
Lernpfad
Grundlagen der KI
10 Std.
Nach der Veröffentlichung der ersten Version von LLaMA durch Meta begann ein neues Wettrüsten um die Entwicklung besserer Large Language Models (LLMs), die es mit Modellen wie GPT-3.5 (ChatGPT) aufnehmen konnten. Die Open-Source-Gemeinschaft veröffentlichte schnell immer leistungsfähigere Modelle. Es fühlte sich an wie Weihnachten für KI-Enthusiasten, denn es wurden ständig neue Entwicklungen angekündigt.
Diese Fortschritte hatten jedoch auch ihre Schattenseiten. Die meisten Open-Source-Modelle haben eine eingeschränkte Lizenz, d.h. sie können nur für Forschungszwecke verwendet werden. Zweitens konnten es sich nur große Unternehmen oder Forschungsinstitute mit beträchtlichen Budgets leisten, die Modelle zu verfeinern oder zu trainieren. Und schließlich war es teuer, große Modelle auf dem neuesten Stand der Technik einzusetzen und zu pflegen.
Die neue Version der LLaMA-Modelle zielt darauf ab, diese Probleme zu lösen. Sie ist mit einer kommerziellen Lizenz ausgestattet, die sie für mehr Organisationen zugänglich macht. Außerdem ermöglichen neue Methoden jetzt eine Feinabstimmung auf Consumer-GPUs mit begrenztem Speicher.
Diese Demokratisierung von KI ist entscheidend für eine breite Akzeptanz. Durch die Überwindung von Einstiegshürden können auch kleine Unternehmen maßgeschneiderte Modelle bauen, die auf ihre Bedürfnisse und Budgets zugeschnitten sind.
In diesem Tutorial erkunden wir Llama-2 und demonstrieren, wie wir es mit Google Colab an einem neuen Datensatz feinjustieren. Außerdem werden wir uns mit neuen Methoden und Feinabstimmungstechniken befassen, die dazu beitragen können, den Speicherverbrauch zu reduzieren und den Trainingsprozess zu beschleunigen.

Bild erstellt vom Autor mit DALL-E 3
Llama 2 ist eine Sammlung von Open-Source-LLMs der zweiten Generation von Meta, die mit einer kommerziellen Lizenz ausgestattet ist. Es ist für eine breite Palette von Aufgaben zur Verarbeitung natürlicher Sprache ausgelegt, wobei die Modelle zwischen 7 Milliarden und 70 Milliarden Parametern umfassen. Mehr über LLaMA-Modelle erfährst du in unserem Artikel Einführung in LLaMA von Meta AI: Stärkung der KI-Innovation.
Llama-2-Chat, das für Dialoge optimiert ist, hat eine ähnliche Leistung gezeigt wie beliebte Closed-Source-Modelle wie ChatGPT und PaLM. Wir können die Leistung des Modells sogar noch verbessern, indem wir es mit einem hochwertigen Gesprächsdatensatz feinabstimmen.
Beim maschinellen Lernen werden die Gewichte und Parameter eines trainierten Modells an neue Daten angepasst, um seine Leistung bei einer bestimmten Aufgabe zu verbessern. Dabei wird das Modell auf einem neuen Datensatz trainiert, der für die jeweilige Aufgabe spezifisch ist, während die Gewichte des Modells aktualisiert werden, um sich an die neuen Daten anzupassen. Mehr über die Feinabstimmung erfährst du in unserer Anleitung zur Feinabstimmung von GPT 3.5.
Eine Feinabstimmung der LLMs ist auf Consumer-Hardware aufgrund der unzureichenden VRAMs und Rechenleistung nicht möglich. In diesem Lernprogramm werden wir jedoch diese Speicher- und Rechenprobleme überwinden und unser Modell mit einer kostenlosen Version von Google Colab Notebook trainieren.
In diesem Teil lernen wir alle Schritte kennen, die für die Feinabstimmung des Llama 2-Modells mit 7 Milliarden Parametern auf einem T4-Grafikprozessor erforderlich sind. Du hast die Möglichkeit, einen kostenlosen Grafikprozessor bei Google Colab oder Kaggle zu verwenden. Der Code läuft auf beiden Plattformen.
Die Colab T4 GPU hat einen begrenzten VRAM von 16 GB. Das ist kaum genug, um die Gewichte von Llama 2-7b zu speichern. Das bedeutet, dass eine vollständige Feinabstimmung nicht möglich ist und wir parameter-effiziente Feinabstimmungstechniken wie LoRA oder QLoRA verwenden müssen.
Wir verwenden die QLoRA-Technik, um das Modell mit 4-Bit-Präzision fein abzustimmen und die VRAM-Nutzung zu optimieren. Dafür werden wir das Hugging Face Ökosystem der LLM-Bibliotheken nutzen: transformers, accelerate, peft, trl und bitsandbytes.
Wir beginnen mit der Installation der benötigten Bibliotheken.
%%capture
%pip install accelerate peft bitsandbytes transformers trlDanach laden wir die notwendigen Module aus diesen Bibliotheken.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig
from trl import SFTTrainerDu kannst auf das offizielle Llama-2-Modell von Meta bei Hugging Face zugreifen, aber du musst eine Anfrage stellen und ein paar Tage warten, bis du eine Bestätigung bekommst. Anstatt zu warten, werden wir das Llama-2-7b-chat-hf von NousResearch als Basismodell verwenden. Es ist dasselbe wie das Original, aber leicht zugänglich.
Bild von Hugging Face
Wir werden unser Basismodell mit einem kleineren Datensatz namens mlabonne/guanaco-llama2-1k feinabstimmen und den Namen für das feinabgestimmte Modell schreiben.
# Model from Hugging Face hub
base_model = "NousResearch/Llama-2-7b-chat-hf"
# New instruction dataset
guanaco_dataset = "mlabonne/guanaco-llama2-1k"
# Fine-tuned model
new_model = "llama-2-7b-chat-guanaco"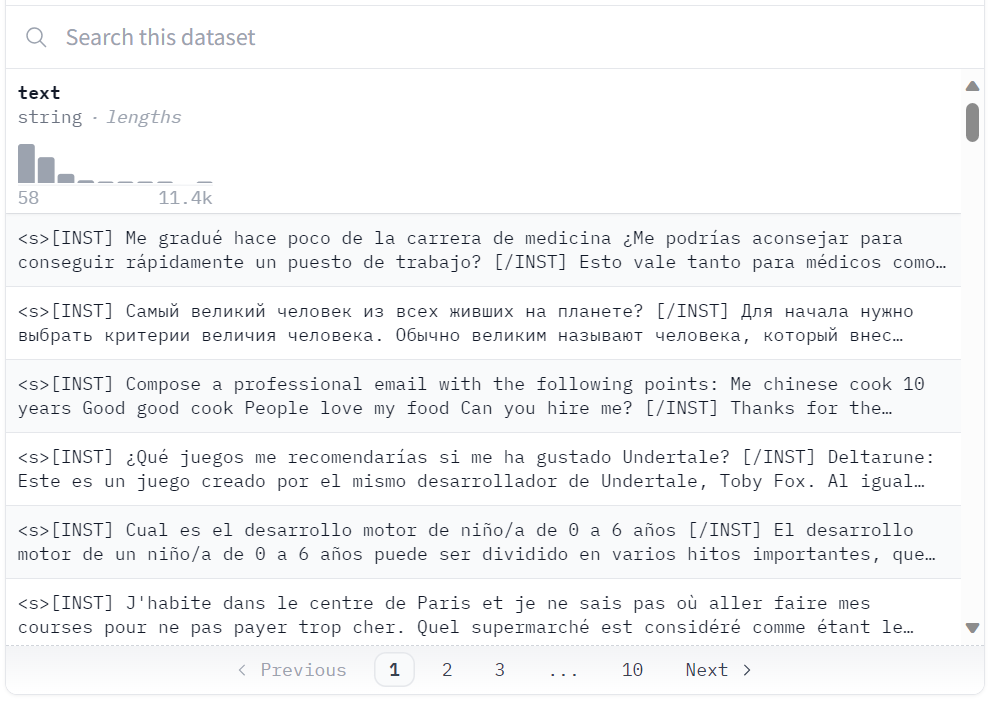
Datensatz bei Hugging Face
Wir laden den Datensatz "guanaco-llama2-1k" aus dem Hugging Face Hub. Der Datensatz enthält 1000 Proben und wurde so bearbeitet, dass er dem Llama 2 Prompt-Format entspricht. Er ist eine Teilmenge des ausgezeichneten timdettmers/openassistant-guanaco-Datensatzes.
dataset = load_dataset(guanaco_dataset, split="train")Dataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/parquet/mlabonne--guanaco-llama2-1k-f1f1134768f90029/0.0.0/0b6d5799bb726b24ad7fc7be720c170d8e497f575d02d47537de9a5bac074901. Subsequent calls will reuse this data.Die 4-Bit-Quantisierung über QLoRA ermöglicht ein effizientes Finetuning großer LLM-Modelle auf Consumer-Hardware bei gleichbleibend hoher Leistung. Das verbessert die Zugänglichkeit und Nutzbarkeit für reale Anwendungen drastisch.
QLoRA quantisiert ein vortrainiertes Sprachmodell auf 4 Bits und friert die Parameter ein. Eine kleine Anzahl von trainierbaren Low-Rank-Adapter-Schichten wird dann zum Modell hinzugefügt.
Während der Feinabstimmung werden die Gradienten durch das eingefrorene 4-Bit-quantisierte Modell nur in die Low-Rank-Adapter-Schichten zurückverfolgt. Das gesamte vortrainierte Modell bleibt also auf 4 Bits fixiert, während nur die Adapter aktualisiert werden. Auch die 4-Bit-Quantisierung beeinträchtigt die Leistung des Modells nicht.
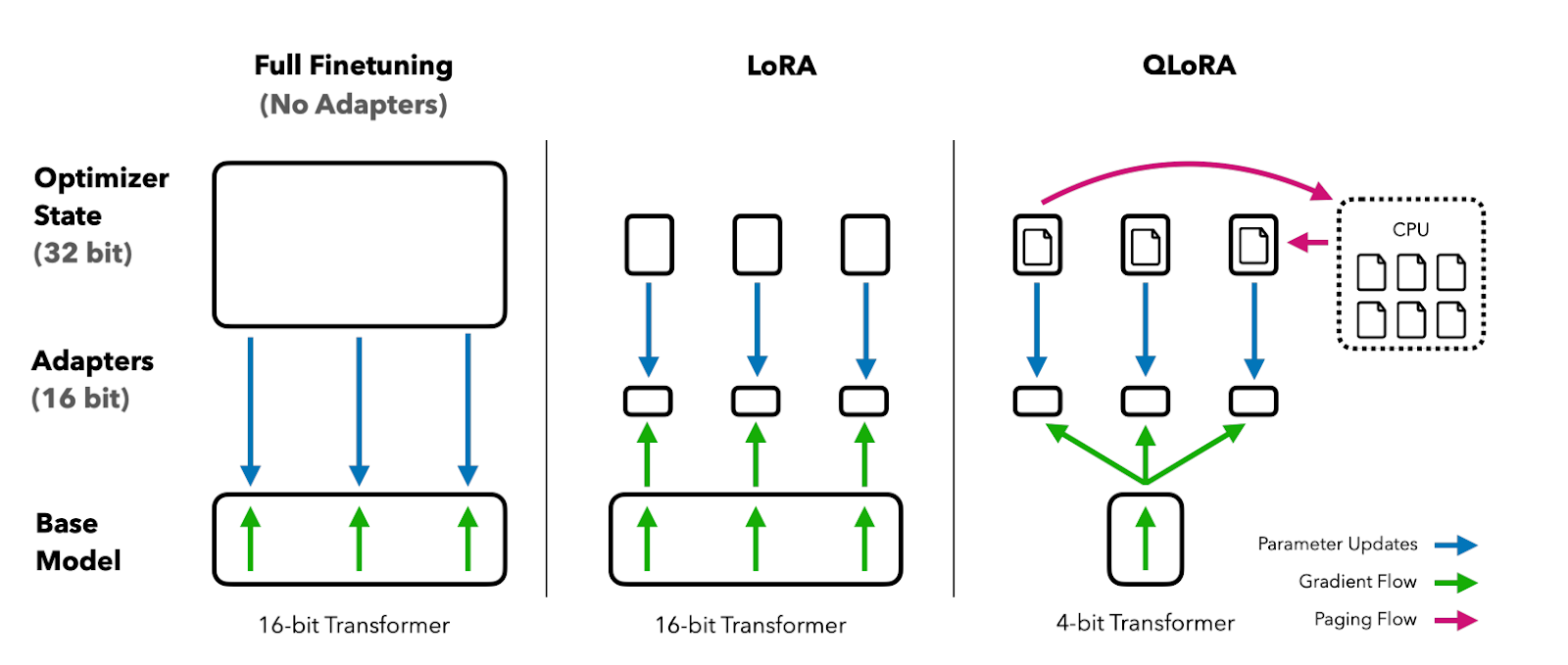
Bild aus dem QLoRA-Papier
Du kannst das Papier lesen, um es besser zu verstehen.
In unserem Fall erstellen wir eine 4-Bit-Quantisierung mit einer Konfiguration vom Typ NF4 unter Verwendung von BitsAndBytes.
compute_dtype = getattr(torch, "float16")
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)Wir laden jetzt ein Modell mit 4-Bit-Präzision mit dem Rechentyp "float16" aus Hugging Face, um schneller zu trainieren.
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=quant_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1Als Nächstes laden wir den Tokenizer von Hugginface und setzen padding_side auf "rechts", um das Problem mit fp16 zu beheben.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Die herkömmliche Feinabstimmung von vorab trainierten Sprachmodellen (PLMs) erfordert die Aktualisierung aller Parameter des Modells, was rechenintensiv ist und große Datenmengen erfordert.
Bei der parametereffizienten Feinabstimmung (PEFT) wird nur eine kleine Teilmenge der einflussreichsten Parameter des Modells aktualisiert, was das Verfahren sehr viel effizienter macht. Erfahre mehr über Parameter, indem du die offizielle PEFT-Dokumentation liest.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)Im Folgenden findest du eine Liste von Hyperparametern, die zur Optimierung des Trainingsprozesses verwendet werden können:
training_params = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="tensorboard"
)Die überwachte Feinabstimmung (SFT) ist ein wichtiger Schritt beim Verstärkungslernen aus menschlichem Feedback (RLHF). Die TRL-Bibliothek von HuggingFace bietet eine benutzerfreundliche API, um SFT-Modelle zu erstellen und sie mit nur wenigen Zeilen Code auf deinem Datensatz zu trainieren. Es enthält Tools zum Trainieren von Sprachmodellen mit Hilfe von Reinforcement Learning, beginnend mit überwachter Feinabstimmung, dann Belohnungsmodellierung und schließlich Proximal Policy Optimization (PPO).
Wir stellen SFT Trainer das Modell, den Datensatz, die Lora-Konfiguration, den Tokenizer und die Trainingsparameter zur Verfügung.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_params,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_params,
packing=False,
)Wir werden .train() nutzen, um das Llama 2-Modell mit einem neuen Datensatz zu verfeinern. Es dauerte eineinhalb Stunden, bis das Modell eine Epoche abgeschlossen hatte.

Nachdem wir das Modell trainiert haben, speichern wir den Modelladapter und die Tokenizer. Du kannst das Modell auch über eine ähnliche API zu Hugging Face hochladen.
trainer.model.save_pretrained(new_model)
trainer.tokenizer.save_pretrained(new_model)
Wir können nun die Trainingsergebnisse in der interaktiven Sitzung von Tensorboard überprüfen.
from tensorboard import notebook
log_dir = "results/runs"
notebook.start("--logdir {} --port 4000".format(log_dir))
Um unser abgestimmtes Modell zu testen, verwenden wir die transformers Textgenerierungspipeline und stellen einfache Fragen wie "Wer ist Leonardo Da Vinci?".
logging.set_verbosity(logging.CRITICAL)
prompt = "Who is Leonardo Da Vinci?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Ausgabe:
Wie wir sehen können, haben wir erstaunliche Ergebnisse erzielt.
<s>[INST] Who is Leonardo Da Vinci? [/INST] Leonardo da Vinci (1452-1519) was an Italian polymath, artist, inventor, and engineer.
Da Vinci is widely considered one of the greatest painters of all time, and his works include the famous Mona Lisa. He was also an accomplished engineer, inventor, and anatomist, and his designs for machines and flight were centuries ahead of his time.
Da Vinci was born in the town of Vinci, Italy, and he was the illegitimate son of a local notary. Despite his humble origins, he was able to study art and engineering in Florence, and he became a renowned artist and inventor.
Da Vinci's work had a profound impact on the Renaissance, and his legacy continues to inspire artists, engineers, and inventors to this day. He
Lass uns eine andere Frage stellen.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Ausgabe:
Guanaco ist ein qualitativ hochwertiger Datensatz, der in der Vergangenheit zur Feinabstimmung modernster LLMs verwendet wurde. Der gesamte Guanaco-Datensatz ist auf Hugging Face verfügbar und hat das Potenzial, bei einer Vielzahl von natürlichsprachlichen Aufgaben eine noch höhere Leistung zu erzielen.
<s>[INST] What is Datacamp Career track? [/INST] DataCamp Career Track is a program that offers a comprehensive learning experience to help you build your skills and prepare for a career in data science.
The program includes a range of courses, projects, and assessments that are designed to help you build your skills in data science. You will learn how to work with data, create visualizations, and build predictive models.
In addition to the technical skills, you will also learn how to communicate your findings to stakeholders and how to work with a team to solve complex problems.
The program is designed to be flexible, so you can learn at your own pace and on your own schedule. You will also have access to a community of learners and mentors who can provide support and guidance throughout the program.
Overall, DataCamp Career Track is a great way to build your skills and prepare for a career inHier ist das Colab-Notizbuch mit dem Code und den Ausgaben, um dich bei deiner Codierungsreise zu unterstützen.
Als Nächstes kannst du LlamaIndex verwenden und deine eigene KI-Anwendung mit deinem neuen Trainingsmodell erstellen, indem du dem LlamaIndex folgst: Hinzufügen persönlicher Daten zu LLMs tutorial. Du kannst dich für dein Projekt inspirieren lassen, indem du dir 5 Projekte mit generativen Modellen und Open Source Tools ansiehst.
Das Tutorial bot eine umfassende Anleitung zur Feinabstimmung des LLaMA 2-Modells mit Techniken wie QLoRA, PEFT und SFT, um Speicher- und Rechenbeschränkungen zu überwinden. Durch den Einsatz von Hugging Face-Bibliotheken wie transformers, accelerate, peft, trl und bitsandbytes konnten wir das LLaMA 2-Modell mit 7B-Parametern erfolgreich auf einer Consumer-GPU feinabstimmen.
Insgesamt hat dieses Tutorial gezeigt, wie die jüngsten Fortschritte die Demokratisierung und Zugänglichkeit von großen Sprachmodellen ermöglicht haben, so dass selbst Hobbyisten mit begrenzten Ressourcen hochmoderne KI erstellen können.
Wenn du dich noch nicht mit großen Sprachmodellen auskennst, solltest du den Master LLMs Concepts Kurs besuchen. Und wenn du deine Karriere im Bereich der künstlichen Intelligenz beginnen willst, solltest du dich für den Skill Track AI Fundamentals anmelden.
Beginne deine KI-Reise noch heute!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.