Kurs
Importing Data in Python (Fortgeschritten)
2 Std.
210.9K

Pandas ist ein beliebtes Python-Paket für Data Science, und das aus gutem Grund: Es bietet leistungsstarke, ausdrucksstarke und flexible Datenstrukturen, die unter anderem die Datenmanipulation und -analyse erleichtern. Der DataFrame ist eine dieser Strukturen.
Dieses Tutorial behandelt Pandas DataFrames, von grundlegenden Manipulationen bis hin zu fortgeschrittenen Operationen, indem es 11 der beliebtesten Fragen behandelt, damit du die Zweifel der Pythonistas, die vor dir da waren, verstehst - und vermeidest.
Wenn du mehr üben möchtest, kannst du das erste Kapitel dieses Pandas DataFrames-Kurses kostenlos ausprobieren!
Bevor du anfängst, lass uns kurz rekapitulieren, was DataFrames sind.
Diejenigen, die mit R vertraut sind, kennen den Datenrahmen als eine Möglichkeit, Daten in rechteckigen Rastern zu speichern, die sich leicht überblicken lassen. Jede Zeile dieser Raster entspricht den Messungen oder Werten einer Instanz, während jede Spalte ein Vektor mit Daten für eine bestimmte Variable ist. Das bedeutet, dass die Zeilen eines Datenrahmens nicht dieselbe Art von Werten enthalten müssen, aber können: Sie können numerisch, zeichenhaft, logisch usw. sein.
DataFrames in Python sind sehr ähnlich: Sie werden mit der Pandas-Bibliothek ausgeliefert und sind als zweidimensionale, beschriftete Datenstrukturen mit Spalten von möglicherweise unterschiedlichen Typen definiert.
Generell kann man sagen, dass der Pandas DataFrame aus drei Hauptkomponenten besteht: den Daten, dem Index und den Spalten.
DataFrameSeries: ein eindimensionales beschriftetes Array, das jeden Datentyp mit Achsenbeschriftung oder Index aufnehmen kann. Ein Beispiel für ein Series-Objekt ist eine Spalte aus einem DataFrame.ndarray, das ein Datensatz oder eine strukturierte Datei sein kannndarrayndarray's, Listen, Wörterbüchern oder Serien.Beachte den Unterschied zwischen np.ndarray und np.array(). Ersteres ist ein echter Datentyp, während letzteres eine Funktion ist, um Arrays aus anderen Datenstrukturen zu erstellen.
Strukturierte Arrays ermöglichen es den Nutzern, die Daten nach benannten Feldern zu bearbeiten: Im folgenden Beispiel wird ein strukturiertes Array mit drei Tupeln erstellt. Das erste Element jedes Tupels wird foo genannt und ist vom Typ int, während das zweite Element bar heißt und ein Float ist.
Record-Arrays hingegen erweitern die Eigenschaften von strukturierten Arrays. Sie ermöglichen den Zugriff auf Felder von strukturierten Arrays nach Attributen und nicht nach Indizes. Unten siehst du, dass die foo Werte im r2 Datensatz-Array aufgerufen werden.
Ein Beispiel:
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Wenn du immer noch nicht weißt, was Pandas DataFrames sind und wie sie sich von anderen Datenstrukturen wie einem NumPy-Array oder einer Serie unterscheiden, kannst du dir die kleine Präsentation unten ansehen:
Beachte, dass in diesem Beitrag die Bibliotheken, die du brauchst, meistens schon geladen sind. Die Pandas-Bibliothek wird normalerweise unter dem Alias pd importiert, während die NumPy-Bibliothek als np geladen wird. Wenn du in deiner eigenen Data-Science-Umgebung programmierst, solltest du diesen Importschritt nicht vergessen, den du einfach so schreibst:
import numpy as np
import pandas as pdJetzt, da du genau weißt, was DataFrames sind, was sie können und wie sie sich von anderen Strukturen unterscheiden, ist es an der Zeit, die häufigsten Fragen zu beantworten, die Benutzer/innen zur Arbeit mit DataFrames haben!
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenNatürlich ist die Erstellung von DataFrames der erste Schritt bei fast allem, was du in Python mit Daten machen willst. Manchmal wirst du ganz von vorne anfangen wollen, aber du kannst auch andere Datenstrukturen wie Listen oder NumPy-Arrays in Pandas DataFrames konvertieren. In diesem Abschnitt behandelst du nur Letzteres. Wenn du jedoch mehr darüber lesen möchtest, wie du leere DataFrames erstellst, die du später mit Daten füllen kannst, lies Abschnitt 7.
Unter den vielen Dingen, die als Eingabe für einen "DataFrame" dienen können, ist ein NumPy ndarray eines davon. Um einen Datenrahmen aus einem NumPy-Array zu erstellen, kannst du es einfach im Argument data an die Funktion DataFrame() übergeben.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Achte darauf, wie die obigen Codeabschnitte Elemente aus dem NumPy-Array auswählen, um den DataFrame zu konstruieren: Du wählst zuerst die Werte aus, die in den Listen enthalten sind, die mit Row1 und Row2 beginnen, dann wählst du die Index- oder Zeilennummern Row1 und Row2 und dann die Spaltennamen Col1 und Col2 aus.
Als Nächstes siehst du auch, dass wir im obigen Beispiel eine kleine Auswahl der Daten gedruckt haben. Das funktioniert genauso wie das Subsetting von 2D-NumPy-Arrays: Du gibst zuerst die Zeile an, in der du nach deinen Daten suchen willst, und dann die Spalte. Vergiss nicht, dass die Indizes bei 0 beginnen! Für data im obigen Beispiel suchst du in den Zeilen bei Index 1 bis Ende und wählst alle Elemente aus, die nach Index 1 kommen. Als Ergebnis wählst du 1, 2, 3 und 4 aus.
Diese Vorgehensweise bei der Erstellung von DataFrames ist für alle Strukturen gleich, die DataFrame() als Eingabe übernehmen kann.
Siehe das Beispiel unten:
Denke daran, dass die Pandas-Bibliothek bereits als pd importiert wurde.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Beachte, dass der Index deiner Serie (und deines DataFrame) die Schlüssel des ursprünglichen Wörterbuchs enthält, aber dass sie sortiert sind: Belgien wird der Index bei 0 sein, während die Vereinigten Staaten der Index bei 3 sein werden.
Nachdem du deinen DataFrame erstellt hast, möchtest du vielleicht noch etwas mehr über ihn wissen. Du kannst die Eigenschaft shape oder die Funktion len() in Kombination mit der Eigenschaft .index verwenden:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Diese beiden Optionen geben dir leicht unterschiedliche Informationen über deinen DataFrame: Die Eigenschaft shape liefert dir die Abmessungen deines DataFrame. Das bedeutet, dass du die Breite und die Höhe deines DataFrames erfährst. Die Funktion len() hingegen gibt dir in Kombination mit der Eigenschaft index nur Informationen über die Höhe deines DataFrame.
Das alles ist aber überhaupt nicht außergewöhnlich, wie du in der index Eigenschaft ausdrücklich angibst.
Du könntest auch df[0].count() verwenden, um mehr über die Höhe deines DataFrames zu erfahren, aber das schließt die NaN Werte aus (falls es welche gibt). Deshalb ist der Aufruf von .count() für deinen DataFrame nicht immer die bessere Option.
Wenn du mehr Informationen über deine DataFrame-Spalten haben möchtest, kannst du jederzeit list(my_dataframe.columns.values) ausführen.
Jetzt, wo du deine Daten in eine praktische Pandas DataFrame-Struktur gebracht hast, ist es an der Zeit, mit der eigentlichen Arbeit zu beginnen!
Dieser erste Abschnitt führt dich durch die ersten Schritte der Arbeit mit DataFrames in Python. Es werden die grundlegenden Operationen behandelt, die du mit deinem neu erstellten DataFrame durchführen kannst: Hinzufügen, Auswählen, Löschen, Umbenennen und mehr.
Bevor du mit dem Hinzufügen, Löschen und Umbenennen der Komponenten deines DataFrame beginnst, musst du zunächst wissen, wie du diese Elemente auswählen kannst. Also, wie machst du das?
Auch wenn du dich vielleicht noch an den vorherigen Abschnitt erinnerst: Einen Index, eine Spalte oder einen Wert aus deinem DataFrame auszuwählen, ist gar nicht so schwer, ganz im Gegenteil. Es ist ähnlich wie in anderen Sprachen (oder Paketen!), die für die Datenanalyse verwendet werden. Wenn du nicht überzeugt bist, solltest du Folgendes bedenken:
In R verwendest du die Notation [,], um auf die Werte des Datenrahmens zuzugreifen.
Nehmen wir an, du hast einen DataFrame wie diesen hier:
A B C
0 1 2 3
1 4 5 6
2 7 8 9Und du willst auf den Wert zugreifen, der auf dem Index 0 in der Spalte "A" steht.
Es gibt verschiedene Möglichkeiten, deinen Wert 1 zurückzubekommen:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Die wichtigsten, die du dir merken solltest, sind zweifelsohne .loc[] und .iloc[]. Die feinen Unterschiede zwischen diesen beiden werden in den nächsten Abschnitten besprochen.
Genug für den Moment über die Auswahl von Werten aus deinem DataFrame. Was ist mit der Auswahl von Zeilen und Spalten? In diesem Fall würdest du verwenden:
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Für den Moment reicht es zu wissen, dass du auf die Werte entweder über ihre Bezeichnung oder über ihre Position im Index oder in der Spalte zugreifen kannst. Wenn du das nicht siehst, schau dir noch einmal die kleinen Unterschiede in den Befehlen an: Einmal siehst du [0][0], das andere Mal [0,'A'], um deinen Wert 1 abzurufen.
Nachdem du nun gelernt hast, wie du einen Wert aus einem DataFrame auswählst, ist es an der Zeit, dich an die eigentliche Arbeit zu machen und einen Index, eine Zeile oder Spalte hinzuzufügen!
Wenn du einen DataFrame erstellst, hast du die Möglichkeit, dem Argument "index" eine Eingabe hinzuzufügen, um sicherzustellen, dass du den gewünschten Index hast. Wenn du dies nicht angibst, hat dein DataFrame standardmäßig einen numerischen Index, der bei 0 beginnt und bis zur letzten Zeile deines DataFrame reicht.
Aber auch wenn dein Index automatisch für dich festgelegt wird, hast du die Möglichkeit, eine deiner Spalten wiederzuverwenden und sie zu deinem Index zu machen. Du kannst dies ganz einfach tun, indem du set_index() für deinen DataFrame aufrufst. Probiere das unten aus!
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9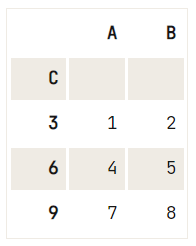
Bevor du zur Lösung kommst, solltest du das Konzept von loc verstehen und wissen, wie es sich von anderen Indexierungsattributen wie .iloc[] und .ix[] unterscheidet:
Das mag alles sehr kompliziert erscheinen. Lass uns das alles mit einem kleinen Beispiel verdeutlichen:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Beachte, dass du in diesem Fall ein Beispiel für einen DataFrame verwendet hast, der nicht ausschließlich auf Integerwerten basiert, damit du die Unterschiede besser verstehen kannst. Du siehst deutlich, dass die Übergabe von 2 an .loc[] oder .iloc[]/.ix[] nicht dasselbe Ergebnis liefert!
48 1
49 2
50 3.iloc[] sich die Positionen im Index ansehen wird. Wenn du 2 passierst, wirst du zurückkommen:48 7
49 8
50 9.ix[] genauso wie iloc und schaut sich die Positionen im Index an. Du erhältst das gleiche Ergebnis wie .iloc[].Jetzt, da der Unterschied zwischen .iloc[], .loc[] und .ix[] klar ist, kannst du deinem DataFrame Zeilen hinzufügen!
Tipp: Als Konsequenz aus dem, was du gerade gelesen hast, verstehst du jetzt auch, dass die allgemeine Empfehlung lautet, dass du .loc verwendest, um Zeilen in deinen DataFrame einzufügen. Denn wenn du df.ix[] verwenden würdest, könntest du versuchen, einen numerisch bewerteten Index mit dem Indexwert zu referenzieren und versehentlich eine bestehende Zeile deines DataFrame überschreiben. Das solltest du vermeiden!
Sieh dir den Unterschied noch einmal in dem DataFrame unten an:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Du verstehst, warum das alles verwirrend sein kann, oder?
In manchen Fällen möchtest du deinen Index zu einem Teil deines DataFrames machen. Du kannst dies ganz einfach tun, indem du eine Spalte aus deinem DataFrame nimmst oder indem du auf eine Spalte verweist, die du noch nicht erstellt hast, und sie der Eigenschaft .index zuweist, so wie hier:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2Mit anderen Worten: Du sagst deinem DataFrame, dass er die Spalte A als Index nehmen soll.
Wenn du jedoch Spalten an deinen DataFrame anhängen möchtest, kannst du auch den gleichen Ansatz verfolgen, wie wenn du einen Index zu deinem DataFrame hinzufügst: Du verwendest .loc[] oder .iloc[]. In diesem Fall fügst du mit Hilfe von .loc[] eine Reihe zu einem bestehenden DataFrame hinzu:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Denke daran, dass ein Series-Objekt ähnlich wie eine Spalte eines DataFrame ist. Das erklärt, warum du ganz einfach eine Reihe zu einem bestehenden Datenrahmen hinzufügen kannst. Beachte auch, dass die zuvor gemachte Beobachtung über .loc[] immer noch gültig ist, auch wenn du Spalten zu deinem DataFrame hinzufügst!
Wenn dein Index nicht ganz so aussieht, wie du ihn haben willst, kannst du ihn zurücksetzen. Das kannst du ganz einfach mit .reset_index() machen. Trotzdem solltest du aufpassen, denn du kannst mehrere Argumente übergeben, die über den Erfolg deines Reset entscheiden können:
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Du kannst versuchen, das Argument drop im obigen Beispiel durch inplace zu ersetzen und sehen, was passiert!
Beachte, dass du mit dem Argument drop angibst, dass du den vorhandenen Index loswerden willst. Wenn du inplace verwendet hättest, würde der ursprüngliche Index mit Floats als zusätzliche Spalte zu deinem DataFrame hinzugefügt.
Nachdem du nun gesehen hast, wie du Indizes, Zeilen und Spalten in deinem DataFrame auswählst und hinzufügst, ist es an der Zeit, einen weiteren Anwendungsfall zu betrachten: das Entfernen dieser drei aus deiner Datenstruktur.
Wenn du den Index aus deinem DataFrame entfernen willst, solltest du es dir noch einmal überlegen, denn DataFrames und Reihen haben immer einen Index.
Was du jedoch tun *kannst*, ist zum Beispiel:
del df.index.name ausführst,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')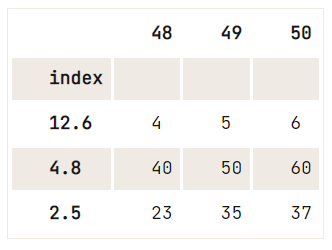
Da du nun weißt, wie du einen Index aus deinem DataFrame entfernst, kannst du mit dem Entfernen von Spalten und Zeilen fortfahren!
Um (eine Auswahl von) Spalten aus deinem DataFrame loszuwerden, kannst du die Methode drop() verwenden:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9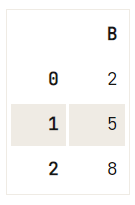
Du denkst jetzt vielleicht: Na ja, das ist nicht so einfach; es gibt einige zusätzliche Argumente, die an die Methode drop() übergeben werden!
axis ist entweder 0, wenn es Zeilen angibt, und 1, wenn es zum Ablegen von Spalten verwendet wird.inplace auf True setzen, um die Spalte zu löschen, ohne den DataFrame neu zuordnen zu müssen.Du kannst doppelte Zeilen aus deinem DataFrame entfernen, indem du df.drop_duplicates() ausführst. Du kannst auch Zeilen aus deinem DataFrame entfernen, wobei du nur die doppelten Werte in einer Spalte berücksichtigst.
Schau dir dieses Beispiel an:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37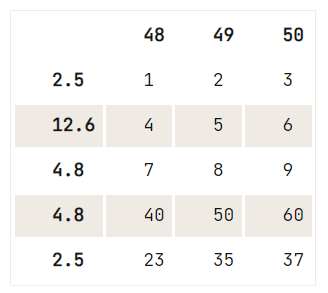
Wenn es kein Einzigartigkeitskriterium für die Löschung gibt, die du durchführen möchtest, kannst du die Methode drop() verwenden, bei der du mit der Eigenschaft index den Index der Zeilen angibst, die du aus deinem DataFrame entfernen möchtest:
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37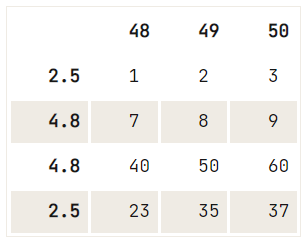
Nach diesem Befehl möchtest du vielleicht den Index wieder zurücksetzen.
Tipp: Versuche selbst, den Index des resultierenden DataFrame zurückzusetzen! Vergiss nicht, das Argument drop zu verwenden, wenn du es für nötig hältst.
Um den Spalten oder Indexwerten deines Datenrahmens einen anderen Wert zu geben, verwendest du am besten die Methode .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9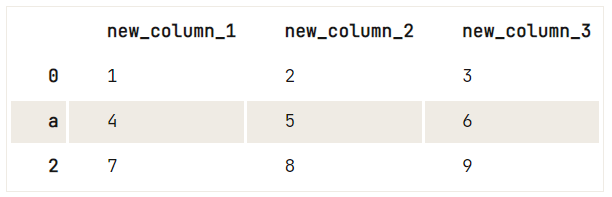
Tipp: Versuche, das Argument inplace in der ersten Aufgabe (Umbenennung deiner Spalten) in False zu ändern und sieh dir an, was das Skript jetzt als Ergebnis ausgibt. Du siehst, dass der DataFrame beim Umbenennen der Spalten nicht neu zugewiesen wurde. Daher nimmt die zweite Aufgabe den ursprünglichen DataFrame als Eingabe und nicht den, den du gerade von der ersten rename() Operation zurückbekommen hast.
Nachdem du nun die ersten Fragen zu Pandas DataFrames beantwortet hast, ist es an der Zeit, über die Grundlagen hinauszugehen und dir die Hände richtig schmutzig zu machen, denn DataFrames haben weit mehr zu bieten als das, was du im ersten Abschnitt gesehen hast.
Meistens möchtest du auch einige Operationen mit den Werten durchführen, die in deinem DataFrame enthalten sind. In den folgenden Abschnitten lernst du verschiedene Möglichkeiten kennen, wie du die Werte deines Pandas DataFrame formatieren kannst
Um bestimmte Zeichenfolgen in deinem DataFrame zu ersetzen, kannst du ganz einfach replace() verwenden: Übergib die Werte, die du ändern möchtest, gefolgt von den Werten, durch die du sie ersetzen willst.
Genau so:
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor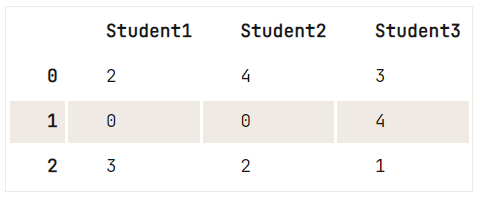
Beachte, dass es auch ein regex Argument gibt, das dir sehr helfen kann, wenn du mit seltsamen Zeichenkettenkombinationen konfrontiert wirst:
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9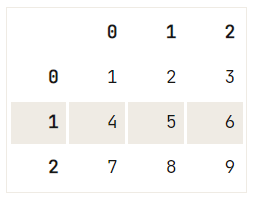
Kurz gesagt: replace() ist das, womit du dich meistens beschäftigen musst, wenn du Werte oder Zeichenketten in deinem DataFrame durch andere ersetzen willst!
Unerwünschte Teile von Strings zu entfernen ist eine mühsame Arbeit. Zum Glück gibt es eine einfache Lösung für dieses Problem!
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Du verwendest map() für die Spalte result, um die Lambda-Funktion auf jedes Element oder elementweise der Spalte anzuwenden. Die Funktion selbst nimmt den Wert der Zeichenkette und entfernt das + oder -, das sich auf der linken Seite befindet, und entfernt auch die sechs aAbBcC auf der rechten Seite.
Dies ist eine etwas schwierigere Formatierungsaufgabe. Der nächste Codeabschnitt führt dich jedoch durch die einzelnen Schritte:
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12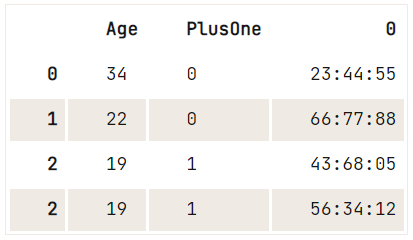
Kurz gesagt, was du tust, ist:
Ticket aus dem DataFrame df und fügst ein Leerzeichen hinzu. So wird sichergestellt, dass die beiden Tickets am Ende in zwei getrennten Reihen landen. Als Nächstes nimmst du diese vier Werte (die vier Ticketnummern) und fügst sie in ein Serienobjekt ein: 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN Werte da drin! Du musst die Reihen stapeln, um sicherzustellen, dass du keine NaN Werte in der resultierenden Reihe hast.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket löschen.Vielleicht möchtest du die Daten in deinem DataFrame anpassen, indem du eine Funktion auf sie anwendest. Beginnen wir mit der Beantwortung dieser Frage, indem wir deine eigene Lambda-Funktion erstellen:
doubler = lambda x: x*2Tipp: Wenn du mehr über Funktionen in Python wissen willst, solltest du dieses Python-Funktionen-Tutorial besuchen.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Beachte, dass du auch die Zeile deines DataFrame auswählen und die doubler Lambda-Funktion darauf anwenden kannst. Vergiss nicht, dass du mit .loc[] oder .iloc[] ganz einfach eine Zeile aus deinem DataFrame auswählen kannst.
Je nachdem, ob du deinen Index anhand seiner Position oder anhand seiner Beschriftung auswählen möchtest, würdest du dann etwas Ähnliches ausführen:
df.loc[0].apply(doubler)Beachte, dass die Funktion apply() die Funktion doubler nur entlang der Achse deines DataFrame anwendet. Das bedeutet, dass du entweder auf den Index oder auf die Spalten abzielst. Oder anders gesagt, entweder eine Zeile oder eine Spalte.
Wenn du sie jedoch auf jedes Element oder elementweise anwenden möchtest, kannst du die Funktion map() verwenden. Du kannst die Funktion apply() im obigen Codeabschnitt einfach durch map() ersetzen. Vergiss nicht, die Funktion doubler zu übergeben, um sicherzustellen, dass du die Werte mit 2 multiplizierst.
Angenommen, du möchtest diese Verdopplungsfunktion nicht nur auf die Spalte A deines DataFrame anwenden, sondern auf den gesamten DataFrame. In diesem Fall kannst du applymap() verwenden, um die Funktion doubler auf jedes einzelne Element im gesamten DataFrame anzuwenden:
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Beachte, dass wir in diesen Fällen mit Lambda-Funktionen oder anonymen Funktionen gearbeitet haben, die zur Laufzeit erstellt werden. Du kannst aber auch deine eigene Funktion schreiben. Zum Beispiel:
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Wenn du mehr Informationen über den Kontrollfluss in Pythonmöchtest, kannst du dir auch unsere anderen Ressourcen ansehen.
Die Funktion, die du verwenden wirst, ist die Pandas-Funktion Dataframe(): Sie erfordert, dass du die Daten, die du einfügen willst, die Indizes und die Spalten übergibst.
Denke daran, dass die Daten, die im Datenrahmen enthalten sind, nicht gleichförmig sein müssen. Es kann sich um verschiedene Datentypen handeln!
Es gibt mehrere Möglichkeiten, wie du mit dieser Funktion einen leeren DataFrame erstellen kannst. Erstens kannst du numpy.nan verwenden, um deinen Datenrahmen mit NaNs zu initialisieren. Beachte, dass numpy.nan den Typ float hat.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNIm Moment wird der Datentyp des Datenrahmens standardmäßig abgeleitet: Da numpy.nan den Typ float hat, enthält der Datenrahmen auch Werte vom Typ float. Du kannst aber auch erzwingen, dass der DataFrame einen bestimmten Typ hat, indem du das Attribut dtype hinzufügst und den gewünschten Typ einträgst. Genau wie in diesem Beispiel:
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNWenn du die Achsenbeschriftungen oder den Index nicht angibst, werden sie nach den Regeln des gesunden Menschenverstands aus den Eingabedaten konstruiert.
Pandas kann es erkennen, aber du musst ihm ein bisschen helfen: Füge das Argument parse_dates hinzu, wenn duDaten aus einer CSV-Datei (comma-separated value) einliest:
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Es gibt jedoch immer wieder seltsame Datums- und Zeitformate.
Mach dir keine Sorgen! In solchen Fällen kannst du deinen eigenen Parser konstruieren, um damit umzugehen. Du könntest zum Beispiel eine Lambda-Funktion erstellen, die deine DateTime nimmt und sie mit einem Format-String steuert.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Das Umformen deines DataFrame bedeutet, dass er so umgestaltet wird, dass die resultierende Struktur besser für deine Datenanalyse geeignet ist. Mit anderen Worten: Bei der Umformung geht es nicht so sehr um die Formatierung der im DataFrame enthaltenen Werte, sondern vielmehr darum, die Form des DataFrame zu verändern.
Das beantwortet die Frage nach dem Wann und Warum. Aber wie würdest du deinen DataFrame umgestalten?
Es gibt drei Arten der Umformung, die bei den Nutzern häufig Fragen aufwerfen: Schwenken, Stapeln und Entstapeln sowie Schmelzen.
Du kannst die Funktion pivot() verwenden, um eine neue abgeleitete Tabelle aus deiner ursprünglichen Tabelle zu erstellen. Wenn du die Funktion verwendest, kannst du drei Argumente übergeben:
valuesMit diesem Argument kannst du angeben, welche Werte deines ursprünglichen DataFrame du in deiner Pivot-Tabelle sehen möchtest.columns: Was auch immer du diesem Argument übergibst, wird eine Spalte in deiner Tabelle.index: Was auch immer du diesem Argument übergibst, wird ein Index in deiner Tabelle.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Wenn du nicht ausdrücklich angibst, welche Werte du in deiner Tabelle erwartest, wirst du nach mehreren Spalten pivotieren:
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Beachte, dass deine Daten keine Zeilen mit doppelten Werten für die von dir angegebenen Spalten enthalten dürfen. Wenn dies nicht der Fall ist, erhältst du eine Fehlermeldung. Wenn du die Einzigartigkeit deiner Daten nicht sicherstellen kannst, solltest du stattdessen die Methode pivot_table verwenden:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Beachte das zusätzliche Argument aggfunc, das an die Methode pivot_table übergeben wird. Dieses Argument zeigt an, dass du eine Aggregationsfunktion verwendest, um mehrere Werte zu kombinieren. In diesem Beispiel kannst du deutlich sehen, dass die Funktion mean verwendet wird.
stack() und unstack() um deinen Pandas DataFrame umzugestaltenEin Beispiel für das Stapeln hast du bereits in Abschnitt 5 gesehen. Im Grunde erinnerst du dich vielleicht noch daran, dass du einen DataFrame größer machst, wenn du ihn stapelst. Du verschiebst den Index der innersten Spalte zum Index der innersten Zeile. Du gibst einen DataFrame mit einem Index mit einer neuen innersten Ebene von Zeilenbeschriftungen zurück.
Wenn du dir nicht sicher bist, wie das System funktioniert, gehe zurück zur vollständigen Anleitung in Abschnitt 5.stack().
Die Umkehrung des Stapelns wird Entstapeln genannt. Ähnlich wie bei stack() verwendest du unstack(), um den innersten Zeilenindex zum innersten Spaltenindex zu machen.
Eine Erklärung zum Pivotieren, Stapeln und Entstapeln von Pandas findest du in unserem Daten umgestalten mit Pandas Kurs.
melt()Das Schmelzen wird als nützlich angesehen, wenn du Daten hast, die eine oder mehrere Spalten haben, die Identifikatorvariablen sind, während alle anderen Spalten als Messvariablen gelten.
Diese Messgrößen sind alle "unpivot" zur Zeilenachse. Das heißt, während die gemessenen Variablen über die Breite des DataFrames verteilt wurden, sorgt die Schmelze dafür, dass sie in der Höhe des DataFrames platziert werden. Oder anders gesagt, dein DataFrame wird jetzt länger statt breiter.
Als Ergebnis hast du zwei nicht identifizierende Spalten, nämlich "Variable" und "Wert".
Lass uns das anhand eines Beispiels verdeutlichen:
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Wenn du nach weiteren Möglichkeiten suchst, deine Daten umzugestalten, sieh dir die Dokumentation an.
Du kannst die Zeilen deines DataFrame mit Hilfe einer for Schleife in Kombination mit einem iterrows() Aufruf auf deinem DataFrame iterieren:
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() ermöglicht es dir, deine DataFrame-Zeilen als (Index, Serie) Paare effizient in einer Schleife zu bearbeiten. Mit anderen Worten: Du erhältst (Index, Zeile) Tupel als Ergebnis.
Wenn du deine Daten mit Pandas bearbeitet hast, möchtest du den DataFrame vielleicht in ein anderes Format exportieren. In diesem Abschnitt werden zwei Möglichkeiten vorgestellt, wie du deinen Pandas DataFrame in eine CSV- oder Excel-Datei ausgeben kannst.
Um einen DataFrame als CSV-Datei zu schreiben, kannst du to_csv() verwenden:
import pandas as pd
df.to_csv('myDataFrame.csv')Dieser Teil des Codes scheint recht einfach zu sein, aber genau hier fangen für die meisten Leute die Schwierigkeiten an, denn du wirst bestimmte Anforderungen an die Ausgabe deiner Daten haben. Vielleicht möchtest du kein Komma als Trennzeichen verwenden oder du möchtest eine bestimmte Kodierung angeben.
Mach dir keine Sorgen! Du kannst einige zusätzliche Argumente an to_csv() übergeben, um sicherzustellen, dass deine Daten so ausgegeben werden, wie du sie haben möchtest!
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding verwenden:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN oder fehlende Werte dargestellt werden sollen, ob du die Kopfzeile ausgeben willst oder nicht, ob du die Zeilennamen ausschreiben willst oder nicht, ob du eine Komprimierung wünschst, du kannst die Optionen nachlesen.Ähnlich wie bei der Ausgabe deines DataFrames in CSV kannst du mit to_excel() deine Tabelle in Excel schreiben. Allerdings ist es ein bisschen komplizierter:
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Beachte jedoch, dass du genau wie bei to_csv() eine Menge zusätzlicher Argumente wie startcol, startrow usw. hast, um sicherzustellen, dass du deine Daten korrekt ausgibst. In unserem Tutorial erfährst du mehr darüber, wie du mit Pandas Daten aus CSV-Dateien importieren und in diese exportieren kannst.
Wenn du jedoch mehr Informationen über die IO-Tools in Pandas haben möchtest, schau dir die Dokumentation zu Pandas DataFrames to excel an.
Das war's! Du hast das Pandas DataFrame-Tutorial erfolgreich abgeschlossen!
Die Antworten auf die 11 häufig gestellten Pandas-Fragen stellen wichtige Funktionen dar, die du zum Importieren, Bereinigen und Manipulieren deiner Daten für deine Data Science-Arbeit benötigst. Bist du dir nicht sicher, dass du dich tief genug in die Materie eingearbeitet hast? Unser Kurs "Datenimport in Python" wird dir dabei helfen! Wenn du den Dreh raus hast, möchtest du vielleicht Pandas in einem echten Projekt bei der Arbeit sehen. Die Tutorial-Reihe The Importance of Preprocessing in Data Science and the Machine Learning Pipeline ist ein Muss, und der offene Kurs Introduction to Python & Machine Learning ist ein absolutes Muss.
Erfahre mehr über Python und Pandas
Kurs
Kurs
Kurs
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
