Cours
Importation intermédiaire de données en Python
2 h
210.9K

Python est un package Python populaire pour la science des données, et pour cause : il offre des structures de données puissantes, expressives et flexibles qui facilitent la manipulation et l'analyse des données, parmi bien d'autres choses. Le DataFrame est l'une de ces structures.
Ce tutoriel couvre les DataFrames pandas, des manipulations de base aux opérations avancées, en abordant 11 des questions les plus populaires afin que vous compreniez -et évitiez- les doutes des Pythonistas qui vous ont précédé.
Pour plus de pratique, essayez gratuitement le premier chapitre de ce cours Pandas DataFrames!
Avant de commencer, rappelons brièvement ce que sont les DataFrame.
Ceux qui connaissent R savent que le cadre de données est un moyen de stocker des données dans des grilles rectangulaires qui peuvent être facilement visualisées. Chaque ligne de ces grilles correspond aux mesures ou aux valeurs d'une instance, tandis que chaque colonne est un vecteur contenant des données pour une variable spécifique. Cela signifie que les lignes d'un cadre de données ne doivent pas nécessairement contenir, mais peuvent contenir, le même type de valeurs : elles peuvent être numériques, de caractères, logiques, etc.
En Python, les DataFrames sont très similaires : elles sont fournies avec la bibliothèque pandas et sont définies comme des structures de données bidimensionnelles étiquetées avec des colonnes de types potentiellement différents.
En général, on peut dire que le DataFrame pandas se compose de trois éléments principaux : les données, l'index et les colonnes.
DataFrameSeries: un tableau unidimensionnel étiqueté capable de contenir n'importe quel type de données avec des étiquettes d'axe ou un index. Une colonne d'un DataFrame est un exemple d'objet Series.ndarray, qui peut être un enregistrement ou une structurendarrayndarray's unidimensionnels, listes, dictionnaires ou séries.Notez la différence entre np.ndarray et np.array(). Le premier est un type de données réel, tandis que le second est une fonction permettant de créer des tableaux à partir d'autres structures de données.
Les tableaux structurés permettent aux utilisateurs de manipuler les données par champs nommés : dans l'exemple ci-dessous, un tableau structuré de trois tuples est créé. Le premier élément de chaque tuple sera appelé foo et sera de type int, tandis que le deuxième élément sera appelé bar et sera un flotteur.
Les tableaux d'enregistrements, quant à eux, étendent les propriétés des tableaux structurés. Ils permettent aux utilisateurs d'accéder aux champs des tableaux structurés par attribut plutôt que par index. Vous voyez ci-dessous que les valeurs de foo sont accessibles dans le tableau d'enregistrement de r2.
Un exemple :
import pandas as pd
import numpy as np
# A structured array
my_array = np.ones(3, dtype=([('foo', int), ('bar', float)]))
# Print the structured array
print(my_array['foo'])
# A record array
my_array2 = my_array.view(np.recarray)
# Print the record array
print(my_array2.foo)[1 1 1]
[1 1 1]Si vous avez encore des doutes sur les DataFrames Pandas et sur leurs différences avec d'autres structures de données telles qu'un tableau NumPy ou une Série, vous pouvez regarder la petite présentation ci-dessous :
Notez que dans ce billet, la plupart du temps, les bibliothèques dont vous avez besoin ont déjà été chargées. La bibliothèque Pandas est généralement importée sous l'alias pd, tandis que la bibliothèque NumPy est chargée sous l'alias np. N'oubliez pas que lorsque vous codez dans votre propre environnement de science des données, vous ne devez pas oublier cette étape d'importation, que vous écrivez comme ceci :
import numpy as np
import pandas as pdMaintenant que vous savez ce que sont les DataFrame, ce qu'ils peuvent faire et en quoi ils diffèrent des autres structures, il est temps d'aborder les questions les plus courantes que les utilisateurs se posent à leur sujet !
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeIl est évident que la création de vos DataFrames est la première étape de presque tout ce que vous voulez faire en matière de traitement de données en Python. Parfois, vous voudrez partir de zéro, mais vous pouvez également convertir d'autres structures de données, telles que des listes ou des tableaux NumPy, en DataFrame Pandas. Dans cette section, vous n'aborderez que ce dernier point. Toutefois, si vous souhaitez en savoir plus sur la création de DataFrame vides que vous pourrez remplir ultérieurement avec des données, consultez la section 7.
Parmi les nombreuses choses qui peuvent servir d'entrée pour créer un "DataFrame", un NumPy ndarray est l'une d'entre elles. Pour créer un cadre de données à partir d'un tableau NumPy, vous pouvez simplement le passer à la fonction DataFrame() dans l'argument data.
data = np.array([['','Col1','Col2'],
['Row1',1,2],
['Row2',3,4]])
print(pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:]))
Col1 Col2
Row1 1 2
Row2 3 4
Prêtez attention à la façon dont les morceaux de code ci-dessus sélectionnent les éléments du tableau NumPy pour construire le DataFrame : vous sélectionnez d'abord les valeurs contenues dans les listes qui commencent par Row1 et Row2, puis vous sélectionnez les numéros d'index ou de ligne Row1 et Row2 et ensuite les noms de colonne Col1 et Col2.
Ensuite, vous voyez également que, dans l'exemple ci-dessus, nous avons imprimé une petite sélection de données. Cela fonctionne de la même manière que le sous-ensemble de tableaux NumPy en 2D : vous indiquez d'abord la ligne dans laquelle vous souhaitez rechercher vos données, puis la colonne. N'oubliez pas que les indices commencent à 0 ! Pour data dans l'exemple ci-dessus, vous allez chercher dans les lignes de l'index 1 à la fin, et vous sélectionnez tous les éléments qui viennent après l'index 1. Vous finissez donc par sélectionner 1, 2, 3 et 4.
Cette approche de la création de DataFrame sera la même pour toutes les structures que DataFrame() peut prendre en entrée.
Voir l'exemple ci-dessous :
Rappelez-vous que la bibliothèque Pandas a déjà été importée sous pd.
# Take a 2D array as input to your DataFrame
my_2darray = np.array([[1, 2, 3], [4, 5, 6]])
print(pd.DataFrame(my_2darray))
# Take a dictionary as input to your DataFrame
my_dict = {1: ['1', '3'], 2: ['1', '2'], 3: ['2', '4']}
print(pd.DataFrame(my_dict))
# Take a DataFrame as input to your DataFrame
my_df = pd.DataFrame(data=[4,5,6,7], index=range(0,4), columns=['A'])
print(pd.DataFrame(my_df))
# Take a Series as input to your DataFrame
my_series = pd.Series({"Belgium":"Brussels", "India":"New Delhi", "United Kingdom":"London", "United States":"Washington"})
print(pd.DataFrame(my_series))0 1 2
0 1 2 3
1 4 5 6
1 2 3
0 1 1 2
1 3 2 4
A
0 4
1 5Notez que l'index de votre Series (et DataFrame) contient les clés du dictionnaire original, mais qu'elles sont triées : La Belgique sera l'indice à 0, tandis que les États-Unis seront l'indice à 3.
Après avoir créé votre DataFrame, vous voudrez peut-être en savoir un peu plus. Vous pouvez utiliser la propriété shape ou la fonction len() en combinaison avec la propriété .index:
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
# Use the `shape` property
print(df.shape)
# Or use the `len()` function with the `index` property
print(len(df))(2, 3)
2Ces deux options vous donnent des informations légèrement différentes sur votre DataFrame : la propriété shape vous fournira les dimensions de votre DataFrame. Cela signifie que vous allez connaître la largeur et la hauteur de votre DataFrame. En revanche, la fonction len(), combinée à la propriété index, ne vous donnera que des informations sur la hauteur de votre DataFrame.
Mais tout cela n'a rien d'extraordinaire, comme vous l'indiquez explicitement dans la propriété index.
Vous pouvez également utiliser df[0].count() pour en savoir plus sur la hauteur de votre DataFrame, mais cela exclura les valeurs de NaN (s'il y en a). C'est pourquoi appeler .count() sur votre DataFrame n'est pas toujours la meilleure option.
Si vous souhaitez obtenir plus d'informations sur les colonnes de votre DataFrame, vous pouvez toujours exécuter list(my_dataframe.columns.values).
Maintenant que vous avez placé vos données dans une structure Pandas DataFrame plus pratique, il est temps de passer aux choses sérieuses !
Cette première section vous guidera dans les premières étapes du travail avec les DataFrame en Python. Il couvrira les opérations de base que vous pouvez effectuer sur votre DataFrame nouvellement créée : ajouter, sélectionner, supprimer, renommer, etc.
Avant de commencer à ajouter, supprimer et renommer les composants de votre DataFrame, vous devez d'abord savoir comment sélectionner ces éléments. Alors, comment faire ?
Même si vous vous souvenez encore de la façon de procéder de la section précédente : sélectionner un index, une colonne ou une valeur dans votre DataFrame n'est pas si difficile, bien au contraire. Il est similaire à ce que vous voyez dans d'autres langages (ou progiciels !) utilisés pour l'analyse des données. Si vous n'êtes pas convaincu, considérez les éléments suivants :
Dans R, vous utilisez la notation [,] pour accéder aux valeurs du cadre de données.
Supposons que vous ayez un DataFrame comme celui-ci :
A B C
0 1 2 3
1 4 5 6
2 7 8 9Et vous voulez accéder à la valeur qui se trouve à l'index 0, dans la colonne "A".
Il existe plusieurs options pour récupérer votre valeur 1:
df = pd.DataFrame({"A":[1,4,7], "B":[2,5,8], "C":[3,6,9]})
print(df) A B C
0 1 2 3
1 4 5 6
2 7 8 9# Using `iloc[]`
print(df.iloc[0][0])
# Using `loc[]`
print(df.loc[0]['A'])
# Using `at[]`
print(df.at[0,'A'])
# Using `iat[]`
print(df.iat[0,0])1
1
1
1Les plus importants à retenir sont, sans aucun doute, .loc[] et .iloc[]. Les différences subtiles entre les deux seront examinées dans les sections suivantes.
Assez parlé pour l'instant de la sélection de valeurs dans votre DataFrame. Qu'en est-il de la sélection des lignes et des colonnes ? Dans ce cas, vous devez utiliser :
# Use `iloc[]` to select row `0`
print(df.iloc[0])
# Use `loc[]` to select column `'A'`
print(df.loc[:,'A'])A 1
B 2
C 3
Name: 0, dtype: int64
0 1
1 4
2 7
Name: A, dtype: int64Pour l'instant, il suffit de savoir que vous pouvez accéder aux valeurs en les appelant par leur libellé ou par leur position dans l'index ou la colonne. Si vous ne le voyez pas, regardez à nouveau les légères différences dans les commandes : une fois, vous voyez [0][0], l'autre fois, vous voyez [0,'A'] pour récupérer votre valeur 1.
Maintenant que vous avez appris à sélectionner une valeur dans un DataFrame, il est temps de passer aux choses sérieuses et d'y ajouter un index, une ligne ou une colonne !
Lorsque vous créez un DataFrame, vous avez la possibilité d'ajouter des données à l'argument "index" afin de vous assurer que vous disposez de l'index souhaité. Si vous ne le spécifiez pas, votre DataFrame aura, par défaut, un index à valeur numérique qui commence par 0 et continue jusqu'à la dernière ligne de votre DataFrame.
Cependant, même lorsque votre index est spécifié automatiquement, vous avez toujours la possibilité de réutiliser l'une de vos colonnes et d'en faire votre index. Vous pouvez facilement le faire en appelant set_index() sur votre DataFrame. Essayez-le ci-dessous !
# Print out your DataFrame `df` to check it out
print(df)
# Set 'C' as the index of your DataFrame
df.set_index('C') A B C
0 1 2 3
1 4 5 6
2 7 8 9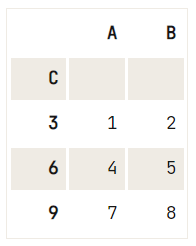
Avant de passer à la solution, il convient d'abord de comprendre le concept de loc et ses différences avec d'autres attributs d'indexation tels que .iloc[] et .ix[] :
Tout cela peut sembler très compliqué. Illustrons tout cela par un petit exemple :
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2, 'A', 4], columns=[48, 49, 50])
# Pass `2` to `loc`
print(df.loc[2])
# Pass `2` to `iloc`
print(df.iloc[2])48 1
49 2
50 3
Name: 2, dtype: int64
48 7
49 8
50 9
Name: 4, dtype: int64Notez que dans ce cas, vous avez utilisé un exemple de DataFrame qui n'est pas uniquement basé sur des nombres entiers afin de vous permettre de comprendre plus facilement les différences. Vous voyez bien que passer 2 à .loc[] ou .iloc[]/.ix[] ne donne pas le même résultat !
48 1
49 2
50 3.iloc[] ira consulter les positions de l'indice. Si vous passez par 2, vous obtiendrez un retour :48 7
49 8
50 9.ix[] aura le même comportement que iloc et regardera les positions dans l'index. Vous obtiendrez le même résultat que .iloc[].Maintenant que la différence entre .iloc[], .loc[] et .ix[] est claire, vous êtes prêt à ajouter des lignes à votre DataFrame !
Conseil: suite à ce que vous venez de lire, vous comprenez maintenant que la recommandation générale est d'utiliser .loc pour insérer des lignes dans votre DataFrame. En effet, si vous utilisez df.ix[], vous risquez d'essayer de référencer un index à valeur numérique avec la valeur de l'index et d'écraser accidentellement une ligne existante de votre DataFrame. Vous devriez éviter cela !
Vérifiez une nouvelle fois la différence dans le DataFrame ci-dessous :
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), index= [2.5, 12.6, 4.8], columns=[48, 49, 50])
# This will make an index labeled `2` and add the new values
df.loc[2] = [11, 12, 13]
print(df) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
2.0 11 12 13Vous comprenez pourquoi tout cela peut être déroutant, n'est-ce pas ?
Dans certains cas, vous souhaitez que votre index fasse partie de votre DataFrame. Vous pouvez facilement le faire en prenant une colonne de votre DataFrame ou en faisant référence à une colonne que vous n'avez pas encore créée et en l'affectant à la propriété .index, comme ceci :
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Use `.index`
df['D'] = df.index
# Print `df`
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2En d'autres termes, vous indiquez à votre DataFrame qu'il doit prendre la colonne A comme index.
Toutefois, si vous souhaitez ajouter des colonnes à votre DataFrame, vous pouvez également suivre la même approche que lorsque vous ajoutez un index à votre DataFrame : vous utilisez .loc[] ou .iloc[]. Dans ce cas, vous ajoutez une série à un DataFrame existant à l'aide de .loc[]:
# Study the DataFrame `df`
print(df)
# Append a column to `df`
df.loc[:, 4] = pd.Series(['5', '6', '7'], index=df.index)
# Print out `df` again to see the changes
print(df) A B C D
0 1 2 3 0
1 4 5 6 1
2 7 8 9 2
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7N'oubliez pas qu'un objet Series est comparable à une colonne d'un DataFrame. Cela explique pourquoi vous pouvez facilement ajouter une série à un DataFrame existant. Notez également que l'observation faite précédemment à propos de .loc[] reste valable, même lorsque vous ajoutez des colonnes à votre DataFrame !
Si votre index n'est pas tout à fait comme vous le souhaitez, vous pouvez choisir de le réinitialiser. Vous pouvez facilement le faire avec .reset_index(). Cependant, vous devez rester vigilant, car vous pouvez passer plusieurs arguments qui peuvent faire ou défaire le succès de votre réinitialisation :
# Check out the weird index of your dataframe
print(df)
# Use `reset_index()` to reset the values.
df_reset = df.reset_index(level=0, drop=True)
# Print `df_reset`
print(df_reset) A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7
A B C D 4
0 1 2 3 0 5
1 4 5 6 1 6
2 7 8 9 2 7Vous pouvez essayer de remplacer l'argument drop par inplace dans l'exemple ci-dessus et voir ce qui se passe !
Notez que vous utilisez l'argument drop pour indiquer que vous voulez vous débarrasser de l'index qui existait. Si vous aviez utilisé inplace, l'index original avec les flottants est ajouté comme une colonne supplémentaire à votre DataFrame.
Maintenant que vous avez vu comment sélectionner et ajouter des indices, des lignes et des colonnes à votre DataFrame, il est temps d'envisager un autre cas d'utilisation : supprimer ces trois éléments de votre structure de données.
Si vous souhaitez supprimer l'index de votre DataFrame, vous devez reconsidérer votre décision car les DataFrames et les Séries ont toujours un index.
Cependant, ce que vous *pouvez* faire, c'est, par exemple :
del df.index.name,df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
df.reset_index().drop_duplicates(subset='index', keep='last').set_index('index')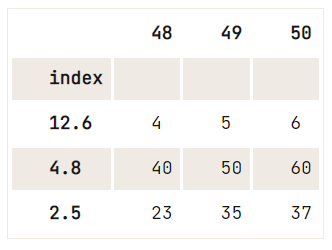
Maintenant que vous savez comment supprimer un index de votre DataFrame, vous pouvez passer à la suppression des colonnes et des lignes !
Pour éliminer (une sélection de) colonnes de votre DataFrame, vous pouvez utiliser la méthode drop():
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out the DataFrame `df`
print(df)
# Drop the column with label 'A'
df.drop('A', axis=1, inplace=True)
# Drop the column at position 1
df.drop(df.columns[[1]], axis=1) A B C
0 1 2 3
1 4 5 6
2 7 8 9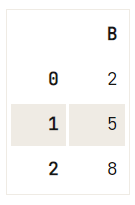
Vous vous dites peut-être maintenant : ce n'est pas si simple ; il y a des arguments supplémentaires qui sont transmis à la méthode drop()!
axis est soit 0 lorsqu'il indique des lignes, soit 1 lorsqu'il est utilisé pour supprimer des colonnes.inplace sur True pour supprimer la colonne sans avoir à réaffecter le DataFrame.Vous pouvez supprimer les lignes dupliquées de votre DataFrame en exécutant df.drop_duplicates(). Vous pouvez également supprimer des lignes de votre DataFrame, en ne prenant en compte que les valeurs en double qui existent dans une colonne.
Regardez cet exemple :
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [40, 50, 60], [23, 35, 37]]),
index= [2.5, 12.6, 4.8, 4.8, 2.5],
columns=[48, 49, 50])
# Check out your DataFrame `df`
print(df)
# Drop the duplicates in `df`
df.drop_duplicates([48], keep='last') 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37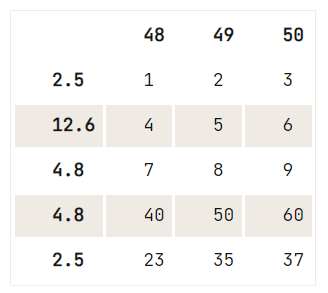
S'il n'y a pas de critère d'unicité pour la suppression que vous souhaitez effectuer, vous pouvez utiliser la méthode drop(), où vous utilisez la propriété index pour spécifier l'index des lignes que vous souhaitez supprimer de votre DataFrame :
# Check out the DataFrame `df`
print(df)
# Drop the index at position 1
df.drop(df.index[1]) 48 49 50
2.5 1 2 3
12.6 4 5 6
4.8 7 8 9
4.8 40 50 60
2.5 23 35 37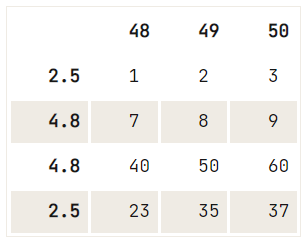
Après cette commande, il se peut que vous souhaitiez réinitialiser l'index.
Conseil : essayez de réinitialiser l'index du DataFrame résultant par vous-même ! N'oubliez pas d'utiliser l'argument drop si vous le jugez nécessaire.
Pour donner aux colonnes ou aux valeurs d'index de votre DataFrame une valeur différente, il est préférable d'utiliser la méthode .rename().
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Check out your DataFrame `df`
print(df)
# Define the new names of your columns
newcols = {
'A': 'new_column_1',
'B': 'new_column_2',
'C': 'new_column_3'
}
# Use `rename()` to rename your columns
df.rename(columns=newcols, inplace=True)
# Rename your index
df.rename(index={1: 'a'}) A B C
0 1 2 3
1 4 5 6
2 7 8 9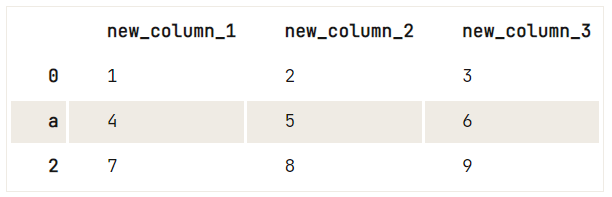
Conseil: essayez de remplacer l'argument inplace dans la première tâche (renommer vos colonnes) par False et voyez ce que le script rend maintenant comme résultat. Vous voyez que le DataFrame n'a pas été réaffecté lorsque les colonnes ont été renommées. Par conséquent, la deuxième tâche prend en entrée le DataFrame d'origine et non celui que vous venez de récupérer lors de la première opération rename().
Maintenant que vous avez répondu à une première série de questions sur les DataFrames de Pandas, il est temps d'aller au-delà des bases et de vous salir les mains pour de vrai car les DataFrames vont bien au-delà de ce que vous avez vu dans la première section.
La plupart du temps, vous souhaiterez également pouvoir effectuer des opérations sur les valeurs réelles contenues dans votre DataFrame. Dans les sections suivantes, vous découvrirez plusieurs façons de formater les valeurs de votre DataFrame pandas.
Pour remplacer certaines chaînes de caractères dans votre DataFrame, vous pouvez facilement utiliser replace(): passez les valeurs que vous souhaitez modifier, suivies des valeurs par lesquelles vous souhaitez les remplacer.
Comme ceci :
df = pd.DataFrame({"Student1":['OK','Awful','Acceptable'],
"Student2":['Perfect','Awful','OK'],
"Student3":['Acceptable','Perfect','Poor']})
# Study the DataFrame `df` first
print(df)
# Replace the strings by numerical values (0-4)
df.replace(['Awful', 'Poor', 'OK', 'Acceptable', 'Perfect'], [0, 1, 2, 3, 4]) Student1 Student2 Student3
0 OK Perfect Acceptable
1 Awful Awful Perfect
2 Acceptable OK Poor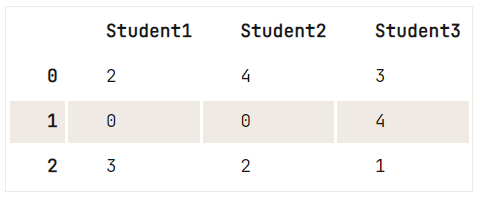
Notez qu'il existe également un argument regex qui peut vous aider considérablement lorsque vous êtes confronté à des combinaisons de chaînes étranges :
df = pd.DataFrame([["1\n", 2, "3\n"], [4, 5, "6\n"] ,[7, "8\n", 9]])
# Check out your DataFrame `df`
print(df)
# Replace strings by others with `regex`
df.replace({'\n': ''}, regex=True) 0 1 2
0 1\n 2 3\n
1 4 5 6\n
2 7 8\n 9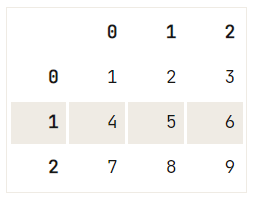
En bref, replace() est principalement ce dont vous avez besoin lorsque vous souhaitez remplacer des valeurs ou des chaînes de caractères dans votre DataFrame par d'autres !
L'élimination des parties non désirées des cordes est un travail fastidieux. Heureusement, il existe une solution simple à ce problème !
df = pd.DataFrame([["+-1aAbBcC", "2", "+-3aAbBcC"], ["4", "5", "+-6aAbBcC"] ,["7", "+-8aAbBcC", "9"]])
# Check out your DataFrame
print(df)
# Delete unwanted parts from the strings in the first column
df[0] = df[0].map(lambda x: x.lstrip('+-').rstrip('aAbBcC'))
# Check out the result again
df 0 1 2
0 +-1aAbBcC 2 +-3aAbBcC
1 4 5 +-6aAbBcC
2 7 +-8aAbBcC 9
Vous utilisez map() sur la colonne result pour appliquer la fonction lambda à chaque élément ou à chaque élément de la colonne. La fonction elle-même prend la valeur de la chaîne et supprime le + ou - qui se trouve à gauche, ainsi que les six aAbBcC qui se trouvent à droite.
Il s'agit d'une tâche de formatage un peu plus difficile. Cependant, le morceau de code suivant vous guidera à travers les étapes :
df = pd.DataFrame({"Age": [34, 22, 19],
"PlusOne":[0,0,1],
"Ticket":["23:44:55", "66:77:88", "43:68:05 56:34:12"]})
# Inspect your DataFrame `df`
print(df)
# Split out the two values in the third row
# Make it a Series
# Stack the values
ticket_series = df['Ticket'].str.split(' ').apply(pd.Series, 1).stack()
# Get rid of the stack:
# Drop the level to line up with the DataFrame
ticket_series.index = ticket_series.index.droplevel(-1)
print(ticket_series) Age PlusOne Ticket
0 34 0 23:44:55
1 22 0 66:77:88
2 19 1 43:68:05 56:34:12
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: object
0
0 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
En bref, ce que vous faites est :
Ticket du DataFrame df et vous y ajoutez un espace. Cela permettra de s'assurer que les deux billets se retrouveront dans deux rangées distinctes à la fin. Ensuite, vous prenez ces quatre valeurs (les quatre numéros de ticket) et vous les placez dans un objet Series : 0 1
0 23:44:55 NaN
1 66:77:88 NaN
2 43:68:05 56:34:12NaN! Vous devez empiler les séries pour vous assurer que vous n'avez pas de valeurs NaN dans la série résultante.0 0 23:44:55
1 0 66:77:88
2 0 43:68:05
1 56:34:120 23:44:55
1 66:77:88
2 43:68:05
2 56:34:12
dtype: objectTicket.Vous pouvez souhaiter ajuster les données de votre DataFrame en lui appliquant une fonction. Commençons par répondre à cette question en créant votre propre fonction lambda :
doubler = lambda x: x*2Conseil: si vous souhaitez en savoir plus sur les fonctions en Python, pensez à suivre ce tutoriel sur les fonctions en Python.
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
# Study the `df` DataFrame
print(df)
# Apply the `doubler` function to the `A` DataFrame column
df['A'].apply(doubler)
A B C
0 1 2 3
1 4 5 6
2 7 8 9
0 2
1 8
2 14
Name: A, dtype: int64Notez que vous pouvez également sélectionner la ligne de votre DataFrame et lui appliquer la fonction lambda doubler. Rappelez-vous que vous pouvez facilement sélectionner une ligne dans votre DataFrame en utilisant .loc[] ou .iloc[].
Ensuite, vous exécuterez quelque chose comme ceci, selon que vous souhaitez sélectionner votre index en fonction de sa position ou de son étiquette :
df.loc[0].apply(doubler)Notez que la fonction apply() n'applique la fonction doubler que le long de l'axe de votre DataFrame. Cela signifie que vous ciblez soit l'index, soit les colonnes. En d'autres termes, il s'agit d'une ligne ou d'une colonne.
Toutefois, si vous souhaitez l'appliquer à chaque élément ou élément par élément, vous pouvez utiliser la fonction map(). Vous pouvez simplement remplacer la fonction apply() dans le morceau de code ci-dessus par map(). N'oubliez pas de lui passer la fonction doubler pour vous assurer que vous multipliez les valeurs par 2.
Supposons que vous souhaitiez appliquer cette fonction de doublement non seulement à la colonne A de votre DataFrame, mais à l'ensemble de celle-ci. Dans ce cas, vous pouvez utiliser applymap() pour appliquer la fonction doubler à chaque élément de l'ensemble du DataFrame :
doubled_df = df.applymap(doubler)
print(doubled_df) A B C
0 2 4 6
1 8 10 12
2 14 16 18Notez que dans ces cas, nous avons travaillé avec des fonctions lambda ou des fonctions anonymes qui sont créées au moment de l'exécution. Cependant, vous pouvez également écrire votre propre fonction. Par exemple :
def doubler(x):
if x % 2 == 0:
return x
else:
return x * 2
# Use `applymap()` to apply `doubler()` to your DataFrame
doubled_df = df.applymap(doubler)
# Check the DataFrame
print(doubled_df) A B C
0 2 2 6
1 4 10 6
2 14 8 18Si vous souhaitez obtenir plus d'informations sur le flux de contrôle en Pythonvous pouvez toujours consulter nos autres ressources.
La fonction que vous utiliserez est la fonction Pandas Dataframe(): elle vous demande de transmettre les données que vous souhaitez introduire, les indices et les colonnes.
N'oubliez pas que les données contenues dans le cadre de données ne doivent pas nécessairement être homogènes. Il peut s'agir de différents types de données !
Vous pouvez utiliser cette fonction de plusieurs façons pour créer un DataFrame vide. Tout d'abord, vous pouvez utiliser numpy.nan pour initialiser votre cadre de données avec NaNs. Notez que numpy.nan a le type float.
df = pd.DataFrame(np.nan, index=[0,1,2,3], columns=['A'])
print(df) A
0 NaN
1 NaN
2 NaN
3 NaNActuellement, le type de données du cadre de données est déduit par défaut : comme numpy.nan est de type float, le cadre de données contiendra également des valeurs de type float. Toutefois, vous pouvez également forcer le DataFrame à être d'un type particulier en ajoutant l'attribut dtype et en renseignant le type souhaité. Comme dans cet exemple :
df = pd.DataFrame(index=range(0,4),columns=['A'], dtype='float')
print(df)
A
0 NaN
1 NaN
2 NaN
3 NaNNotez que si vous ne spécifiez pas les étiquettes ou l'index des axes, ils seront construits à partir des données d'entrée sur la base de règles de bon sens.
Pandas peut le reconnaître, mais vous devez l'aider un tout petit peu : ajoutez l'argument parse_dates lorsque vouslisez des données provenant, par exemple, d'un fichier de valeurs séparées par des virgules (CSV):
import pandas as pd
pd.read_csv('yourFile', parse_dates=True)
# or this option:
pd.read_csv('yourFile', parse_dates=['columnName'])Il existe cependant toujours des formats de date et d'heure bizarres.
Ne vous inquiétez pas ! Dans ce cas, vous pouvez construire votre propre analyseur syntaxique. Vous pouvez, par exemple, créer une fonction lambda qui prend votre DateTime et la contrôle avec une chaîne de format.
import pandas as pd
dateparser = lambda x: pd.datetime.strptime(x, '%Y-%m-%d %H:%M:%S')
# Which makes your read command:
pd.read_csv(infile, parse_dates=['columnName'], date_parser=dateparse)
# Or combine two columns into a single DateTime column
pd.read_csv(infile, parse_dates={'datetime': ['date', 'time']}, date_parser=dateparse)Remodeler votre DataFrame, c'est le transformer de manière à ce que la structure résultante soit plus adaptée à votre analyse de données. En d'autres termes, le remodelage ne concerne pas tant le formatage des valeurs contenues dans le DataFrame que la transformation de sa forme.
Ceci répond aux questions "quand" et "pourquoi". Mais comment remodeler votre DataFrame ?
Trois modes de remodelage posent fréquemment des questions aux utilisateurs : le pivotement, l'empilement et le dépilement, et la fusion.
Vous pouvez utiliser la fonction pivot() pour créer un nouveau tableau dérivé à partir de votre tableau d'origine. Lorsque vous utilisez la fonction, vous pouvez passer trois arguments :
values: cet argument vous permet de spécifier les tableaux de votre DataFrame d'origine que vous souhaitez voir apparaître dans votre tableau croisé dynamique.columns: ce que vous donnez à cet argument deviendra une colonne dans votre tableau.index: ce que vous donnez à cet argument deviendra un index dans votre tableau.# Import pandas
import pandas as pd
# Create your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot the DataFrame
pivot_products = products.pivot(index='category', columns='store', values='price')
# Check out the result
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 55.75 NaN 111.55Lorsque vous n'indiquez pas précisément les valeurs que vous souhaitez voir figurer dans le tableau obtenu, vous effectuez un pivot sur plusieurs colonnes :
# Import the Pandas library
import pandas as pd
# Construct the DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 55.75, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Use `pivot()` to pivot your DataFrame
pivot_products = products.pivot(index='category', columns='store')
# Check out the results
print(pivot_products)
price testscore
store Dia Fnac Walmart Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42 3.0 NaN 4.0
Entertainment NaN 15.95 19.99 NaN 7.0 5.0
Tech 55.75 NaN 111.55 5.0 NaN 8.0Notez que vos données ne peuvent pas comporter de lignes avec des valeurs dupliquées pour les colonnes que vous spécifiez. Si ce n'est pas le cas, vous obtiendrez un message d'erreur. Si vous ne pouvez pas garantir l'unicité de vos données, vous devrez plutôt utiliser la méthode pivot_table:
# Import the Pandas library
import pandas as pd
# Your DataFrame
products = pd.DataFrame({'category': ['Cleaning', 'Cleaning', 'Entertainment', 'Entertainment', 'Tech', 'Tech'],
'store': ['Walmart', 'Dia', 'Walmart', 'Fnac', 'Dia','Walmart'],
'price':[11.42, 23.50, 19.99, 15.95, 19.99, 111.55],
'testscore': [4, 3, 5, 7, 5, 8]})
# Pivot your `products` DataFrame with `pivot_table()`
pivot_products = products.pivot_table(index='category', columns='store', values='price', aggfunc='mean')
# Check out the results
print(pivot_products)store Dia Fnac Walmart
category
Cleaning 23.50 NaN 11.42
Entertainment NaN 15.95 19.99
Tech 19.99 NaN 111.55Notez l'argument supplémentaire aggfunc qui est transmis à la méthode pivot_table. Cet argument indique que vous utilisez une fonction d'agrégation permettant de combiner plusieurs valeurs. Dans cet exemple, vous pouvez clairement voir que la fonction mean est utilisée.
stack() et unstack() pour remodeler votre DataFrame PandasVous avez déjà vu un exemple d'empilage dans la section 5. En substance, vous vous souvenez peut-être encore que lorsque vous empilez un DataFrame, vous le rendez plus grand. Vous déplacez l'indice de la colonne la plus proche pour qu'il devienne l'indice de la ligne la plus proche. Vous renvoyez un DataFrame avec un index comportant un nouveau niveau interne d'étiquettes de ligne.
Si vous n'êtes pas sûrs du fonctionnement de l'applicationstack().
L'inverse de l'empilage s'appelle le dépilage. Comme pour stack(), vous utilisez unstack() pour déplacer l'indice de la ligne la plus proche pour qu'il devienne l'indice de la colonne la plus proche.
Pour une explication du pivotement, de l'empilement et du dépilement des pandas, consultez notre article intitulé Remodeler les données avec pandas .
melt()La fusion est considérée comme utile dans les cas où vous avez des données dont une ou plusieurs colonnes sont des variables d'identification, tandis que toutes les autres colonnes sont considérées comme des variables mesurées.
Ces variables mesurées sont toutes "non pivotées" par rapport à l'axe des lignes. Autrement dit, alors que les variables mesurées qui étaient réparties sur la largeur du DataFrame, la fonte fera en sorte qu'elles soient placées dans la hauteur de celui-ci. En d'autres termes, votre DataFrame s'allonge au lieu de s'élargir.
Par conséquent, vous avez deux colonnes non identifiées, à savoir "variable" et "valeur".
Illustrons cela par un exemple :
# The `people` DataFrame
people = pd.DataFrame({'FirstName' : ['John', 'Jane'],
'LastName' : ['Doe', 'Austen'],
'BloodType' : ['A-', 'B+'],
'Weight' : [90, 64]})
# Use `melt()` on the `people` DataFrame
print(pd.melt(people, id_vars=['FirstName', 'LastName'], var_name='measurements')) FirstName LastName measurements value
0 John Doe BloodType A-
1 Jane Austen BloodType B+
2 John Doe Weight 90
3 Jane Austen Weight 64Si vous cherchez d'autres moyens de remodeler vos données, consultez la documentation.
Vous pouvez itérer sur les lignes de votre DataFrame à l'aide d'une boucle for en combinaison avec un appel iterrows() sur votre DataFrame :
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
for index, row in df.iterrows() :
print(row['A'], row['B'])1 2
4 5
7 8iterrows() vous permet de boucler efficacement les lignes de votre DataFrame sous forme de paires (index, Series). En d'autres termes, il vous donne comme résultat des tuples (index, ligne).
Une fois que vous avez effectué vos manipulations de données avec Pandas, vous voudrez peut-être exporter le DataFrame dans un autre format. Cette section aborde deux façons de sortir votre DataFrame pandas vers un fichier CSV ou Excel.
Pour écrire un DataFrame sous forme de fichier CSV, vous pouvez utiliser to_csv():
import pandas as pd
df.to_csv('myDataFrame.csv')Ce morceau de code semble assez simple, mais c'est là que les difficultés commencent pour la plupart des gens, car vous aurez des exigences spécifiques pour la sortie de vos données. Vous ne voulez peut-être pas de virgule comme délimiteur, ou vous voulez spécifier un encodage particulier.
Ne vous inquiétez pas ! Vous pouvez passer des arguments supplémentaires à to_csv() pour vous assurer que vos données sont restituées comme vous le souhaitez !
sep:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t')encoding:import pandas as pd
df.to_csv('myDataFrame.csv', sep='\t', encoding='utf-8')NaN ou manquantes soient représentées, si vous voulez ou non éditer l'en-tête, si vous voulez ou non écrire les noms de ligne, si vous voulez une compression, vous pouvez lire les options.De la même manière que pour la sortie de votre DataFrame au format CSV, vous pouvez utiliser to_excel() pour écrire votre tableau dans Excel. Cependant, c'est un peu plus compliqué :
import pandas as pd
writer = pd.ExcelWriter('myDataFrame.xlsx')
df.to_excel(writer, 'DataFrame')
writer.save()Notez cependant que, comme pour to_csv(), vous disposez de nombreux arguments supplémentaires tels que startcol, startrow, et ainsi de suite, pour vous assurer que vous produisez vos données correctement. Pour en savoir plus sur l'importation et l'exportation de données vers des fichiers CSV à l'aide de pandas, consultez notre tutoriel.
Si, toutefois, vous souhaitez plus d'informations sur les outils IO dans Pandas, vous pouvez consulter la documentation pandas DataFrames to excel.
C'est tout ! Vous avez terminé avec succès le tutoriel Pandas DataFrame !
Les réponses aux 11 questions fréquemment posées sur Pandas représentent les fonctions essentielles dont vous aurez besoin pour importer, nettoyer et manipuler vos données dans le cadre de votre travail de science des données. Vous n'êtes pas sûr d'avoir suffisamment approfondi la question ? Notre cours sur l'importation de données en Python vous aidera ! Si vous avez bien compris, vous voudrez peut-être voir les Pandas à l'œuvre dans un projet réel. La série de tutoriels L'importance du prétraitement en science des données et le pipeline d'apprentissage automatique est à lire absolument, et le cours ouvert Introduction à Python et à l'apprentissage automatique est à compléter impérativement.
En savoir plus sur Python et pandas
Cours
Cours
Cours
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Laiba Siddiqui
Tutoriel
Abid Ali Awan
