Einführung
Pipelines, Deployment und MLOps sind sehr wichtige Konzepte für Datenwissenschaftler. Es reicht nicht aus, ein Modell in Notebook zu bauen. Der Einsatz von Pipelines und die Verwaltung von End-to-End-Prozessen mit MLOps-Best-Practices ist ein wachsender Schwerpunkt für viele Unternehmen. In diesem Tutorium werden verschiedene wichtige Konzepte wie Pipeline, CI/DI, API, Container, Docker und Kubernetes behandelt. Du wirst auch etwas über MLOps-Frameworks und -Bibliotheken in Python lernen. Schließlich zeigt das Tutorial die End-to-End-Implementierung einer Flask-basierten ML-Webanwendung in Containern und deren Bereitstellung in der Microsoft Azure Cloud.
Schlüsselkonzepte
MLOps
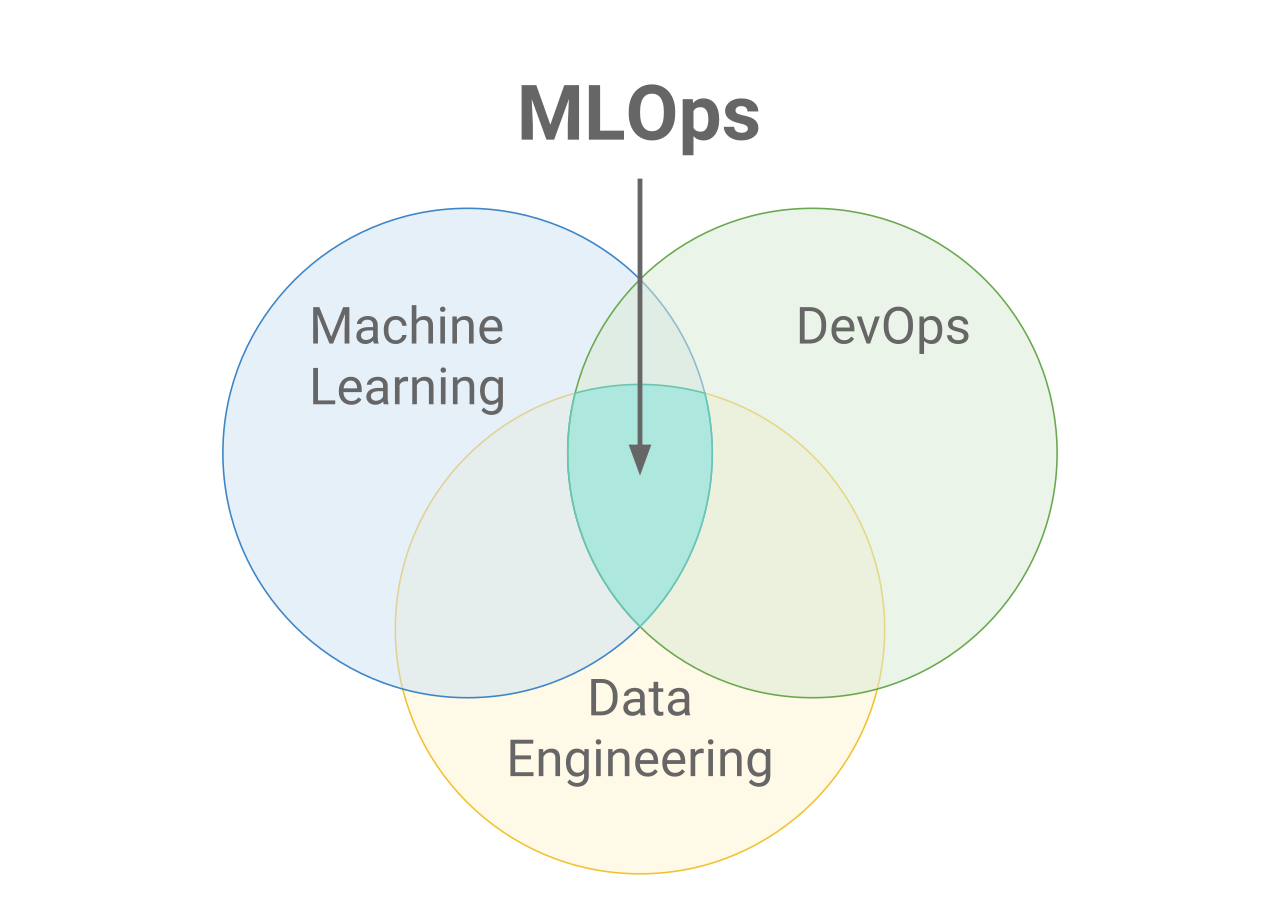
MLOps steht für Machine Learning Operations. MLOps konzentriert sich darauf, den Prozess des Einsatzes von Machine-Learning-Modellen in der Produktion zu rationalisieren und sie dann zu warten und zu überwachen. MLOps ist eine kollaborative Funktion, die oft aus Datenwissenschaftlern, ML-Ingenieuren und DevOps-Ingenieuren besteht. Das Wort MLOps setzt sich aus zwei verschiedenen Bereichen zusammen, nämlich dem maschinellen Lernen und DevOps aus der Softwaretechnik.
MLOps können alles umfassen, von der Datenpipeline bis zur Produktion von Machine Learning-Modellen. An manchen Stellen wird MLOps nur für die Bereitstellung des Machine-Learning-Modells implementiert, aber es gibt auch Unternehmen, die MLOps in vielen verschiedenen Bereichen der ML-Lebenszyklusentwicklung implementieren, z. B. bei der explorativen Datenanalyse (EDA), der Datenvorverarbeitung, dem Modelltraining usw.
Während MLOps als eine Reihe von Best Practices begann, entwickelt es sich langsam zu einem eigenständigen Ansatz für das ML Lifecycle Management. MLOps gilt für den gesamten Lebenszyklus - von der Integration in die Modellerstellung (Software Development Lifecycle und Continuous Integration/Continuous Delivery) über die Orchestrierung und Bereitstellung bis hin zu Status, Diagnose, Governance und Geschäftskennzahlen.
Warum MLOps?
Es gibt viele Ziele, die Unternehmen mit MLOps erreichen wollen. Einige der häufigsten sind:
- Automatisierung
- Skalierbarkeit
- Reproduzierbarkeit
- Monitoring
- Governance
MLOps vs. DevOps
DevOps ist ein iterativer Ansatz, um Softwareanwendungen in die Produktion zu überführen. MLOps macht sich dieselben Prinzipien zunutze, um Machine-Learning-Modelle in die Produktion zu bringen. Ob Devops oder MLOps, das Ziel ist letztendlich eine höhere Qualität und Kontrolle der Softwareanwendungen/ML-Modelle.
CI/CD: Continuous Integration, Continuous Delivery und Continuous Deployment.
CI/CD ist eine von DevOps abgeleitete Praxis und bezieht sich auf einen fortlaufenden Prozess, bei dem Probleme erkannt, neu bewertet und die Machine-Learning-Modelle automatisch aktualisiert werden. Die wichtigsten Konzepte, die CI/CD zugeschrieben werden, sind kontinuierliche Integration, kontinuierliche Lieferung und kontinuierliche Bereitstellung. Es automatisiert die Pipeline des maschinellen Lernens (Aufbau, Testen und Einsatz) und reduziert die Notwendigkeit für Data Scientists, manuell in den Prozess einzugreifen, was ihn effizient, schnell und weniger anfällig für menschliche Fehler macht.
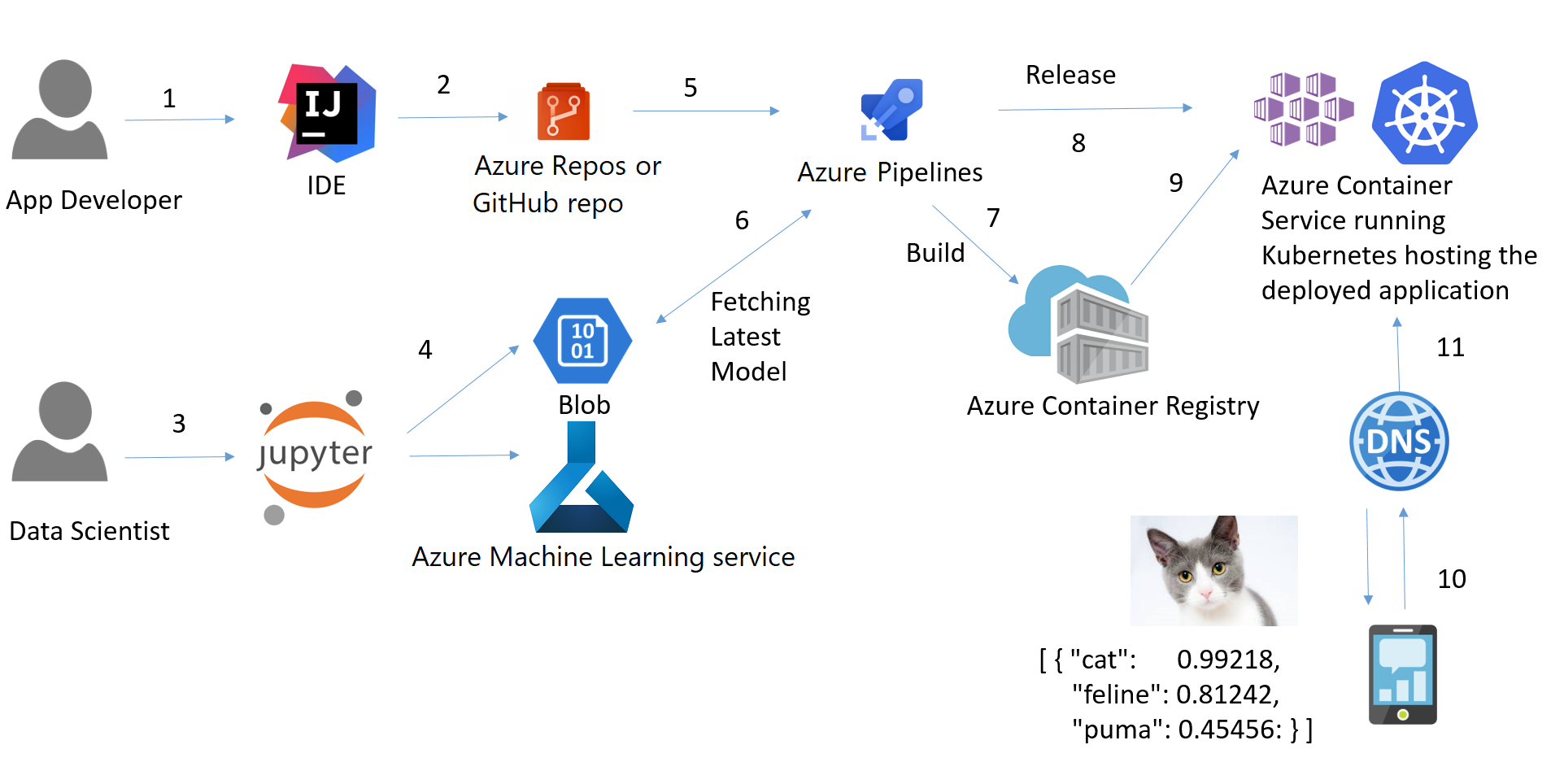
Pipeline
Eine Pipeline für maschinelles Lernen ist eine Möglichkeit, den Arbeitsablauf für die Erstellung eines maschinellen Lernmodells zu steuern und zu automatisieren. Pipelines für maschinelles Lernen bestehen aus mehreren aufeinanderfolgenden Schritten, die von der Datenextraktion und -vorverarbeitung bis zum Modelltraining und -einsatz reichen.
Pipelines für maschinelles Lernen sind iterativ, da jeder Schritt wiederholt wird, um die Genauigkeit des Modells kontinuierlich zu verbessern und das Endziel zu erreichen.
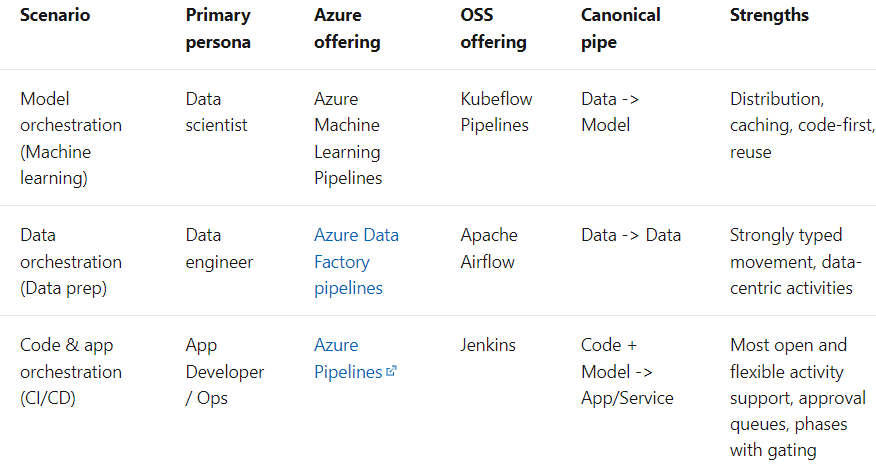
Der Begriff Pipeline wird allgemein verwendet, um die unabhängige Abfolge von Schritten zu beschreiben, die zusammen angeordnet werden, um eine Aufgabe zu erfüllen. Diese Aufgabe kann maschinelles Lernen sein oder auch nicht. Machine Learning Pipelines sind weit verbreitet, aber das ist nicht die einzige Art von Pipelines, die es gibt. Ein weiteres Beispiel sind Daten-Orchestrations-Pipelines. Laut den Microsoft-Dokumenten gibt es drei Szenarien:
Einsatz
Der Einsatz von Machine-Learning-Modellen (oder Pipelines) ist der Prozess der Bereitstellung von Modellen in der Produktion, bei dem Webanwendungen, Unternehmenssoftware (ERPs) und APIs das trainierte Modell durch die Bereitstellung neuer Datenpunkte konsumieren und die Vorhersagen erhalten können.
Kurz gesagt: Deployment in Machine Learning ist die Methode, mit der du ein maschinelles Lernmodell in eine bestehende Produktionsumgebung integrierst, um praktische Geschäftsentscheidungen auf der Grundlage von Daten zu treffen. Es ist die letzte Stufe im Lebenszyklus des maschinellen Lernens.
Normalerweise wird der Begriff Machine Learning Model Deployment verwendet, um die Bereitstellung der gesamten Machine Learning Pipeline zu beschreiben, wobei das Modell selbst nur eine Komponente der Pipeline ist.
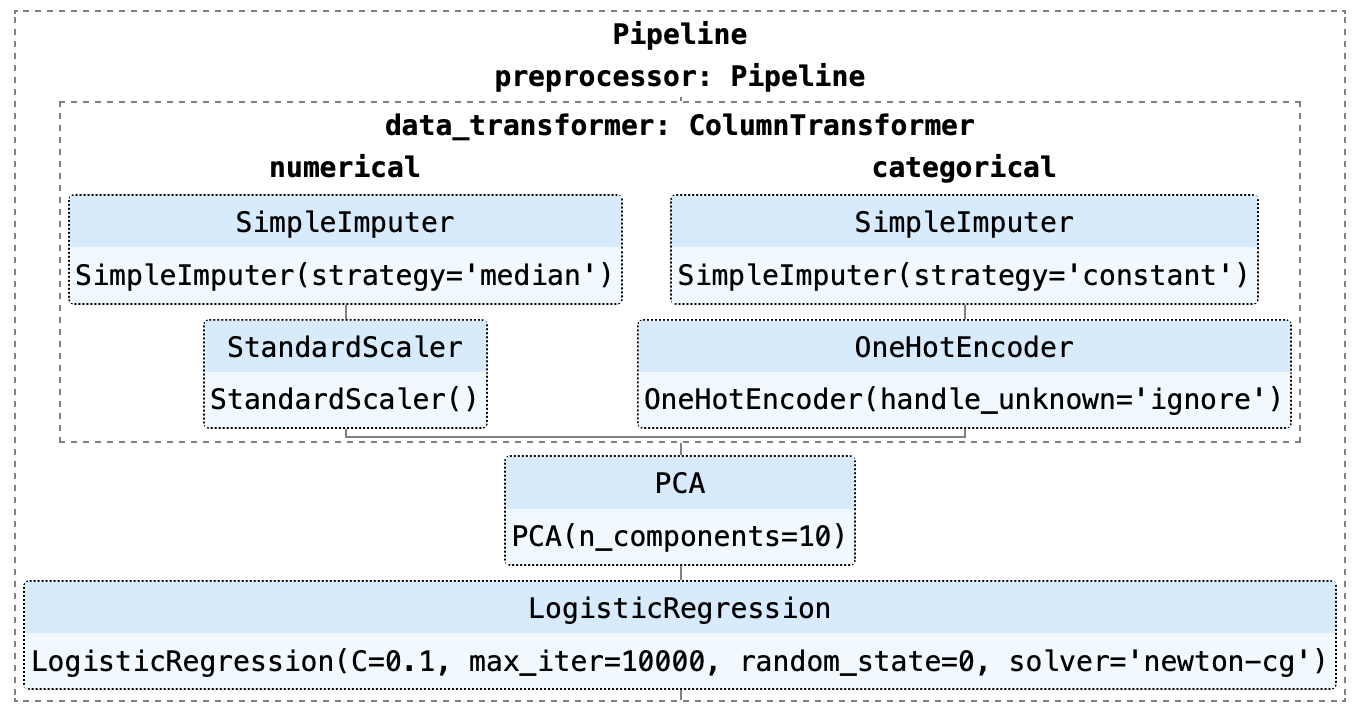
Wie du im obigen Beispiel sehen kannst, besteht diese Pipeline aus einem logistischen Regressionsmodell. Es gibt mehrere Schritte in der Pipeline, die zuerst ausgeführt werden müssen, bevor mit dem Training begonnen werden kann, z. B. die Imputation fehlender Werte, die One-Hot-Kodierung, die Skalierung und die Hauptkomponentenanalyse (PCA).
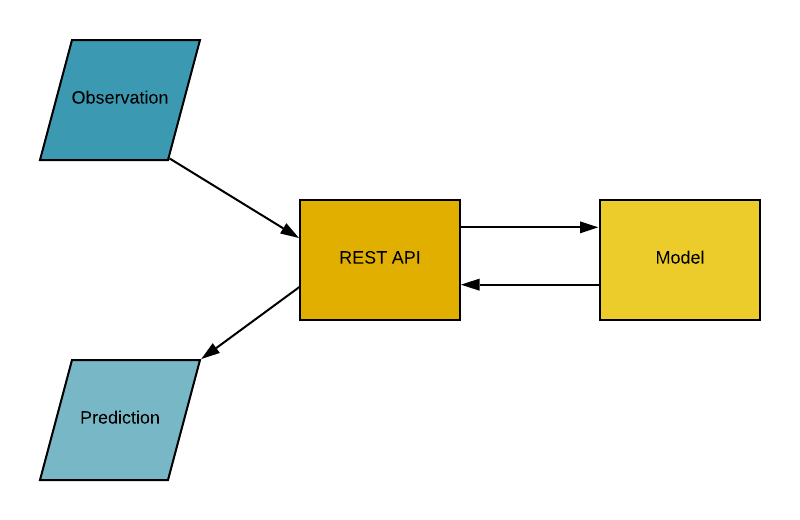
Anwendungsprogrammierschnittstelle (API)
Application Programming Interface (API), ist ein Software-Vermittler, der es zwei Anwendungen ermöglicht, miteinander zu kommunizieren. Einfach ausgedrückt ist eine API ein Vertrag zwischen zwei Anwendungen, der besagt, dass die API dem Nutzer das Ergebnis zur Verfügung stellt, wenn die Benutzersoftware Eingaben in einem vordefinierten Format macht. Mit anderen Worten: Die API ist ein Endpunkt, an dem du die trainierten Machine-Learning-Modelle / (Pipelines) zur Nutzung bereitstellst. In der Praxis sieht das ungefähr so aus:
Container
Hattest du schon mal das Problem, dass dein Python-Code (oder jeder andere Code) auf deinem Computer einwandfrei funktioniert, aber wenn dein Freund oder deine Freundin versucht, genau denselben Code auszuführen, funktioniert er nicht? Wenn dein Freund oder deine Freundin genau die gleichen Schritte wiederholt, sollte er oder sie auch die gleichen Ergebnisse erzielen, oder? Die einfache Antwort darauf ist, dass die Python-Umgebung deines Freundes eine andere ist als deine.
Was gehört zu einer Umgebung?
Python (oder eine andere Sprache, die du verwendet hast) und alle Bibliotheken und Abhängigkeiten, die zum Erstellen der Anwendung verwendet wurden.
Wenn es uns gelingt, eine Umgebung zu schaffen, die wir auf andere Rechner übertragen können (z. B. auf den Computer deines Freundes oder einen Cloud-Dienstleister wie Microsoft Azure, AWS oder GCP), können wir die Ergebnisse überall reproduzieren. Ein Container ist eine Art von Software, die eine Anwendung und alle ihre Abhängigkeiten zusammenfasst, damit die Anwendung zuverlässig in einer anderen Computerumgebung ausgeführt werden kann.
Der intuitivste Weg, Container in der Datenwissenschaft zu verstehen, ist, an Container auf einem Schiff zu denken. Das Ziel ist es, den Inhalt eines Behälters von den anderen zu trennen, damit sie nicht durcheinander kommen. Das ist genau das, wofür Container in der Datenwissenschaft verwendet werden.
Nachdem wir nun die Metapher hinter Containern verstanden haben, wollen wir uns die alternativen Möglichkeiten ansehen, eine isolierte Umgebung für unsere Anwendung zu schaffen. Eine einfache Alternative ist, dass du für jede deiner Anwendungen einen eigenen Rechner hast.
Die Verwendung eines separaten Rechners ist zwar einfach, wiegt aber die Vorteile der Verwendung von Containern nicht auf, denn mehrere Rechner für jede Anwendung zu unterhalten ist teuer, ein Alptraum und schwer zu skalieren. Kurz gesagt, es ist in vielen realen Szenarien nicht praktikabel.
Eine andere Möglichkeit, eine isolierte Umgebung zu schaffen, ist die Verwendung von virtuellen Maschinen. Auch hier sind Container vorzuziehen, da sie weniger Ressourcen benötigen, sehr portabel sind und schneller hochgefahren werden können.
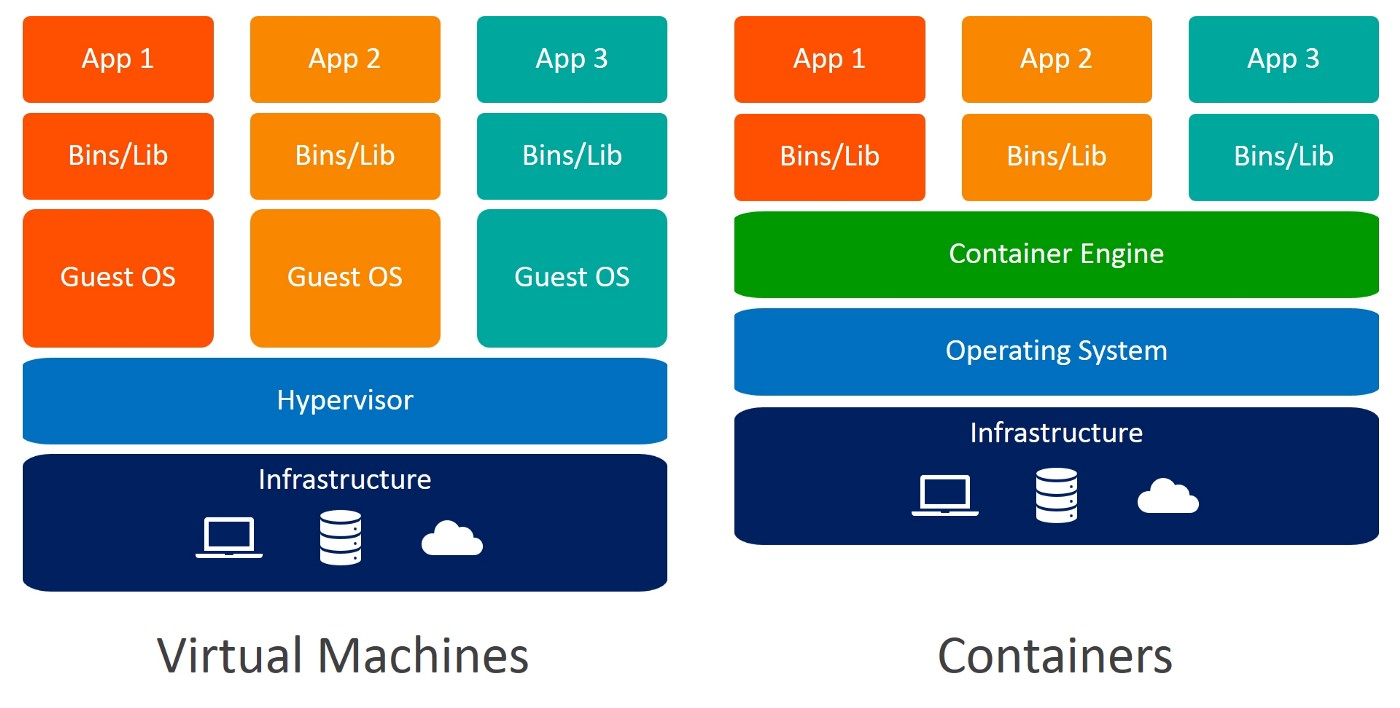
Kannst du die Unterschiede zwischen virtuellen Maschinen und Containern erkennen? Wenn du Container verwendest, brauchst du keine Gastbetriebssysteme. Stell dir vor, 10 Anwendungen laufen auf einer virtuellen Maschine. Dies würde 10 Gastbetriebssysteme erfordern, während du bei der Verwendung von Containern keines benötigst.
Docker
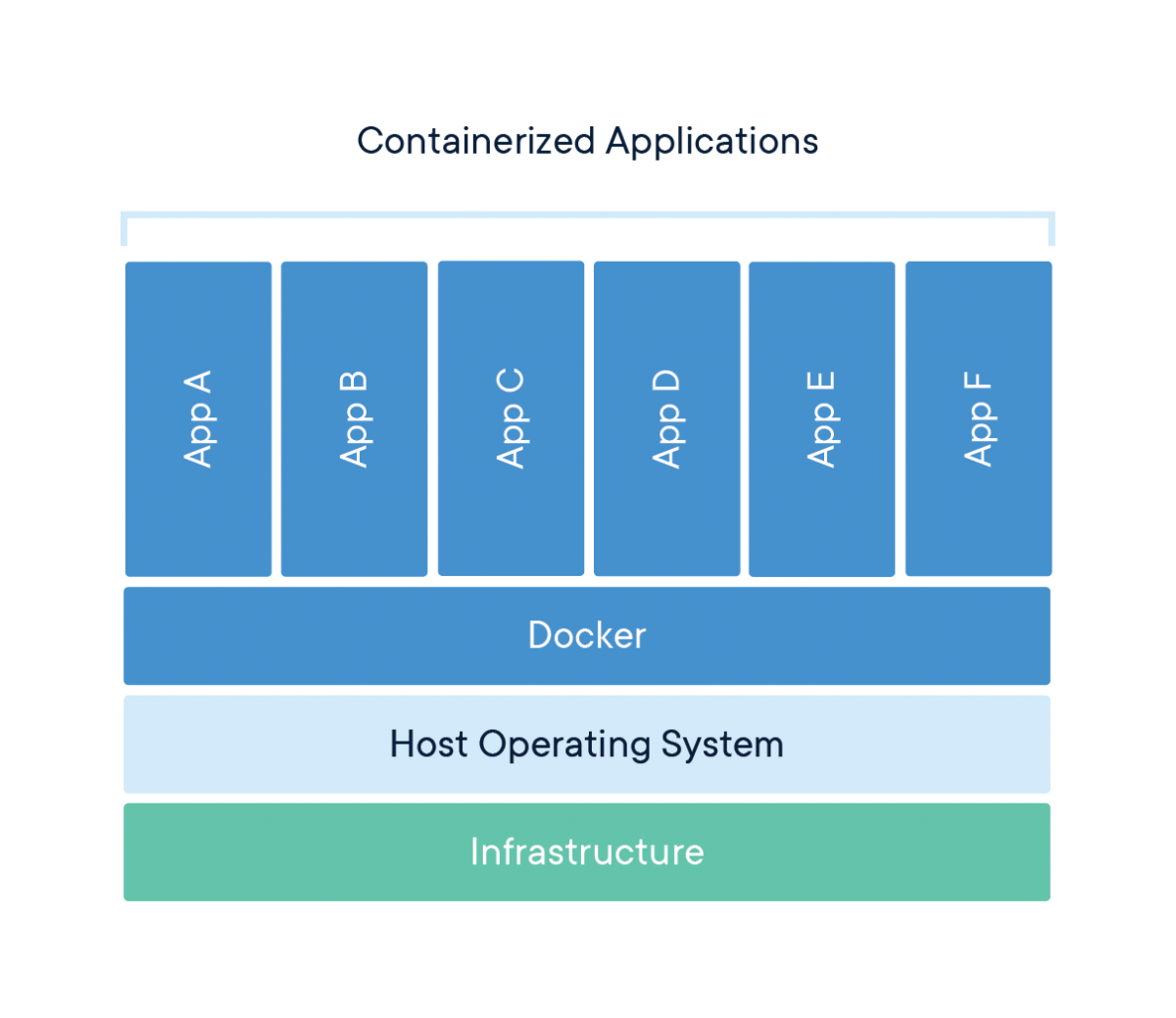
Docker ist ein Unternehmen, das Software (auch Docker genannt) anbietet, mit der Nutzer/innen Container bauen, ausführen und verwalten können. Während die Container von Docker am weitesten verbreitet sind, bieten auch andere, weniger bekannte Alternativen wie LXD und LXC Containerlösungen an.
Docker ist ein Tool, das die Erstellung, den Einsatz und die Ausführung von Anwendungen mit Hilfe von Containern erleichtert. Container werden verwendet, um eine Anwendung mit allen notwendigen Komponenten, wie Bibliotheken und anderen Abhängigkeiten, zu verpacken und als ein Paket auszuliefern.
Den Hype brechen
Letztendlich ist Docker nur eine Datei mit ein paar Zeilen Anweisungen, die unter dem Namen "Dockerfile" in deinem Projektordner gespeichert wird.
Eine andere Art, über Docker-Dateien nachzudenken, ist, dass sie wie Rezepte sind, die du in deiner eigenen Küche erfunden hast. Wenn du diese Rezepte an andere weitergibst und sie genau die gleichen Anweisungen befolgen, können sie das gleiche Gericht zubereiten. Ebenso kannst du deine Docker-Dateien mit anderen Personen teilen, die dann auf der Grundlage der jeweiligen Docker-Datei Images erstellen und Container ausführen können.
Kubernetes
Kubernetes wurde 2014 von Google entwickelt und ist ein leistungsfähiges Open-Source-System zur Verwaltung von Container-Anwendungen. Einfach ausgedrückt ist Kubernetes ein System zur Ausführung und Koordinierung von Container-Anwendungen in einem Cluster von Maschinen. Es ist eine Plattform, die den Lebenszyklus von containerisierten Anwendungen vollständig verwaltet.
Eigenschaften
- Load Balancing: Verteilt die Last automatisch auf die Container.
- Skalierung: Vergrößere oder verkleinere die Kapazität automatisch, indem du Container hinzufügst oder entfernst, wenn sich die Nachfrage ändert, z. B. zu Stoßzeiten, an Wochenenden und Feiertagen.
- Lagerung: Sorgt für eine einheitliche Speicherung bei mehreren Instanzen einer Anwendung.
Warum brauchst du Kubernetes, wenn du Docker hast?
Stell dir ein Szenario vor, in dem du mehrere Docker-Container auf mehreren Rechnern betreiben musst, um eine ML-Anwendung auf Unternehmensebene mit unterschiedlichen Arbeitslasten Tag und Nacht zu unterstützen. So einfach es auch klingen mag, es ist eine Menge Arbeit, das manuell zu tun.
Du musst die richtigen Container zur richtigen Zeit starten, herausfinden, wie sie miteinander kommunizieren können, Überlegungen zur Speicherung anstellen und mit ausgefallenen Containern oder Hardware umgehen. Genau dieses Problem löst Kubernetes, indem es einer großen Anzahl von Containern ermöglicht, harmonisch zusammenzuarbeiten und den operativen Aufwand zu reduzieren.
Google Kubernetes Engine ist eine Implementierung von Googles Open-Source-Kubernetes auf der Google Cloud Platform. Andere beliebte Alternativen zu GKE sind Amazon ECS und Microsoft Azure Kubernetes Service.
Kurze Zusammenfassung der Begriffe:
- Ein Container ist eine Art von Software, die eine Anwendung und alle ihre Abhängigkeiten verpackt, damit die Anwendung zuverlässig in einer anderen Computerumgebung läuft.
- Docker ist eine Software, mit der du Container bauen und verwalten kannst.
- Kubernetes ist ein Open-Source-System zur Verwaltung von containerisierten Anwendungen in einer Cluster-Umgebung.
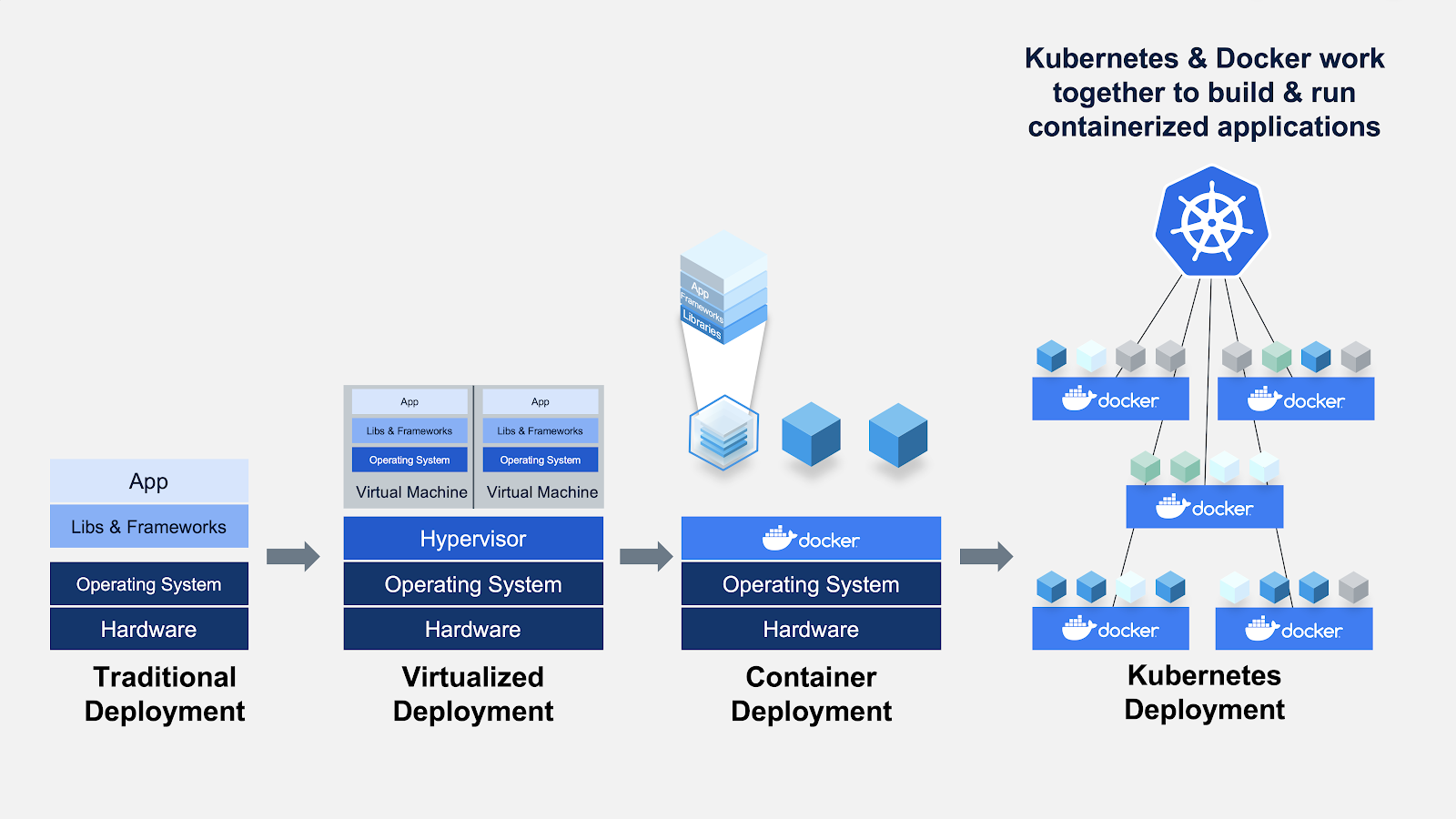
MLOps Frameworks und Bibliotheken in Python
MLflow
MLflow ist eine Open-Source-Plattform zur Verwaltung des ML-Lebenszyklus, einschließlich Experimenten, Reproduzierbarkeit, Einsatz und einer zentralen Modellregistrierung. MLflow bietet derzeit MLflow-Lernpfad, MLflow-Projekte, MLflow-Modelle und Modellregister.
Metaflow
Metaflow ist eine menschenfreundliche Python-Bibliothek, die Wissenschaftlern und Ingenieuren dabei hilft, reale Data-Science-Projekte zu erstellen und zu verwalten. Metaflow wurde ursprünglich bei Netflix entwickelt, um die Produktivität von Datenwissenschaftlern zu steigern, die an einer Vielzahl von Projekten arbeiten, von klassischer Statistik bis zu modernem Deep Learning. Metaflow bietet eine einheitliche API für den Infrastruktur-Stack, der für die Durchführung von Data Science-Projekten vom Prototyp bis zur Produktion erforderlich ist.
Kubeflow
Kubeflow ist eine Open-Source-Plattform für maschinelles Lernen, mit der maschinelle Lernpipelines komplizierte Workflows auf Kubernetes orchestrieren können. Kubeflow basierte auf Googles interner Methode zum Einsatz von TensorFlow-Modellen, genannt TensorFlow Extended.
Kedro
Kedro ist ein quelloffenes Python-Framework zur Erstellung von reproduzierbarem, wartbarem und modularem Data Science Code. Es lehnt sich an bewährte Konzepte aus der Softwareentwicklung an und wendet sie auf den Code für maschinelles Lernen an; zu den angewandten Konzepten gehören Modularität, Trennung von Belangen und Versionierung.
FastAPI
FastAPI ist ein Web-Framework für die Entwicklung von RESTful APIs in Python. FastAPI basiert auf Pydantic und Typ-Hinweisen, um Daten zu validieren, zu serialisieren und zu deserialisieren und automatisch OpenAPI-Dokumente zu generieren.
ZenML
ZenML ist ein erweiterbares, quelloffenes MLOps-Framework, mit dem du produktionsreife Pipelines für maschinelles Lernen erstellen kannst. Sie wurde für Data Scientists entwickelt und hat eine einfache, flexible Syntax, ist Cloud- und Tool-unabhängig und hat Schnittstellen/Abstraktionen, die auf ML-Workflows zugeschnitten sind.
Beispiel: End-to-End-Pipeline-Entwicklung, -Einsatz und MLOps
Problemstellung
Ein Versicherungsunternehmen möchte seine Cashflow-Prognosen verbessern, indem es die Kosten für die Patienten anhand von demografischen und grundlegenden Gesundheitsrisikokennzahlen zum Zeitpunkt des Krankenhausaufenthalts besser vorhersagt.
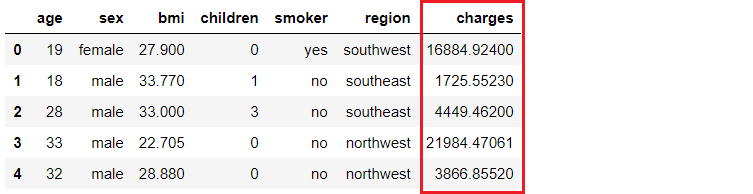
Unser Ziel ist es, eine Webanwendung zu entwickeln und einzusetzen, bei der die demografischen und gesundheitlichen Daten eines Patienten in ein webbasiertes Formular eingegeben werden, das dann einen voraussichtlichen Gebührenbetrag ausgibt. Um dies zu erreichen, werden wir Folgendes tun:
- Trainiere und entwickle eine Pipeline für maschinelles Lernen für den Einsatz (einfaches lineares Regressionsmodell).
- Baue eine Web-App mit dem Flask-Framework. Sie nutzt die trainierte ML-Pipeline, um Vorhersagen für neue Datenpunkte in Echtzeit zu erstellen (der Front-End-Code ist nicht der Schwerpunkt dieses Tutorials).
- Erstelle ein Docker-Image und einen Container.
- Veröffentliche den Container in der Azure Container Registry (ACR).
- Stelle die Web-App im Container bereit, indem du sie auf ACR veröffentlichst. Nach der Bereitstellung wird sie öffentlich zugänglich und kann über eine Web-URL aufgerufen werden.
Pipeline für maschinelles Lernen
Ich werde PyCaret in Python für das Training und die Entwicklung einer maschinellen Lernpipeline verwenden, die als Teil unserer Web-App eingesetzt wird. Du kannst jedes beliebige Framework verwenden, da die folgenden Schritte nicht davon abhängen.
# load dataset
from pycaret.datasets import get_data
insurance = get_data('insurance')
# init environment
from pycaret.regression import *
r1 = setup(insurance, target = 'charges', session_id = 123,
normalize = True,
polynomial_features = True, trigonometry_features = True,
feature_interaction=True,
bin_numeric_features= ['age', 'bmi'])
# train a model
lr = create_model('lr')
# save pipeline/model
save_model(lr, model_name = 'c:/username/pycaret-deployment-azure/deployment_28042020')
Wenn du ein Modell in PyCaret speicherst, wird die gesamte Transformationspipeline auf der Grundlage der in der Setup-Funktion festgelegten Konfiguration erstellt. Alle gegenseitigen Abhängigkeiten werden automatisch orchestriert. Siehe die Pipeline und das Modell, die in der Variable "deployment_28042020" gespeichert sind:

Front-End-Webanwendung
In diesem Lernprogramm geht es nicht darum, eine Flask-Anwendung zu erstellen. Sie wird hier nur der Vollständigkeit halber erwähnt. Jetzt, wo unsere Pipeline für maschinelles Lernen fertig ist, brauchen wir eine Webanwendung, die unsere trainierte Pipeline lesen kann, um neue Datenpunkte vorherzusagen. Dieser Antrag besteht aus zwei Teilen:
- Frontend (entworfen mit HTML)
- Back-End (entwickelt mit Flask)
So sieht das Frontend aus:
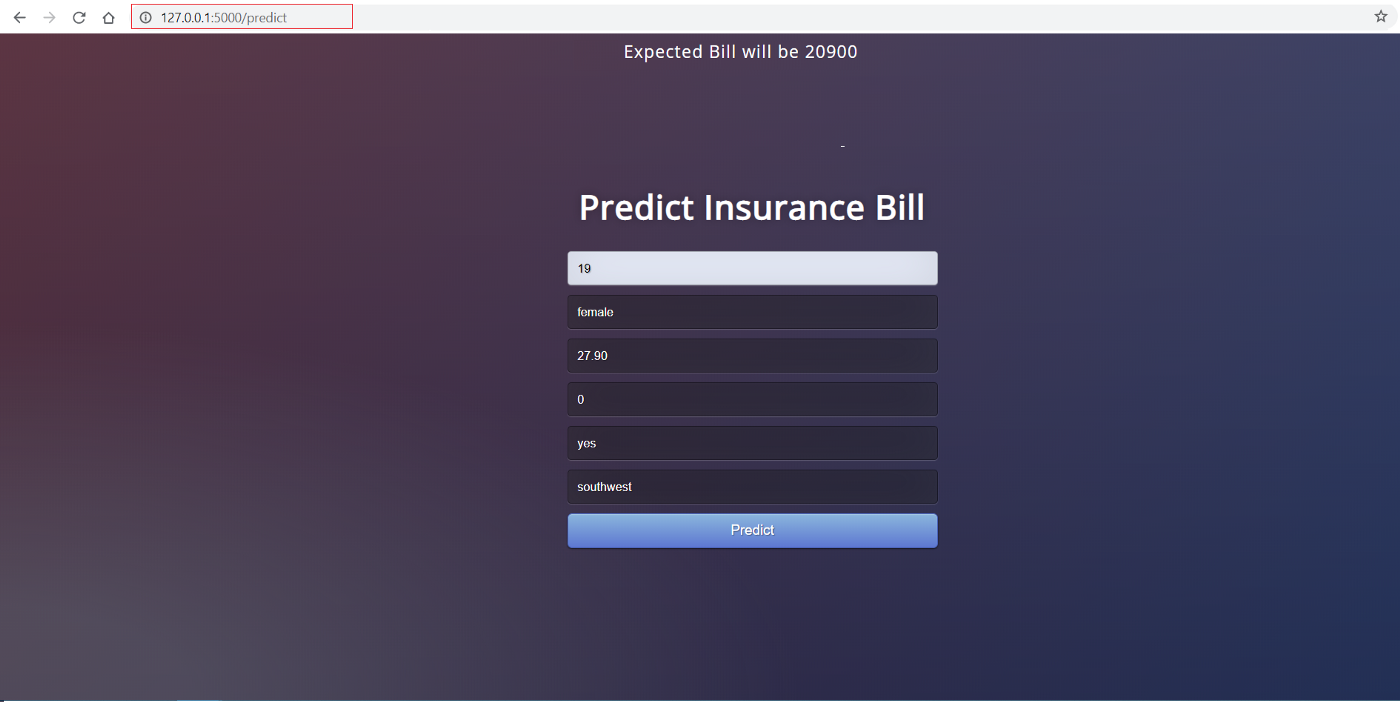
Das Frontend dieser Anwendung ist ganz einfaches HTML mit etwas CSS-Styling. Wenn du dir den Code ansehen möchtest, schau dir bitte dieses Repo an. Jetzt, wo wir eine voll funktionsfähige Webanwendung haben, können wir mit der Containerisierung der Anwendung mit Docker beginnen.
Back-End der Anwendung
Das Back-End der Anwendung ist eine Python-Datei namens app.py. Sie wurde mit dem Flask-Framework erstellt.
from flask import Flask,request, url_for, redirect, render_template, jsonify
from pycaret.regression import *
import pandas as pd
import pickle
import numpy as np
app = Flask(__name__)
model = load_model('deployment_28042020')
cols = ['age', 'sex', 'bmi', 'children', 'smoker', 'region']
@app.route('/')
def home():
return render_template("home.html")
@app.route('/predict',methods=['POST'])
def predict():
int_features = [x for x in request.form.values()]
final = np.array(int_features)
data_unseen = pd.DataFrame([final], columns = cols)
prediction = predict_model(model, data=data_unseen, round = 0)
prediction = int(prediction.Label[0])
return render_template('home.html',pred='Expected Bill will be {}'.format(prediction))
@app.route('/predict_api',methods=['POST'])
def predict_api():
data = request.get_json(force=True)
data_unseen = pd.DataFrame([data])
prediction = predict_model(model, data=data_unseen)
output = prediction.Label[0]
return jsonify(output)
if __name__ == '__main__':
app.run(debug=True)
Docker Container
Wenn du Windows verwendest, musst du Docker für Windows installieren. Wenn du Ubuntu verwendest, wird Docker standardmäßig mitgeliefert und muss nicht installiert werden.
Der erste Schritt bei der Containerisierung deiner Anwendung besteht darin, eine Dockerdatei in demselben Ordner/Verzeichnis zu erstellen, in dem sich deine Anwendung befindet. Ein Dockerfile ist einfach eine Datei mit einer Reihe von Anweisungen. Das Dockerfile für dieses Projekt sieht wie folgt aus:
FROM python:3.7
RUN pip install virtualenv
ENV VIRTUAL_ENV=/venv
RUN virtualenv venv -p python3
ENV PATH="VIRTUAL_ENV/bin:$PATH"
WORKDIR /app
ADD . /app
# install dependencies
RUN pip install -r requirements.txt
# expose port
EXPOSE 5000
# run application
CMD ["python", "app.py"]
Bei Dockerfile wird zwischen Groß- und Kleinschreibung unterschieden und es muss sich im Projektordner mit den anderen Projektdateien befinden. Ein Dockerfile hat keine Erweiterung und kann mit einem beliebigen Editor erstellt werden. Wir haben Visual Studio Code verwendet, um es zu erstellen.
Cloud-Bereitstellung
Nachdem wir das Dockerfile korrekt eingerichtet haben, werden wir einige Befehle schreiben, um ein Docker-Image aus dieser Datei zu erstellen, aber zuerst brauchen wir einen Dienst, der dieses Image hostet. In diesem Beispiel nutzen wir Microsoft Azure, um unsere Anwendung zu hosten.
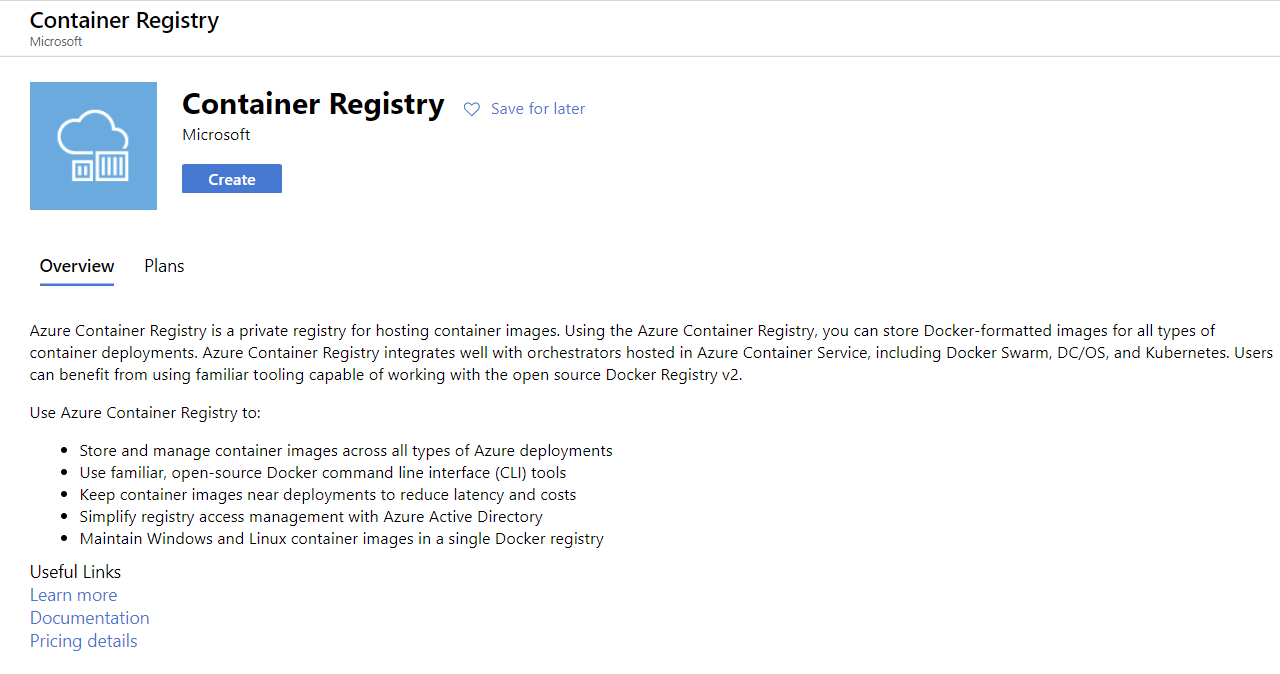
Azure Container Registry
Wenn du noch kein Microsoft Azure-Konto hast oder es noch nie genutzt hast, kannst du dich kostenlos anmelden. Wenn du dich zum ersten Mal anmeldest, bekommst du ein kostenloses Guthaben für die ersten 30 Tage. Du kannst dieses Guthaben nutzen, um eine Web-App auf Azure zu erstellen und einzusetzen. Sobald du dich angemeldet hast, folgst du diesen Schritten:
- Anmeldung auf https://portal.azure.com
- Klick auf Ressource erstellen
- Suche nach Container Registry und klicke auf Erstellen
- Wähle Abonnement, Ressourcengruppe und Registry-Name (in unserem Fall: pycaret.azurecr.io ist unser Registry-Name)
Sobald eine Registry erstellt ist, besteht der erste Schritt darin, ein Docker-Image über die Kommandozeile zu erstellen. Navigiere zum Projektordner und führe den folgenden Code aus:
docker build -t pycaret.azurecr.io/pycaret-insurance:latest .
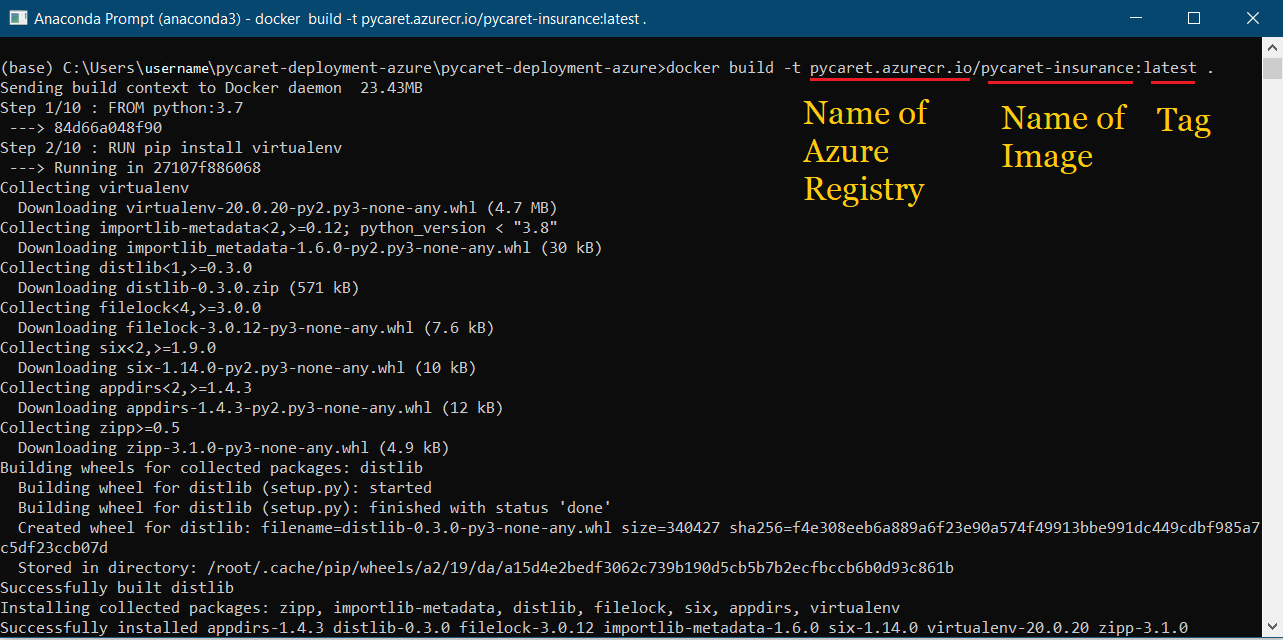
- pycaret.azurecr.io ist der Name der Registry, die du erhältst, wenn du eine Ressource im Azure-Portal erstellst.
- pycaret-insurance ist der Name des Bildes und das latest ist das Tag; das kann alles sein, was du willst
Container aus dem Docker-Image starten
Jetzt, wo das Image erstellt ist, werden wir einen Container lokal ausführen und die Anwendung testen, bevor wir sie in die Azure Container Registry übertragen. Um den Container lokal zu starten, führe den folgenden Code aus:
docker run -d -p 5000:5000 pycaret.azurecr.io/pycaret-insurance
Du kannst die App in Aktion sehen, indem du localhost:5000 in deinem Internetbrowser aufrufst. Es sollte sich eine Web-App öffnen.
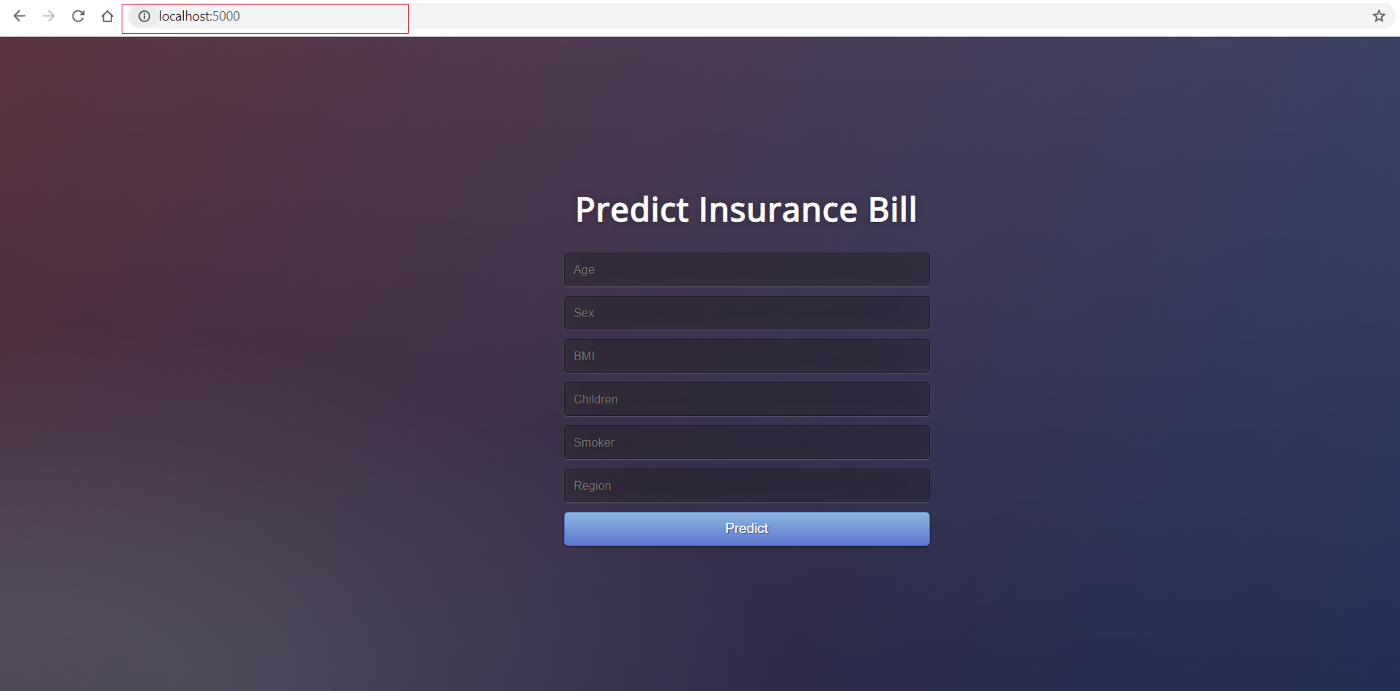
Wenn du das sehen kannst, bedeutet das, dass die Anwendung jetzt auf deinem lokalen Rechner läuft und du sie nur noch in die Cloud übertragen musst. Für den Einsatz auf Azure, lies weiter:
Azure-Anmeldeinformationen authentifizieren
Ein letzter Schritt, bevor du den Container auf ACR hochladen kannst, ist die Authentifizierung der Azure-Anmeldedaten auf deinem lokalen Rechner. Führe dazu den folgenden Code in der Befehlszeile aus:
docker login pycaret.azurecr.io
Du wirst aufgefordert, einen Benutzernamen und ein Passwort einzugeben. Der Benutzername ist der Name deiner Registry (in diesem Beispiel ist der Benutzername "pycaret"). Du findest dein Passwort unter den Zugangsschlüsseln der Azure Container Registry Ressource, die du erstellt hast.
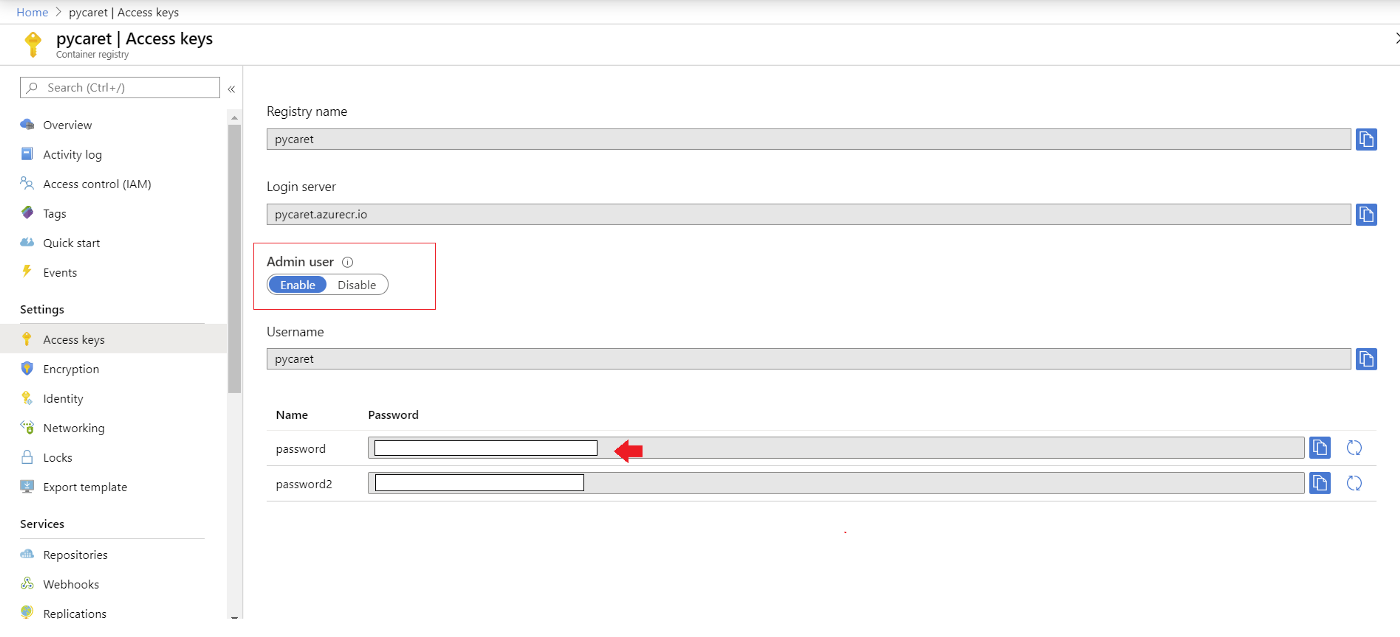
Container in die Azure Container Registry verschieben
Nachdem du dich bei ACR authentifiziert hast, kannst du den Container, den du erstellt hast, zu ACR pushen, indem du den folgenden Code ausführst:
docker push pycaret.azurecr.io/pycaret-insurance:latest
Je nach Größe des Containers kann der Push-Befehl einige Zeit brauchen, um den Container in die Cloud zu übertragen.
Webanwendung
Um eine Web-App auf Azure zu erstellen, befolge diese Schritte:
- Anmeldung im Azure-Portal
- Klick auf Ressource erstellen
- Suche nach der Web-App und klicke auf "Erstellen
- Verknüpfe dein ACR-Bild mit deiner Anwendung
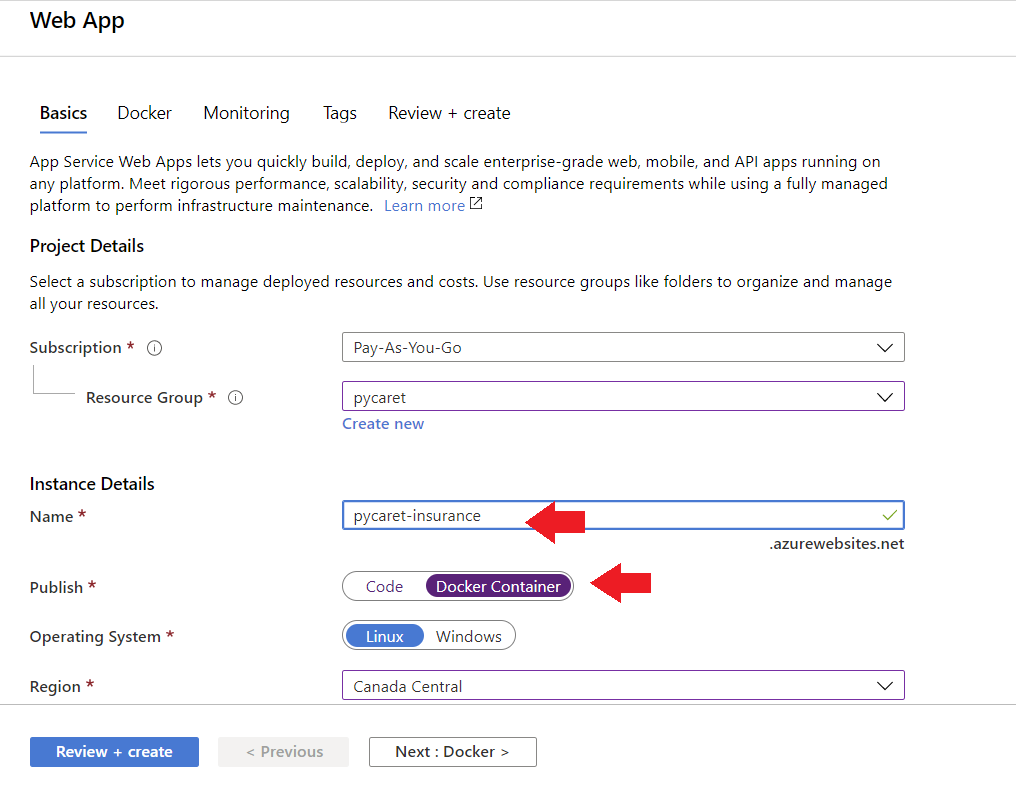
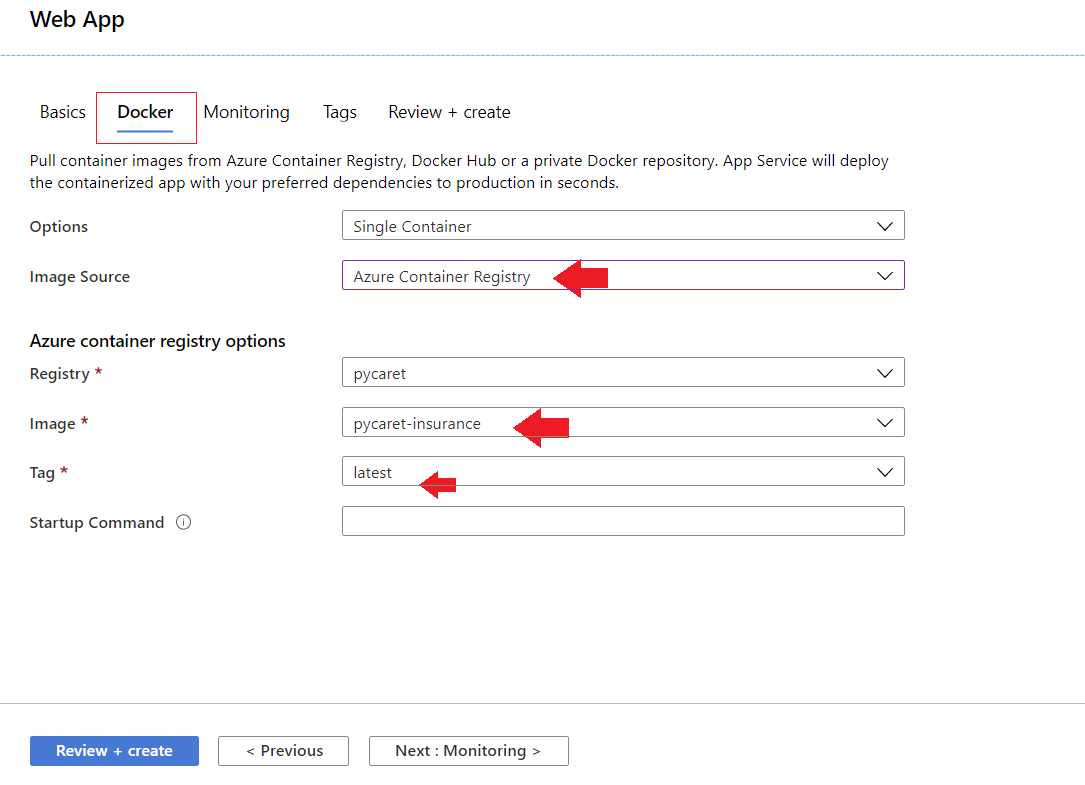
Die Anwendung ist jetzt auf Azure Web Services eingerichtet und läuft.

Fazit
MLOps stellen sicher, dass die eingesetzten Modelle gut gewartet werden, wie erwartet funktionieren und keine negativen Auswirkungen auf das Geschäft haben. Diese Rolle ist entscheidend, um das Unternehmen vor Risiken zu schützen, die durch Modelle entstehen, die sich im Laufe der Zeit verändern oder die zwar eingesetzt, aber nicht gewartet oder nicht überwacht werden.
MLOps führen das LinkedIn-Ranking der aufstrebenden Berufe mit einem Wachstum von 9,8 Mal in fünf Jahren an .
Auf dem DataCamp gibt es einen neuen Lernpfad für MLOps-Grundlagen, der den gesamten Lebenszyklus einer Machine-Learning-Anwendung abdeckt, von der Erfassung der Geschäftsanforderungen bis hin zu Design, Entwicklung, Einsatz, Betrieb und Wartung. Datacamp hat auch einen tollen Kurs "Understanding Data Engineering". Melde dich noch heute an und erfahre, wie Dateningenieure die Grundlagen für Data Science schaffen, ohne dass sie programmieren müssen.
