Cours
Google Sheets intermédiaire
4 h
57.2K
Alors que de nombreuses organisations stockent des données dans des bases de données et des options de stockage telles que AWS, Azure et GCP, les feuilles de calcul Microsoft Excel continuent d'être largement utilisées pour stocker des ensembles de données plus petits.
Les fonctionnalités de science des données d'Excel sont plus limitées que celles de R. Il est donc utile de pouvoir importer des données de feuilles de calcul vers R.
Dans ce tutoriel, nous aborderons la lecture de feuilles de calcul Excel (ainsi que de lignes et de colonnes spécifiques) dans R à l'aide du package readxl.
Pour comprendre cela, vous aurez besoin d'une connaissance de base de R.
Pour un guide plus général sur l'importation de nombreux types de fichiers dans R, consultez Comment importer des données dans R : Un tutoriel.
L'ensemble de données que nous allons lire dans R est un petit ensemble avec seulement deux feuilles pour démontrer comment spécifier la feuille à lire. Elle est disponible ici.
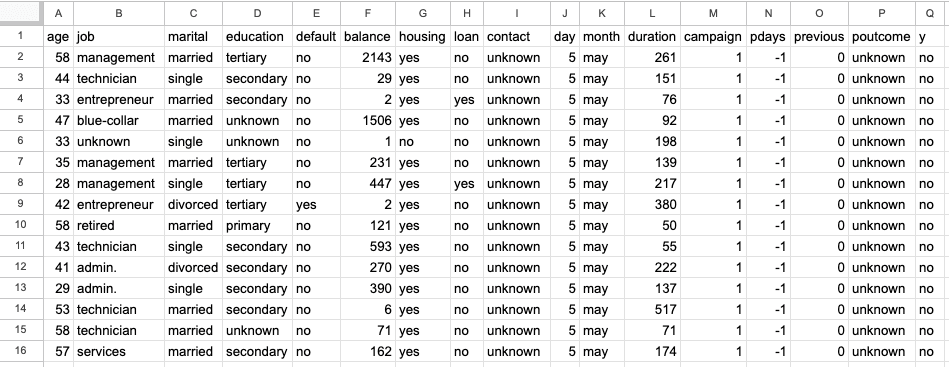
La première feuille est un ensemble de données sur le marketing bancaire comprenant 45 211 lignes et 17 colonnes. La capture d'écran ci-dessous provient du fichier Excel "sample.xlsx" et de la feuille "bank-full".
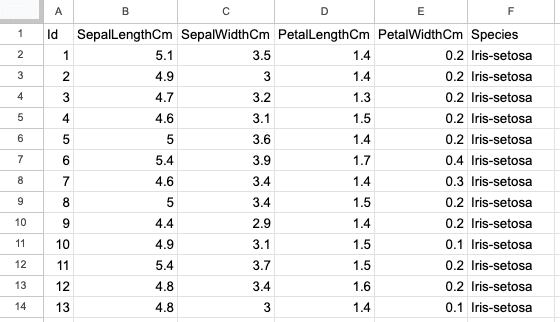
La deuxième feuille est l'ensemble de données Iris, avec 150 lignes et 6 colonnes, et contient des informations sur les types de fleurs d'Iris, telles que la longueur et la largeur des sépales et des pétales. La capture d'écran ci-dessous provient du même fichier Excel, "sample.xlsx" et de la feuille "iris".
Ce tutoriel utilise le paquetage readxl. Le package openxlsx est une alternative décente qui inclut également la possibilité d'écrire dans des fichiers XLSX, mais son intégration avec les packages tidyverse tels que dplyr et tidyr est moins forte.
Pour lire des fichiers Excel avec le paquet readxl, nous devons d'abord installer le paquet, puis l'importer à l'aide de la fonction "library".
install.packages("readxl")Vous verrez la sortie suivante dans la console, indiquant que l'installation a réussi.
trying URL 'https://cran.rstudio.com/bin/macosx/big-sur-arm64/contrib/4.2/readxl_1.4.2.tgz'
Content type 'application/x-gzip' length 1545782 bytes (1.5 MB)
==================================================
downloaded 1.5 MB
The downloaded binary packages are in
/var/folders/mq/46mc_8tj06n0wh2xjkk08r140000gn/T//RtmpHIGYqM/downloaded_packagesPour utiliser les méthodes "readxl", exécutez la commande suivante dans la console R.
library(readxl)Notez que le paquetage openxlsx est une autre bonne alternative pour écrire dans des fichiers XLSX.
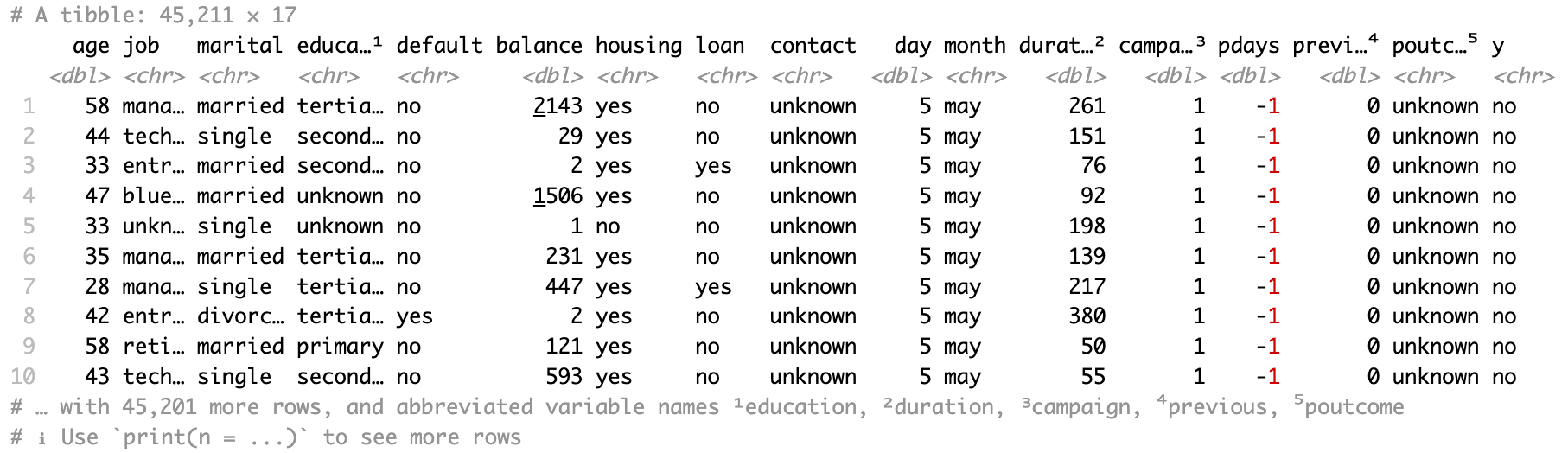
Lisons toutes les données de la première feuille de calcul, "bank-full", avec read_xlsx() et seulement l'argument path.
bank_df <- read_xlsx(path = "sample.xlsx")Les données résultantes sont un tibble.
Vous pouvez également utiliser read_excel() de la même manière que read_xlsx(), et tous les arguments que vous allez voir dans les sections suivantes fonctionnent de la même manière avec cette fonction. read_excel() essaiera de deviner si vous avez une feuille de calcul XLSX ou l'ancien type de feuille de calcul XLS.
bank_df <- read_excel(path = "sample.xlsx")
Lisons maintenant toutes les données du deuxième classeur, c'est-à-dire "iris", avec la fonction read_xlsx() et l'argument de la feuille.
iris <- read_xlsx("sample.xlsx", sheet = "iris")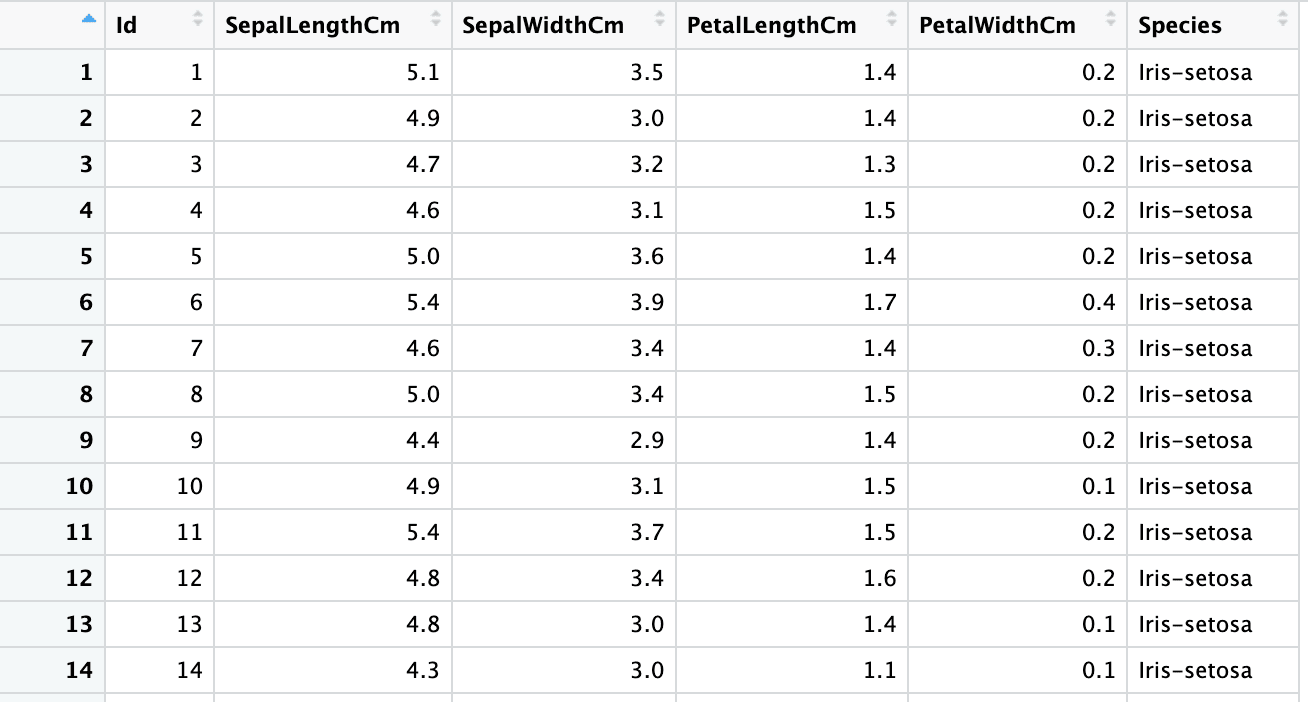
Vous pouvez également spécifier le numéro de la feuille dans l'argument de la feuille au lieu du nom de la feuille.
iris2 <- read_xlsx("sample.xlsx", sheet = 1)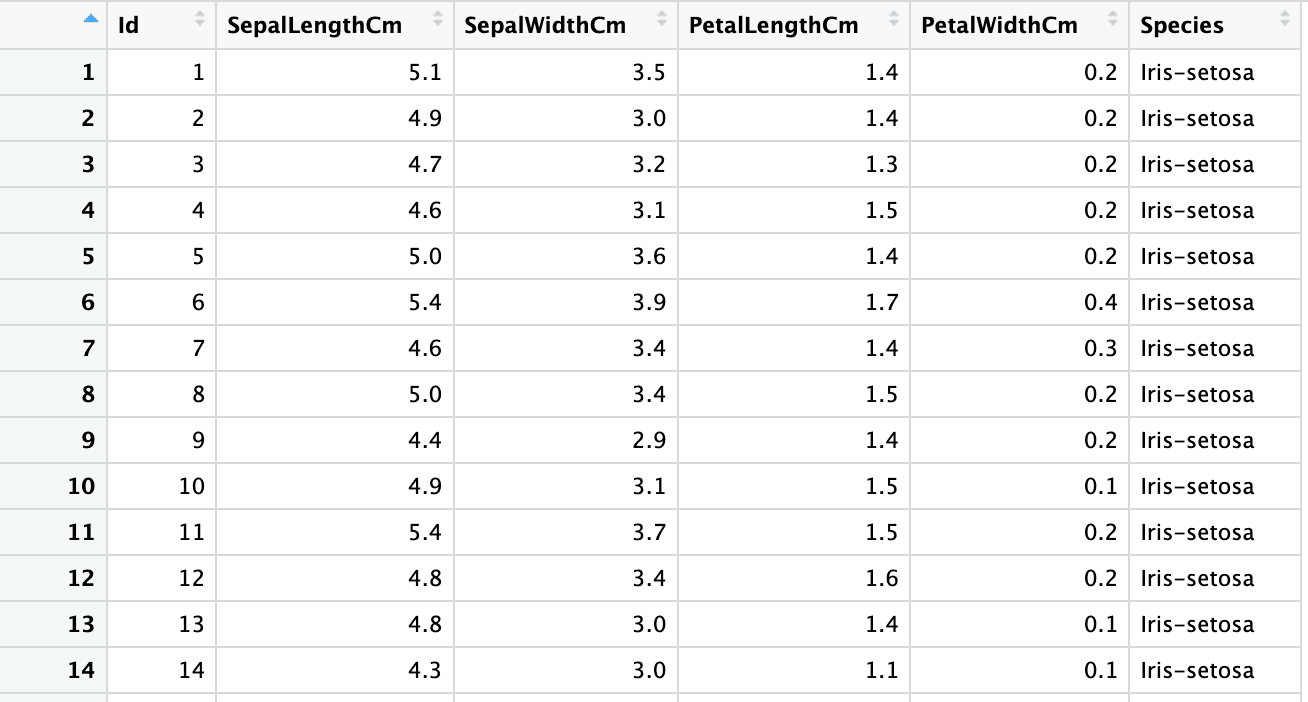
Lisons des lignes spécifiques d'un classeur en définissant les arguments skip et n_max. Pour sauter les premières lignes, vous pouvez utiliser l'argument skip avec une valeur égale au nombre de lignes que vous voulez sauter.
bank_df_s2 <- read_excel("sample.xlsx", sheet = "bank-full", skip = 2)Veuillez noter que le code ci-dessus ne tient pas compte des en-têtes. Vous apprendrez à spécifier explicitement les en-têtes dans la fonction read_xlsx() dans les sections suivantes.
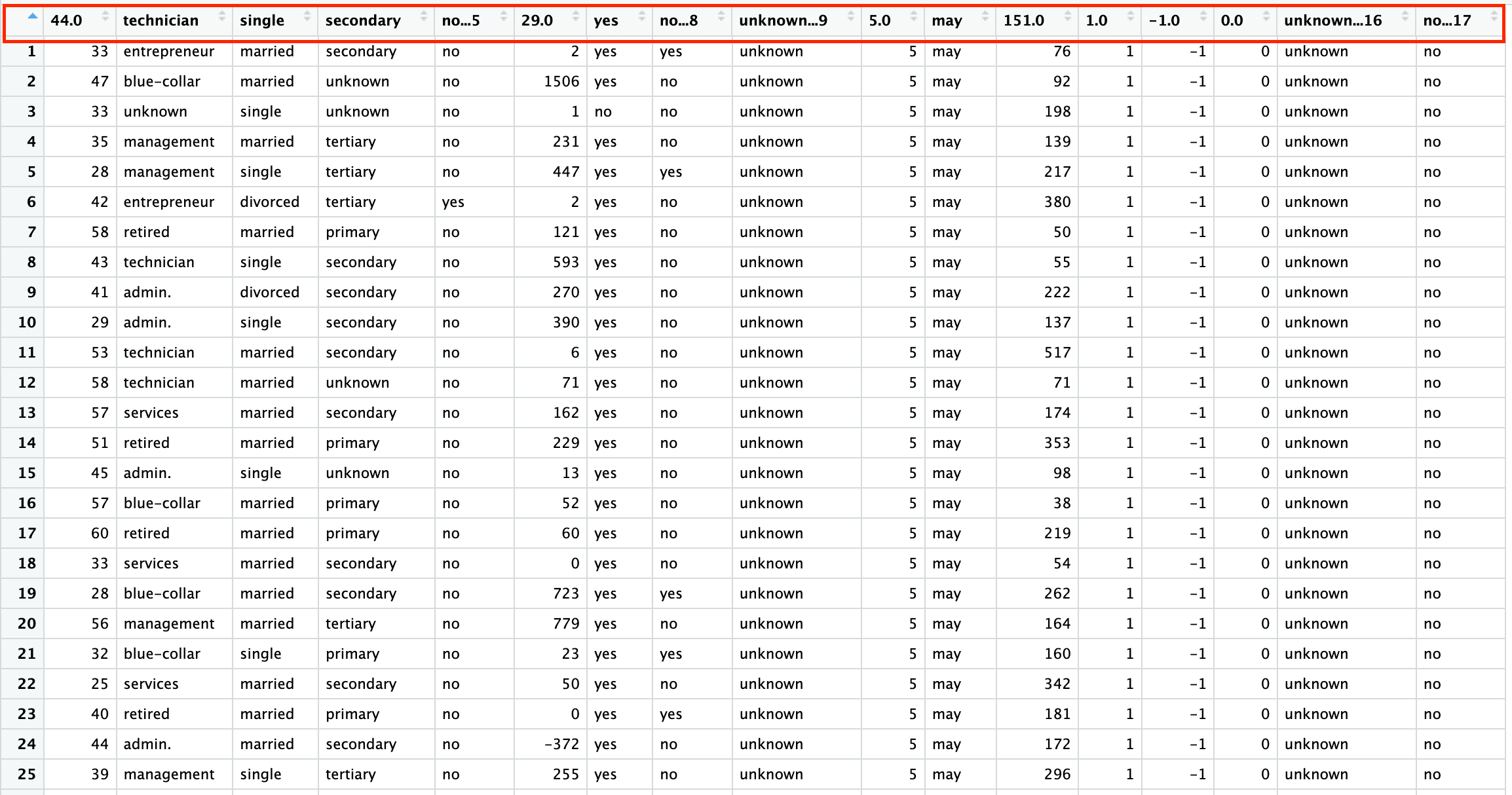
De même, pour lire les n premières lignes, spécifiez l'argument n_max dans la fonction read_xlsx(). Le code ci-dessous lit les 1000 premières lignes de la feuille "bank-full".
bank_df_n1k <- read_excel("sample.xlsx", sheet = "bank-full", n_max = 1000)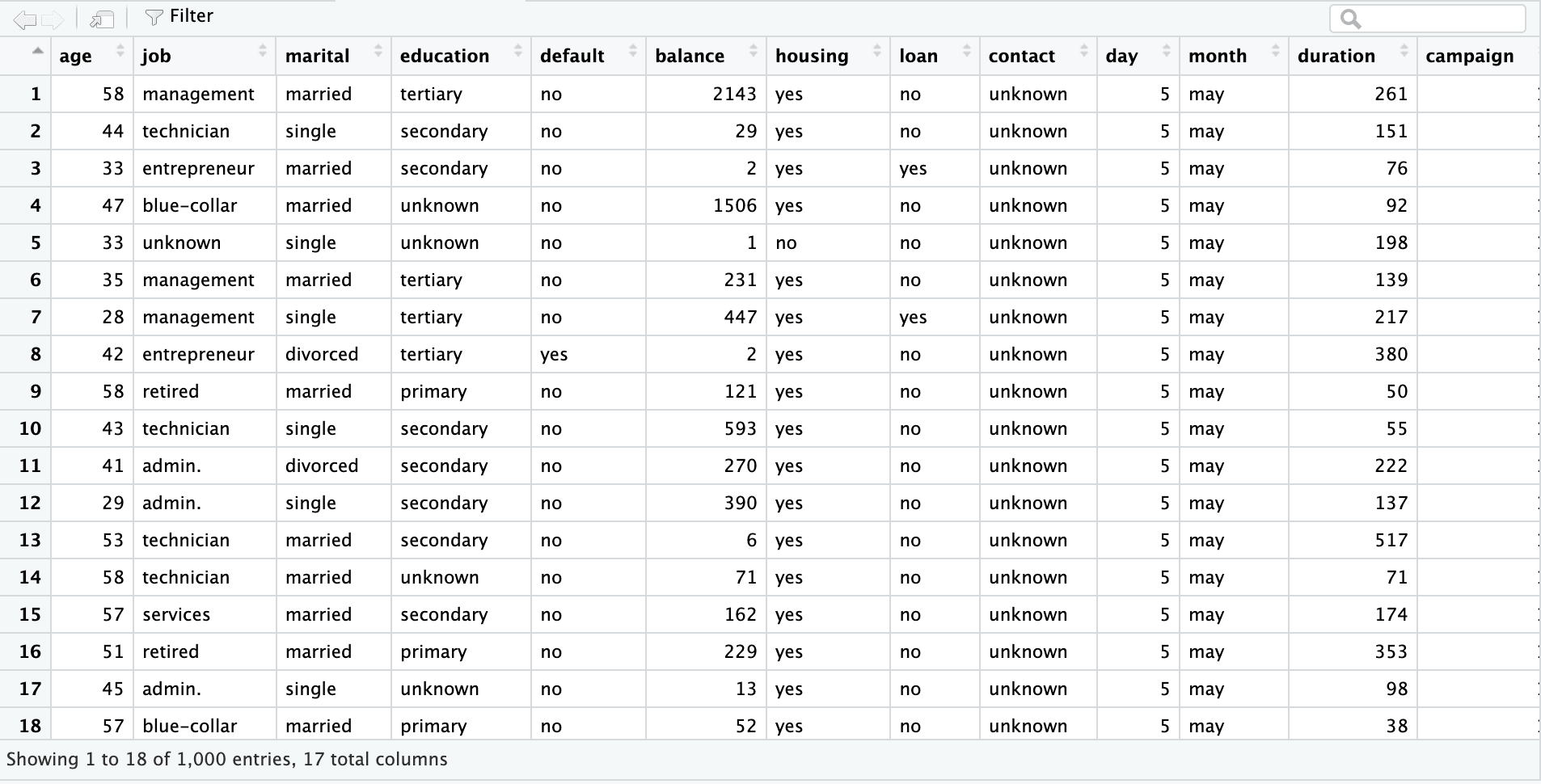
Vous pouvez également combiner les deux arguments pour ignorer quelques lignes et lire un nombre spécifique de lignes de l'ensemble de données restant.
Alors que les arguments "skip" et "n_max" vous permettent de lire un sous-ensemble des lignes des données, vous pouvez lire des cellules spécifiques d'un classeur en définissant l'argument range.
Il existe deux notations pour spécifier le sous-ensemble de l'ensemble de données :
L'idée est de spécifier les coordonnées du rectangle que vous souhaitez découper dans l'ensemble de données.
Notation 1 :
bank_df_range1 <- read_excel("sample.xlsx", sheet = "bank-full", range = "A3:E10")Notation 2 :
bank_df_range2 <- read_excel("sample.xlsx", sheet = "bank-full",
range = "R3C1:R10C5")Range vous permet également d'inclure le nom de la feuille dans l'argument (exemple : wbook!E4:G8).
bank_df_range3 <- read_excel("sample.xlsx", range = "bank-full!R3C1:R10C5")Lisons les données qui n'ont pas de ligne d'en-tête en définissant l'argument col_names comme un vecteur de caractères.
PS : Nous utilisons d'abord l'argument skip pour supprimer la ligne d'en-tête.
columns <- c("ID", "Sepal Length", "Sepal Width", "Petal Length", "Petal Width", "Species Name")
iris3 <- read_excel("sample.xlsx", sheet = 2, skip = 1, col_names = columns)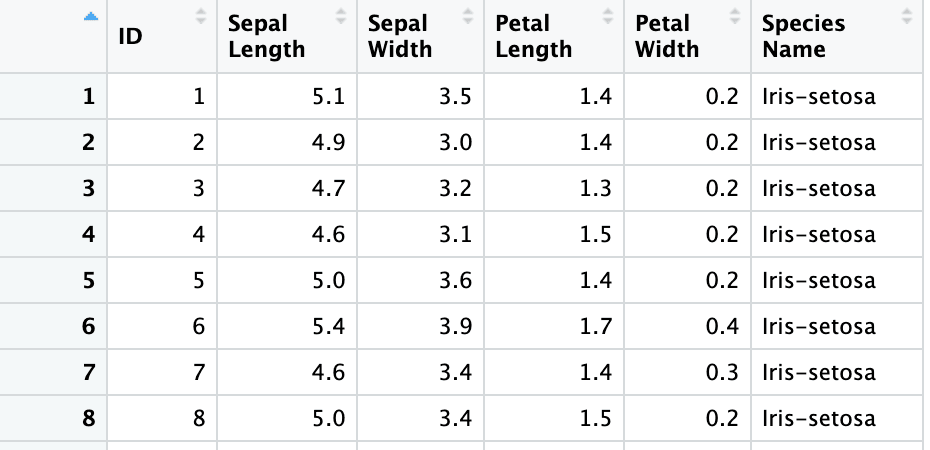
Dans la dernière section, les en-têtes que nous avons spécifiés étaient séparés par des espaces. Vous pouvez transformer les noms d'en-tête en variables syntaxiques R avec l'argument .name_repair = "universal".
iris4 <- read_excel("sample.xlsx", sheet = 2, skip = 1,
col_names = columns, .name_repair = "universal")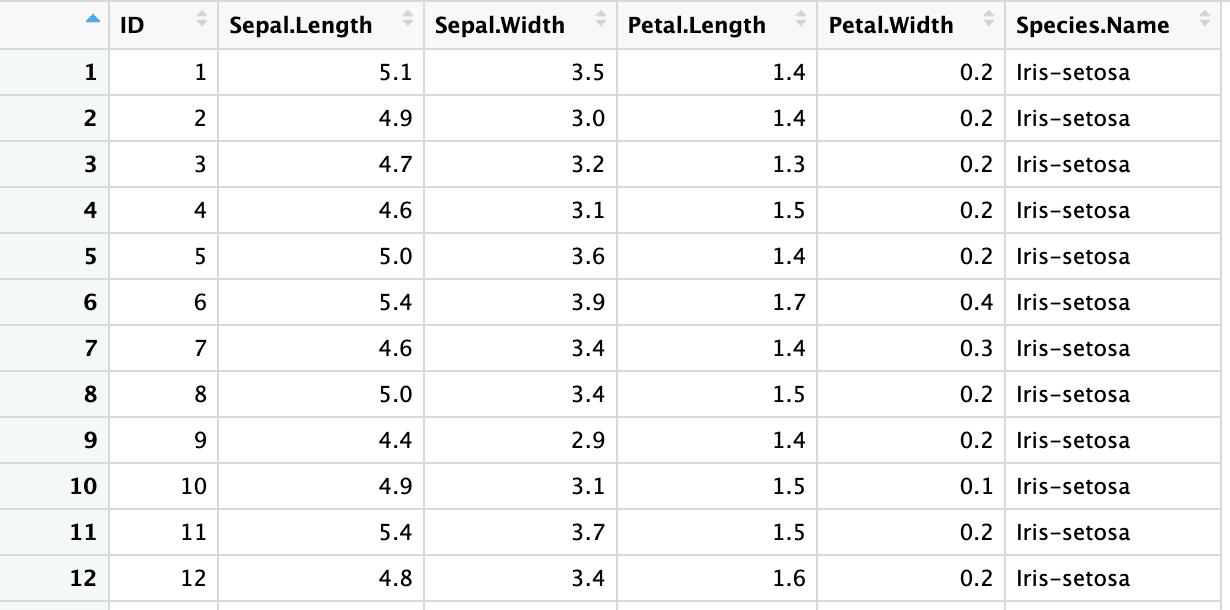
Par défaut, lorsque vous lisez un fichier Excel, R devine le type de données de chaque variable. Observons les types de colonnes de l'ensemble de données de l'iris lu en utilisant les arguments par défaut.
sapply(iris, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" Pour remplacer les suppositions de type de colonne, vous pouvez utiliser l'argument col_types.
iris5 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris5, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 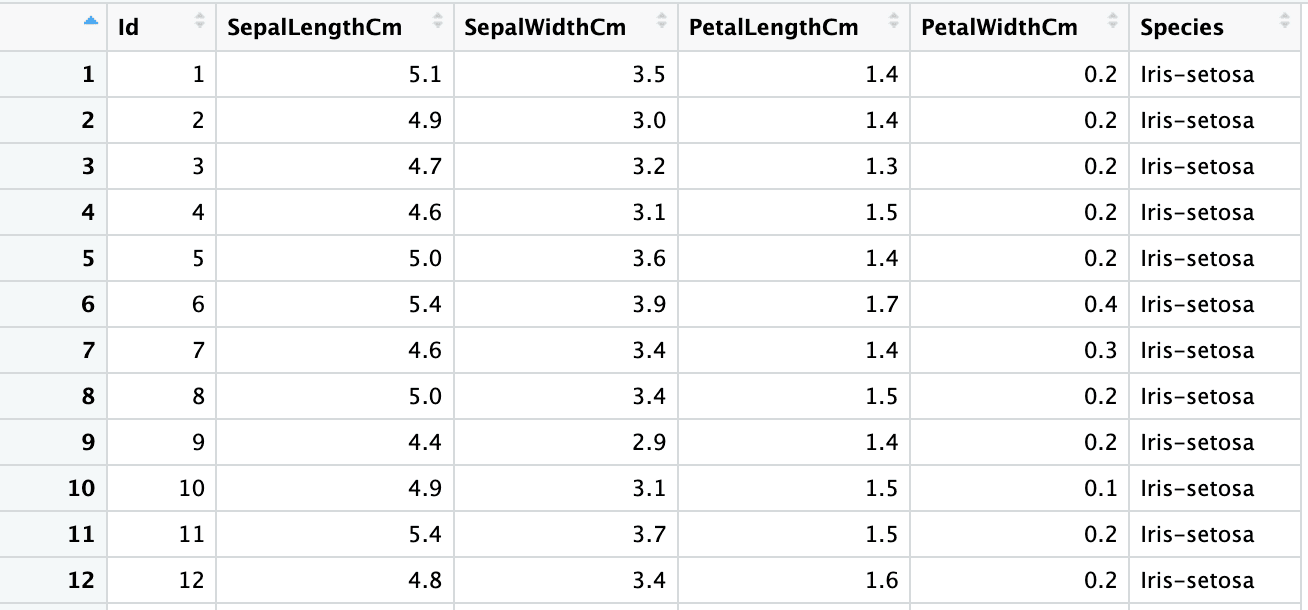
Vous pouvez également laisser R deviner les types de colonnes des variables sélectionnées en spécifiant la valeur col_types comme "guess" pour une colonne particulière.
iris6 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("guess", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris6, class)Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 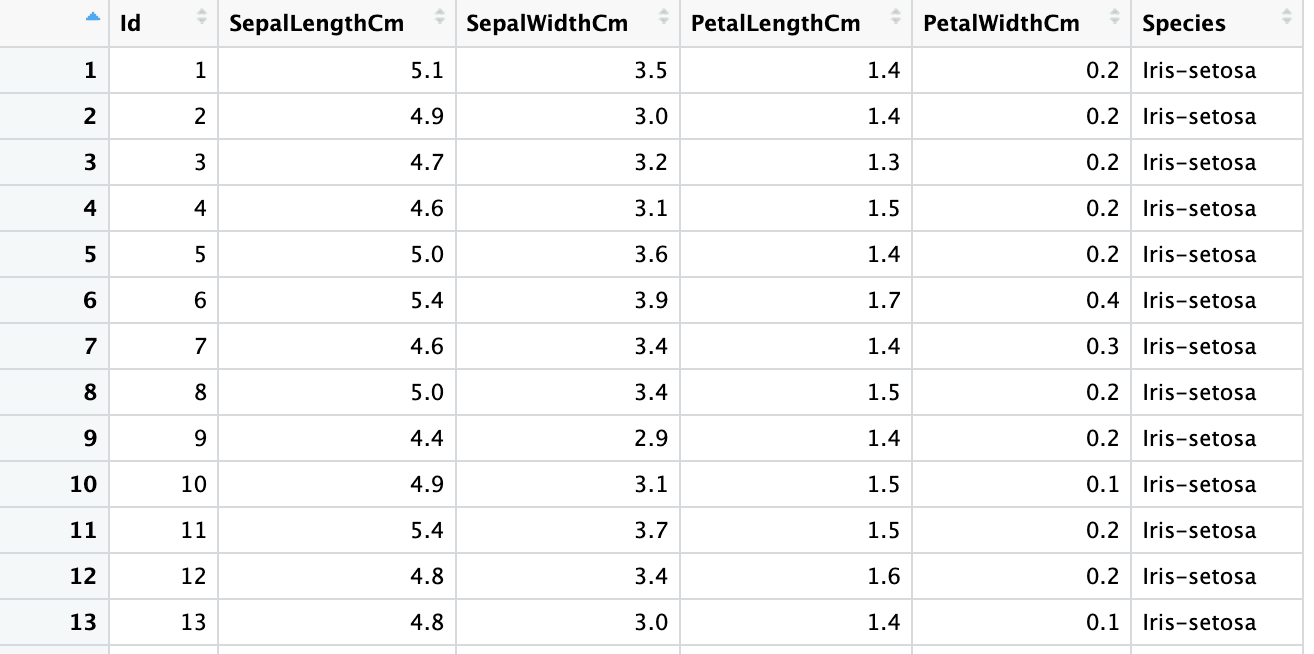
On entend souvent dire que plus il y a de données, mieux c'est. Mais dans de nombreux cas d'utilisation, vous constatez que certaines variables/colonnes ne contiennent aucun signal, ce qui peut être dû à l'une des raisons suivantes.
Vous pouvez ignorer la lecture de certaines colonnes en définissant col_types sur "skip", comme indiqué ci-dessous.
iris7 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "skip", "skip", "numeric", "numeric", "text"))
sapply(iris7, class) au niveau supérieur
au niveau supérieurDans un monde où les données sont générées à un rythme effréné et sous des formes variées, votre langage de programmation doit prendre en charge la lecture de ces types de données. R est l'un de ces langages puissants qui permettent d'atteindre cet objectif. Inscrivez-vous au cours "Introduction à l'importation de données dans R" pour apprendre comment R propose des packages pour importer des ensembles de données variés. Ce cours propose des tutoriels et des quiz pour renforcer votre compréhension de l'importation de données dans R.
En savoir plus sur R et les feuilles de calcul
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach