
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Die Bewertung von LLMs erfordert einen umfassenden Ansatz, bei dem eine Reihe von Maßnahmen zur Bewertung verschiedener Aspekte ihrer Leistung eingesetzt wird. In dieser Diskussion gehen wir auf die wichtigsten Bewertungskriterien für LLMs ein, darunter Genauigkeit und Leistung, Voreingenommenheit und Fairness sowie andere wichtige Messgrößen.
Die genaue Messung der Leistung ist ein wichtiger Schritt, um die Fähigkeiten eines LLMs zu verstehen. In diesem Abschnitt werden die wichtigsten Kennzahlen zur Bewertung derGenauigkeit und Leistung von vorgestellt.
Die Komplexität ist ein grundlegender Maßstab für die Bewertung und Messung der Fähigkeit eines LLMs, das nächste Wort in einer Sequenz vorherzusagen. So können wir es berechnen:
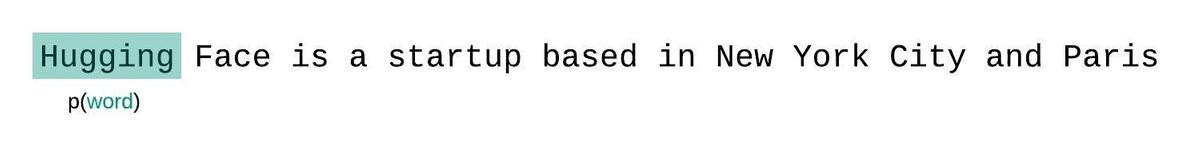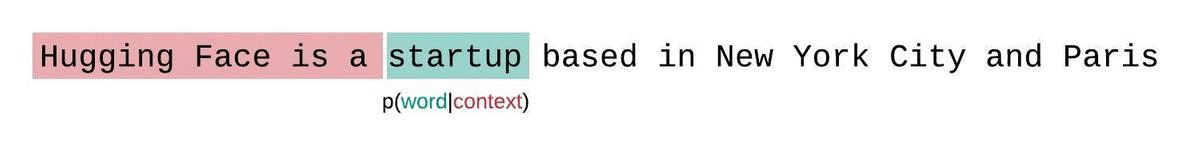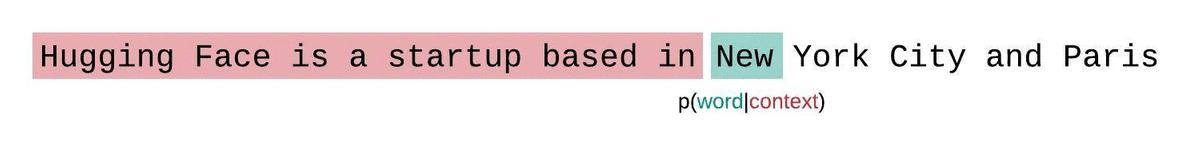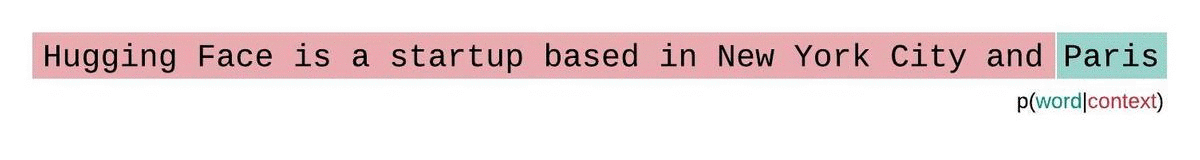
Niedrigere Perplexitätswerte zeigen an, dass das Modell das nächste Wort genauer vorhersagt, was eine bessere Leistung bedeutet. Im Wesentlichen gibt sie an, wie gut eine Wahrscheinlichkeitsverteilung oder ein Vorhersagemodell eine Stichprobe vorhersagt.
Für LLMs bedeutet eine geringere Komplexität, dass das Modell mehr Vertrauen in seine Wortvorhersagen hat, was zu einer kohärenteren und kontextgerechteren Texterstellung führt.
Die Genauigkeit ist eine weit verbreitete Metrik für KlassifizierungsaufgabenSie gibt den Anteil der richtigen Vorhersagen an, die das Modell trifft. Dies ist zwar ein typisch intuitiver Maßstab, aber im Zusammenhang mit offenen Generierungsaufgaben kann er oft irreführend sein.
Bei der Erstellung von kreativen oder kontextuell nuancierten Texten ist die "Korrektheit" der Ausgabe nicht so einfach zu definieren wie bei Aufgaben wie Stimmungsanalyse oder Themenklassifizierung. Obwohl die Genauigkeit für bestimmte Aufgaben nützlich ist, sollte sie bei der Bewertung von LLMs durch andere Kennzahlen ergänzt werden.
BLEU (Bilingual Evaluation Understudy) und ROUGE (Recall-Oriented Understudy for Gisting Evaluation) werden verwendet, um die Qualität des generierten Textes zu bewerten, indem er mit Referenztexten verglichen wird.
Bei BLEU geht es um Präzision: Wenn eine maschinelle Übersetzung genau dieselben Wörter verwendet wie eine menschliche Übersetzung, erhält sie eine hohe BLEU-Punktzahl. Wenn die menschliche Referenz zum Beispiel "Die Katze liegt auf der Matte" lautet und die maschinelle Ausgabe "Die Katze sitzt auf der Matte", würde die BLEU-Punktzahl hoch sein, weil sich viele Wörter überschneiden.
ROUGE konzentriert sich auf die Wiedererkennung: Es prüft, ob der maschinell erstellte Text alle wichtigen Ideen der menschlichen Referenz erfasst. Nehmen wir an, eine von Menschen geschriebene Zusammenfassung lautet: "Die Studie ergab, dass Menschen, die sich regelmäßig bewegen, einen niedrigeren Blutdruck haben." Wenn die von der KI erstellte Zusammenfassung "Bewegung senkt den Blutdruck" lautet, würde ROUGE ihr eine hohe Punktzahl geben, weil sie den Kern der Sache trifft, auch wenn der Wortlaut anders ist.
Diese Metriken sind nützlich für Aufgaben wie maschinelle ÜbersetzungZusammenfassungen und Texterstellung, da sie eine quantitative Bewertung der Übereinstimmung des Modells mit von Menschen erstellten Referenztexten liefern.
Gewährleistung von Fairness und Abbau von Vorurteilen in LLMs ist entscheidend für gerechte Bewerbungen. Im Folgenden werden die wichtigsten Kriterien für die Bewertung von Voreingenommenheit und Fairness in LLMs vorgestellt.
Die demografische Parität gibt an, ob die Leistung eines Modells über verschiedene demografische Gruppen hinweg konsistent ist. Sie bewertet den Anteil der positiven Ergebnisse in Gruppen, die durch Merkmale wie Ethnie, Geschlecht oder Alter definiert sind.
Das Erreichen der demografischen Parität bedeutet, dass die Vorhersagen des Modells für keine bestimmte Gruppe voreingenommen sind, wodurch Fairness und Gerechtigkeit bei der Anwendung gewährleistet werden.
Die Chancengleichheit konzentriert sich darauf, ob die Fehler des Modells gleichmäßig auf die verschiedenen demografischen Gruppen verteilt sind. Sie bewertet die Falsch-Negativ-Raten für jede Gruppe und bestätigt, dass das Modell bei bestimmten Bevölkerungsgruppen nicht überproportional versagt.
Diese Kennzahl ist entscheidend für Anwendungen, bei denen es auf Fairness und gleichen Zugang ankommt, z. B. bei Einstellungsalgorithmen oder Kreditgenehmigungsverfahren.
Die kontrafaktische Fairness bewertet, ob sich die Vorhersagen eines Modells ändern würden, wenn bestimmte sensible Merkmale anders wären. Dabei werden kontrafaktische Beispiele erstellt, bei denen das sensible Merkmal (z. B. Geschlecht oder Ethnie) verändert wird, während die anderen Merkmale konstant bleiben.
Wenn sich die Vorhersage des Modells aufgrund dieser Änderung ändert, deutet dies auf eine Verzerrung in Bezug auf das sensible Attribut hin. Die kontrafaktische Fairness ist von entscheidender Bedeutung, um Verzerrungen zu erkennen und abzumildern, die durch andere Messgrößen möglicherweise nicht sichtbar werden.
Neben Leistung und Fairness sind weitere Kriterien für eine umfassende Bewertung von LLMs nützlich. Dieser Abschnitt beleuchtet diese Aspekte.
Der flüssige Sprachgebrauch bewertet die Natürlichkeit und grammatikalische Korrektheit des generierten Textes. Ein fließendes LLM erzeugt Ausgaben, die leicht zu lesen und zu verstehen sind und den Fluss der menschlichen Sprache nachahmen.
Dies kann durch automatisierte Tools oder durch menschliches Urteil beurteilt werden, wobei Aspekte wie Grammatik, Syntax und allgemeine Lesbarkeit im Vordergrund stehen.
Kohärenz hilft bei der Analyse des logischen Flusses und der Konsistenz des erzeugten Textes. Ein kohärenter Text zeichnet sich durch eine klare Struktur und eine logische Abfolge von Ideen aus, so dass die Leser/innen ihm leicht folgen können. Kohärenz ist besonders wichtig für längere Texte, wie z. B. Aufsätze oder Artikel, bei denen es darauf ankommt, eine konsistente Erzählung aufrechtzuerhalten.
Die Faktizität bewertet die Richtigkeit der vom LLM bereitgestellten Informationen, insbesondere bei Aufgaben zur Informationssuche. Diese Metrik bestätigt, dass das Modell nicht nur plausible, sondern auch sachlich korrekte Texte erzeugt.
Faktizität ist unverzichtbar für Anwendungen wie die Erstellung von Nachrichten, Bildungsinhalten und Kundensupport, bei denen die Bereitstellung genauer Informationen das Hauptziel ist.

Eine solide Bewertung von LLMs erfordert die Integration von quantitativen und qualitativen Ansätzen. Dieser Abschnitt beschreibt eine Reihe von Methoden, wie z. B. Benchmark-Datensätze, menschliche Bewertungstechniken und automatische Bewertungsmethoden, um die LLM-Leistung gründlich zu bewerten.
Benchmark-Datensätze sind wertvolle Hilfsmittel für die Bewertung von LLMs. Sie bieten standardisierte Aufgaben, die eine vergleichende Analyse verschiedener Modelle ermöglichen. Diese Datensätze helfen dabei, eine Basis für die Modellleistung zu schaffen und erleichtern das Benchmarking.
Benchmark-Datensätze sind wichtige Instrumente für die Bewertung von LLMs. Sie bieten standardisierte Aufgaben, die eine vergleichende Analyse verschiedener Modelle ermöglichen. Zu den beliebtesten Benchmark-Datensätzen für verschiedene Aufgaben der natürlichen Sprachverarbeitung (NLP) gehören:
Während bestehende Benchmarks von unschätzbarem Wert sind, ist die Erstellung eigener Datensätze für eine domänenspezifische Bewertung unerlässlich. Benutzerdefinierte Datensätze ermöglichen es uns, den Bewertungsprozess auf die einzigartigen Anforderungen und Herausforderungen der jeweiligen Anwendung oder Branche zuzuschneiden.
Zum Beispiel kann ein Gesundheitswesen eine Gesundheitseinrichtung einen Datensatz mit medizinischen Aufzeichnungen und klinischen Notizen erstellen, um die Fähigkeit eines LLM zu bewerten, mit medizinischer Terminologie und Kontext umzugehen. Benutzerdefinierte Datensätze stellen sicher, dass die Leistung des Modells mit realen Anwendungsfällen übereinstimmt und somit relevante und umsetzbare Erkenntnisse liefert.
Menschliche Bewertungsmethoden sind unverzichtbar, um die nuancierten Aspekte von LLM-Ergebnissen zu beurteilen, die automatisierte Messverfahren möglicherweise übersehen. Diese Techniken beinhalten direktes Feedback von menschlichen Beurteilern und bieten qualitative Einblicke in die Modellleistung.
Die Bewertung durch Menschen ist nach wie vor der Goldstandard für die Beurteilung der Qualität von LLM-Ergebnissen. Bei den direkten Bewertungsmethoden werden Rückmeldungen von menschlichen Richtern mithilfe von Umfragen und Bewertungsskalen gesammelt.
Diese Methoden können nuancierte Aspekte der Textqualität erfassen, wie z.B. Flüssigkeit, Kohärenz und Relevanz, die von automatischen Metriken möglicherweise übersehen werden. Menschliche Richter können qualitatives Feedback zu bestimmten Stärken und Schwächen geben und dabei helfen, bestimmte Bereiche für Verbesserungen zu identifizieren.
Die vergleichende Beurteilung umfasst Techniken wie den paarweisen Vergleich, bei dem menschliche Bewerter die Ergebnisse verschiedener Modelle direkt vergleichen. Diese Methode kann zuverlässiger sein als absolute Bewertungsskalen, da sie die Subjektivität, die mit individuellen Bewertungen verbunden ist, reduziert.
Die Bewerter werden gebeten, aus den Textpaaren die bessere Ausgabe auszuwählen und so eine relative Rangfolge der Modellleistung zu erstellen. Ein vergleichendes Urteil ist besonders nützlich für Feinabstimmung von Modellen und Auswahl der leistungsstärksten Varianten.
Automatisierte Bewertungsmethoden bieten eine schnelle und objektive Möglichkeit, die LLM-Leistung zu beurteilen. Diese Methoden verwenden verschiedene Metriken, um verschiedene Aspekte der Modellergebnisse zu quantifizieren und eine umfassende Bewertung zu gewährleisten.
Automatisierte Metriken bieten eine schnelle und objektive Möglichkeit, die LLM-Leistung zu bewerten. Metriken wie Perplexität und BLEU werden häufig verwendet, um verschiedene Aspekte der Texterstellung zu bewerten.
Wie bereits erwähnt, misst die Komplexität die Vorhersagekraft des Modells, wobei niedrigere Werte eine bessere Leistung anzeigen. BLEU hingegen bewertet die Qualität des generierten Textes, indem es ihn mit Referenztexten vergleicht und sich dabei auf die Präzision der n-Gramme.
Die adversarische Bewertung beinhaltet LLMs gegnerischen Angriffen zu unterziehen um ihre Robustheit zu testen. Diese Angriffe zielen darauf ab, Schwächen und Verzerrungen des Modells auszunutzen und Schwachstellen aufzudecken, die mit den üblichen Bewertungsmethoden nicht erkennbar sind.
Ein feindlicher Angriff könnte darin bestehen, leicht veränderte oder irreführende Daten einzugeben, um zu analysieren, wie das Modell reagiert. Dieser Ansatz ist nützlich für Anwendungen, bei denen Zuverlässigkeit und Sicherheit einen hohen Stellenwert haben, da er hilft, potenzielle Risiken zu erkennen und zu mindern.

Um die Fähigkeiten von LLMs effektiv zu bewerten, sollte ein strategischer Ansatz verfolgt werden. Die Übernahme von Best Practices stellt sicher, dass dein Evaluierungsprozess gründlich, transparent und auf deine individuellen Anforderungen zugeschnitten ist. Hier stellen wir die besten Praktiken vor, die du beachten solltest.
|
Best Practice |
Beschreibung |
Beispielfall |
Relevante Metrik(en) |
|
Klare Ziele definieren |
Bestimme die Aufgaben und Ziele, die das LLM erreichen soll, bevor du mit dem Evaluierungsprozess beginnst. |
Verbesserung der maschinellen Übersetzungsleistung eines LLM |
BLEU/ROUGE-Werte |
|
Bedenke dein Publikum |
Schneide die Bewertung auf die beabsichtigten Nutzer/innen des LLM zu und berücksichtige ihre Erwartungen und Bedürfnisse. |
LLM für die Texterstellung |
Verwirrtheit, Geläufigkeit, Kohärenz |
|
Transparenz und Reproduzierbarkeit |
Stelle sicher, dass der Bewertungsprozess gut dokumentiert ist und von anderen zur Überprüfung und Verbesserung nachgeahmt werden kann. |
Die Veröffentlichung der Evaluierungsdaten und des Codes, die zur Bewertung der Fähigkeiten des LLM verwendet wurden |
Jede relevante Kennzahl, abhängig von der spezifischen Aufgabe und den Zielen der Evaluierung |
Dieser Leitfaden bietet einen umfassenden Überblick über die wichtigsten Messgrößen und Methoden zur Bewertung von LLMs, von Perplexität und Genauigkeit bis hin zu Verzerrungs- und Fairnessmaßnahmen.
Durch den Einsatz von quantitativen und qualitativen Bewertungsmethoden und die Einhaltung von Best Practices können wir eine gründliche und zuverlässige Bewertung dieser Modelle sicherstellen.
Mit diesem Wissen sind wir besser in der Lage, LLMs auszuwählen und zu implementieren, die unsere Bedürfnisse am besten erfüllen und die optimale Leistung und Zuverlässigkeit in den von uns gewählten Anwendungen gewährleisten.
Top KI-Kurse
Lernpfad
Kurs
Kurs