Lernpfad
ChatGPT-Grundlagen
3 Std.
Die AutoGPT-Plattform ist eine Plattform, die es Nutzern ermöglicht, kontinuierliche KI-Agenten zu erstellen, einzusetzen und zu verwalten. Es nutzt eine Low-Code-Benutzeroberfläche, um Tausende von digitalen Prozessen zu automatisieren, wobei die Agenten im Hintergrund autonom arbeiten.
Die AutoGPT-Plattform besteht aus zwei Kernkomponenten: dem AutoGPT-Server, der die Hauptlogik und -infrastruktur enthält, und dem AutoGPT-Frontend, der Benutzeroberfläche für die Erstellung der Agenten, die Verwaltung der Arbeitsabläufe und die Implementierung wiederkehrender Zeitpläne.
Es ist mit LLM-Anbietern wie OpenAI, Anthropic, Groq und Llama vorintegriert, so dass eine Vielzahl von Aufgaben wie Datenverarbeitung, Inhaltserstellung oder sogar Spaßaktivitäten automatisiert werden können.
In diesem Tutorial zeigen wir technischen Fachkräften, wie sie die AutoGPT-Plattform lokal einrichten und ihren ersten Agenten erstellen können. Du kannst unseren vollständigen Leitfaden zum Verständnis von KI-Agenten lesen, um mehr zu erfahren, und auch die verschiedenen Arten von KI-Agenten in einem separaten Artikel entdecken.
AutoGPT ist eine KI-Plattform/Software, die es Nutzern ermöglicht, autonome KI-Agenten zu erstellen, einzusetzen und zu verwalten. Diese Agenten können verschiedene Aufgaben mit minimaler menschlicher Aufsicht über eine Low-Code-Schnittstelle ausführen, die auf dem Computer des Nutzers installiert wird.
Zum Zeitpunkt der Erstellung dieses Artikels gibt es eine offene Warteliste für eine kommende Cloud-Version von AutoGPT, wenn du dir die Mühe der lokalen Einrichtung ersparen willst.
Zu den wichtigsten Funktionen und Möglichkeiten von AutGPT gehören:
Die AutoGPT-Plattform besteht aus zwei Hauptkomponenten:
1. AutoGPT-Server:
2. AutoGPT frontend:
Das Backend von AutoGPT verwendet Python mit FastAPI als Web-Framework und PostgreSQL mit Prisma ORM zur Datenspeicherung. Sie nutzt Websockets für die Echtzeitkommunikation und enthält Manager für die Ausführung, Planung und Benachrichtigung.
Dieses Design verbessert die Skalierbarkeit und Wartung, wenn die Plattform wächst.
Das Frontend verwendet Next.js 14 mit TypeScript, Radix-Komponenten und Tailwind-CSS, wobei der Workflow mit xyflow visualisiert wird. So entsteht eine intuitive Low-Code-Schnittstelle, mit der Nutzer/innen KI-Agenten ohne umfangreiche Programmierkenntnisse erstellen können.
Die Plattform umfasst diese wichtigen Dienste:
Als AutoGPT um das Jahr 2023 herum zum ersten Mal angekündigt wurde, erfreute es sich großer Beliebtheit und wurde als der Open-Source-Killer von ChatGPT angesehen. Natürlich war das nur ein Hype, der von Social-Media-Influencern angeheizt wurde, denn jetzt ist es 2025 und ChatGPT ist immer noch da. Aber AutoGPT signalisiert, dass sich der Fokus der KI-Gemeinschaft auf KI-Agenten verlagert.
Die früheren Versionen von AutoGPT versprachen völlig autonome Agenten, die mit einer einzigen Eingabeaufforderung erstellt werden konnten. Es könnte die Eingabeaufforderung in überschaubare Aufgaben aufteilen und eine Vielzahl von Tools, Software und APIs zusammenstellen, um die Aufgabe zu erledigen, während das Kurz- und Langzeitgedächtnis durch eine selbstreflektierende Feedbackschleife gestärkt wird.
Im Laufe der Zeit müssen sie jedoch erkannt haben, dass dieser Ansatz aufgrund der Unvorhersehbarkeit von LLMs in Produktionsszenarien an seine Grenzen stößt.
Heute ist AutoGPT keine "Prompt-to-Agent"-Plattform, sondern etwas viel Besseres - eine Low-Code-Plattform, die den Nutzern die Kontrolle darüber gibt, wie ihre Agenten erstellt werden. Du kannst diesen Wandel von der ursprünglichen Version von AutoGPT zu der Plattform, die wir im Jahr 2025 haben, sehen, wenn du die Beiträge von vor 1-2 Jahren liest oder dir YouTube-Videos ansiehst.
Diese Beiträge zeigen ganz andere Einrichtungsanweisungen und Arbeitsabläufe als das, was ich dir jetzt beibringen werde.
Schauen wir uns also ohne Umschweife an, wie du die Plattform auf deinem Rechner einrichten kannst.
Um AutoGPT lokal einzurichten, musst du deine Entwicklungsumgebung richtig konfigurieren und dich mit Containerisierungswerkzeugen auskennen - schau dir unseren Kurs über Containerisierung und Virtualisierung mit Docker und Kubernetes an, wenn du eine Auffrischung brauchst. Dieser Abschnitt führt dich durch den gesamten Prozess von den Voraussetzungen bis zur ersten Inbetriebnahme der Plattform.
Bevor du AutoGPT installierst, musst du sicherstellen, dass du die folgenden Voraussetzungen erfüllst:
1. Node.js & NPM
brew install nodesudo apt update sudo apt install nodejs npmnode -v npm -v2. Docker & Docker Compose
sudo apt update sudo apt install docker.io docker-compose sudo systemctl enable --now dockerdocker -v docker compose -v3. Git
brew install gitsudo apt update sudo apt install gitgit clone https://github.com/Significant-Gravitas/AutoGPT.gitDiese Voraussetzungen sind wichtig, um AutoGPT effektiv zu nutzen. Für die Frontend-Anwendung werden Node.js und NPM benötigt, damit du über eine benutzerfreundliche Oberfläche mit AutoGPT interagieren kannst.
Docker und Docker Compose erstellen isolierte Container, die eine konsistente Leistung über verschiedene Systeme hinweg gewährleisten und die Bereitstellung der Backend-Dienste vereinfachen. Mit Git kannst du das Repository klonen und mit den neuesten Verbesserungen auf dem Laufenden bleiben.
Nach diesem Schritt musst du das AutoGPT-Verzeichnis auf deinem Rechner haben, das alles enthält, um die Anwendung auszuführen. Das Einzige, was bleibt, ist die Konfiguration.
Docker bietet eine isolierte, konsistente Umgebung für die Ausführung von AutoGPT und stellt sicher, dass alle Abhängigkeiten unabhängig von deinem Hostsystem korrekt funktionieren.
cd AutoGPT/autogpt_platform
cp .env.example .env
docker compose up -d --buildDie neue Datei .env enthält Umgebungsvariablen, die mit sinnvollen Standardwerten gefüllt sind. Du musst diese Datei nicht unbedingt selbst konfigurieren, aber ihr Vorhandensein ist ein Muss. Sie wird von der Fronted Application verwendet, wenn du bei der Erstellung deiner benutzerdefinierten Agenten verschiedene Schlüssel und Geheimnisse angibst.
Der letzte Befehl docker compose kann bis zu 15 Minuten dauern, je nachdem, wie schnell dein Internet beim ersten Durchlauf ist. Sie richtet die Backend-Komponenten ein, mit denen sich das Frontend verbinden wird.
cd frontend
cp .env.example .env
npm install
npm run devDiese Befehle richten die Umgebungsdatei für das Frontend ein, installieren seine Abhängigkeiten mit Node.js und starten die Benutzeroberfläche.
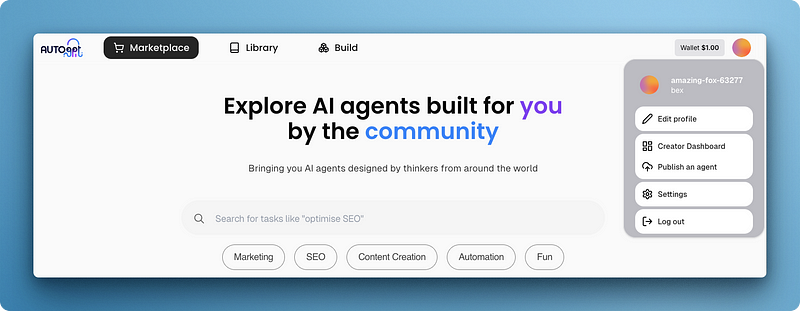
Wenn du Port 3000 besuchst, wird dir die Marketplace-Benutzeroberfläche angezeigt, über die du dein Konto erstellen und dich anmelden musst.
# Generate a new key with Python
from cryptography.fernet import Fernet
Fernet.generate_key().decode()
# Or use the built-in CLI
poetry run cli gen-encrypt-keyErsetze den vorhandenen Schlüssel auf autogpt_platform/backend/.env durch deinen neuen Schlüssel.
Hinweis für Windows-Benutzer: Wenn du Docker unter Windows verwendest, wähle bei der Installation WSL 2 anstelle von Hyper-V, um Kompatibilitätsprobleme mit Supabase zu vermeiden. Wenn du bereits mit Hyper-V installiert hast, kannst du in den Docker Desktop-Einstellungen zu WSL 2 wechseln.
Bevor wir einen funktionierenden Agenten erstellen, wollen wir ein Gefühl für die Benutzeroberfläche von AutGPT bekommen.
Die Oberfläche ist eine große leere Leinwand mit vier Hauptschaltflächen:
Wenn du auf "Blöcke" klickst, erscheint ein Menü mit den in AutoGPT eingebauten wiederverwendbaren Komponenten, die in Kategorien gruppiert sind.
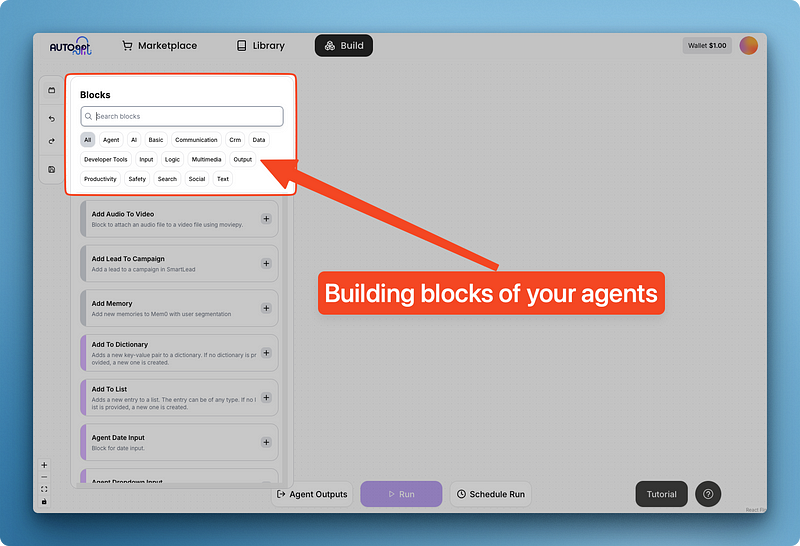
Diese Blöcke bieten wichtige Werkzeuge, die in vielen Agentenszenarien universell eingesetzt werden können.
Unten habe ich zum Beispiel zwei Blöcke gesucht und hinzugefügt - Langtexteingabe und KI-Textgenerator. Diese beiden Komponenten reichen mir aus, um die Grundversion der ChatGPT-Oberfläche nachzubauen:
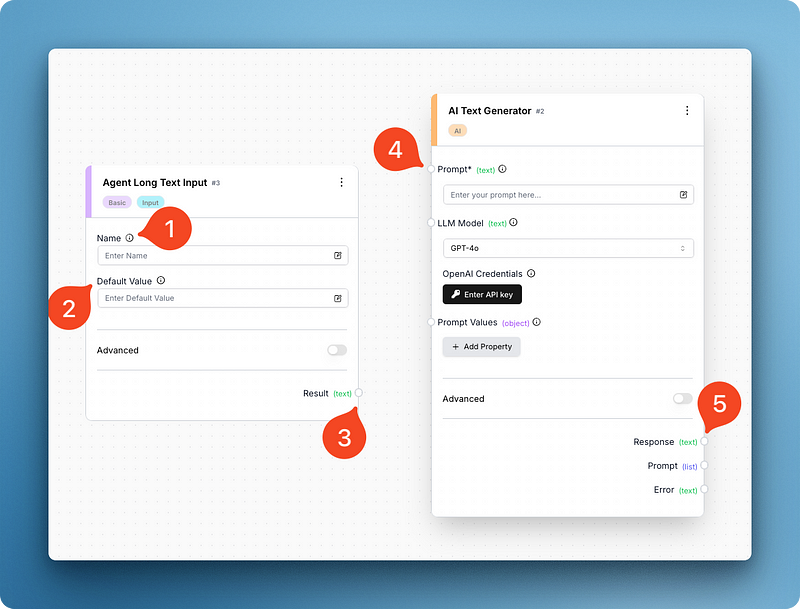
Wenn du dir das Bild ansiehst, kannst du sehen, dass jeder Block verschiedene bewegliche Teile hat. Der Eingabeblock hat Felder für den Blocknamen und einen Standardwert, während der Textgenerator ein Feld für den Prompt, das Modell und die Prompt-Variablen hat.
Letzteres hat auch ein einmaliges Eingabefeld für deinen OpenAI-API-Schlüssel, den du angeben musst, bevor du den Agenten startest (tu es jetzt). Das API-Schlüsselfeld ändert sich je nach gewähltem Modell und AutoGPT unterstützt die meisten großen und kleinen Anbieter.
Wie du siehst, haben beide Blöcke kleine Kanten (siehe 3 und 5), mit denen du sie verbinden kannst:
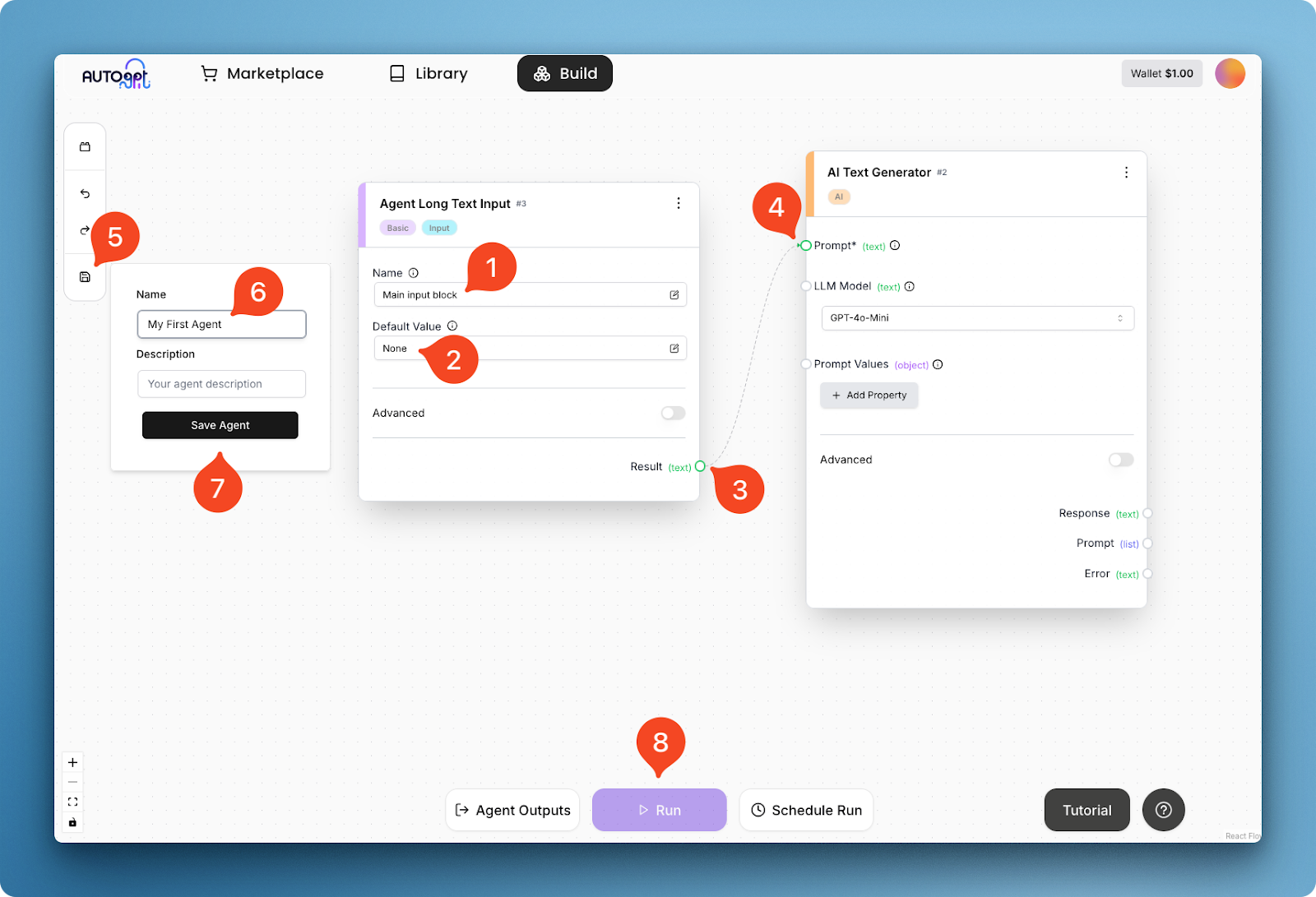
In der Abbildung oben gebe ich dem Eingabeblock einen Namen (1) und einen Standardwert (2) und verbinde sein Textergebnis (3) mit dem Eingabefeld (4) des Textgenerators. Durch diese Verbindung wird ein grundlegender Agenten-Workflow erstellt, der nach dem Speichern des Agenten selbst ausgeführt werden kann (Schritte 5-8).
Nachdem du auf "Ausführen" geklickt hast, erscheint ein Pop-up-Menü "Ausführungseinstellungen" für das Eingabefeld:
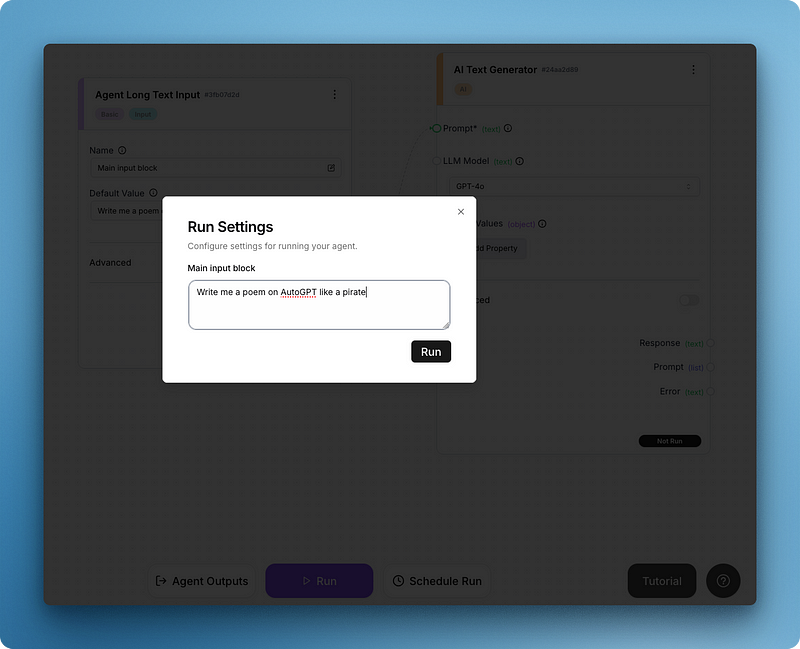
Schreibe deine Eingabeaufforderung und führe das Ganze aus, um die erste Ausgabe wie unten zu erhalten:
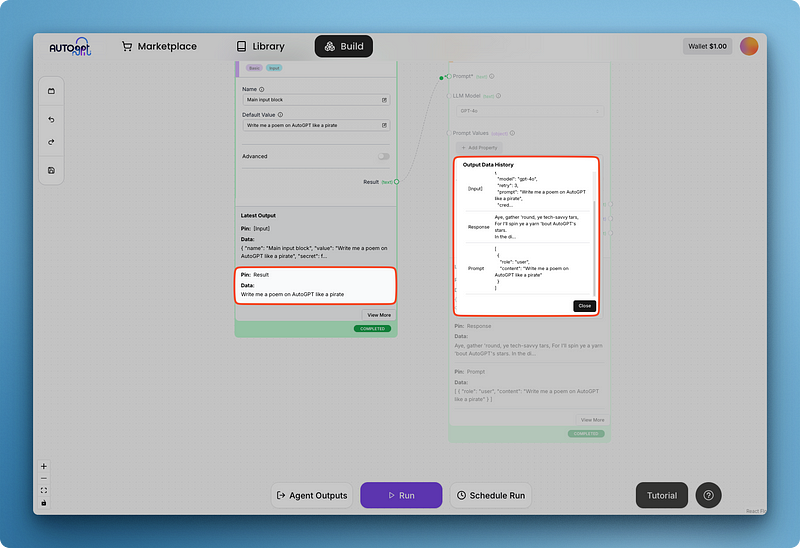
Du wirst feststellen, dass die Modellantwort in dem größeren Textgenerierungsblock schwer zu lesen ist. Deshalb hat AutoGPT Blöcke für Agentenausgaben, die ich unten hinzufüge:
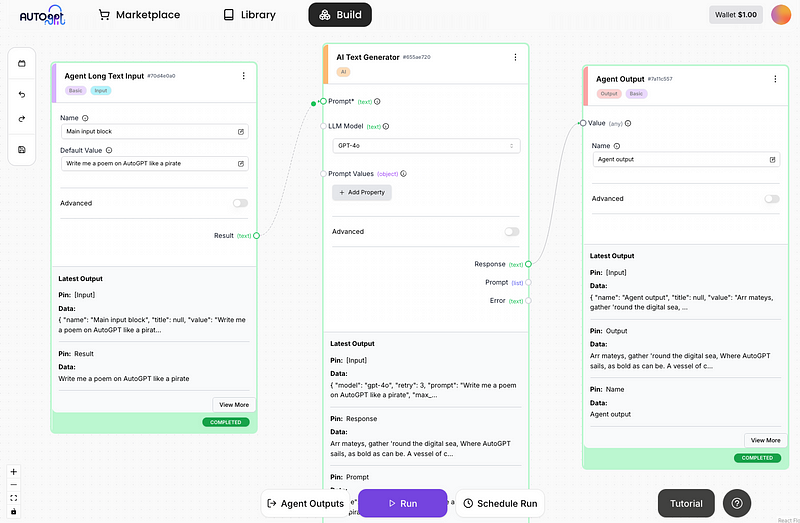
Beachte, wie ich das Antwortfeld des Textgenerators mit dem Wert des Agentenausgabeblocks verbunden habe. Wenn du einen Ausgabeblock hinzufügst, kannst du auch alle Agentenausgaben von verschiedenen Blöcken im Bereich "Agentenausgaben" an einem Ort anzeigen:
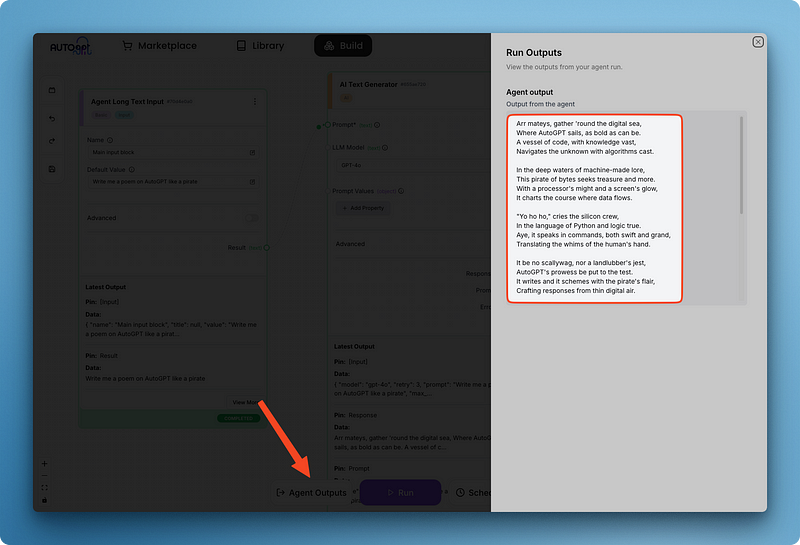
Sobald du deinen Agenten gespeichert hast, wird er in deiner Bibliothek abgelegt. Außerdem kann dieser gesamte Agent dann als Block in anderen Agenten, die du erstellst, verwendet werden. Dieser modulare Ansatz bietet mehrere Vorteile:
Dieser Baustein-Ansatz ermöglicht es dir, immer leistungsfähigere KI-Systeme zu erstellen, indem du Fähigkeiten übereinander legst.
Die Stärke von AutoGPT liegt in seinem modularen Blocksystem. Die Plattform enthält zwar viele nützliche integrierte Blöcke, aber du kannst ihre Möglichkeiten erweitern, indem du deine eigenen Blöcke in Python erstellst. Diese Funktion ermöglicht dir die Integration mit jeder API, jedem Dienst oder jedem Tool, auf das du programmatisch zugreifen kannst.
Das Erstellen eines benutzerdefinierten Blocks umfasst die folgenden wichtigen Schritte:
autogpt_platform/backend/backend/blocks mit dem Namen snake_caseBlock erbtBlockSchema verwenden, um die Datenstruktur zu definieren__init__ mit einer eindeutigen ID und Testdatenrun, die die Kernlogik deines Blocks enthält.Schauen wir uns die einzelnen Komponenten im Detail an:
Jeder Block muss von der Basisklasse Block erben und seine Ein- und Ausgabeschemata definieren:
from backend.data.block import Block, BlockSchema, BlockOutput
class MyCustomBlock(Block):
class Input(BlockSchema):
# Define input fields with types
field1: str
field2: int
class Output(BlockSchema):
# Define output fields with types
result: str
error: str # Always include an error field
def __init__(self):
super().__init__(
id="xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", # Generate proper UUID
input_schema=MyCustomBlock.Input,
output_schema=MyCustomBlock.Output,
test_input={"field1": "test", "field2": 42},
test_output=("result", "expected output"),
test_mock=None # Only needed for external API calls
)
def run(self, input_data: Input, **kwargs) -> BlockOutput:
try:
# Your block logic here
result = f"Processed {input_data.field1} and {input_data.field2}"
yield "result", result
except Exception as e:
raise RuntimeError(f"Error in block: {str(e)}")yield, um die Ergebnisse nacheinander auszugeben.Lass uns ein detailliertes Beispiel für einen benutzerdefinierten Block erstellen, der mit der OpenAI API eine Stimmungsanalyse durchführt. Hier wird gezeigt, wie man mit externen KI-Diensten integriert und API-Schlüssel sicher handhabt.
Bevor du diesen Block verwendest, musst du deinen OpenAI-API-Schlüssel einrichten:
1. Installiere die benötigten Pakete:
pip install openai python-dotenv2. Erstelle eine .env Datei im autogpt_platform/backend/blocks Verzeichnis mit deinem OpenAI API Schlüssel:
OPENAI_API_KEY=your_api_key_hereJetzt lass uns den Block erstellen:
Zuerst kümmern wir uns um den Import und die Einrichtung der Umgebung:
# autogpt_platform/backend/blocks/sentiment_analyzer.py
from backend.data.block import Block, BlockSchema, BlockOutput
from typing import Dict, Any, List
import os
from dotenv import load_dotenv
from openai import OpenAI
import json
# Load environment variables from .env file
load_dotenv()Dieser Abschnitt importiert die notwendigen Bibliotheken und lädt die Umgebungsvariablen aus der Datei .env. Die Funktion load_dotenv() stellt sicher, dass dein API-Schlüssel über os.getenv() verfügbar ist.
Als Nächstes definieren wir die Blockklasse mit Eingangs- und Ausgangsschemata:
class OpenAISentimentBlock(Block):
"""Block to analyze sentiment of text using OpenAI API"""
class Input(BlockSchema):
text: str # Text to analyze
model: str = "gpt-3.5-turbo" # OpenAI model to use
detailed_analysis: bool = False # Whether to return detailed analysis
class Output(BlockSchema):
sentiment: str # Positive, Negative, or Neutral
confidence: float # Confidence score of the prediction
explanation: str # Brief explanation of the sentiment
detailed_analysis: Dict[str, Any] # Optional detailed analysis
error: str # Error message if analysis failsDas Eingabeschema definiert drei Parameter:
text: Der zu analysierende Inhalt (erforderlich)model: Das zu verwendende OpenAI-Modell (Standardwert ist "gpt-3.5-turbo")detailed_analysis: Ob zusätzliche Details zurückgegeben werden sollen (Standardwert: False)Das Ausgabeschema definiert die Struktur der Ergebnisse, einschließlich der Stimmungskategorie, des Konfidenzwerts, der Erklärung und der optionalen detaillierten Analyse.
Die Methode __init__ richtet den Block mit Testdaten ein und initialisiert den OpenAI-Client:
def __init__(self):
super().__init__(
id="8f67d394-9f52-4352-a78b-175d5d1d7182", # Generated UUID
input_schema=OpenAISentimentBlock.Input,
output_schema=OpenAISentimentBlock.Output,
test_input={
"text": "I really enjoyed this product, it exceeded my expectations!",
"detailed_analysis": True
},
test_output=[
("sentiment", str),
("confidence", float),
("explanation", str),
("detailed_analysis", dict)
],
test_mock={
"_analyze_sentiment": lambda text, model, detailed: {
"sentiment": "positive",
"confidence": 0.92,
"explanation": "The text expresses clear enjoyment and states that expectations were exceeded.",
"detailed_analysis": {
"emotions": {
"joy": "high",
"satisfaction": "high",
"disappointment": "none"
},
"key_phrases": ["really enjoyed", "exceeded expectations"],
"tone": "enthusiastic"
}
}
}
)
# Initialize OpenAI client
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise RuntimeError("OpenAI API key not found. Please set OPENAI_API_KEY in .env file.")
self.client = OpenAI(api_key=api_key)Diese Methode:
Die Kernfunktionalität ist in der Methode _analyze_sentiment implementiert:
@staticmethod
def _analyze_sentiment(self, text: str, model: str, detailed: bool) -> Dict[str, Any]:
"""Analyze sentiment using OpenAI API"""
# Create prompt based on whether detailed analysis is requested
if detailed:
system_prompt = """
You are a sentiment analysis expert. Analyze the following text and provide:
1. The overall sentiment (positive, negative, or neutral)
2. A confidence score from 0.0 to 1.0
3. A brief explanation of your assessment
4. A detailed analysis including:
- Key emotions detected and their intensity
- Key phrases that influenced your assessment
- Overall tone of the text
Format your response as a JSON object with the following structure:
{
"sentiment": "positive|negative|neutral",
"confidence": 0.0-1.0,
"explanation": "brief explanation",
"detailed_analysis": {
"emotions": {"emotion1": "intensity", "emotion2": "intensity"},
"key_phrases": ["phrase1", "phrase2"],
"tone": "description of tone"
}
}
"""
else:
system_prompt = """
You are a sentiment analysis expert. Analyze the following text and provide:
1. The overall sentiment (positive, negative, or neutral)
2. A confidence score from 0.0 to 1.0
3. A brief explanation of your assessment
Format your response as a JSON object with the following structure:
{
"sentiment": "positive|negative|neutral",
"confidence": 0.0-1.0,
"explanation": "brief explanation"
}
"""
try:
# Make API call using the latest OpenAI API syntax
response = self.client.chat.completions.create(
model=model,
response_format={"type": "json_object"},
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": text}
],
temperature=0.2 # Low temperature for more consistent results
)
# Extract and parse JSON response
content = response.choices[0].message.content
result = json.loads(content)
return result
except Exception as e:
raise RuntimeError(f"OpenAI API error: {str(e)}")Diese Methode:
Schließlich verbindet die Methode run alles miteinander:
def run(self, input_data: Input, **kwargs) -> BlockOutput:
try:
# Validate input
if not input_data.text or not isinstance(input_data.text, str):
raise ValueError("Text must be a non-empty string")
# Process through OpenAI
results = self._analyze_sentiment(
input_data.text,
input_data.model,
input_data.detailed_analysis
)
# Yield the results
yield "sentiment", results["sentiment"]
yield "confidence", results["confidence"]
yield "explanation", results["explanation"]
# Only return detailed analysis if requested and available
if input_data.detailed_analysis and "detailed_analysis" in results:
yield "detailed_analysis", results["detailed_analysis"]
except ValueError as e:
raise RuntimeError(f"Input validation error: {str(e)}")
except Exception as e:
raise RuntimeError(f"Sentiment analysis failed: {str(e)}")Diese Methode:
dotenvDieser Block zeigt, wie du moderne KI-Dienste integrieren kannst, um die Fähigkeiten deiner Agenten zu verbessern. Die OpenAI-Integration ermöglicht eine anspruchsvolle Textanalyse, die mit einfachen regelbasierten Ansätzen nur schwer zu realisieren wäre.
Wenn du deine eigenen Blöcke schreibst, denke immer daran:
Ausführlichere Informationen zur Erstellung von benutzerdefinierten Blöcken, einschließlich Feldtypen, Authentifizierung, Webhook-Integration und Best Practices, findest du in der offiziellen AutoGPT Block-Dokumentation.
AutoGPT bietet eine leistungsstarke Plattform für die Erstellung und den Einsatz von autonomen KI-Agenten durch seine intuitive, blockbasierte Schnittstelle. Dieses Tutorial führt dich durch den gesamten Prozess, von der lokalen Installation und Konfiguration bis hin zum Verständnis der Benutzeroberfläche, der Erstellung grundlegender Agenten und der Erweiterung der Funktionalität durch eigene Blöcke.
Die modulare Architektur von AutoGPT ermöglicht es technischen Fachkräften, komplexe Arbeitsabläufe ohne umfangreiche Programmierkenntnisse zu automatisieren und gleichzeitig die Flexibilität zu haben, bei Bedarf eigene Funktionen hinzuzufügen.
Für diejenigen, die auf dieser Grundlage aufbauen und KI-Agenten weiter erforschen wollen, bietet die offizielle AutoGPT-Dokumentation eine umfassende Anleitung, während DataCamp ergänzende Ressourcen wie Understanding AI Agents und ChatGPT Fundamentals anbietet.
Der Kurs "Einführung in GPTs " kann dir helfen, dein Verständnis für große Sprachmodelle zu festigen, während "Building RAG Chatbots for Technical Documentation " eine weitere praktische Anwendung von KI-Agenten demonstriert. Wenn du weiter mit KI-Agenten experimentierst, solltest du dir auch neue Tools wie Mistral Agents API, Dify AI und Langflow anschauen.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
