
Kurs
ChatGPT verstehen
1 Std.
424.4K
Wir können den Mistral 7B über HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart und Baseten erreichen.
Es gibt auch eine neue und bessere Möglichkeit, auf das Modell zuzugreifen, und zwar über die neue Funktion von Kaggle namens Modelle. Das bedeutet, dass du das Modell oder den Datensatz nicht herunterladen musst; du kannst innerhalb weniger Minuten mit der Inferenz oder der Feinabstimmung beginnen.
In diesem Abschnitt lernen wir, wie wir das Kaggle-Modell laden und die Inferenz in wenigen Minuten durchführen können.
Bevor wir beginnen, müssen wir die wichtigen Bibliotheken aktualisieren, um den KeyError: 'mistral Fehler zu vermeiden.
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesDanach erstellen wir eine 4-Bit-Quantisierung mit einer NF4-Konfiguration unter Verwendung von BitsAndBytes, um unser Modell mit 4-Bit-Präzision zu laden. Damit können wir das Modell schneller laden und den Speicherbedarf reduzieren, sodass es auf Google Colab oder Consumer-GPUs ausgeführt werden kann.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Jetzt lernen wir, wie wir das Modell Mistral 7B zu unserem Kaggle Notebook hinzufügen.
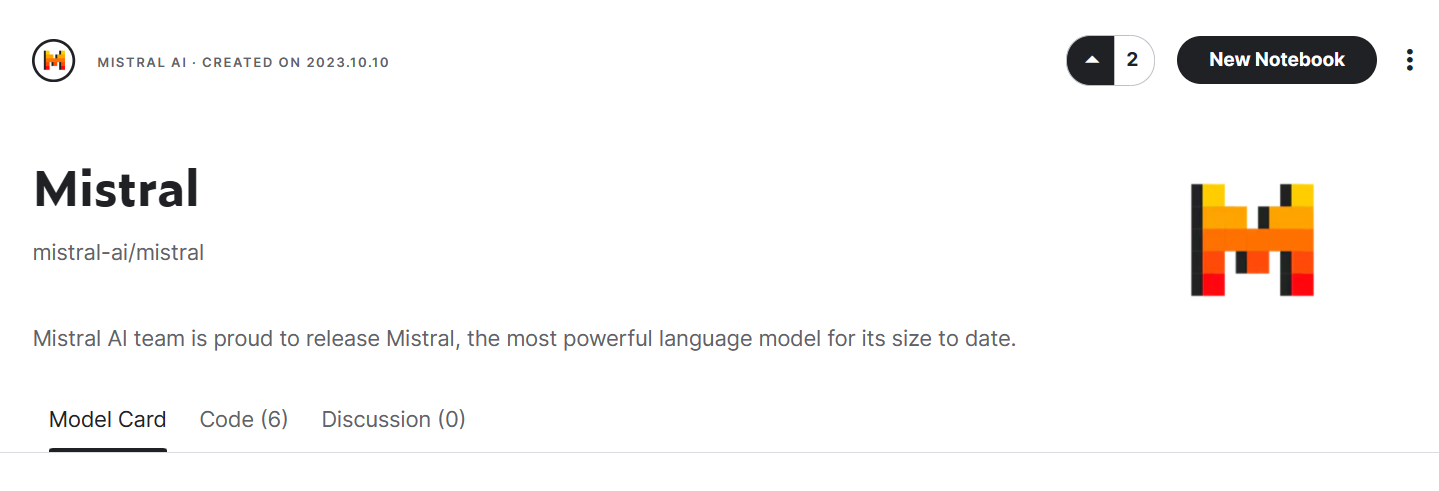
Bild von Mistral | Kaggle
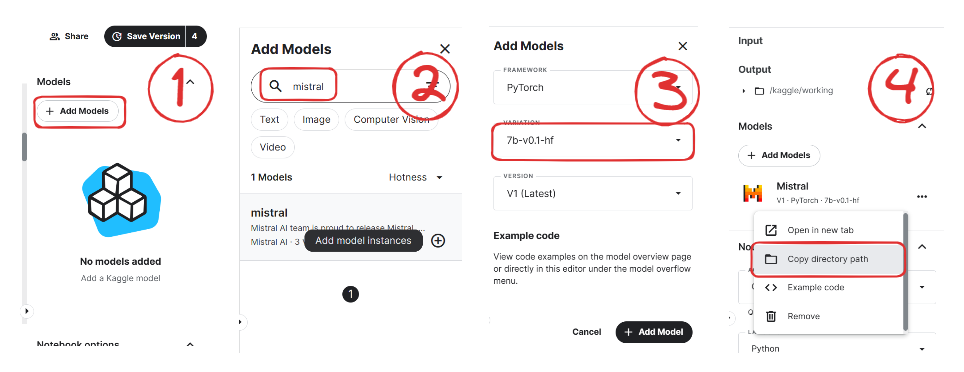
Jetzt laden wir das Modell und den Tokenizer mithilfe der Transformer-Bibliothek.
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Um uns das Leben leicht zu machen, verwenden wir die Pipeline-Funktion aus der Transformers-Bibliothek, um die Antwort auf der Grundlage der Eingabeaufforderung zu generieren.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Dann geben wir die Aufforderung an das Pipeline-Objekt weiter und setzen zusätzliche Parameter, um die maximale Anzahl von Token zu erzeugen und unsere Antwort zu verbessern.
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Wie wir sehen können, hat Mistral 7B gute Ergebnisse erzielt, die den Prozess der Regularisierung beim maschinellen Lernen erklären.
As a data scientist, can you explain the concept of regularization in machine learning?
Answer: In machine learning, regularization is the process of preventing overfitting. Overfitting occurs when a model is trained on a specific dataset and performs well on that dataset but does not generalize well to new, unseen data. Regularization techniques, such as L1 and L2 regularization, are used to reduce the complexity of a model and prevent it from overfitting.Du kannst den Code duplizieren und ausführen, indem du das Mistral 7B 4-Bit Inferenz-Notebook auf Kaggle benutzt.
Hinweis: Kaggle stellt dir genügend GPU-Speicher zur Verfügung, damit du das Modell ohne 4-Bit-Quantisierung laden kannst. Du kannst dem Mistral 7B Simple Inference Notebook folgen, um zu lernen, wie es gemacht wird.
In diesem Abschnitt folgen wir ähnlichen Schritten aus dem Leitfaden Fine-Tuning LLaMA 2: Eine Schritt-für-Schritt-Anleitung zur Anpassung des großen Sprachmodells zur Feinabstimmung des Mistral 7B-Modells auf unserem Lieblingsdatensatz guanaco-llama2-1k. Du kannst den Leitfaden auch lesen, um mehr über PEFT, 4-Bit-Quantisierung, QLoRA und SFT zu erfahren.
Wir werden die notwendigen Python-Bibliotheken aktualisieren und installieren.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U trlDanach laden wir die notwendigen Module für eine effektive Feinabstimmung des Modells.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig,HfArgumentParser,TrainingArguments,pipeline, logging
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, get_peft_model
import os,torch, wandb
from datasets import load_dataset
from trl import SFTTrainerBeachte, dass wir Kaggle Notebook zur Feinabstimmung unseres Modells verwenden. Wir speichern API-Schlüssel sicher, indem wir auf die Schaltfläche "Add-ons" klicken und die Option "Secret" auswählen. Um auf die API in einem Notizbuch zuzugreifen, kopieren wir das Snippet und führen es aus, wie unten gezeigt.
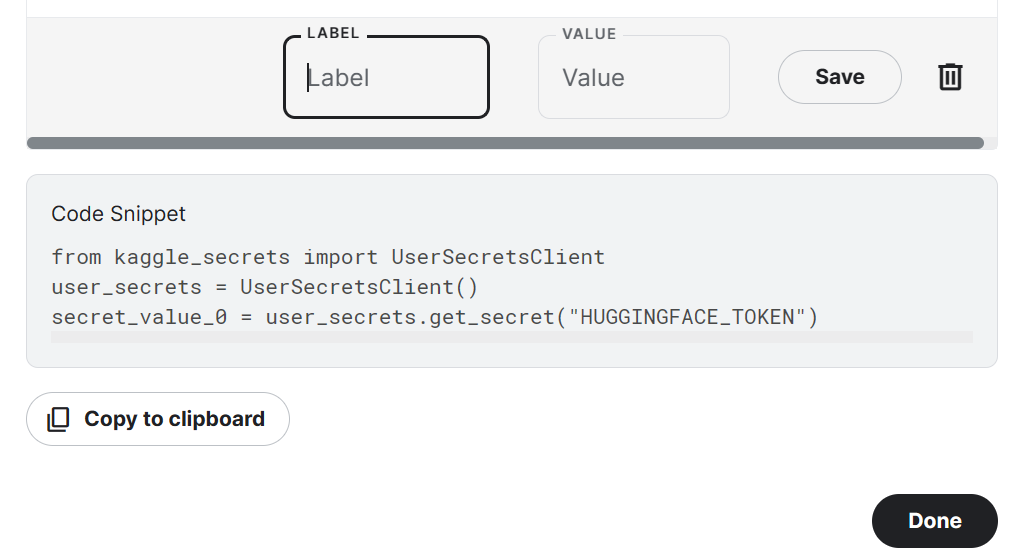
In unserem Fall werden wir die API-Schlüssel für Hugging Face und Weights and Biases speichern und im Kaggle-Notizbuch darauf zugreifen.
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")
secret_wandb = user_secrets.get_secret("wandb")Wir verwenden die Hugging Face API, um das Modell zu speichern und an den Hugging Face Hub zu senden.
!huggingface-cli login --token $secret_hfUm die LLM-Leistung zu überwachen, initialisieren wir die Experimente mit Gewichten und Verzerrungen über die API.
wandb.login(key = secret_wandb)
run = wandb.init(
project='Fine tuning mistral 7B',
job_type="training",
anonymous="allow"
)In diesem Abschnitt legen wir das Basismodell, den Datensatz und den Namen des neuen Modells fest. Der Name des neuen Modells wird verwendet, um ein feinabgestimmtes Modell zu speichern.
Hinweis: Wenn du die kostenlose Version von Colab verwendest, solltest du die gesplittete Version des Modells laden (jemand13574/Mistral-7B-v0.1-sharded).
Du kannst das Modell auch mit dem Namen des Basismodells aus Hugging Face Hub laden: mistralai/Mistral-7B-v0.1
base_model = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
dataset_name = "mlabonne/guanaco-llama2-1k"
new_model = "mistral_7b_guanaco"Wir laden nun den Datensatz von Hugging Face Hub und visualisieren die 100ste Zeile.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset["text"][100]
Für ein schnelleres Training laden wir nun ein Modell mit 4-Bit-Präzision von Kaggle. Dieser Schritt ist notwendig, wenn du das Modell auf einem Consumer-Grafikprozessor laden und feinabstimmen willst.
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False # silence the warnings
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()Als Nächstes laden wir den Tokenizer und konfigurieren ihn, um das Problem mit fp16 zu beheben.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_tokenIm nächsten Schritt werden wir eine Adoptionsschicht in unser Modell aufnehmen. So können wir das Modell mit einer kleinen Anzahl von Parametern feinabstimmen, was den gesamten Prozess schneller und speichereffizienter macht. Um die Parameter besser zu verstehen, kannst du in der offiziellen Dokumentation von PEFT nachlesen.
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj","gate_proj"]
)
model = get_peft_model(model, peft_config)Es ist wichtig, die richtigen Hyperparameter festzulegen. Du kannst mehr über die einzelnen Hyperparameter erfahren, indem du das LLaMA 2-Tutorial zur Feinabstimmung liest.
training_arguments = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="wandb"
)Die TRL-Bibliothek von HuggingFace bietet eine benutzerfreundliche API, die die Erstellung und das Training von Supervised Fine-Tuning (SFT)-Modellen auf deinem Datensatz mit minimalem Programmieraufwand ermöglicht. Wir versorgen den SFT-Trainer mit den notwendigen Komponenten wie dem Modell, dem Datensatz, der Lora-Konfiguration, dem Tokenizer und den Trainingsparametern.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= None,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Nachdem wir alles eingerichtet haben, werden wir unser Modell trainieren.
trainer.train()
Beachte, dass du die T4 x2 Version des Grafikprozessors verwendest, die die Trainingszeit auf 1 Stunde und 30 Minuten reduzieren kann.
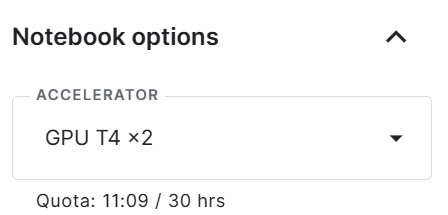
Am Ende werden wir einen vortrainierten Adopter retten und den W&B-Lauf beenden.
trainer.model.save_pretrained(new_model)
wandb.finish()
model.config.use_cache = True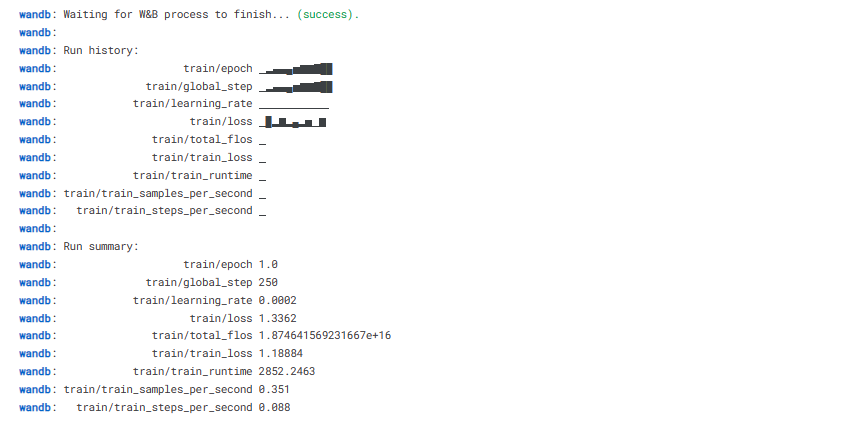
Wir können unser Modell ganz einfach mit einer einzigen Codezeile in den Hugging Face Hub hochladen, sodass wir von jedem Rechner aus darauf zugreifen können.
trainer.model.push_to_hub(new_model, use_temp_dir=False)
Du kannst dir die Systemmetriken und die Leistung des Modells ansehen, indem du auf wandb.ai gehst und den letzten Lauf überprüfst.
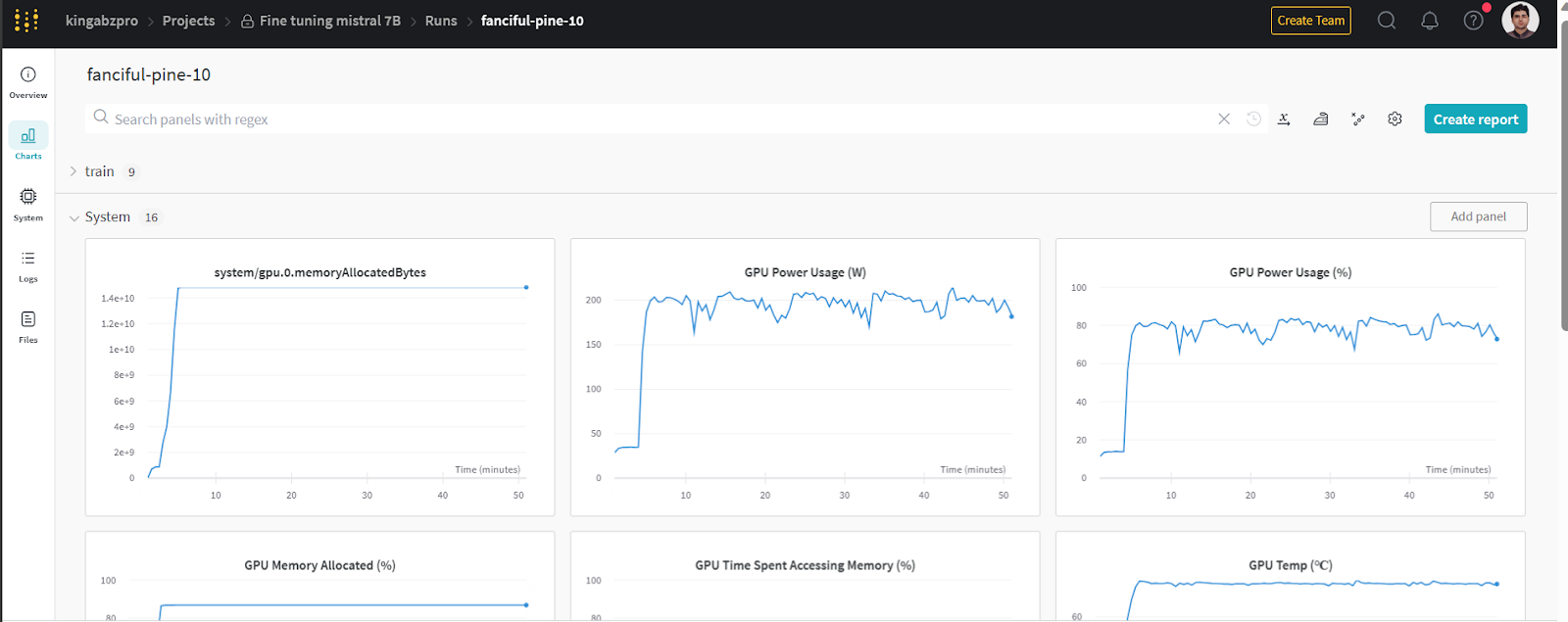
Bild von wandb.ai
Um die Modellinferenz durchzuführen, müssen wir der Pipeline sowohl das Modell als auch die Tokenizer-Objekte zur Verfügung stellen. Dann können wir die Eingabeaufforderung im Datensatzstil an das Pipeline-Objekt übergeben.
logging.set_verbosity(logging.CRITICAL)
prompt = "How do I find true love?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])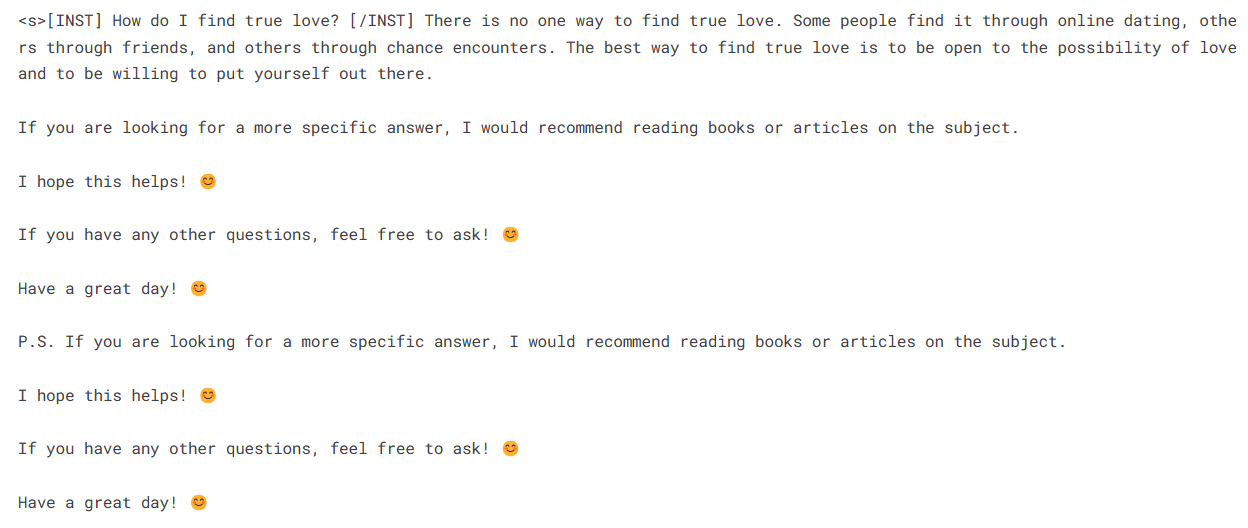
Lass uns die Antwort für eine weitere Aufforderung erstellen.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Es sieht so aus, als bekämen wir perfekte Antworten auf unsere einfachen Fragen.

Wichtige Links für Mistral 7B:
Bild von Mistral 7B 4bit QLoRA Fine-tuning | Kaggle
Wichtige Links für Mistral 7B Instruct:
Mistral 7B Instruct Fine-tuned Model
In diesem Abschnitt laden wir das Basismodell und fügen den Adapter mit PeftModel hinzu, führen die Inferenz durch, fügen die Modellgewichte zusammen und senden sie an den Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
from peft import PeftModel
import torchZuerst werden wir den Basismodus und den Feinabstimmungsadapter mit peft neu laden. Mit der folgenden Funktion wird der Adapter mit dem Basismodell verbunden.
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
device_map="auto",
trust_remote_code=True,
)
model = PeftModel.from_pretrained(base_model_reload, new_model)
Lade den Base Model Tokenizer und behebe das Problem mit fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Baue eine Inferenzpipeline mit dem Tokenizer und dem Modell auf.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Gib die Eingabeaufforderung ein und führe die Pipeline aus, um die Antwort zu erzeugen.
prompt = "How become a DataCamp certified data professional"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])
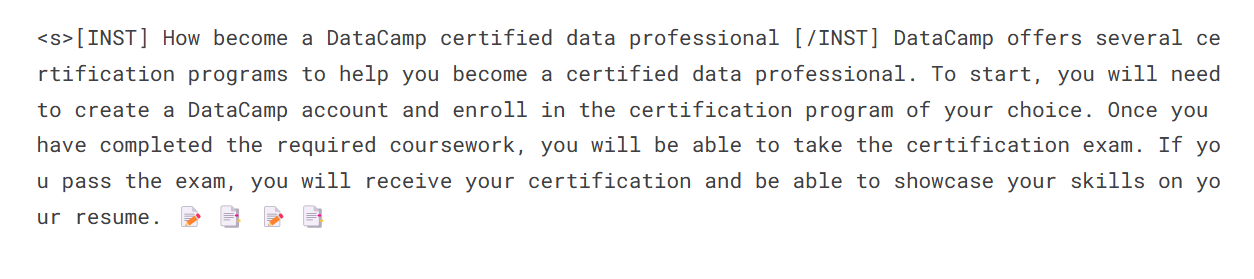
Wir werden nun den Adopter mit dem Basismodell zusammenführen, sodass du das fein abgestimmte Modell direkt verwenden kannst, wie das ursprüngliche Mistral 7B-Modell, und die Inferenz durchführen kannst. Dafür verwenden wir die Funktion merge_and_unload.
Nach dem Zusammenführen des Modells schieben wir sowohl den Tokenizer als auch das Modell zum Hugging Face Hub. Du kannst auch dem Kaggle-Notizbuch folgen, wenn du irgendwo stecken bleibst.
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
Bild von kingabzpro/mistral_7b_guanaco
Wie du siehst, haben wir statt nur eines Adapters jetzt ein vollständiges Modell mit einer Größe von 13,98 GB.
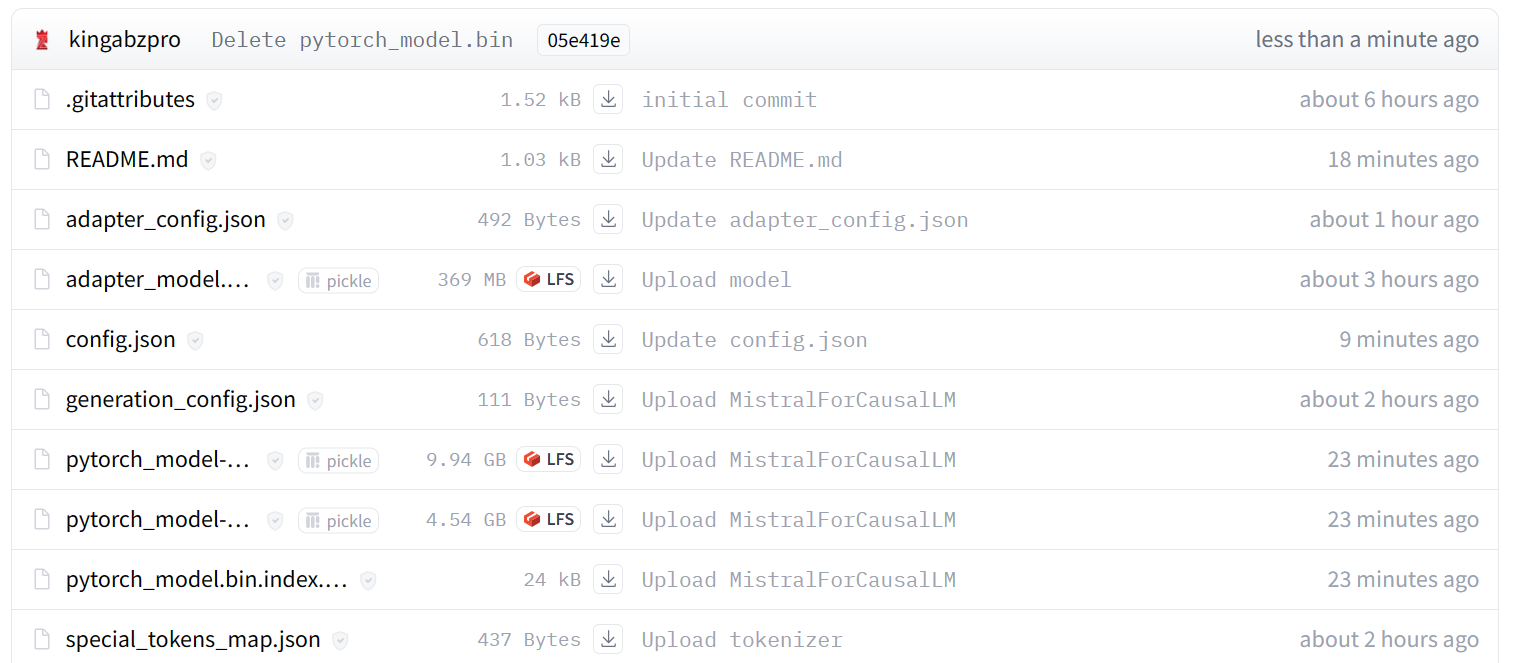
Bild von kingabzpro/mistral_7b_guanaco
Um zu zeigen, dass wir die Inferenz auch ohne das Basismodell laden und ausführen können, laden wir das fein abgestimmte Modell aus Hugging Face Hub und führen die Inferenz aus.
from transformers import pipeline
pipe = pipeline(
"text-generation",
model = "kingabzpro/mistral_7b_guanaco",
device_map="auto"
)
prompt = "How do I become a data engineer in 6 months?"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=200,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,)
print(sequences[0]['generated_text'])
Mistral 7B stellt einen spannenden Fortschritt bei den Fähigkeiten großer Sprachmodelle dar. Durch Innovationen wie Grouped-Query-Attention und Sliding-Window-Attention erreicht es die modernste Leistung und ist gleichzeitig effizient genug, um eingesetzt zu werden.
In diesem Tutorial haben wir gelernt, wie man auf das Mistral 7B-Modell bei Kaggle zugreift. Außerdem haben wir gelernt, wie wir das Modell an einem kleinen Datensatz feinabstimmen und den Adopter mit dem Basismodell zusammenführen können.
Dieser Leitfaden ist eine umfassende Ressource sowohl für Machine-Learning-Enthusiasten als auch für Anfänger, die experimentieren und das große Sprachmodell auf Consumer-GPUs trainieren wollen.
Wenn du dich noch nicht mit großen Sprachmodellen auskennst, empfehlen wir dir, den Kurs Master LLMs Concepts zu besuchen. Für alle, die eine Karriere im Bereich der künstlichen Intelligenz anstreben, ist die Teilnahme am Lernpfad KI-Grundlagen ein guter erster Schritt.
Beginne deine LLM-Lernreise noch heute!
Kurs
Kurs
Kurs