
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Phi-4-multimodal ist eine leichte multimodales Basis-Modell, das von Microsoft entwickelt wurde. Es ist Teil der Phi-Familie von Microsofts kleinen Sprachmodellen (SLMs).
In diesem Tutorial erkläre ich dir Schritt für Schritt, wie du mit Phi-4-multimodal einen multimodalen Sprachtutor erstellst , der mit Text, Bildern und Audio arbeiten kann. Die wichtigsten Merkmale dieser Anwendung sind:
Lass uns zuerst eine kurze Präsentation des Phi-4-multimodalen Modells machen und dann beginnen wir mit dem Aufbau der App.
Phi-4-multimodal ist ein fortschrittliches KI-Modell, das für die Text-, Bild- und Sprachverarbeitung entwickelt wurde. Sie ermöglicht die nahtlose Integration verschiedener Modalitäten und ist damit ideal für Sprachlernanwendungen. Einige der wichtigsten Funktionen sind:
Mit einer Kontextlänge von 128K Token ist das multimodale Phi-4-Modell für effizientes Reasoning und speicherbegrenzte Umgebungen optimiert und eignet sich daher perfekt für KI-gestütztes Sprachenlernen in Echtzeit.
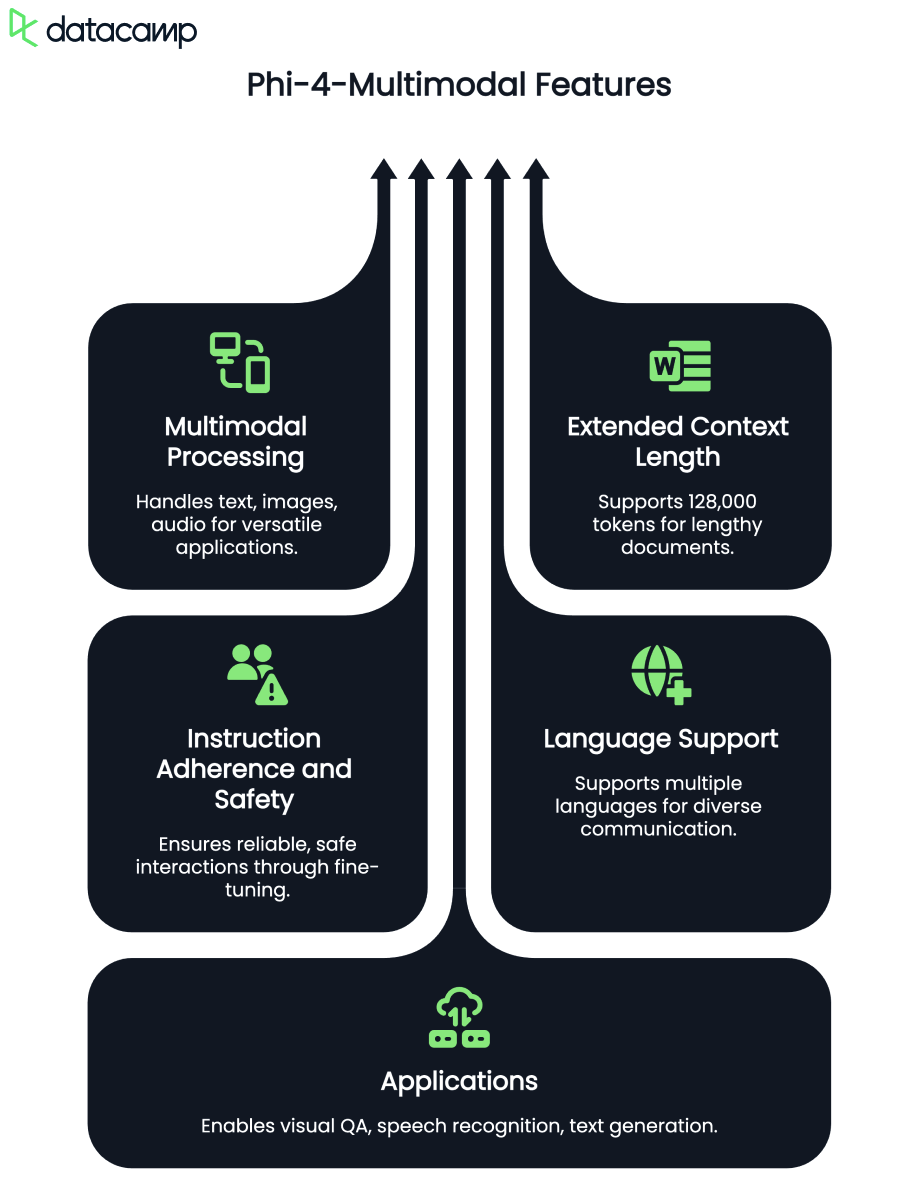
Die multimodale Sprachtutoren-App, die wir entwickeln werden, ist ein KI-gestütztes interaktives Tool, das den Nutzern beim Erlernen neuer Sprachen durch eine Kombination aus Text-, Bild- und Audiointeraktionen helfen soll.
Bevor wir beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
pip install gradio transformers torch soundfile pillowAußerdem müssen wir sicherstellen, dass FlashAttention2 für eine bessere Leistung installiert ist:
pip install flash-attn --no-build-isolationHinweis: In diesem Projekt wird ein A100-Grafikprozessor auf einem Google Colab-Notebook verwendet. Wenn du einen älteren Grafikprozessor verwendest (z.B. NVIDIA V100), musst du FlashAttention2 eventuell deaktivieren, indem du _attn_implementation="eager" im Schritt der Modellinitialisierung einstellst.
Sobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
import gradio as gr
import torch
import requests
import io
import os
import soundfile as sf
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfigUm die multimodalen Fähigkeiten des Phi-4 zu nutzen, laden wir zunächst sowohl das Modell als auch den Prozessor. Der Modellpfad wird von Hugging FaceDer Prozessor kümmert sich um die Tokenisierung von Text, die Größenänderung und Normalisierung von Bildern und die Konvertierung von Audiowellenformen in ein mit dem Modell kompatibles Format für eine nahtlose multimodale Verarbeitung.
# Load model and processor
model_path = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2',
).cuda()
generation_config = GenerationConfig.from_pretrained(model_path)Der Modellinitialisierungsschritt verwendet die 'AutoModelForCausalLM.from_pretrained() function to load the pretrained Phi-4 model for causal language modeling (CLM) and loads the model on GPU using device_map="cuda".
Ein wichtiger Parameter in diesem Schritt ist _attn_implementation='flash_attention_2'`, der FlashAttention2 für einen schnelleren und speichereffizienteren Aufmerksamkeitsmechanismus verwendet, insbesondere für die Verarbeitung langer Kontexte.
Jetzt, wo wir das Modell geladen haben, können wir die wichtigsten Funktionen erstellen.
Ein wichtiger Aspekt jedes LLM- oder VLM-basierten Projekts ist es, sicherzustellen, dass das Modell genaue und relevante Antworten erzeugt. Dazu gehört auch, dass jeglicher Aufforderungstext aus der Ausgabe entfernt wird, um sicherzustellen, dass die Nutzer eine saubere und direkte Antwort erhalten, ohne dass die erste Anweisung am Anfang erscheint.
def clean_response(response, instruction_keywords):
"""Removes the prompt text dynamically based on instruction keywords."""
for keyword in instruction_keywords:
if response.lower().startswith(keyword.lower()):
response = response[len(keyword):].strip()
return responseWir verwenden einfach die Funktion strip(), um den Text der Aufforderung auf der Grundlage der Schlüsselwörter der Anweisung zu entfernen.
Verarbeiten wir nun unsere Eingaben, die je nach Benutzereingabe oder Szenario Text, Bild oder Audio sein können.
def process_input(file, input_type, question):
user_prompt = "<|user|>"
assistant_prompt = "<|assistant|>"
prompt_suffix = "<|end|>"
if input_type == "Image":
prompt= f'{user_prompt}<|image_1|>{question}{prompt_suffix}{assistant_prompt}'
image = Image.open(file)
inputs = processor(text=prompt, images=image, return_tensors='pt').to(model.device)
elif input_type == "Audio":
prompt= f'{user_prompt}<|audio_1|>{question}{prompt_suffix}{assistant_prompt}'
audio, samplerate = sf.read(file)
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to(model.device)
elif input_type == "Text":
prompt = f'{user_prompt}{question} "{file}"{prompt_suffix}{assistant_prompt}'
inputs = processor(text=prompt, return_tensors='pt').to(model.device)
else:
return "Invalid input type"
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
return clean_response(response, [question])Die obige Funktion ist dafür verantwortlich, Text-, Bild- und Audioeingaben zu verarbeiten und eine Antwort nach dem multimodalen Phi-4-Modell zu erzeugen. Hier ist eine technische Aufschlüsselung dieses Workflows:
"Image" ist, wird die Eingabeaufforderung mit einem Bildplatzhalter formatiert (<|image_1|>). Dann wird das Bild geladen und der Prozessor tokenisiert den dazugehörigen Text und extrahiert visuelle Merkmale. Die verarbeiteten Eingaben werden zur optimierten Berechnung an die GPU übertragen."Audio" ist, wird die Eingabeaufforderung mit einem Audio-Platzhalter (<|audio_1|>) aufgebaut. Die Audiodatei wird mit der Funktion sf.read() gelesen, wobei die rohe Wellenform und die Samplerate extrahiert werden. Der Prozessor kodiert dann sowohl den Ton als auch den Text und sorgt so für eine nahtlose Integration für multimodales Verstehen."Text" ist, wird der Text direkt in die Eingabeaufforderung eingebettet. Der Prozessor tokenisiert und kodiert die Eingabe und bereitet sie für die weitere Verarbeitung durch das Modell vor.Als Nächstes verarbeiten wir den Text für die Übersetzung und Grammatikkorrektur mit dem Phi-4-multimodalen Modell.
def process_text_translate(text, target_language):
prompt = f'Translate the following text to {target_language}: "{text}"'
return process_input(text, "Text", prompt)
def process_text_grammar(text):
prompt = f'Check the grammar and provide corrections if needed for the following text: "{text}"'
return process_input(text, "Text", prompt)Die Funktion process_text_translate() erstellt dynamisch einen Übersetzungsprompt, indem sie die Zielsprache angibt, und übergibt den Eingabetext und den strukturierten Prompt an die Funktion process_input() und gibt den übersetzten Text zurück.
In ähnlicher Weise erstellt die Funktion process_text_grammar() eine Grammatikkorrekturaufforderung, ruft die Funktion process_input() mit dem Eingabetext und dem Typ auf und gibt eine grammatikalisch korrigierte Version des Textes zurück. Beide Funktionen optimieren die Sprachverarbeitung, indem sie die Fähigkeiten des Modells zur Übersetzung und Grammatikkorrektur nutzen.
Jetzt sind alle wichtigen logischen Funktionen vorhanden. Als Nächstes arbeiten wir daran, mit Gradio eine interaktive Benutzeroberfläche zu erstellen.
def gradio_interface():
with gr.Blocks() as demo:
gr.Markdown("# Phi 4 Powered - Multimodal Language Tutor")
with gr.Tab("Text-Based Learning"):
text_input = gr.Textbox(label="Enter Text")
language_input = gr.Textbox(label="Target Language", value="French")
text_output = gr.Textbox(label="Response")
text_translate_btn = gr.Button("Translate")
text_grammar_btn = gr.Button("Check Grammar")
text_clear_btn = gr.Button("Clear")
text_translate_btn.click(process_text_translate, inputs=[text_input, language_input], outputs=text_output)
text_grammar_btn.click(process_text_grammar, inputs=[text_input], outputs=text_output)
text_clear_btn.click(lambda: ("", "", ""), outputs=[text_input, language_input, text_output])
with gr.Tab("Image-Based Learning"):
image_input = gr.Image(type="filepath", label="Upload Image")
language_input_image = gr.Textbox(label="Target Language for Translation", value="English")
image_output = gr.Textbox(label="Response")
image_clear_btn = gr.Button("Clear")
image_translate_btn = gr.Button("Translate Text in Image")
image_summarize_btn = gr.Button("Summarize Image")
image_translate_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Extract and translate text", visible=False)], outputs=image_output)
image_summarize_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Summarize this image", visible=False)], outputs=image_output)
image_clear_btn.click(lambda: (None, "", ""), outputs=[image_input, language_input_image, image_output])
with gr.Tab("Audio-Based Learning"):
audio_input = gr.Audio(type="filepath", label="Upload Audio")
language_input_audio = gr.Textbox(label="Target Language for Translation", value="English")
transcript_output = gr.Textbox(label="Transcribed Text")
translated_output = gr.Textbox(label="Translated Text")
audio_clear_btn = gr.Button("Clear")
audio_transcribe_btn = gr.Button("Transcribe & Translate")
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), gr.Textbox(value="Transcribe this audio", visible=False)], outputs=transcript_output)
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), language_input_audio], outputs=translated_output)
audio_clear_btn.click(lambda: (None, "", "", ""), outputs=[audio_input, language_input_audio, transcript_output, translated_output])
demo.launch(debug=True)
if __name__ == "__main__":
gradio_interface()Der obige Code gliedert die Gradio-Oberfläche in drei interaktive Registerkarten: textbasiertes Lernen, bildbasiertes Lernen und audiobasiertes Lernen, die jeweils für unterschiedliche Sprachlernfunktionen konzipiert sind.
Die Nutzer können Text für die Übersetzung oder Grammatikkorrektur eingeben, Bilder für die Textextraktion und Zusammenfassung hochladen oder Audio für die Sprachtranskription und -übersetzung bereitstellen.
Jede Funktion wird mit der Methode click() von Gradio ausgelöst, die wie oben beschrieben Verarbeitungsfunktionen wie process_text_translate(), process_text_grammar() und process_input() aufruft, indem sie die erforderlichen Eingaben übergibt und die Ausgaben dynamisch aktualisiert.
Für jede Registerkarte gibt es eine Clear Taste, mit der die Ein- und Ausgänge zurückgesetzt werden können, um einen reibungslosen Ablauf zu gewährleisten. Schließlich wird die Schnittstelle mit demo.launch(debug=True) gestartet, was es Entwicklern ermöglicht, jeden Fehler in der Anwendung leicht zu beheben.
Hier sind ein paar meiner Experimente mit dieser Anwendung.
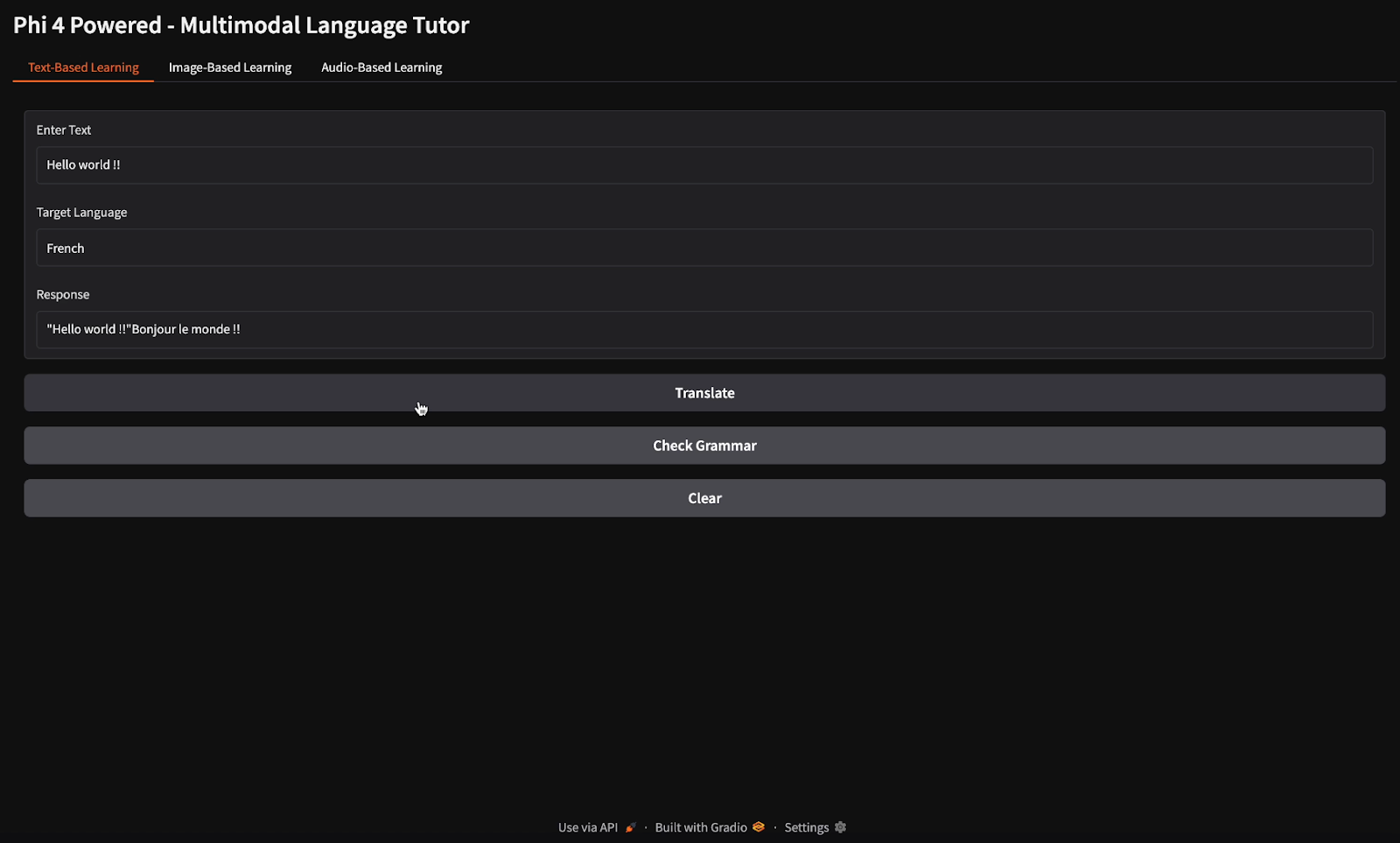
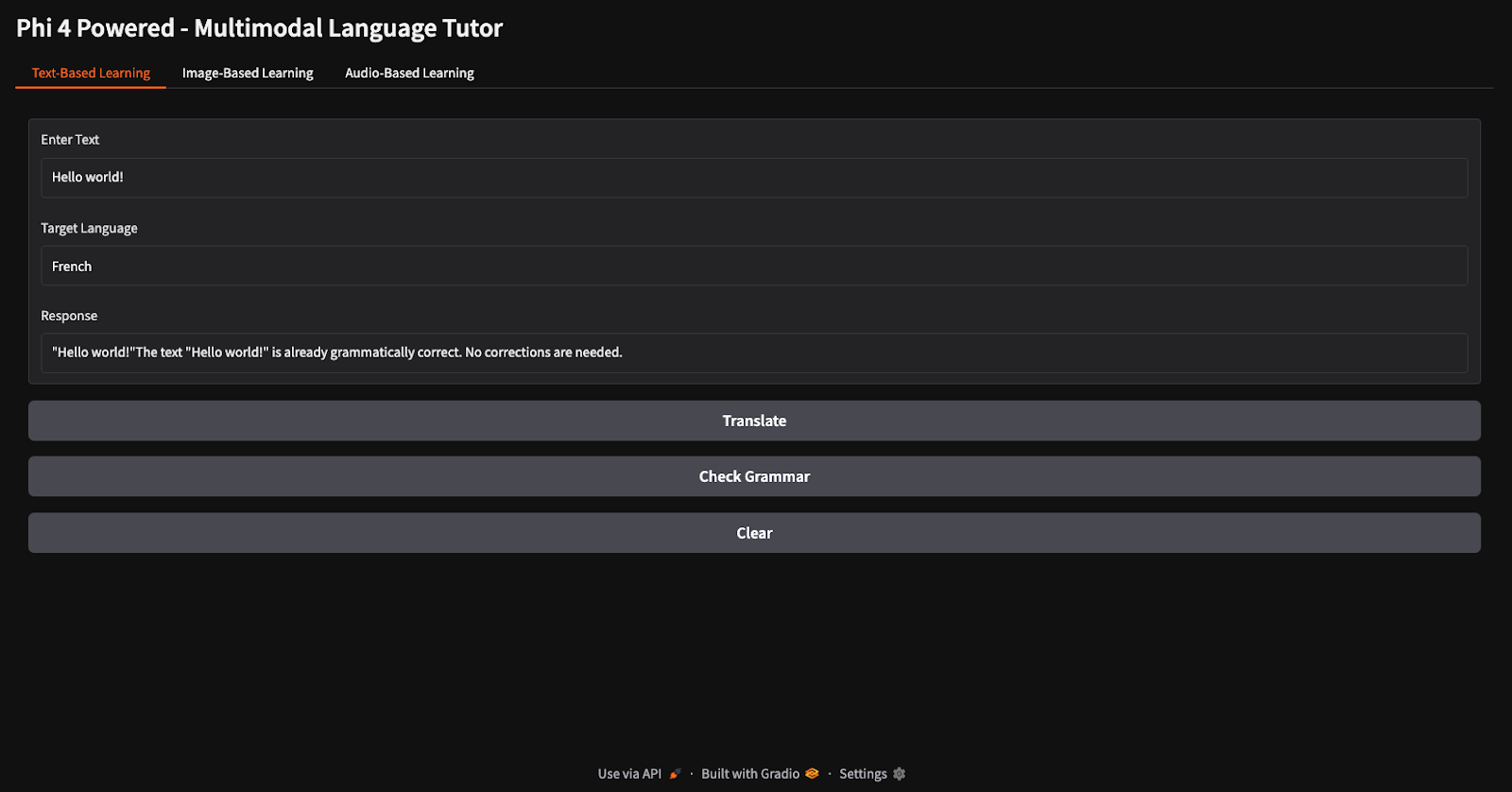
Für die Übersetzungs- und Grammatikprüfung habe ich den Text "Hallo Welt" vorgegeben und das Modell angewiesen, ihn ins Französische zu übersetzen und die Grammatik zu überprüfen (beachte die verschiedenen Schaltflächen für Übersetzung und Grammatikprüfung).
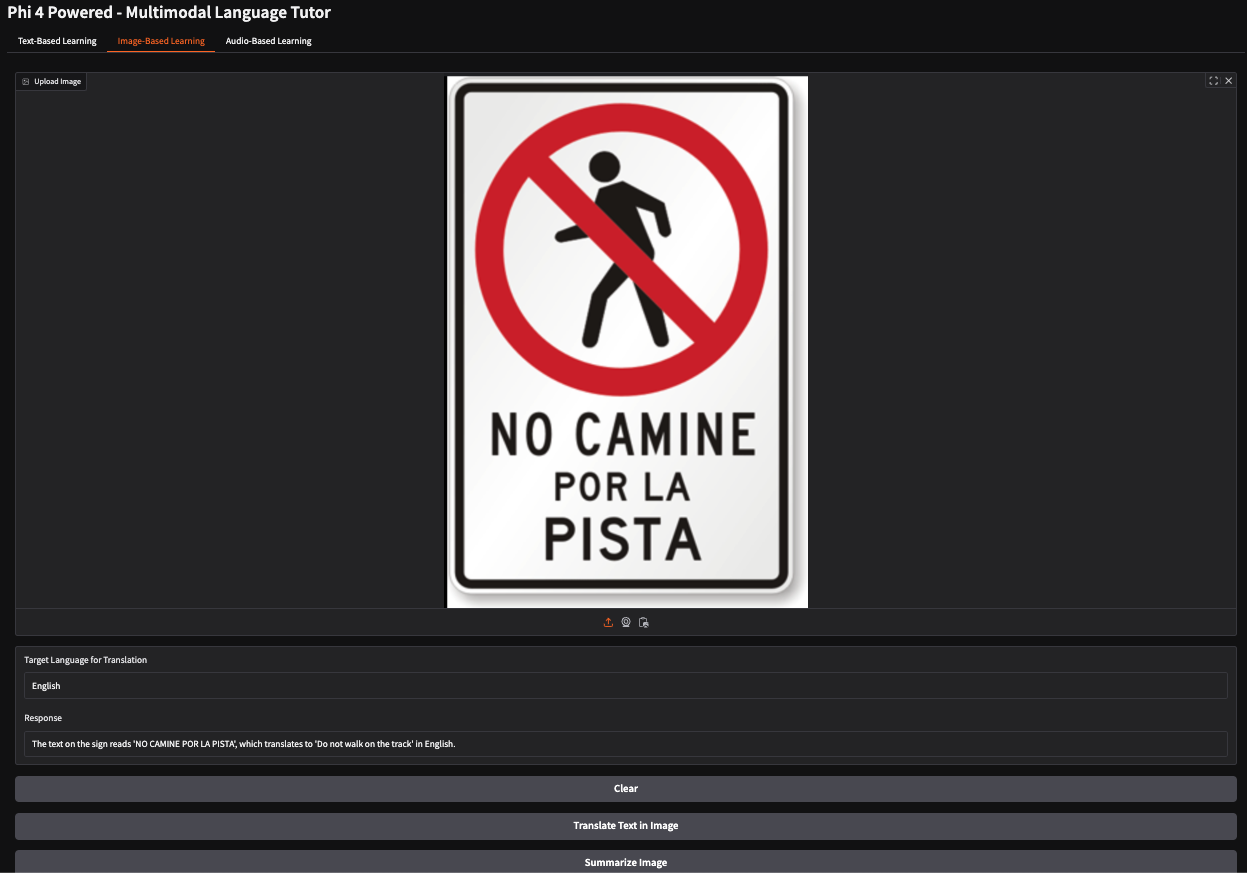
In diesem Beispiel habe ich ein spanisches Stoppschild abgebildet, das die Fußgänger anweist, einen bestimmten Weg nicht zu betreten. Das Modell hat die Bedeutung des Zeichens richtig interpretiert und die Antwort erzeugt: "Geh nicht auf dem Lernpfad."
Für die Audiotranskription stellte ich eine englische Audiodatei zur Verfügung und wies das Modell an, die Sprache zu transkribieren und die Transkription ins Französische zu übersetzen.
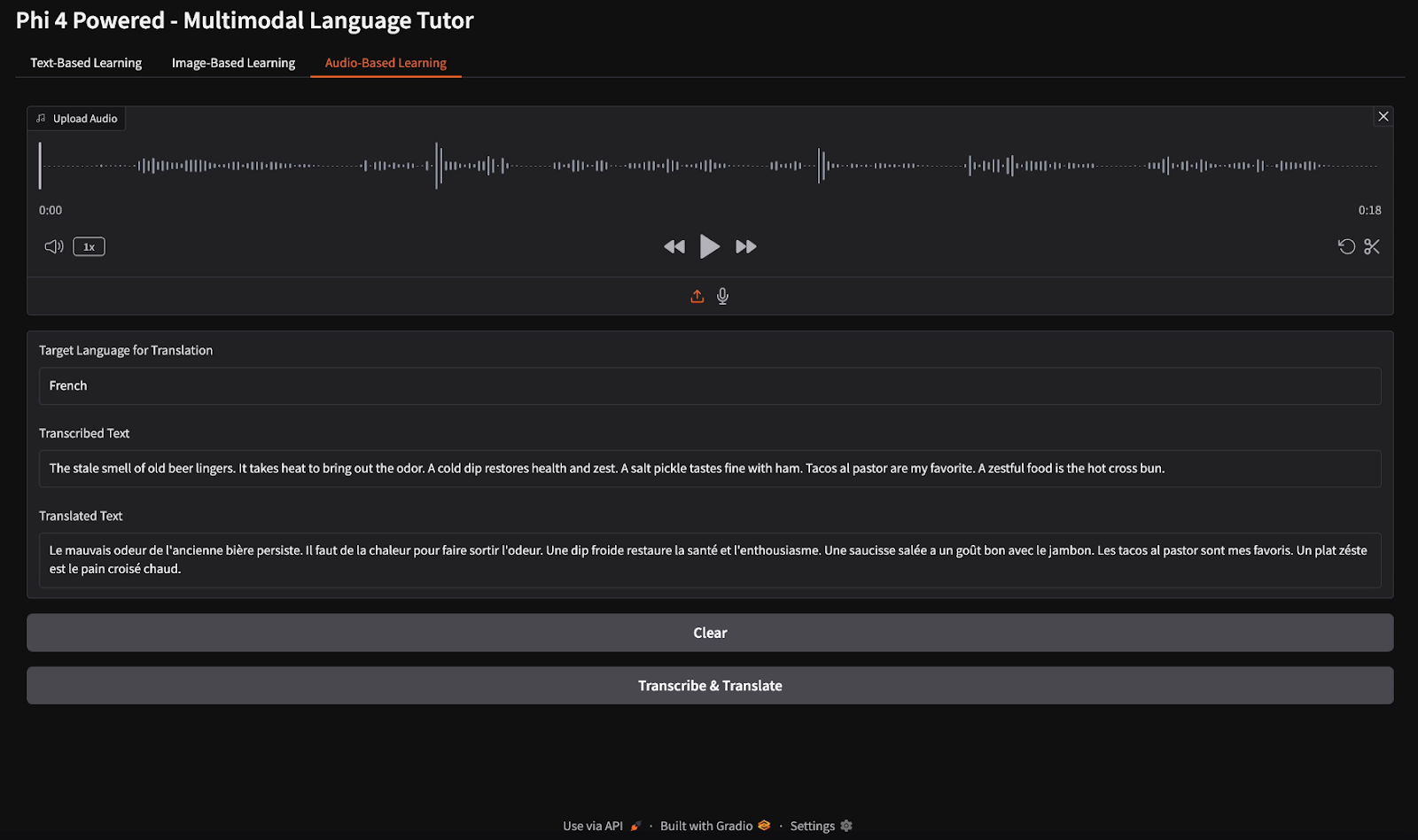
In diesem Tutorial haben wir einen multimodalen Sprachtutor entwickelt, der das multimodale Modell Phi-4 verwendet und text-, bild- und audiobasiertes Sprachenlernen ermöglicht. Wir haben die fortschrittlichen Bild-, Sprach- und Textfunktionen von Phi-4 genutzt, um Übersetzungen in Echtzeit, Grammatikkorrekturen, Sprachtranskription und bildbasierte Lernerfahrungen zu ermöglichen. Dieses Projekt zeigt, wie multimodale KI den Sprachunterricht und die Barrierefreiheit verbessern kann.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs