
Kurs
Agentische Systeme mit LangChain entwerfen
3 Std.
12.2K
Wenn du OpenClaw mit einem lokalen Ollama-Modell nutzt, wird dein System zu einer eigenständigen KI-Umgebung. Anstatt Befehle und Daten an externe APIs zu schicken, läuft der ganze Arbeitsablauf, einschließlich der Argumentation, des Dateizugriffs und der Artefaktgenerierung, auf deinem Rechner.
Diese Konfiguration hat ein paar praktische Vorteile:
Dieses Tutorial dreht sich um den Aufbau einer lokalen Agentenarchitektur, bei der OpenClaw als Ausführungs-Engine fungiert und Ollama die Argumentationsschicht bereitstellt.
In diesem Abschnitt erstellen wir eine Local Data Analyst-Anwendung, die komplett auf deinem Rechner mit OpenClaw und einem lokalen Ollama-Modell läuft. Auf hoher Ebene macht das System drei wichtige Sachen:
Das System macht drei verschiedene Ausgabeartefakte:
trend_chart.pnganalysis_report.mdtool_trace.jsonHinter den Kulissen wird der Ablauf von drei Sachen koordiniert:
web_assistant.py): Diese Python-Datei kümmert sich um Datei-Uploads, erstellt ein Ausführungsverzeichnis und schickt einen Slash-Befehl an OpenClaw.main.py): Diese Datei liest den Datensatz, findet die relevanten Spalten, erstellt Diagramme und Erkenntnisse und speichert alles auf der Festplatte.Sobald der Workflow fertig ist, zeigt die Webschnittstelle eine Vorschau der erstellten Artefakte an, sodass du die Ergebnisse und den Ausführungspfad anschauen kannst.
Bevor wir den Local Data Analyst-Workflow erstellen, muss OpenClaw Gateway auf deinem Rechner laufen. Stell dir OpenClaw als die Ausführungsebene in diesem Projekt vor, die Anfragen von der Web-Benutzeroberfläche bekommt, die Workspace-Fähigkeit lädt, lokale Tools (wie Shell-Befehle und Python-Skripte) ausführt und den gesamten Workflow von Anfang bis Ende koordiniert.
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemonDieser Befehl installiert die OpenClaw-CLI, startet den Onboarding-Assistenten, um die lokale Umgebung einzurichten, und richtet den Gateway-Daemon so ein, dass er einfach gestartet und gestoppt werden kann. Auch wenn wir das Gateway für diese Demo im Vordergrund laufen lassen, sorgt die Installation des Daemons für eine Standardkonfiguration und macht die Fehlerbehebung einfacher.
Jetzt checken wir mal, ob alles läuft:
openclaw doctor
openclaw gateway statusDie Datei „ OpenClaw doctor ” zeigt, dass OpenClaw richtig installiert ist. Der Befehl „ OpenClaw gateway status “ zeigt dir, ob das Gateway gerade läuft. Im Moment kann es sein, dass „läuft nicht“ angezeigt wird, aber das ist okay. Das Wichtigste ist, dass der Befehl funktioniert und die Installation erkannt wird.
Wenn du eine detaillierte Anleitung zu allen Onboarding-Optionen (Kanäle, Authentifizierung, Fähigkeiten, Gateway-Sicherheit) brauchst, kannst du dir das OpenClaw-Tutorial ansehen, das dir Schritt für Schritt zeigt, wie du alles einrichtest.
Als Nächstes richten wir Ollama ein, das als lokales LLM-Backend für dieses Projekt dienen wird. OpenClaw wird weiterhin den Arbeitsablauf organisieren, aber wenn es Modellintelligenz für Zusammenfassungen oder Schlussfolgerungen braucht, wird es LLMs über Ollama aufrufen.
Mach mal die folgenden Befehle:
brew install ollama
ollama serve
ollama pull qwen3:8bDie oben genannten Befehle installieren die Ollama-Laufzeitumgebung, starten den lokalen Modellserver, mit dem OpenClaw kommunizieren wird, und laden das Modell „ qwen3:8b ” herunter. Wir nehmen qwen3:8b, weil es für die meisten Laptops ein gutes Gleichgewicht zwischen Leistung und Qualität bietet, aber du kannst auch ein anderes Modell wählen, je nachdem, was dein System hergibt. Du kannst auch diese Einrichtungsanleitung von Ollama checken.
Als Nächstes müssen wir OpenClaw so einrichten, dass es die lokale Ollama-Instanz nutzt. So wird sichergestellt, dass alle Überlegungen, Zusammenfassungen und Analysen komplett auf deinem Rechner laufen, ohne dass externe API-Aufrufe nötig sind.
Mach ein lokales Konfigurationsverzeichnis:
mkdir -p .openclaw-localDann mach die Datei:
.openclaw-local/openclaw.json
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama-local",
"api": "openai-completions",
"models": [
{
"id": "qwen3:8b",
"name": "qwen3:8b",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 131072,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "ollama/qwen3:8b" }
}
},
"tools": {
"web": {
"search": { "enabled": false },
"fetch": { "enabled": true }
}
}
}Die obige Konfiguration hat drei wichtige Teile:
baseUrl “ zeigt auf den lokalen API-Endpunkt, der von „ ollama serve “ bereitgestellt wird, während die Einstellung „ api: openai-completions “ die OpenAI-kompatible Kommunikation aktiviert. Die Modellregistrierung für qwen3:8b zeigt, was es kann, zum Beispiel ein großes 131K-Kontextfenster für große Datensätze und ein Token-Limit für kontrollierte Antworten. Weil das Modell lokal läuft, sind alle Kostenwerte auf Null gesetzt.agent defaults “ legt fest, welches Modell die OpenClaw-Agenten für ihre Schlussfolgerungen verwenden. Wenn du das Hauptmodell auf „ ollama/qwen3:8b “ stellst, werden alle Aufgaben der Agenten, wie zum Beispiel das Interpretieren von Eingabeaufforderungen, das Erstellen von Zusammenfassungen oder das Schlussfolgern über Daten, automatisch an das lokale Ollama-Modell weitergeleitet, ohne dass externe API-Aufrufe nötig sind.Zusammen sorgen diese Einstellungen dafür, dass der ganze Arbeitsablauf privat auf deinem Rechner läuft, wobei OpenClaw die Koordination übernimmt und Ollama die lokale Intelligenz bereitstellt.
In diesem Schritt legen wir die Arbeitsbereichsfähigkeit fest, die OpenClaw sagt, wie es unseren Arbeitsablauf ausführen soll. Anstatt uns bei der Planung der Tool-Nutzung auf das Modell zu verlassen, nutzen wir den Befehlsversandmodus, mit dem ein Slash-Befehl direkt einen lokalen Ausführungsbefehl auslösen kann, was den Arbeitsablauf schneller und komplett lokal macht.
Lass uns dieDatei „ SKILL.md “in deinem Arbeitsbereich erstellen:
---
name: local-data-analyst
description: Local Data Analyst: analyze private local data with Ollama, generate chart/report, and keep all data on-device.
user-invocable: true
command-dispatch: tool
command-tool: exec
command-arg-mode: raw
---
Invoke as /local-data-analyst <raw command>.
This skill bypasses model planning and dispatches raw command text directly to the exec tool.
Use this exact command template in this workspace:
python3 /……/main.py --docs-dir <context_dir> --data-file <data_file> --output-dir <output_dir> --prompt "<prompt>" --use-ollama --model qwen3:8b
Expected outputs under <output_dir>:
- trend_chart.png
- analysis_report.md
- tool_trace.jsonDiese Skill-Konfiguration bestimmt, wie OpenClaw die Analyse durchführt:
local-data-analyst ”, die als Slash-Befehl „ /local-data-analyst ” verfügbar ist.command-dispatch: tool “ aktiviert den Befehlsversandmodus, bei dem OpenClaw den Befehl direkt an ein Tool weiterleitet, anstatt das Modell zu fragen, was zu tun ist.command-arg-mode: raw “ wird die ganze Befehlszeichenfolge unverändert an das Tool „ exec “ weitergegeben, was eine vorhersehbare Ausführung sicherstellt.main.py “, das:Ollama (qwen3:8b) “ für Argumentationen und ZusammenfassungenAlso, OpenClaw kümmert sich um die Koordination und Ausführung, während Ollama für die lokale Entscheidungsfindung zuständig ist. Als Nächstes verbinden wir diese Funktion mit einer Webschnittstelle, damit Leute Daten hochladen und die Analyse mit einem einzigen Klick starten können.
Im Moment haben wir schon zwei Kernkomponenten, die an einer OpenClaw-Workspace-Fähigkeit und einem lokalen Modell-Backend (Ollama) arbeiten, das für die Schlussfolgerungen zuständig ist. Jetzt brauchen wir eine einfache Schnittstelle, mit der du Dateien hochladen und Ausführungen starten kannst, ohne jedes Mal das Terminal zu benutzen.
Die Datei „ web_assistant.py ” ist ein schlanker Frontend-Server, der:
Die wichtigste Designentscheidung hier ist, dass der Webserver die Analyselogik nie selbst ausführt. Es übergibt alles an OpenClaw, sodass die Benutzeroberfläche einfach bleibt.
Das Ziel ist, eine einzige Zeichenfolge zu erstellen, die OpenClaw als Chat-Nachricht empfangen kann, zum Beispiel: /local-data-analyst python3 ... --data-file ... --output-dir …
def build_slash_command(
data_path: Path,
docs_dir: Path,
output_dir: Path,
prompt: str,
model: str,
x_col: str,
y_col: str,
) -> str:
args = [
"python3",
str(BASE_DIR / "src" / "main.py"),
"--docs-dir", str(docs_dir),
"--data-file", str(data_path),
"--output-dir", str(output_dir),
"--prompt", prompt,
"--use-ollama",
"--model", model,
]
if x_col:
args.extend(["--x-column", x_col])
if y_col:
args.extend(["--y-column", y_col])
raw = " ".join(shlex.quote(a) for a in args)
return f"/local-data-analyst {raw}"Die Funktion „ build_slash_command() ” macht die genaue Anweisung fertig, die an OpenClaw geschickt wird. Anstatt die Analyse direkt durchzuführen, erstellt die Web-App einen strukturierten Slash-Befehl, den OpenClaw an die passende Workspace-Funktion weiterleiten kann. Diese Funktion macht vier wichtige Sachen:
args “ zeigt, wie man die CLI-Funktion „ src/main.py “ aufruft. Das ist derselbe Befehl, den du auch manuell über das Terminal ausführen könntest.--x-column “ und „ --y-column “ werden nur angehängt, wenn sie angegeben werden. Wenn diese Werte fehlen, kann das Analyseskript die Spalten automatisch aus dem Datensatz ermitteln.shlex.quote() “ lässt alle Argumente, einschließlich der Benutzeraufforderung, unverändert. Das ist super wichtig für die Verarbeitung von Leerzeichen und Sonderzeichen und verhindert, dass Befehlsinjektionsrisiken entstehen, wenn Benutzereingaben an einen shell-Befehl weitergeleitet werden.Die Funktion gibt eine Zeichenfolge zurück, die mit „ /local-data-analyst “ anfängt. Dieses Präfix passt zu dem Fertigkeitsnamen, der in „ SKILL.md “ definiert ist. Wenn OpenClaw diesen Slash-Befehl bekommt, leitet es die Anfrage sofort an die Workspace-Funktion „ local-data-analyst ” weiter, die dann den Befehl mit dem Tool „ exec ” ausführt.
Jetzt, wo wir den Slash-Befehl haben, schicken wir ihn über den CLI-Agent-Runner an OpenClaw. Hier gibt die Web-App die Ausführung ab.
slash_message = build_slash_command(
data_path=data_path,
docs_dir=docs_dir,
output_dir=output_dir,
prompt=prompt,
model=model,
x_col=x_col,
y_col=y_col,
)
agent_cmd = [
"openclaw", "agent",
"--local",
"--session-id", f"stealth-web-{run_id}",
"--message", slash_message,
"--timeout", "120",
]
proc = subprocess.run(agent_cmd, capture_output=True,
text=True, env=openclaw_env())Der Aufruf des OpenClaw-Agenten ist der Punkt, an dem die Web-App aufhört zu arbeiten und stattdessen OpenClaw bittet, den Workflow komplett durchzuführen.
--local “ stellst du sicher, dass der Lauf auf deinem Rechner bleibt und der Agent die Anfrage über dein lokales Gateway und das Ollama-gestützte Modell verarbeitet, statt über einen gehosteten Dienst.--session-id stealth-web-{run_id} “ gibt jedem Lauf seinen eigenen isolierten Sitzungsnamensraum, was verhindert, dass der Status zwischen den Läufen übergeht, und das spätere Debuggen einer bestimmten Ausführung vereinfacht. --message ” gibt den Slash-Befehl genau so weiter, wie wenn ein Nutzer ihn im Chat eingeben würde. OpenClaw nimmt ihn entgegen, leitet ihn an die Funktion „ /local-data-analyst ” weiter und führt den zugrunde liegenden Befehl über das Tool „ exec ” aus. --timeout 120 “ als Sicherheitsventil, damit die Web-Benutzeroberfläche nicht ewig hängt, wenn die Analyse ins Stocken gerät, und „ env=openclaw_env() “ zwingt den Unterprozess, deine projektlokale OpenClaw-Konfiguration und dein Statusverzeichnis zu verwenden, damit er konsequent auf die beabsichtigte Ollama-Konfiguration abzielt.Als Nächstes laden wir die erstellten Artefakte, wie Diagramme, Berichte und Tool-Traces, und zeigen im Browser einfache Vorschauen an.
Schließlich läuft „ web_assistant.py “ auf einem kleinen lokalen HTTP-Server, sodass du über den Browser interagieren kannst.
def main() -> int:
host = "127.0.0.1"
port = 8765
server = ThreadingHTTPServer((host, port), Handler)
print(f"Local Data Analyst web UI: http://{host}:{port}")
print("Press Ctrl+C to stop.")
try:
server.serve_forever()
except KeyboardInterrupt:
pass
return 0Das macht die Bereitstellung einfach:
ThreadingHTTPServer ermöglicht mehrere Anfragen, ohne die ganze App zu blockieren.Handler, der Uploads annimmt, Run-Ordner erstellt, OpenClaw startet und Vorschauen zurücksendet.Anmerkung: Die komplette Code-Implementierung von „ web_assistant.py “ findest du im GitHub-Repo des Projekts.
Im Moment kann OpenClaw den Workflow schon über die Workspace-Funktion ausführen, und die Web-Benutzeroberfläche kann Läufe über einen Slash-Befehl starten. Der letzte Teil ist die Analyse-Engine, die deine hochgeladenen Dateien nimmt, die Workflow-Schritte durchführt und die Artefakte erstellt.
Die Datei „ main.py ” in diesem Repo dreht sich um zwei Funktionen, die das Herzstück der Pipeline bilden, nämlich das Laden von Tabellendaten und den Aufruf von Ollama für lokale Schlussfolgerungen.
Dieser Helfer kann mit mehreren Eingabeformaten umgehen und sorgt trotzdem dafür, dass der Arbeitsablauf gleich bleibt.
def load_tabular_data(data_path: Path, events: List[SkillEvent]) -> pd.DataFrame:
ext = data_path.suffix.lower()
if ext == ".csv":
df = pd.read_csv(data_path)
elif ext in {".tsv", ".tab"}:
df = pd.read_csv(data_path, sep="\t")
elif ext in {".json", ".jsonl"}:
try:
df = pd.read_json(data_path)
except ValueError:
df = pd.read_json(data_path, lines=True)
elif ext in {".xlsx", ".xls"}:
df = pd.read_excel(data_path)
else:
raise ValueError(f"Unsupported data file...")
log_event(events, "fs", "read", f"Loaded data file: {data_path.name}")
return dfDie Funktion „ load_tabular_data() ” erkennt den Dateityp mit „ data_path.suffix ” und leitet ihn an den richtigen Pandas-Loader weiter. CSV- und TSV-Dateien werden mit read_csv() verarbeitet, wobei bei TSV-/Tab-Dateien einfach das Trennzeichen auf \t geändert wird. JSON -Eingaben werden zuerst mit read_json() verarbeitet, und wenn pandas einen ValueError auslöst, wird auf lines=True für JSONL zurückgegriffen. Excel -Unterstützung wird über read_excel() hinzugefügt, sodass Benutzer .xlsx -Dateien ohne Vorverarbeitung hochladen können.
Schließlich speichert der Aufruf „ log_event() “ einen strukturierten Trace-Eintrag, den die Pipeline später in „ tool_trace.json “ umwandeln kann.
Da diese Demo kein SDK braucht, ruft sie direkt die lokale HTTP-API von Ollama auf.
def ollama_generate(model: str, prompt: str) -> str:
url = "http://localhost:11434/api/generate"
payload = json.dumps({
"model": model,
"prompt": prompt,
"stream": False
}).encode("utf-8")
req = request.Request(url, data=payload,
headers={"Content-Type": "application/json"})
with request.urlopen(req, timeout=45) as resp:
body = json.loads(resp.read().decode("utf-8"))
return str(body.get("response", "")).strip()Die Funktion „ ollama_generate() ” schickt eine JSON-Nutzlast an Ollamas Endpunkt „ /api/generate ” auf localhost. Die Nutzlast gibt den Modellnamen an (zum Beispiel qwen3:8b), die abschließende Eingabeaufforderungszeichenfolge und deaktiviert das Streaming, sodass die Funktion eine einzige vollständige Antwort zurückgibt.
Mit „ urllib.request ” bleibt dieser Wrapper leicht und portabel, und der „ timeout=45 ”-Schutz verhindert, dass unser Workflow endlos hängt, wenn das Modell langsam ist oder der Server ausfällt. Schließlich holt die Funktion die Modellausgabe aus dem Feld „ response “ und gibt sauberen Text zurück, der später zum Schreiben der Datei „ analysis_report.md “ verwendet wird.
Hier ist ein kleines Startskript, um die lokale Web-Benutzeroberfläche zu starten, die Uploads annimmt und OpenClaw im Hintergrund auslöst.
set -euo pipefail
ROOT="$(cd "$(dirname "$0")" && pwd)"
cd "$ROOT/.."
python3 ../web_assistant.pyDieses Skript macht drei Sachen:
set -euo pipefail sorgt dafür, dass das Skript schnell fehlschlägt, d. h. es stoppt bei Fehlern, sieht nicht gesetzte Variablen als Fehler und vermeidet stille Fehler in Pipelines.ROOT=... Löst das Verzeichnis auf, in dem sich das Skript befindet, sodass es auch dann funktioniert, wenn du es von einem anderen Ort aus ausführst.cd "$ROOT/.." Wechselt in das erwartete Projektverzeichnis und startet dann web_assistant.py, das die Benutzeroberfläche hostet und die komplette Pipeline verwaltet.Sobald dieses Skript läuft, wird die Benutzeroberfläche deines Browsers zum Einstieg in die Demo.
Als letzten Schritt lassen wir das System mit zwei Prozessen laufen. Das OpenClaw-Gateway kümmert sich um die Ausführung aller Aufgaben, während die Webschnittstelle als Benutzerebene zum Senden von Anfragen und zum Anzeigen der generierten Ergebnisse dient.
Bevor wir die Schnittstelle starten, machen wir erst mal das OpenClaw-Gateway an. Dieser Prozess ist die Ausführungsschicht des Systems. Er kümmert sich um die Anfragen der Agenten, lädt die Arbeitsbereichsfähigkeiten, ruft lokale Tools auf und leitet Schlussfolgerungsaufrufe an das Ollama-Modell weiter.
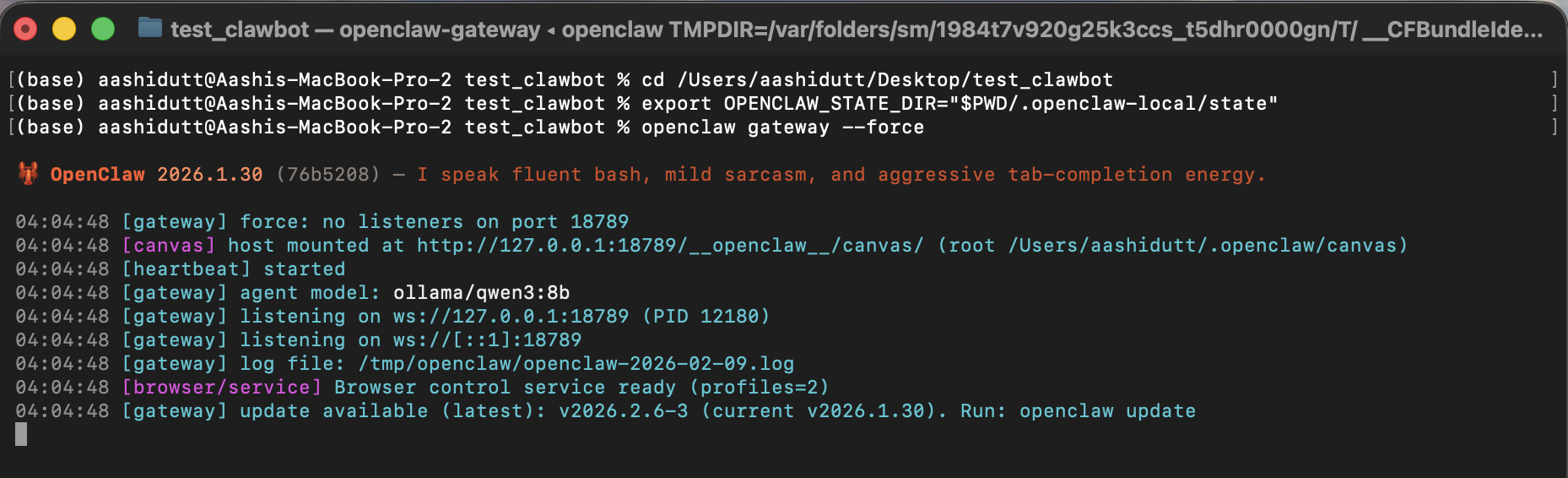
export OPENCLAW_CONFIG_PATH="$PWD/.openclaw-local/openclaw.json"
openclaw gateway --forceIn diesem Terminal zeigt OPENCLAW_CONFIG_PATH OpenClaw die projektlokale Konfiguration, wo wir das Standardmodell auf ollama/qwen3:8b festgelegt und die Websuche aus Datenschutzgründen deaktiviert haben. Als Nächstes startet „ openclaw gateway --force “ das Gateway, auch wenn OpenClaw denkt, dass schon was läuft oder teilweise konfiguriert ist.
Wenn das Gateway läuft, kann es lokale Agentennachrichten empfangen (einschließlich unseres Slash-Befehls „ /local-data-analyst “).
Sobald das Gateway läuft, starten wir die Webschnittstelle, die Benutzereingaben sammelt, jede Anfrage an den lokalen OpenClaw-Agenten schickt und die erstellten Diagramme, Berichte und Ausführungsspuren anzeigt.
./local_data_analyst/run_web.sh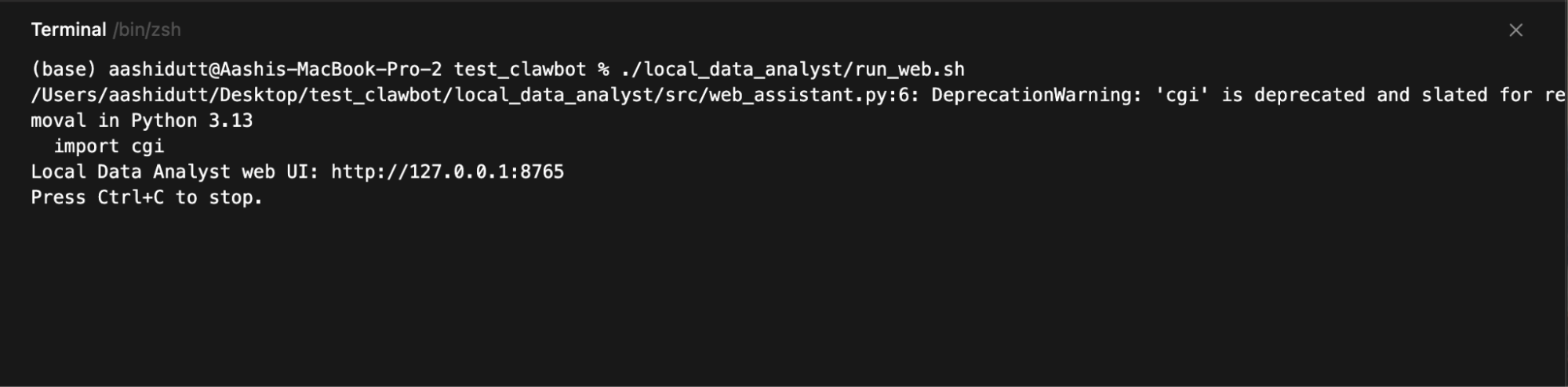
Dann öffne:
http://127.0.0.1:8765Der Webserver läuft auf 127.0.0.1, du kannst also nur von deinem Rechner aus drauf zugreifen. Wenn du auf „Analyse ausführen“ klickst, erstellt die Benutzeroberfläche einen Ausführungsordner, baut den Slash-Befehl auf, ruft „ openclaw agent --local “ auf und fragt dann die Festplatte nach den Ausgabedateien ab, um eine Vorschau anzuzeigen:
trend_chart.pnganalysis_report.mdtool_trace.jsonDas Endergebnis wird ungefähr so aussehen. Du kannst diese Demo mit ein paar Beispieldateien.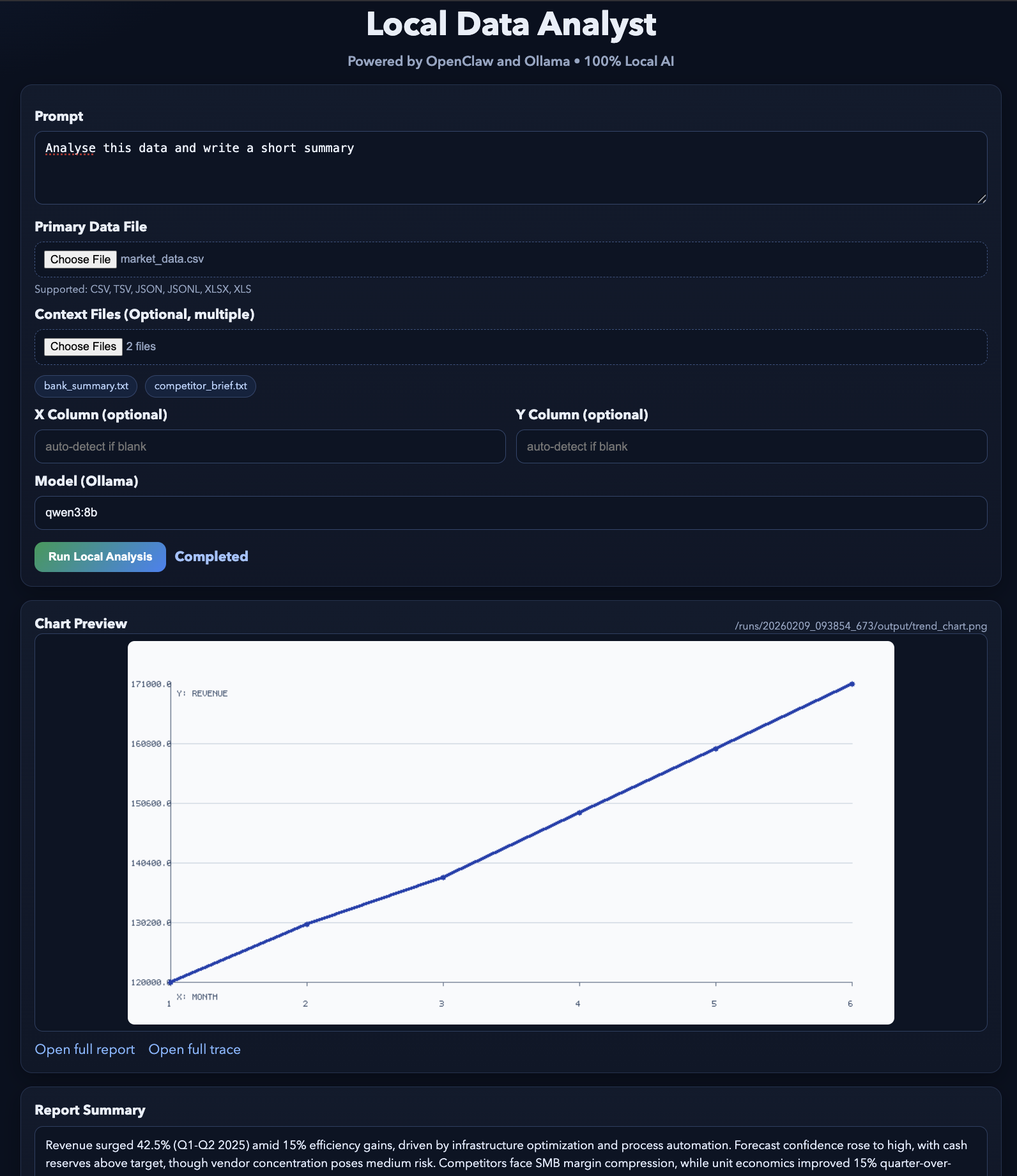
In diesem Tutorial haben wir eine lokal ausgerichtete KI-Anwendung erstellt, bei der eine einfache Webschnittstelle einen kompletten Agenten-Workflow auslöst, der von OpenClaw und einem lokalen Ollama-Modell unterstützt wird. Anstatt externe APIs aufzurufen, läuft die ganze Schleife auf deinem Rechner.
OpenClaw kümmert sich um die Koordination und die Ausführung der Tools, während Ollama die lokale Intelligenzschicht bereitstellt. Das Ergebnis ist ein agentenähnlicher Arbeitsablauf, bei dem eine einzige Anfrage strukturierte Artefakte wie Visualisierungen, Berichte und Prüfpfade erzeugt.
Von hier aus kannst du dieses Projekt in verschiedene Richtungen weiterentwickeln. Du kannst neue Arbeitsbereichsfunktionen für verschiedene Arbeitsabläufe hinzufügen, zusätzliche lokale Tools (z. B. Datenbankabfragen oder Dokumentensuche) integrieren oder OpenClaw mit Messaging-Kanälen wie Slack oder WhatsApp verbinden, um einen sicheren Fernzugriff zu ermöglichen.
Du kannst auch mit verschiedenen Ollama-Modellen rumprobieren, um Leistung und Qualität je nach deiner Hardware auszugleichen.
Um mehr über die Arbeit mit KI in deinen Arbeitsabläufen zu erfahren, empfehle ich dir den Kurs Kurs „KI-gestütztes Programmieren für Entwickler”.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui

