
Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.2K
L'exécution d'OpenClaw avec un modèle Ollama local transforme votre système en un environnement d'IA autonome. Au lieu d'envoyer des invites et des données à des API externes, l'ensemble du flux de travail, y compris le raisonnement, l'accès aux fichiers et la génération d'artefacts, s'exécute sur votre machine.
Cette configuration offre plusieurs avantages pratiques :
Ce tutoriel se concentre sur la création d'une architecture d'agent local, dans laquelle OpenClaw agit comme moteur d'exécution et Ollama fournit la couche de raisonnement.
Dans cette section, nous allons créer une application Local Data Analyst qui s'exécute entièrement sur votre machine à l'aide d'OpenClaw et d'un modèle Ollama local. À un niveau élevé, le système remplit trois tâches principales :
Le système génère trois artefacts de sortie :
trend_chart.pnganalysis_report.mdtool_trace.jsonEn arrière-plan, le flux de travail est coordonné par trois composants :
web_assistant.py) : Ce fichier Python gère les téléchargements de fichiers, crée un répertoire d'exécution et envoie une commande slash à OpenClaw.main.py) : Ce fichier lit l'ensemble de données, détermine les colonnes pertinentes, génère des graphiques et des informations, puis enregistre tous les résultats sur le disque.Une fois le flux de travail terminé, l'interface Web affiche un aperçu des artefacts générés, permettant à l'utilisateur de visualiser les résultats et la trace d'exécution.
Avant de créer le flux de travail Local Data Analyst, il est nécessaire que OpenClaw Gateway soit installé et opérationnel sur votre ordinateur. Considérez OpenClaw comme la couche d'exécution de ce projet, qui reçoit les requêtes de l'interface utilisateur Web, charge la compétence de l'espace de travail, exécute les outils locaux (tels que les commandes shell et les scripts Python) et coordonne l'ensemble du flux de travail de bout en bout.
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemonCette commande installe l'interface CLI OpenClaw, exécute l'assistant d'intégration pour configurer l'environnement local et configure le démon de passerelle afin qu'il puisse être démarré et arrêté facilement. Bien que nous exécutions la passerelle en avant-plan pour cette démonstration, l'installation du démon garantit une configuration standard et facilite le dépannage.
Vérifions maintenant que tout fonctionne correctement :
openclaw doctor
openclaw gateway statusLe rapport d'installation d'OpenClaw ( OpenClaw doctor ) indique que OpenClaw est correctement installé. La commande ` OpenClaw gateway status ` vous indique si la passerelle est actuellement en cours d'exécution. À ce stade, il se peut que le message « ne fonctionne pas » s'affiche, mais cela n'est pas préoccupant. Le point essentiel est que la commande fonctionne et que l'installation est reconnue.
Si vous souhaitez obtenir des instructions détaillées sur chaque option d'intégration (canaux, authentification, compétences, sécurité de la passerelle), veuillez vous référer au tutoriel OpenClaw pour une configuration complète étape par étape.
Ensuite, nous allons configurer Ollama, qui servira de backend LLM local pour ce projet. OpenClaw continuera à coordonner le flux de travail, mais lorsqu'il aura besoin de l'intelligence du modèle pour la synthèse ou le raisonnement, il fera appel aux LLM via Ollama.
Veuillez exécuter les commandes suivantes :
brew install ollama
ollama serve
ollama pull qwen3:8bLes commandes ci-dessus permettent d'installer le runtime Ollama, de démarrer le serveur de modèle local avec lequel OpenClaw communiquera et de télécharger le modèle qwen3:8b. Nous utilisons qwen3:8b car il offre un bon équilibre entre performances et qualité pour la plupart des ordinateurs portables, mais vous pouvez choisir un modèle différent en fonction des ressources de votre système. Vous pouvez également consulter ce guide de configuration fourni par Ollama.
Ensuite, nous devons configurer OpenClaw pour qu'il utilise l'instance Ollama locale. Cela garantit que tous les raisonnements, résumés et analyses sont effectués entièrement sur votre machine, sans aucun appel API externe.
Veuillez créer un répertoire de configuration local :
mkdir -p .openclaw-localVeuillez ensuite créer le fichier :
.openclaw-local/openclaw.json
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama-local",
"api": "openai-completions",
"models": [
{
"id": "qwen3:8b",
"name": "qwen3:8b",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 131072,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "ollama/qwen3:8b" }
}
},
"tools": {
"web": {
"search": { "enabled": false },
"fetch": { "enabled": true }
}
}
}La configuration ci-dessus définit trois composants clés :
baseUrl pointe vers le point de terminaison API local exposé par ollama serve, tandis que le paramètre api: openai-completions active la communication compatible avec OpenAI. L'enregistrement du modèle pour qwen3:8b précise ses capacités, notamment une grande fenêtre contextuelle de 131 Ko pour traiter des ensembles de données volumineux et une limite de jetons pour contrôler les réponses. Étant donné que le modèle fonctionne localement, toutes les valeurs de coût sont définies sur zéro.agent defaults » (Modèle de raisonnement) permet de contrôler le modèle utilisé par les agents OpenClaw pour le raisonnement. En définissant le modèle principal sur ollama/qwen3:8b, toutes les tâches de l'agent, telles que l'interprétation des invites, la génération de résumés ou le raisonnement sur les données, sont automatiquement acheminées vers le modèle Ollama local sans nécessiter d'appels API externes.Ensemble, ces paramètres garantissent que l'ensemble du flux de travail s'exécute de manière privée sur votre machine, OpenClaw se chargeant de l'orchestration et Ollama fournissant l'intelligence locale.
Dans cette étape, nous définissons la compétence de l'espace de travail qui indique à OpenClaw comment exécuter notre flux de travail. Au lieu de nous appuyer sur le modèle pour planifier l'utilisation des outils, nous utilisons le mode de répartition des commandes, qui permet à une commande slash de déclencher directement une commande d'exécution locale, ce qui accélère le flux de travail et le rend entièrement local.
Veuillez créer lefichier suivant SKILL.md dans votre espace de travail :
---
name: local-data-analyst
description: Local Data Analyst: analyze private local data with Ollama, generate chart/report, and keep all data on-device.
user-invocable: true
command-dispatch: tool
command-tool: exec
command-arg-mode: raw
---
Invoke as /local-data-analyst <raw command>.
This skill bypasses model planning and dispatches raw command text directly to the exec tool.
Use this exact command template in this workspace:
python3 /……/main.py --docs-dir <context_dir> --data-file <data_file> --output-dir <output_dir> --prompt "<prompt>" --use-ollama --model qwen3:8b
Expected outputs under <output_dir>:
- trend_chart.png
- analysis_report.md
- tool_trace.jsonCette configuration de compétences détermine la manière dont OpenClaw exécute l'analyse :
local-data-analyst, qui devient disponible sous la forme de la commande slash /local-data-analyst.command-dispatch: tool active le mode d'envoi de commandes, dans lequel OpenClaw achemine directement la commande vers un outil au lieu de demander au modèle de déterminer l'action à entreprendre.command-arg-mode: raw, la chaîne de commande complète est transmise telle quelle à l'outil exec, garantissant ainsi une exécution prévisible.main.py, qui :Ollama (qwen3:8b) pour le raisonnement et les résumésAinsi, OpenClaw gère l'orchestration et l'exécution, tandis qu'Ollama assure le raisonnement local. Dans l'étape suivante, nous relierons cette compétence à une interface Web afin que les utilisateurs puissent télécharger des données et déclencher l'analyse en une seule action.
À ce stade, nous disposons déjà de deux éléments essentiels fonctionnant sur une compétence OpenClaw Workspace et un backend de modèle local (Ollama) qui fournit le raisonnement. Nous avons maintenant besoin d'une interface légère qui vous permette de télécharger des fichiers et de lancer des exécutions sans avoir à utiliser le terminal à chaque fois.
Le fichier web_assistant.py agit comme un serveur frontal léger qui :
Le choix de conception principal ici est que le serveur web n'exécute jamais lui-même la logique d'analyse. Il délègue toutes les tâches à OpenClaw, ce qui permet de conserver une interface utilisateur simple.
L'objectif ici est de produire une chaîne unique qu'OpenClaw peut recevoir comme message de chat, par exemple : /local-data-analyst python3 ... --data-file ... --output-dir …
def build_slash_command(
data_path: Path,
docs_dir: Path,
output_dir: Path,
prompt: str,
model: str,
x_col: str,
y_col: str,
) -> str:
args = [
"python3",
str(BASE_DIR / "src" / "main.py"),
"--docs-dir", str(docs_dir),
"--data-file", str(data_path),
"--output-dir", str(output_dir),
"--prompt", prompt,
"--use-ollama",
"--model", model,
]
if x_col:
args.extend(["--x-column", x_col])
if y_col:
args.extend(["--y-column", y_col])
raw = " ".join(shlex.quote(a) for a in args)
return f"/local-data-analyst {raw}"La fonction ` build_slash_command() ` prépare l'instruction exacte qui sera envoyée à OpenClaw. Au lieu d'exécuter directement l'analyse, l'application web construit une commande slash structurée qu'OpenClaw peut acheminer vers la compétence appropriée de l'espace de travail. Cette fonction remplit quatre tâches principales :
args définit l'appel CLI vers src/main.py. Il s'agit de la même commande que celle que vous pourriez exécuter manuellement à partir du terminal.--x-column et --y-column ne sont ajoutés que lorsqu'ils sont fournis. Si ces valeurs sont manquantes, le script d'analyse peut automatiquement déduire les colonnes à partir de l'ensemble de données.shlex.quote() n échappe aucun argument, y compris l'invite utilisateur. Ceci est essentiel pour gérer les espaces et les caractères spéciaux et empêche les risques d'injection de commande lors du transfert des entrées utilisateur vers une commande shell.La fonction renvoie une chaîne commençant par : /local-data-analyst. Ce préfixe correspond au nom de la compétence défini dans SKILL.md. Lorsque OpenClaw reçoit cette commande slash, il achemine immédiatement la requête vers la compétence de l'espace de travail local-data-analyst, qui exécute ensuite la commande à l'aide de l'outil exec.
Maintenant que nous disposons de la commande slash, nous l'envoyons à OpenClaw à l'aide du CLI agent runner. C'est ici que l'application web transfère l'exécution.
slash_message = build_slash_command(
data_path=data_path,
docs_dir=docs_dir,
output_dir=output_dir,
prompt=prompt,
model=model,
x_col=x_col,
y_col=y_col,
)
agent_cmd = [
"openclaw", "agent",
"--local",
"--session-id", f"stealth-web-{run_id}",
"--message", slash_message,
"--timeout", "120",
]
proc = subprocess.run(agent_cmd, capture_output=True,
text=True, env=openclaw_env())L'invocation de l'agent OpenClaw constitue le point de transfert où l'application web cesse de fonctionner et demande à OpenClaw d'exécuter le flux de travail de bout en bout.
--local garantit que l'exécution reste sur votre machine et que l'agent traite la demande via votre passerelle locale et le modèle soutenu par Ollama plutôt que via un service hébergé.--session-id stealth-web-{run_id} ` attribue à chaque exécution son propre espace de noms de session isolé, ce qui empêche le débordement d'état entre les exécutions et facilite le débogage ultérieur d'une exécution spécifique. --message transmet la chaîne de commande slash exactement comme si un utilisateur l'avait saisie dans le chat ; OpenClaw la reçoit, la transmet à la compétence /local-data-analyst et exécute la commande sous-jacente via l'outil exec. --timeout 120 sert de soupape de sécurité afin que l'interface utilisateur Web ne se bloque pas indéfiniment si l'analyse est interrompue, et env=openclaw_env() oblige le sous-processus à utiliser la configuration OpenClaw locale de votre projet et le répertoire d'état afin qu'il cible systématiquement la configuration Ollama prévue.Dans l'étape suivante, nous chargerons les artefacts générés, notamment un graphique, un rapport et une trace d'outil, et nous afficherons des aperçus allégés dans le navigateur.
Enfin, web_assistant.py exécute un petit serveur HTTP local afin que vous puissiez interagir via le navigateur.
def main() -> int:
host = "127.0.0.1"
port = 8765
server = ThreadingHTTPServer((host, port), Handler)
print(f"Local Data Analyst web UI: http://{host}:{port}")
print("Press Ctrl+C to stop.")
try:
server.serve_forever()
except KeyboardInterrupt:
pass
return 0Cela simplifie le déploiement :
ThreadingHTTPServer permet d'effectuer plusieurs requêtes sans bloquer l'ensemble de l'application.Handler, qui reçoit les téléchargements, crée des dossiers d'exécution, déclenche OpenClaw et renvoie des aperçus.Remarque : Le code complet de l'implémentation d'web_assistant.py est disponible dans le dépôt GitHub du projet.
À ce stade, OpenClaw est déjà en mesure d'exécuter le workflow via la compétence workspace, et l'interface utilisateur web peut déclencher des exécutions via une commande slash. Le dernier élément est le moteur d'analyse qui traite les fichiers que vous avez téléchargés, exécute les étapes du flux de travail et produit les artefacts.
Le fichier main.py de ce référentiel se concentre sur deux fonctions qui définissent le cœur du pipeline, à savoir le chargement des données tabulaires et l'appel à Ollama pour le raisonnement local.
Cet assistant prend en charge plusieurs formats d'entrée tout en conservant la cohérence du flux de travail.
def load_tabular_data(data_path: Path, events: List[SkillEvent]) -> pd.DataFrame:
ext = data_path.suffix.lower()
if ext == ".csv":
df = pd.read_csv(data_path)
elif ext in {".tsv", ".tab"}:
df = pd.read_csv(data_path, sep="\t")
elif ext in {".json", ".jsonl"}:
try:
df = pd.read_json(data_path)
except ValueError:
df = pd.read_json(data_path, lines=True)
elif ext in {".xlsx", ".xls"}:
df = pd.read_excel(data_path)
else:
raise ValueError(f"Unsupported data file...")
log_event(events, "fs", "read", f"Loaded data file: {data_path.name}")
return dfLa fonction ` load_tabular_data() ` détecte le type de fichier à l'aide de ` data_path.suffix ` et le redirige vers le chargeur pandas approprié. Les fichiers CSV et TSV sont traités à l'aide de read_csv(), tandis que les fichiers TSV/tabulent changent simplement le délimiteur en \t. Les entrées JSON sont traitées à l'aide de read_json() en premier lieu, et si pandas renvoie une erreur ValueError, le système revient à lines=True pour JSONL. La prise en charge de Excel est ajoutée via read_excel() afin que les utilisateurs puissent télécharger des fichiers .xlsx sans prétraitement.
Enfin, l'appel d'log_event() enregistre une entrée de trace structurée que le pipeline peut ensuite sérialiser dans tool_trace.json.
Étant donné que cette démonstration ne repose pas sur un SDK, elle fait directement appel à l'API HTTP locale d'Ollama.
def ollama_generate(model: str, prompt: str) -> str:
url = "http://localhost:11434/api/generate"
payload = json.dumps({
"model": model,
"prompt": prompt,
"stream": False
}).encode("utf-8")
req = request.Request(url, data=payload,
headers={"Content-Type": "application/json"})
with request.urlopen(req, timeout=45) as resp:
body = json.loads(resp.read().decode("utf-8"))
return str(body.get("response", "")).strip()La fonction ollama_generate() envoie une charge utile JSON au point de terminaison /api/generate d'Ollama sur localhost. La charge utile spécifie le nom du modèle (par exemple, qwen3:8b), la chaîne d'invite finale et désactive la diffusion en continu afin que la fonction renvoie une seule réponse complète.
L'utilisation d'urllib.request s permet de conserver la légèreté et la portabilité de ce wrapper, tandis que la protection timeout=45 empêche notre flux de travail de se bloquer indéfiniment si le modèle est lent ou si le serveur est hors service. Enfin, la fonction extrait la sortie du modèle du champ « response » et renvoie un texte propre, qui sera ensuite utilisé pour écrire le fichier « analysis_report.md ».
Voici un petit script de lancement permettant de démarrer l'interface utilisateur Web locale qui accepte les téléchargements et déclenche l'exécution d'OpenClaw en arrière-plan.
set -euo pipefail
ROOT="$(cd "$(dirname "$0")" && pwd)"
cd "$ROOT/.."
python3 ../web_assistant.pyCe script effectue trois actions :
set -euo pipefail permet au script d'échouer rapidement, c'est-à-dire qu'il s'arrête en cas d'erreurs, traite les variables non définies comme des erreurs et évite les échecs silencieux dans les pipelines.ROOT=... détermine le répertoire dans lequel se trouve le script, ce qui permet de l'exécuter même à partir d'un autre emplacement.cd "$ROOT/.." se déplace vers la racine du projet attendue, puis lance web_assistant.py, qui héberge l'interface utilisateur et gère l'ensemble du pipeline.Une fois ce script exécuté, l'interface utilisateur de votre navigateur devient la porte d'entrée de la démonstration.
Pour la dernière étape, nous exécutons le système à l'aide d'une configuration à deux processus. La passerelle OpenClaw gère l'exécution de toutes les tâches, tandis que l'interface Web sert de couche utilisateur pour soumettre des requêtes et afficher les résultats générés.
Avant de lancer l'interface, nous commençons par démarrer la passerelle OpenClaw. Ce processus agit comme la couche d'exécution du système, traitant les demandes des agents, chargeant la compétence de l'espace de travail, invoquant les outils locaux et acheminant les appels de raisonnement vers le modèle Ollama.
export OPENCLAW_CONFIG_PATH="$PWD/.openclaw-local/openclaw.json"
openclaw gateway --forceDans ce terminal, OPENCLAW_CONFIG_PATH dirige OpenClaw vers la configuration locale du projet, où nous avons défini le modèle par défaut sur ollama/qwen3:8b et désactivé la recherche Web pour des raisons de confidentialité. Ensuite, veuillez exécuter la commande suivante : ` openclaw gateway --force `. Cette commande démarre la passerelle, même si OpenClaw détecte qu'un élément est déjà en cours d'exécution ou partiellement configuré.
Lorsque la passerelle est opérationnelle, elle est prête à accepter les messages des agents locaux (y compris notre commande slash /local-data-analyst ).
Une fois la passerelle opérationnelle, nous lançons l'interface Web, qui recueille les entrées des utilisateurs, envoie chaque requête à l'agent OpenClaw local et affiche les graphiques, rapports et traces d'exécution générés.
./local_data_analyst/run_web.sh
Veuillez ouvrir :
http://127.0.0.1:8765Le serveur web fonctionne sur 127.0.0.1, il est donc accessible uniquement depuis votre ordinateur. Lorsque vous cliquez sur Exécuter l'analyse, l'interface utilisateur crée un dossier d'exécution, construit la commande slash, invoque openclaw agent --local, puis interroge le disque pour obtenir les fichiers de sortie afin de pouvoir les prévisualiser :
trend_chart.pnganalysis_report.mdtool_trace.jsonLe résultat final ressemblera à ceci. Vous pouvez tester cette démonstration à l'aide de quelques exemples de fichiers.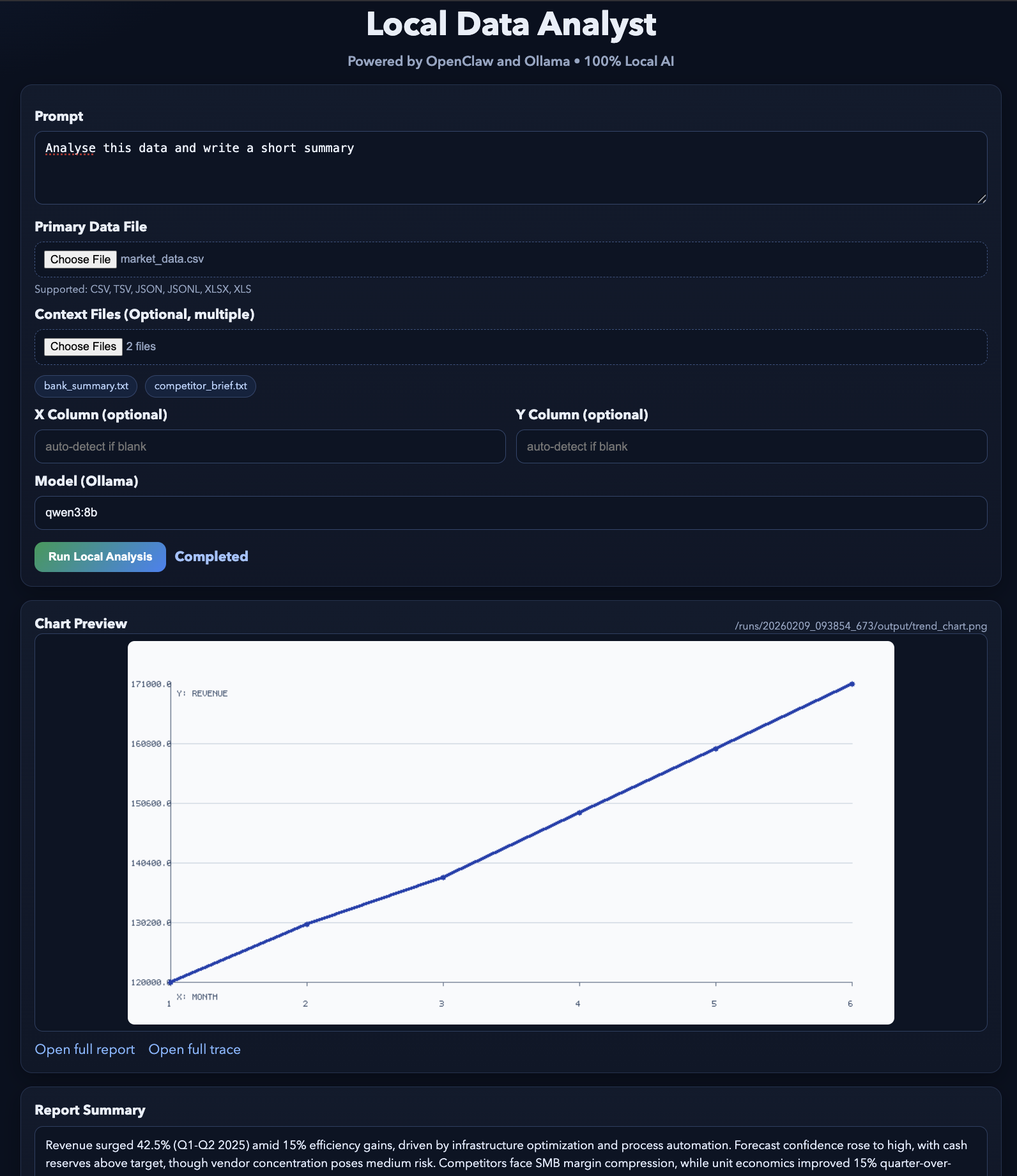
Dans ce tutoriel, nous avons développé une application d'intelligence artificielle locale où une interface web simple déclenche un workflow complet alimenté par OpenClaw et un modèle Ollama local. Au lieu d'appeler des API externes, le système conserve l'intégralité de la boucle sur votre machine.
OpenClaw gère l'orchestration et l'exécution des outils, tandis qu'Ollama fournit la couche d'intelligence locale. Le résultat est un flux de travail de type agent dans lequel une seule demande génère des artefacts structurés tels que des visualisations, des rapports et des pistes d'audit.
À partir de là, vous pouvez développer ce projet dans plusieurs directions. Vous pouvez ajouter de nouvelles fonctionnalités à l'espace de travail pour différents flux de travail, intégrer des outils locaux supplémentaires (par exemple, des requêtes de base de données ou la recherche de documents) ou connecter OpenClaw à des canaux de messagerie tels que Slack ou WhatsApp pour un accès à distance sécurisé.
Vous pouvez également tester différents modèles Ollama afin de trouver le meilleur équilibre entre performances et qualité en fonction de votre matériel.
Pour en savoir plus sur l'utilisation de l'IA dans vos flux de travail, je vous recommande de consulter le cours cours « Codage assisté par l'IA pour les développeurs ».
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
Tutoriel
Tutoriel
Samuel Shaibu


