
programa
Desarrollo de aplicaciones de IA
21 h
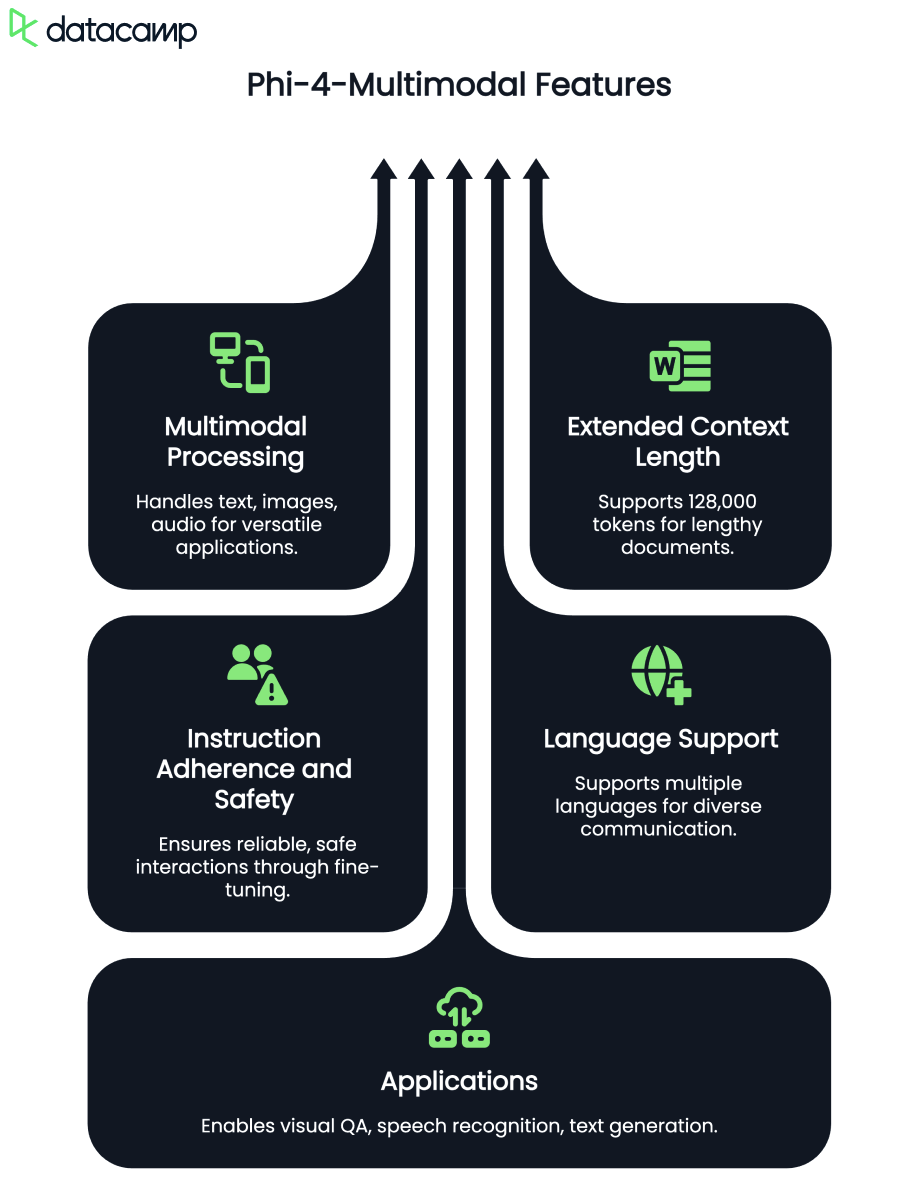
Phi-4-multimodal es un multimodal ligero multimodal ligero desarrollado por Microsoft. Forma parte de la familia Phi de Microsoft de pequeños modelos lingüísticos (SLM).
En este tutorial, te explicaré paso a paso cómo utilizar Phi-4-multimodal para construir un tutor lingüístico multimodal que pueda trabajar con texto, imágenes y audio. Las principales características de esta aplicación son
Hagamos primero una presentación muy rápida del modelo multimodal Phi-4, y luego empezaremos a construir la aplicación.
Phi-4-multimodal es un modelo avanzado de IA diseñado para el procesamiento de texto, visión y habla. Permite la integración perfecta de múltiples modalidades, lo que lo hace ideal para aplicaciones de aprendizaje de idiomas. Algunas de sus capacidades clave son:
Con una longitud de contexto de 128K tokens, el modelo multimodal Phi-4 está optimizado para un razonamiento eficiente y entornos con limitaciones de memoria, lo que lo hace perfecto para el aprendizaje del lenguaje impulsado por IA en tiempo real.
La aplicación de tutor lingüístico multimodal que vamos a construir es una herramienta interactiva potenciada por IA diseñada para ayudar a los usuarios a aprender nuevos idiomas mediante una combinación de interacciones basadas en texto, imágenes y audio.
Antes de empezar, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
pip install gradio transformers torch soundfile pillowTambién debemos asegurarnos de que FlashAttention2 está instalado para mejorar el rendimiento:
pip install flash-attn --no-build-isolationNota: Este proyecto utiliza una GPU A100 en un portátil Google Colab. Si utilizas una GPU antigua (por ejemplo, NVIDIA V100), puede que tengas que desactivar FlashAttention2 configurando _attn_implementation="eager" en el paso de inicialización del modelo.
Una vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
import gradio as gr
import torch
import requests
import io
import os
import soundfile as sf
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfigPara aprovechar las capacidades multimodales de Phi-4, primero cargamos tanto el modelo como su procesador. La ruta del modelo se establece desde Cara Abrazadamientras que el procesador se encarga de tokenizar el texto, redimensionar y normalizar las imágenes, y convertir las formas de onda de audio a un formato compatible con el modelo para un procesamiento multimodal sin fisuras.
# Load model and processor
model_path = "microsoft/Phi-4-multimodal-instruct"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
_attn_implementation='flash_attention_2',
).cuda()
generation_config = GenerationConfig.from_pretrained(model_path)El paso de inicialización del modelo utiliza el 'AutoModelForCausalLM.from_pretrained() function to load the pretrained Phi-4 model for causal language modeling (CLM) and loads the model on GPU using device_map="cuda".
Un parámetro clave en este paso es _attn_implementation='flash_attention_2'`, que utiliza FlashAttention2 para un mecanismo de atención más rápido y eficiente en memoria, especialmente para el procesamiento de contextos largos.
Ahora que hemos cargado el modelo, vamos a construir las funcionalidades clave.
Un aspecto importante de cualquier proyecto basado en LLM o VLM es garantizar que el modelo genere respuestas precisas y pertinentes. Esto también implica eliminar cualquier texto de aviso de la salida, garantizando que los usuarios reciban una respuesta limpia y directa sin que la instrucción inicial aparezca al principio.
def clean_response(response, instruction_keywords):
"""Removes the prompt text dynamically based on instruction keywords."""
for keyword in instruction_keywords:
if response.lower().startswith(keyword.lower()):
response = response[len(keyword):].strip()
return responseSimplemente utilizamos la función strip() para eliminar el texto de la instrucción basándonos en las palabras clave de la instrucción.
Ahora, vamos a procesar nuestras entradas, que pueden ser texto, imagen o audio, según la entrada del usuario o el escenario.
def process_input(file, input_type, question):
user_prompt = "<|user|>"
assistant_prompt = "<|assistant|>"
prompt_suffix = "<|end|>"
if input_type == "Image":
prompt= f'{user_prompt}<|image_1|>{question}{prompt_suffix}{assistant_prompt}'
image = Image.open(file)
inputs = processor(text=prompt, images=image, return_tensors='pt').to(model.device)
elif input_type == "Audio":
prompt= f'{user_prompt}<|audio_1|>{question}{prompt_suffix}{assistant_prompt}'
audio, samplerate = sf.read(file)
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to(model.device)
elif input_type == "Text":
prompt = f'{user_prompt}{question} "{file}"{prompt_suffix}{assistant_prompt}'
inputs = processor(text=prompt, return_tensors='pt').to(model.device)
else:
return "Invalid input type"
generate_ids = model.generate(**inputs, max_new_tokens=1000, generation_config=generation_config)
response = processor.batch_decode(generate_ids, skip_special_tokens=True)[0]
return clean_response(response, [question])La función anterior se encarga de manejar las entradas de texto, imagen y audio y de generar una respuesta utilizando el modelo multimodal Phi-4. Aquí tienes un desglose técnico de este flujo de trabajo:
"Image", la consulta se formatea con un marcador de posición de imagen (<|image_1|>). A continuación se carga la imagen, y el procesador tokeniza el texto que la acompaña mientras extrae las características visuales. Las entradas procesadas se transfieren a la GPU para un cálculo optimizado."Audio", el indicador se estructura con un marcador de posición de audio (<|audio_1|>). El archivo de audio se lee con la función sf.read(), extrayendo la forma de onda en bruto y la frecuencia de muestreo. A continuación, el procesador codifica tanto el audio como el texto, garantizando una integración perfecta para la comprensión multimodal."Text", el texto se incrusta directamente en el prompt. El procesador tokeniza y codifica la entrada, preparándola para su posterior procesamiento por el modelo.A continuación, procesamos el texto para su traducción y corrección gramatical mediante el modelo multimodal Phi-4.
def process_text_translate(text, target_language):
prompt = f'Translate the following text to {target_language}: "{text}"'
return process_input(text, "Text", prompt)
def process_text_grammar(text):
prompt = f'Check the grammar and provide corrections if needed for the following text: "{text}"'
return process_input(text, "Text", prompt)La función process_text_translate() construye dinámicamente un aviso de traducción especificando la lengua de destino y pasa el texto de entrada y el aviso estructurado a la función process_input(), devolviendo el texto traducido.
Del mismo modo, la función process_text_grammar() construye un aviso de corrección gramatical, llama a la función process_input() con el texto de entrada y el tipo, y devuelve una versión gramaticalmente corregida del texto. Ambas funciones agilizan el procesamiento lingüístico utilizando las capacidades del modelo para la traducción y la corrección gramatical.
Ahora ya tenemos todas las funciones lógicas clave. A continuación, trabajaremos en la creación de una interfaz de usuario interactiva con Gradio.
def gradio_interface():
with gr.Blocks() as demo:
gr.Markdown("# Phi 4 Powered - Multimodal Language Tutor")
with gr.Tab("Text-Based Learning"):
text_input = gr.Textbox(label="Enter Text")
language_input = gr.Textbox(label="Target Language", value="French")
text_output = gr.Textbox(label="Response")
text_translate_btn = gr.Button("Translate")
text_grammar_btn = gr.Button("Check Grammar")
text_clear_btn = gr.Button("Clear")
text_translate_btn.click(process_text_translate, inputs=[text_input, language_input], outputs=text_output)
text_grammar_btn.click(process_text_grammar, inputs=[text_input], outputs=text_output)
text_clear_btn.click(lambda: ("", "", ""), outputs=[text_input, language_input, text_output])
with gr.Tab("Image-Based Learning"):
image_input = gr.Image(type="filepath", label="Upload Image")
language_input_image = gr.Textbox(label="Target Language for Translation", value="English")
image_output = gr.Textbox(label="Response")
image_clear_btn = gr.Button("Clear")
image_translate_btn = gr.Button("Translate Text in Image")
image_summarize_btn = gr.Button("Summarize Image")
image_translate_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Extract and translate text", visible=False)], outputs=image_output)
image_summarize_btn.click(process_input, inputs=[image_input, gr.Textbox(value="Image", visible=False), gr.Textbox(value="Summarize this image", visible=False)], outputs=image_output)
image_clear_btn.click(lambda: (None, "", ""), outputs=[image_input, language_input_image, image_output])
with gr.Tab("Audio-Based Learning"):
audio_input = gr.Audio(type="filepath", label="Upload Audio")
language_input_audio = gr.Textbox(label="Target Language for Translation", value="English")
transcript_output = gr.Textbox(label="Transcribed Text")
translated_output = gr.Textbox(label="Translated Text")
audio_clear_btn = gr.Button("Clear")
audio_transcribe_btn = gr.Button("Transcribe & Translate")
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), gr.Textbox(value="Transcribe this audio", visible=False)], outputs=transcript_output)
audio_transcribe_btn.click(process_input, inputs=[audio_input, gr.Textbox(value="Audio", visible=False), language_input_audio], outputs=translated_output)
audio_clear_btn.click(lambda: (None, "", "", ""), outputs=[audio_input, language_input_audio, transcript_output, translated_output])
demo.launch(debug=True)
if __name__ == "__main__":
gradio_interface()El código anterior organiza la interfaz de Gradio en tres pestañas interactivas, a saber: aprendizaje basado en texto, aprendizaje basado en imágenes y aprendizaje basado en audio, cada una de ellas diseñada para diferentes funcionalidades de aprendizaje de idiomas.
Los usuarios pueden introducir texto para traducción o corrección gramatical, subir imágenes para extracción y resumen de texto, o proporcionar audio para transcripción y traducción de voz.
Cada función se activa mediante el método click() de Gradio, que llama a funciones de procesamiento como process_text_translate(), process_text_grammar() y process_input(), como ya se ha comentado, pasando las entradas necesarias y actualizando las salidas dinámicamente.
Se incluye un botónClear en cada pestaña para restablecer las entradas y salidas, garantizando una experiencia de usuario sin problemas. Por último, la interfaz se lanza con demo.launch(debug=True), lo que permite a los desarrolladores depurar fácilmente cualquier error de la aplicación.
Aquí tienes algunos de mis experimentos con esta aplicación.
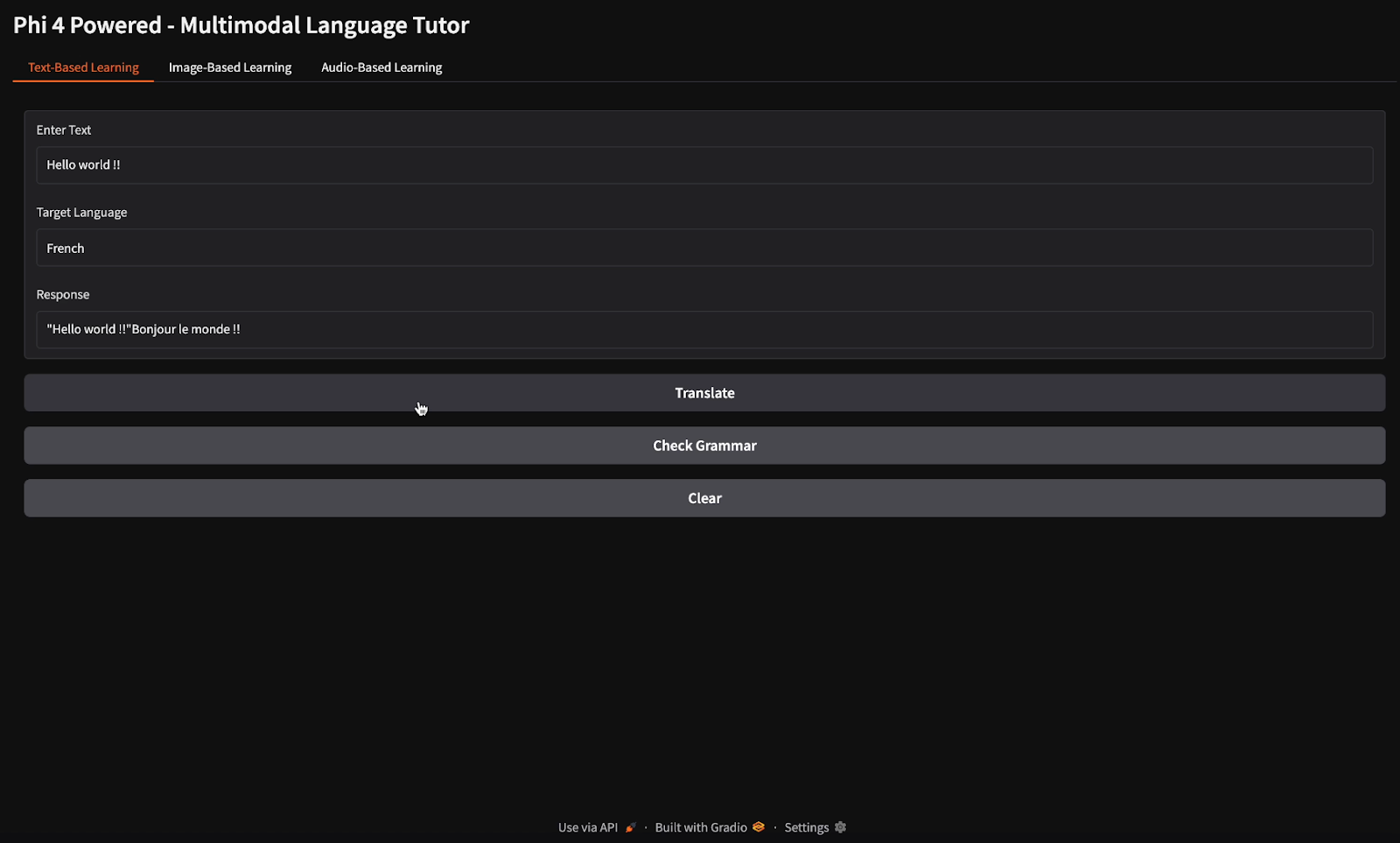
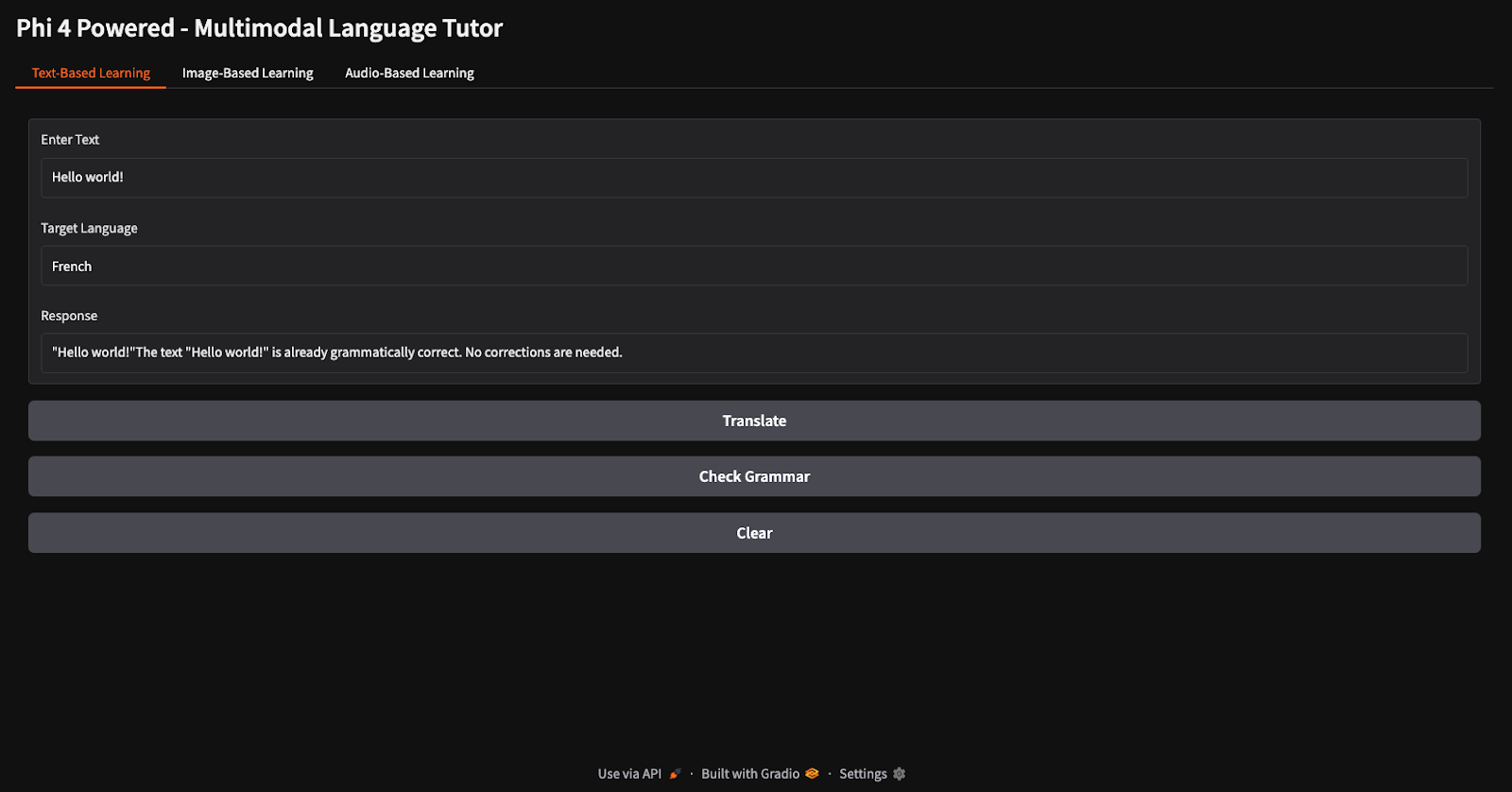
Para las tareas de traducción y comprobación gramatical, proporcioné el texto "Hola mundo" e indiqué al modelo que lo tradujera al francés y comprobara su gramática (fíjate en los diferentes botones para traducción y comprobación gramatical).
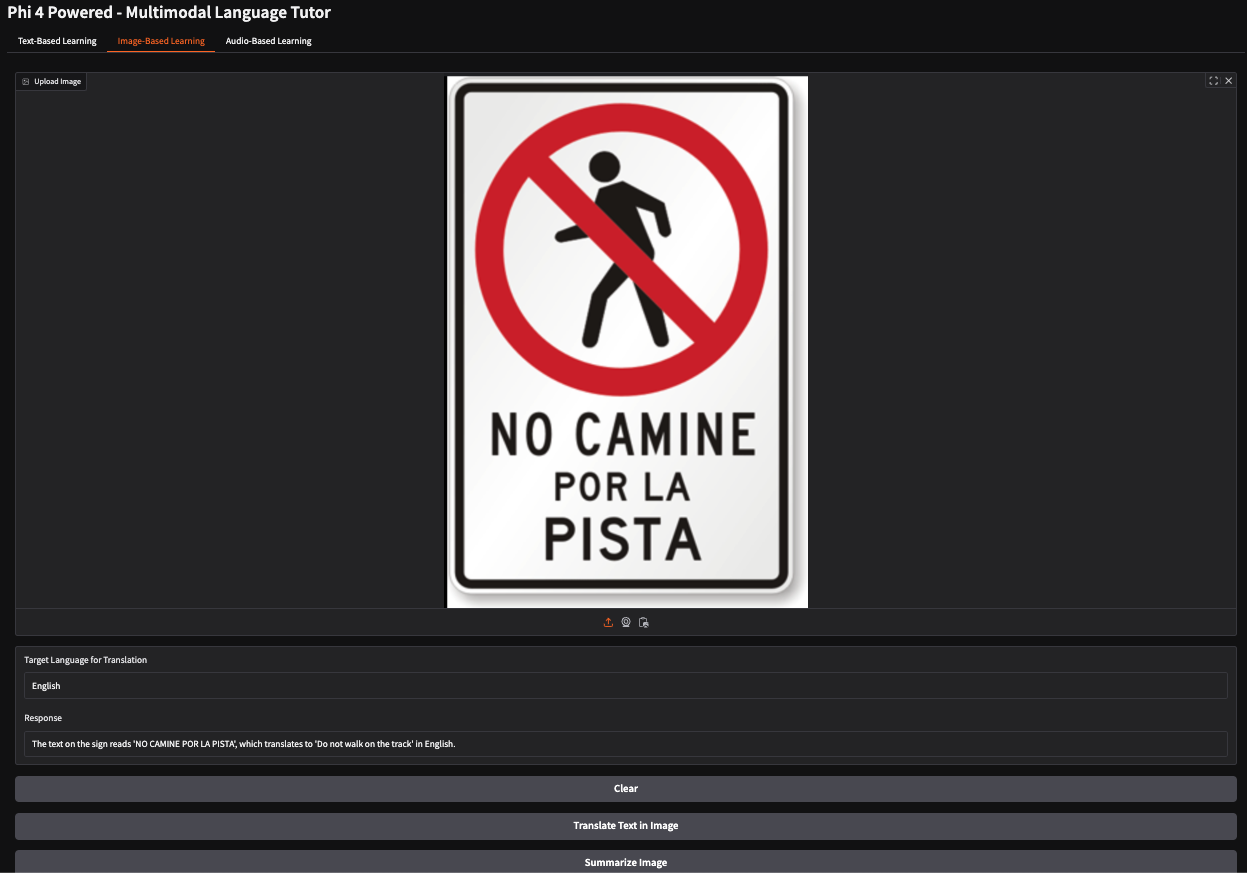
En este ejemplo, he proporcionado una imagen de una señal de stop española que indica a los peatones que no deben circular por un camino concreto. El modelo interpretó con precisión el significado del signo y generó la respuesta: "No camines por la pista".
Para la transcripción del audio, proporcioné un archivo de audio en inglés e indiqué a la modelo que transcribiera el discurso y tradujera la transcripción al francés.
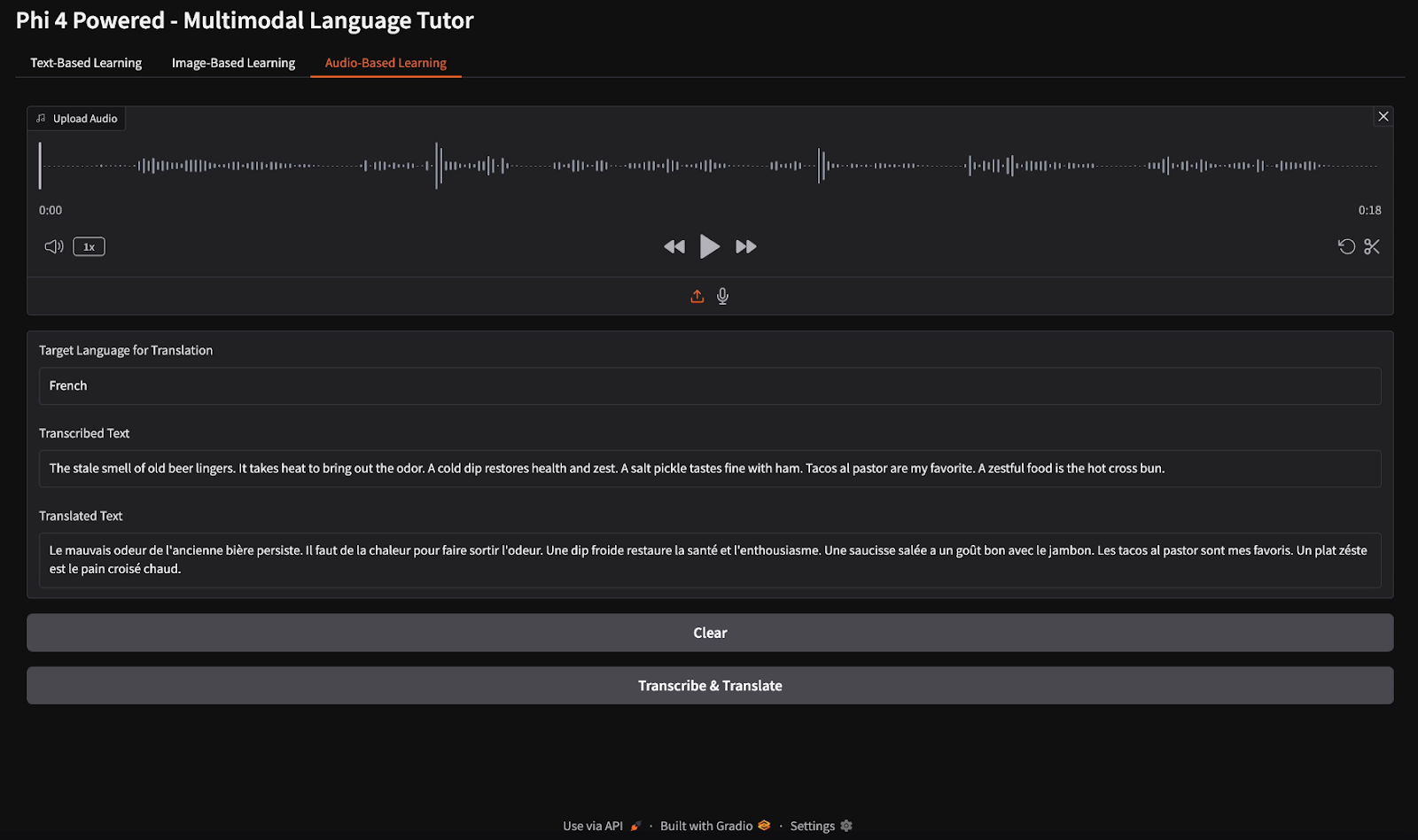
En este tutorial, construimos un tutor de idiomas multimodal utilizando el modelo multimodal Phi-4, que permite el aprendizaje de idiomas basado en texto, imágenes y audio. Utilizamos las capacidades avanzadas de visión, voz y texto de Phi-4 para proporcionar traducciones en tiempo real, correcciones gramaticales, transcripción de voz y conocimientos de aprendizaje basados en imágenes. Este proyecto demuestra cómo la IA multimodal puede mejorar la educación lingüística y la accesibilidad.
Aprende IA con estos cursos
programa
programa
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
10 min
blog
Stanislav Karzhev
9 min
Tutorial
Arunn Thevapalan
Tutorial
Josep Ferrer

