Kurs
Google Sheets: Fortgeschrittene Funktionen
4 Std.
57.2K
Während viele Unternehmen ihre Daten in Datenbanken und Speicheroptionen wie AWS, Azure und GCP speichern, werden für die Speicherung kleinerer Datenmengen nach wie vor häufig Microsoft Excel-Tabellen verwendet.
Die Data Science-Funktionen von Excel sind begrenzter als die von R. Daher ist es nützlich, Daten aus Tabellenkalkulationen in R importieren zu können.
In diesem Tutorium geht es darum, Excel-Arbeitsblätter (sowie bestimmte Zeilen und Spalten) mit dem readxl-Paket in R einzulesen.
Um das zu verstehen, brauchst du grundlegende Kenntnisse in R.
Eine allgemeinere Anleitung zum Importieren vieler verschiedener Dateitypen in R findest du unter Datenimport in R: Ein Tutorial.
Der Datensatz, den wir in R einlesen werden, ist ein kleiner Datensatz mit nur zwei Blättern, um zu zeigen, wie man festlegt, welches Blatt gelesen werden soll. Du kannst sie hier finden.
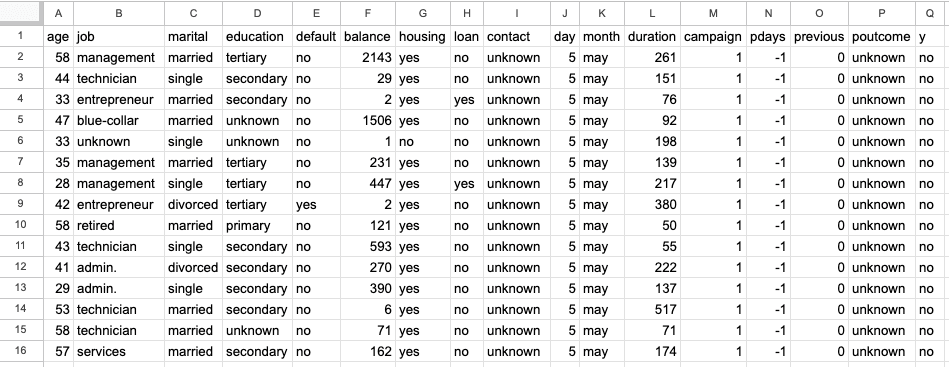
Das erste Blatt ist ein Bank-Marketing-Datensatz mit 45.211 Zeilen und 17 Spalten. Der Screenshot unten stammt aus der Excel-Datei "sample.xlsx" mit dem Blattnamen "bank-full".
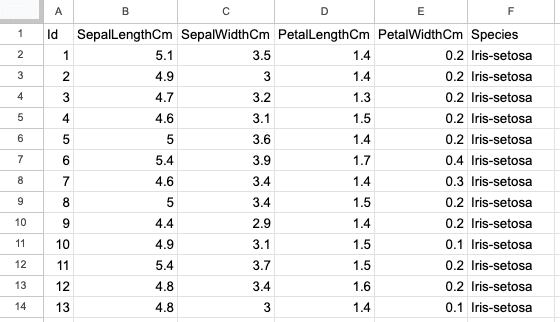
Das zweite Blatt ist der Iris-Datensatz mit 150 Zeilen und 6 Spalten und enthält Informationen über die Irisblüten, z. B. die Länge und Breite der Kelch- und Blütenblätter. Der Screenshot unten stammt aus derselben Excel-Datei, "sample.xlsx" und dem Blatt "iris".
Dieses Tutorial verwendet das Paket readxl. Das openxlsx-Paket ist eine gute Alternative, die auch die Möglichkeit bietet, XLSX-Dateien zu schreiben, aber weniger gut mit tidyverse-Paketen wie dplyr und tidyr integriert ist.
Um Excel-Dateien mit dem readxl-Paket zu lesen, müssen wir das Paket zunächst installieren und dann mit der Funktion "Bibliothek" importieren.
install.packages("readxl")In der Konsole siehst du die folgende Ausgabe, die die erfolgreiche Installation anzeigt.
trying URL 'https://cran.rstudio.com/bin/macosx/big-sur-arm64/contrib/4.2/readxl_1.4.2.tgz'
Content type 'application/x-gzip' length 1545782 bytes (1.5 MB)
==================================================
downloaded 1.5 MB
The downloaded binary packages are in
/var/folders/mq/46mc_8tj06n0wh2xjkk08r140000gn/T//RtmpHIGYqM/downloaded_packagesUm die "readxl"-Methode zu verwenden, führe den folgenden Befehl in der R-Konsole aus.
library(readxl)Beachte, dass das openxlsx-Paket eine weitere gute Alternative ist, um XLSX-Dateien zu schreiben.
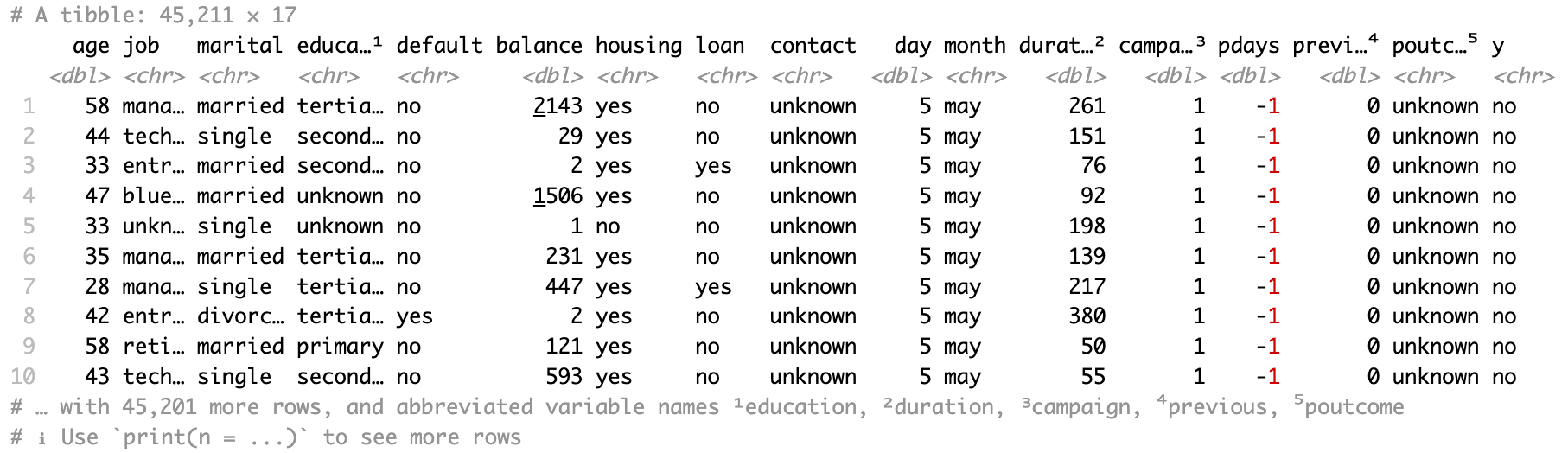
Lesen wir alle Daten aus dem ersten Arbeitsblatt, "bank-full", mit read_xlsx() und nur dem Pfad-Argument.
bank_df <- read_xlsx(path = "sample.xlsx")Die resultierenden Daten sind ein Tibble.
Du kannst read_excel() genauso verwenden wie read_xlsx(), und alle Argumente, die du in den folgenden Abschnitten sehen wirst, funktionieren mit dieser Funktion ähnlich. read_excel() versucht zu erraten, ob du eine XLSX-Tabelle oder den älteren XLS-Tabellentyp hast.
bank_df <- read_excel(path = "sample.xlsx")
Jetzt lesen wir alle Daten aus der zweiten Arbeitsmappe, also "iris", mit der Funktion read_xlsx() und dem Argument sheet.
iris <- read_xlsx("sample.xlsx", sheet = "iris")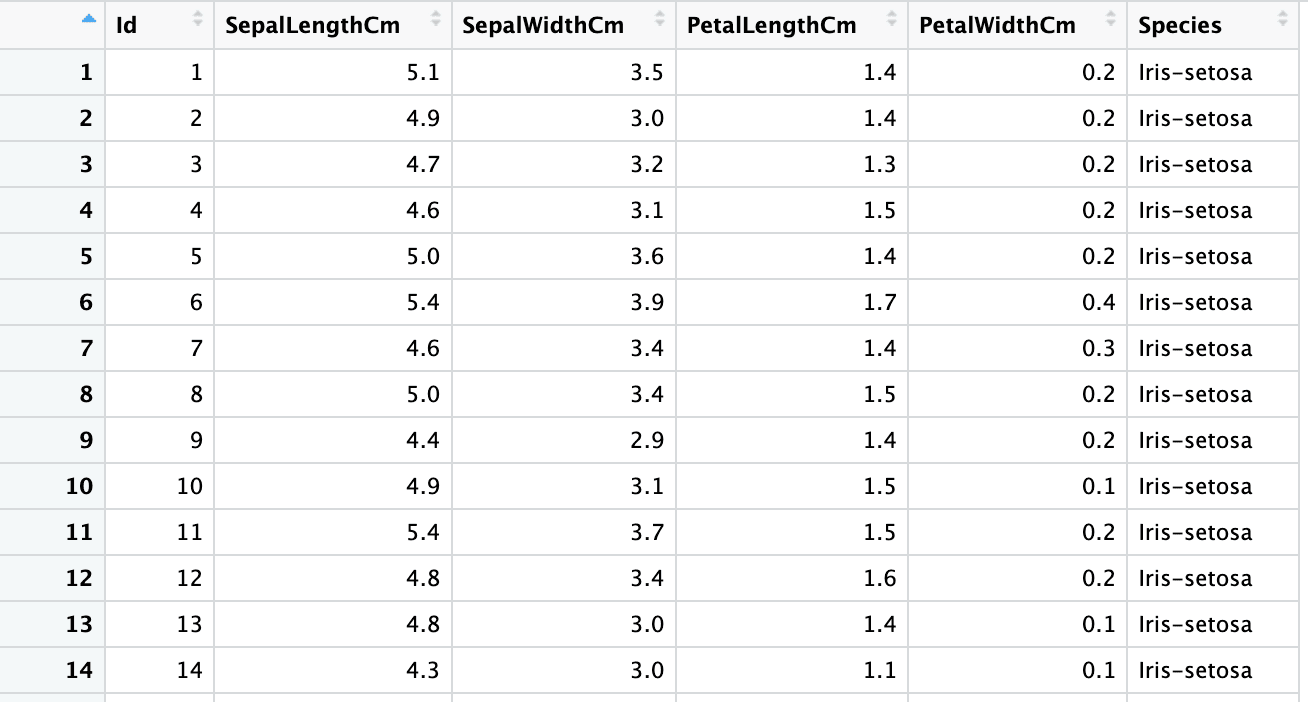
Du kannst im Blattargument auch die Blattnummer anstelle des Blattnamens angeben.
iris2 <- read_xlsx("sample.xlsx", sheet = 1)
Lass uns bestimmte Zeilen aus einer Arbeitsmappe lesen, indem wir die Argumente skip und n_max setzen. Um die ersten paar Zeilen zu überspringen, kannst du das Argument skip mit einem Wert verwenden, der der Anzahl der Zeilen entspricht, die du überspringen möchtest.
bank_df_s2 <- read_excel("sample.xlsx", sheet = "bank-full", skip = 2)Bitte beachte, dass der obige Code auch die Kopfzeilen überspringt. In den folgenden Abschnitten erfährst du, wie du die Kopfzeilen in der Funktion read_xlsx() explizit angeben kannst.
Um die ersten n Zeilen zu lesen, gibst du das Argument n_max in der Funktion read_xlsx() an. Der folgende Code liest die ersten 1000 Zeilen des Blattes "bank-full".
bank_df_n1k <- read_excel("sample.xlsx", sheet = "bank-full", n_max = 1000)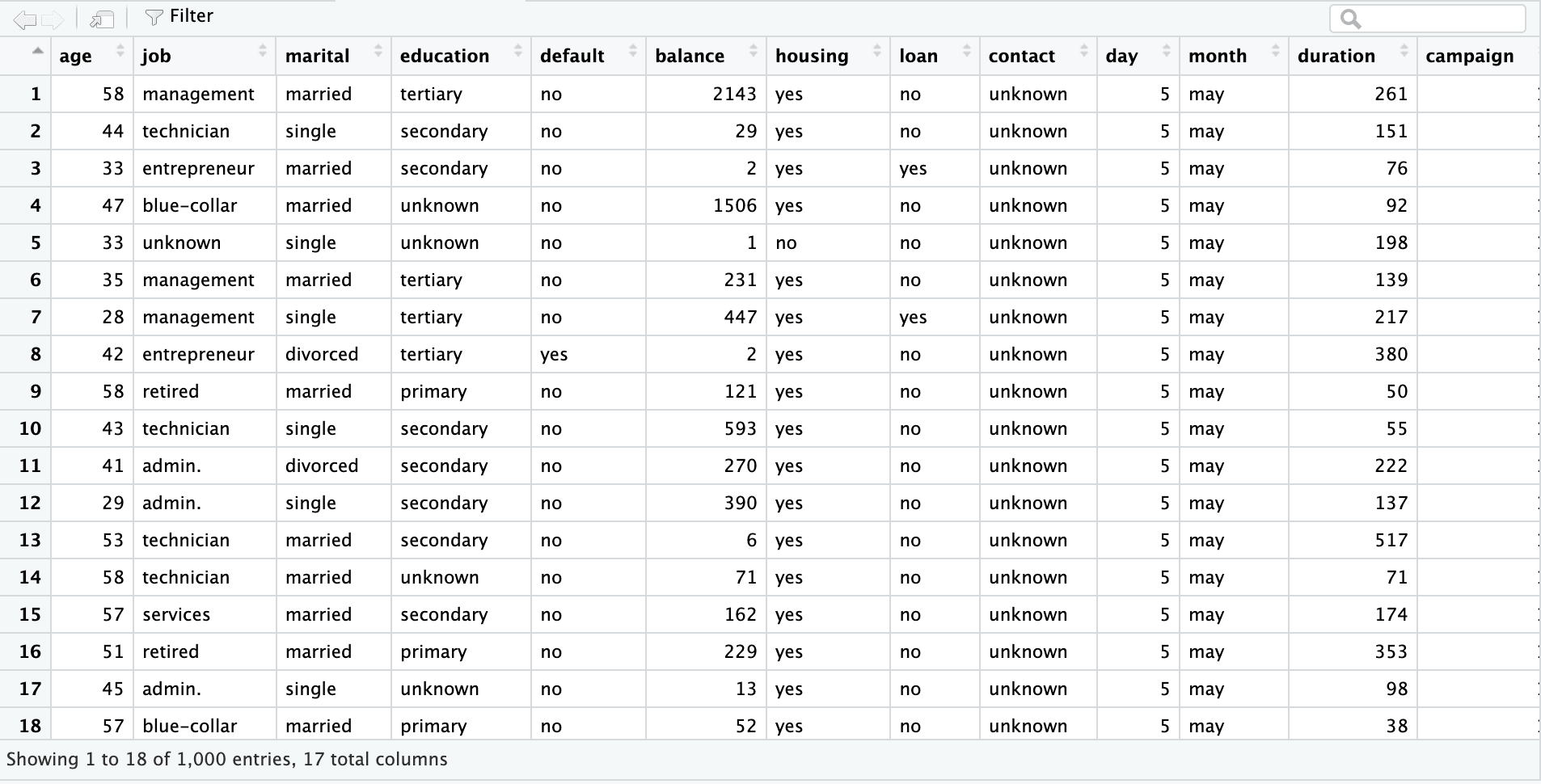
Du kannst auch beide Argumente kombinieren, um ein paar Zeilen zu überspringen und eine bestimmte Anzahl von Zeilen aus dem verbleibenden Datensatz zu lesen.
Während die Argumente "skip" und "n_max" es dir ermöglichen, eine Teilmenge der Datenzeilen zu lesen, kannst du bestimmte Zellen aus einer Arbeitsmappe lesen, indem du das Argument range setzt.
Es gibt zwei Schreibweisen, um die Teilmenge des Datensatzes anzugeben:
Dazu gibst du die Koordinaten des Rechtecks an, das du aus dem Datensatz ausschneiden möchtest.
Notation 1:
bank_df_range1 <- read_excel("sample.xlsx", sheet = "bank-full", range = "A3:E10")Notation 2:
bank_df_range2 <- read_excel("sample.xlsx", sheet = "bank-full",
range = "R3C1:R10C5")Range erlaubt es dir auch, den Blattnamen in das Argument aufzunehmen (Beispiel: wbook!E4:G8).
bank_df_range3 <- read_excel("sample.xlsx", range = "bank-full!R3C1:R10C5")Wir lesen Daten, die keine Kopfzeile haben, indem wir das Argument col_names auf einen Zeichenvektor setzen.
PS: Wir verwenden das Argument skip zuerst, um die Kopfzeile zu entfernen.
columns <- c("ID", "Sepal Length", "Sepal Width", "Petal Length", "Petal Width", "Species Name")
iris3 <- read_excel("sample.xlsx", sheet = 2, skip = 1, col_names = columns)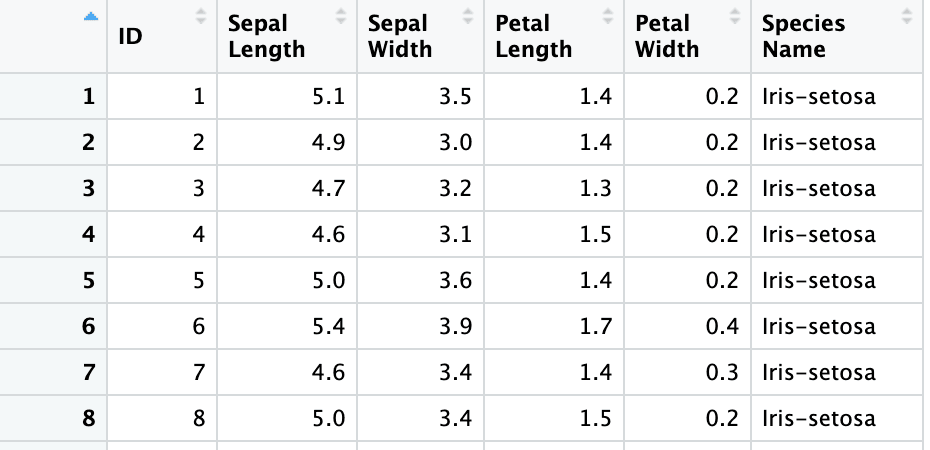
Im letzten Abschnitt haben wir die Kopfzeilen durch Leerzeichen getrennt angegeben. Mit dem Argument .name_repair = "universal" kannst du Header-Namen in syntaktische R-Variablen verwandeln.
iris4 <- read_excel("sample.xlsx", sheet = 2, skip = 1,
col_names = columns, .name_repair = "universal")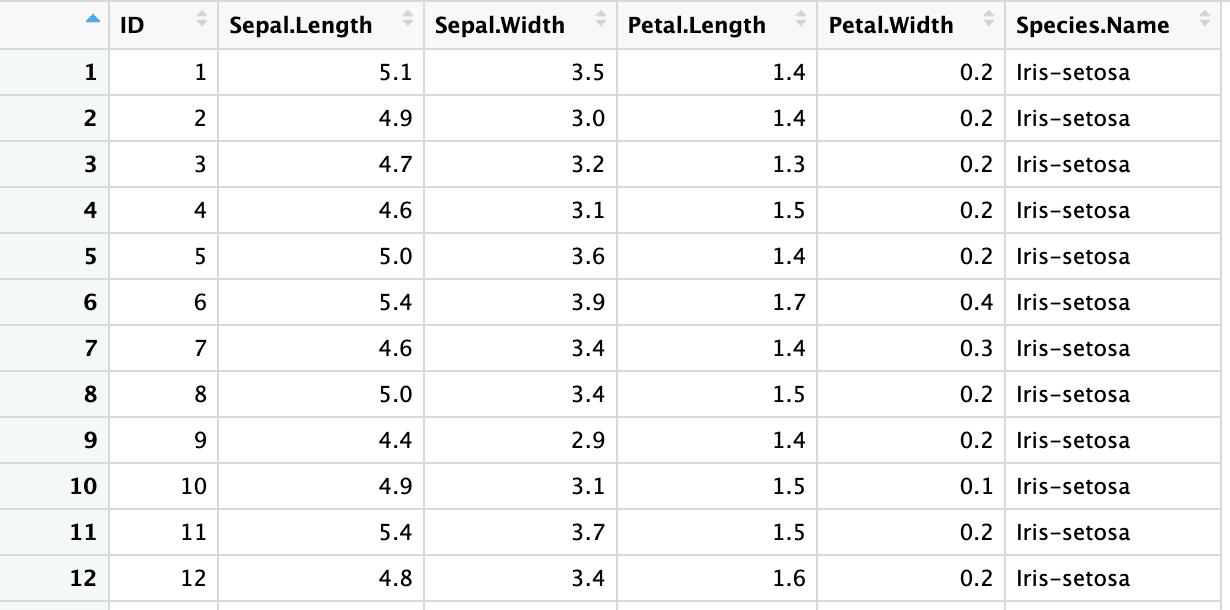
Wenn du eine Excel-Datei liest, errät R standardmäßig den Datentyp jeder Variablen. Schauen wir uns die Spaltentypen des Iris-Datensatzes an, der mit den Standardargumenten gelesen wird.
sapply(iris, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" Um die Spaltentypermittlung zu überschreiben, kannst du das Argument col_types verwenden.
iris5 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris5, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 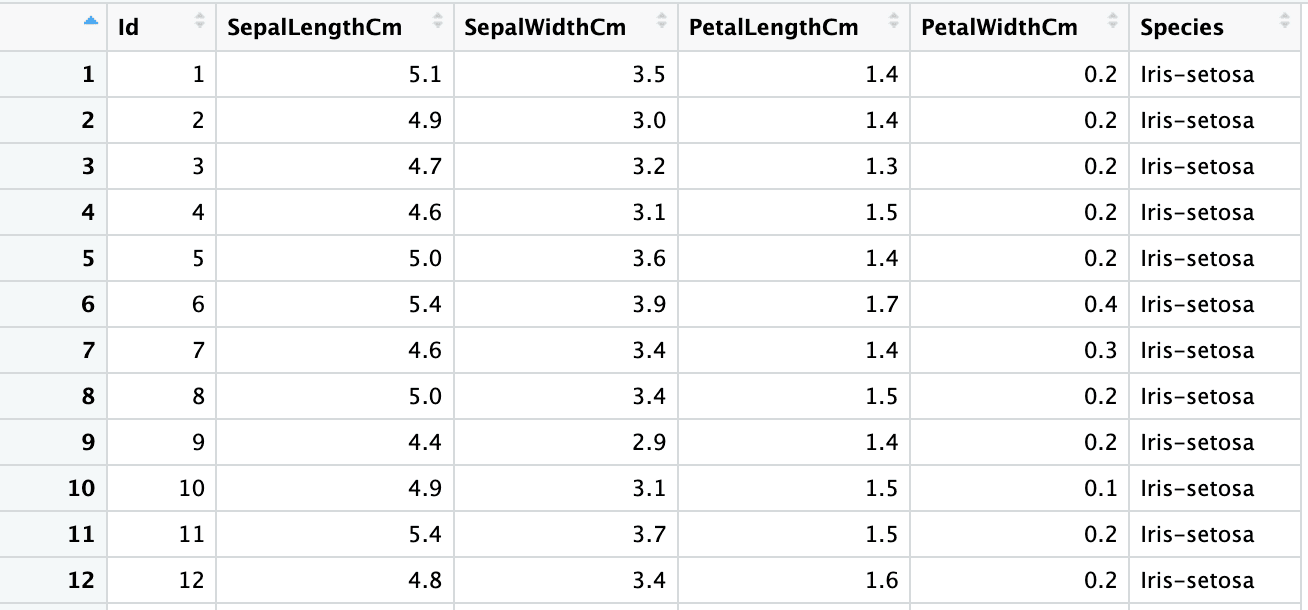
Du kannst R auch die Spaltentypen ausgewählter Variablen erraten lassen, indem du für eine bestimmte Spalte den Wert col_types als "guess" angibst.
iris6 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("guess", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris6, class)Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 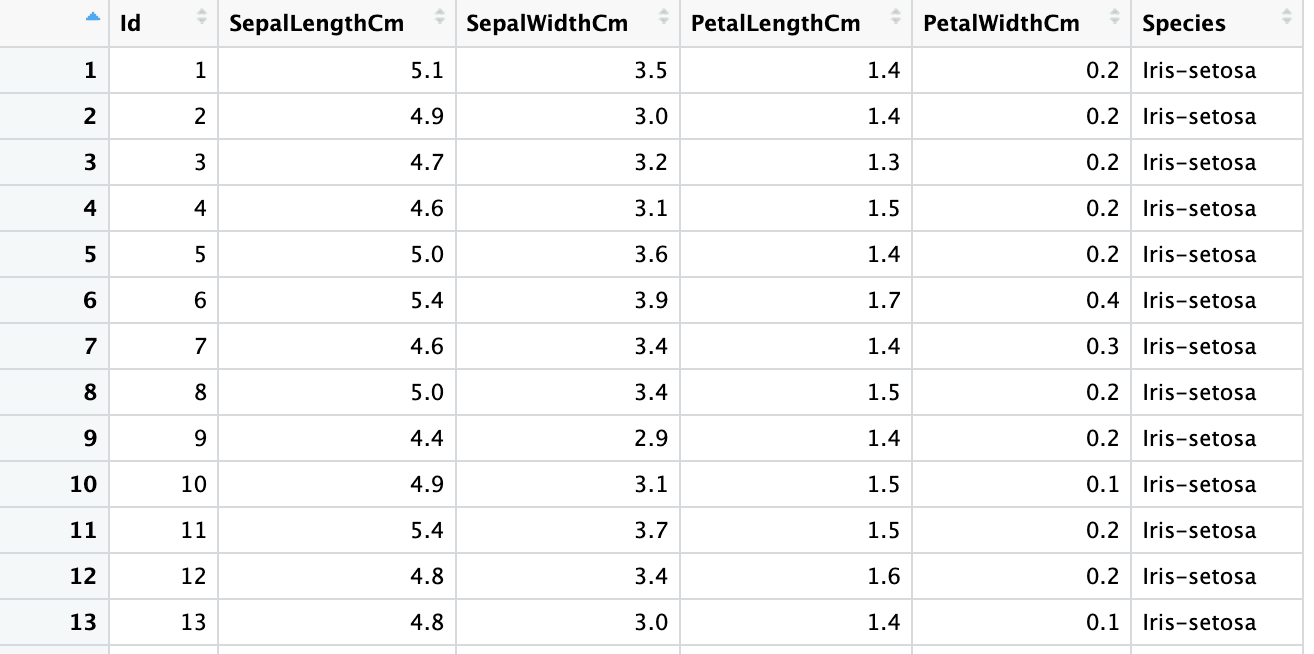
Oft heißt es: Je mehr Daten, desto besser. In vielen Anwendungsfällen wirst du jedoch feststellen, dass einige der Variablen/Spalten kein Signal enthalten. Das kann einen der folgenden Gründe haben.
Du kannst das Lesen einiger Spalten überspringen, indem du col_types auf "skip" setzt, wie unten gezeigt.
iris7 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "skip", "skip", "numeric", "numeric", "text"))
sapply(iris7, class) es auf die nächste Stufe
es auf die nächste StufeIn einer Welt, in der Daten in rasantem Tempo und in verschiedenen Formen erzeugt werden, muss deine Programmiersprache das Lesen dieser Datentypen unterstützen. R ist eine dieser mächtigen Sprachen, die dieses Unterfangen unterstützen. Melde dich für den Kurs "Einführung in den Datenimport in R" an, um zu lernen, wie R Pakete zum Import verschiedener Datensätze anbietet. Dieser Kurs bietet Tutorien und Quizze, um dein Verständnis für das Importieren von Daten in R zu stärken.
Erfahre mehr über R und Tabellenkalkulationen
Kurs