
Cursus
Développer des applications d'IA
21 h
Phi-4-multimodal est un logiciel léger de type multimodal multimodal léger développé par Microsoft. Il fait partie de la famille Phi de Microsoft, composée de petits modèles de langage (SLM) de la famille Phi de Microsoft.
Dans ce tutoriel, j'expliquerai étape par étape comment utiliser Phi-4-multimodal pour construire un tuteur de langue multimodal qui peut travailler avec du texte, des images et de l'audio. Les principales caractéristiques de cette application sont les suivantes :
Commençons par une présentation très rapide du modèle Phi-4-multimodal, puis nous commencerons à construire l'application.
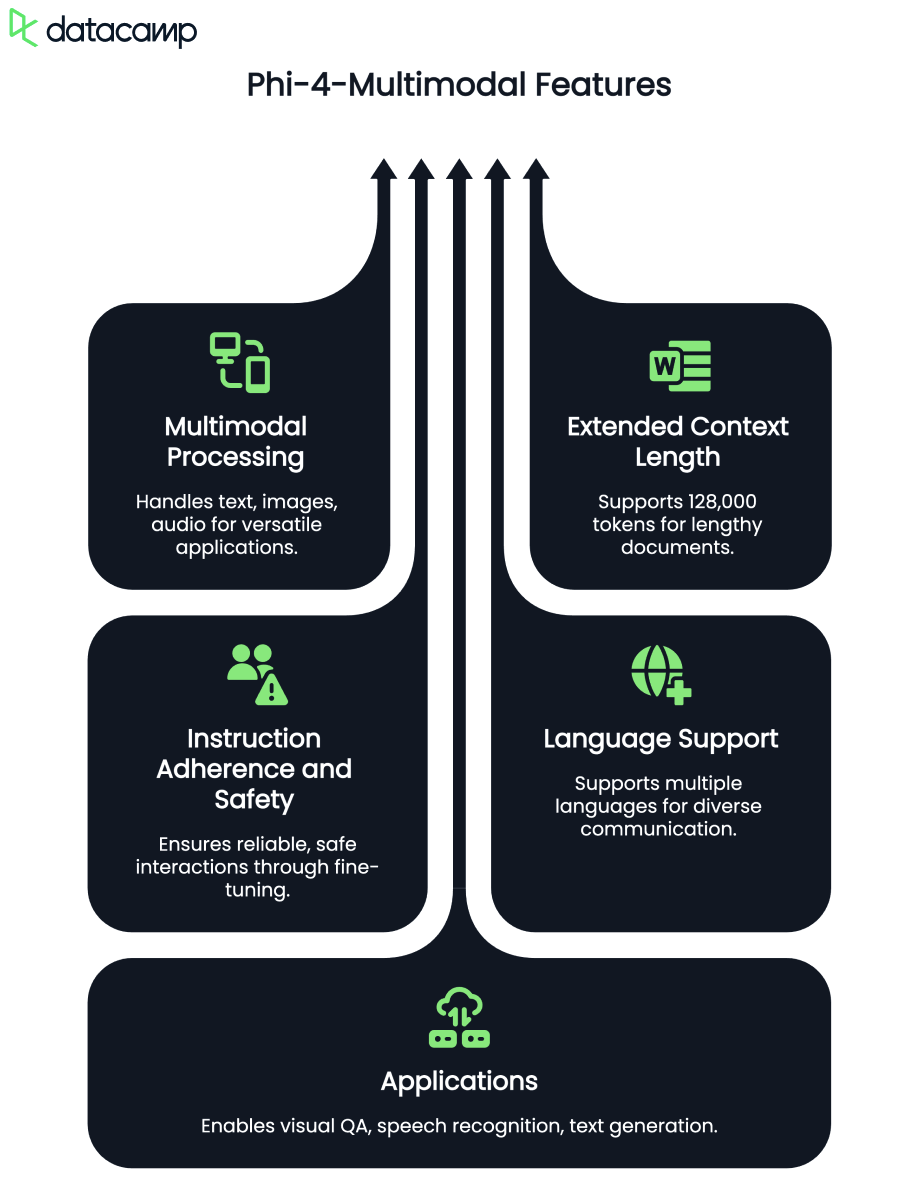
Phi-4-multimodal est un modèle d'IA avancé conçu pour le traitement du texte, de la vision et de la parole. Il permet une intégration transparente de plusieurs modalités, ce qui le rend idéal pour les applications d'apprentissage des langues. Voici quelques-unes de ses principales capacités :
Avec une longueur de contexte de 128 000 jetons, le modèle multimodal Phi-4 est optimisé pour un raisonnement efficace et des environnements à mémoire limitée, ce qui en fait un outil parfait pour l'apprentissage des langues en temps réel alimenté par l'IA.
L'application multimodale de tutorat linguistique que nous allons créer est un outil interactif alimenté par l'IA et conçu pour aider les utilisateurs à apprendre de nouvelles langues grâce à une combinaison d'interactions basées sur le texte, l'image et l'audio.
Avant de commencer, nous devons nous assurer que les outils et bibliothèques suivants sont installés :
Exécutez les commandes suivantes pour installer les dépendances nécessaires :
pip install gradio transformers torch soundfile pillowNous devons également nous assurer que FlashAttention2 est installé pour de meilleures performances :
pip install flash-attn --no-build-isolationNote : Ce projet utilise un GPU A100 sur un ordinateur portable Google Colab. Si vous utilisez un ancien GPU (par exemple, NVIDIA V100), vous devrez peut-être désactiver FlashAttention2 en définissant _attn_implementation="eager" dans l'étape d'initialisation du modèle.
Une fois les dépendances ci-dessus installées, exécutez les commandes d'importation suivantes :
import gradio as gr
import torch
import requests
import io
import os
import soundfile as sf
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfigPour tirer parti des capacités multimodales de Phi-4, nous chargeons d'abord le modèle et son processeur. La trajectoire du modèle est définie à partir de Hugging Facetandis que le processeur se charge de la tokenisation du texte, du redimensionnement et de la normalisation des images, et de la conversion des formes d'onde audio dans un format compatible avec le modèle pour un traitement multimodal transparent.
# Load model and processor
model_path = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2',
).cuda()
generation_config = GenerationConfig.from_pretrained(model_path)L'étape d'initialisation du modèle utilise le modèle 'AutoModelForCausalLM.from_pretrained() function to load the pretrained Phi-4 model for causal language modeling (CLM) and loads the model on GPU using device_map="cuda".
Un paramètre clé de cette étape est _attn_implementation='flash_attention_2'`, qui utilise FlashAttention2 pour un mécanisme d'attention plus rapide et plus efficace sur le plan de la mémoire, en particulier pour le traitement des contextes longs.
Maintenant que nous avons chargé le modèle, construisons les principales fonctionnalités.
Un aspect important de tout projet basé sur le LLM ou le VLM est de s'assurer que le modèle génère des réponses précises et pertinentes. Cela implique également de supprimer tout texte d'invite de la sortie, afin que les utilisateurs reçoivent une réponse propre et directe sans que l'instruction initiale n'apparaisse au début.
def clean_response(response, instruction_keywords):
"""Removes the prompt text dynamically based on instruction keywords."""
for keyword in instruction_keywords:
if response.lower().startswith(keyword.lower()):
response = response[len(keyword):].strip()
return responseNous utilisons simplement la fonction strip() pour dépouiller le texte de l'invite en fonction des mots-clés de l'instruction.
Traitons maintenant nos entrées, qui peuvent être du texte, des images ou du son, en fonction de l'entrée de l'utilisateur ou du scénario.
def process_input(file, input_type, question):
user_prompt = "<|user|>"
assistant_prompt = "<|assistant|>"
prompt_suffix = "<|end|>"
if input_type == "Image":
prompt= f'{user_prompt}<|image_1|>{question}{prompt_suffix}{assistant_prompt}'
image = Image.open(file)
inputs = processor(text=prompt, images=image, return_tensors='pt').to(model.device)
elif input_type == "Audio":
prompt= f'{user_prompt}<|audio_1|>{question}{prompt_suffix}{assistant_prompt}'
audio, samplerate = sf.read(file)
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to(model.device)
elif input_type == "Text":
prompt = f'{user_prompt}{question} "{file}"{prompt_suffix}{assistant_prompt}'
inputs = processor(text=prompt, return_tensors='pt').to(model.device)
else:
return "Invalid input type"
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
return clean_response(response, [question])La fonction ci-dessus est chargée de traiter les entrées texte, image et audio et de générer une réponse à l'aide du modèle multimodal Phi-4. Voici une description technique de ce flux de travail :
"Image", l'invite est formatée avec un espace réservé à l'image (<|image_1|>). L'image est ensuite chargée, et le processeur identifie le texte qui l'accompagne tout en extrayant les caractéristiques visuelles. Les données traitées sont transférées au GPU pour un calcul optimisé."Audio", l'invite est structurée par un caractère générique audio (<|audio_1|>). Le fichier audio est lu à l'aide de la fonction sf.read(), qui extrait la forme d'onde brute et la fréquence d'échantillonnage. Le processeur encode ensuite le son et le texte, assurant ainsi une intégration transparente pour une compréhension multimodale."Text", le texte est directement intégré dans l'invite. Le processeur symbolise et encode l'entrée, la préparant ainsi à un traitement ultérieur par le modèle.Ensuite, nous traitons le texte pour la traduction et la correction grammaticale à l'aide du modèle Phi-4-multimodal.
def process_text_translate(text, target_language):
prompt = f'Translate the following text to {target_language}: "{text}"'
return process_input(text, "Text", prompt)
def process_text_grammar(text):
prompt = f'Check the grammar and provide corrections if needed for the following text: "{text}"'
return process_input(text, "Text", prompt)La fonction process_text_translate() construit dynamiquement une invite de traduction en spécifiant la langue cible et transmet le texte d'entrée et l'invite structurée à la fonction process_input(), qui renvoie le texte traduit.
De même, la fonction process_text_grammar() crée une invite de correction grammaticale, appelle la fonction process_input() avec le texte d'entrée et le type, et renvoie une version grammaticalement corrigée du texte. Ces deux fonctions rationalisent le traitement linguistique en utilisant les capacités du modèle pour la traduction et la correction grammaticale.
Toutes les fonctions logiques clés sont désormais en place. Ensuite, nous travaillerons sur la construction d'une interface utilisateur interactive avec Gradio.
def gradio_interface():
with gr.Blocks() as demo:
gr.Markdown("# Phi 4 Powered - Multimodal Language Tutor")
with gr.Tab("Text-Based Learning"):
text_input = gr.Textbox(label="Enter Text")
language_input = gr.Textbox(label="Target Language", value="French")
text_output = gr.Textbox(label="Response")
text_translate_btn = gr.Button("Translate")
text_grammar_btn = gr.Button("Check Grammar")
text_clear_btn = gr.Button("Clear")
text_translate_btn.click(process_text_translate, inputs=[text_input, language_input], outputs=text_output)
text_grammar_btn.click(process_text_grammar, inputs=[text_input], outputs=text_output)
text_clear_btn.click(lambda: ("", "", ""), outputs=[text_input, language_input, text_output])
with gr.Tab("Image-Based Learning"):
image_input = gr.Image(type="filepath", label="Upload Image")
language_input_image = gr.Textbox(label="Target Language for Translation", value="English")
image_output = gr.Textbox(label="Response")
image_clear_btn = gr.Button("Clear")
image_translate_btn = gr.Button("Translate Text in Image")
image_summarize_btn = gr.Button("Summarize Image")
image_translate_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Extract and translate text", visible=False)], outputs=image_output)
image_summarize_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Summarize this image", visible=False)], outputs=image_output)
image_clear_btn.click(lambda: (None, "", ""), outputs=[image_input, language_input_image, image_output])
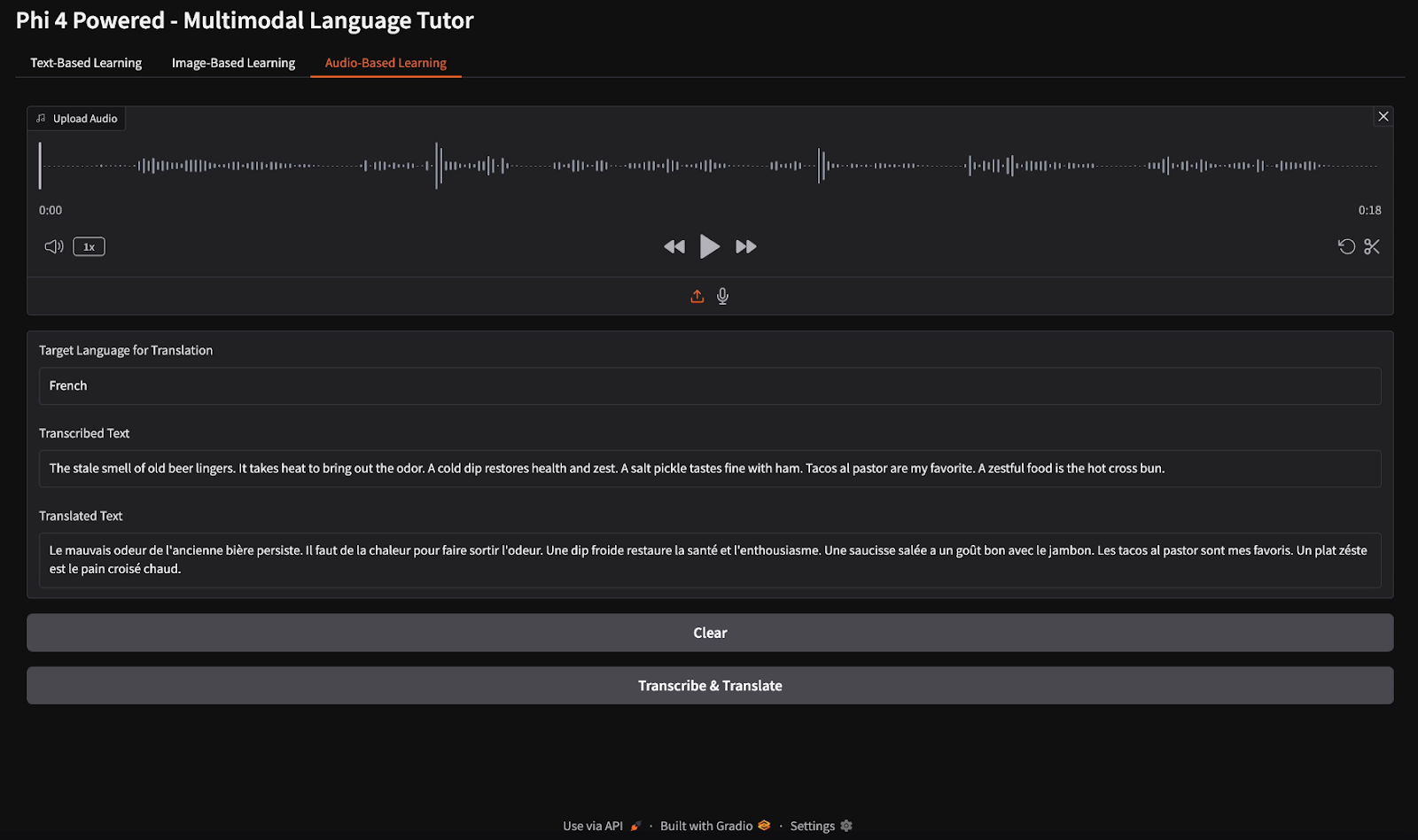
with gr.Tab("Audio-Based Learning"):
audio_input = gr.Audio(type="filepath", label="Upload Audio")
language_input_audio = gr.Textbox(label="Target Language for Translation", value="English")
transcript_output = gr.Textbox(label="Transcribed Text")
translated_output = gr.Textbox(label="Translated Text")
audio_clear_btn = gr.Button("Clear")
audio_transcribe_btn = gr.Button("Transcribe & Translate")
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), gr.Textbox(value="Transcribe this audio", visible=False)], outputs=transcript_output)
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), language_input_audio], outputs=translated_output)
audio_clear_btn.click(lambda: (None, "", "", ""), outputs=[audio_input, language_input_audio, transcript_output, translated_output])
demo.launch(debug=True)
if __name__ == "__main__":
gradio_interface()Le code ci-dessus organise l'interface de Gradio en trois onglets interactifs, à savoir l'apprentissage par le texte, l'apprentissage par l'image et l'apprentissage par l'audio, chacun étant conçu pour des fonctionnalités d'apprentissage linguistique différentes.
Les utilisateurs peuvent saisir du texte pour traduction ou correction grammaticale, télécharger des images pour extraction et résumé de texte, ou fournir des données audio pour transcription et traduction vocales.
Chaque fonction est déclenchée à l'aide de la méthode click() de Gradio, qui appelle des fonctions de traitement telles que process_text_translate(), process_text_grammar() et process_input(), comme indiqué ci-dessus, en transmettant les entrées requises et en mettant à jour les sorties de manière dynamique.
Un boutonClear est inclus pour chaque onglet afin de réinitialiser les entrées et les sorties, garantissant ainsi une expérience utilisateur fluide. Enfin, l'interface est lancée avec demo.launch(debug=True), ce qui permet aux développeurs de déboguer facilement toute erreur dans l'application.
Voici quelques-unes de mes expériences avec cette application.
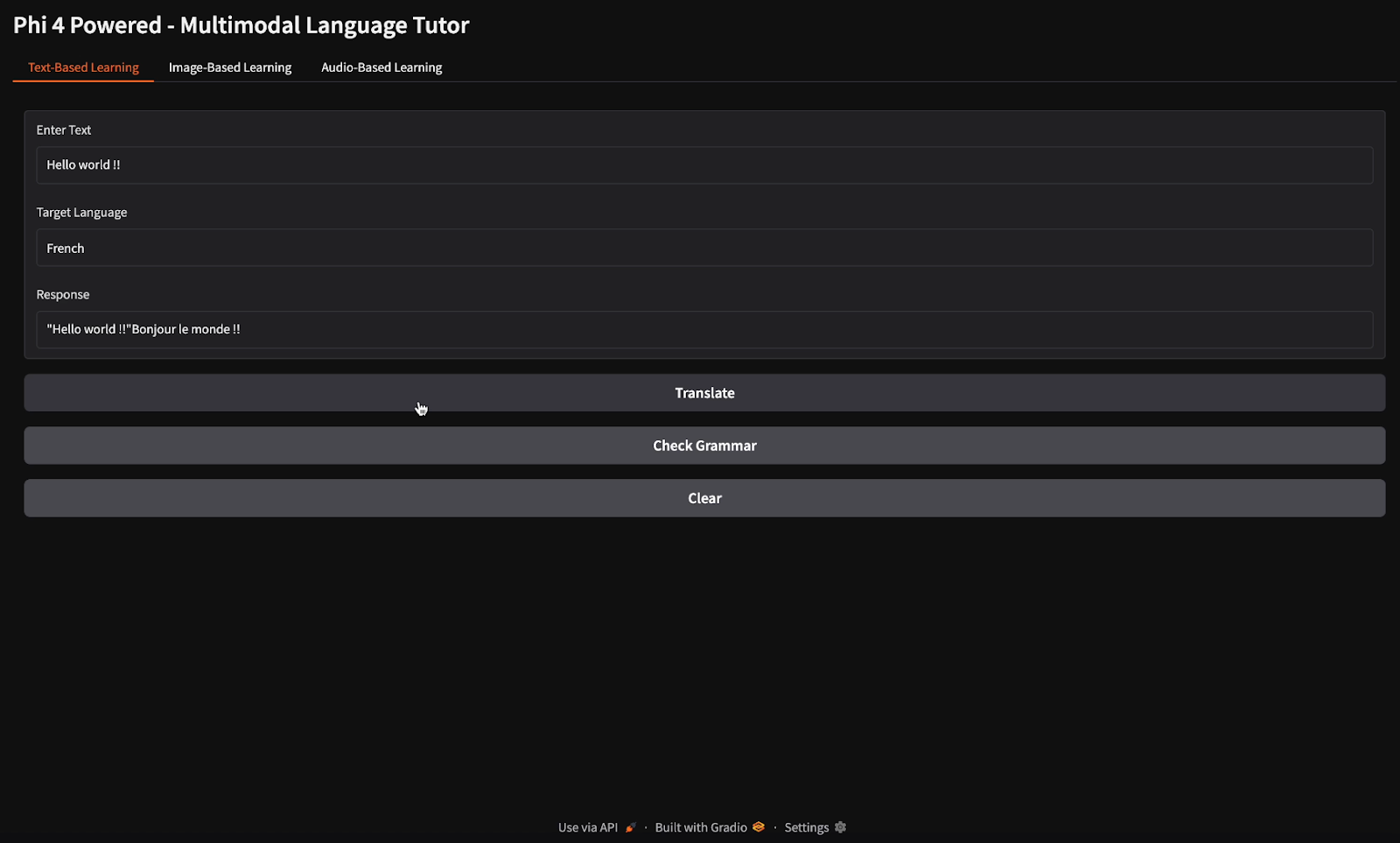
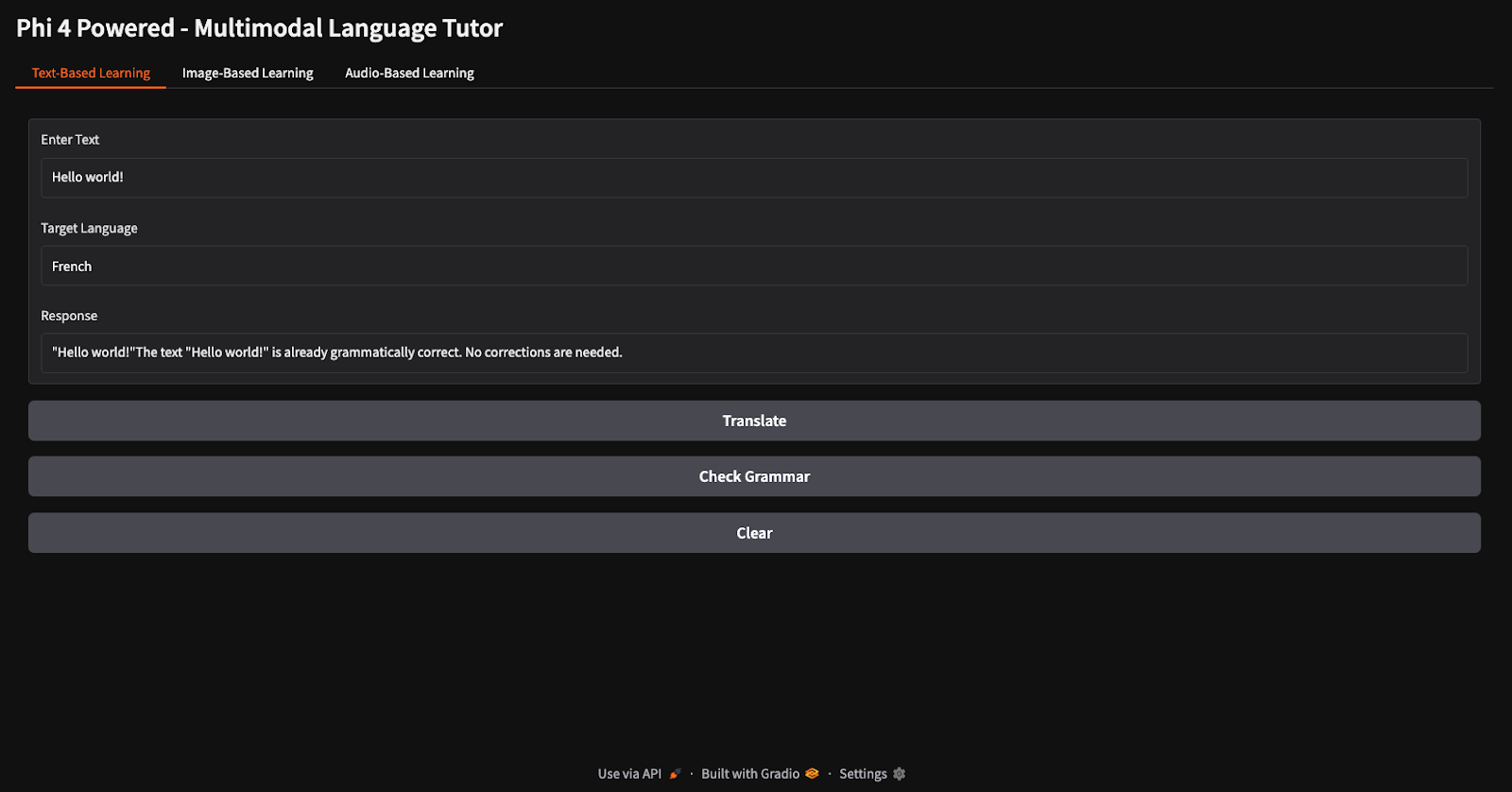
Pour les tâches de traduction et de vérification grammaticale, j'ai fourni le texte "Hello world" et j'ai demandé au modèle de le traduire en français et de vérifier sa grammaire (remarquez les différents boutons pour la traduction et la vérification grammaticale).
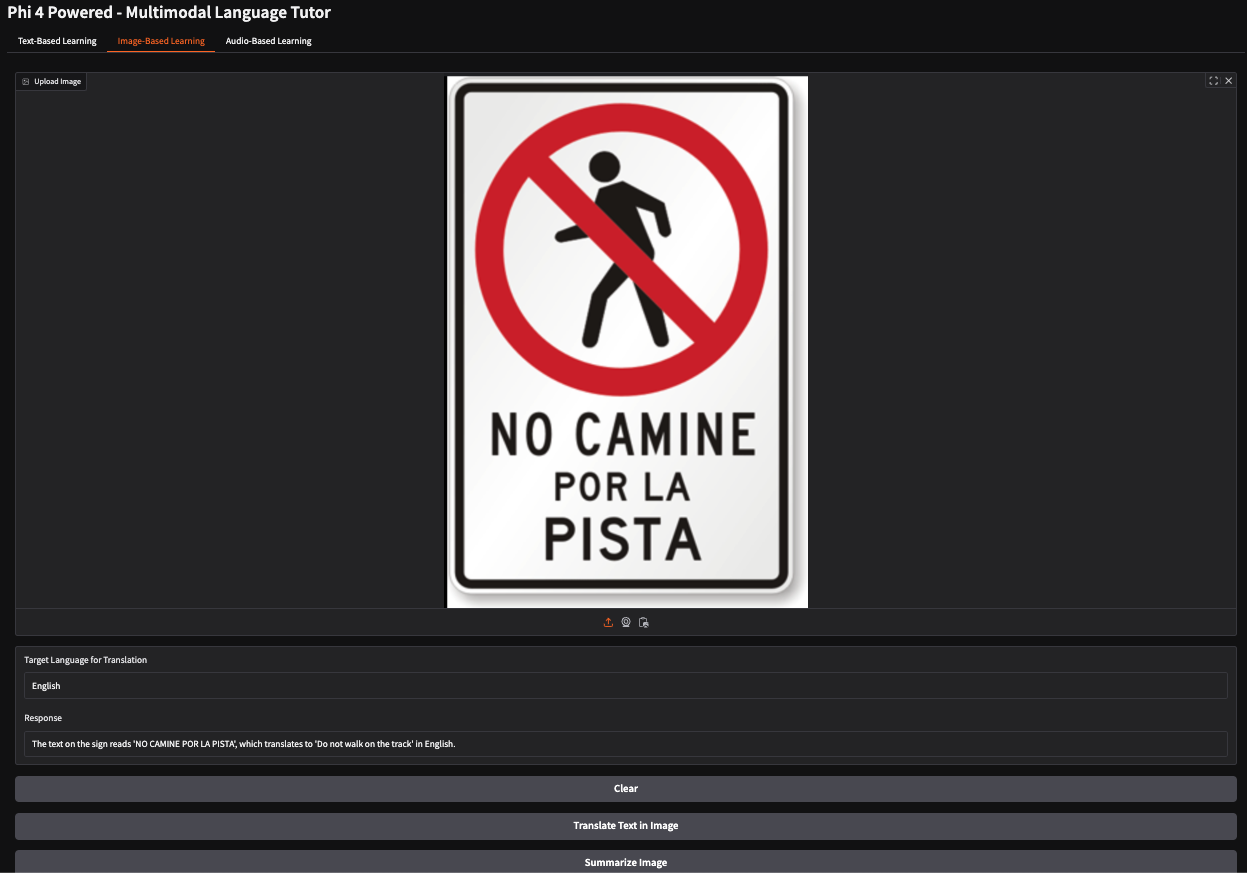
Dans cet exemple, j'ai fourni l'image d'un panneau d'arrêt espagnol indiquant aux piétons de ne pas emprunter un chemin spécifique. Le modèle a interprété avec précision la signification du panneau et a généré la réponse : "Ne marchez pas sur le cursus".
Pour la transcription audio, j'ai fourni un fichier audio en anglais et j'ai demandé au modèle de transcrire le discours et de traduire la transcription en français.
Dans ce tutoriel, nous avons construit un tuteur linguistique multimodal en utilisant le modèle multimodal Phi-4, permettant un apprentissage linguistique basé sur le texte, l'image et l'audio. Nous avons utilisé les capacités avancées de Phi-4 en matière de vision, de parole et de texte pour fournir des traductions en temps réel, des corrections grammaticales, des transcriptions vocales et des connaissances basées sur l'image. Ce projet démontre comment l'IA multimodale peut améliorer l'enseignement des langues et l'accessibilité.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach