
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
PaliGemma 2 Mix ist ein multimodales KI-Modell, das von Google entwickelt wurde. Es ist eine verbesserte Version des PaliGemma Vision Language Model (VLM)und integriert erweiterte Funktionen des SigLIP-Vision-Modells und der Gemma 2-Sprachmodelle.
In diesem Tutorial erkläre ich dir, wie du mit PaliGemma 2 Mix einen KI-gesteuerten Rechnungsscanner und Ausgabenanalysator bauen kannst:
Wir konzentrieren uns zwar auf die Entwicklung eines Tools für finanzielle Einblicke, aber du kannst das, was du in diesem Blog lernst, auch für andere Anwendungsfälle von PaliGemma 2 Mix nutzen, z. B. für Bildsegmentierung, Objekterkennung und die Beantwortung von Fragen.
PaliGemma 2 Mix ist ein fortschrittliches Vision-Language-Modell (VLM), das sowohl Bilder als auch Text als Eingabe verarbeitet und textbasierte Ausgaben erzeugt. Es wurde entwickelt, um eine breite Palette von multimodalen KI Aufgaben und unterstützt mehrere Sprachen.
PaliGemma 2 wurde für eine breite Palette von visuell-sprachlichen Aufgaben entwickelt, darunter Bild- und kurze Videobeschriftungen, Beantwortung visueller Fragen, optische Zeichenerkennung (OCR), Objekterkennung und Segmentierung.
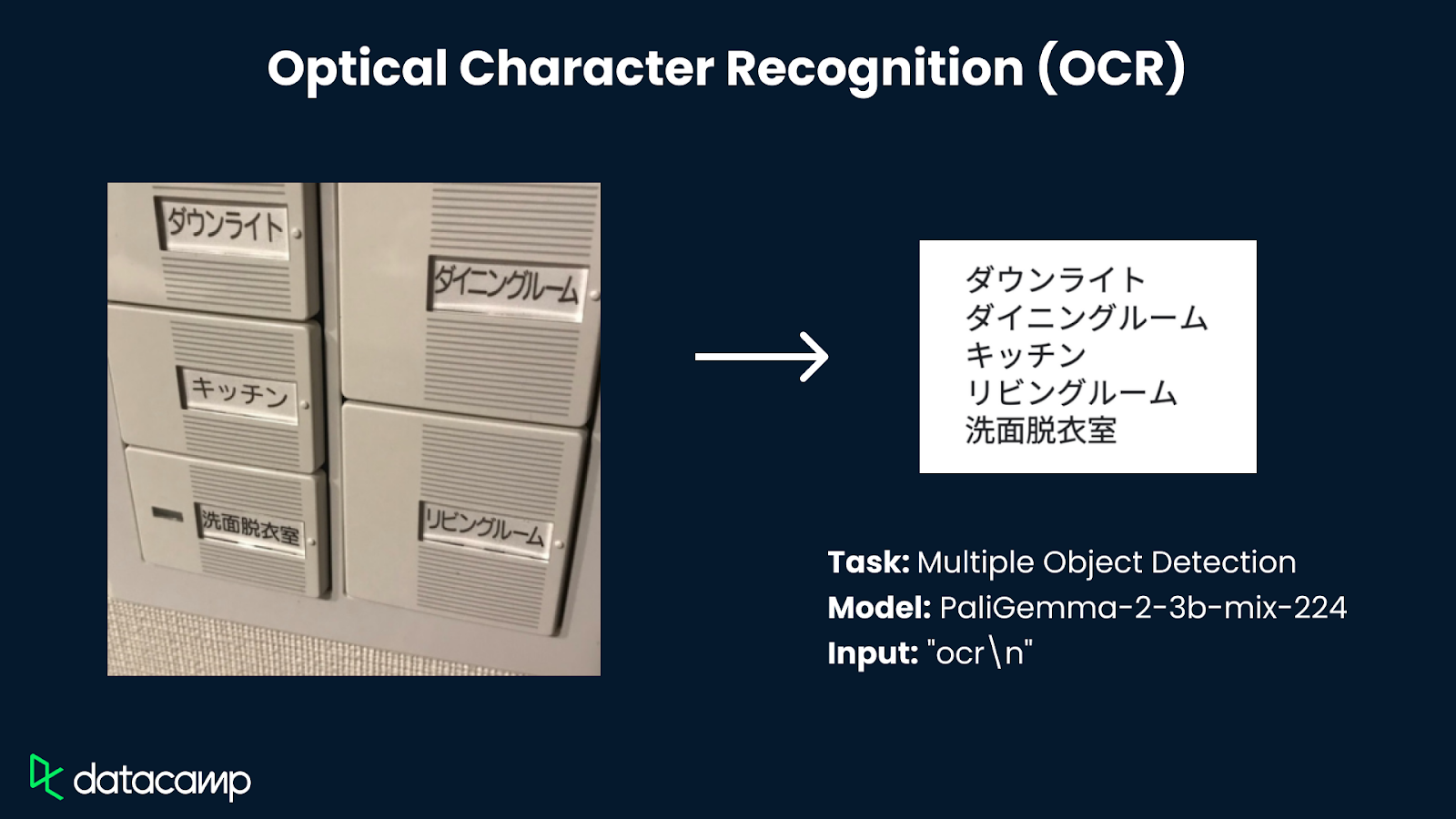
Quelle der im Diagramm verwendeten Bilder: Google
Das PaliGemma 2 Mix Modell ist für:
Weitere Informationen über das PaliGemma 2 Mix Modell findest du im offiziellen Artikel zur Veröffentlichung.
Lass uns die wichtigsten Schritte skizzieren, die wir unternehmen werden:
Bevor wir beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
pip install gradio -U bitsandbytes -U transformers -qSobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
import gradio as gr
import torch
import pandas as pd
import matplotlib.pyplot as plt
from transformers import PaliGemmaForConditionalGeneration, PaliGemmaProcessor, BitsAndBytesConfig
from transformers import BitsAndBytesConfig
from PIL import Image
import reWir konfigurieren und laden das PaliGemma 2 Mix-Modell mit Quantisierung um die Leistung zu optimieren. Für diese Demo verwenden wir das 10b-Parameter-Modell mit einer Auflösung des Eingangsbildes von 448 x 448. Du brauchst mindestens eine T4-GPU mit 40 GB Speicher (Colab-Konfiguration), um dieses Modell zu betreiben.
device = "cuda" if torch.cuda.is_available() else "cpu"
# Model setup
model_id = "google/paligemma2-10b-mix-448"
bnb_config = BitsAndBytesConfig(
load_in_8bit=True, # Change to load_in_4bit=True for even lower memory usage
llm_int8_threshold=6.0,
)
# Load model with quantization
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id, quantization_config=bnb_config
).eval()
# Load processor
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Print success message
print("Model and processor loaded successfully!")Die BitsAndBytes-Quantisierung hilft dabei, die Speichernutzung zu reduzieren und gleichzeitig die Leistung beizubehalten, so dass große Modelle auf begrenzten GPU-Ressourcen ausgeführt werden können. In dieser Implementierung verwenden wir eine 4-Bit-Quantisierung, um die Speichereffizienz weiter zu optimieren.
Wir laden das Modell mit der Klasse PaliGemmaForConditionalGeneration aus der Bibliothek transformers, indem wir die Modell-ID und die Quantisierungskonfiguration übergeben. Auf ähnliche Weise laden wir den Prozessor, der die Eingaben in Tensoren vorverarbeitet, bevor er sie an das Modell weitergibt.
Sobald die Modellsplitter geladen sind, verarbeiten wir die Bilder, bevor wir sie an das Modell weitergeben, um die Kompatibilität der Bildformate zu erhalten und Einheitlichkeit zu erreichen. Wir konvertieren Bilder in das RGB-Format:
def ensure_rgb(image: Image.Image) -> Image.Image:
if image.mode != "RGB":
image = image.convert("RGB")
return imageJetzt sind unsere Bilder bereit für Schlussfolgerungen.
Jetzt richten wir die Hauptfunktion für die Inferenz mit dem Modell ein. Diese Funktion nimmt Eingabebilder und Fragen auf, baut sie in Prompts ein und leitet sie über den Prozessor an das Modell weiter, damit es daraus Schlüsse ziehen kann.
def ask_model(image: Image.Image, question: str) -> str:
prompt = f"<image> answer en {question}"
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device)
with torch.inference_mode():
generated_ids = model.generate(
**inputs,
max_new_tokens=50,
do_sample=False
)
result = processor.batch_decode(generated_ids, skip_special_tokens=True)
return result[0].strip()Nachdem wir nun die Hauptfunktion fertiggestellt haben, arbeiten wir als Nächstes daran, die wichtigsten Parameter aus dem Bild zu extrahieren - in unserem Fall sind das die Gesamtbetrag und Warenkategorie.
def extract_total_amount(image: Image.Image) -> float:
question = "ocr\n what is the total amount? in numbers only"
answer = ask_model(image, question)
print(f"Answer from model: {answer}")
try:
amounts = re.findall(r'\d+\.\d+|\d+', answer) # Capture both integer and decimal values
if amounts:
return float(amounts[-1]) # Get the last valid amount as the total
except ValueError:
pass
return 0.0Die Funktion extract_total_amount() verarbeitet ein Bild, um mithilfe von OCR den Gesamtbetrag aus einem Kassenbon zu extrahieren. Sie konstruiert eine Abfrage (Frage), die das Modell anweist, nur numerische Werte zu extrahieren, und ruft dann die Funktion ask_model() auf, um eine Antwort des Modells zu generieren.
def categorize_goods(image: Image.Image) -> str:
question = "what is the category of goods in the image - Grocery/ Clothing/ Electronics/ Other?"
answer = ask_model(image, question)
print(f"Category from model: {answer}")
answer = answer.split("\n")[-1].strip().capitalize()
valid_categories = ["Grocery", "Clothing", "Electronics", "Other"]
return answer if answer in valid_categories else "Other"Die Funktion categorize_goods() klassifiziert die Art der Waren in einem Bild, indem sie das Modell mit einer vordefinierten Frage auffordert, mögliche Kategorien aufzulisten: Lebensmittel, Kleidung, Elektronik oder andere. Die Funktion ask_model() verarbeitet dann das Bild und gibt eine textuelle Antwort zurück. Wenn die verarbeitete Antwort mit einer der vordefinierten gültigen Kategorien übereinstimmt, wird diese Kategorie zurückgegeben - andernfalls wird standardmäßig die Kategorie "Sonstige" verwendet.
Wir haben alle wichtigen Funktionen parat, also lass uns die Ausgaben analysieren.
def generate_spending_chart(categories: dict):
filtered_categories = {k: v for k, v in categories.items() if v > 0} # Remove zero-value categories
labels = list(filtered_categories.keys())
values = list(filtered_categories.values())
if not values or sum(values) == 0:
fig, ax = plt.subplots()
ax.text(0.5, 0.5, "No Spending Data", ha="center", va="center", fontsize=12)
ax.axis("off")
return fig
fig, ax = plt.subplots()
ax.pie(values, labels=labels, autopct='%1.1f%%', startangle=90)
ax.axis('equal')
plt.title("Spending Distribution")
return figDie obige Funktion erstellt ein Tortendiagramm, um die Verteilung der Ausgaben auf verschiedene Kategorien zu visualisieren. Wenn keine gültigen Ausgabendaten vorhanden sind, wird eine leere Zahl mit der Meldung "Keine Ausgabendaten" erzeugt. Andernfalls wird ein Tortendiagramm mit Kategoriebeschriftungen und Prozentwerten erstellt, das eine proportionale und gut ausgerichtete Visualisierung gewährleistet.
Normalerweise müssen wir mehrere Rechnungen analysieren, also erstellen wir eine Funktion, die alle unsere Rechnungen gleichzeitig verarbeitet.
def process_multiple_bills(files: list):
results = []
images = []
total_spending = 0
category_totals = {"Grocery": 0, "Clothing": 0, "Electronics": 0, "Other": 0}
for file in files:
image = Image.open(file)
image = ensure_rgb(image)
images.append(image)
total_amount = extract_total_amount(image)
category = categorize_goods(image)
total_spending += total_amount
category_totals[category] += total_amount
results.append({"Bill": len(results) + 1, "Category": category, "Total Amount": f"₹{total_amount:.2f}"})
pie_chart = generate_spending_chart(category_totals)
summary_text = f"**Total Spending Across All Bills:** ₹{total_spending:.2f}"
return images, pd.DataFrame(results), summary_text, pie_chartUm mehrere Rechnungen auf einmal zu analysieren, führen wir die folgenden Schritte durch:
DataFrame der Zusammenfassungen der Gesetzesentwürfe, die Zusammenfassung der Gesamtausgaben und das Ausgabendiagramm zurück.Jetzt sind alle wichtigen logischen Funktionen vorhanden. Als Nächstes arbeiten wir daran, mit Gradio eine interaktive Benutzeroberfläche zu erstellen.
def gradio_demo():
with gr.Blocks() as demo:
gr.Markdown("## PaliGemma 2 Mix Powered- Multiple Bill Scanner\nUpload multiple bill images, and this demo will extract text, categorize spending, and generate insights.")
with gr.Row():
with gr.Column():
image_input = gr.File(file_count="multiple", file_types=["image"], label="Upload Bill Images")
submit_button = gr.Button("Process Bills")
with gr.Column():
image_output = gr.Gallery(label="Uploaded Bills")
table_output = gr.Dataframe(label="Bill Summary")
summary_output = gr.Text(label="Total Spending Summary")
chart_output = gr.Plot(label="Aggregated Spending Distribution")
submit_button.click(
fn=process_multiple_bills,
inputs=image_input,
outputs=[image_output, table_output, summary_output, chart_output]
)
demo.launch(debug=True)
if __name__ == "__main__":
gradio_demo()Der obige Code erstellt eine strukturierte Gradio-Benutzeroberfläche mit einem Datei-Uploader für mehrere Bilder und einem Submit-Button, um die Verarbeitung auszulösen. Nach der Übermittlung werden die hochgeladenen Rechnungsbilder in einer Galerie angezeigt, die extrahierten Daten werden in einer Tabelle dargestellt, die Gesamtausgaben werden in einem Text zusammengefasst und es wird ein Kreisdiagramm zur Ausgabenverteilung erstellt.
Die Funktion verbindet die Benutzereingaben mit der Funktion process_multiple_bills() und sorgt so für eine nahtlose Datenextraktion und -visualisierung. Schließlich startet die Funktion demo.launch() die Gradio-App für Echtzeit-Interaktion.
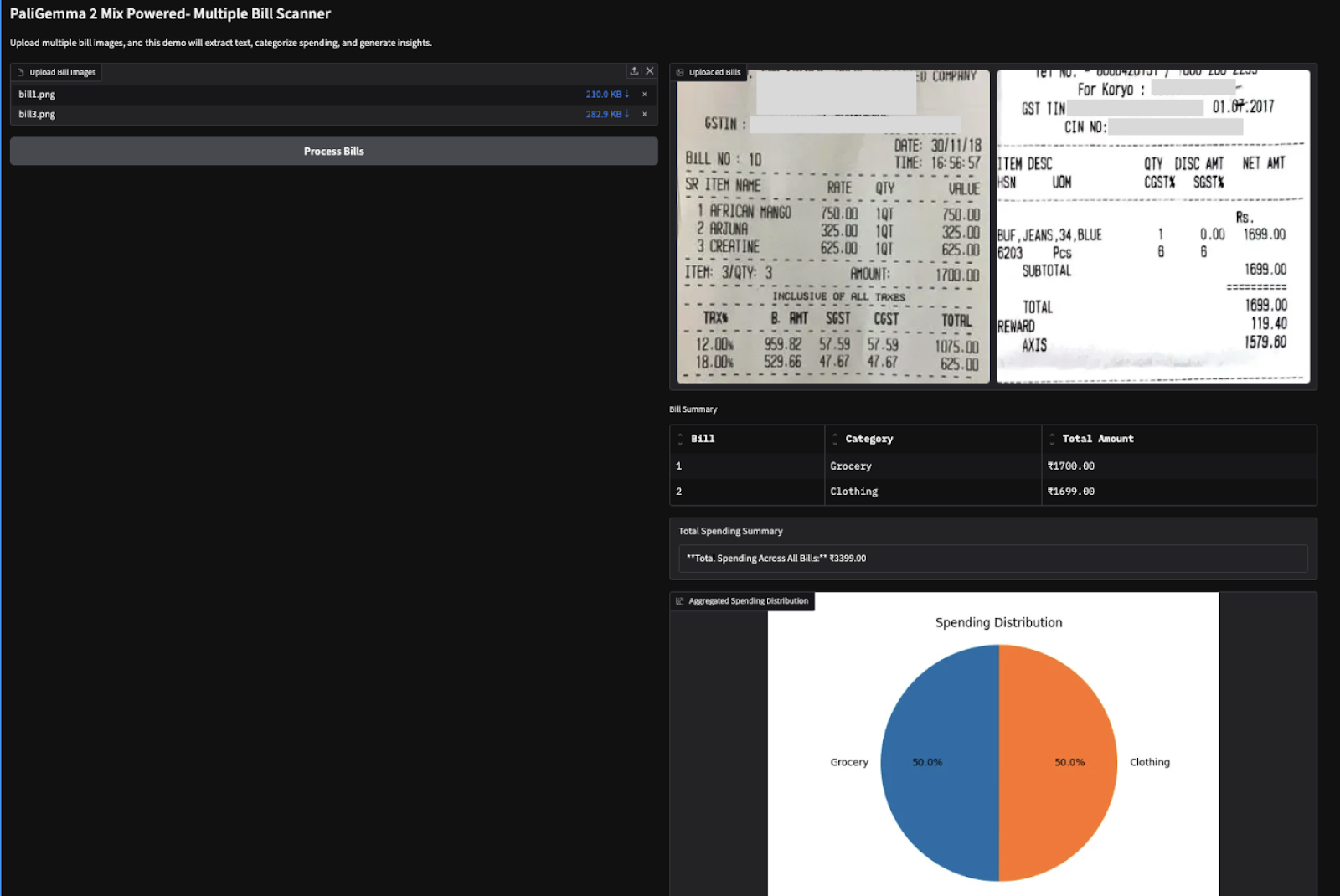
Ich habe diese Demo auch mit zwei bildbasierten Rechnungen (Amazon-Einkaufsrechnung) ausprobiert und folgende Ergebnisse erhalten.
Hinweis: VLMs finden es schwierig, Zahlen zu extrahieren, was manchmal zu falschen Ergebnissen führt. So wurde zum Beispiel der falsche Gesamtbetrag für die zweite Rechnung unten abgezogen. Dies lässt sich durch die Verwendung größerer Modelle oder einfach durch Feinabstimmung der vorhandenen Modelle.
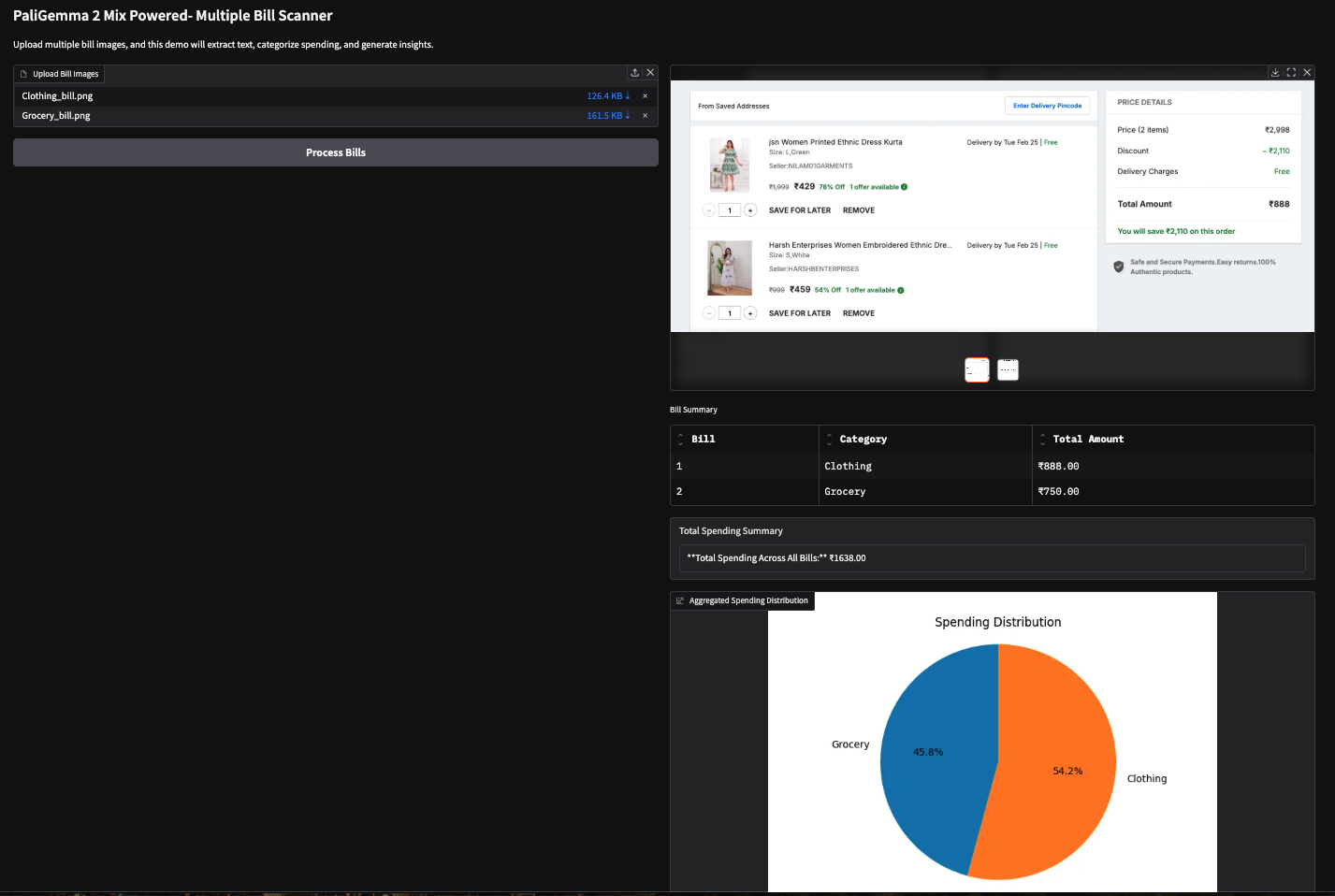
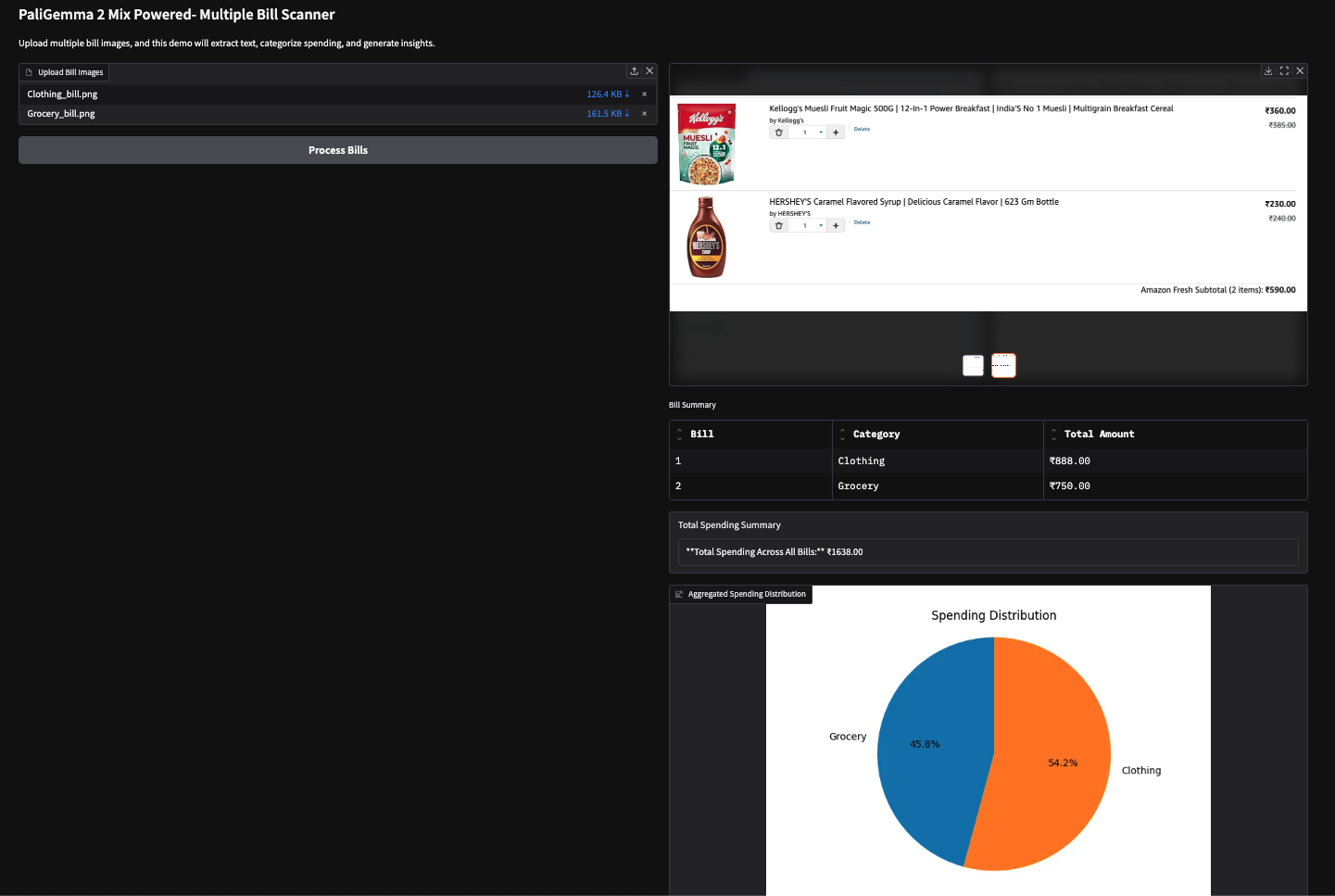
In diesem Tutorial haben wir mit PaliGemma 2 Mix einen KI-gesteuerten Mehrfach-Rechnungsscanner gebaut, mit dem wir unsere Ausgaben aus den Quittungen extrahieren und kategorisieren können. Wir haben die OCR- und Klassifizierungsfunktionen von PaliGemma 2 Mix genutzt, um die Ausgaben mühelos zu analysieren. Ich ermutige dich, dieses Tutorial an deinen eigenen Anwendungsfall anzupassen.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs