
Programa
Desenvolvimento de aplicativos de IA
21 h
O Phi-4-multimodal é um sistema leve e multimodal multimodal leve desenvolvido pela Microsoft. Ele faz parte da família Phi da Microsoft de modelos de linguagem pequenos (SLMs).
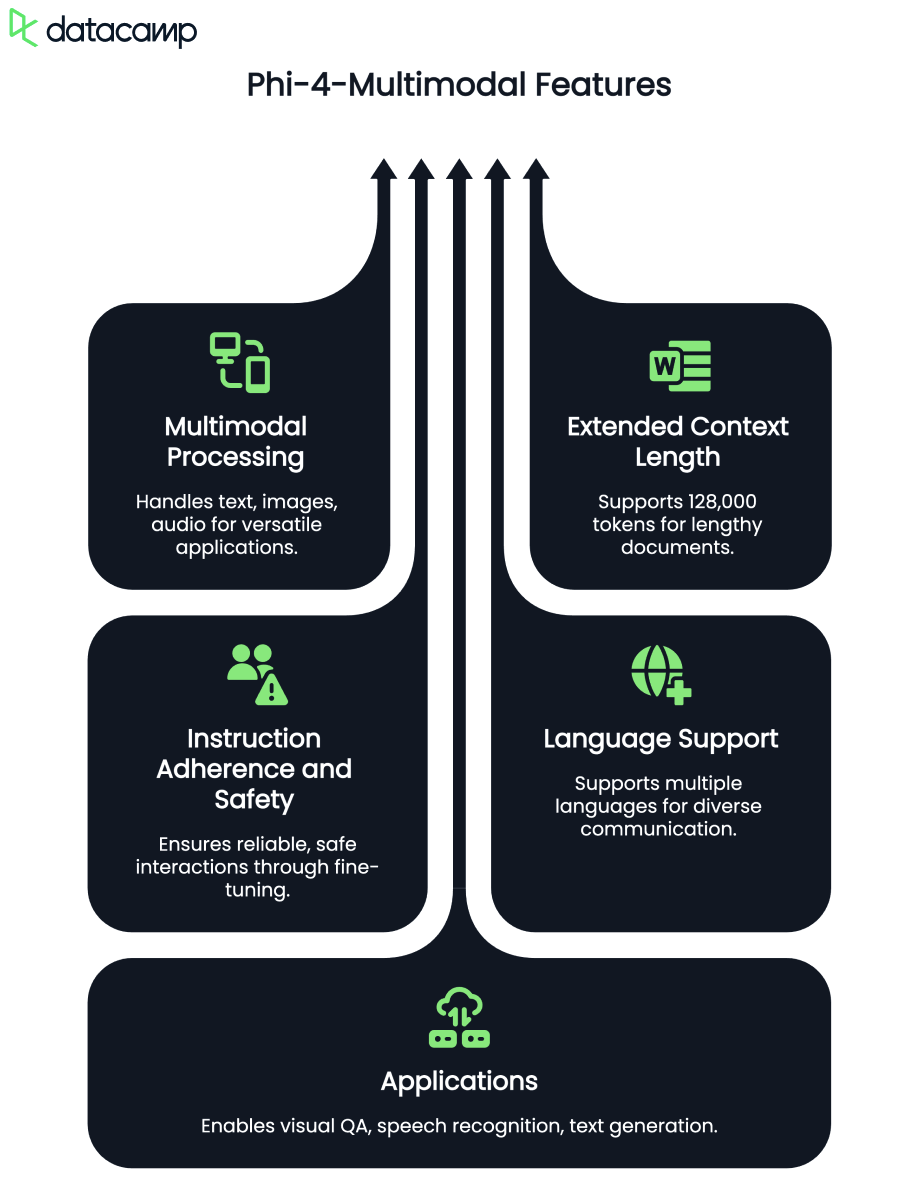
Neste tutorial, explicarei passo a passo como usar o Phi-4-multimodal para criar um tutor de idiomas multimodal que possa trabalhar com texto, imagens e áudio. Os principais recursos desse aplicativo são:
Vamos primeiro fazer uma apresentação muito rápida do modelo multimodal Phi-4 e, em seguida, começaremos a criar o aplicativo.
O Phi-4-multimodal é um modelo avançado de IA projetado para processamento de texto, visão e fala. Ele permite a integração perfeita de várias modalidades, o que o torna ideal para aplicativos de aprendizado de idiomas. Alguns de seus principais recursos incluem:
Com um comprimento de contexto de token de 128K, o modelo multimodal Phi-4 é otimizado para raciocínio eficiente e ambientes com restrições de memória, o que o torna perfeito para o aprendizado de idiomas em tempo real com base em IA.
O aplicativo tutor de idiomas multimodal que vamos criar é uma ferramenta interativa com tecnologia de IA projetada para ajudar os usuários a aprender novos idiomas por meio de uma combinação de interações baseadas em texto, imagem e áudio.
Antes de começarmos, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
pip install gradio transformers torch soundfile pillowTambém precisamos garantir que o FlashAttention2 esteja instalado para melhorar o desempenho:
pip install flash-attn --no-build-isolationObservação: Este projeto usa uma GPU A100 em um notebook do Google Colab. Se você usar uma GPU mais antiga (por exemplo, NVIDIA V100), talvez seja necessário desativar o FlashAttention2 definindo _attn_implementation="eager" na etapa de inicialização do modelo.
Quando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
import gradio as gr
import torch
import requests
import io
import os
import soundfile as sf
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfigPara aproveitar os recursos multimodais do Phi-4, primeiro carregamos o modelo e seu processador. O caminho do modelo é definido a partir de Hugging Faceenquanto o processador lida com o texto de tokenização, redimensionamento e normalização de imagens e conversão de formas de onda de áudio em um formato compatível com o modelo para processamento multimodal contínuo.
# Load model and processor
model_path = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2',
).cuda()
generation_config = GenerationConfig.from_pretrained(model_path)A etapa de inicialização do modelo usa o 'AutoModelForCausalLM.from_pretrained() function to load the pretrained Phi-4 model for causal language modeling (CLM) and loads the model on GPU using device_map="cuda".
Um parâmetro importante nessa etapa é _attn_implementation='flash_attention_2'`, que usa o FlashAttention2 para um mecanismo de atenção mais rápido e mais eficiente em termos de memória, especialmente para o processamento de contextos longos.
Agora que carregamos o modelo, vamos criar as principais funcionalidades.
Um aspecto importante de qualquer projeto baseado em LLM ou VLM é garantir que o modelo gere respostas precisas e relevantes. Isso também envolve a remoção de qualquer texto de prompt da saída, garantindo que os usuários recebam uma resposta limpa e direta sem que a instrução inicial apareça no início.
def clean_response(response, instruction_keywords):
"""Removes the prompt text dynamically based on instruction keywords."""
for keyword in instruction_keywords:
if response.lower().startswith(keyword.lower()):
response = response[len(keyword):].strip()
return responseBasta usar a função strip() para remover o texto do prompt com base nas palavras-chave de instrução.
Agora, vamos processar nossas entradas, que podem ser texto, imagem ou áudio, dependendo da entrada do usuário ou do cenário.
def process_input(file, input_type, question):
user_prompt = "<|user|>"
assistant_prompt = "<|assistant|>"
prompt_suffix = "<|end|>"
if input_type == "Image":
prompt= f'{user_prompt}<|image_1|>{question}{prompt_suffix}{assistant_prompt}'
image = Image.open(file)
inputs = processor(text=prompt, images=image, return_tensors='pt').to(model.device)
elif input_type == "Audio":
prompt= f'{user_prompt}<|audio_1|>{question}{prompt_suffix}{assistant_prompt}'
audio, samplerate = sf.read(file)
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to(model.device)
elif input_type == "Text":
prompt = f'{user_prompt}{question} "{file}"{prompt_suffix}{assistant_prompt}'
inputs = processor(text=prompt, return_tensors='pt').to(model.device)
else:
return "Invalid input type"
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
return clean_response(response, [question])A função acima é responsável por lidar com entradas de texto, imagem e áudio e gerar uma resposta usando o modelo multimodal Phi-4. Aqui está um detalhamento técnico desse fluxo de trabalho:
"Image", o prompt será formatado com um espaço reservado para imagem (<|image_1|>). Em seguida, a imagem é carregada, e o processador tokeniza o texto que a acompanha enquanto extrai recursos visuais. As entradas processadas são transferidas para a GPU para que a computação seja otimizada."Audio", o prompt será estruturado com um espaço reservado para áudio (<|audio_1|>). O arquivo de áudio é lido usando a função sf.read(), extraindo a forma de onda bruta e a taxa de amostragem. Em seguida, o processador codifica o áudio e o texto, garantindo uma integração perfeita para a compreensão multimodal."Text", o texto será incorporado diretamente ao prompt. O processador tokeniza e codifica a entrada, preparando-a para processamento adicional pelo modelo.Em seguida, processamos o texto para tradução e correção gramatical usando o modelo multimodal Phi-4.
def process_text_translate(text, target_language):
prompt = f'Translate the following text to {target_language}: "{text}"'
return process_input(text, "Text", prompt)
def process_text_grammar(text):
prompt = f'Check the grammar and provide corrections if needed for the following text: "{text}"'
return process_input(text, "Text", prompt)A função process_text_translate() constrói dinamicamente um prompt de tradução especificando o idioma de destino e passa o texto de entrada e o prompt estruturado para a função process_input(), retornando o texto traduzido.
Da mesma forma, a função process_text_grammar() cria um prompt de correção gramatical, chama a função process_input() com o texto e o tipo de entrada e retorna uma versão gramaticalmente corrigida do texto. Ambas as funções otimizam o processamento de idiomas usando os recursos do modelo para tradução e correção gramatical.
Agora, temos todas as principais funções lógicas implementadas. Em seguida, trabalharemos na criação de uma interface de usuário interativa com o Gradio.
def gradio_interface():
with gr.Blocks() as demo:
gr.Markdown("# Phi 4 Powered - Multimodal Language Tutor")
with gr.Tab("Text-Based Learning"):
text_input = gr.Textbox(label="Enter Text")
language_input = gr.Textbox(label="Target Language", value="French")
text_output = gr.Textbox(label="Response")
text_translate_btn = gr.Button("Translate")
text_grammar_btn = gr.Button("Check Grammar")
text_clear_btn = gr.Button("Clear")
text_translate_btn.click(process_text_translate, inputs=[text_input, language_input], outputs=text_output)
text_grammar_btn.click(process_text_grammar, inputs=[text_input], outputs=text_output)
text_clear_btn.click(lambda: ("", "", ""), outputs=[text_input, language_input, text_output])
with gr.Tab("Image-Based Learning"):
image_input = gr.Image(type="filepath", label="Upload Image")
language_input_image = gr.Textbox(label="Target Language for Translation", value="English")
image_output = gr.Textbox(label="Response")
image_clear_btn = gr.Button("Clear")
image_translate_btn = gr.Button("Translate Text in Image")
image_summarize_btn = gr.Button("Summarize Image")
image_translate_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Extract and translate text", visible=False)], outputs=image_output)
image_summarize_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Summarize this image", visible=False)], outputs=image_output)
image_clear_btn.click(lambda: (None, "", ""), outputs=[image_input, language_input_image, image_output])
with gr.Tab("Audio-Based Learning"):
audio_input = gr.Audio(type="filepath", label="Upload Audio")
language_input_audio = gr.Textbox(label="Target Language for Translation", value="English")
transcript_output = gr.Textbox(label="Transcribed Text")
translated_output = gr.Textbox(label="Translated Text")
audio_clear_btn = gr.Button("Clear")
audio_transcribe_btn = gr.Button("Transcribe & Translate")
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), gr.Textbox(value="Transcribe this audio", visible=False)], outputs=transcript_output)
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), language_input_audio], outputs=translated_output)
audio_clear_btn.click(lambda: (None, "", "", ""), outputs=[audio_input, language_input_audio, transcript_output, translated_output])
demo.launch(debug=True)
if __name__ == "__main__":
gradio_interface()O código acima organiza a interface do Gradio em três guias interativas, a saber: aprendizagem baseada em texto, aprendizagem baseada em imagem e aprendizagem baseada em áudio, cada uma projetada para diferentes funcionalidades de aprendizagem de idiomas.
Os usuários podem inserir texto para tradução ou correção gramatical, carregar imagens para extração e resumo de texto ou fornecer áudio para transcrição e tradução de fala.
Cada função é acionada usando o método click() do Gradio, que chama funções de processamento como process_text_translate(), process_text_grammar() e process_input(), conforme discutido acima, passando as entradas necessárias e atualizando as saídas dinamicamente.
Um botãoClear está incluído em cada guia para redefinir entradas e saídas, garantindo uma experiência de usuário tranquila. Por fim, a interface é iniciada com demo.launch(debug=True), o que permite que os desenvolvedores depurem facilmente qualquer erro no aplicativo.
Aqui estão alguns dos meus experimentos com esse aplicativo.
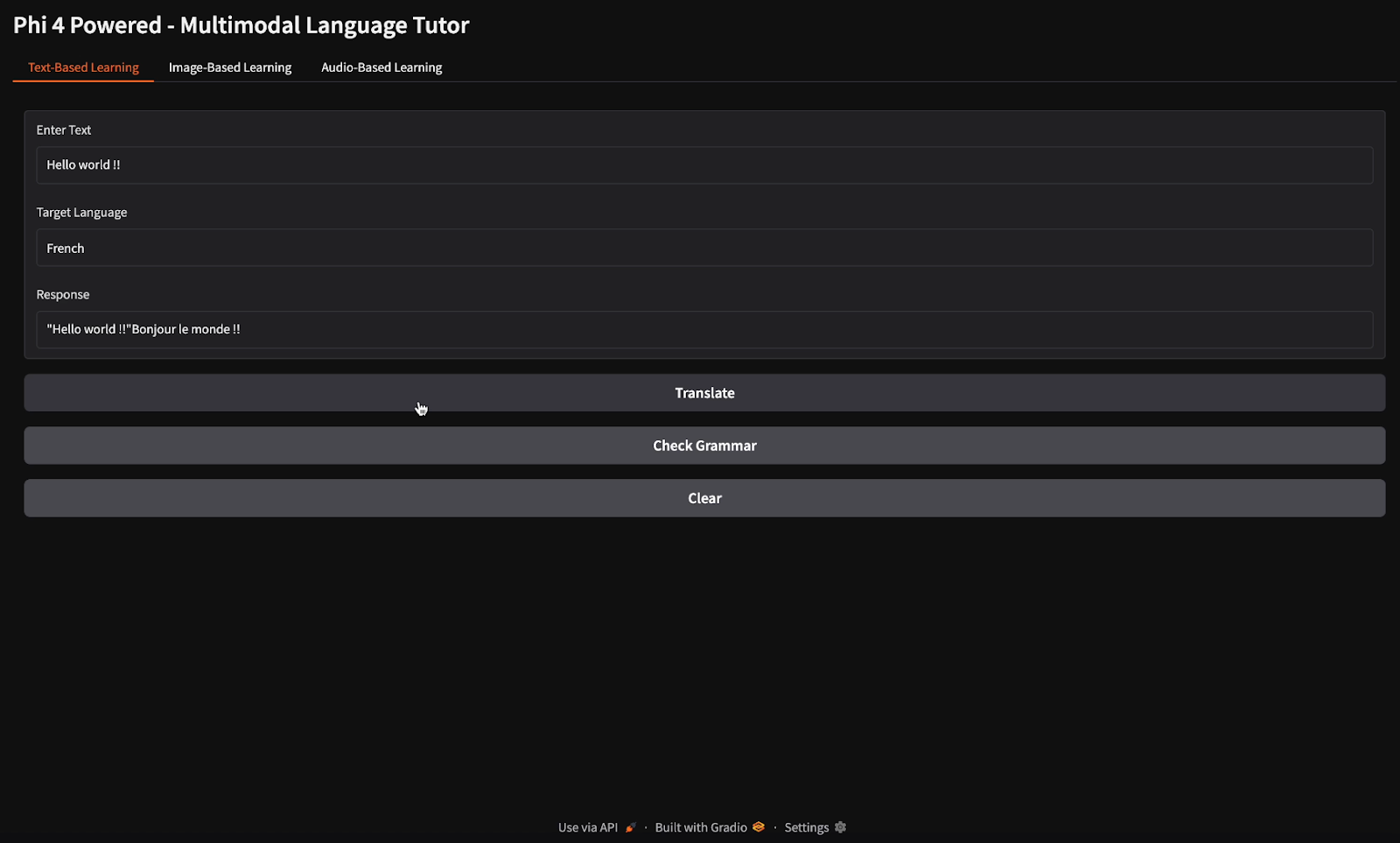
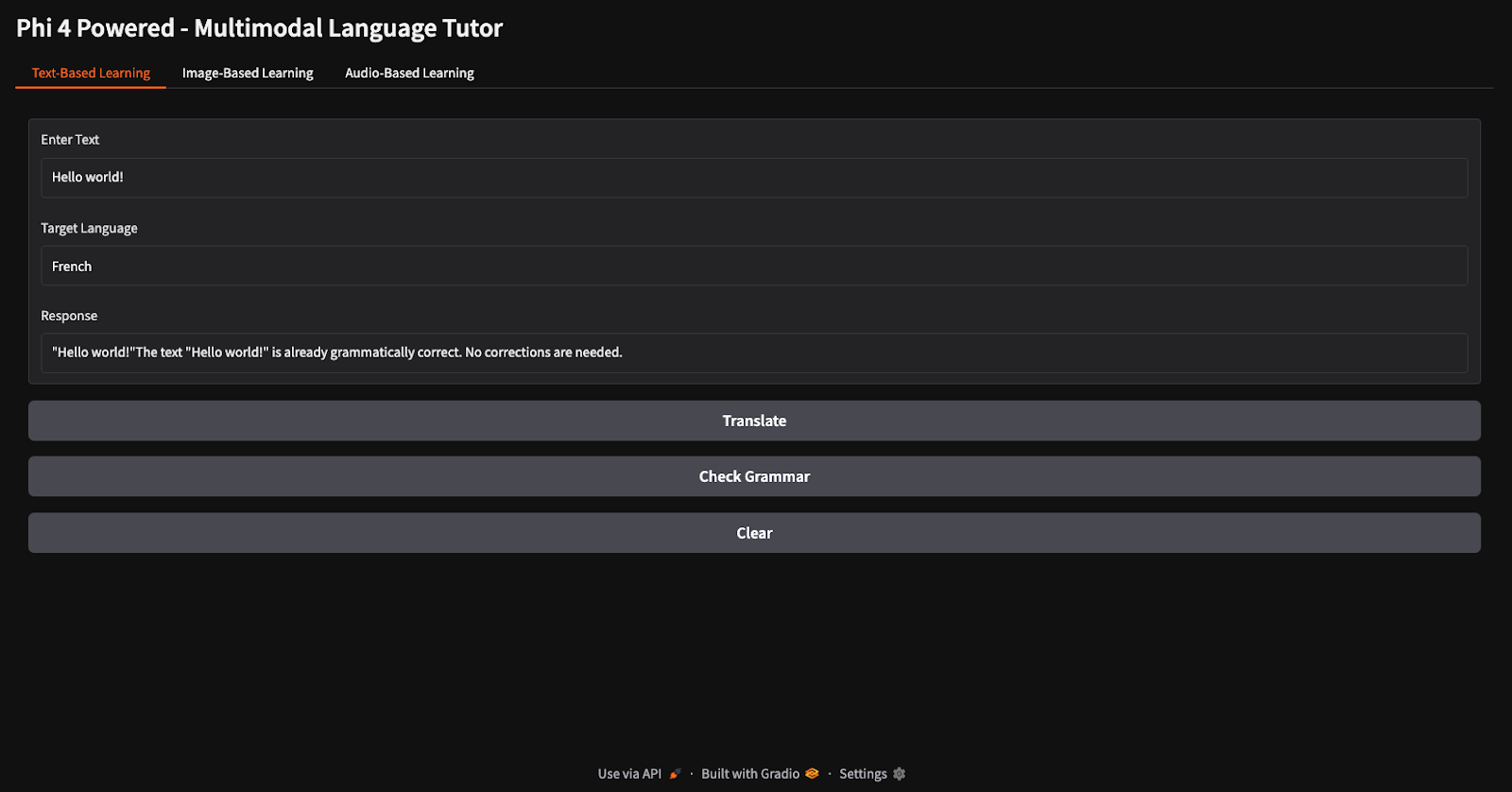
Para as tarefas de tradução e verificação gramatical, forneci o texto "Hello world" e instruí o modelo a traduzi-lo para o francês e verificar sua gramática (observe os diferentes botões para tradução e verificação gramatical).
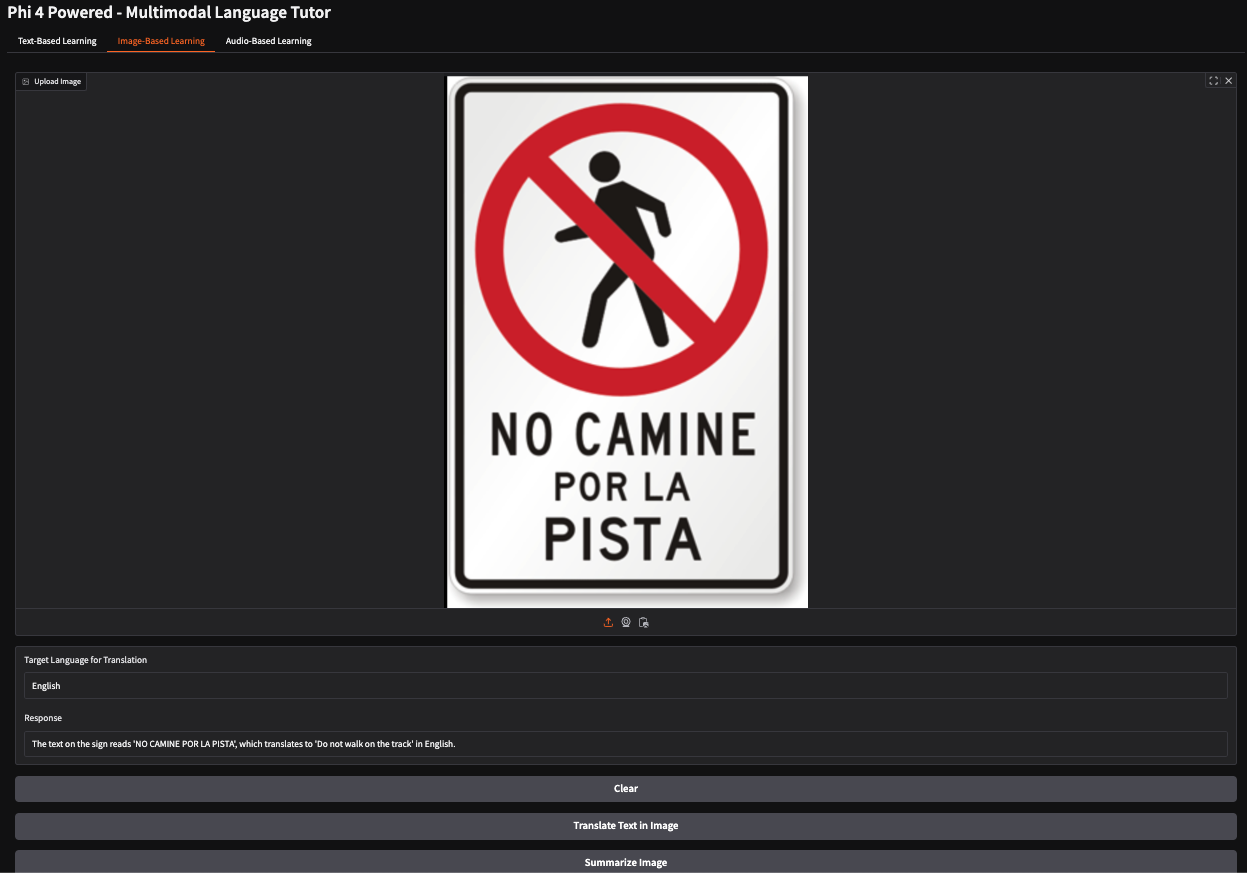
Neste exemplo, forneci uma imagem de uma placa de pare em espanhol instruindo os pedestres a não andar em um caminho específico. O modelo interpretou com precisão o significado do sinal e gerou a resposta: "Você não deve andar sobre o programa."
Para a transcrição de áudio, forneci um arquivo de áudio em inglês e instruí o modelo a transcrever a fala e traduzir a transcrição para o francês.
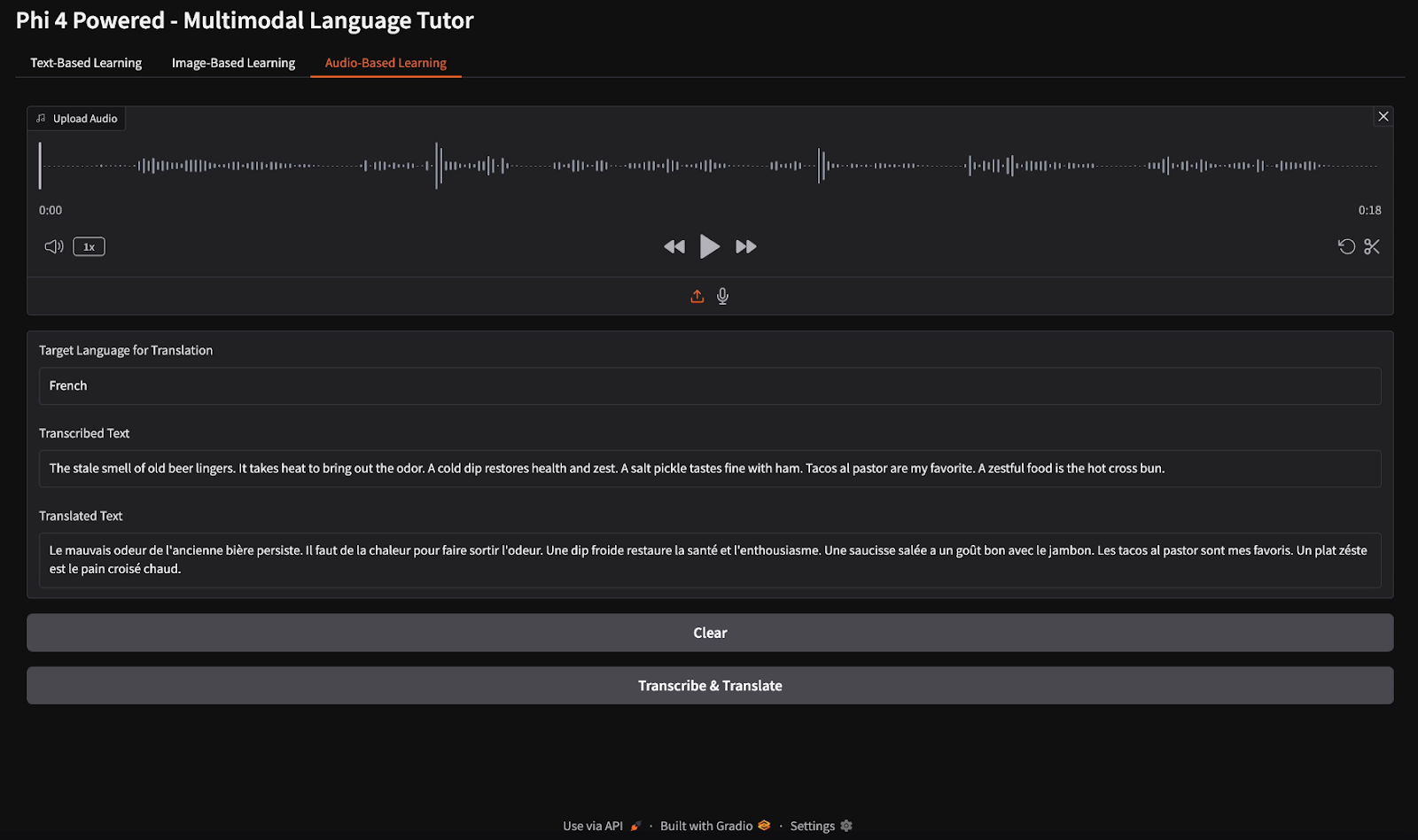
Neste tutorial, criamos um tutor de idiomas multimodal usando o modelo multimodal Phi-4, permitindo o aprendizado de idiomas baseado em texto, imagem e áudio. Usamos os recursos avançados de visão, fala e texto do Phi-4 para fornecer traduções em tempo real, correções gramaticais, transcrição de fala e insights de aprendizado baseados em imagens. Esse projeto demonstra como a IA multimodal pode aprimorar o ensino de idiomas e a acessibilidade.
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Javier Canales Luna
8 min
Tutorial
Arunn Thevapalan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali


