
Programa
Desenvolvimento de aplicativos de IA
21 h
PaliGemma 2 Mix é um modelo de IA multimodal desenvolvido pelo Google. É uma versão aprimorada do PaliGemma modelo de linguagem de visão (VLM)integrando recursos avançados do modelo de visão SigLIP e dos modelos de linguagem Gemma 2.
Neste tutorial, explicarei como usar o PaliGemma 2 Mix para criar um scanner de contas e um analisador de gastos com tecnologia de IA capaz de:
Embora nosso foco seja a criação de uma ferramenta de insights financeiros, você pode usar o que aprendeu neste blog para explorar outros casos de uso do PaliGemma 2 Mix, como segmentação de imagens, detecção de objetos e resposta a perguntas.
O PaliGemma 2 Mix é um modelo avançado de visão e linguagem (VLM) que processa imagens e textos como entrada e gera resultados baseados em texto. Ele foi projetado para lidar com uma gama diversificada de tarefas multimodais de IA multimodal, com suporte a vários idiomas.
O PaliGemma 2 foi projetado para uma ampla gama de tarefas de linguagem visual, incluindo legendas de imagens e vídeos curtos, respostas a perguntas visuais, reconhecimento óptico de caracteres (OCR), detecção de objetos e segmentação.
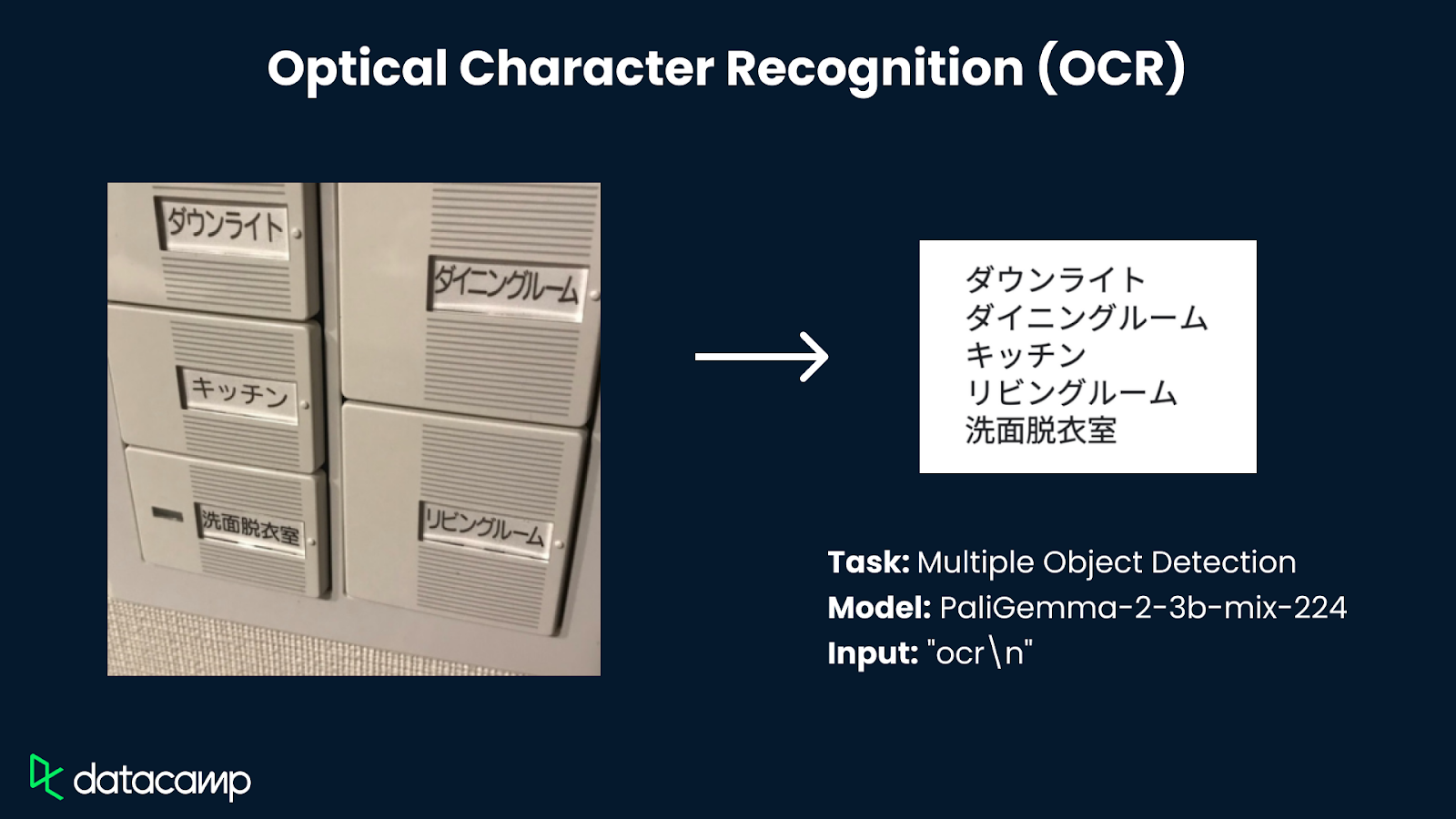
Fonte das imagens usadas no diagrama: Google
O modelo PaliGemma 2 Mix foi projetado para você:
Você pode encontrar mais informações sobre o modelo PaliGemma 2 Mix no artigo oficial de lançamento.
Vamos delinear as principais etapas que vamos seguir:
Antes de começarmos, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
pip install gradio -U bitsandbytes -U transformers -qQuando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
import gradio as gr
import torch
import pandas as pd
import matplotlib.pyplot as plt
from transformers import PaliGemmaForConditionalGeneration, PaliGemmaProcessor, BitsAndBytesConfig
from transformers import BitsAndBytesConfig
from PIL import Image
import reConfiguramos e carregamos o modelo PaliGemma 2 Mix com quantização para otimizar o desempenho. Para esta demonstração, usaremos o modelo de parâmetro modelo de parâmetro 10b com resolução de imagem de entrada de 448 x 448. Você precisa de um mínimo de GPU T4 com 40 GB de memória (configuração Colab) para executar esse modelo.
device = "cuda" if torch.cuda.is_available() else "cpu"
# Model setup
model_id = "google/paligemma2-10b-mix-448"
bnb_config = BitsAndBytesConfig(
load_in_8bit=True, # Change to load_in_4bit=True for even lower memory usage
llm_int8_threshold=6.0,
)
# Load model with quantization
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id, quantization_config=bnb_config
).eval()
# Load processor
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Print success message
print("Model and processor loaded successfully!")A quantização BitsAndBytes ajuda a reduzir o uso da memória e, ao mesmo tempo, manter o desempenho, possibilitando a execução de modelos grandes com recursos limitados de GPU. Nessa implementação, usamos a quantização de 4 bits para otimizar ainda mais a eficiência da memória.
Carregamos o modelo usando a classe PaliGemmaForConditionalGeneration da biblioteca transformers, passando o ID do modelo e a configuração de quantização. Da mesma forma, carregamos o processador, que pré-processa as entradas em tensores antes de passá-las para o modelo.
Depois que os fragmentos do modelo são carregados, processamos as imagens antes de passá-las para o modelo para manter a compatibilidade do formato da imagem e obter uniformidade. Convertemos as imagens para o formato RGB:
def ensure_rgb(image: Image.Image) -> Image.Image:
if image.mode != "RGB":
image = image.convert("RGB")
return imageAgora, nossas imagens estão prontas para a inferência.
Agora, configuramos a função principal para executar a inferência com o modelo. Essa função recebe imagens e perguntas de entrada, incorpora-as em prompts e as passa para o modelo por meio do processador para inferência.
def ask_model(image: Image.Image, question: str) -> str:
prompt = f"<image> answer en {question}"
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device)
with torch.inference_mode():
generated_ids = model.generate(
**inputs,
max_new_tokens=50,
do_sample=False
)
result = processor.batch_decode(generated_ids, skip_special_tokens=True)
return result[0].strip()Agora que temos a função principal pronta, trabalharemos em seguida para extrair os parâmetros principais da imagem - em nosso caso, são os seguintes valor total e a categoria da mercadoria.
def extract_total_amount(image: Image.Image) -> float:
question = "ocr\n what is the total amount? in numbers only"
answer = ask_model(image, question)
print(f"Answer from model: {answer}")
try:
amounts = re.findall(r'\d+\.\d+|\d+', answer) # Capture both integer and decimal values
if amounts:
return float(amounts[-1]) # Get the last valid amount as the total
except ValueError:
pass
return 0.0A função extract_total_amount() processa uma imagem para extrair o valor total de um recibo usando OCR. Ele constrói uma consulta (pergunta) instruindo o modelo a extrair somente valores numéricos e, em seguida, chama a função ask_model() para gerar uma resposta do modelo.
def categorize_goods(image: Image.Image) -> str:
question = "what is the category of goods in the image - Grocery/ Clothing/ Electronics/ Other?"
answer = ask_model(image, question)
print(f"Category from model: {answer}")
answer = answer.split("\n")[-1].strip().capitalize()
valid_categories = ["Grocery", "Clothing", "Electronics", "Other"]
return answer if answer in valid_categories else "Other"A função categorize_goods() classifica o tipo de mercadoria em uma imagem, solicitando ao modelo uma pergunta predefinida que lista as possíveis categorias: mercearia, roupas, eletrônicos ou outros. A função ask_model() processa a imagem e retorna uma resposta textual. Se a resposta processada corresponder a qualquer uma das categorias válidas predefinidas, ela retornará essa categoria; caso contrário, o padrão será a categoria "Outros".
Temos todas as funções principais prontas, então vamos analisar os resultados.
def generate_spending_chart(categories: dict):
filtered_categories = {k: v for k, v in categories.items() if v > 0} # Remove zero-value categories
labels = list(filtered_categories.keys())
values = list(filtered_categories.values())
if not values or sum(values) == 0:
fig, ax = plt.subplots()
ax.text(0.5, 0.5, "No Spending Data", ha="center", va="center", fontsize=12)
ax.axis("off")
return fig
fig, ax = plt.subplots()
ax.pie(values, labels=labels, autopct='%1.1f%%', startangle=90)
ax.axis('equal')
plt.title("Spending Distribution")
return figA função acima cria um gráfico de pizza para visualizar a distribuição de gastos em diferentes categorias. Se não houver dados de despesas válidos, você verá uma figura em branco com uma mensagem indicando "No Spending Data" (Sem dados de despesas). Caso contrário, ele cria um gráfico de pizza com rótulos de categoria e valores percentuais, garantindo uma visualização proporcional e bem alinhada.
Normalmente, temos várias contas para analisar, portanto, vamos criar uma função para processar todas as nossas contas simultaneamente.
def process_multiple_bills(files: list):
results = []
images = []
total_spending = 0
category_totals = {"Grocery": 0, "Clothing": 0, "Electronics": 0, "Other": 0}
for file in files:
image = Image.open(file)
image = ensure_rgb(image)
images.append(image)
total_amount = extract_total_amount(image)
category = categorize_goods(image)
total_spending += total_amount
category_totals[category] += total_amount
results.append({"Bill": len(results) + 1, "Category": category, "Total Amount": f"₹{total_amount:.2f}"})
pie_chart = generate_spending_chart(category_totals)
summary_text = f"**Total Spending Across All Bills:** ₹{total_spending:.2f}"
return images, pd.DataFrame(results), summary_text, pie_chartPara analisar várias contas de uma só vez, executamos as seguintes etapas:
DataFrame de resumos de projetos de lei, o resumo de gastos totais e o gráfico de gastos.Agora, temos todas as principais funções lógicas implementadas. Em seguida, trabalharemos na criação de uma interface de usuário interativa com o Gradio.
def gradio_demo():
with gr.Blocks() as demo:
gr.Markdown("## PaliGemma 2 Mix Powered- Multiple Bill Scanner\nUpload multiple bill images, and this demo will extract text, categorize spending, and generate insights.")
with gr.Row():
with gr.Column():
image_input = gr.File(file_count="multiple", file_types=["image"], label="Upload Bill Images")
submit_button = gr.Button("Process Bills")
with gr.Column():
image_output = gr.Gallery(label="Uploaded Bills")
table_output = gr.Dataframe(label="Bill Summary")
summary_output = gr.Text(label="Total Spending Summary")
chart_output = gr.Plot(label="Aggregated Spending Distribution")
submit_button.click(
fn=process_multiple_bills,
inputs=image_input,
outputs=[image_output, table_output, summary_output, chart_output]
)
demo.launch(debug=True)
if __name__ == "__main__":
gradio_demo()O código acima cria uma interface de usuário estruturada do Gradio com um carregador de arquivos para várias imagens e um botão de envio para acionar o processamento. Após o envio, as imagens de contas carregadas são exibidas em uma galeria, os dados extraídos são mostrados em uma tabela, o total de gastos é resumido em um texto e um gráfico de distribuição de gastos é gerado.
A função conecta as entradas do usuário à função process_multiple_bills(), garantindo a extração e a visualização perfeitas dos dados. Por fim, a função demo.launch() inicia o aplicativo Gradio para interação em tempo real.
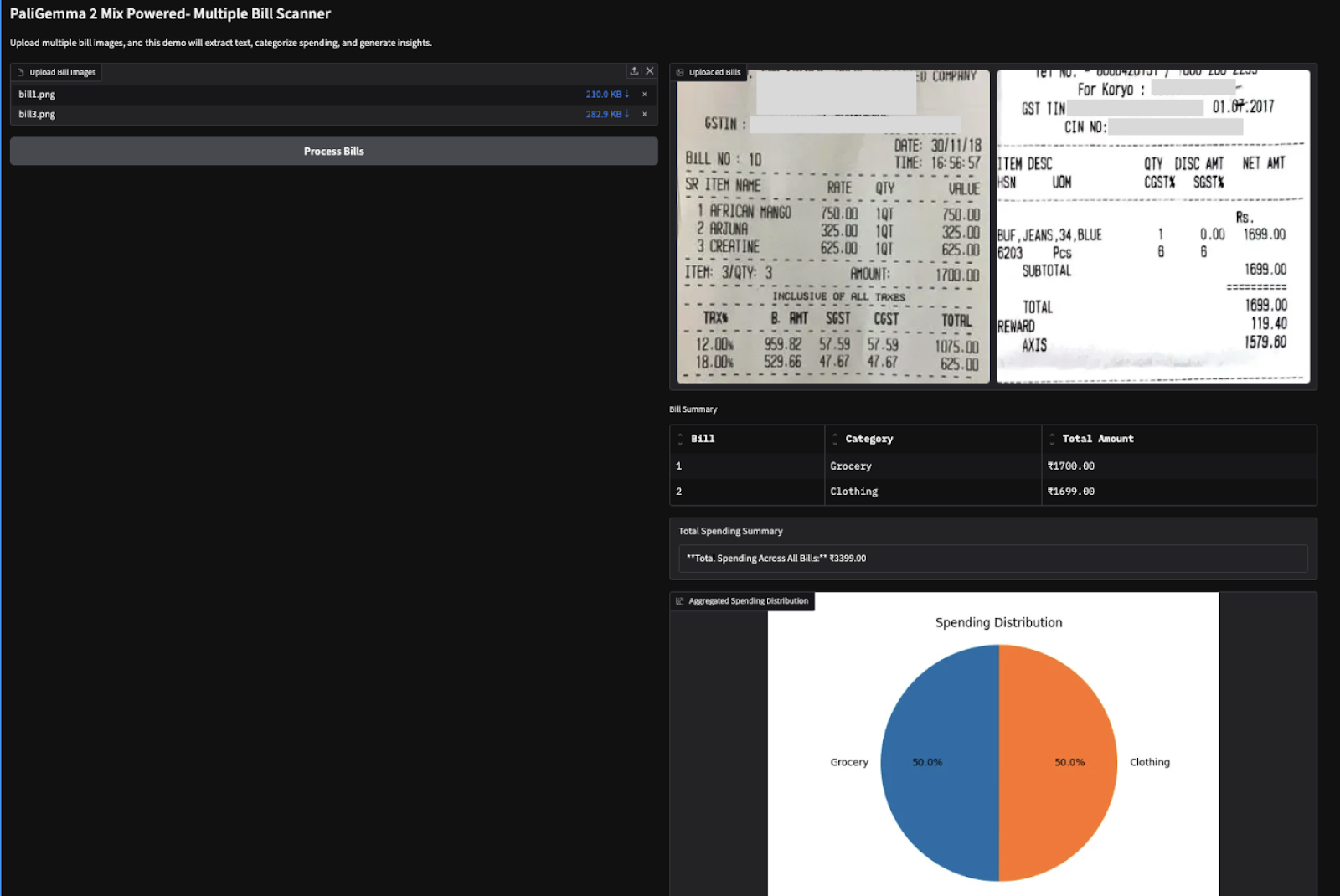
Também experimentei essa demonstração com duas faturas baseadas em imagens (fatura de compras da Amazon) e obtive os seguintes resultados.
Observação: Os VLMs têm dificuldade para extrair números, o que, às vezes, pode levar a resultados incorretos. Por exemplo, ele extraiu o valor total errado para a segunda fatura abaixo. Isso pode ser corrigido com o uso de modelos maiores ou simplesmente ajuste fino os existentes.
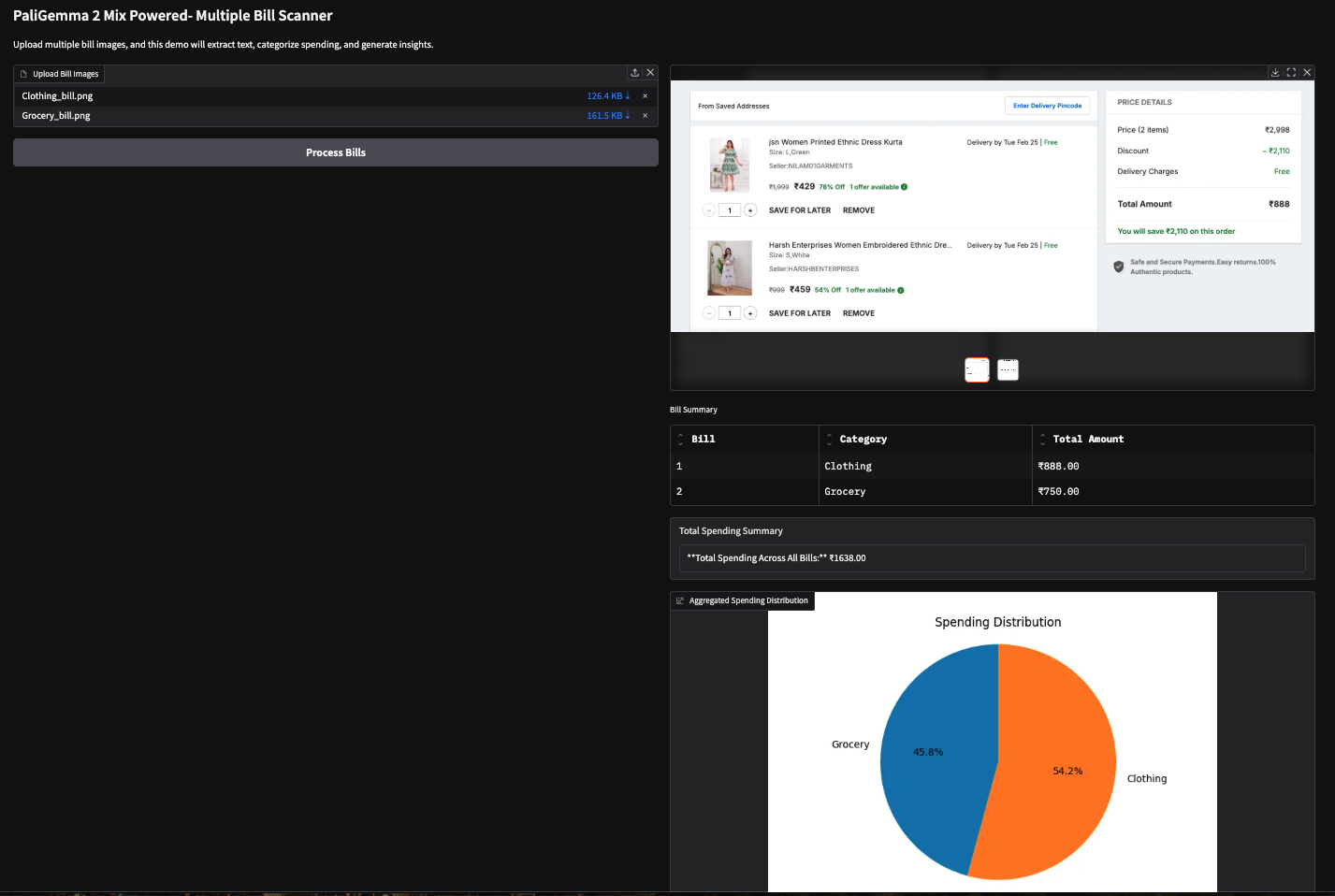
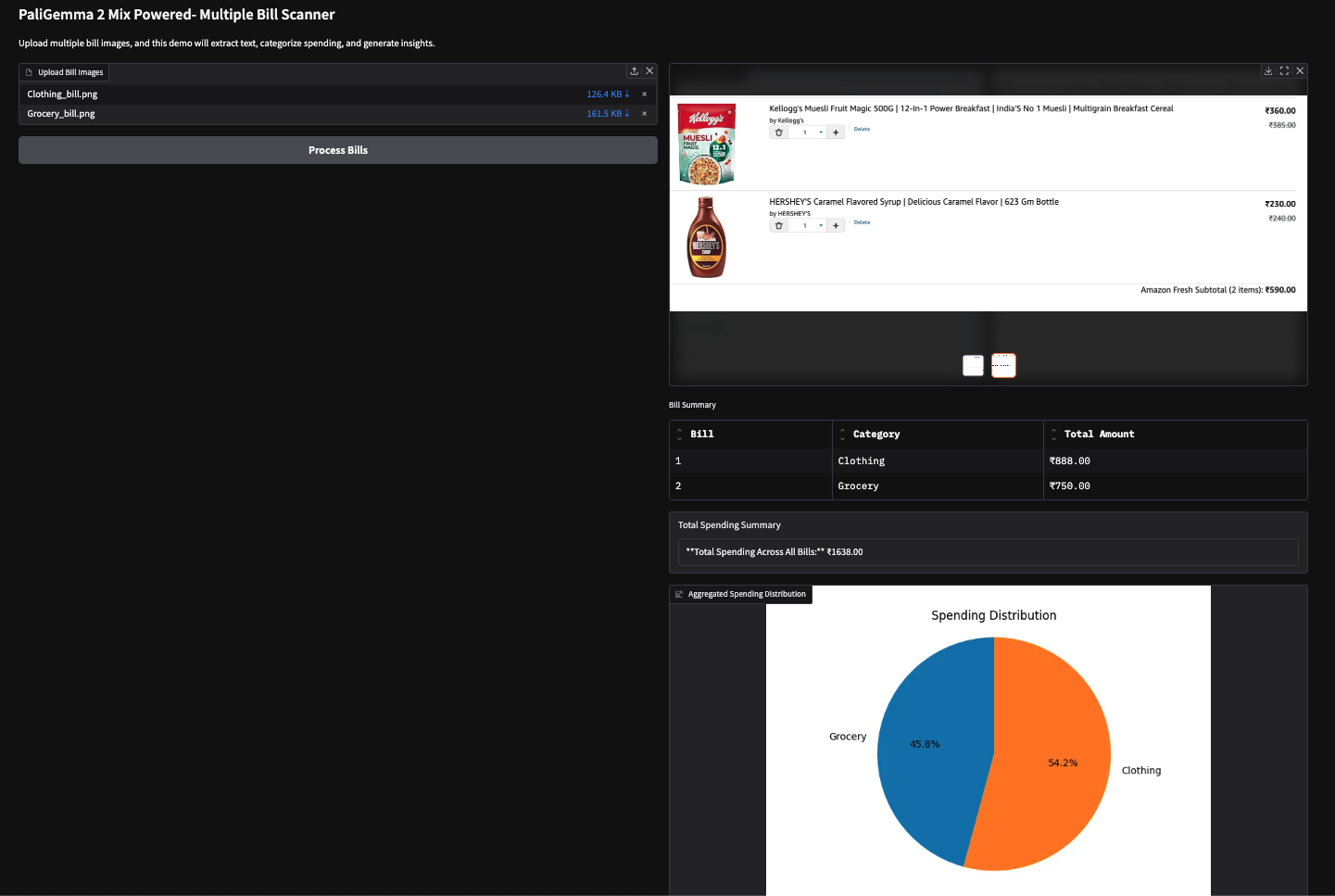
Neste tutorial, criamos um scanner de várias contas com tecnologia de IA usando o PaliGemma 2 Mix, que pode nos ajudar a extrair e categorizar nossas despesas a partir de recibos. Usamos os recursos de linguagem de visão do PaliGemma 2 Mix para OCR e classificação para analisar os insights de gastos sem esforço. Recomendo que você adapte este tutorial ao seu próprio caso de uso.
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Dimitri Didmanidze
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan

