecrawl:
export OPENAI_API_KEY=sk-...
export FIRECRAWL_API_KEY="fc-..." Once that’s in place, install the Python packages that power the workflow. The first one, openai-agents, is a lightweight framework that makes building multi-agent pipelines surprisingly easy. The second, firecrawl-py, handles crawling and extracting useful information from your repositories or documentation.
pip install openai-agents
pip install firecrawl-pyFinally, make sure your GitHub CLI is installed and set up. The following command will help you log in to your GitHub account.
gh auth login
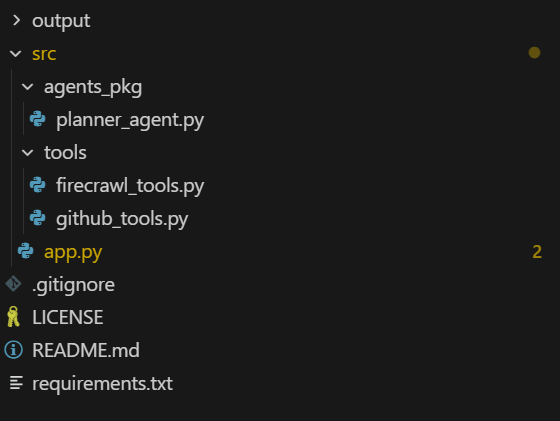
We will create a folder named "src" that will contain all the code files. The "agents_pkg" folder will hold all the agent files, while the "tools" folder will contain all the tool files.
The main application, "app.py," features a command-line interface (CLI) that utilizes the planning agents to generate a GitHub issue report based on user inputs.
Here is how your project directory should look:
First, we will create an agentic tools file that will help the agent access GitHub and Firecrawl API using simple Python functions.
We will start with the tools first. Create a file named firecrawl_tools.py in the src/tools directory and add the following code.
1. Create and return a Firecrawl client using the FIRECRAWL_API_KEY from your environment, and it will raise an error if the key is missing.
import json
import os
from agents import function_tool
from firecrawl import firecrawl
def _get_firecrawl_client():
api_key = os.getenv("FIRECRAWL_API_KEY")
if not api_key:
raise RuntimeError("FIRECRAWL_API_KEY is not set")
return firecrawl(api_key=api_key)2. Uses Firecrawl to run a focused web search (e.g., docs, blog posts, errors) and returns the results as JSON for the agent to use as external context.
@function_tool
def firecrawl_search(query: str, limit: int = 3) -> str:
"""
Run a Firecrawl search for docs related to the issue or tech stack.
Args:
query: Search query (usually based on issue title / framework / error message).
limit: Max number of results to return.
Returns:
JSON string of Firecrawl search results.
"""
client = _get_firecrawl_client()
results = client.search(query=query, limit=limit)
return json.dumps(results)3. Scrapes a single URL with Firecrawl (in markdown format) and returns the structured page content as JSON for deeper technical research.
@function_tool
def firecrawl_scrape(url: str) -> str:
"""
Scrape a single URL using Firecrawl for deeper research.
Args:
url: URL to scrape (docs, blog, README in another repo, etc.).
Returns:
JSON (markdown/structured) content from Firecrawl scrape.
"""
client = _get_firecrawl_client()
result = client.scrape(url=url, params={"formats": ["markdown"]})
return json.dumps(result)Then, we will create a file named github_tools.py in the src/tools directory and add the following code.
1. Fetches a specific GitHub issue via the GitHub CLI and returns its details as JSON for the agent to read.
import base64
import json
import subprocess
from typing import List, Optional
from agents import function_tool
@function_tool
def get_github_issue(repo: str, issue_number: int) -> str:
"""
Fetch a GitHub issue using the GitHub CLI.
Args:
repo: Repository in 'owner/name' format.
issue_number: The issue number to fetch.
Returns:
A JSON string containing the issue fields (title, body, labels, URL, etc.),
or an error payload if the command fails.
"""
try:
result = subprocess.run(
[
"gh",
"issue",
"view",
str(issue_number),
"--repo",
repo,
"--json",
"number,title,body,labels,url,author,createdAt,state,assignees",
],
capture_output=True,
text=True,
check=True,
)
return result.stdout
except subprocess.CalledProcessError as e:
return json.dumps(
{
"error": "Failed to fetch issue via GitHub CLI",
"stderr": e.stderr,
"repo": repo,
"issue_number": issue_number,
}
)2. Lists only the relevant files in a remote GitHub repo (optionally filtered by path and extension) so the agent doesn’t scan the whole project.
@function_tool
def list_repo_files_gh(
repo: str,
max_files: int = 80,
extensions: Optional[List[str]] = None,
path_prefixes: Optional[List[str]] = None,
) -> str:
"""
List *relevant* files in the remote repo using GitHub CLI.
Uses:
gh api repos/{repo}/git/trees/HEAD?recursive=1
The agent is expected to reason first which areas of the codebase are likely relevant
(e.g. 'src/', 'app/', 'backend/api/', 'cli/'), and then call this tool with a small
set of path_prefixes instead of scanning the entire project.
Args:
repo: Repository in 'owner/name' format (e.g. openai/openai-agents-python).
max_files: Max number of files to return.
extensions: Optional list of file extensions to keep (e.g. [".py", ".ts"]).
path_prefixes: Optional list of path prefixes to include (e.g. ["src/", "app/api/"]).
Returns:
JSON string with file paths and filters applied.
"""
try:
result = subprocess.run(
[
"gh",
"api",
f"repos/{repo}/git/trees/HEAD?recursive=1",
],
capture_output=True,
text=True,
check=True,
)
except subprocess.CalledProcessError as e:
return json.dumps(
{
"error": "Failed to list repo files via GitHub CLI",
"stderr": e.stderr,
"repo": repo,
}
)
try:
data = json.loads(result.stdout)
except json.JSONDecodeError:
return json.dumps(
{
"error": "Failed to parse JSON from gh api",
"raw": result.stdout[:2000],
"repo": repo,
}
)
tree = data.get("tree", [])
if extensions is not None and not isinstance(extensions, list):
extensions = [str(extensions)]
exts = [e.lower() for e in (extensions or [])]
if path_prefixes is not None and not isinstance(path_prefixes, list):
path_prefixes = [str(path_prefixes)]
prefixes = [p.strip() for p in (path_prefixes or []) if p.strip()]
paths: List[str] = []
for entry in tree:
if entry.get("type") != "blob":
continue # only files
path = entry.get("path", "")
if not path:
continue
# If prefixes are provided, only keep files under those subtrees
if prefixes and not any(path.startswith(pref) for pref in prefixes):
continue
if exts:
suffix = "." + path.split(".")[-1].lower() if "." in path else ""
if suffix not in exts:
continue
paths.append(path)
if len(paths) >= max_files:
break
return json.dumps(
{
"repo": repo,
"count": len(paths),
"files": paths,
"filtered_by_extensions": bool(exts),
"filtered_by_prefixes": bool(prefixes),
}
)3. Downloads and decodes the contents of a single file from the repo using the GitHub CLI, returning the text (truncated if needed) as JSON.
@function_tool
def get_repo_file_gh(
repo: str,
path: str,
ref: str = "",
max_chars: int = 8000,
) -> str:
"""
Read a file's contents from the remote repo using GitHub CLI.
Uses:
gh api repos/{repo}/contents/{path} [ -F ref=<branch> ]
Args:
repo: Repository in 'owner/name' format.
path: File path in the repo (e.g. 'src/main.py').
ref: Optional branch / commit / tag ref (default: repo's default branch).
max_chars: Max characters of decoded content to return.
Returns:
JSON with file metadata and decoded content (truncated if needed),
or an error payload if anything fails.
"""
cmd = ["gh", "api", f"repos/{repo}/contents/{path}"]
# Only add ref when explicitly set (GitHub default branch otherwise)
if ref:
cmd += ["-F", f"ref={ref}"]
try:
result = subprocess.run(
cmd,
capture_output=True,
text=True,
check=True,
)
except subprocess.CalledProcessError as e:
return json.dumps(
{
"error": "Failed to fetch file via GitHub CLI",
"stderr": e.stderr,
"repo": repo,
"path": path,
"ref": ref or "DEFAULT_BRANCH",
}
)
try:
data = json.loads(result.stdout)
except json.JSONDecodeError:
return json.dumps(
{
"error": "Failed to parse JSON from gh api (contents)",
"raw": result.stdout[:2000],
"repo": repo,
"path": path,
}
)
if data.get("type") != "file":
return json.dumps(
{
"error": "Path is not a file",
"repo": repo,
"path": path,
"data_type": data.get("type"),
}
)
encoding = data.get("encoding")
content_b64 = data.get("content", "")
if encoding != "base64":
return json.dumps(
{
"error": "Unexpected encoding",
"repo": repo,
"path": path,
"encoding": encoding,
}
)
try:
# GitHub often includes newlines in base64 payload
raw_bytes = base64.b64decode(content_b64)
text = raw_bytes.decode("utf-8", errors="replace")
except Exception as e: # noqa: BLE001
return json.dumps(
{
"error": f"Failed to decode file content: {e}",
"repo": repo,
"path": path,
"encoding": encoding,
}
)
truncated = text[:max_chars]
return json.dumps(
{
"repo": repo,
"path": path,
"ref": ref or "DEFAULT_BRANCH",
"truncated": len(text) > max_chars,
"content": truncated,
}
)Here, we define an Issue Planner agent that knows how to:
We wire in the GitHub and Firecrawl tools, give the agent detailed instructions on how to work in a cost-aware way, and tell it to run on the gpt-5.1-codex model.
Create the planner_agent.py file in the src/agents_pkg directory and add the following code:
from agents import Agent
from tools.github_tools import (
get_github_issue,
list_repo_files_gh,
get_repo_file_gh,
)
from tools.firecrawl_tools import (
firecrawl_search,
firecrawl_scrape,
)
def build_planner_agent() -> Agent:
"""
Issue Planner agent that:
- Reads the GitHub issue
- Reasons about which parts of the repo are relevant
- Uses GitHub CLI to inspect a *small* set of files online
- Uses Firecrawl for external research
- Outputs a concrete, step-by-step execution plan
"""
return Agent(
name="Issue Planner",
instructions=(
"You are a senior software engineer.\n"
"Goal: Given a GitHub issue and the online repo (structure + files), plus optional "
"external research, produce a clear, step-by-step execution plan to resolve the issue.\n\n"
"CONTEXT:\n"
"- All repository interaction must be done *online* via GitHub CLI tools.\n"
"- You have tools to: read the issue, list files under certain paths, read specific files, "
" and call Firecrawl search/scrape for docs.\n\n"
"IMPORTANT STRATEGY (BE SMART):\n"
"- Be selective and cost-aware. Do NOT scan the whole project.\n"
"- First, deeply read the issue and infer which part of the system it affects:\n"
" routing layer, CLI, API handlers, DB layer, tests, etc.\n"
"- Based on this reasoning, decide a small list of path prefixes and file types.\n\n"
"RECOMMENDED WORKFLOW:\n"
"1. Call get_github_issue(repo, issue_number) to fully understand the problem.\n"
"2. From the issue, infer a small list of path prefixes where relevant code likely lives,\n"
" e.g. ['src/', 'app/', 'backend/api/', 'cli/'] depending on the project style.\n"
"3. Call list_repo_files_gh with:\n"
" - extensions like ['.py', '.ts', '.js', '.tsx', '.jsx']\n"
" - path_prefixes set to that small, targeted list\n"
" This keeps the search focused instead of scanning the entire project.\n"
"4. From the returned file list, pick at most ~5-15 key files that are most likely related\n"
" (entrypoints, routers, handlers, services, tests).\n"
"5. Call get_repo_file_gh(repo, path=...) only on those selected files to inspect the "
" actual implementation.\n"
"6. If you need framework or library context (FastAPI, Click, React, etc.), use\n"
" firecrawl_search and firecrawl_scrape to pull official docs or good examples.\n\n"
"OUTPUT FORMAT (execution plan):\n"
"After you have enough context from the issue + targeted code inspection (+ optional research), "
"output a concise but concrete plan with sections:\n"
" - Issue summary\n"
" - Project/codebase understanding (where this issue lives in the architecture)\n"
" - Key files / components to touch (with file paths)\n"
" - Step-by-step implementation plan (Step 1, Step 2, ...)\n"
" - Testing strategy (unit / integration / manual)\n"
" - Edge cases, risks, and any open questions\n\n"
"The plan must be actionable for a mid-level developer. Avoid generic advice; tie your steps "
"to the actual files and modules you inspected.\n"
),
tools=[
get_github_issue,
list_repo_files_gh,
get_repo_file_gh,
firecrawl_search,
firecrawl_scrape,
],
model="gpt-5.1-codex",
)This is the main Python file that provides a command-line interface (CLI) and integrates all the logic, callbacks, and error handling into one comprehensive file. It utilizes tools and agents from other files efficiently.
1. First, we set up and import everything the CLI needs. We include standard libraries, ensure proper Unicode output on Windows so that emojis and symbols print correctly, and import the OpenAI runner along with our planner agent.
2. Next, we define the command-line options, allowing you to pass in a GitHub repository and issue number when you run the tool.
src/app.py:
import argparse
import asyncio
import json
import os
import pathlib
import sys
from datetime import datetime
# Set UTF-8 encoding for stdout to handle Unicode characters
if sys.platform == "win32":
import codecs
sys.stdout = codecs.getwriter("utf-8")(sys.stdout.detach())
sys.stderr = codecs.getwriter("utf-8")(sys.stderr.detach())
from agents import Runner, ItemHelpers
from openai.types.responses import ResponseTextDeltaEvent
from agents_pkg.planner_agent import build_planner_agent
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(
description=(
"Issue Planner: GPT-5.1-Codex + OpenAI Agents + GitHub CLI + Firecrawl\n" )
)
parser.add_argument(
"--repo",
help="GitHub repo in 'owner/name' format (e.g. openai/openai-agents-python).",
)
parser.add_argument(
"--issue",
type=int,
help="Issue number to plan for.",
)
return parser.parse_args()
3. Then, we collect the inputs and prepare the context. We read the repo and issue from arguments, make sure the OpenAI API key is set, build a clear prompt that tells the agent how to analyse the issue step by step, and create a timestamped markdown file where the final plan will be saved.
def get_user_input(args: argparse.Namespace) -> tuple[str, int]:
"""Get repository and issue number from arguments or user input."""
repo = args.repo or input("GitHub repo (owner/name): ").strip()
issue_number = args.issue or int(input("Issue number: ").strip())
return repo, issue_number
def validate_environment() -> None:
"""Validate that required environment variables are set."""
if not os.getenv("OPENAI_API_KEY"):
raise RuntimeError("OPENAI_API_KEY is not set")
def build_user_prompt(repo: str, issue_number: int) -> str:
"""Build the user prompt for the agent."""
return (
f"You are helping me plan how to implement GitHub issue #{issue_number} "
f"in repo '{repo}'.\n\n"
"Be selective and cost-aware:\n"
"1. Use get_github_issue(repo, issue_number) to understand the problem.\n"
"2. Based on the issue text, first reason about which directories and components "
" are likely relevant.\n"
"3. Call list_repo_files_gh(repo, extensions=['.py', '.ts', '.js', '.tsx', '.jsx'], "
" path_prefixes=[<your inferred prefixes>]) to only explore those areas.\n"
"4. From those results, choose a small set of the most relevant files and call "
" get_repo_file_gh(repo, path=...) on them.\n"
"5. Optionally, use firecrawl_search and firecrawl_scrape if you need external docs.\n"
"6. Finally, generate the execution plan in the structured format from your instructions."
)
def setup_output_file(repo: str, issue_number: int) -> pathlib.Path:
"""Create output directory and return the markdown file path."""
output_dir = pathlib.Path("output")
output_dir.mkdir(exist_ok=True)
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
markdown_file = output_dir / f"execution_plan_{repo.replace('/', '_')}_issue_{issue_number}_{timestamp}.md"
return markdown_file4. Next, we make the agent’s thinking visible. We try to pull out a clean reasoning snippet from each event and print a short “💭 Reasoning…” line, so instead of raw internals, you see a human-readable hint of what the model is working on in the background.
def extract_reasoning_text(event_item) -> str | None:
"""Extract reasoning text from a reasoning event item."""
reasoning_text = None
if hasattr(event_item, 'raw_item'):
raw = event_item.raw_item
# Try multiple attribute names
for attr_name in ['content', 'text', 'reasoning', 'message', 'delta']:
if hasattr(raw, attr_name):
val = getattr(raw, attr_name)
if val and str(val).strip() and str(val) != 'None':
reasoning_text = str(val)
break
# If still not found, try to access as dict-like
if not reasoning_text:
try:
if hasattr(raw, '__dict__'):
for key, val in raw.__dict__.items():
if val and str(val).strip() and str(val) != 'None' and key in ['content', 'text', 'reasoning', 'message', 'delta']:
reasoning_text = str(val)
break
except:
pass
# Also try direct attributes on event.item
if not reasoning_text:
for attr_name in ['content', 'text', 'reasoning', 'message']:
if hasattr(event_item, attr_name):
val = getattr(event_item, attr_name)
if val and str(val).strip() and str(val) != 'None':
reasoning_text = str(val)
break
return reasoning_text
def handle_reasoning_event(event_item) -> None:
"""Handle and display reasoning events."""
reasoning_text = extract_reasoning_text(event_item)
if reasoning_text and reasoning_text.strip():
# Show first line or first 100 chars
first_line = reasoning_text.split('\n')[0].strip()[:100]
if len(reasoning_text.split('\n')[0].strip()) > 100:
first_line += "..."
print(f"\n💭 Reasoning: {first_line}", flush=True)
else:
# Don't show "None" - just show that reasoning is happening
print(f"\n💭 Reasoning...", flush=True)5. After that, we handle tool calls and tracking. We detect which tool the agent is using, format its arguments (like repo, path, or query) into a compact string, print a “🔧 Calling…” message, and keep an internal map of active tools so we can mark them as completed and later summarise everything that ran.
def extract_tool_info(event_item) -> tuple[str | None, str | None]:
"""Extract tool name and ID from a tool call event item."""
tool_name = None
tool_id = None
# First try raw_item which contains the actual tool call data
if hasattr(event_item, 'raw_item'):
raw = event_item.raw_item
# Try accessing tool_call through various paths
tool_call = None
if hasattr(raw, 'tool_call'):
tool_call = raw.tool_call
elif hasattr(raw, 'function_call'):
tool_call = raw.function_call
if tool_call:
# Try to get name from tool_call
if hasattr(tool_call, 'name'):
tool_name = tool_call.name
elif hasattr(tool_call, 'function') and hasattr(tool_call.function, 'name'):
tool_name = tool_call.function.name
# Try to get ID
if hasattr(tool_call, 'id'):
tool_id = tool_call.id
elif hasattr(tool_call, 'tool_call_id'):
tool_id = tool_call.tool_call_id
# Fallback: try direct attributes on raw
if not tool_name:
if hasattr(raw, 'name'):
tool_name = getattr(raw, 'name')
elif hasattr(raw, 'function') and hasattr(raw.function, 'name'):
tool_name = raw.function.name
# Try using getattr with different possible attribute names
for attr_name in ['tool_name', 'function_name', 'name']:
if hasattr(raw, attr_name):
tool_name = getattr(raw, attr_name, None)
if tool_name:
break
# Fallback to direct attributes
if not tool_name and hasattr(event_item, 'tool_call'):
tool_call = event_item.tool_call
if hasattr(tool_call, 'name'):
tool_name = tool_call.name
if hasattr(tool_call, 'id'):
tool_id = tool_call.id
elif hasattr(tool_call, 'function') and hasattr(tool_call.function, 'name'):
tool_name = tool_call.function.name
if not tool_name and hasattr(event_item, 'name'):
tool_name = event_item.name
if not tool_name and hasattr(event_item, 'function'):
func = event_item.function
if hasattr(func, 'name'):
tool_name = func.name
return tool_name, tool_id
def format_tool_arguments(tool_call_obj) -> str:
"""Format tool arguments for display."""
if not tool_call_obj or not hasattr(tool_call_obj, 'arguments'):
return ""
try:
args_dict = json.loads(tool_call_obj.arguments) if isinstance(tool_call_obj.arguments, str) else tool_call_obj.arguments
if 'repo' in args_dict:
tool_args = f" → {args_dict['repo']}"
if 'issue_number' in args_dict:
tool_args += f"#{args_dict['issue_number']}"
return tool_args
elif 'path' in args_dict:
return f" → {args_dict['path']}"
elif 'query' in args_dict:
q = str(args_dict['query'])
return f" → {q[:40]}..." if len(q) > 40 else f" → {q}"
elif 'url' in args_dict:
return f" → {args_dict['url']}"
elif 'extensions' in args_dict or 'path_prefixes' in args_dict:
parts = []
if 'extensions' in args_dict:
parts.append(f"ext={args_dict['extensions']}")
if 'path_prefixes' in args_dict:
parts.append(f"paths={args_dict['path_prefixes']}")
return f" → {', '.join(parts)}"
except:
pass
return ""
def handle_tool_call_event(event_item, active_tools: dict, tool_counter: int) -> tuple[int, bool]:
"""Handle tool call events and return updated tool_counter and whether event was handled."""
tool_name, tool_id = extract_tool_info(event_item)
if tool_name:
tool_counter += 1
tool_id = tool_id or f"tool_{tool_counter}"
active_tools[tool_id] = tool_name
# Get tool arguments if available
tool_call_obj = None
if hasattr(event_item, 'raw_item') and hasattr(event_item.raw_item, 'tool_call'):
tool_call_obj = event_item.raw_item.tool_call
elif hasattr(event_item, 'tool_call'):
tool_call_obj = event_item.tool_call
tool_args = format_tool_arguments(tool_call_obj)
print(f"\n[{tool_counter}] 🔧 Calling: {tool_name}{tool_args}...", flush=True)
return tool_counter, True
else:
# Still couldn't extract - try to inspect raw_item structure
if hasattr(event_item, 'raw_item'):
raw = event_item.raw_item
try:
raw_attrs = [attr for attr in dir(raw) if not attr.startswith('_')]
# Look for attributes that might contain the tool name
for attr in raw_attrs:
try:
val = getattr(raw, attr)
if isinstance(val, str) and ('get_github' in val.lower() or 'list_repo' in val.lower() or 'firecrawl' in val.lower()):
tool_name = val
break
# Check if it's a dict-like object with name
if hasattr(val, 'name'):
tool_name = val.name
break
except:
continue
if tool_name:
tool_counter += 1
tool_id = tool_id or f"tool_{tool_counter}"
active_tools[tool_id] = tool_name
print(f"\n[{tool_counter}] 🔧 Calling: {tool_name}...", flush=True)
return tool_counter, True
else:
# Print raw_item structure for debugging
print(f"\n[DEBUG] raw_item attrs: {raw_attrs[:10]}", flush=True)
except Exception as e:
print(f"\n[DEBUG] Error inspecting raw_item: {e}", flush=True)
return tool_counter, False
def handle_tool_output_event(event_item, active_tools: dict, completed_tools: list) -> None:
"""Handle tool output events and track completed tools."""
tool_id = None
# Try raw_item first
if hasattr(event_item, 'raw_item') and hasattr(event_item.raw_item, 'tool_call_id'):
tool_id = event_item.raw_item.tool_call_id
elif hasattr(event_item, 'tool_call_id'):
tool_id = event_item.tool_call_id
elif hasattr(event_item, 'raw_item') and hasattr(event_item.raw_item, 'tool_call'):
if hasattr(event_item.raw_item.tool_call, 'id'):
tool_id = event_item.raw_item.tool_call.id
elif hasattr(event_item, 'tool_call'):
if hasattr(event_item.tool_call, 'id'):
tool_id = event_item.tool_call.id
elif hasattr(event_item.tool_call, 'function') and hasattr(event_item.tool_call.function, 'name'):
# Try to match by name if ID not available
tool_name_match = event_item.tool_call.function.name
for tid, tname in active_tools.items():
if tname == tool_name_match:
tool_id = tid
break
if tool_id and tool_id in active_tools:
tool_name = active_tools.pop(tool_id)
completed_tools.append(tool_name)
elif active_tools:
# Fallback: use the first active tool
tool_id, tool_name = next(iter(active_tools.items()))
active_tools.pop(tool_id)
completed_tools.append(tool_name)6. Now, we wire up the streaming loop and persistence. We process streaming events from the agent, print tokens as they arrive, show reasoning and tool calls in real time, fall back gracefully to a non-streaming run if something goes wrong, and finally write the complete execution plan to a markdown file with some useful metadata.
async def process_streaming_events(result, repo: str, issue_number: int) -> str:
"""Process streaming events from the agent execution."""
final_output = ""
active_tools = {} # Track active tool calls by ID
tool_counter = 0
completed_tools = []
first_event_received = False
# Stream the events as they come in
async for event in result.stream_events():
# Handle raw response events (token-by-token streaming) - print immediately
if event.type == "raw_response_event" and isinstance(event.data, ResponseTextDeltaEvent):
if not first_event_received:
first_event_received = True
delta = event.data.delta
print(delta, end="", flush=True)
final_output += delta
# Handle run item events (higher level updates)
elif event.type == "run_item_stream_event":
item_type = getattr(event.item, 'type', 'unknown')
# Show reasoning events
if item_type == "reasoning_item":
handle_reasoning_event(event.item)
elif item_type == "tool_call_item":
tool_counter, handled = handle_tool_call_event(event.item, active_tools, tool_counter)
if handled:
first_event_received = True
elif item_type == "tool_call_output_item":
handle_tool_output_event(event.item, active_tools, completed_tools)
elif item_type == "message_output_item":
message_text = ItemHelpers.text_message_output(event.item)
if message_text and (not final_output or message_text not in final_output):
print(f"\n{message_text}", flush=True)
final_output += message_text
print() # Add newline after streaming
# Show summary of tools used
if completed_tools:
print(f"---\n\n📊 Tools used ({len(completed_tools)}): {', '.join(completed_tools)}", flush=True)
# If no streaming events occurred, fall back to final output
if not final_output:
final_output = result.final_output
if final_output:
print(final_output, flush=True)
return final_output
async def run_agent_with_streaming(agent, user_prompt: str, repo: str, issue_number: int) -> str:
"""Run the agent with streaming support and fallback handling."""
try:
# Run agent with streaming (run_streamed is synchronous, returns immediately)
result = Runner.run_streamed(
agent,
input=user_prompt,
context={"repo": repo, "issue_number": issue_number},
)
return await process_streaming_events(result, repo, issue_number)
except Exception as e:
print(f"⚠️ Error: {e}", flush=True)
# Fallback to standard async run
result = await Runner.run(
agent,
input=user_prompt,
context={"repo": repo, "issue_number": issue_number},
)
print(result.final_output, flush=True)
return result.final_output
def save_output_to_file(markdown_file: pathlib.Path, repo: str, issue_number: int, final_output: str) -> None:
"""Save the final output to a markdown file."""
with open(markdown_file, 'w', encoding='utf-8') as f:
f.write(f"# GitHub Issue Analysis: {repo}#{issue_number}\n\n")
f.write(f"**Generated on:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")
f.write(f"**Repository:** {repo}\n")
f.write(f"**Issue Number:** {issue_number}\n\n")
f.write("---\n\n")
f.write(final_output)
print(f"---\n\n✅ Saved: {markdown_file}", flush=True)7. Finally, we tie everything together in the main entry point. We parse the arguments, get the repo and issue, validate the environment, build the agent and its prompt, run the planner with streaming (falling back to a sync run if needed), and save the result.
async def main() -> None:
"""Main entry point for the application."""
args = parse_args()
repo, issue_number = get_user_input(args)
validate_environment()
agent = build_planner_agent()
user_prompt = build_user_prompt(repo, issue_number)
markdown_file = setup_output_file(repo, issue_number)
print(f"\n🔍 Analyzing {repo}#{issue_number}...\n")
# Run the agent with streaming support
try:
final_output = await run_agent_with_streaming(agent, user_prompt, repo, issue_number)
except Exception as e:
print(f"⚠️ Error: {e}", flush=True)
# Final fallback to standard sync run
result = Runner.run_sync(
agent,
input=user_prompt,
context={"repo": repo, "issue_number": issue_number},
)
print(result.final_output, flush=True)
final_output = result.final_output
# Save output to file
save_output_to_file(markdown_file, repo, issue_number, final_output)
if __name__ == "__main__":
asyncio.run(main())Note: The source code, configuration, and documentation are available at the GitHub repository: kingabzpro/Issue-Analyzer. Please review it and use it as a guide when replicating the results.
There are two ways to use our CLI app: Interactive mode, where the app will prompt you one by one to provide the repository name and issue number, and CLI mode, where you must provide all the information when launching the app.
To start the interactive mode, type the following command:
python src/app.pyOnce started, you will be prompted to provide the repository name and issue number, and the app will begin using tools and reasoning to assist you.
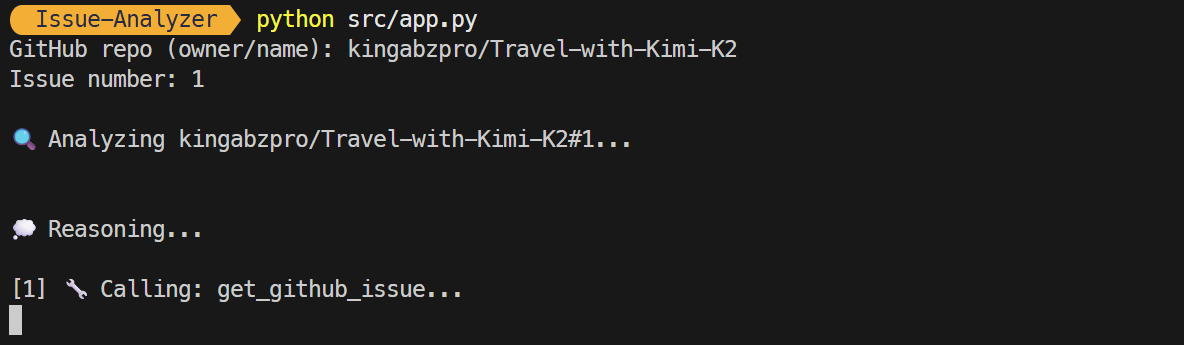
As a result, within a few seconds, you will receive a summary of the issue and ways to resolve it. This summary includes details about the tools used and the location of the markdown file where the information is saved.
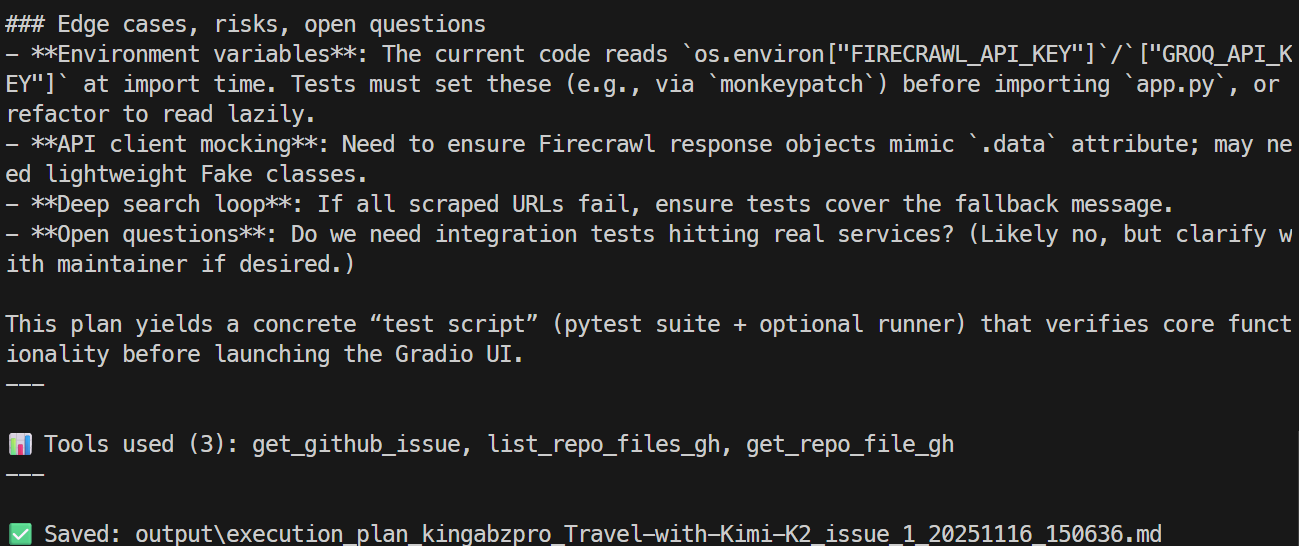
You can open the markdown file to review a detailed issue plan.

The CLI mode requires the repository name and issue argument to be included directly in the command, as shown below:
python src/app.py --repo kingabzpro/Travel-with-Kimi-K2 --issue 1The entire process is streamed, meaning you will see which tools the agent is using and whether it is reasoning effectively or not. It will also stream the response generated at the end.
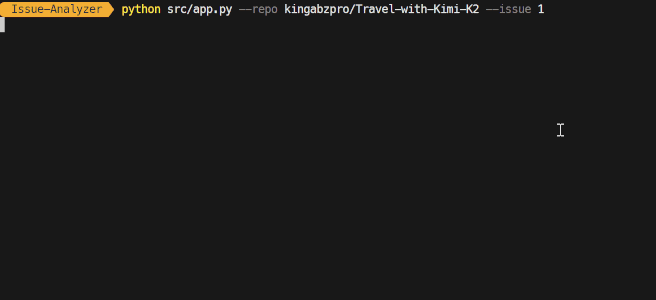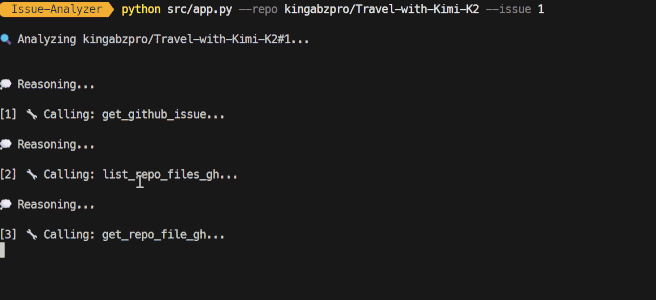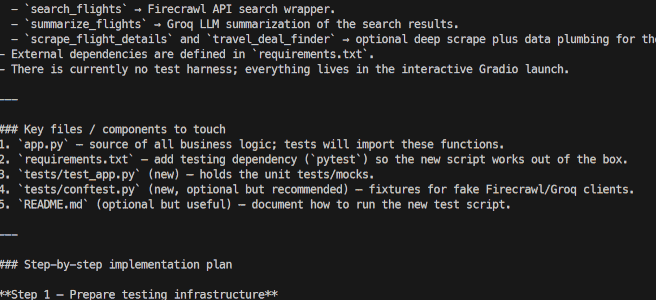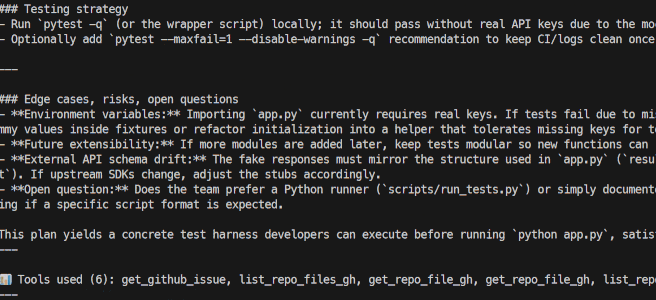
The current version of the GitHub Issue Analyzer is designed to understand issues and generate accurate execution plans.
However, the true potential of an agentic workflow lies in automating all the steps that occur after the plan is created. Here are some major upgrades that you can implement in the system:
The goal of the project is to transform a plan into a functioning pull request automatically. This will streamline the development process, allowing for a more efficient workflow.
This feature will include the ability to create a new branch directly from the agent, which will facilitate the implementation of changes. Additionally, the agent will apply code modifications based on the generated plan and run GitHub CLI workflows, such as gh pr create and gh pr view.
Moreover, the system will generate pull request descriptions, changelogs, and linked issue references automatically. It will also apply labels intelligently, categorizing them as bug fixes, enhancements, or refactors.
Overall, this initiative effectively transforms the agent into a fully autonomous Issue to Pull Request automation system, significantly enhancing productivity and consistency in the development cycle.
This upgrade will enhance the process of issue analysis by introducing batch capabilities for GitHub issues. Instead of focusing on individual problems, teams will be able to perform batch scans on multiple issues simultaneously. This new feature allows for either parallel or queued analysis of entire backlogs, making it easier to handle larger volumes of issues effectively.
Additionally, this upgrade will facilitate the identification of duplicate or related issues, enabling better organization. Issues can be classified based on criteria such as complexity, subsystem, or impact.
To further streamline operations, teams will be able to run GitHub or Firecrawl tools in a batched mode, significantly improving efficiency. Ultimately, this upgrade provides teams with a single command that can automatically triage dozens or even hundreds of issues at once.
Before creating a pull request (PR), it is essential for the agent to thoroughly validate the proposed changes rather than simply generating them. This validation process should encompass several planned features, including running unit tests through GitHub Actions or local test runners to ensure the code behaves as expected.
Dependency validation is also critical. It involves checking imports for accuracy, identifying any missing modules, and resolving version mismatches that could affect the project. Furthermore, linting, formatting, and type checking play a crucial role in maintaining code quality.
It is vital to ensure that the modifications do not disrupt existing build pipelines and to detect any breaking changes to APIs or regressions. By adhering to these steps, we can ensure that the PR remains clean, safe, and ready for production deployment.
Building advanced, multi-step agents with GPT-5.1 Codex and openai-agents is surprisingly simple. All you really need to do is define your own tools and give the model clear instructions on when and how to use them.
In this tutorial, I used the GitHub CLI because it’s fast, intuitive, and easy to integrate, but you could just as easily use the GitHub Python SDK, direct API calls, or any other CLI or Bash utility. The flexibility is the real power here.
You can extend this setup as far as you want.
For example, you could create:
The goal of this tutorial was to show what GPT-5.1 Codex can really do: It handles tool-calling effortlessly, understands large codebases, performs structured reasoning, and can run long automation chains without constant user input.
If you’re keen to learn more about creating AI agents, I recommend checking out our AI Agents with Google ADK course, as well as our list of AI agent projects to build.
Top DataCamp Courses
Kurs
Kurs
Kurs
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan