Kurs
Überwachtes Lernen in R: Klassifikation
4 Std.
100.4K
Die Klassifizierung ist eine überwachte Methode des maschinellen Lernens, bei der das Modell versucht, die korrekte Kennzeichnung der eingegebenen Daten vorherzusagen. Bei der Klassifizierung wird das Modell anhand der Trainingsdaten vollständig trainiert und dann anhand von Testdaten ausgewertet, bevor es für die Vorhersage neuer, ungesehener Daten verwendet wird.
Zum Beispiel kann ein Algorithmus lernen, vorherzusagen, ob eine bestimmte E-Mail Spam oder Ham (kein Spam) ist, wie unten dargestellt.
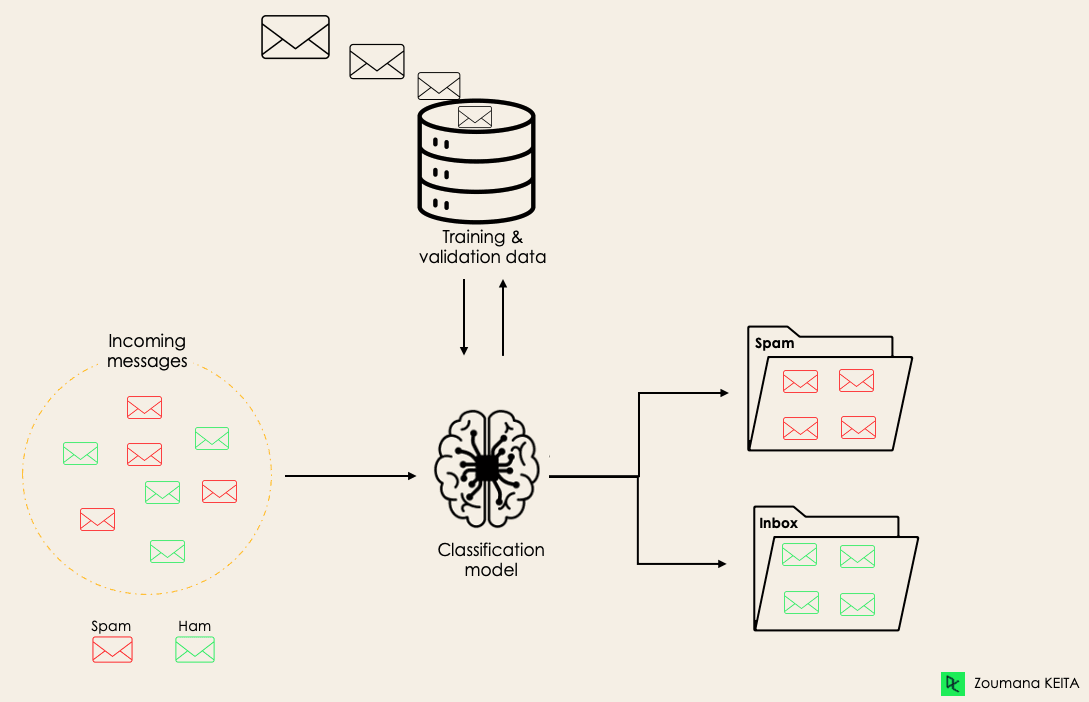 Bevor wir in das Klassifizierungskonzept eintauchen, wollen wir zunächst den Unterschied zwischen den beiden Arten von Lernenden bei der Klassifizierung verstehen: faule und eifrige Lernende. Dann werden wir das Missverständnis zwischen Klassifizierung und Regression klären.
Bevor wir in das Klassifizierungskonzept eintauchen, wollen wir zunächst den Unterschied zwischen den beiden Arten von Lernenden bei der Klassifizierung verstehen: faule und eifrige Lernende. Dann werden wir das Missverständnis zwischen Klassifizierung und Regression klären.
Bei der Klassifizierung durch maschinelles Lernen gibt es zwei Arten von Lernenden: faule und eifrige Lernende.
Eager Learners sind Algorithmen für maschinelles Lernen, die zunächst ein Modell aus dem Trainingsdatensatz erstellen, bevor sie Vorhersagen für zukünftige Datensätze treffen. Sie benötigen mehr Zeit während des Trainingsprozesses, weil sie darauf bedacht sind, durch das Lernen der Gewichte eine bessere Generalisierung zu erreichen, aber sie benötigen weniger Zeit für die Vorhersage.
Die meisten Algorithmen für maschinelles Lernen sind eifrige Lerner, und hier sind einige Beispiele:
Faule Lerner oder instanzbasierte Lerner hingegen erstellen kein Modell unmittelbar aus den Trainingsdaten, daher auch der Begriff "faul". Sie merken sich nur die Trainingsdaten und suchen jedes Mal, wenn sie eine Vorhersage treffen müssen, nach dem nächsten Nachbarn aus den gesamten Trainingsdaten, was sie bei der Vorhersage sehr langsam macht. Einige Beispiele dieser Art sind:
Einige Algorithmen, wie z.B. BallTrees und KDTrees, können jedoch verwendet werden, um die Vorhersage-Latenzzeit zu verbessern.
Es gibt vier Hauptkategorien von Algorithmen für maschinelles Lernen: überwachtes, unüberwachtes, halbüberwachtes und verstärkendes Lernen.
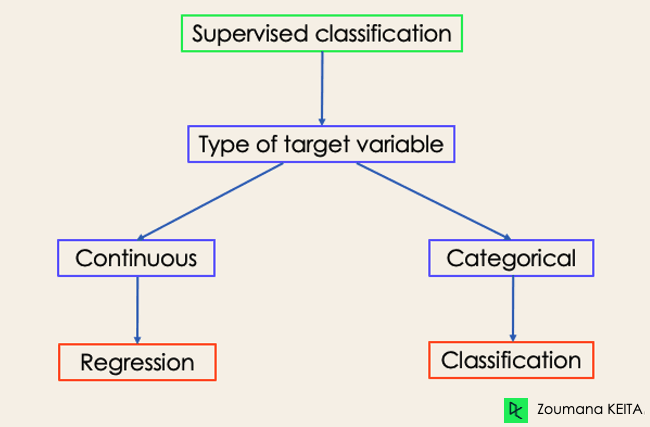
Auch wenn Klassifizierung und Regression beide zur Kategorie des überwachten Lernens gehören, sind sie nicht dasselbe.
Wenn du mehr über Klassifizierung wissen möchtest, könnten die Kurse Supervised Learning mit scikit-learn und Supervised Learning in R hilfreich sein. Sie vermitteln dir ein besseres Verständnis dafür, wie die einzelnen Algorithmen an ihre Aufgaben herangehen und welche Python- und R-Funktionen für ihre Umsetzung erforderlich sind.
Zum Thema Regression helfen dir Introduction to Regression in R und Introduction to Regression with statsmodels in Python dabei, verschiedene Arten von Regressionsmodellen und ihre Implementierung in R und Python kennenzulernen.
 für die Klassifizierung durch maschinelles Lernen im echten Leben
für die Klassifizierung durch maschinelles Lernen im echten Leben Überwachtes maschinelles Lernen Klassifizierung hat verschiedene Anwendungen in vielen Bereichen unseres täglichen Lebens. Im Folgenden findest du einige Beispiele.
Das Training eines maschinellen Lernmodells auf historischen Patientendaten kann Fachkräften im Gesundheitswesen helfen, ihre Diagnosen genau zu analysieren:
Der Bildungsbereich ist einer der Bereiche, in dem die meisten Text-, Video- und Audiodaten anfallen. Diese unstrukturierten Informationen können mit Hilfe von Technologien für natürliche Sprache analysiert werden, um verschiedene Aufgaben zu erfüllen, z. B:
Der Verkehr ist der Schlüssel für die wirtschaftliche Entwicklung vieler Länder. Infolgedessen setzen Branchen maschinelle und Deep-Learning-Modelle ein:
Die Landwirtschaft ist eine der wichtigsten Säulen des menschlichen Überlebens. Die Einführung der Nachhaltigkeit kann dazu beitragen, die Produktivität der Landwirte auf einer anderen Ebene zu verbessern, ohne die Umwelt zu schädigen:
Beim maschinellen Lernen gibt es vier Hauptklassifizierungsaufgaben: binäre, Mehrklassen-, Multi-Label- und unausgewogene Klassifizierungen.
Bei einer binären Klassifizierungsaufgabe besteht das Ziel darin, die Eingabedaten in zwei sich gegenseitig ausschließende Kategorien einzuordnen. Die Trainingsdaten werden in einer solchen Situation in einem binären Format gekennzeichnet: wahr und falsch; positiv und negativ; 0 und 1; Spam und nicht Spam usw., je nach dem zu lösenden Problem. Wir wollen zum Beispiel herausfinden, ob es sich bei einem bestimmten Bild um einen LKW oder ein Boot handelt.
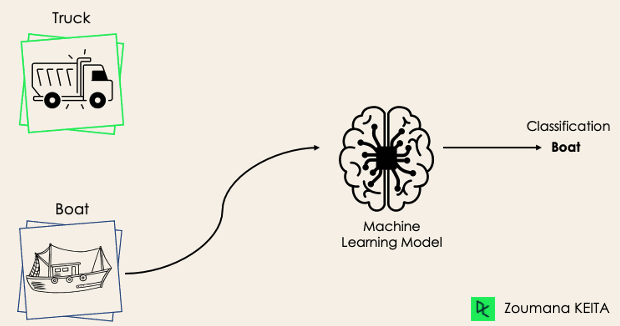
Die Algorithmen der logistischen Regression und der Support Vector Machines sind von Natur aus für binäre Klassifizierungen konzipiert. Es können aber auch andere Algorithmen wie K-Nächste Nachbarn und Entscheidungsbäume für die binäre Klassifizierung verwendet werden.
Bei der Mehrklassen-Klassifizierung hingegen gibt es mindestens zwei sich gegenseitig ausschließende Klassenlabels, wobei das Ziel darin besteht, vorherzusagen, zu welcher Klasse ein bestimmtes Eingabebeispiel gehört. Im folgenden Fall hat das Modell das Bild korrekt als Ebene klassifiziert.
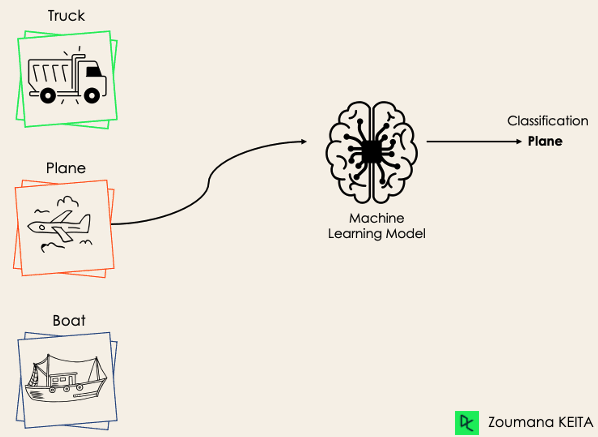
Die meisten binären Klassifizierungsalgorithmen können auch für die Klassifizierung mehrerer Klassen verwendet werden. Zu diesen Algorithmen gehören unter anderem:
Aber warte! Hast du nicht gesagt, dass SVM und Logistische Regression standardmäßig keine Mehrklassen-Klassifizierung unterstützen?
→ Das ist richtig. Wir können jedoch binäre Transformationsansätze wie Eins-gegen-Eins und Eins-gegen-Alle anwenden, um native binäre Klassifizierungsalgorithmen für Mehrklassen-Klassifizierungsaufgaben anzupassen.
Eins-gegen-eins: Bei dieser Strategie werden so viele Klassifikatoren trainiert, wie es Paare von Bezeichnungen gibt. Bei einer 3-Klassen-Klassifizierung haben wir drei Paare von Kennzeichnungen, also drei Klassifikatoren, wie unten dargestellt.
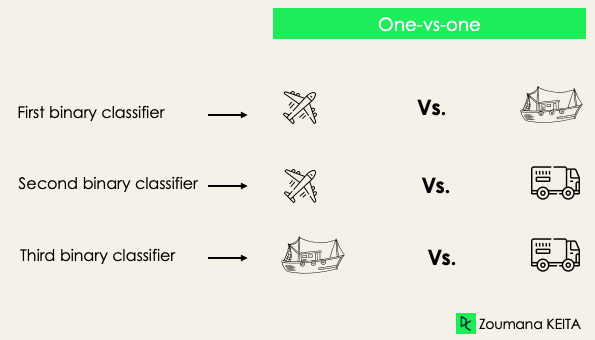
Im Allgemeinen haben wir für N Labels Nx(N-1)/2 Klassifikatoren. Jeder Klassifikator wird auf einem einzigen binären Datensatz trainiert, und die endgültige Klasse wird durch eine Mehrheitsabstimmung zwischen allen Klassifikatoren vorhergesagt. Der Eins-gegen-Eins-Ansatz funktioniert am besten für SVM und andere kernelbasierte Algorithmen.
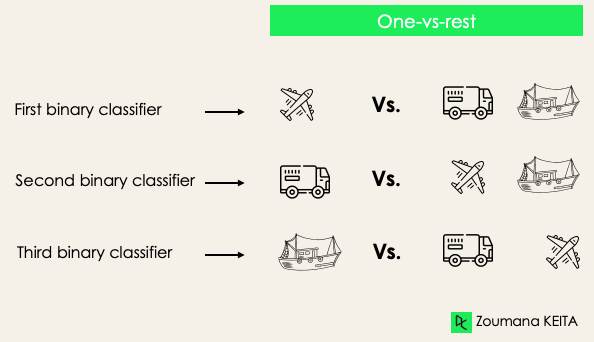
Eins gegen den Rest: In dieser Phase betrachten wir zunächst jedes Label als unabhängiges Label und betrachten den Rest zusammen als ein einziges Label. Bei 3-Klassen haben wir drei Klassifikatoren.
Im Allgemeinen haben wir für N Labels N binäre Klassifikatoren.
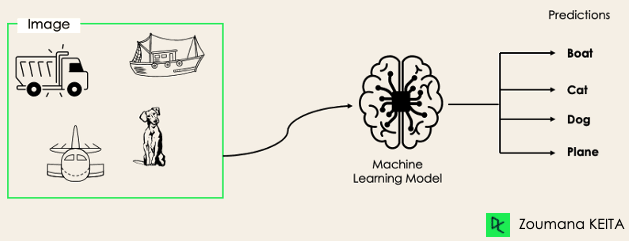
Bei Multi-Label-Klassifizierungsaufgaben versuchen wir, für jedes Eingabebeispiel 0 oder mehr Klassen vorherzusagen. In diesem Fall gibt es keinen gegenseitigen Ausschluss, weil das Eingabebeispiel mehr als ein Label haben kann.
Ein solches Szenario kann in verschiedenen Bereichen beobachtet werden, z. B. beim Auto-Tagging in der natürlichen Sprachverarbeitung, wo ein bestimmter Text mehrere Themen enthalten kann. Ähnlich wie beim Computersehen kann ein Bild mehrere Objekte enthalten, wie unten dargestellt: Das Modell sagte voraus, dass das Bild ein Flugzeug, ein Boot, einen LKW und einen Hund enthält.
Es ist nicht möglich, Mehrklassen- oder binäre Klassifizierungsmodelle zu verwenden, um eine Multi-Label-Klassifizierung durchzuführen. Die meisten Algorithmen, die für diese Standard-Klassifizierungsaufgaben verwendet werden, haben jedoch ihre speziellen Versionen für die Multi-Label-Klassifizierung. Wir können zitieren:
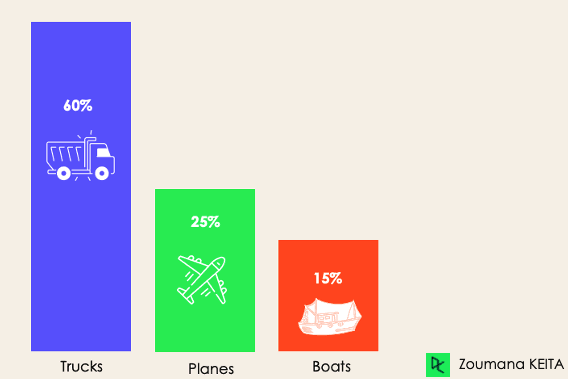
Bei der unausgewogenen Klassifizierung ist die Anzahl der Beispiele in jeder Klasse ungleich verteilt, d.h. wir können in den Trainingsdaten mehr von einer Klasse als von den anderen haben. Betrachten wir das folgende 3-Klassen-Klassifizierungsszenario, bei dem die Trainingsdaten Folgendes enthalten: 60% der Lastwagen, 25% der Flugzeuge und 15% der Boote.
Das Problem der unausgewogenen Klassifizierung könnte in folgendem Szenario auftreten:
Herkömmliche Vorhersagemodelle wie Entscheidungsbäume, logistische Regression usw. sind bei einem unausgewogenen Datensatz möglicherweise nicht effektiv, da sie dazu neigen, die Klasse mit der höchsten Anzahl von Beobachtungen vorherzusagen und die mit weniger Beobachtungen als Rauschen zu betrachten.
Heißt das also, dass solche Probleme hinter uns liegen?
Natürlich nicht! Wir können mehrere Ansätze verwenden, um das Problem des Ungleichgewichts in einem Datensatz zu lösen. Zu den am häufigsten verwendeten Ansätzen gehören Stichprobenverfahren oder die Nutzung der Leistungsfähigkeit kostensensitiver Algorithmen.
Diese Techniken zielen darauf ab, die Verteilung des Originals auszugleichen, indem:
Diese Algorithmen berücksichtigen die Kosten einer Fehlklassifizierung. Ihr Ziel ist es, die Gesamtkosten, die durch die Modelle entstehen, zu minimieren.
Nachdem wir nun eine Vorstellung von den verschiedenen Arten von Klassifizierungsmodellen haben, ist es entscheidend, die richtigen Bewertungsmaßstäbe für diese Modelle zu wählen. In diesem Abschnitt gehen wir auf die am häufigsten verwendeten Kennzahlen ein: Genauigkeit, Präzision, Wiedererkennung, F1-Score, Fläche unter der ROC-Kurve (Receiver Operating Characteristic) und AUC (Area Under the Curve).



Wir haben jetzt alle Werkzeuge in der Hand, um mit der Implementierung einiger Algorithmen fortzufahren. In diesem Abschnitt werden vier Algorithmen und ihre Implementierung für den Darlehensdatensatz vorgestellt, um einige der zuvor behandelten Konzepte zu veranschaulichen, insbesondere für die unausgewogenen Datensätze mit einer binären Klassifizierungsaufgabe. Der Einfachheit halber konzentrieren wir uns auf nur vier Algorithmen.
Das Ziel ist nicht, das bestmögliche Modell zu haben, sondern zu zeigen, wie man jeden der folgenden Algorithmen trainiert. Der Quellcode ist auf DataLab verfügbar, wo du alles mit einem Klick ausführen kannst.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()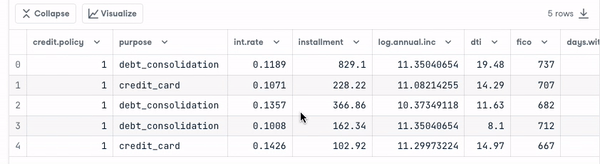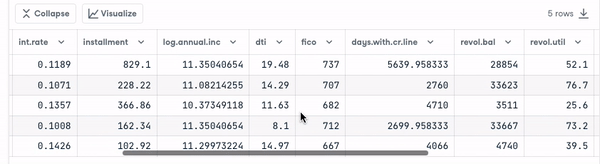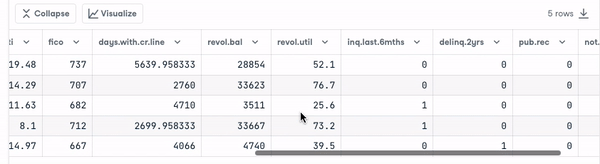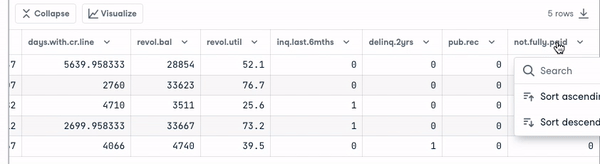
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)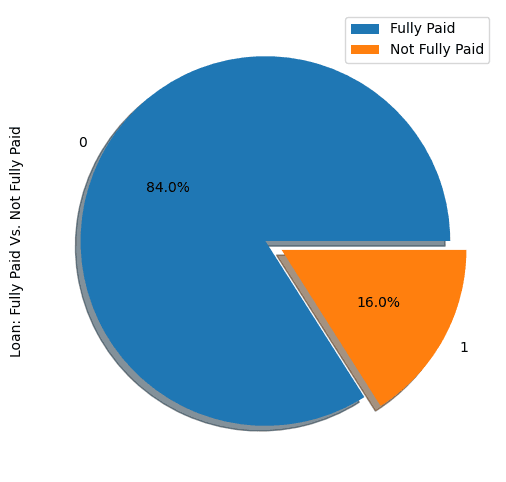
Aus der obigen Grafik geht hervor, dass 84% der Kreditnehmer ihre Kredite zurückzahlten und nur 16% sie nicht zurückzahlten, was den Datensatz sehr unausgewogen macht.
Bevor wir weitermachen, müssen wir den Typ der Variablen überprüfen, damit wir die Variablen kodieren können, die kodiert werden müssen.
Wir sehen, dass alle Spalten kontinuierliche Variablen sind, mit Ausnahme des Attributs " Zweck", das kodiert werden muss.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Wir werden hier zwei Stichprobenstrategien untersuchen: zufälliges Undersampling und SMOTE Oversampling.
Wir werden die Mehrheitsklasse, die den "Vollzahlern" (Klasse 0) entspricht, unterproben.
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)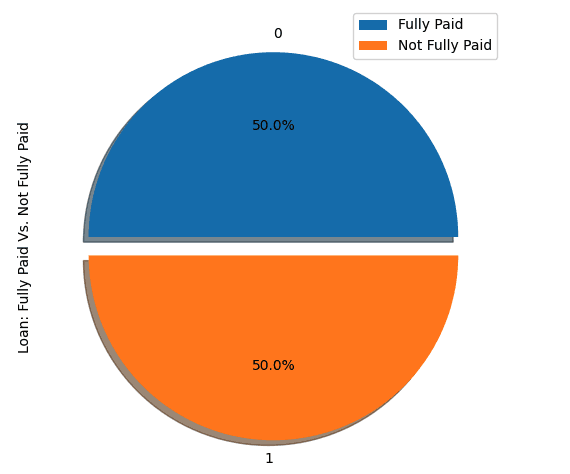
Oversampling in der Minderheitenklasse durchführen
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Nach Anwendung der Stichprobenstrategien stellen wir fest, dass der Datensatz gleichmäßig auf die verschiedenen Arten von Kreditnehmern verteilt ist.
In diesem Abschnitt werden wir diese beiden Klassifizierungsalgorithmen auf den SMOTE-Smote-Datensatz anwenden. Der gleiche Trainingsansatz kann auch auf unterabgetastete Daten angewendet werden.
Dies ist ein erklärbarer Algorithmus. Sie klassifiziert einen Datenpunkt, indem sie die Wahrscheinlichkeit der Zugehörigkeit zu einer bestimmten Klasse mithilfe der Sigmoid-Funktion modelliert.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))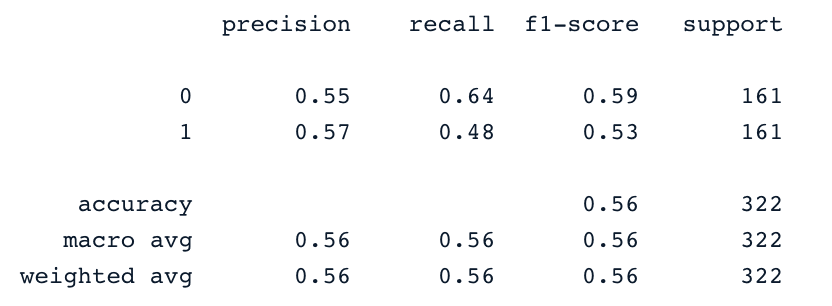
Dieser Algorithmus kann sowohl für die Klassifizierung als auch für die Regression verwendet werden. Es lernt, die Hyperebene (Entscheidungsgrenze) zu zeichnen, indem es das Prinzip der Margenmaximierung anwendet. Diese Entscheidungsgrenze wird durch die beiden nächstgelegenen Stützvektoren gezogen.
Die SVM bietet eine Transformationsstrategie, die sogenannten Kernel-Tricks, mit denen nicht trennbare Daten auf einen höherdimensionalen Raum projiziert werden, um sie linear trennbar zu machen.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))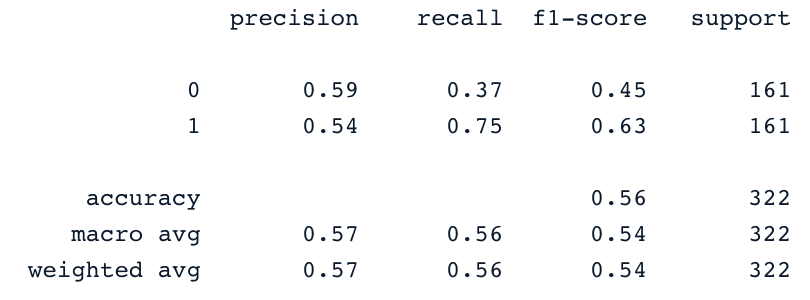
Diese Ergebnisse können natürlich noch verbessert werden, indem man die Merkmale weiter ausarbeitet und feiner abstimmt. Aber sie sind besser als die Verwendung der ursprünglichen unausgewogenen Daten.
Dieser Algorithmus ist eine Erweiterung eines bekannten Algorithmus namens Gradient-Boosted Trees. Sie ist nicht nur ein großartiger Kandidat für die Bekämpfung von Overfitting, sondern auch für Geschwindigkeit und Leistung.
Um es nicht länger zu machen, kannst du auch auf Machine Learning with Tree-Based Models in Python und Machine Learning with Tree-Based Models in R verweisen. In diesen Kursen lernst du, wie du mit Python und R baumbasierte Modelle implementieren kannst.
Mit der Weiterentwicklung des maschinellen Lernens sind neue Klassifizierungsalgorithmen und -techniken entstanden, die mehr Leistung, Skalierbarkeit und Interpretierbarkeit bieten. Hier werden wir einige der bemerkenswertesten Fortschritte untersuchen, die seit 2022 an Popularität gewonnen haben, darunter Transformatoren, Deep-Ensemble-Methoden und erklärbare KI-Techniken (XAI).
Transformatoren, die ursprünglich für Aufgaben der natürlichen Sprachverarbeitung wie Übersetzung und Texterstellung entwickelt wurden, sind in letzter Zeit für verschiedene Klassifizierungsaufgaben in unterschiedlichen Bereichen angepasst worden. Die wichtigste Innovation der Transformatoren ist die Verwendung von Selbstbeobachtungsmechanismen, die es den Modellen ermöglichen, die Bedeutung verschiedener Teile der Eingabedaten effektiv zu gewichten.
Transformatoren zeichnen sich durch die Verarbeitung großer, komplexer Datensätze aus und werden in vielen Branchen wie dem Gesundheitswesen, dem Finanzwesen und dem E-Commerce für Aufgaben wie Bilderkennung, Betrugserkennung und Empfehlungssysteme eingesetzt.
Deep-Ensemble-Methoden kombinieren die Vorhersagen mehrerer Modelle, um die Robustheit, Genauigkeit und Unsicherheitsabschätzung zu verbessern. Indem sie die Stärken verschiedener Modelle nutzen, können diese Methoden oft besser abschneiden als einzelne Modelle, vor allem bei komplexen Klassifizierungsaufgaben.
Da maschinelle Lernmodelle immer komplexer werden, ist der Bedarf an Interpretierbarkeit und Transparenz gestiegen. Erklärbare KI-Techniken (Explainable AI, XAI) wurden entwickelt, um den Entscheidungsprozess von Klassifizierungsmodellen für Menschen verständlicher zu machen, was für das Vertrauen in KI-Systeme von entscheidender Bedeutung ist, vor allem in Bereichen, in denen viel auf dem Spiel steht, wie im Gesundheits- und Finanzwesen.
Diese XAI-Techniken werden zunehmend in Klassifizierungsmodelle integriert, um nicht nur die Transparenz zu verbessern, sondern auch um regulatorische Anforderungen zu erfüllen, wie z. B. die Allgemeine Datenschutzverordnung (GDPR) in Europa, die Erklärungen für automatisierte Entscheidungen vorschreibt.
In diesem konzeptionellen Blog haben wir uns mit den wichtigsten Aspekten von Klassifizierungen beim maschinellen Lernen befasst und dir einige Beispiele für verschiedene Bereiche gegeben, in denen sie angewendet werden. Schließlich wurden die logistische Regression und die Support Vector Machine implementiert, nachdem die Strategien des undersampling und des SMOTE oversampling angewendet wurden, um einen ausgewogenen Datensatz für das Training der Modelle zu erzeugen.
Wir hoffen, es hat dir geholfen, das Thema Klassifizierung beim maschinellen Lernen besser zu verstehen. Du kannst dein Wissen im Kurs "Machine Learning Scientist with Python" vertiefen , der sowohl überwachtes als auch unüberwachtes und Deep Learning abdeckt. Es bietet auch eine gute Einführung in die Verarbeitung natürlicher Sprache, Bildverarbeitung, Spark und Keras.
Kurse zum maschinellen Lernen
Kurs
Kurs
Kurs
Blog
Tutorial
Derrick Mwiti
Tutorial
Allan Ouko
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
