
Cursus
Développer des applications d'IA
21 h
J'ai essayé OpenAId'OpenAI outil de distillation de modèles-Il nécessite un codage minimal et nous permet de gérer l'ensemble du processus de distillation au sein d'une plateforme unique, de la génération d'ensembles de données à l'affinement des modèles. la mise au point des modèles et l'évaluation de leurs performances.
Dans ce tutoriel, je vais vous aider à démarrer avec l'outil de distillation de modèles d'OpenAI. Tout d'abord, nous couvrirons les bases de la distillation de modèles, puis nous ferons un projet de distillation de démonstration en utilisant l'API de l'API d'OpenAI.
Imaginez un enseignant compétent et bien formé qui enseigne son processus de réflexion et ses connaissances à un élève. Il s'agit là des principes de base du fonctionnement de la distillation assistée par ordinateur.
Dans cette technique, l'enseignant est un grand modèle pré-entraîné et l'élève est un modèle plus petit qui apprend à reproduire les résultats de l'enseignant. Cela permet à l'élève d'effectuer des tâches spécifiques à un niveau comparable à celui de l'enseignant, mais avec moins de ressources.
La distillation de modèles se présente sous de nombreuses formes, chacune ayant ses propres méthodes et objectifs. Dans un cas, nous avons besoin que l'étudiant se contente d'imiter les sorties d'un modèle plus grand. Dans un autre cas, nous voulons inculquer l'approche de résolution de problèmes de l'enseignant au modèle plus petit. En fin de compte, l'objectif est de bénéficier des capacités d'un grand modèle, en utilisant un modèle efficace.
Une méthode courante pour transférer les connaissances d'un modèle "enseignant" à un modèle "étudiant" consiste à affiner le réglage de l'étudiant sur un ensemble de données constitué d'entrées et de sorties correspondantes générées par l'enseignant.
Au cours de cet processus d'apprentissage supervisé le modèle de l'élève apprend à reproduire les réponses de l'enseignant lorsqu'il est confronté à des données similaires.
Le processus de distillation présente de nombreux avantages :
Pour en savoir plus sur la distillation, vous pouvez lire cet article : La distillation du LLM expliquée.
Dans cette section, nous allons explorer un exemple de distillation de modèle en utilisant la plateforme OpenAI. Nous nous concentrerons principalement sur pour générer des commandes Git à la demande d'un utilisateur.
Nous allons tout d'abord créer un ensemble de données sur les petits appareils d'OpenAI GPT-4o mini d'OpenAI (étudiant) et évaluer les résultats.
Ensuite, nous utilisons GPT-4o (enseignant) pour traduire les mêmes phrases et affiner le modèle de l'étudiant sur l'ensemble des données produites par l'enseignant.
Enfin, nous devons évaluer le modèle de l'étudiant et déterminer les améliorations apportées.
En résumé, voici les mesures que nous allons prendre :
La première étape de la distillation de modèles consiste à sélectionner l'enseignant et l'élève, en fonction de la tâche envisagée et de votre budget de calcul.
Lorsque vous travaillez avec des modèles open source, il existe une variété de LLM avec des capacités et des tailles différentes. Avec la plateforme d'OpenAI, les options sont limitées.

Pour les besoins de notre exemple, nous sélectionnerons GPT-4o mini pour le modèle étudiant le plus petit et le modèle GPT-4o comme modèle pour l'enseignant.
Le GPT-4o-mini est un modèle relativement petit et un bon candidat pour le rôle d'étudiant. Le GPT-4o est relativement plus grand mais beaucoup plus performant et peut servir d'enseignant efficace pour l'élève.
D'autres options existent, et la modification des modèles ne nécessiterait qu'un effort minimal dans le cadre de notre projet de distillation de modèles.
Votre jeu de données pour cette tâche doit être suffisamment stimulant pour le modèle de l'étudiant, mais pas trop pour l'enseignant. Les qualités d'un bon ensemble de données, telles que la diversité, la représentativité ou la précision, sont toujours pertinentes dans la distillation de modèles.
Il est très important de disposer d'un ensemble de données suffisamment important pour avoir un impact sur le modèle de l'étudiant. Il n'existe pas de réponse directe à laquestion "Quelle doit être la taille de l'ensemble de données de distillation ?", car elle dépend de la complexité de votre tâche cible et des modèles que vous avez choisis comme enseignant et élève.
Selon la documentation d documentation d'OpenAIquelques centaines d'échantillons peuvent suffire, mais un groupe plus diversifié de milliers d'échantillons peut parfois conduire à de meilleurs résultats.
Notre ensemble de données dans cet article est composé de 386 demandes d'utilisateurs stockées dans un fichier JSON (vous pourriez tout aussi bien les stocker sous la forme d'une liste Python).
{
"requests": [
"Initialize a new Git repository in the current directory.",
"Clone the repository from GitHub to my local machine.",
"Create a new branch called 'feature-login'.",
...
"Show the differences between the working directory and the staging area.",
"Stage all modified and deleted files for commit.",
]
}Notre ensemble de données est actuellement constitué uniquement d'entrées, et nous devrions également générer des sorties. Les résultats de l'élève ne sont pas nécessaires pour la distillation, mais nous en avons besoin pour obtenir une base de référence pour la précision du modèle de l'élève (étape 4).
Nous utilisons le code ci-dessous pour parcourir l'ensemble des données d'entrée et générer une sortie pour chacune d'entre elles :
def generate_responses():
with open(JSON_PATH, 'r') as file:
user_messages = json.load(file)
for sentence in user_messages['requests']:
# Call the OpenAI model gpt-4o-mini and store the response
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": sentence
},
],
store=True,
metadata={
"task": "git"
}
)
generate_responses()Notez que nous utilisons store=True lorsque nous appelons le modèle OpenAI. Cet argument enregistrera les paires entrée/sortie dans notre tableau de bord OpenAI, de sorte que nous n'aurons pas besoin de stocker les sorties à l'aide du code.
Afin d'identifier et de filtrer ultérieurement ces complétions de chat, n'oubliez pas d'inclure des métadonnées lors de l'appel de la fonction client.chat.completions.create. Les arguments de ces métadonnées sont arbitraires.
Les résultats générés peuvent être consultés sur le site Achèvements du chat de notre tableau de bord OpenAI.
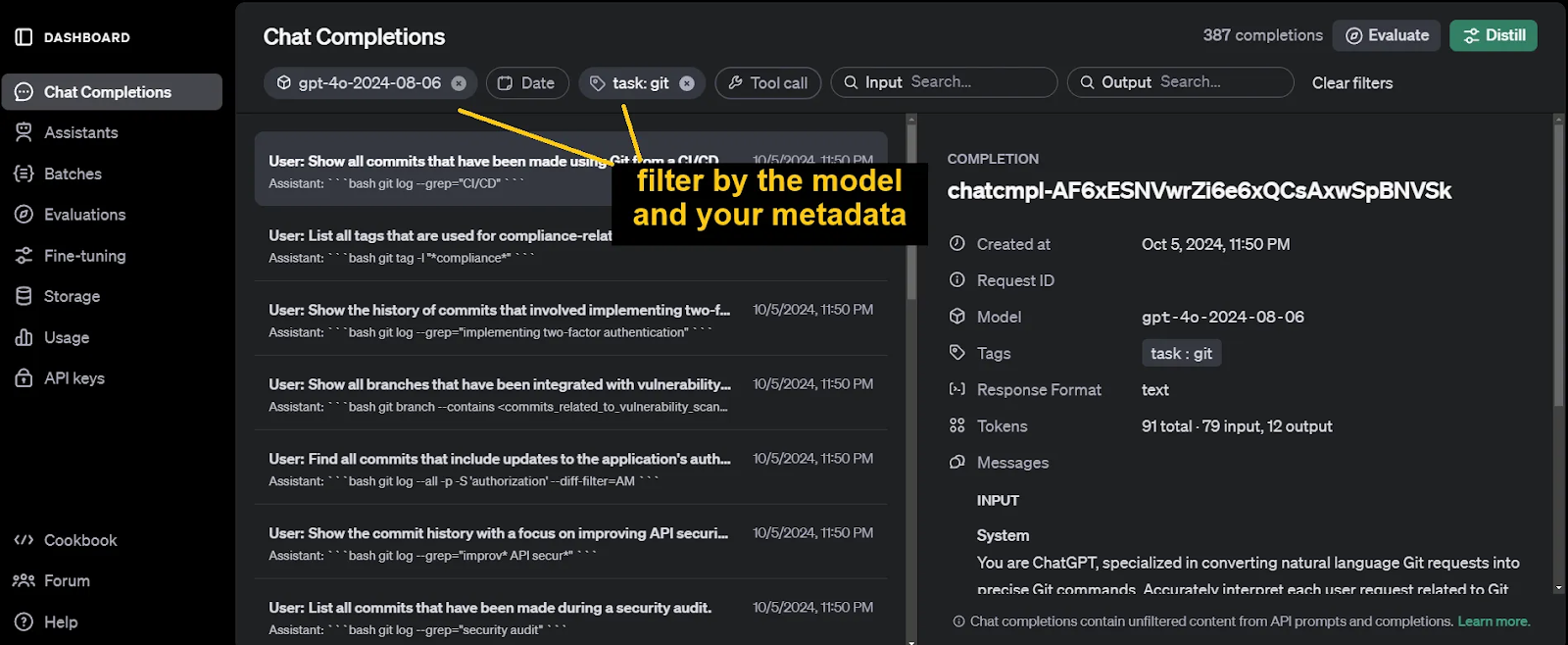
Un autre outil d'OpenAI qui s'avère utile pour la distillation de modèles est l'outil d'évaluation des modèles d'OpenAI. Evaluations est l'outil Evaluations. Nous utilisons cet outil pour évaluer les performances du modèle de l'étudiant avant la formation, en tant que mesure de référence. Nous l'utiliserons également plus tard lors de l'évaluation du modèle d'étudiant affiné.
Après avoir filtré les messages complétés à l'étape précédente, cliquez sur le boutonÉvaluer. Nous devons maintenant ajouter des critères de test.
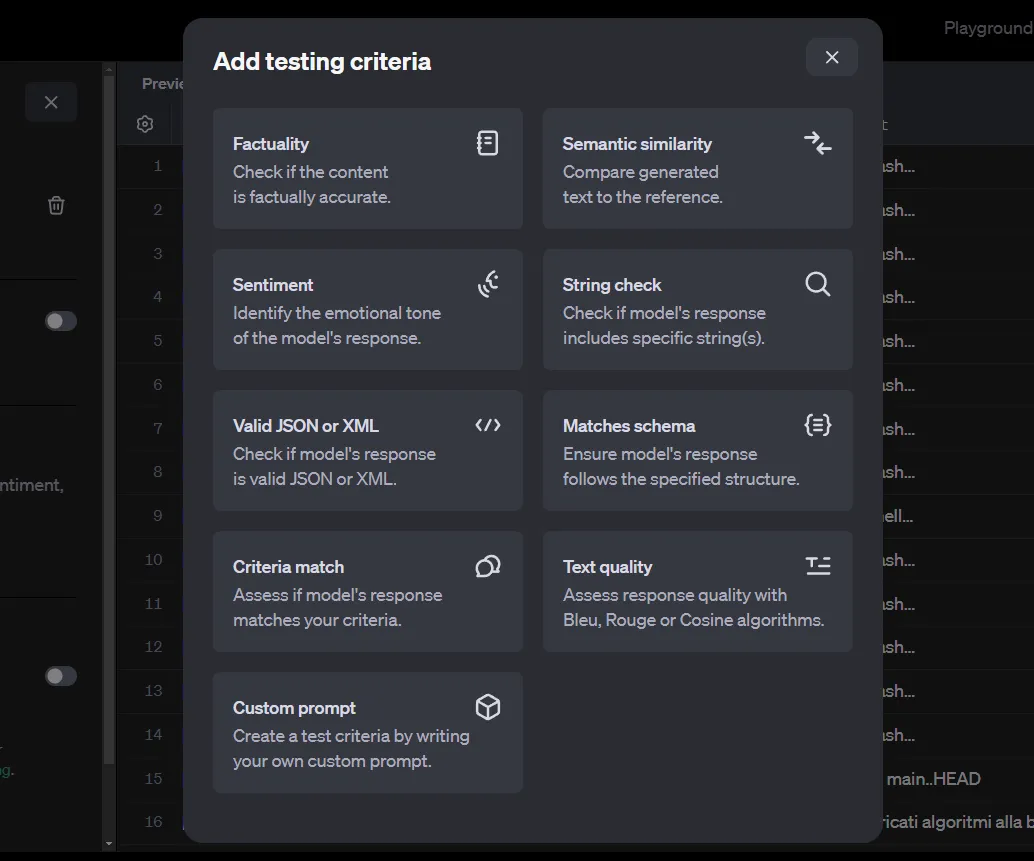
Il existe plusieurs méthodes pour évaluer les paires entrée/sortie. Notez que notre ensemble de données actuel est généré automatiquement par les complétions de chat d'OpenAI et ne contient que les entrées et les sorties. Cependant, certains de ces critères nécessitent également uneréférence pour être comparés.
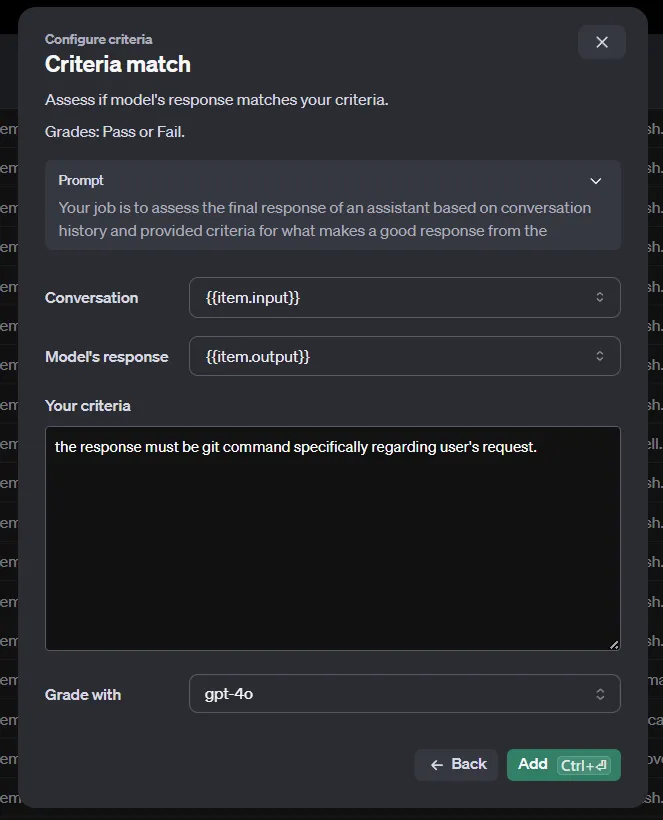
Cette référence pourrait être les résultats générés par un modèle plus sophistiqué, tel que GPT-4o ou o1-preview. Comme le stockage automatique des chats dans OpenAI ne nous permet pas de fournir une telle référence, nous sommes limités à l'utilisation des méthodes Criteria match ou Custom prompt, qui n'ont besoin que d'une entrée et d'une sortie.
Si vous devez utiliser d'autres méthodes, vous ne pouvez pas utiliser les complétions de chat d'OpenAI et devez créer votre fichierJSON avec du code. Ce n'est pas compliqué, mais nous ne nous y attarderons pas dans cet article.
Une fois les évaluations effectuées, vous recevrez vos résultats dans les plus brefs délais.
Pour affiner le modèle de l'élève, nous avons besoin d'un ensemble de données de haute qualité généré par l'enseignant. Cette étape est presque identique à l'étape 3 - vous devez seulement changer l'argument model de gpt-4o-mini à gpt-4o.
De nouveau, dans la section "Chat Completions", filtrez en fonction du modèle de l'enseignant et des métadonnées. Ensuite, sélectionnez le bouton Distiller. Le distillateur d'OpenAI est essentiellement l'outil de mise au point.
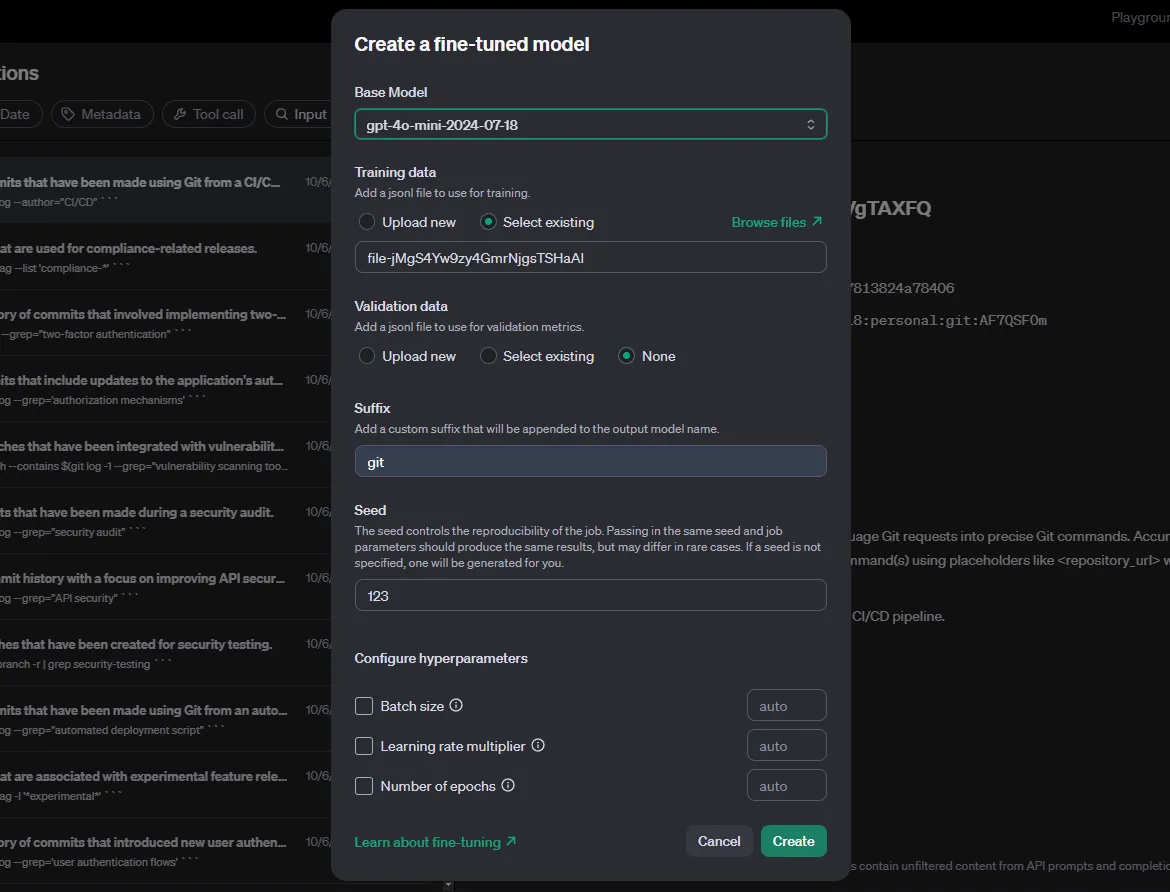
Pour le modèle de base, nous choisissons l'étudiant. Les hyperparamètres doivent être expérimentés et testés pour obtenir les meilleurs résultats. Enfin, sélectionnez Create et attendez la fin de la mise au point.
Une fois terminé, nous utiliserons à nouveau le code de l'étape 3, en utilisant cette fois le modèle affiné comme argument model. Le nom du modèle affiné est affiché en tant que "Modèle de sortie" sur votre page d'affinage.
def generate_responses():
with open(JSON_PATH, 'r') as file:
user_messages = json.load(file)
for sentence in user_messages['requests']:
# Call the OpenAI model gpt-4o-mini and store the response
response = client.chat.completions.create(
model="ft:gpt-4o-mini-2024-07-18:personal:git:AF7QSF0m",
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": sentence
},
],
store=True,
metadata={
"task": "git"
}
)
generate_responses()Après avoir fini de générer des résultats, utilisez les évaluations pour évaluer la capacité de votre nouveau modèle sur les données d'entrée.
La recette de la distillation d'OpenAI est simple mais directe. C'est d'autant plus utile que vous n'aurez pas à vous soucier d'affiner les modèles vous-même ou d'utiliser du code pour évaluer les résultats.
Les modèles d'OpenAI, même les plus petits, sont déjà très sophistiqués. Veillez à expérimenter les hyperparamètres avant d'affiner le modèle, à préparer des invites adéquates et stimulantes pour l'enseignant et l'élève, et à comparer l'évaluation affinée avec l'évaluation de base.
Avant de vous lancer dans la distillation de votre propre modèle, je vous conseille de lire ces deux ressources OpenAI : Distillation du modèle OpenAI dans l'API et Document sur la distillation de modèles.
Apprenez à créer des applications d'intelligence artificielle !
Cursus
Cursus
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach