
programa
Desarrollo de aplicaciones de IA
21 h
PaliGemma 2 Mix es un modelo de IA multimodal desarrollado por Google. Es una versión mejorada del PaliGemma modelo de lenguaje de visión (VLM)que integra funciones avanzadas del modelo de visión SigLIP y de los modelos de lenguaje Gemma 2.
En este tutorial, te explicaré cómo utilizar PaliGemma 2 Mix para construir un escáner de facturas y analizador de gastos basado en IA capaz de:
Aunque nos centraremos en crear una herramienta de información financiera, puedes utilizar lo que aprendas en este blog para explorar otros casos de uso de PaliGemma 2 Mix, como la segmentación de imágenes, la detección de objetos y la respuesta a preguntas.
PaliGemma 2 Mix es un modelo avanzado de visión-lenguaje (VLM) que procesa tanto imágenes como texto como entrada y genera salidas basadas en texto. Está diseñado para manejar una amplia gama de IA multimodal multimodal y admite varios idiomas.
PaliGemma 2 está diseñado para una amplia gama de tareas de visión-lenguaje, como subtitulado de imágenes y vídeos cortos, respuesta a preguntas visuales, reconocimiento óptico de caracteres (OCR), detección de objetos y segmentación.
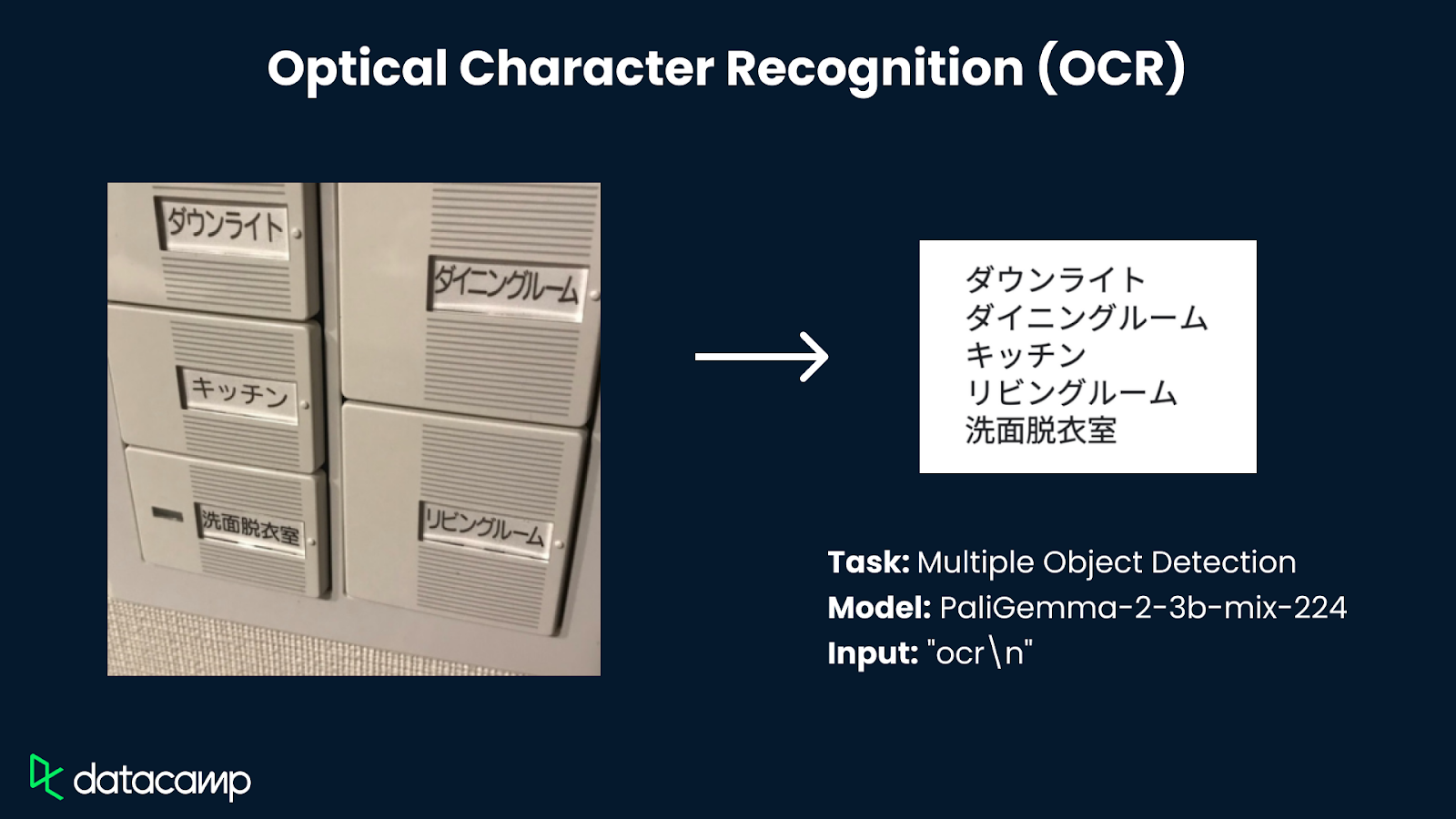
Fuente de las imágenes utilizadas en el esquema: Google
El modelo PaliGemma 2 Mix está diseñado para:
Puedes encontrar más información sobre el modelo PaliGemma 2 Mix en el artículo oficial.
Vamos a esbozar los pasos principales que vamos a dar:
Antes de empezar, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
pip install gradio -U bitsandbytes -U transformers -qUna vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
import gradio as gr
import torch
import pandas as pd
import matplotlib.pyplot as plt
from transformers import PaliGemmaForConditionalGeneration, PaliGemmaProcessor, BitsAndBytesConfig
from transformers import BitsAndBytesConfig
from PIL import Image
import reConfiguramos y cargamos el modelo PaliGemma 2 Mix con cuantización para optimizar el rendimiento. Para esta demostración, utilizaremos el modelo de parámetros 10b con una resolución de imagen de entrada de 448 x 448. Necesitas un mínimo de GPU T4 con 40 GB de memoria (configuración Colab) para ejecutar este modelo.
device = "cuda" if torch.cuda.is_available() else "cpu"
# Model setup
model_id = "google/paligemma2-10b-mix-448"
bnb_config = BitsAndBytesConfig(
load_in_8bit=True, # Change to load_in_4bit=True for even lower memory usage
llm_int8_threshold=6.0,
)
# Load model with quantization
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id, quantization_config=bnb_config
).eval()
# Load processor
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Print success message
print("Model and processor loaded successfully!")La cuantización BitsAndBytes ayuda a reducir el uso de memoria manteniendo el rendimiento, lo que permite ejecutar grandes modelos con recursos limitados de la GPU. En esta implementación, utilizamos una cuantización de 4 bits para optimizar aún más la eficiencia de la memoria.
Cargamos el modelo utilizando la clase PaliGemmaForConditionalGeneration de la biblioteca transformers pasando el ID del modelo y la configuración de la cuantización. Del mismo modo, cargamos el procesador, que preprocesa las entradas en tensores antes de pasarlas al modelo.
Una vez cargados los fragmentos del modelo, procesamos las imágenes antes de pasarlas al modelo para mantener la compatibilidad del formato de imagen y ganar uniformidad. Convertimos las imágenes a formato RGB:
def ensure_rgb(image: Image.Image) -> Image.Image:
if image.mode != "RGB":
image = image.convert("RGB")
return imageAhora, nuestras imágenes están listas para la inferencia.
Ahora, configuramos la función principal para ejecutar la inferencia con el modelo. Esta función toma imágenes y preguntas de entrada, las incorpora a las preguntas y las pasa al modelo a través del procesador para su inferencia.
def ask_model(image: Image.Image, question: str) -> str:
prompt = f"<image> answer en {question}"
inputs = processor(text=prompt, images=image, return_tensors="pt").to(device)
with torch.inference_mode():
generated_ids = model.generate(
**inputs,
max_new_tokens=50,
do_sample=False
)
result = processor.batch_decode(generated_ids, skip_special_tokens=True)
return result[0].strip()Ahora que ya tenemos lista la función principal, trabajaremos a continuación en la extracción de los parámetros clave de la imagen -en nuestro caso, son la importe total y la categoría de la mercancía.
def extract_total_amount(image: Image.Image) -> float:
question = "ocr\n what is the total amount? in numbers only"
answer = ask_model(image, question)
print(f"Answer from model: {answer}")
try:
amounts = re.findall(r'\d+\.\d+|\d+', answer) # Capture both integer and decimal values
if amounts:
return float(amounts[-1]) # Get the last valid amount as the total
except ValueError:
pass
return 0.0La función extract_total_amount() procesa una imagen para extraer el importe total de un recibo mediante OCR. Construye una consulta (pregunta) indicando al modelo que extraiga sólo valores numéricos, y luego llama a la función ask_model() para generar una respuesta del modelo.
def categorize_goods(image: Image.Image) -> str:
question = "what is the category of goods in the image - Grocery/ Clothing/ Electronics/ Other?"
answer = ask_model(image, question)
print(f"Category from model: {answer}")
answer = answer.split("\n")[-1].strip().capitalize()
valid_categories = ["Grocery", "Clothing", "Electronics", "Other"]
return answer if answer in valid_categories else "Other"La función categorize_goods() clasifica el tipo de mercancía de una imagen planteando al modelo una pregunta predefinida con una lista de posibles categorías: comestibles, ropa, electrónica u otros. A continuación, la función ask_model() procesa la imagen y devuelve una respuesta textual. Si la respuesta procesada coincide con alguna de las categorías válidas predefinidas, devuelve esa categoría; de lo contrario, se pasa por defecto a la categoría "Otros".
Ya tenemos listas todas las funciones clave, así que vamos a analizar las salidas.
def generate_spending_chart(categories: dict):
filtered_categories = {k: v for k, v in categories.items() if v > 0} # Remove zero-value categories
labels = list(filtered_categories.keys())
values = list(filtered_categories.values())
if not values or sum(values) == 0:
fig, ax = plt.subplots()
ax.text(0.5, 0.5, "No Spending Data", ha="center", va="center", fontsize=12)
ax.axis("off")
return fig
fig, ax = plt.subplots()
ax.pie(values, labels=labels, autopct='%1.1f%%', startangle=90)
ax.axis('equal')
plt.title("Spending Distribution")
return figLa función anterior crea un gráfico circular para visualizar la distribución del gasto en las distintas categorías. Si no existen datos de gasto válidos, genera una cifra en blanco con un mensaje que indica "No hay datos de gasto". Si no, crea un gráfico circular con etiquetas de categoría y valores porcentuales, garantizando una visualización proporcional y bien alineada.
Normalmente tenemos varias facturas que analizar, así que vamos a crear una función para procesar todas nuestras facturas simultáneamente.
def process_multiple_bills(files: list):
results = []
images = []
total_spending = 0
category_totals = {"Grocery": 0, "Clothing": 0, "Electronics": 0, "Other": 0}
for file in files:
image = Image.open(file)
image = ensure_rgb(image)
images.append(image)
total_amount = extract_total_amount(image)
category = categorize_goods(image)
total_spending += total_amount
category_totals[category] += total_amount
results.append({"Bill": len(results) + 1, "Category": category, "Total Amount": f"₹{total_amount:.2f}"})
pie_chart = generate_spending_chart(category_totals)
summary_text = f"**Total Spending Across All Bills:** ₹{total_spending:.2f}"
return images, pd.DataFrame(results), summary_text, pie_chartPara analizar varias facturas a la vez, realizamos los siguientes pasos:
DataFrame de resúmenes de facturas, el resumen de gastos totales y el gráfico de gastos.Ahora ya tenemos todas las funciones lógicas clave. A continuación, trabajaremos en la creación de una interfaz de usuario interactiva con Gradio.
def gradio_demo():
with gr.Blocks() as demo:
gr.Markdown("## PaliGemma 2 Mix Powered- Multiple Bill Scanner\nUpload multiple bill images, and this demo will extract text, categorize spending, and generate insights.")
with gr.Row():
with gr.Column():
image_input = gr.File(file_count="multiple", file_types=["image"], label="Upload Bill Images")
submit_button = gr.Button("Process Bills")
with gr.Column():
image_output = gr.Gallery(label="Uploaded Bills")
table_output = gr.Dataframe(label="Bill Summary")
summary_output = gr.Text(label="Total Spending Summary")
chart_output = gr.Plot(label="Aggregated Spending Distribution")
submit_button.click(
fn=process_multiple_bills,
inputs=image_input,
outputs=[image_output, table_output, summary_output, chart_output]
)
demo.launch(debug=True)
if __name__ == "__main__":
gradio_demo()El código anterior crea una interfaz de usuario de Gradio estructurada con un cargador de archivos para varias imágenes y un botón de envío para activar el procesamiento. Tras el envío, las imágenes de las facturas cargadas se muestran en una galería, los datos extraídos se muestran en una tabla, el gasto total se resume en texto y se genera un gráfico circular de distribución del gasto.
La función conecta las entradas del usuario con la función process_multiple_bills(), garantizando una extracción y visualización de datos sin fisuras. Por último, la función demo.launch() inicia la app Gradio para interactuar en tiempo real.
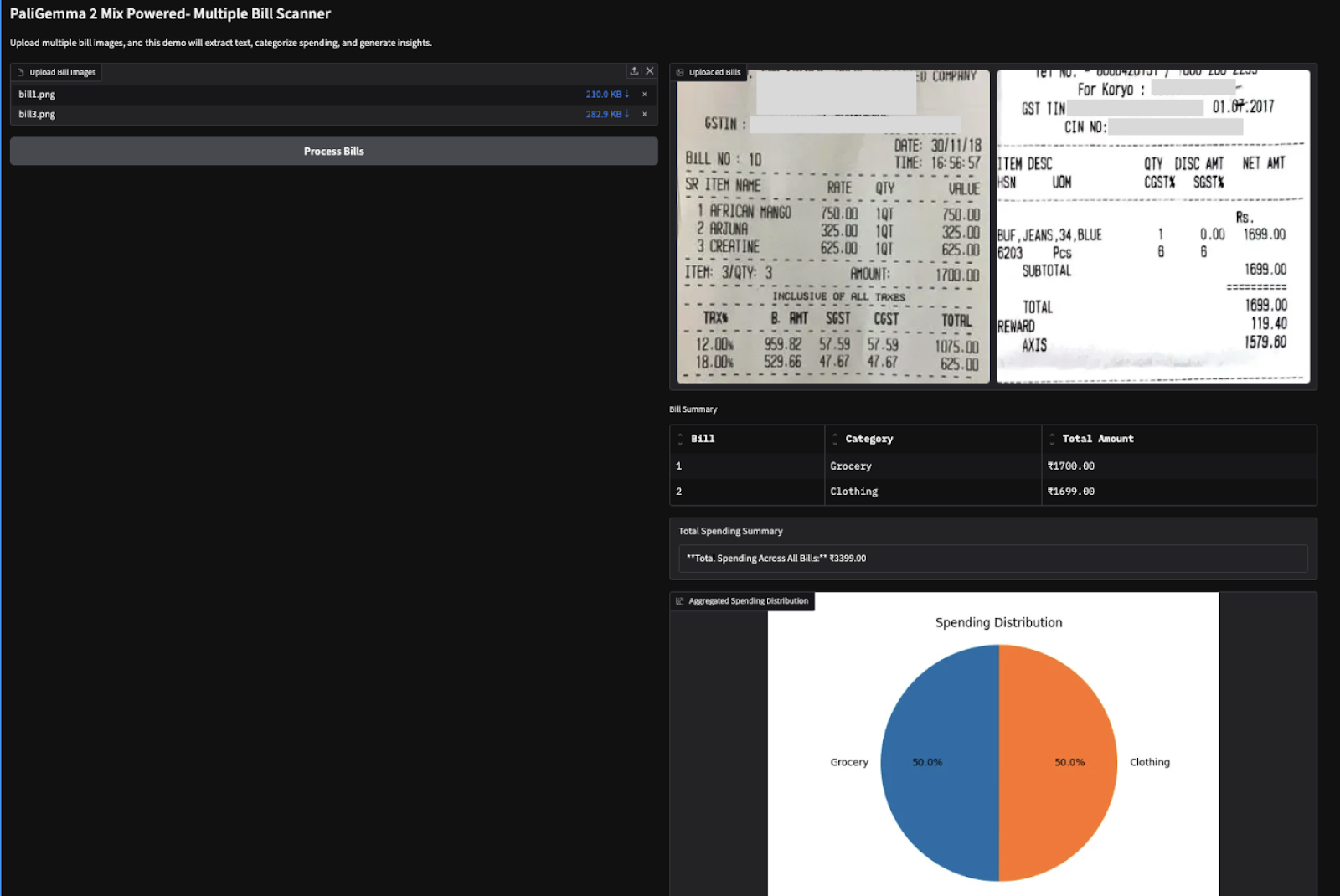
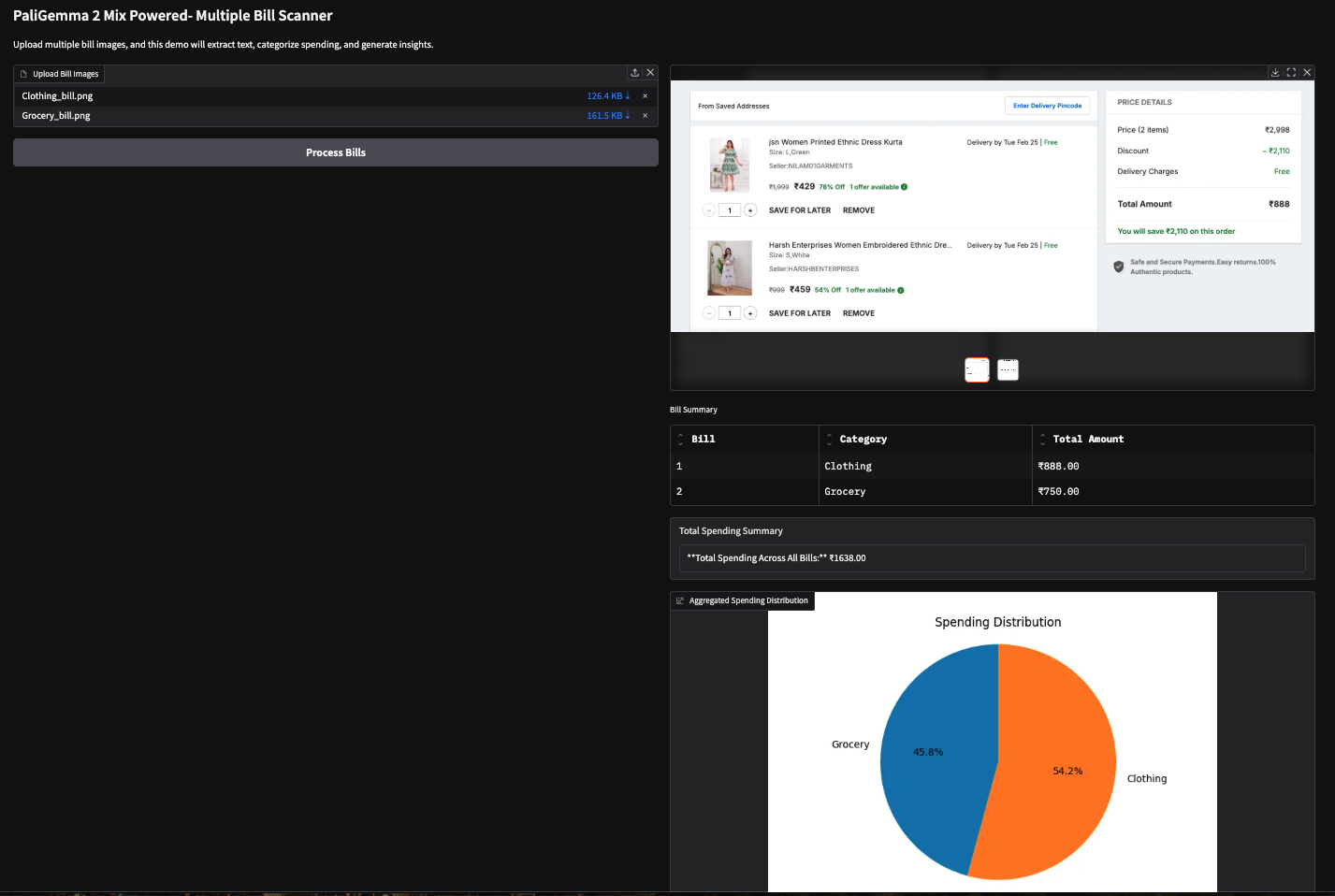
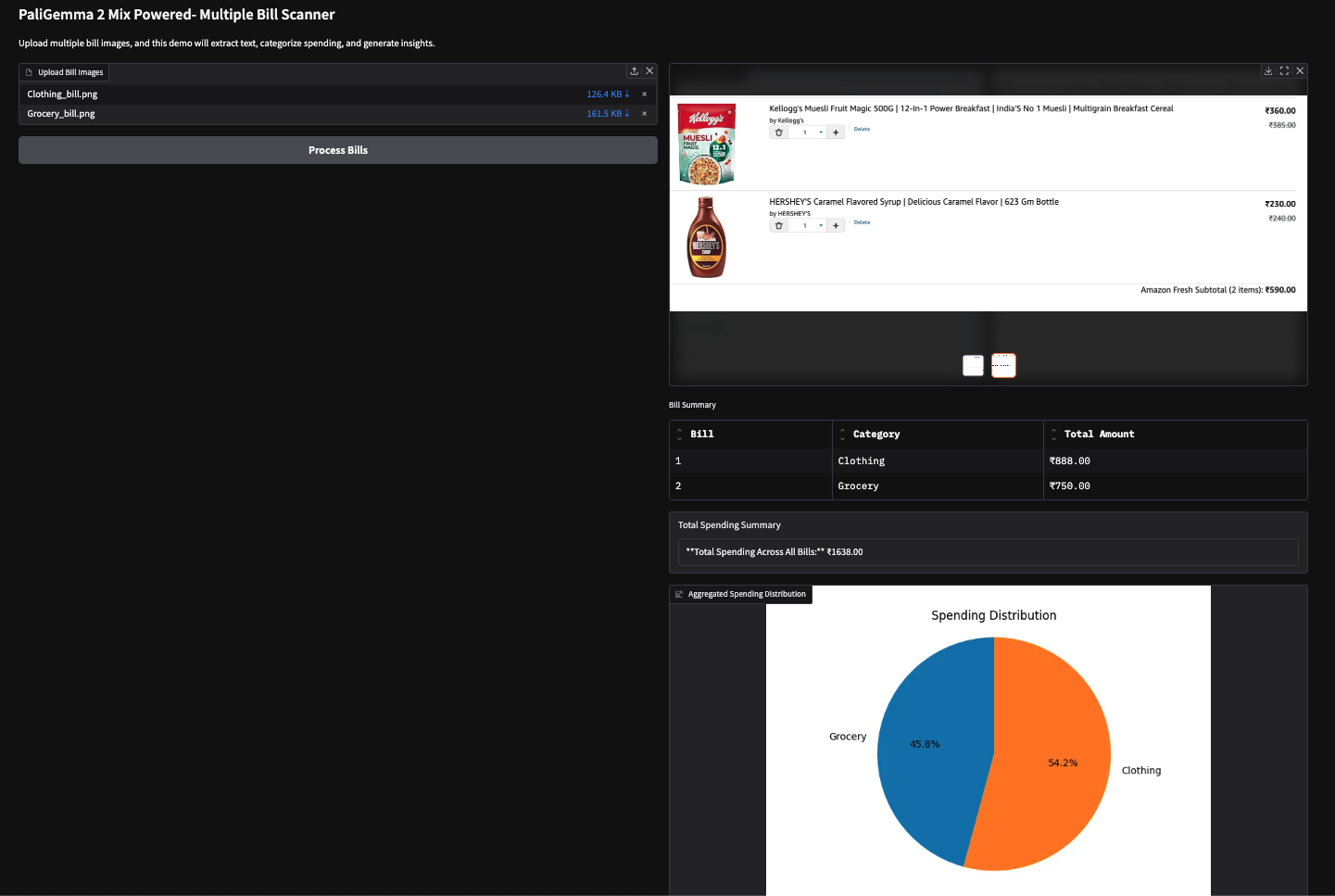
También probé esta demostración con dos facturas basadas en imágenes (factura de compra de Amazon) y obtuve los siguientes resultados.
Nota: A los VLM les resulta difícil extraer números, lo que a veces puede dar lugar a resultados incorrectos. Por ejemplo, extrajo un importe total erróneo para la segunda factura de abajo. Esto se puede corregir utilizando modelos más grandes o simplemente afinando los existentes.
En este tutorial, construimos un escáner de facturas múltiples impulsado por IA utilizando PaliGemma 2 Mix, que puede ayudarnos a extraer y categorizar nuestros gastos de los recibos. Utilizamos las capacidades de visión-idioma de PaliGemma 2 Mix para el OCR y la clasificación, con el fin de analizar la información sobre el gasto sin esfuerzo. Te animo a que adaptes este tutorial a tu propio caso de uso.
Aprende IA con estos cursos
programa
Curso
Curso
blog
Matt Crabtree
13 min
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Dimitri Didmanidze


