
Track
Developing AI Applications
21 hr
Phi-4-multimodal is a lightweight multimodal foundation model developed by Microsoft. It is part of Microsoft’s Phi family of small language models (SLMs).
In this tutorial, I’ll explain step-by-step how to use Phi-4-multimodal to build a multimodal language tutor that can work with text, images, and audio. The key features of this application are:
Let’s first do a very quick presentation of the Phi-4-multimodal model, and then we’ll start building the app.
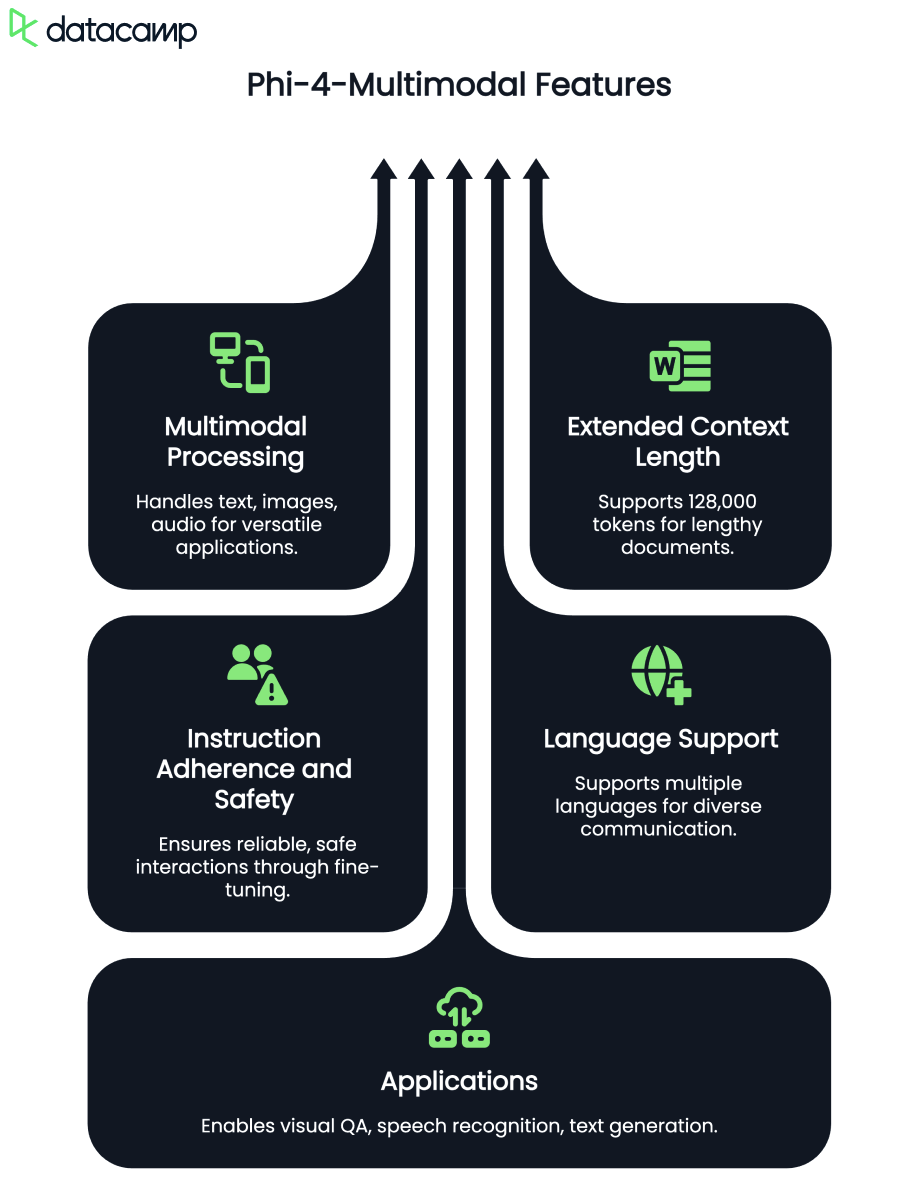
Phi-4-multimodal is an advanced AI model designed for text, vision, and speech processing. It allows seamless integration of multiple modalities, making it ideal for language learning applications. Some of its key capabilities include:
With a 128K token context length, the Phi-4 multimodal model is optimized for efficient reasoning and memory-constrained environments, making it a perfect fit for real-time AI-powered language learning.
The multimodal language tutor app that we’re going to build is an AI-powered interactive tool designed to assist users in learning new languages through a combination of text, image, and audio-based interactions.
Before we start, let’s ensure that we have the following tools and libraries installed:
Run the following commands to install the necessary dependencies:
pip install gradio transformers torch soundfile pillowWe also need to ensure that FlashAttention2 is installed for better performance:
pip install flash-attn --no-build-isolationNote: This project uses an A100 GPU on a Google Colab notebook. If you use an older GPU (e.g., NVIDIA V100), you may need to disable FlashAttention2 by setting _attn_implementation="eager" in the model initialization step.
Once the above dependencies are installed, run the following import commands:
import gradio as gr
import torch
import requests
import io
import os
import soundfile as sf
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfigTo take advantage of Phi-4’s multimodal capabilities, we first load both the model and its processor. The model path is set from Hugging Face, while the processor handles tokenizing text, resizing and normalizing images, and converting audio waveforms into a format compatible with the model for seamless multimodal processing.
# Load model and processor
model_path = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2',
).cuda()
generation_config = GenerationConfig.from_pretrained(model_path)The model initialization step uses the 'AutoModelForCausalLM.from_pretrained() function to load the pretrained Phi-4 model for causal language modeling (CLM) and loads the model on GPU using device_map="cuda".
A key parameter in this step is _attn_implementation='flash_attention_2'`, which uses FlashAttention2 for a faster and more memory-efficient attention mechanism, especially for long-context processing.
Now we have loaded the model, let’s build the key functionalities.
An important aspect of any LLM or VLM-based project is ensuring the model generates accurate and relevant responses. This also involves removing any prompt text from the output, ensuring that users receive a clean and direct response without the initial instruction appearing at the beginning.
def clean_response(response, instruction_keywords):
"""Removes the prompt text dynamically based on instruction keywords."""
for keyword in instruction_keywords:
if response.lower().startswith(keyword.lower()):
response = response[len(keyword):].strip()
return responseWe simply use the strip() function to strip the prompt text based on instruction keywords.
Now, let’s process our inputs, which can be text, image, or audio, depending on the user input or scenario.
def process_input(file, input_type, question):
user_prompt = "<|user|>"
assistant_prompt = "<|assistant|>"
prompt_suffix = "<|end|>"
if input_type == "Image":
prompt= f'{user_prompt}<|image_1|>{question}{prompt_suffix}{assistant_prompt}'
image = Image.open(file)
inputs = processor(text=prompt, images=image, return_tensors='pt').to(model.device)
elif input_type == "Audio":
prompt= f'{user_prompt}<|audio_1|>{question}{prompt_suffix}{assistant_prompt}'
audio, samplerate = sf.read(file)
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to(model.device)
elif input_type == "Text":
prompt = f'{user_prompt}{question} "{file}"{prompt_suffix}{assistant_prompt}'
inputs = processor(text=prompt, return_tensors='pt').to(model.device)
else:
return "Invalid input type"
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
return clean_response(response, [question])The above function is responsible for handling text, image, and audio inputs and generating a response using the Phi-4-multimodal model. Here is a technical breakdown of this workflow:
"Image", the prompt is formatted with an image placeholder (<|image_1|>). The image is then loaded, and the processor tokenizes the accompanying text while extracting visual features. The processed inputs are transferred to the GPU for optimized computation."Audio", the prompt is structured with an audio placeholder (<|audio_1|>). The audio file is read using the sf.read() function, extracting the raw waveform and sample rate. The processor then encodes both the audio and text, ensuring seamless integration for multimodal understanding."Text", the text is directly embedded into the prompt. The processor tokenizes and encodes the input, preparing it for further processing by the model.Next, we process the text for translation and grammar correction using the Phi-4-multimodal model.
def process_text_translate(text, target_language):
prompt = f'Translate the following text to {target_language}: "{text}"'
return process_input(text, "Text", prompt)
def process_text_grammar(text):
prompt = f'Check the grammar and provide corrections if needed for the following text: "{text}"'
return process_input(text, "Text", prompt)The process_text_translate() function dynamically constructs a translation prompt by specifying the target language and passes the input text and structured prompt to the process_input() function, returning the translated text.
Similarly, process_text_grammar() function builds a grammar correction prompt, calls process_input() function with the input text and type, and returns a grammatically corrected version of the text. Both functions streamline language processing by using the model's capabilities for translation and grammar correction.
Now, we have all key logic functions in place. Next, we work on building interactive UI with Gradio.
def gradio_interface():
with gr.Blocks() as demo:
gr.Markdown("# Phi 4 Powered - Multimodal Language Tutor")
with gr.Tab("Text-Based Learning"):
text_input = gr.Textbox(label="Enter Text")
language_input = gr.Textbox(label="Target Language", value="French")
text_output = gr.Textbox(label="Response")
text_translate_btn = gr.Button("Translate")
text_grammar_btn = gr.Button("Check Grammar")
text_clear_btn = gr.Button("Clear")
text_translate_btn.click(process_text_translate, inputs=[text_input, language_input], outputs=text_output)
text_grammar_btn.click(process_text_grammar, inputs=[text_input], outputs=text_output)
text_clear_btn.click(lambda: ("", "", ""), outputs=[text_input, language_input, text_output])
with gr.Tab("Image-Based Learning"):
image_input = gr.Image(type="filepath", label="Upload Image")
language_input_image = gr.Textbox(label="Target Language for Translation", value="English")
image_output = gr.Textbox(label="Response")
image_clear_btn = gr.Button("Clear")
image_translate_btn = gr.Button("Translate Text in Image")
image_summarize_btn = gr.Button("Summarize Image")
image_translate_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Extract and translate text", visible=False)], outputs=image_output)
image_summarize_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Summarize this image", visible=False)], outputs=image_output)
image_clear_btn.click(lambda: (None, "", ""), outputs=[image_input, language_input_image, image_output])
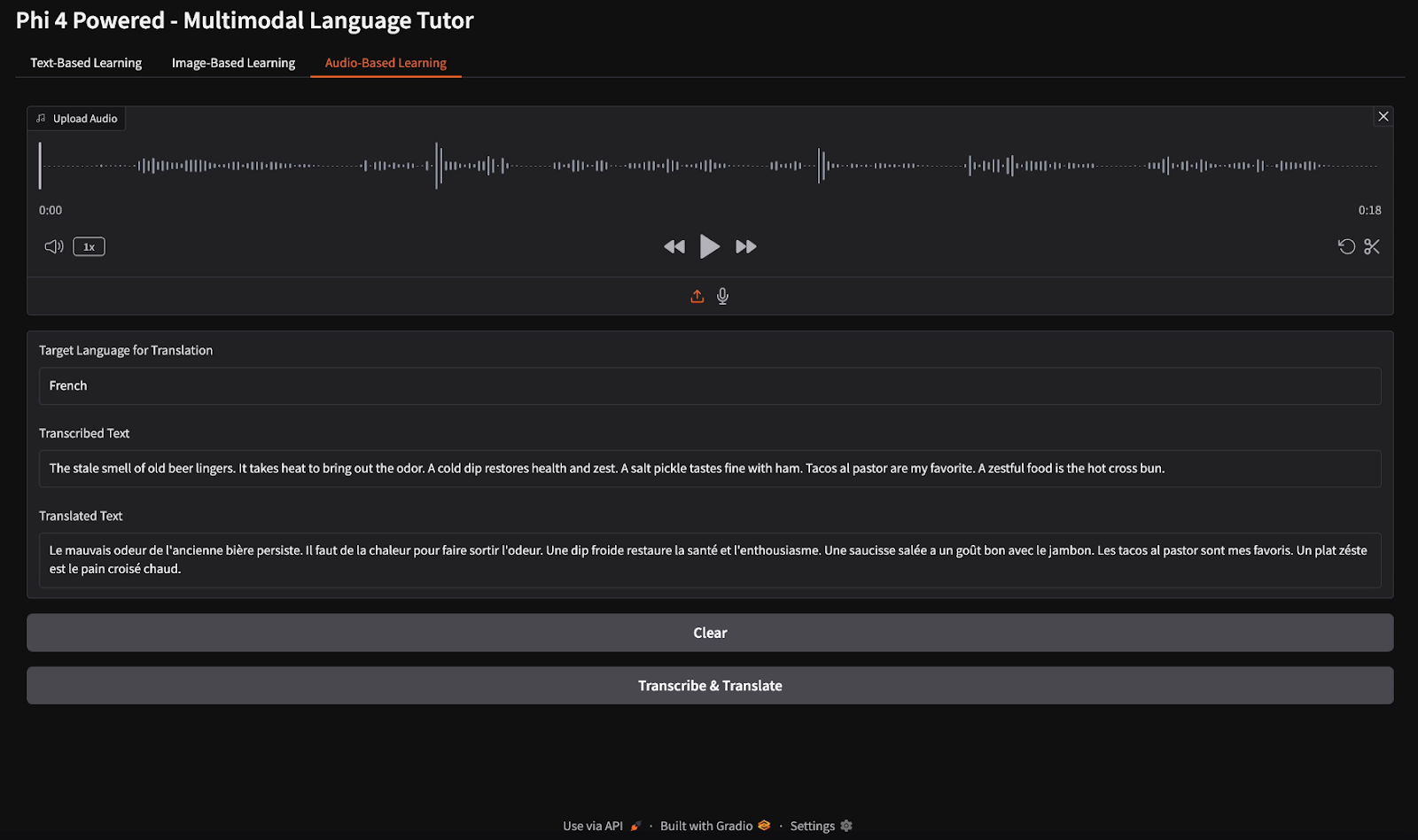
with gr.Tab("Audio-Based Learning"):
audio_input = gr.Audio(type="filepath", label="Upload Audio")
language_input_audio = gr.Textbox(label="Target Language for Translation", value="English")
transcript_output = gr.Textbox(label="Transcribed Text")
translated_output = gr.Textbox(label="Translated Text")
audio_clear_btn = gr.Button("Clear")
audio_transcribe_btn = gr.Button("Transcribe & Translate")
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), gr.Textbox(value="Transcribe this audio", visible=False)], outputs=transcript_output)
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), language_input_audio], outputs=translated_output)
audio_clear_btn.click(lambda: (None, "", "", ""), outputs=[audio_input, language_input_audio, transcript_output, translated_output])
demo.launch(debug=True)
if __name__ == "__main__":
gradio_interface()The above code organizes the Gradio interface into three interactive tabs, namely - text-based learning, image-based learning, and audio-based learning, each designed for different language learning functionalities.
Users can enter text for translation or grammar correction, upload images for text extraction and summarization, or provide audio for speech transcription and translation.
Each function is triggered using Gradio's click() method, which calls processing functions like process_text_translate(), process_text_grammar(), and process_input() as discussed above, by passing the required inputs and updating the outputs dynamically.
A Clear button is included for each tab to reset inputs and outputs, ensuring a smooth user experience. Finally, the interface is launched with demo.launch(debug=True) which allows developers to easily debug any error in the application.
Here are a few of my experiments with this application.
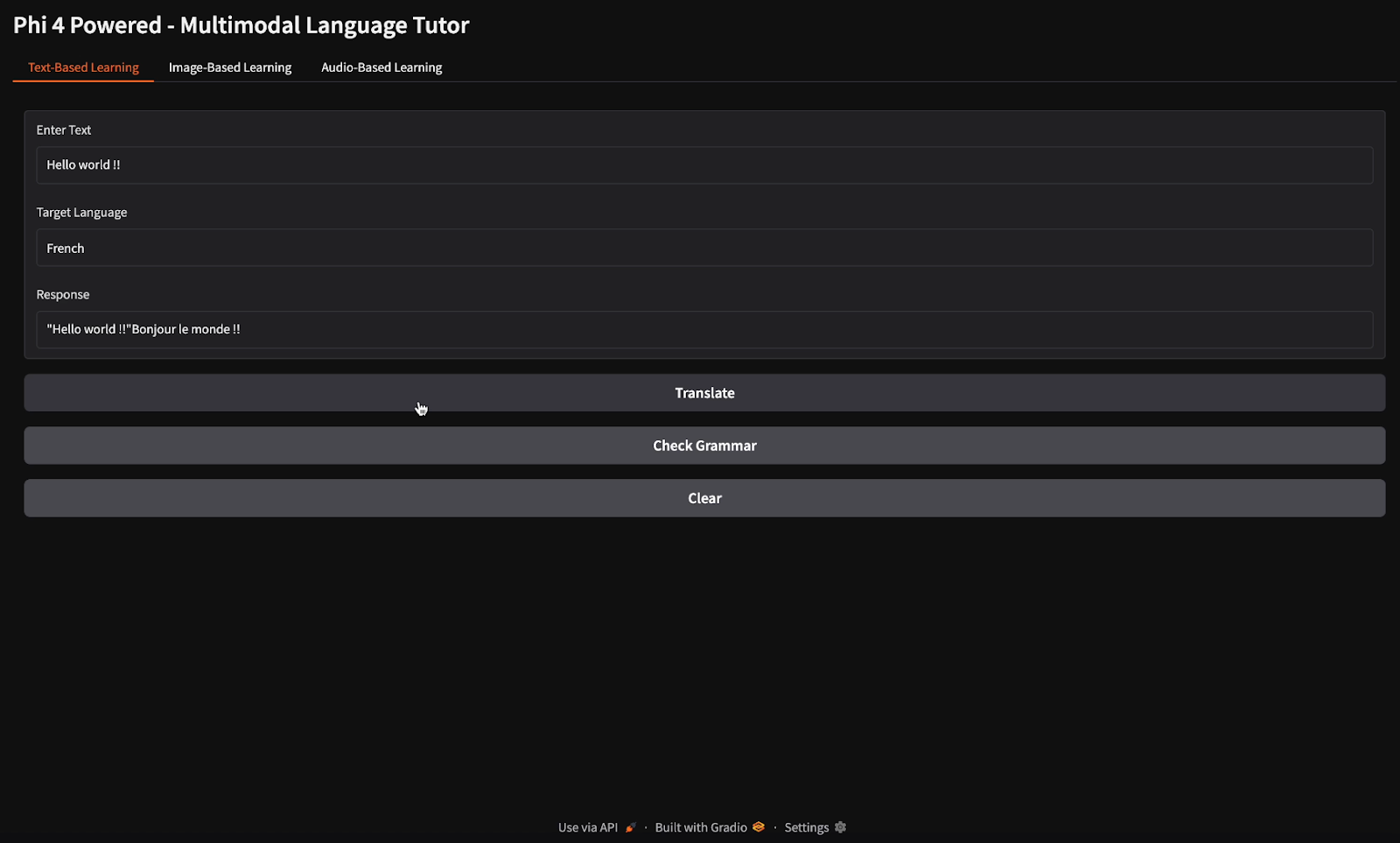
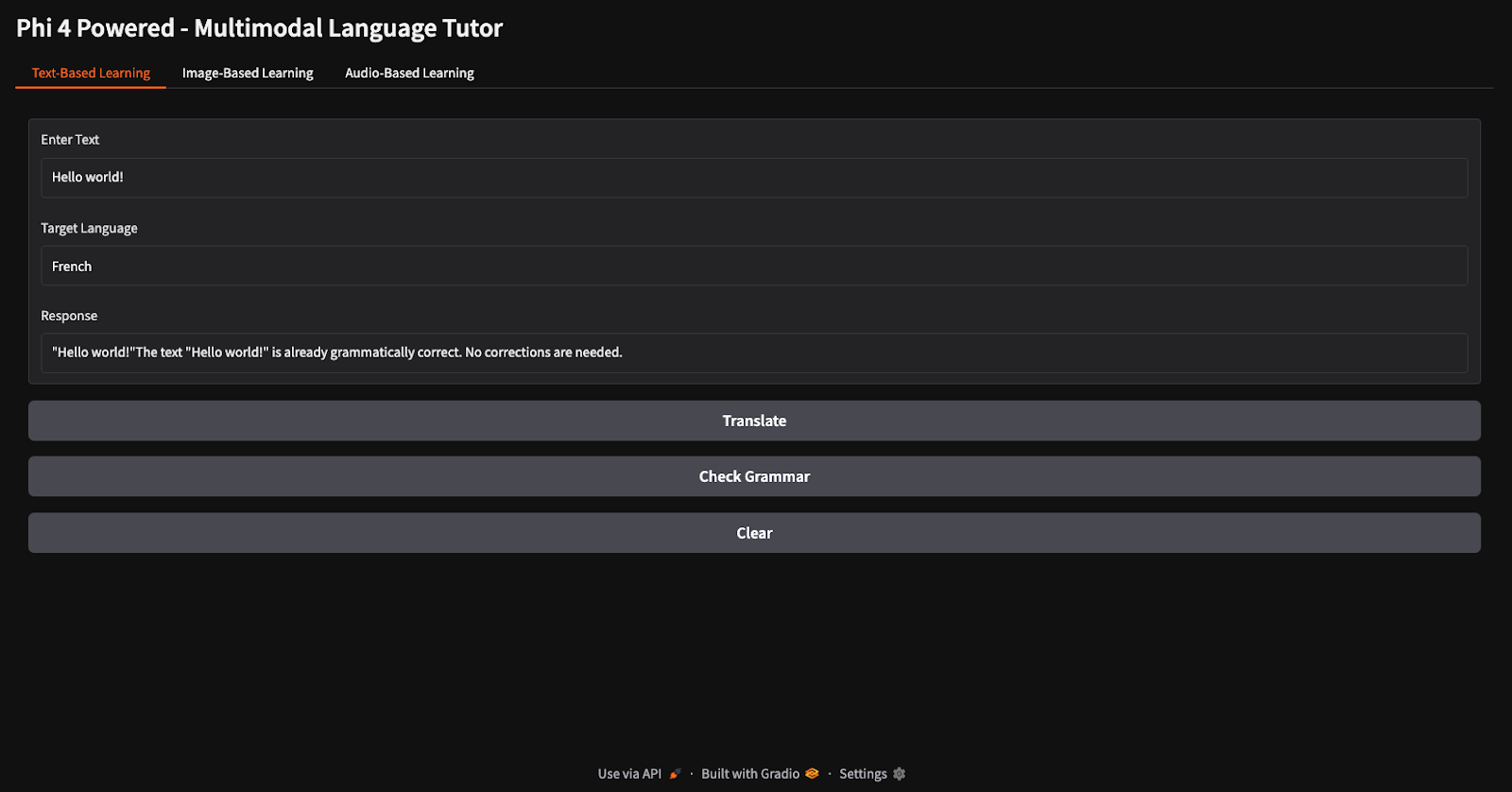
For the translation and grammar check tasks, I provided the text "Hello world" and instructed the model to translate it into French and verify its grammar (notice the different buttons for translation and grammar check).
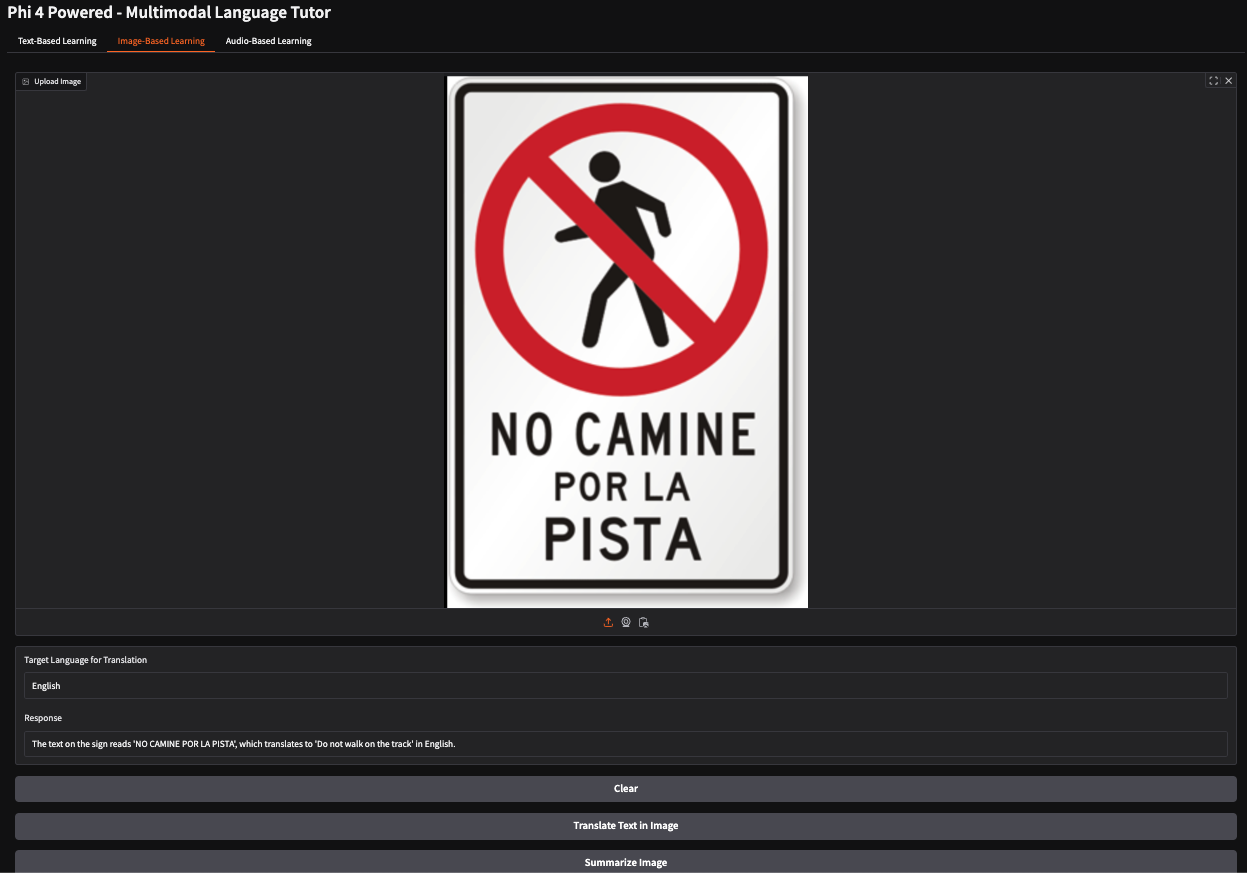
In this example, I provided an image of a Spanish stop sign instructing pedestrians not to walk on a specific path. The model accurately interpreted the sign's meaning and generated the response: "Do not walk on the track."
For audio transcription, I provided an English audio file and instructed the model to transcribe the speech and translate the transcription into French.
In this tutorial, we built a multimodal language tutor using the Phi-4 multimodal model, enabling text, image, and audio-based language learning. We used Phi-4’s advanced vision, speech, and text capabilities to provide real-time translations, grammar corrections, speech transcription, and image-based learning insights. This project demonstrates how multimodal AI can enhance language education and accessibility.
Learn AI with these courses!
Track
Track
Course
Tutorial
Aashi Dutt
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Dr Ana Rojo-Echeburúa
code-along
Korey Stegared-Pace

