Python for Spreadsheet Users
BeginnerSkill Level
4 Std.
29K learners
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenDie Installation von Pandas ist ganz einfach: Verwende den Befehl pip install in deinem Terminal.
pip install pandasAlternativ kannst du es auch über conda installieren:
conda install pandasNach der Installation von Pandas ist es ratsam, die installierte Version zu überprüfen, um sicherzustellen, dass alles richtig funktioniert:
import pandas as pd
print(pd.__version__) # Prints the pandas versionDamit wird bestätigt, dass Pandas korrekt installiert ist und du kannst die Kompatibilität mit anderen Paketen überprüfen.
Um mit Pandas zu arbeiten, importierst du das Python-Paket pandas wie unten gezeigt. Wenn du Pandas importierst, ist der häufigste Alias für Pandas pd.
import pandas as pdVerwende read_csv() mit dem Pfad zur CSV-Datei, um eine kommagetrennte Wertedatei zu lesen (weitere Informationen findest du in unserem Tutorial zum Importieren von Daten mit read_csv() ).
df = pd.read_csv("diabetes.csv")Dieser Lesevorgang lädt die CSV-Datei diabetes.csv, um ein Pandas DataFrame-Objekt df zu erzeugen. In diesem Lehrgang wirst du sehen, wie du solche DataFrame-Objekte manipulieren kannst.
Das Lesen von Textdateien ist ähnlich wie bei CSV-Dateien. Die einzige Besonderheit ist, dass du mit dem Argument sep ein Trennzeichen angeben musst, wie unten gezeigt. Das Trennzeichen-Argument bezieht sich auf das Symbol, das zum Trennen von Zeilen in einem DataFrame verwendet wird. Komma (sep = ","), Leerzeichen(sep = "\s"), Tabulator (sep = "\t") und Doppelpunkt(sep = ":") sind die am häufigsten verwendeten Trennzeichen. Hier steht \s für ein einzelnes Leerzeichen.
df = pd.read_csv("diabetes.txt", sep="\s")Das Lesen von Excel-Dateien (sowohl XLS als auch XLSX) ist so einfach wie die Funktion read_excel(), wobei der Dateipfad als Eingabe verwendet wird.
df = pd.read_excel('diabetes.xlsx')Du kannst auch andere Argumente angeben, z. B. header, um festzulegen, welche Zeile die Kopfzeile des DataFrame wird. Der Standardwert ist 0, der die erste Zeile als Kopfzeile oder Spaltennamen kennzeichnet. Du kannst die Spaltennamen auch als Liste im Argument names angeben. Das Argument index_col (Standard ist None) kann verwendet werden, wenn die Datei einen Zeilenindex enthält.
Hinweis: In einem Pandas DataFrame oder einer Serie ist der Index ein Bezeichner, der auf die Position einer Zeile oder Spalte in einem Pandas DataFrame verweist. Kurz gesagt, kennzeichnet der Index die Zeile oder Spalte eines DataFrame und ermöglicht dir den Zugriff auf eine bestimmte Zeile oder Spalte über ihren Index (das wirst du später noch sehen). Der Zeilenindex eines DataFrame kann ein Bereich (z. B. 0 bis 303), eine Zeitreihe (Datum oder Zeitstempel), ein eindeutiger Bezeichner (z. B. employee_ID in einer employees Tabelle) oder andere Datentypen sein. Bei Spalten handelt es sich in der Regel um eine Zeichenkette (die den Spaltennamen bezeichnet).
Das Lesen von Excel-Dateien mit mehreren Blättern ist nicht viel anders. Du musst nur ein zusätzliches Argument angeben, sheet_name, bei dem du entweder eine Zeichenkette für den Blattnamen oder eine Ganzzahl für die Blattposition übergeben kannst (beachte, dass Python eine 0-Indexierung verwendet, bei der das erste Blatt mit sheet_name = 0 aufgerufen werden kann).
# Extracting the second sheet since Python uses 0-indexing
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)Ähnlich wie die Funktion read_csv() kannst du read_json() für JSON-Dateitypen mit dem JSON-Dateinamen als Argument verwenden (für weitere Details lies dieses Tutorial zum Importieren von JSON- und HTML-Daten in Pandas). Der folgende Code liest eine JSON-Datei von der Festplatte und erstellt ein DataFrame-Objekt df.
df = pd.read_json("diabetes.json")Wenn du mehr über das Importieren von Daten mit Pandas erfahren möchtest, schau dir diesen Spickzettel zum Importieren verschiedener Dateitypen mit Python an.
Um Daten aus einer relationalen Datenbank zu laden, verwende pd.read_sql() zusammen mit einer Datenbankverbindung.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Bei großen Datenmengen kannst du SQLAlchemy zur Optimierung von Abfragen verwenden.
Wenn deine Daten von einer Web-API kommen, kann Pandas sie mit pd.read_json() direkt lesen:
df = pd.read_json("https://api.example.com/data.json")Wenn die API-Antwort paginiert ist oder in einem verschachtelten JSON-Format vorliegt, ist möglicherweise eine zusätzliche Verarbeitung mit json_normalize() von pandas.io.json erforderlich.
Genauso wie Pandas Daten aus verschiedenen Dateitypen importieren kann, erlaubt es dir auch, Daten in verschiedene Formate zu exportieren. Das passiert vor allem dann, wenn Daten mit Pandas transformiert werden und lokal auf deinem Rechner gespeichert werden müssen. Im Folgenden wird beschrieben, wie du Pandas DataFrames in verschiedene Formate ausgeben kannst.
Ein Pandas DataFrame (hier verwenden wir df) wird mit der Methode .to_csv() als CSV-Datei gespeichert. Die Argumente umfassen den Dateinamen mit Pfad und index - wobei index = True den Index des DataFrames schreibt.
df.to_csv("diabetes_out.csv", index=False)Exportiere das DataFrame-Objekt in eine JSON-Datei, indem du die Methode .to_json() aufrufst.
df.to_json("diabetes_out.json")Hinweis: In einer JSON-Datei wird ein tabellarisches Objekt wie ein DataFrame als Schlüssel-Wert-Paar gespeichert. So würdest du wiederholte Spaltenüberschriften in einer JSON-Datei beobachten.
Wie beim Schreiben von DataFrames in CSV-Dateien kannst du .to_csv() aufrufen. Die einzigen Unterschiede sind, dass das Format der Ausgabedatei .txt ist und dass du mit dem Argument sep ein Trennzeichen angeben musst.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Rufe .to_excel() aus dem DataFrame-Objekt auf, um es als “.xls” oder “.xlsx” Datei zu speichern.
df.to_excel("diabetes_out.xlsx", index=False)Nachdem du tabellarische Daten als DataFrame gelesen hast, musst du dir einen Überblick über die Daten verschaffen. Du kannst dir entweder eine kleine Stichprobe des Datensatzes oder eine Zusammenfassung der Daten in Form einer zusammenfassenden Statistik ansehen.
.head() und .tail()Du kannst die ersten oder letzten Zeilen eines DataFrames mit den Methoden .head() bzw. .tail() anzeigen. Du kannst die Anzahl der Zeilen mit dem Argument n angeben (der Standardwert ist 5).
df.head()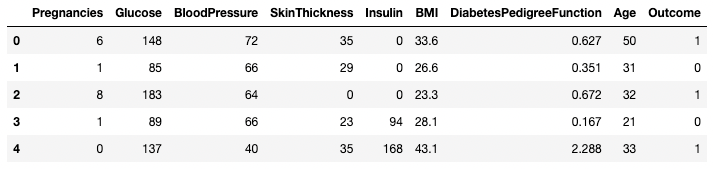
Die ersten fünf Zeilen des DataFrame
df.tail(n = 10)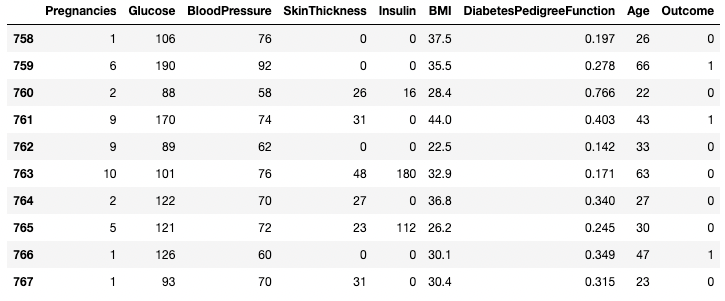
Die ersten 10 Zeilen des DataFrame
.describe()Die Methode .describe() gibt die zusammenfassenden Statistiken aller numerischen Spalten aus, z. B. Anzahl, Mittelwert, Standardabweichung, Bereich und Quartile der numerischen Spalten.
df.describe()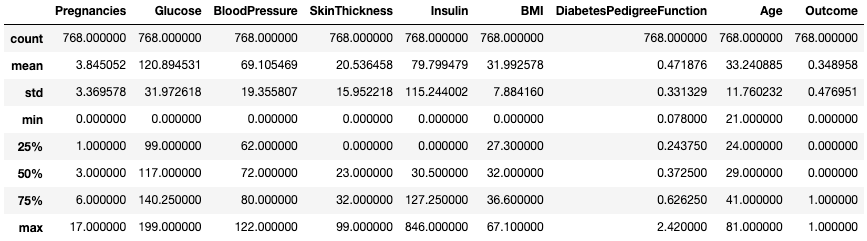
Zusammenfassende Statistiken erhalten mit .describe()
Sie ermöglicht einen schnellen Blick auf die Skala, die Schiefe und den Bereich von numerischen Daten.
Du kannst die Quartile auch mit dem Argument percentiles ändern. Hier sehen wir uns zum Beispiel die 30%-, 50%- und 70%-Perzentile der numerischen Spalten im DataFrame df an.
df.describe(percentiles=[0.3, 0.5, 0.7])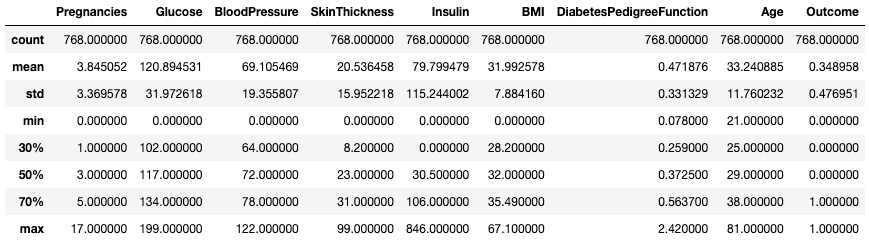
Zusammenfassende Statistiken mit bestimmten Perzentilen erhalten
Du kannst auch bestimmte Datentypen in deiner Zusammenfassungsausgabe isolieren, indem du das Argument include verwendest. Hier fassen wir zum Beispiel nur die Spalten mit dem Datentyp integer zusammen.
df.describe(include=[int])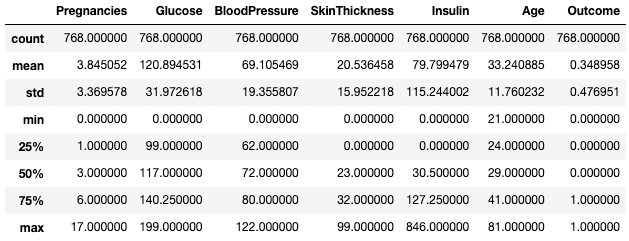
Zusammenfassende Statistiken nur für Integer-Spalten abrufen
Genauso kannst du mit dem Argument exclude bestimmte Datentypen ausschließen.
df.describe(exclude=[int])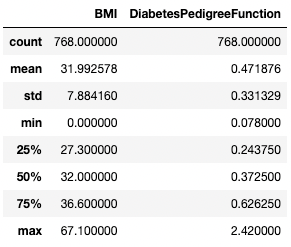
Nur zusammenfassende Statistiken für nicht-ganzzahlige Spalten abrufen
Für Praktiker ist es oft einfach, solche Statistiken mit dem Attribut .T anzuzeigen.
df.describe().T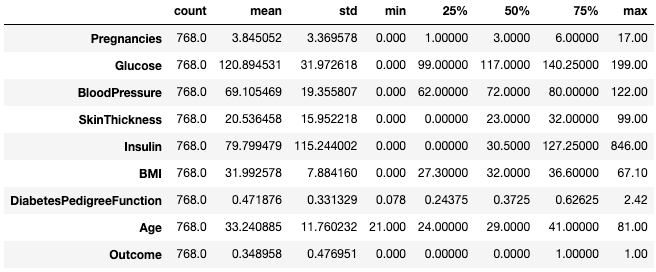
Transponiere zusammenfassende Statistiken mit .T
Mehr zur Beschreibung von DataFrames findest du auf dem folgenden Spickzettel.
.info()Die Methode .info() ist eine schnelle Möglichkeit, die Datentypen, fehlenden Werte und die Datengröße eines DataFrames zu überprüfen. Hier setzen wir das Argument show_counts auf True, was ein paar mehr als die gesamten nicht fehlenden Werte in jeder Spalte ergibt. Außerdem setzen wir memory_usage auf True, was den gesamten Speicherverbrauch der DataFrame-Elemente anzeigt. Wenn verbose auf True gesetzt ist, wird die vollständige Zusammenfassung von .info() gedruckt.
df.info(show_counts=True, memory_usage=True, verbose=True)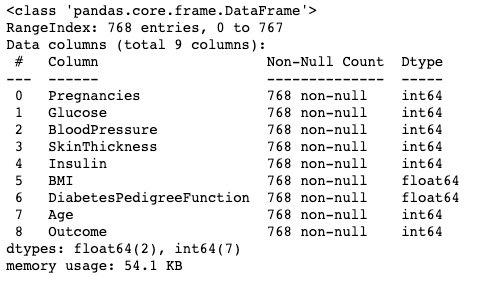
.shapeDie Anzahl der Zeilen und Spalten eines DataFrame kann mit dem Attribut .shape des DataFrame ermittelt werden. Sie gibt ein Tupel (Zeile, Spalte) zurück und kann indiziert werden, um nur Zeilen zu erhalten, und nur Spalten zählen als Ausgabe.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9Der Aufruf des .columns -Attributs eines DataFrame-Objekts liefert die Spaltennamen in Form eines Index -Objekts. Zur Erinnerung: Ein Pandas-Index ist die Adresse/Bezeichnung der Zeile oder Spalte.
df.columns
Sie kann mit einer list() Funktion in eine Liste umgewandelt werden.
list(df.columns)
.isnull()Der DataFrame der Stichprobe enthält keine fehlenden Werte. Lass uns ein paar vorstellen, um die Sache interessant zu machen. Die Methode .copy() erstellt eine Kopie des ursprünglichen DataFrames. Damit soll sichergestellt werden, dass sich Änderungen an der Kopie nicht im ursprünglichen DataFrame widerspiegeln. Mit .loc (wird später besprochen) kannst du die Zeilen zwei bis fünf der Spalte Pregnancies auf NaN Werte setzen, die fehlende Werte bezeichnen.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)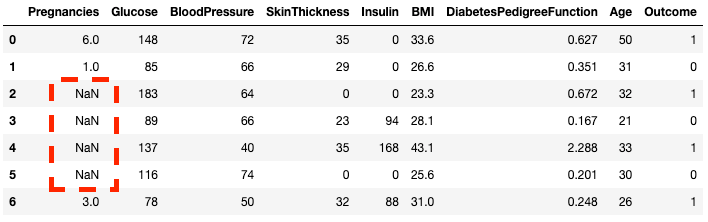
Du kannst sehen, dass die Zeilen 2 bis 5 nun NaN
Du kannst mit der Methode .isnull() überprüfen, ob jedes Element in einem DataFrame fehlt.
df2.isnull().head(7)Da es oft nützlicher ist, zu wissen, wie viele fehlende Daten du hast, kannst du .isnull() mit .sum() kombinieren, um die Anzahl der Nullen in jeder Spalte zu zählen.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Du kannst auch eine Doppelsumme bilden, um die Gesamtzahl der Nullen im DataFrame zu ermitteln.
df2.isnull().sum().sum()4Das Pandas-Paket bietet verschiedene Möglichkeiten, Daten in deinen DataFrames zu sortieren, zu unterteilen, zu filtern und zu isolieren. Hier sehen wir uns die häufigsten Möglichkeiten an.
So sortierst du einen DataFrame nach einer bestimmten Spalte:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderDu kannst nach mehreren Spalten sortieren:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Wenn du einen DataFrame filterst oder sortierst, kann dein Index falsch ausgerichtet werden. Verwende .reset_index(), um dies zu beheben:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnUm Daten auf der Grundlage einer Bedingung zu extrahieren:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100[ ] Du kannst eine einzelne Spalte isolieren, indem du eine eckige Klammer [ ] mit einem Spaltennamen darin verwendest. Die Ausgabe ist ein Pandas Series Objekt. Eine Pandas-Reihe ist ein eindimensionales Array, das Daten beliebigen Typs enthält, darunter Integer, Float, String, Boolean, Python-Objekte usw. Ein DataFrame besteht aus vielen Reihen, die als Spalten fungieren.
df['Outcome']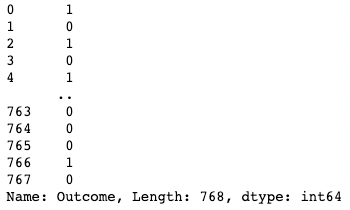
Eine Spalte in Pandas isolieren
[[ ]] Du kannst auch eine Liste von Spaltennamen innerhalb der eckigen Klammern angeben, um mehr als eine Spalte abzurufen. Hier werden die eckigen Klammern auf zwei verschiedene Arten verwendet. Wir verwenden die äußeren eckigen Klammern, um eine Teilmenge eines DataFrame anzugeben, und die inneren eckigen Klammern, um eine Liste zu erstellen.
df[['Pregnancies', 'Outcome']]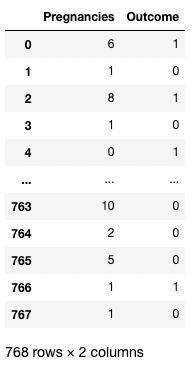
Zwei Spalten in Pandas isolieren
[ ] Eine einzelne Zeile kann durch Übergabe einer booleschen Reihe mit einem True Wert abgerufen werden. Im folgenden Beispiel wird die zweite Zeile mit index = 1 zurückgegeben. Hier gibt .index die Zeilenbeschriftungen des DataFrame zurück, und der Vergleich macht daraus ein eindimensionales boolesches Array.
df[df.index==1]
Eine Zeile in Pandas isolieren
[ ] Ebenso können zwei oder mehr Zeilen mit der Methode .isin() anstelle eines == Operators zurückgegeben werden.
df[df.index.isin(range(2,10))]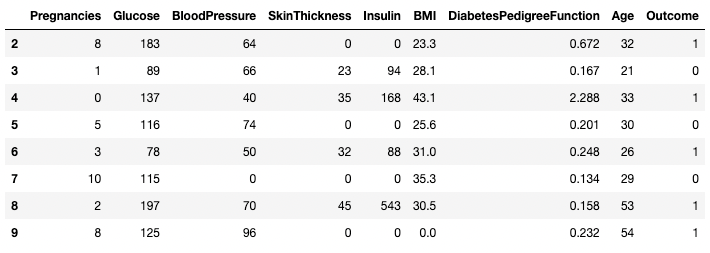
Bestimmte Zeilen in Pandas isolieren
.loc[] und .iloc[] um Zeilen zu holenMit .loc[] und .iloc[] ("location" und "integer location") kannst du bestimmte Zeilen nach Beschriftungen oder Bedingungen abrufen. .loc[] verwendet eine Beschriftung, die auf eine Zeile, Spalte oder Zelle verweist, während .iloc[] die numerische Position verwendet. Um den Unterschied zwischen den beiden zu verstehen, ändern wir den zuvor erstellten Index von df2.
df2.index = range(1,769)Das folgende Beispiel gibt statt eines DataFrames ein Pandas Series zurück. Das 1 steht für den Zeilenindex (Label), während das 1 in .iloc[] die Zeilenposition (erste Zeile) ist.
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Du kannst auch mehrere Zeilen abrufen, indem du einen Bereich in eckigen Klammern angibst.
df2.loc[100:110]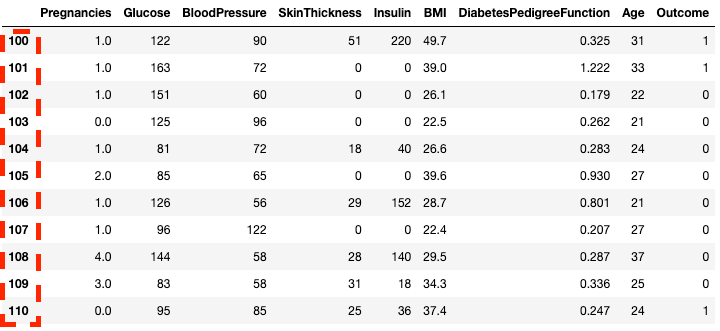
Isolieren von Zeilen in Pandas mit .loc[]
df2.iloc[100:110]![Zeilen in Pandas mit .loc[] isolieren](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Isolieren von Zeilen in Pandas mit .iloc[]
Du kannst auch mit .loc[] und .iloc[] untergliedern, indem du eine Liste statt eines Bereichs verwendest.
df2.loc[[100, 200, 300]]![Isolieren von Zeilen mithilfe einer Liste in Pandas mit .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Isolieren von Zeilen mithilfe einer Liste in Pandas mit .loc[]
df2.iloc[[100, 200, 300]]
Isolieren von Zeilen mithilfe einer Liste in Pandas mit .iloc[]
Du kannst auch bestimmte Spalten zusammen mit den Zeilen auswählen. Hier unterscheidet sich .iloc[] von .loc[] - es erfordert die Position der Spalte und nicht die Spaltenbeschriftung.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolieren von Spalten mithilfe einer Liste in Pandas mit .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Isolieren von Spalten in Pandas mit .loc[]
df2.iloc[100:110, :3]![Spalten in Pandas mit .iloc[] isolieren](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Spalten isolieren mit .iloc[]
Für schnellere Arbeitsabläufe kannst du den Anfangsindex einer Zeile als Bereich übergeben.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Spalten in Pandas mit .loc[] isolieren](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Isolieren von Spalten und Zeilen in Pandas mit .loc[]
df2.iloc[760:, :3]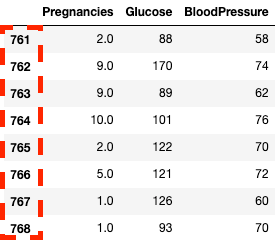
Isolieren von Spalten und Zeilen in Pandas mit .iloc[]
Du kannst bestimmte Werte aktualisieren/ändern, indem du den Zuweisungsoperator =
df2.loc[df['Age']==81, ['Age']] = 80Mit Pandas kannst du Daten nach Bedingungen über Zeilen-/Spaltenwerte filtern. Der folgende Code wählt zum Beispiel die Zeile aus, in der der Blutdruck genau 122 beträgt. Hier isolieren wir die Zeilen mithilfe der Klammern [ ] wie in den vorherigen Abschnitten. Anstatt jedoch Zeilenindizes oder Spaltennamen einzugeben, geben wir eine Bedingung ein, bei der die Spalte BloodPressure gleich 122 ist. Wir bezeichnen diese Bedingung mit df.BloodPressure == 122.
df[df.BloodPressure == 122]
Isolieren von Zeilen basierend auf einer Bedingung in Pandas
Im folgenden Beispiel werden alle Zeilen abgefragt, in denen Outcome gleich 1 ist. Hier wählt df.Outcome diese Spalte aus, df.Outcome == 1 gibt eine Reihe von booleschen Werten zurück, die bestimmen, welche Outcomes gleich 1 sind, und [] nimmt eine Teilmenge von df, bei der diese boolesche Reihe True ist.
df[df.Outcome == 1]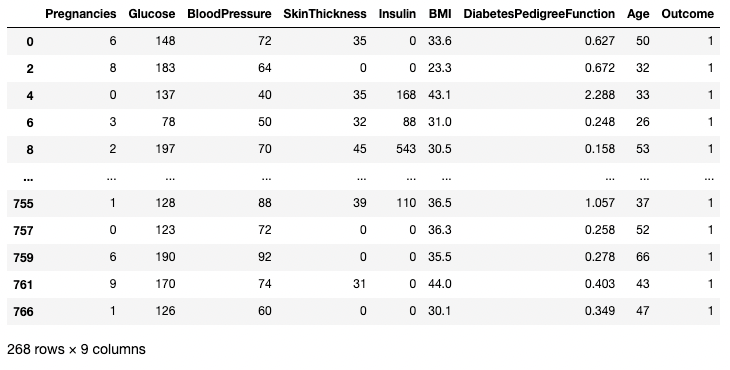
Isolieren von Zeilen basierend auf einer Bedingung in Pandas
Du kannst einen > Operator verwenden, um Vergleiche zu ziehen. Der folgende Code holt Pregnancies, Glucose und BloodPressure für alle Datensätze mit BloodPressure größer als 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]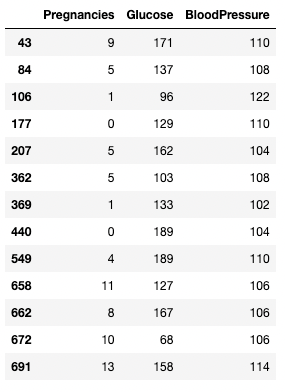
Isolieren von Zeilen und Spalten basierend auf einer Bedingung in Pandas
Das Bereinigen von Daten ist eine der häufigsten Aufgaben in der Datenwissenschaft. Mit Pandas kannst du Daten für jeden Zweck vorverarbeiten, unter anderem für das Training von Machine Learning- und Deep Learning-Modellen. Nehmen wir den DataFrame df2 von vorhin, der vier fehlende Werte enthält, um einige Anwendungsfälle der Datenbereinigung zu veranschaulichen. Zur Erinnerung: So kannst du sehen, wie viele fehlende Werte in einem DataFrame enthalten sind.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Eine Möglichkeit, mit fehlenden Daten umzugehen, ist, sie wegzulassen. Das ist besonders dann nützlich, wenn du viele Daten hast und der Verlust eines kleinen Teils keine Auswirkungen auf die nachfolgende Analyse hat. Du kannst eine .dropna() Methode verwenden, wie unten gezeigt. Hier speichern wir die Ergebnisse von .dropna() in einem DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2Mit dem Argument axis kannst du angeben, ob du Zeilen oder Spalten mit fehlenden Werten fallen lassen willst. Die Standardeinstellung axis entfernt die Zeilen, die NaNs enthalten. Verwende axis = 1, um die Spalten mit einem oder mehreren NaN-Werten zu entfernen. Beachte auch, dass wir das Argument inplace=True verwenden, mit dem du das Speichern der Ausgabe von .dropna() in einem neuen DataFrame überspringen kannst.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()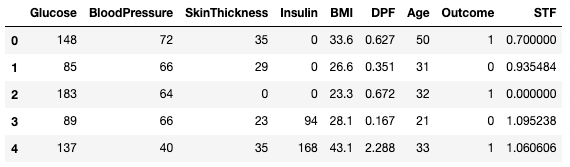
Fehlende Daten in Pandas löschen
Du kannst auch sowohl Zeilen als auch Spalten mit fehlenden Werten löschen, indem du das Argument how auf 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Anstatt zu streichen, ist es vielleicht am besten, fehlende Werte durch eine zusammenfassende Statistik oder einen bestimmten Wert (je nach Anwendungsfall) zu ersetzen. Wenn zum Beispiel eine Zeile in einer Temperaturspalte fehlt, die die Temperaturen der einzelnen Wochentage angibt, kann es effektiver sein, den fehlenden Wert durch die Durchschnittstemperatur der Woche zu ersetzen, als die Werte ganz wegzulassen. Du kannst die fehlenden Daten durch den Zeilen- oder Spaltenmittelwert ersetzen, indem du den folgenden Code verwendest.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Fügen wir den Originaldaten einige Duplikate hinzu, um zu lernen, wie man Duplikate in einem DataFrame eliminiert. Hier verwenden wir die Methode .concat(), um die Zeilen des df2 DataFrame mit dem df2 DataFrame zu verketten, indem wir perfekte Duplikate jeder Zeile in df2 hinzufügen.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Mit der Methode .drop_duplicates() kannst du alle doppelten Zeilen (Standard) aus dem DataFrame entfernen.
df3 = df3.drop_duplicates()
df3.shape(768, 9)Eine häufige Aufgabe bei der Datenbereinigung ist das Umbenennen von Spalten. Mit der Methode .rename() kannst du columns als Argument verwenden, um bestimmte Spalten umzubenennen. Der folgende Code zeigt das Wörterbuch für die Zuordnung von alten und neuen Spaltennamen.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()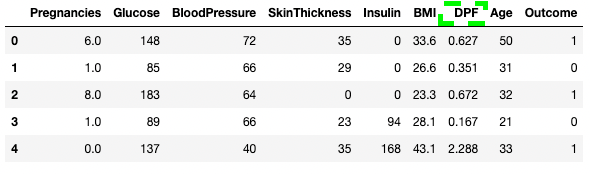
Umbenennen von Spalten in Pandas
Du kannst dem DataFrame auch direkt Spaltennamen als Liste zuweisen.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()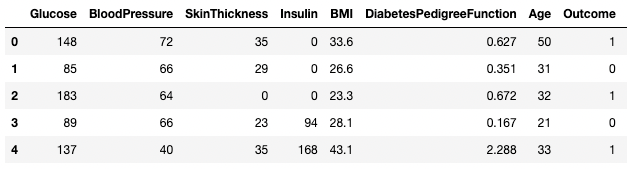
Umbenennen von Spalten in Pandas
Wenn du mehr über die Datenbereinigung wissen willst und deine Arbeitsabläufe einfacher und vorhersehbarer gestalten willst, solltest du dir die folgende Checkliste ansehen, die dir eine umfassende Zusammenstellung gängiger Datenbereinigungsaufgaben bietet.
Der Hauptnutzen von Pandas liegt in seiner schnellen Datenanalysefunktion. In diesem Abschnitt konzentrieren wir uns auf eine Reihe von Analysetechniken, die du in Pandas verwenden kannst.
Wie du bereits gesehen hast, kannst du den Mittelwert jeder Spalte mit der Methode .mean() ermitteln.
df.mean()
Den Mittelwert von Spalten in Pandas drucken
Ein Modus kann auf ähnliche Weise mit der Methode .mode() berechnet werden.
df.mode()
Den Modus von Spalten in Pandas drucken
Auf ähnliche Weise wird der Median jeder Spalte mit der Methode .median() berechnet
df.median()
Drucken des Medians von Spalten in Pandas
pandas ermöglicht schnelle und effiziente Berechnungen, indem es zwei oder mehr Spalten wie skalare Variablen kombiniert. Der folgende Code teilt jeden Wert in der Spalte Glucose durch den entsprechenden Wert in der Spalte Insulin, um eine neue Spalte namens Glucose_Insulin_Ratio zu berechnen.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Eine neue Spalte aus bestehenden Spalten in Pandas erstellen
.value_counts()Oft arbeitest du mit kategorialen Werten und möchtest die Anzahl der Beobachtungen pro Kategorie in einer Spalte zählen. Kategoriewerte können mit den Methoden von .value_counts() gezählt werden. Hier zählen wir zum Beispiel die Anzahl der Beobachtungen, bei denen Outcome Diabetiker ist (1), und die Anzahl der Beobachtungen, bei denen Outcome kein Diabetiker ist (0).
df['Outcome'].value_counts()
Verwendung von .value_counts() in Pandas
Wenn du das Argument normalize hinzufügst, erhältst du die Proportionen statt der absoluten Zahlen.
df['Outcome'].value_counts(normalize=True)
Verwendung von .value_counts() in Pandas mit Normalisierung
Schalte die automatische Sortierung der Ergebnisse mit dem Argument sort aus (True standardmäßig). Die Standardsortierung basiert auf den Zählungen in absteigender Reihenfolge.
df['Outcome'].value_counts(sort=False)
Verwendung von .value_counts() in Pandas mit Sortierung
Du kannst .value_counts() auch auf ein DataFrame-Objekt und bestimmte Spalten darin anwenden, anstatt nur auf eine Spalte. Hier wenden wir zum Beispiel value_counts() auf df mit dem Subset-Argument an, das eine Liste von Spalten enthält.
df.value_counts(subset=['Pregnancies', 'Outcome'])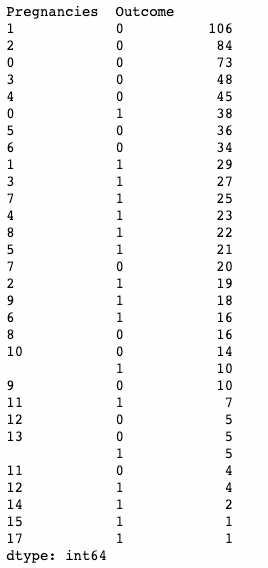
Verwendung von .value_counts() in Pandas beim Subsetting von Spalten
.groupby() bei PandasMit Pandas kannst du Werte aggregieren, indem du sie nach bestimmten Spaltenwerten gruppierst. Das kannst du tun, indem du die Methode .groupby() mit einer Zusammenfassungsmethode deiner Wahl kombinierst. Der folgende Code zeigt den Mittelwert jeder der numerischen Spalten gruppiert nach Outcome an.
df.groupby('Outcome').mean()
Aggregieren von Daten nach einer Spalte in Pandas
.groupby() ermöglicht die Gruppierung nach mehr als einer Spalte durch die Übergabe einer Liste von Spaltennamen, wie unten gezeigt.
df.groupby(['Pregnancies', 'Outcome']).mean()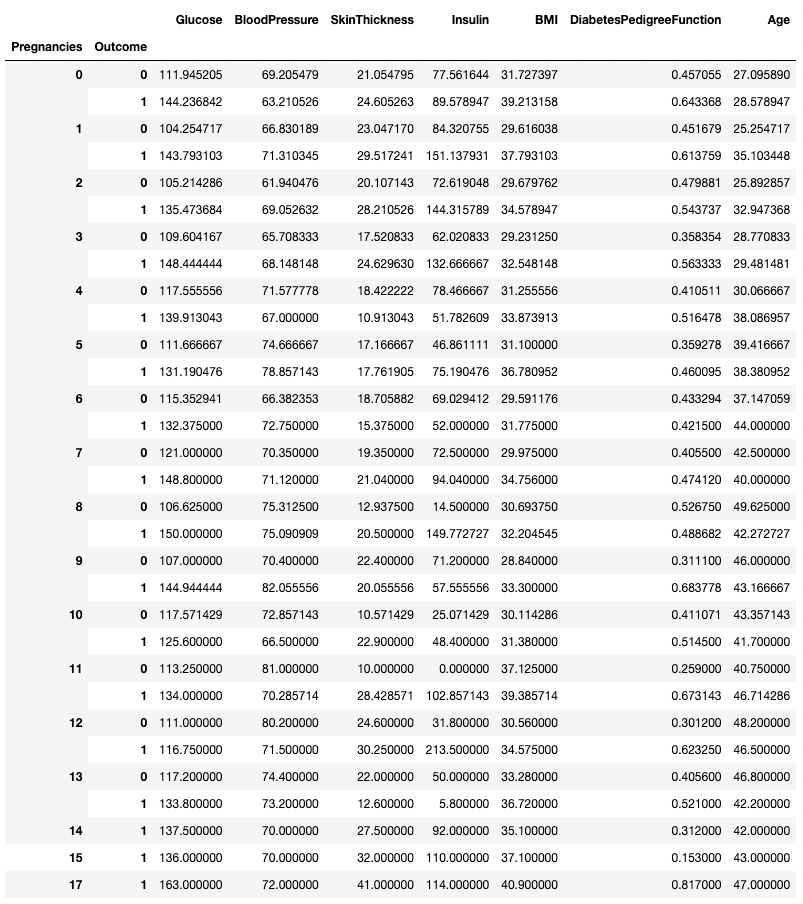
Aggregieren von Daten nach zwei Spalten in Pandas
Jede Zusammenfassungsmethode kann zusammen mit .groupby() verwendet werden, einschließlich .min(), .max(), .mean(), .median(), .sum(), .mode() und mehr.
pandas ermöglicht es dir auch, zusammenfassende Statistiken als Pivot-Tabellen zu berechnen. Das macht es einfach, Schlussfolgerungen aus einer Kombination von Variablen zu ziehen. Der folgende Code wählt die Zeilen als eindeutige Werte von Pregnancies aus, die Spaltenwerte sind die eindeutigen Werte von Outcome, und die Zellen enthalten den Durchschnittswert von BMI in der entsprechenden Gruppe.
Auf Pregnancies = 5 und Outcome = 0 zum Beispiel liegt der durchschnittliche BMI bei 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc=np.mean)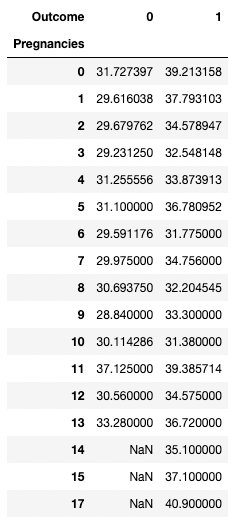
Aggregieren von Daten durch Pivoting mit Pandas
pandas bietet bequeme Wrapper für die Matplotlib Plotting-Funktionen, mit denen du deine DataFrames einfach visualisieren kannst. Im Folgenden erfährst du, wie du mit Pandas gängige Datenvisualisierungen erstellen kannst.
pandas ermöglicht es dir, die Beziehungen zwischen den Variablen mithilfe von Liniendiagrammen darzustellen. Unten siehst du ein Liniendiagramm von BMI und Glukose im Vergleich zum Reihenindex.
df[['BMI', 'Glucose']].plot.line()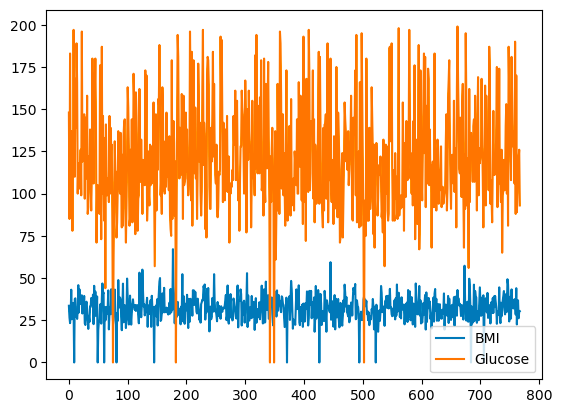
Grundlegendes Liniendiagramm mit Pandas
Du kannst die Farbauswahl mit dem Argument Farbe treffen.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})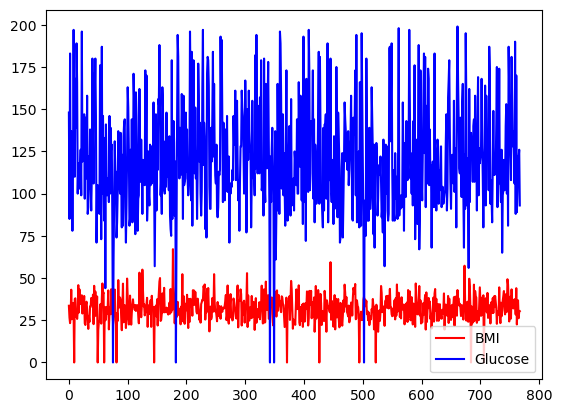
Einfaches Liniendiagramm mit Pandas, mit benutzerdefinierten Farben
Alle Spalten von df können auch auf verschiedenen Skalen und Achsen dargestellt werden, indem du das Argument subplots verwendest.
df.plot.line(subplots=True)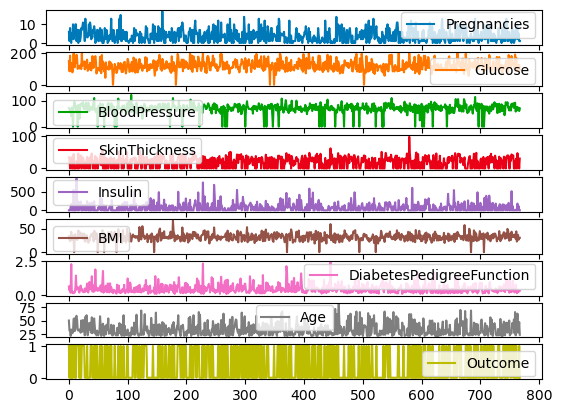
Subplots für Liniendiagramme mit Pandas
Für diskrete Spalten kannst du ein Balkendiagramm über die Anzahl der Kategorien erstellen, um ihre Verteilung zu visualisieren. Die Variable Outcome mit binären Werten ist unten abgebildet.
df['Outcome'].value_counts().plot.bar()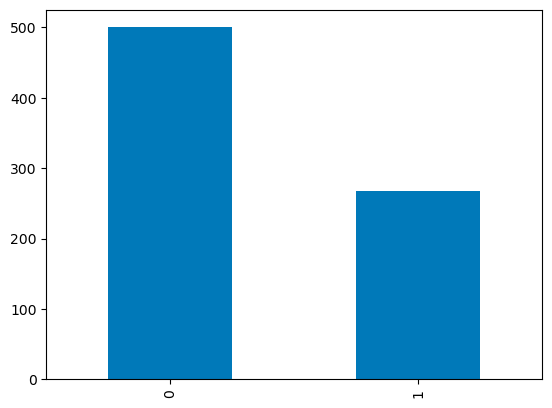
Barplots bei Pandas
Die Quartilsverteilung von kontinuierlichen Variablen kann mit einem Boxplot visualisiert werden. Mit dem folgenden Code kannst du einen Boxplot mit Pandas erstellen.
df.boxplot(column=['BMI'], by='Outcome')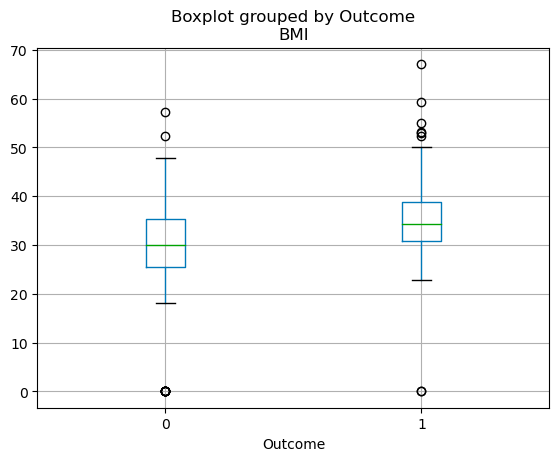
Boxplots in Pandas
Das obige Tutorial kratzt nur an der Oberfläche dessen, was mit Pandas möglich ist. Egal, ob du Daten analysierst, visualisierst, filterst oder aggregierst, Pandas bietet ein unglaublich umfangreiches Feature-Set, mit dem du jeden Datenworkflow beschleunigen kannst. Wenn du Pandas mit anderen Data Science-Paketen kombinierst, kannst du interaktive Dashboards erstellen, Vorhersagemodelle mit maschinellem Lernen entwickeln, Daten-Workflows automatisieren und vieles mehr. Schau dir die folgenden Ressourcen an, um deine Pandas-Lernreise zu beschleunigen:
Mehr Pandakurse
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
Tutorial
Aditya Sharma
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Satyabrata Pal
