
Curso
Diseño de sistemas agénticos con LangChain
3 h
12.1K
Ejecutar OpenClaw con un modelo Ollama local convierte tu sistema en un entorno de IA autónomo. En lugar de enviar indicaciones y datos a API externas, todo el flujo de trabajo, incluyendo el razonamiento, el acceso a archivos y la generación de artefactos, se ejecuta en tu máquina.
Esta configuración ofrece varias ventajas prácticas:
Este tutorial se centra en la creación de una arquitectura de agente local, en la que OpenClaw actúa como motor de ejecución y Ollama proporciona la capa de razonamiento.
En esta sección, crearemos una aplicación Local Data Analyst que se ejecuta íntegramente en tu máquina utilizando OpenClaw y un modelo Ollama local. A alto nivel, el sistema realiza tres tareas fundamentales:
El sistema produce tres artefactos de salida:
trend_chart.pnganalysis_report.mdtool_trace.jsonEntre bastidores, el flujo de trabajo está coordinado por tres componentes:
web_assistant.py): Este archivo Python gestiona las cargas de archivos, crea un directorio de ejecución y envía un comando de barra inclinada a OpenClaw.main.py): Este archivo lee el conjunto de datos, infiere las columnas relevantes, genera gráficos y conocimientos, y escribe todos los resultados en el disco.Una vez completado el flujo de trabajo, la interfaz web muestra una vista previa de los artefactos generados, lo que te permite ver los resultados y el seguimiento de la ejecución.
Antes de crear el flujo de trabajo del analista de datos locales, necesitamos que OpenClaw Gateway se ejecute en tu equipo. Piensa en OpenClaw como la capa de ejecución de este proyecto, que recibe solicitudes de la interfaz de usuario web, carga la habilidad del espacio de trabajo, ejecuta herramientas locales (como comandos de terminal y scripts de Python) y coordina todo el flujo de trabajo de principio a fin.
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemonEste comando instala la CLI de OpenClaw, ejecuta el asistente de incorporación para configurar el entorno local y configura el demonio de la puerta de enlace para que se pueda iniciar y detener fácilmente. Aunque ejecutaremos la puerta de enlace en primer plano para esta demostración, la instalación del demonio garantiza una configuración estándar y facilita la resolución de problemas.
Ahora, confirmemos que todo funciona correctamente:
openclaw doctor
openclaw gateway statusEl informe « OpenClaw doctor » indica que OpenClaw está instalado correctamente. OpenClaw gateway status te indica si la puerta de enlace está actualmente en funcionamiento. En esta etapa, es posible que aparezca el mensaje «no se está ejecutando», pero no hay problema. Lo importante es que el comando funciona y se reconoce la instalación.
Si deseas obtener una guía detallada de todas las opciones de incorporación (canales, autenticación, habilidades, seguridad de la puerta de enlace), puedes consultar el tutorial de OpenClaw para obtener una configuración completa paso a paso.
A continuación, configuraremos Ollama, que actuará como backend LLM local para este proyecto. OpenClaw seguirá coordinando el flujo de trabajo, pero cuando necesite inteligencia de modelos para resumir o razonar, llamará a los LLM a través de Ollama.
Ejecuta los siguientes comandos:
brew install ollama
ollama serve
ollama pull qwen3:8bLos comandos anteriores instalan el tiempo de ejecución de Ollama, inician el servidor de modelos local con el que se comunicará OpenClaw y descargan el modelo qwen3:8b. Utilizamos qwen3:8b, ya que ofrece un buen equilibrio entre rendimiento y calidad para la mayoría de los portátiles, pero puedes elegir un modelo diferente en función de los recursos de tu sistema. También puedes consultar esta guía de configuración de Ollama.
A continuación, hay que configurar OpenClaw para que utilice la instancia local de Ollama. Esto garantiza que todo el razonamiento, el resumen y el análisis se realicen íntegramente en tu equipo, sin llamadas a API externas.
Crea un directorio de configuración local:
mkdir -p .openclaw-localA continuación, crea el archivo:
.openclaw-local/openclaw.json
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "ollama-local",
"api": "openai-completions",
"models": [
{
"id": "qwen3:8b",
"name": "qwen3:8b",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 131072,
"maxTokens": 8192
}
]
}
}
},
"agents": {
"defaults": {
"model": { "primary": "ollama/qwen3:8b" }
}
},
"tools": {
"web": {
"search": { "enabled": false },
"fetch": { "enabled": true }
}
}
}La configuración anterior define tres componentes clave:
baseUrl apunta al punto final API local expuesto por ollama serve, mientras que la configuración api: openai-completions habilita la comunicación compatible con OpenAI. El registro del modelo para qwen3:8b especifica sus capacidades, incluyendo una gran ventana de contexto de 131K para manejar conjuntos de datos de gran tamaño y un límite de tokens para respuestas controladas. Dado que el modelo se ejecuta localmente, todos los valores de coste se establecen en cero.agent defaults » controla qué modelo utilizan los agentes OpenClaw para el razonamiento. Al configurar el modelo principal como ollama/qwen3:8b, todas las tareas de los agentes, como interpretar indicaciones, generar resúmenes o razonar sobre datos, se dirigen automáticamente al modelo Ollama local sin necesidad de realizar llamadas API externas.En conjunto, estos ajustes garantizan que todo el flujo de trabajo se ejecute de forma privada en tu máquina, con OpenClaw encargándose de la coordinación y Ollama proporcionando inteligencia local.
En este paso, definimos la habilidad del espacio de trabajo que indica a OpenClaw cómo ejecutar nuestro flujo de trabajo. En lugar de basarnos en el modelo para planificar el uso de las herramientas, utilizamos el modo de envío de comandos, que permite que un comando de barra inclinada active directamente un comando de ejecución local, lo que agiliza el flujo de trabajo y lo hace totalmente local.
Creemos el siguientearchivo SKILL.md en tu espacio de trabajo:
---
name: local-data-analyst
description: Local Data Analyst: analyze private local data with Ollama, generate chart/report, and keep all data on-device.
user-invocable: true
command-dispatch: tool
command-tool: exec
command-arg-mode: raw
---
Invoke as /local-data-analyst <raw command>.
This skill bypasses model planning and dispatches raw command text directly to the exec tool.
Use this exact command template in this workspace:
python3 /……/main.py --docs-dir <context_dir> --data-file <data_file> --output-dir <output_dir> --prompt "<prompt>" --use-ollama --model qwen3:8b
Expected outputs under <output_dir>:
- trend_chart.png
- analysis_report.md
- tool_trace.jsonEsta configuración de habilidades controla cómo OpenClaw ejecuta el análisis:
local-data-analyst », que está disponible como comando de barra inclinada « /local-data-analyst ».command-dispatch: tool habilita el modo de envío de comandos, en el que OpenClaw envía directamente el comando a una herramienta en lugar de pedir al modelo que decida qué hacer.command-arg-mode: raw, la cadena de comando completa se pasa sin cambios a la herramienta exec, lo que garantiza una ejecución predecible.main.py, que:Ollama (qwen3:8b) para razonamientos y resúmenes.Así, OpenClaw se encarga de la coordinación y la ejecución, mientras que Ollama proporciona el razonamiento local. En el siguiente paso, conectaremos esta habilidad a una interfaz web para que los usuarios puedan cargar datos y activar el análisis con una sola acción.
En este momento, ya contamos con dos elementos fundamentales que funcionan en una habilidad del espacio de trabajo OpenClaw y un backend de modelo local (Ollama) que proporciona razonamiento. Ahora necesitamos una interfaz ligera que te permita cargar archivos y activar ejecuciones sin tener que tocar el terminal cada vez.
El archivo web_assistant.py actúa como un servidor frontend ligero que:
La decisión clave en cuanto al diseño es que el servidor web nunca ejecuta la lógica de análisis por sí mismo. Delega todo a OpenClaw, por lo que la interfaz de usuario sigue siendo sencilla.
El objetivo aquí es producir una sola cadena que OpenClaw pueda recibir como un mensaje de chat, como: /local-data-analyst python3 ... --data-file ... --output-dir …
def build_slash_command(
data_path: Path,
docs_dir: Path,
output_dir: Path,
prompt: str,
model: str,
x_col: str,
y_col: str,
) -> str:
args = [
"python3",
str(BASE_DIR / "src" / "main.py"),
"--docs-dir", str(docs_dir),
"--data-file", str(data_path),
"--output-dir", str(output_dir),
"--prompt", prompt,
"--use-ollama",
"--model", model,
]
if x_col:
args.extend(["--x-column", x_col])
if y_col:
args.extend(["--y-column", y_col])
raw = " ".join(shlex.quote(a) for a in args)
return f"/local-data-analyst {raw}"La función ` build_slash_command() ` prepara la instrucción exacta que se enviará a OpenClaw. En lugar de ejecutar el análisis directamente, la aplicación web construye un comando de barra inclinada estructurado que OpenClaw puede dirigir a la habilidad del espacio de trabajo adecuado. Esta función realiza cuatro tareas clave:
args define la llamada CLI a src/main.py. Este es el mismo comando que podrías ejecutar manualmente desde el terminal.--x-column ` y ` --y-column ` solo se añaden cuando se proporcionan. Si faltan estos valores, el script de análisis puede inferir automáticamente las columnas a partir del conjunto de datos.shlex.quote() escapa todos los argumentos, incluido el mensaje de usuario. Esto es fundamental para gestionar espacios y caracteres especiales, y evita riesgos de inyección de comandos al pasar la entrada del usuario a un comando de terminal.La función devuelve una cadena que comienza por: /local-data-analyst. Este prefijo coincide con el nombre de la habilidad definido en SKILL.md. Cuando OpenClaw recibe este comando de barra, envía inmediatamente la solicitud a la habilidad del espacio de trabajo local-data-analyst, que a continuación ejecuta el comando utilizando la herramienta exec.
Ahora que tenemos el comando slash, lo enviamos a OpenClaw utilizando el ejecutor de agentes CLI. Aquí es donde la aplicación web cede el control de la ejecución.
slash_message = build_slash_command(
data_path=data_path,
docs_dir=docs_dir,
output_dir=output_dir,
prompt=prompt,
model=model,
x_col=x_col,
y_col=y_col,
)
agent_cmd = [
"openclaw", "agent",
"--local",
"--session-id", f"stealth-web-{run_id}",
"--message", slash_message,
"--timeout", "120",
]
proc = subprocess.run(agent_cmd, capture_output=True,
text=True, env=openclaw_env())La invocación del agente OpenClaw es el punto de traspaso en el que la aplicación web deja de funcionar y solicita a OpenClaw que ejecute el flujo de trabajo de principio a fin.
--local garantiza que la ejecución se mantenga en tu máquina y que el agente procese la solicitud a través de tu puerta de enlace local y el modelo respaldado por Ollama, en lugar de cualquier servicio alojado.--session-id stealth-web-{run_id} ` proporciona a cada ejecución su propio espacio de nombres de sesión aislado, lo que evita que el estado se filtre entre ejecuciones y facilita la depuración posterior de una ejecución específica. --message pasa la cadena de comandos de barra inclinada exactamente como si un usuario la hubiera escrito en el chat; OpenClaw la recibe, la envía a la habilidad /local-data-analyst y ejecuta el comando subyacente a través de la herramienta exec. --timeout 120 actúa como válvula de seguridad para que la interfaz de usuario web no se cuelgue indefinidamente si el análisis se detiene, y env=openclaw_env() obliga al subproceso a utilizar la configuración y el directorio de estado de OpenClaw locales de tu proyecto, de modo que se dirija sistemáticamente a la configuración prevista de Ollama.En el siguiente paso, cargaremos los artefactos generados, incluyendo un gráfico, un informe y un rastreo de herramientas, y renderizaremos vistas previas ligeras en el navegador.
Por último, web_assistant.py ejecuta un pequeño servidor HTTP local para que puedas interactuar a través del navegador.
def main() -> int:
host = "127.0.0.1"
port = 8765
server = ThreadingHTTPServer((host, port), Handler)
print(f"Local Data Analyst web UI: http://{host}:{port}")
print("Press Ctrl+C to stop.")
try:
server.serve_forever()
except KeyboardInterrupt:
pass
return 0Esto simplifica la implementación:
ThreadingHTTPServer permite múltiples solicitudes sin bloquear toda la aplicación.Handler, que recibe las cargas, crea carpetas de ejecución, activa OpenClaw y devuelve vistas previas.Nota: La implementación completa del código web_assistant.py está disponible en el repositorio GitHub del proyecto.
En este momento, OpenClaw ya es capaz de ejecutar el flujo de trabajo a través de la habilidad del espacio de trabajo, y la interfaz de usuario web puede activar las ejecuciones mediante un comando de barra inclinada. La pieza restante es el motor de análisis que toma los archivos cargados, ejecuta los pasos del flujo de trabajo y produce los artefactos.
El archivo main.py de este repositorio se centra en dos funciones que definen el núcleo del proceso, es decir, la carga de datos tabulares y la llamada a Ollama para el razonamiento local.
Este asistente admite múltiples formatos de entrada y mantiene la coherencia del flujo de trabajo.
def load_tabular_data(data_path: Path, events: List[SkillEvent]) -> pd.DataFrame:
ext = data_path.suffix.lower()
if ext == ".csv":
df = pd.read_csv(data_path)
elif ext in {".tsv", ".tab"}:
df = pd.read_csv(data_path, sep="\t")
elif ext in {".json", ".jsonl"}:
try:
df = pd.read_json(data_path)
except ValueError:
df = pd.read_json(data_path, lines=True)
elif ext in {".xlsx", ".xls"}:
df = pd.read_excel(data_path)
else:
raise ValueError(f"Unsupported data file...")
log_event(events, "fs", "read", f"Loaded data file: {data_path.name}")
return dfLa función « load_tabular_data() » detecta el tipo de archivo utilizando « data_path.suffix » y lo envía al cargador de pandas adecuado. Los archivos CSV y TSV se gestionan con read_csv(), donde los archivos TSV/tab simplemente cambian el delimitador a \t. Las entradas JSON se gestionan utilizando primero read_json() y, si pandas lanza un ValueError, se recurre a lines=True para JSONL. Se ha añadido compatibilidad con Excel a través de read_excel() para que los usuarios puedan cargar archivos .xlsx sin necesidad de preprocesarlos.
Por último, la llamada log_event() registra una entrada de seguimiento estructurada que la canalización puede serializar posteriormente en tool_trace.json.
Dado que esta demostración no depende de un SDK, llama directamente a la API HTTP local de Ollama.
def ollama_generate(model: str, prompt: str) -> str:
url = "http://localhost:11434/api/generate"
payload = json.dumps({
"model": model,
"prompt": prompt,
"stream": False
}).encode("utf-8")
req = request.Request(url, data=payload,
headers={"Content-Type": "application/json"})
with request.urlopen(req, timeout=45) as resp:
body = json.loads(resp.read().decode("utf-8"))
return str(body.get("response", "")).strip()La función ollama_generate() envía una carga JSON al punto final /api/generate de Ollama en localhost. La carga útil especifica el nombre del modelo (por ejemplo, qwen3:8b), la cadena de solicitud final y deshabilita la transmisión para que la función devuelva una única respuesta completa.
El uso de urllib.request mantiene este envoltorio ligero y portátil, y el guard timeout=45 evita que tu flujo de trabajo se cuelgue indefinidamente si el modelo es lento o el servidor está caído. Por último, la función extrae el resultado del modelo del campo « response » (Nombre del archivo de salida) y devuelve texto limpio, que posteriormente se utiliza para escribir un archivo « analysis_report.md » (Nombre del archivo de salida).
Aquí hay un pequeño script de inicio para iniciar la interfaz de usuario web local que acepta cargas y activa OpenClaw en segundo plano.
set -euo pipefail
ROOT="$(cd "$(dirname "$0")" && pwd)"
cd "$ROOT/.."
python3 ../web_assistant.pyEste script hace tres cosas:
set -euo pipefail Hace que el script falle rápidamente, es decir, se detiene ante los errores, trata las variables no definidas como errores y evita los fallos silenciosos en las tuberías.ROOT=... resuelve el directorio donde se encuentra el script, por lo que funciona incluso si lo ejecutas desde otro lugar.cd "$ROOT/.." Se desplaza a la raíz del proyecto esperada y, a continuación, inicia web_assistant.py, que aloja la interfaz de usuario y gestiona todo el proceso.Una vez que este script se está ejecutando, la interfaz de usuario de tu navegador se convierte en la puerta de entrada a la demostración.
Para el paso final, ejecutamos el sistema utilizando una configuración de dos procesos. La puerta de enlace OpenClaw se encarga de ejecutar todas las tareas, mientras que la interfaz web sirve como capa de usuario para enviar solicitudes y ver los resultados generados.
Antes de iniciar la interfaz, primero iniciamos la puerta de enlace OpenClaw. Este proceso actúa como la capa de ejecución del sistema, gestionando las solicitudes de los agentes, cargando la habilidad del espacio de trabajo, invocando herramientas locales y enrutando las llamadas de razonamiento al modelo Ollama.
export OPENCLAW_CONFIG_PATH="$PWD/.openclaw-local/openclaw.json"
openclaw gateway --forceEn este terminal, OPENCLAW_CONFIG_PATH apunta OpenClaw a la configuración local del proyecto, que es donde fijamos el modelo predeterminado en ollama/qwen3:8b y desactivamos la búsqueda web por motivos de privacidad. A continuación, openclaw gateway --force inicia la puerta de enlace aunque OpenClaw considere que ya hay algo en ejecución o parcialmente configurado.
Cuando la puerta de enlace está activa, está lista para aceptar mensajes de agentes locales (incluido nuestro comando de barra inclinada /local-data-analyst ).
Una vez que la puerta de enlace está en funcionamiento, iniciamos la interfaz web, que recopila las entradas de los usuarios, envía cada solicitud al agente OpenClaw local y muestra los gráficos, informes y trazas de ejecución generados.
./local_data_analyst/run_web.sh
A continuación, abre:
http://127.0.0.1:8765El servidor web se ejecuta en 127.0.0.1, por lo que solo se puede acceder a él desde tu equipo. Al hacer clic en Ejecutar análisis, la interfaz de usuario escribe una carpeta de ejecución, construye el comando de barra, invoca openclaw agent --local y, a continuación, sondea el disco en busca de los archivos de salida para poder previsualizarlos:
trend_chart.pnganalysis_report.mdtool_trace.jsonEl resultado final será similar a este. Puedes probar esta demostración utilizando algunos archivos de ejemplo.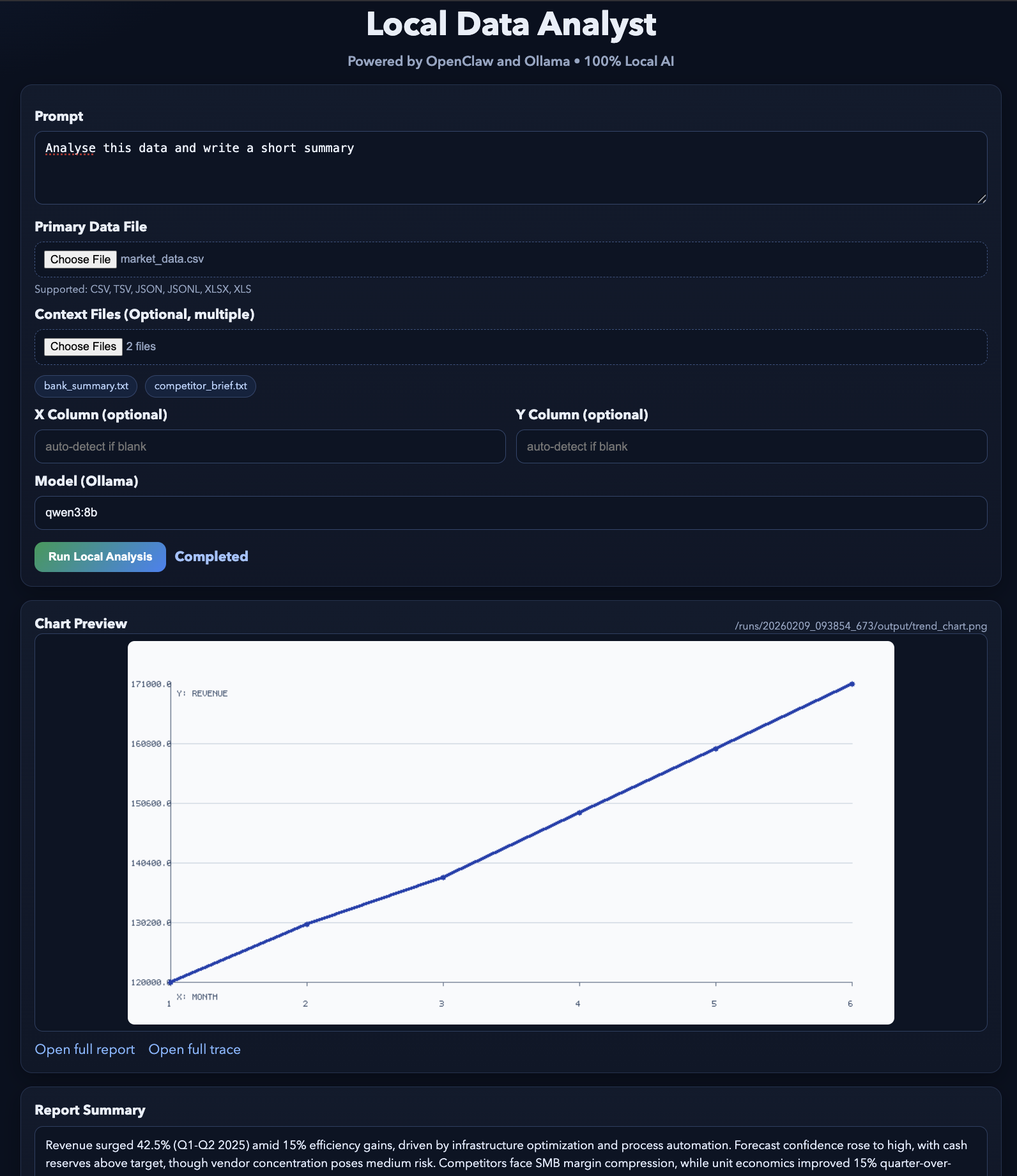
En este tutorial, hemos creado una aplicación de IA local en la que una sencilla interfaz web activa un flujo de trabajo completo impulsado por OpenClaw y un modelo Ollama local. En lugar de llamar a API externas, el sistema mantiene todo el bucle en tu máquina.
OpenClaw se encarga de la coordinación y la ejecución de herramientas, mientras que Ollama proporciona la capa de inteligencia local. El resultado es un flujo de trabajo de tipo agente en el que una sola solicitud genera artefactos estructurados, como visualizaciones, informes y registros de auditoría.
Desde aquí, puedes ampliar este proyecto en varias direcciones. Podrías añadir nuevas funciones al espacio de trabajo para diferentes flujos de trabajo, integrar herramientas locales adicionales (por ejemplo, consultas a bases de datos o búsqueda de documentos) o conectar OpenClaw a canales de mensajería como Slack o WhatsApp para un acceso remoto seguro.
También puedes probar diferentes modelos de Ollama para equilibrar el rendimiento y la calidad en función de tu hardware.
Para obtener más información sobre cómo trabajar con IA en tus flujos de trabajo, te recomiendo que consultes el curso curso Codificación asistida por IA para programadores.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Austin Chia
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Duong Vu


