
Track
Developing AI Applications
21 hr
I have tried OpenAI's new model distillation tool—it requires minimal coding and enables us to manage the entire distillation process within a single platform, from generating datasets to fine-tuning models and evaluating their performance.
In this tutorial, I'll help you get started with OpenAI's model distillation tool. First, we'll cover the basics of model distillation, and then we'll do a demo distillation project using OpenAI's API.
Imagine a skilled, well-educated teacher teaching their thinking process and knowledge to a student. This is the basics of how model distillation works.
In this technique, the teacher is a large pre-trained model, and the student is a smaller model that learns to replicate the teacher’s output. This allows the student to perform specific tasks at a level comparable to the teacher's, only with fewer resources required.
Model distillation comes in many forms, each with its own methods and goals. In one case, we need the student to only mimic the outputs of a larger model. In another case, we want to instill the teacher’s problem-solving approach into the smaller model. Ultimately, the goal is to benefit from a large model’s capabilities, using an efficient model.
One common method for transferring knowledge from a "teacher" model to a "student" model is fine-tuning the student on a dataset consisting of inputs and their corresponding outputs generated by the teacher.
During this supervised learning process, the student model learns to replicate the teacher's responses when presented with similar inputs.
The distillation process comes with many advantages:
To learn more about distillation, you can read this article: LLM Distillation Explained.
In this section, we will explore an example of model distillation utilizing the OpenAI platform. Our primary focus will be on generating Git commands for a user’s request.
We will first create a dataset of OpenAI’s small GPT-4o mini (student) and evaluate the outputs.
Next, we use GPT-4o (teacher) to translate the same sentences and fine-tune the student model on the dataset produced by the teacher.
Finally, we need to evaluate the student model and assess the improvement.
In summary, here are the steps that we’re going to take:
The first step of model distillation is to select the teacher and the student, which is determined by the intended task and your computational budget.
When working with open source models, there are a variety of LLMs with different capabilities and sizes. With OpenAI’s platform, the options are limited.

For the purpose of our example, we will select GPT-4o mini as the smaller student model and GPT-4o as the teacher model.
GPT-4o-mini is a relatively small model and a good candidate for the student role. GPT-4o is relatively larger but much more capable and can work as an efficient teacher for the student.
Other options exist, and changing the models would require minimum effort in our model distillation project.
Your dataset for this task must be challenging enough for the student model but not as challenging for the teacher. The qualities of a good dataset, such as diversity, representativeness, or accuracy, are still relevant in model distillation.
Having a dataset large enough to impact the student model is very important. There is no straight answer to “How large should the distillation dataset be?” as it depends on the complexity of your target task and the models you selected as teacher and student.
As per OpenAI's documentation, while a few hundred samples could be enough, a more diverse group of thousands of samples can sometimes lead to improved outcomes.
Our dataset in this article is composed of 386 user requests stored in a JSON file (you could store them in the form of a Python list just as well).
{
"requests": [
"Initialize a new Git repository in the current directory.",
"Clone the repository from GitHub to my local machine.",
"Create a new branch called 'feature-login'.",
...
"Show the differences between the working directory and the staging area.",
"Stage all modified and deleted files for commit.",
]
}Our dataset currently consists of inputs only, and we should generate outputs as well. The outputs of the student are not necessary for the distillation, but we need them to get a baseline for the student model’s accuracy (step 4).
We use the code below to iterate over the inputs dataset and generate an output for each:
def generate_responses():
with open(JSON_PATH, 'r') as file:
user_messages = json.load(file)
for sentence in user_messages['requests']:
# Call the OpenAI model gpt-4o-mini and store the response
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": sentence
},
],
store=True,
metadata={
"task": "git"
}
)
generate_responses()Note that we use store=True while calling the OpenAI model. This argument will save the input/output pairs in our OpenAI dashboard, so we won’t need to store the outputs using code.
To later identify and filter out these chat completions, don’t forget to include metadata while calling the client.chat.completions.create function. The arguments for this metadata are arbitrary.
The generated outputs can be found on the Chat Completions section of our OpenAI dashboard.
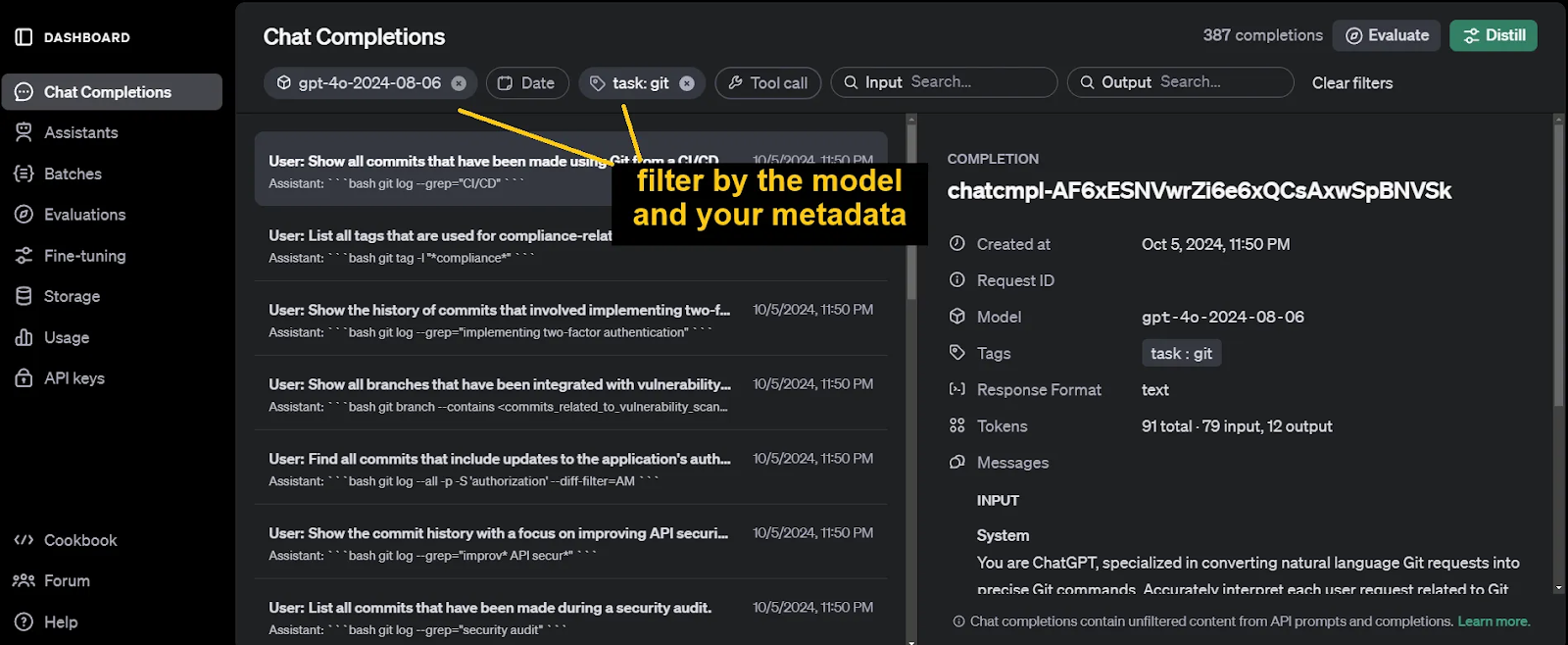
Another tool by OpenAI that comes in handy for model distillation is their Evaluations tool. We use this tool to assess the performance of the student model before training as a baseline metric. We will also use it later on when evaluating the fine-tuned student model.
After filtering out the chat completions of the previous step, click on the Evaluate button. We now need to add testing criteria.
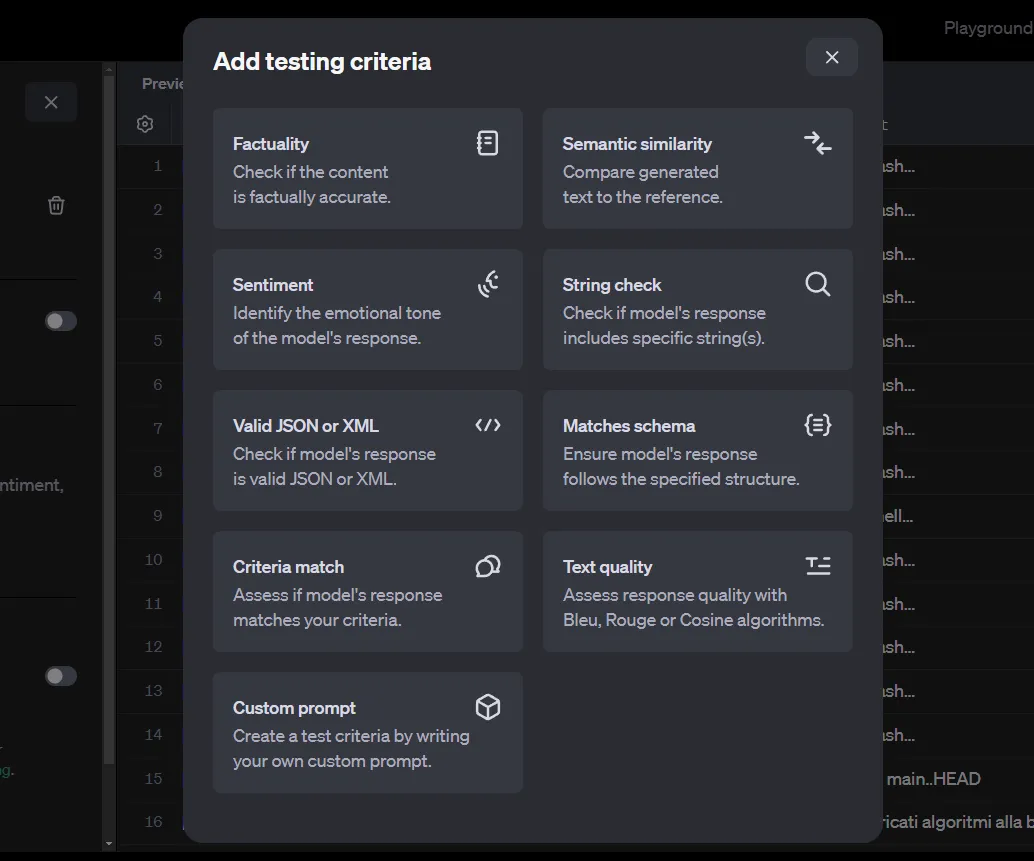
There is a variety of methods to evaluate the input/output pairs. Note that our current dataset is generated automatically by OpenAI’s chat completions and only contains the inputs and outputs. However, some of these criteria also require a reference to compare against.
This reference could be the outputs generated by a more sophisticated model, such as GPT-4o or o1-preview. Since automatically storing the chats to OpenAI doesn’t allow us to provide such a reference, we are limited to using the Criteria match or the Custom prompt methods, which only need an input and an output.
If you need to use other methods, you cannot use OpenAI’s chat completions and must create your JSON file with code. This is not complicated, but we won’t get into it in this article.
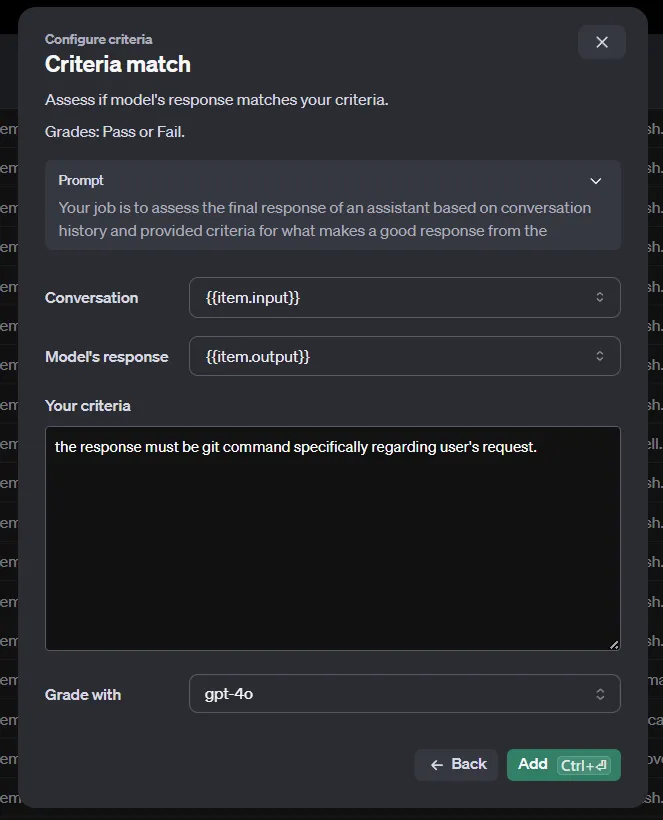
Once you run the evaluations, you will receive your results shortly.
To fine-tune the student model, we need a high-quality dataset generated by the teacher. This step is almost the same as step 3—you only need to change the model argument from gpt-4o-mini, to gpt-4o.
Again, in the Chat Completions, filter out by the teacher model and the metadata. Next, select the Distill button. OpenAI’s distill is essentially the fine-tuning tool.
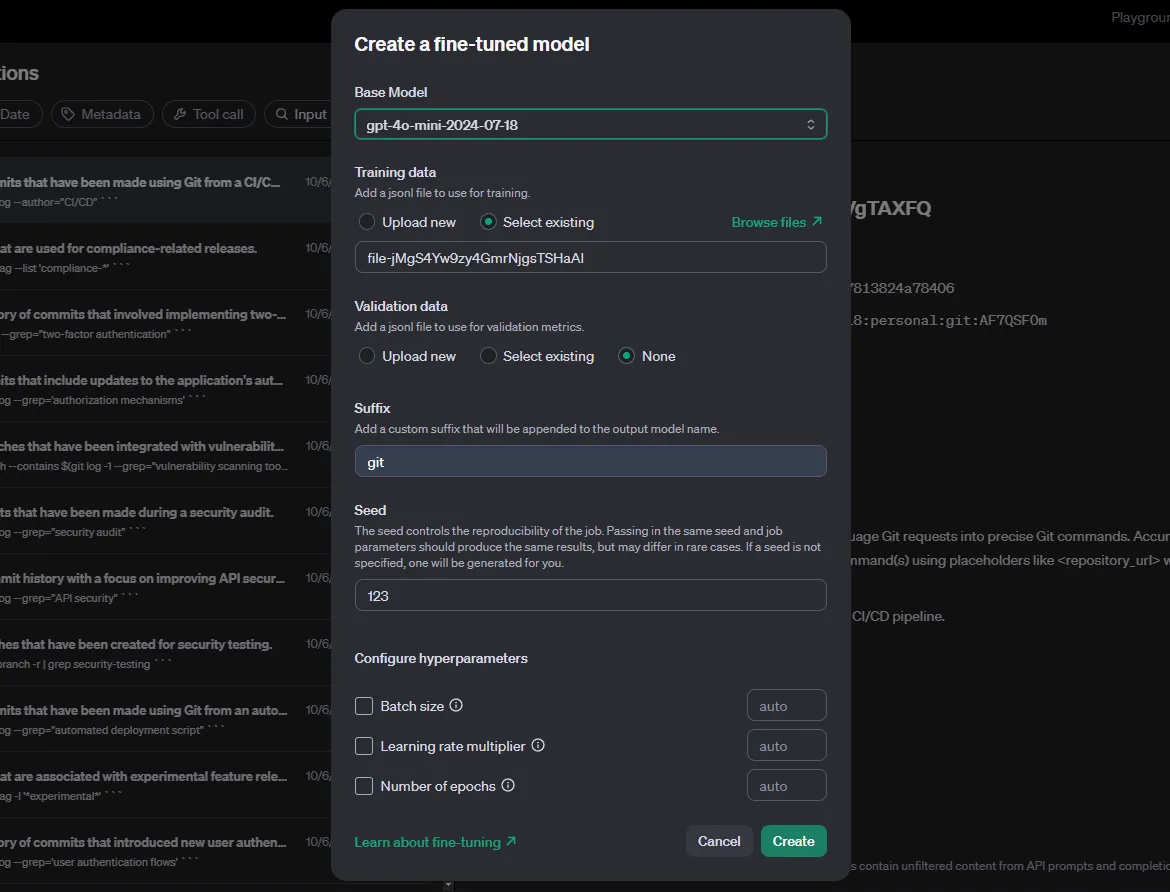
For the base model, we select the student. The hyperparameters need to be experimented with and tested to achieve the best results—set to auto. Finally, select Create and wait for the fine-tuning to finish.
Once finished, we will use the code from step 3 again, this time using the fine-tuned model as the model argument. The name of the fine-tuned model is displayed as the “Output model” on your fine-tuning page.
def generate_responses():
with open(JSON_PATH, 'r') as file:
user_messages = json.load(file)
for sentence in user_messages['requests']:
# Call the OpenAI model gpt-4o-mini and store the response
response = client.chat.completions.create(
model="ft:gpt-4o-mini-2024-07-18:personal:git:AF7QSF0m",
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": sentence
},
],
store=True,
metadata={
"task": "git"
}
)
generate_responses()After finishing off with generating outputs, use the evaluations to assess the capability of your new model on the inputs.
OpenAI’s recipe for distillation is simple but straightforward. It’s especially helpful since you won’t need to worry about fine-tuning the models yourself or using code to evaluate the results.
OpenAI’s models, even the smaller ones, are already pretty sophisticated. Make sure to experiment with the hyperparameters before fine-tuning the model, prepare adequate and challenging prompts for both teacher and student, and compare the fine-tuned evaluation with the baseline evaluation.
Before getting hands-on with your own model distillation, I advise you to read these two OpenAI resources: OpenAI Model Distillation in the API and Model Distillation Document.
Learn to build AI applications!
Track
Track
Course
blog
Stanislav Karzhev
12 min
blog
Alex Olteanu
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Josep Ferrer
Tutorial
Moez Ali
code-along
Richie Cotton

