
Curso
Projetando Sistemas Agentes com LangChain
3 h
12.1K
Executar o OpenClaw com um modelo Ollama local transforma seu sistema em um ambiente de IA independente. Em vez de mandar comandos e dados para APIs externas, todo o fluxo de trabalho, incluindo raciocínio, acesso a arquivos e geração de artefatos, rola na sua máquina.
Essa configuração traz várias vantagens práticas:
Esse tutorial foca na construção de uma arquitetura de agente local, onde o OpenClaw é o mecanismo de execução e o Ollama é a camada de raciocínio.
Nesta seção, vamos criar um aplicativo Local Data Analyst que roda totalmente na sua máquina usando o OpenClaw e um modelo Ollama local. Em um nível mais alto, o sistema faz três coisas principais:
O sistema gera três artefatos de saída:
trend_chart.pnganalysis_report.mdtool_trace.jsonNos bastidores, o fluxo de trabalho é coordenado por três componentes:
web_assistant.py): Esse arquivo Python cuida dos uploads de arquivos, cria um diretório de execução e manda um comando de barra para o OpenClaw.main.py): Esse arquivo lê o conjunto de dados, descobre as colunas relevantes, gera gráficos e insights e guarda tudo no disco.Quando o fluxo de trabalho terminar, a interface web mostra uma pré-visualização dos artefatos gerados, permitindo que o usuário veja os resultados e o rastreamento da execução.
Antes de criarmos o fluxo de trabalho do Analista de Dados Locais, precisamos que o OpenClaw Gateway esteja rodando na sua máquina. Pense no OpenClaw como a camada de execução deste projeto, que recebe solicitações da interface do usuário da web, carrega a habilidade do espaço de trabalho, executa ferramentas locais (como comandos shell e scripts Python) e coordena todo o fluxo de trabalho de ponta a ponta.
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemonEsse comando instala a CLI do OpenClaw, executa o assistente de integração para configurar o ambiente local e configura o daemon do gateway para que ele possa ser iniciado e parado facilmente. Embora a gente vá rodar o gateway em primeiro plano para essa demonstração, instalar o daemon garante uma configuração padrão e facilita o diagnóstico de problemas.
Agora, vamos ver se tá tudo funcionando:
openclaw doctor
openclaw gateway statusO arquivo ` OpenClaw doctor ` mostra que o OpenClaw está instalado direitinho. O comando ` OpenClaw gateway status ` mostra se o gateway está funcionando agora. Nesta fase, pode aparecer a mensagem “não está em execução”, mas não se preocupe. O ponto principal é que o comando funciona e a instalação é reconhecida.
Se você quiser um guia detalhado de todas as opções de integração (canais, autenticação, habilidades, segurança de gateway), pode conferir o tutorial do OpenClaw para uma configuração completa passo a passo.
Depois, vamos configurar o Ollama, que vai ser o backend LLM local pra esse projeto. O OpenClaw ainda vai organizar o fluxo de trabalho, mas quando precisar de inteligência de modelo para resumir ou raciocinar, vai chamar os LLMs pelo Ollama.
Execute os seguintes comandos:
brew install ollama
ollama serve
ollama pull qwen3:8bOs comandos acima instalam o Ollama runtime, iniciam o servidor de modelo local com o qual o OpenClaw se comunicará e baixam o modelo qwen3:8b. Usamos o qwen3:8b porque ele tem um bom equilíbrio entre desempenho e qualidade pra maioria dos laptops, mas você pode escolher um modelo diferente dependendo dos recursos do seu sistema. Você também pode conferir este guia de configuração da Ollama.
Depois, precisamos configurar o OpenClaw pra usar a instância local do Ollama. Isso garante que todo o raciocínio, resumo e análise sejam feitos inteiramente em sua máquina, sem chamadas de API externas.
Crie um diretório de configuração local:
mkdir -p .openclaw-localDepois, crie o arquivo:
.openclaw-local/openclaw.json
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama-local",
"api": "openai-completions",
"models": [
{
"id": "qwen3:8b",
"name": "qwen3:8b",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 131072,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "ollama/qwen3:8b" }
}
},
"tools": {
"web": {
"search": { "enabled": false },
"fetch": { "enabled": true }
}
}
}A configuração acima define três componentes principais:
baseUrl aponta para o endpoint da API local exposto por ollama serve, enquanto a configuração api: openai-completions permite a comunicação compatível com OpenAI. O registro do modelo para qwen3:8b mostra o que ele pode fazer, incluindo uma janela de contexto grande de 131K para lidar com conjuntos de dados enormes e um limite de tokens para respostas controladas. Como o modelo funciona localmente, todos os valores de custo são definidos como zero.agent defaults ` controla qual modelo os agentes OpenClaw usam para raciocínio. Ao definir o modelo principal como ollama/qwen3:8b, todas as tarefas do agente, como interpretar prompts, gerar resumos ou raciocinar sobre dados, são automaticamente encaminhadas para o modelo Ollama local, sem precisar de chamadas de API externas.Juntas, essas configurações garantem que todo o fluxo de trabalho seja executado de forma privada em sua máquina, com o OpenClaw cuidando da orquestração e o Ollama fornecendo inteligência local.
Nesta etapa, vamos definir a habilidade do espaço de trabalho que diz ao OpenClaw como executar nosso fluxo de trabalho. Em vez de depender do modelo para planejar o uso da ferramenta, usamos o modo de envio de comandos, que permite que um comando de barra inclinada acione diretamente um comando de execução local, tornando o fluxo de trabalho mais rápido e totalmente local.
Vamos criar o seguintearquivo SKILL.md no seu espaço de trabalho:
---
name: local-data-analyst
description: Local Data Analyst: analyze private local data with Ollama, generate chart/report, and keep all data on-device.
user-invocable: true
command-dispatch: tool
command-tool: exec
command-arg-mode: raw
---
Invoke as /local-data-analyst <raw command>.
This skill bypasses model planning and dispatches raw command text directly to the exec tool.
Use this exact command template in this workspace:
python3 /……/main.py --docs-dir <context_dir> --data-file <data_file> --output-dir <output_dir> --prompt "<prompt>" --use-ollama --model qwen3:8b
Expected outputs under <output_dir>:
- trend_chart.png
- analysis_report.md
- tool_trace.jsonEssa configuração de habilidades controla como o OpenClaw faz a análise:
local-data-analyst, que fica disponível como o comando de barra /local-data-analyst.command-dispatch: tool ativa o modo de envio de comandos, onde o OpenClaw encaminha diretamente o comando para uma ferramenta, em vez de pedir ao modelo para decidir o que fazer.command-arg-mode: raw`, a string de comando completa é passada sem alterações para a ferramenta ` exec `, garantindo uma execução previsível.main.py, que:Ollama (qwen3:8b) para raciocínio e resumosEntão, o OpenClaw cuida da orquestração e execução, enquanto o Ollama faz o raciocínio local. Na próxima etapa, vamos conectar essa habilidade a uma interface web para que os usuários possam enviar dados e iniciar a análise com uma única ação.
Neste momento, já temos duas peças principais funcionando em uma habilidade do espaço de trabalho OpenClaw e um backend de modelo local (Ollama) que fornece raciocínio. Agora precisamos de uma interface leve que permita fazer upload de arquivos e iniciar execuções sem precisar usar o terminal toda vez.
O arquivo web_assistant.py funciona como um servidor front-end leve que:
A principal escolha de design aqui é que o servidor web nunca executa a lógica de análise por conta própria. Ele deixa tudo por conta do OpenClaw, então a interface do usuário continua simples.
O objetivo aqui é criar uma única string que o OpenClaw possa receber como uma mensagem de chat, tipo: /local-data-analyst python3 ... --data-file ... --output-dir …
def build_slash_command(
data_path: Path,
docs_dir: Path,
output_dir: Path,
prompt: str,
model: str,
x_col: str,
y_col: str,
) -> str:
args = [
"python3",
str(BASE_DIR / "src" / "main.py"),
"--docs-dir", str(docs_dir),
"--data-file", str(data_path),
"--output-dir", str(output_dir),
"--prompt", prompt,
"--use-ollama",
"--model", model,
]
if x_col:
args.extend(["--x-column", x_col])
if y_col:
args.extend(["--y-column", y_col])
raw = " ".join(shlex.quote(a) for a in args)
return f"/local-data-analyst {raw}"A função ` build_slash_command() ` prepara a instrução exata que vai ser enviada para o OpenClaw. Em vez de fazer a análise direto, o aplicativo web cria um comando estruturado que o OpenClaw pode mandar para a habilidade certa do espaço de trabalho. Essa função faz quatro coisas importantes:
args define a chamada CLI para src/main.py. Esse é o mesmo comando que você poderia executar manualmente no terminal.--x-column ` e ` --y-column ` só são adicionados quando fornecidos. Se esses valores estiverem faltando, o script de análise pode automaticamente inferir as colunas a partir do conjunto de dados.shlex.quote() ` escapa todos os argumentos, incluindo o prompt do usuário. Isso é super importante pra lidar com espaços e caracteres especiais e evita riscos de injeção de comando quando passa a entrada do usuário pra um comando shell.A função retorna uma string que começa com: /local-data-analyst. Esse prefixo combina com o nome da habilidade definido em SKILL.md. Quando o OpenClaw recebe esse comando de barra, ele imediatamente encaminha a solicitação para a habilidade do espaço de trabalho local-data-analyst, que então executa o comando usando a ferramenta exec.
Agora que temos o comando slash, vamos mandá-lo para o OpenClaw usando o executador de agente CLI. É aqui que o aplicativo web passa a execução.
slash_message = build_slash_command(
data_path=data_path,
docs_dir=docs_dir,
output_dir=output_dir,
prompt=prompt,
model=model,
x_col=x_col,
y_col=y_col,
)
agent_cmd = [
"openclaw", "agent",
"--local",
"--session-id", f"stealth-web-{run_id}",
"--message", slash_message,
"--timeout", "120",
]
proc = subprocess.run(agent_cmd, capture_output=True,
text=True, env=openclaw_env())A invocação do agente OpenClaw é o ponto de transferência em que o aplicativo web para de funcionar e, em vez disso, solicita ao OpenClaw que execute o fluxo de trabalho de ponta a ponta.
--local garante que a execução fique na sua máquina, e o agente processa a solicitação através do seu gateway local e do modelo Ollama, em vez de qualquer serviço hospedado.--session-id stealth-web-{run_id} ` dá a cada execução seu próprio namespace de sessão isolado, o que evita que o estado se espalhe entre as execuções e facilita a depuração de uma execução específica mais tarde. --message passa a string do comando de barra exatamente como se um usuário tivesse digitado no chat; o OpenClaw recebe, encaminha para a habilidade /local-data-analyst e executa o comando subjacente por meio da ferramenta exec. --timeout 120 funciona como uma válvula de segurança para que a interface do usuário da web não fique travada para sempre se a análise parar, e env=openclaw_env() força o subprocesso a usar a configuração OpenClaw local do seu projeto e o diretório de estado para que ele sempre vise a configuração Ollama pretendida.Na próxima etapa, vamos carregar os artefatos gerados, incluindo um gráfico, relatório e rastreamento de ferramenta, e renderizar pré-visualizações leves no navegador.
Por fim, o web_assistant.py roda um pequeno servidor HTTP local para que você possa interagir pelo navegador.
def main() -> int:
host = "127.0.0.1"
port = 8765
server = ThreadingHTTPServer((host, port), Handler)
print(f"Local Data Analyst web UI: http://{host}:{port}")
print("Press Ctrl+C to stop.")
try:
server.serve_forever()
except KeyboardInterrupt:
pass
return 0Isso mantém a implantação simples:
ThreadingHTTPServer permite várias solicitações sem bloquear todo o aplicativo.Handler, que recebe uploads, cria pastas de execução, aciona o OpenClaw e retorna pré-visualizações.Observação: A implementação completa do código web_assistant.py está disponível no repositório GitHub do projeto.
Neste momento, o OpenClaw já consegue executar o fluxo de trabalho através da habilidade do espaço de trabalho, e a interface do usuário da web pode acionar execuções por meio de um comando de barra. A parte que falta é o mecanismo de análise que pega os arquivos que você enviou, executa as etapas do fluxo de trabalho e produz os artefatos.
O arquivo main.py neste repositório foca em duas funções que definem o coração do pipeline, ou seja, carregar dados tabulares e chamar o Ollama para raciocínio local.
Esse auxiliar suporta vários formatos de entrada, mantendo o fluxo de trabalho consistente.
def load_tabular_data(data_path: Path, events: List[SkillEvent]) -> pd.DataFrame:
ext = data_path.suffix.lower()
if ext == ".csv":
df = pd.read_csv(data_path)
elif ext in {".tsv", ".tab"}:
df = pd.read_csv(data_path, sep="\t")
elif ext in {".json", ".jsonl"}:
try:
df = pd.read_json(data_path)
except ValueError:
df = pd.read_json(data_path, lines=True)
elif ext in {".xlsx", ".xls"}:
df = pd.read_excel(data_path)
else:
raise ValueError(f"Unsupported data file...")
log_event(events, "fs", "read", f"Loaded data file: {data_path.name}")
return dfA função ` load_tabular_data() ` descobre o tipo de arquivo usando ` data_path.suffix ` e manda ele pro carregador pandas certo. Os arquivos CSV e TSV são tratados com read_csv(), onde os arquivos TSV/tab simplesmente trocam o delimitador para \t. As entradas JSON são tratadas usando o read_json() primeiro e, se o pandas lançar um ValueError, ele volta para lines=True para JSONL. O suporte Excel é adicionado via read_excel() para que os usuários possam enviar arquivos .xlsx sem pré-processamento.
Por fim, a chamada log_event() registra uma entrada de rastreamento estruturada que o pipeline pode posteriormente serializar em tool_trace.json.
Como essa demonstração não depende de um SDK, ela chama diretamente a API HTTP local do Ollama.
def ollama_generate(model: str, prompt: str) -> str:
url = "http://localhost:11434/api/generate"
payload = json.dumps({
"model": model,
"prompt": prompt,
"stream": False
}).encode("utf-8")
req = request.Request(url, data=payload,
headers={"Content-Type": "application/json"})
with request.urlopen(req, timeout=45) as resp:
body = json.loads(resp.read().decode("utf-8"))
return str(body.get("response", "")).strip()A função ollama_generate() manda uma carga JSON para o endpoint /api/generate do Ollama em localhost. A carga útil especifica o nome do modelo (por exemplo, qwen3:8b), a string de prompt final e desativa o streaming para que a função retorne uma única resposta completa.
Usar urllib.request deixa esse wrapper leve e portátil, e o timeout=45 guard evita que nosso fluxo de trabalho fique travado pra sempre se o modelo estiver lento ou o servidor estiver fora do ar. Por fim, a função pega a saída do modelo do campo “ response ” e devolve um texto limpo, que depois é usado para escrever um arquivo “ analysis_report.md ”.
Aqui está um pequeno script de inicialização para iniciar a interface de usuário local da web que aceita uploads e aciona o OpenClaw em segundo plano.
set -euo pipefail
ROOT="$(cd "$(dirname "$0")" && pwd)"
cd "$ROOT/.."
python3 ../web_assistant.pyEsse script faz três coisas:
set -euo pipefail faz com que o script falhe rapidamente, ou seja, ele para em caso de erros, trata variáveis não definidas como erros e evita falhas silenciosas em pipelines.ROOT=... resolve o diretório onde o script está, então funciona mesmo se você executá-lo de outro lugar.cd "$ROOT/.." vai para a raiz do projeto e inicia o web_assistant.py, que hospeda a interface do usuário e gerencia todo o pipeline.Quando esse script estiver rodando, a interface do seu navegador vai virar a porta de entrada da demonstração.
Para a etapa final, executamos o sistema usando uma configuração de dois processos. O gateway OpenClaw cuida de toda a execução das tarefas, enquanto a interface web é a parte do usuário para mandar pedidos e ver os resultados gerados.
Antes de abrir a interface, primeiro a gente inicia o gateway OpenClaw. Esse processo funciona como a camada de execução do sistema, cuidando das solicitações dos agentes, carregando a habilidade do espaço de trabalho, chamando as ferramentas locais e encaminhando as chamadas de raciocínio para o modelo Ollama.
export OPENCLAW_CONFIG_PATH="$PWD/.openclaw-local/openclaw.json"
openclaw gateway --forceNeste terminal, OPENCLAW_CONFIG_PATH direciona o OpenClaw para a configuração local do projeto, onde fixamos o modelo padrão em ollama/qwen3:8b e desativamos a pesquisa na web por motivos de privacidade. Depois, o openclaw gateway --force inicia o gateway mesmo que o OpenClaw ache que algo já está rodando ou parcialmente configurado.
Quando o gateway estiver ativo, ele estará pronto para aceitar mensagens do agente local (incluindo nosso comando de barra /local-data-analyst ).
Quando o gateway estiver funcionando, a gente abre a interface web, que pega as entradas do usuário, manda cada solicitação pro agente OpenClaw local e mostra os gráficos, relatórios e rastros de execução gerados.
./local_data_analyst/run_web.sh
Então abra:
http://127.0.0.1:8765O servidor web funciona em 127.0.0.1, então só dá para acessar a partir do seu computador. Quando você clica em Executar Análise, a interface do usuário cria uma pasta de execução, constrói o comando de barra, chama openclaw agent --local e, em seguida, pesquisa o disco em busca dos arquivos de saída para que possa visualizá-los:
trend_chart.pnganalysis_report.mdtool_trace.jsonO resultado final vai ficar mais ou menos assim. Você pode testar essa demonstração usando alguns arquivos de exemplo.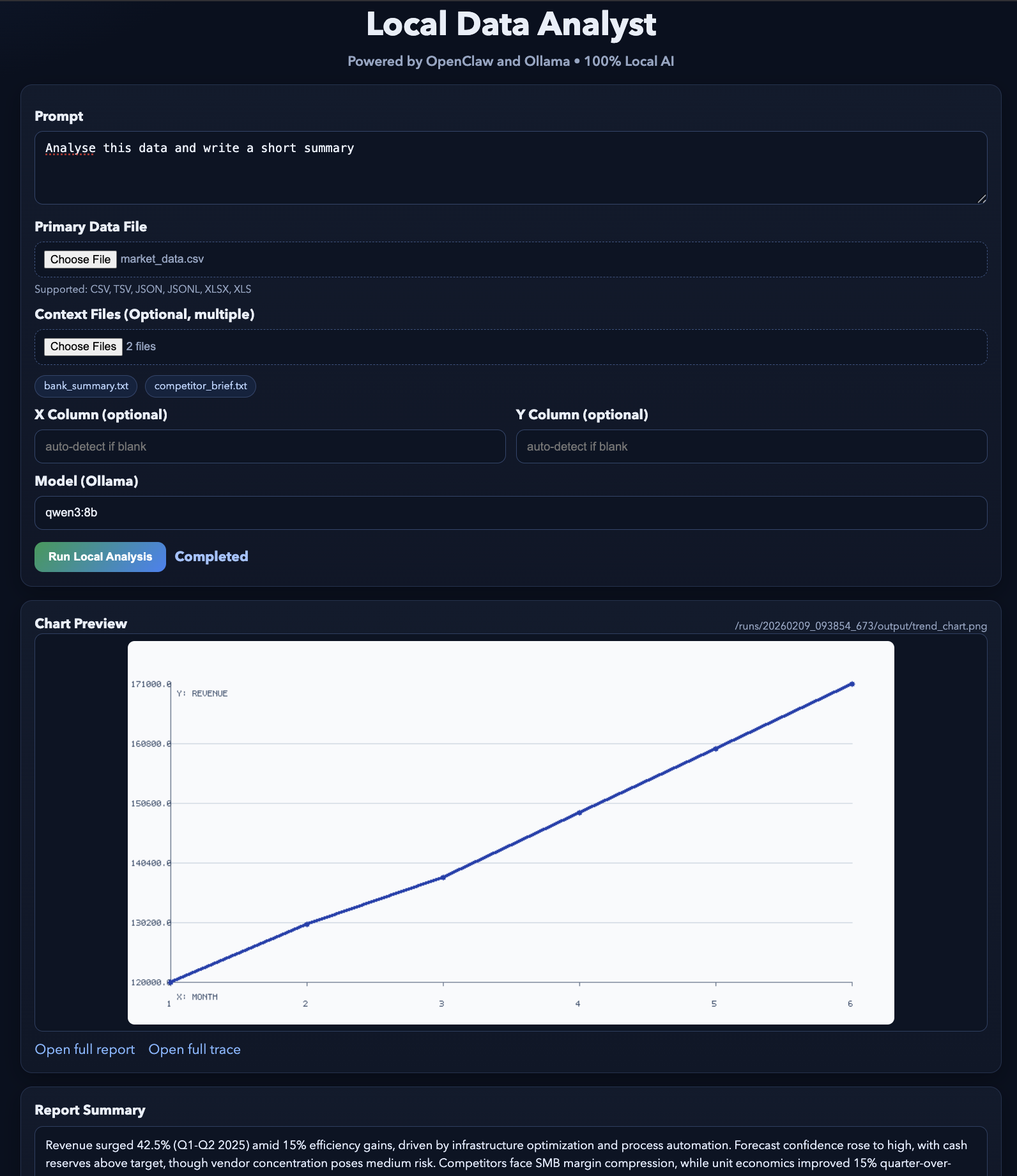
Neste tutorial, criamos um aplicativo de IA local-first, onde uma interface web simples aciona um fluxo de trabalho completo do agente, alimentado pelo OpenClaw e um modelo Ollama local. Em vez de chamar APIs externas, o sistema mantém todo o loop na sua máquina.
O OpenClaw cuida da orquestração e da execução das ferramentas, enquanto o Ollama fornece a camada de inteligência local. O resultado é um fluxo de trabalho tipo agente, onde uma única solicitação gera artefatos estruturados, como visualizações, relatórios e trilhas de auditoria.
A partir daqui, você pode expandir esse projeto em várias direções. Você pode adicionar novas habilidades ao espaço de trabalho para diferentes fluxos de trabalho, integrar ferramentas locais adicionais (por exemplo, consultas a bancos de dados ou pesquisa de documentos) ou conectar o OpenClaw a canais de mensagens como Slack ou WhatsApp para acesso remoto seguro.
Você também pode experimentar diferentes modelos do Ollama para equilibrar desempenho e qualidade com base no seu hardware.
Pra saber mais sobre como usar IA nos seus fluxos de trabalho, recomendo dar uma olhada no curso curso Codificação assistida por IA para desenvolvedores.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Austin Chia
Tutorial
Ryan Ong
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan


