
Lernpfad
Entwicklung von Anwendungen mit LangChain
9 Std.
Deine KI-App läuft super mit OpenAI, bis die Rechnung für den Monat auf 2.000 Dollar steigt. Du nimmst Anthropic für bessere Schlussfolgerungen und Google für Kosteneinsparungen dazu, und jetzt jonglierst du mit drei verschiedenen APIs, jede mit separater Abrechnung und Überwachung. Wenn OpenAI ausfällt, funktioniert deine App nicht mehr. Wenn du die Ratenbeschränkungen erreichst, sehen deine Nutzer Fehlermeldungen. Du brauchst einen zuverlässigeren Ansatz.
Requesty löst das Problem, indem es ein einheitliches Gateway mit automatischen Failovers und Tools zur Kostenoptimierung bereitstellt. Richte deine Failover-Ketten und Caching-Einstellungen einmalig im Dashboard ein, dann werden diese Richtlinien automatisch bei jeder API-Anfrage angewendet.
Wenn ein Anbieter ausfällt, wechselt Requesty zu deinem Backup-Modell. Wenn du das Caching bei unterstützten Anbietern wie Anthropic aktivierst, sparst du Kosten für wiederholte Abfragen.
In diesem Tutorial zeig ich dir die wichtigsten Funktionen von Requesty. Ich fang mal mit den grundlegenden API-Aufrufen über das einheitliche Gateway und das Antwort-Streaming an. Dann richten wir automatische Failovers ein, damit alles immer läuft, aktivieren Provider-Caching, um bei wiederholten Abfragen Kosten zu sparen, und nutzen das Analyse-Dashboard, um die Ausgaben im Blick zu behalten und deine Nutzung zu optimieren. Diese Funktionen funktionieren genauso, egal ob du deinen ersten KI-Prototyp entwickelst oder Produktionssysteme in großem Maßstab einsetzt.
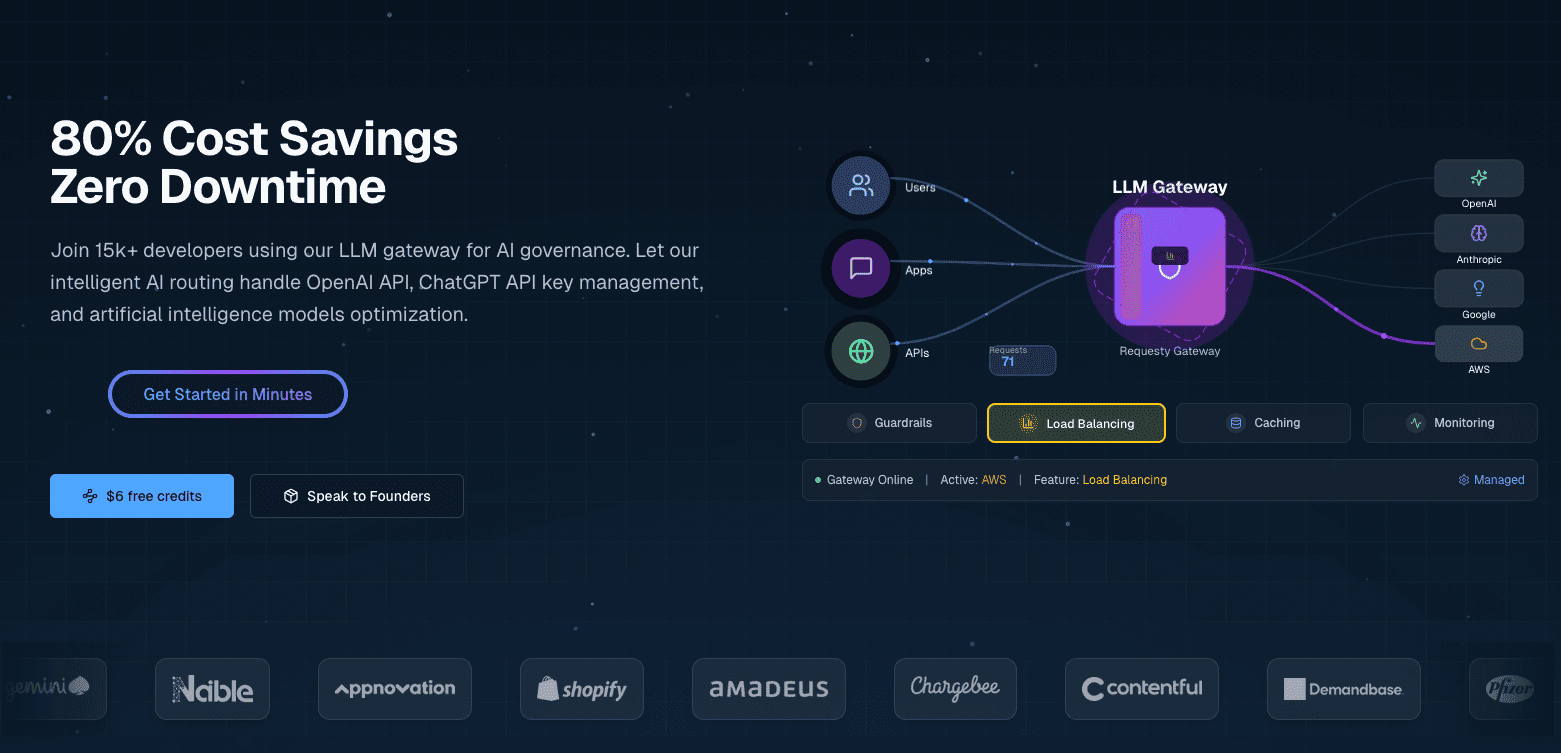
Requesty ist ein einheitliches LLM-Gateway, das dich mit über 300 Modellen von Anbietern wie OpenAI, Anthropic, Google, Meta und AWS über eine einzige API. Es ist ein verwalteter Dienst, du musst also nichts selbst hosten.
Requesty macht Routing-Regeln über ein Dashboard statt über Code oder Konfigurationsdateien. Du richtest Failover-Ketten, Lastenausgleichsgewichte und Caching-Einstellungen über eine Webschnittstelle ein, und diese Richtlinien gelten automatisch für alle API-Anfragen.
Die Konfiguration über das Dashboard ermöglicht Folgendes:
Diese Funktionen werden mit flexiblen Routing-Richtlinien (Fallback-Ketten, Lastenausgleich, Latenzoptimierung), integrierten Sicherheitsvorkehrungen für personenbezogene Daten und Prompt-Injection sowie einer detaillierten Kostenverfolgung kombiniert.
OpenRouter bietet einen ähnlichen einheitlichen Zugriff auf mehrere LLMs, aber mit grundlegendem Routing und ohne Analyse-Dashboard. LiteLLM bietet ähnliche Funktionen, aber man muss es selbst hosten und die Routing-Richtlinien manuell in YAML konfigurieren. Requesty ist dazwischen als verwalteter Dienst mit einer über ein Dashboard gesteuerten Konfiguration angesiedelt.
Wenn du Unternehmenssysteme mit strengen Anforderungen an die Verfügbarkeit betreibst, ist die 99,99 %-SLA wichtig. Wenn deine App nicht läuft, verlierst du Geld. Integrierte Sicherheitsfunktionen wie die Schwärzung personenbezogener Daten und die Erkennung von Prompt-Injection-Angriffen sorgen dafür, dass du die Compliance-Anforderungen erfüllst, ohne diese Systeme selbst aufbauen zu müssen. Teams, die nach der DSGVO arbeiten, können EU-Hosting nutzen, um Daten in den richtigen Gerichtsbarkeiten zu speichern.
Entwicklerteams, die KI-Anwendungen für die Produktion entwickeln, vermeiden eine Bindung an einen bestimmten Anbieter, indem sie den Anbieter durch Konfiguration wechseln, anstatt den Code neu zu schreiben. Dank automatischer Failovers musst du keine eigene zuverlässige Infrastruktur aufbauen.
Projekte mit kleinem Budget profitieren von Caching durch Anbieter und strategischem Lastenausgleich. Anstatt die Optimierungslogik selbst zu schreiben, stellst du die Richtlinien einmalig ein und überlässt Requesty die Kostenreduzierung.
Richte deine Entwicklungsumgebung ein. Das dauert ungefähr 5 Minuten und umfasst die Python-Pakete, den API-Schlüssel und die Grundkonfiguration.
Du musst Python 3.7 oder neuer auf deinem System installiert haben. Überprüfe deine Version:
import sys
print(f"Python {sys.version_info.major}.{sys.version_info.minor}")Installiere die benötigten Pakete mit pip oder uv:
pip install openai python-dotenv
# or with uv: uv add openai python-dotenvDu brauchst das Paket „ openai ”, um mit der API von Requesty zu arbeiten. Das Paket „ python-dotenv “ geht sicher mit Umgebungsvariablen um.
Mach dir ein Requesty-Konto unter app.requesty.ai. Wenn du eingeloggt bist, geh zum Abschnitt „API-Schlüssel“ und erstelle einen neuen Schlüssel. Kopiere diesen Schlüssel für die Authentifizierung. Vergiss nicht, auch ein paar Dollar auf dein Konto zu überweisen.
Speicher deinen API-Schlüssel in einer Datei namens „ .env ” in deinem Projektverzeichnis:
REQUESTY_API_KEY=your_api_key_hereSo bleiben deine Zugangsdaten aus deinem Code raus und du kannst dein Projekt sicherer teilen, ohne Geheimnisse preiszugeben.
Überprüfe, ob alles funktioniert, indem du deine Umgebungsvariablen lädst und sicherstellst, dass der API-Schlüssel zugänglich ist:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
api_key = os.getenv("REQUESTY_API_KEY")
# Check your setup
if api_key:
print("✓ API key loaded")
client = OpenAI(
api_key=api_key,
base_url="https://router.requesty.ai/v1"
)
print("✓ Client configured")
else:
print("✗ API key not found")Wenn du beide Häkchen siehst, kannst du deine erste Anfrage stellen.
Wenn deine Umgebung fertig eingerichtet ist und du deinen API-Schlüssel hast, kannst du deinen ersten API-Aufruf machen. Requesty kann einfach als Ersatz für das OpenAI SDK verwendet werden. Wenn du OpenAI schon mal benutzt hast, wird dir das bekannt vorkommen. Der einzige Unterschied ist, dass du deinen Client auf den Router von Requesty verweisen musst.
So richtest du deinen Client ein:
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("REQUESTY_API_KEY"),
base_url="https://router.requesty.ai/v1"
)Der Parameter „ base_url “ leitet deine Anfragen über Requesty weiter, statt sie direkt an OpenAI zu schicken. Du kannst es mit einem Aufruf an GPT-5 testen:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(response.choices[0].message.content)Ausgabe:
Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.Der Modellparameter hat das Format „ provider/model-name “. Hier geht's zu openai/gpt-5, wo du auf das neueste Modell von OpenAI zugreifen kannst, das nativen Schlussfolgerungsfähigkeiten und verbesserter Leistung bei Programmier- und Mathematikaufgaben. Abgesehen vom Modellformat und der Basis-URL funktioniert das SDK genauso wie das von OpenAI.
Hey, schau mal: Jeder API-Aufruf kostet Geld. Requesty legt Aufschlag von 5 % auf den Grundpreis des Anbieters drauf, sodass GPT-5 über Requesty ein bisschen mehr kostet als wenn man OpenAI direkt anruft. Du bezahlst für die Zuverlässigkeit, die Failover-Funktionen und das einheitliche Dashboard. Behalte deine Nutzung über das Requesty-Dashboard im Auge, um deine Ausgaben zu verfolgen.
Das Antwortobjekt hat nützliche Metadaten, die über den reinen Nachrichteninhalt hinausgehen:
print(f"Model used: {response.model}")
print(f"Total tokens: {response.usage.total_tokens}")
print(f"Response: {response.choices[0].message.content}")Ausgabe:
Model used: gpt-5-2025-08-07
Total tokens: 108
Response: Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.Mit der Token-Anzahl kannst du die Kosten im Blick behalten, weil die Preise normalerweise pro Token berechnet werden.
Wechsel zu einem anderen Anbieter durch Ändern des Modellnamens:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(f"Claude says: {response.choices[0].message.content}")Ausgabe:
Claude says: Recursion is a programming technique where a function calls itself to solve a problem by breaking it down into smaller, similar subproblems until it reaches a base case that stops the repetition.Claude 4 hat erweiterte Kontextfenster und ein besseres Schlussfolgerungsvermögen, was es besonders gut für komplexe Code-Analysen macht. Alle verfügbaren Modelle haben das gleiche Muster für Anbieter/Modellname:
# OpenAI GPT-4o
model = "openai/gpt-4o"
# Anthropic Claude
model = "anthropic/claude-sonnet-4"
Wrap your API calls in error handling before moving to production:
try:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error: {e}")Das fängt Netzwerk-Timeouts, ungültige API-Schlüssel oder nicht verfügbare Modelle ab, ohne dass deine Anwendung abstürzt.
Wenn du eine Anfrage für eine lange Antwort stellst, friert der Bildschirm für ein paar Sekunden ein, während das Modell Tausende von Tokens generiert. Dann kommt alles auf einmal raus.
Die Leute starren auf einen leeren Bildschirm und fragen sich, ob irgendwas passiert.
Streaming löst das Problem, indem es Antwortblöcke sendet, sobald das Modell sie generiert, sodass die Nutzer die Wörter nach und nach sehen, genau wie bei chatGPT. Dadurch fühlen sich Anwendungen reaktionsschnell an, vor allem bei längeren Antworten wie Erklärungen, Codegenerierung oder kreativem Schreiben.
Um Streaming in Requesty zu aktivieren, stell den Parameter „ stream ” auf „ True ” ein:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[
{"role": "user", "content": "Explain recursion like I'm five years old"}
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)Die Antwort kommt Wort für Wort:
Okay! Imagine you have a big basket of toys, and you're trying to find your favorite teddy bear.
But instead of looking through the whole basket all at once, you call your little sibling and say,
"Can you look in here and find my teddy bear? If you see more baskets inside, ask someone else to help in the same way!" …Der Parameter „ stream=True ” ändert die Antwort von einem einzelnen Objekt zu einem Iterator, der Blöcke ausgibt. Jeder Chunk hat einen Text in der Datei „ delta.content “. Der Parameter „ end="" “ verhindert Zeilenumbrüche zwischen den Blöcken, und „ flush=True “ sorgt dafür, dass die Daten sofort angezeigt werden, statt sie zwischenzuspeichern.
Produktionsanwendungen brauchen oft sowohl das Streaming-Erlebnis als auch den kompletten Text für Protokollierung oder Analyse. Eine Hilfsfunktion macht beides:
def stream_and_capture(model, messages):
"""Stream response to user while capturing complete text."""
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
complete_text = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
text = chunk.choices[0].delta.content
complete_text += text
print(text, end="", flush=True)
print() # Final newline
return complete_text
# Use it
full_response = stream_and_capture(
"anthropic/claude-sonnet-4",
[{"role": "user", "content": "Write a haiku about debugging code at 3 AM"}]
)
print(f"\nCaptured {len(full_response)} characters")Ausgabe:
Blinking cursor waits
Coffee cold, eyes burning red,
One missing bracket.
Captured 74 charactersStreaming ist nicht immer die beste Wahl. Für kurze Antworten oder strukturierte Ausgaben wie JSON-Daten sind normale Anfragen einfacher und schneller, weil der Aufwand für die Verarbeitung von Chunks die Vorteile für die Benutzererfahrung überwiegt.
Streams können wegen Netzwerkproblemen, Ratenbeschränkungen oder Ausfällen des Anbieters mitten drin hängen bleiben. Pack deinen Streaming-Code in eine einfache Fehlerbehandlung:
try:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "Explain quantum entanglement in one sentence"}],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
except Exception as e:
print(f"\nError: {e}")Wenn ein Stream nicht klappt, fängst du den Fehler ab und kannst es manuell nochmal versuchen oder auf ein anderes Modell ausweichen.
Produktionsanlagen können sich keine Ausfallzeiten leisten. Wenn OpenAI während der Stoßzeiten an seine Ratenlimits stößt, kriegen deine Nutzer Fehlermeldungen zu sehen. Wenn Anthropic mal nicht läuft, funktioniert dein Chatbot nicht mehr. Diese Probleme sind einfach unvermeidbar, wenn man sich auf externe Anbieter verlässt.
Requesty macht das mit automatischen Failovers. Wenn dein Hauptmodell ausfällt, wechselt Requesty in weniger als 50 Millisekunden zu deinem Backup.
Ein Failover-System merkt, wenn dein Hauptmodell nicht verfügbar ist, und leitet deine Anfrage an ein Backup-Modell weiter, ohne dass du deinen Code ändern musst. Die Erkennung passiert automatisch, wenn ein Anbieter einen Fehler meldet, die Ratenbegrenzung erreicht oder eine Zeitüberschreitung auftritt. Requesty leitet deine Anfrage dann an das nächste Modell in deiner konfigurierten Kette weiter.
Requesty sorgt dafür, dass das System zu 99,99 % immer läuft. Das sind maximal etwa 4 Minuten Ausfallzeit pro Monat, verglichen mit möglicherweise mehreren Stunden, wenn du einen einzigen Anbieter ohne Backup-Optionen nutzt.
Drei Arten von Richtlinien bestimmen, wie Failovers funktionieren:
Die meisten Teams fangen mit Fallback Chain an, weil es vorhersehbar ist. Du kriegst dein Lieblingsmodell, wenn es verfügbar ist, und automatische Backups, wenn es nicht verfügbar ist.
Das Einrichten von Failovers machst du im Requesty-Dashboard. Geh zum Abschnitt „API-Schlüssel“ und klick dann auf „Richtlinien“. Mach eine neue Fallback-Chain-Richtlinie. Du siehst ein Formular, in dem du Modelle nach deiner Präferenz hinzufügen kannst.
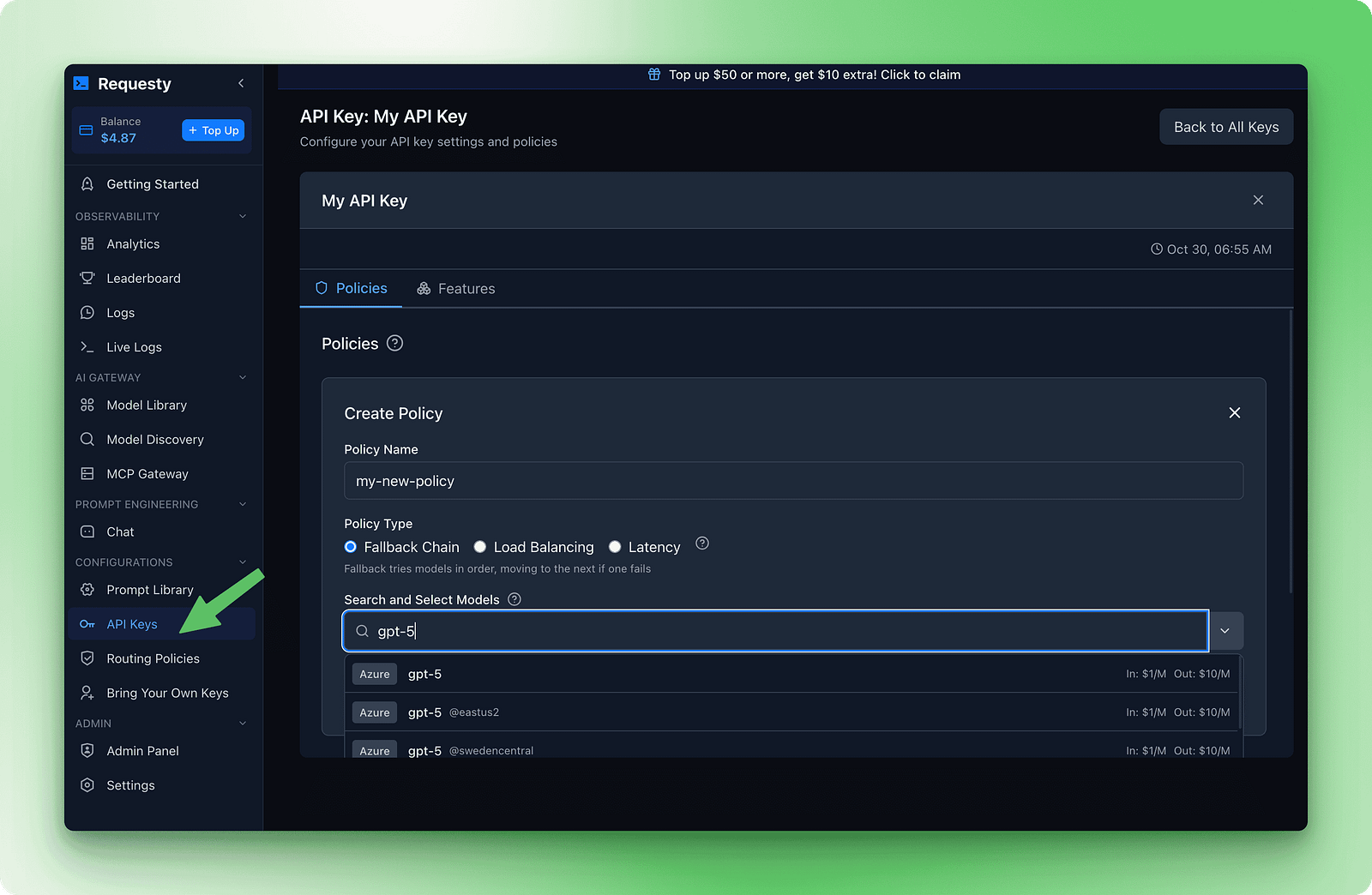
Hier ist ein Beispiel für eine Kette, die Qualität, Kosten und Verfügbarkeit gut zusammenbringt:
1. openai/gpt-5
2. anthropic/claude-sonnet-4
3. deepseek/deepseek-r1:kostenlos
Diese Kette probiert zuerst GPT-5 aus, weil es schnell und leistungsfähig ist. Wenn das nicht klappt, probiert es Claude Sonnet 4 für ähnliche Qualität. Wenn beide Premium-Modelle nicht funktionieren, greift man auf DeepSeek R1 zurück , das kostenlos und fast immer verfügbar ist.
Sobald du diese Richtlinie speicherst und mit deinem API-Schlüssel verbindest, klappt das Failover ohne Codeänderungen:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Explain how DNS works"}]
)
print(f"Model used: {response.model}")
print(response.choices[0].message.content)Das Feld „ response.model “ zeigt, welches Modell deine Anfrage tatsächlich bearbeitet hat. Das Dashboard zeigt dir, wie oft ein Failover passiert, damit du sehen kannst, wann Backup-Modelle benutzt werden.
Ausgabe:
Model used: gpt-5-2025-08-07
DNS (Domain Name System) translates human-readable website addresses like "google.com" into IP addresses (like 142.250.80.46) that computers use to locate and connect to servers. This translation happens through a hierarchical system of DNS servers that cache and distribute this information globally for fast lookups.Wenn alle Modelle in deiner Kette versagen, gibt Requesty nach jedem Versuch einen Fehler zurück. Du bekommst eine Standard-API-Fehlermeldung, die dir sagt, dass keine Modelle verfügbar waren. Das kommt zwar selten vor, kann aber bei großflächigen Ausfällen passieren.
Ein paar Tipps helfen beim Aufbau von Failover-Ketten:
openai/gpt-5 und openai/gpt-4o in deine Kette einfügst, könnten beide während eines Ausfalls von OpenAI nicht funktionieren. Kombiniere Anbieter für mehr Zuverlässigkeit.Während LiteLLM manuelle Eingaben braucht YAML für Failovers braucht, macht Requesty alles über Dashboard-Richtlinien.
Die gleiche Abfrage immer wieder auszuführen, kostet Geld. Wenn du einen Chatbot für die Dokumentation hast, der immer wieder die gleichen Fragen beantwortet, oder einen Programmierassistenten, der bei jeder Anfrage die gleiche Systemaufforderung zeigt, zahlst du jedes Mal den vollen Preis. Caching löst dieses Problem, indem es Teile deiner Eingabeaufforderungen wiederverwendet, die sich nicht ändern.
Einige Anbieter unterstützen das Prompt-Caching von Haus aus. Mit Anthropic und Gemini kannst du unveränderte Teile deiner Eingabeaufforderungen zwischenspeichern und für verschiedene Anfragen wiederverwenden. Das spart Kosten, wenn du immer wieder die gleichen Muster hast, weil du nur für die neuen Teile den vollen Preis bezahlst.
Wenn du eine Anfrage mit einer langen Systemaufforderung sendest, speichert der Anbieter diese Aufforderung in seinem Cache. Bei der nächsten Anfrage mit derselben Systemaufforderung holen sie die Daten aus dem Cache, anstatt sie nochmal zu verarbeiten. Du zahlst eine reduzierte Gebühr für das Auslesen des Caches statt der vollen Bearbeitungskosten.
Gib „ auto_cache “ im Feld „ extra_body “ mit einem verschachtelten „ requesty “-Objekt an:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": "You are a helpful documentation assistant. You answer questions about Python's asyncio library based on the official docs. Be concise and include code examples."},
{"role": "user", "content": "How do I create a basic event loop?"}
],
extra_body={
"requesty": {
"auto_cache": True
}
}
)
print(response.choices[0].message.content)Die Systemaufforderung bleibt bei allen Anfragen gleich. Mit „ auto_cache: True “ speichert Anthropic die Daten nach der ersten Anfrage im Cache. Bei den nächsten Anfragen wird die zwischengespeicherte Eingabeaufforderung wiederverwendet und nur die Frage des Benutzers bearbeitet.
Der Caching-Parameter kann drei Werte haben:
True: Caching für diese Anfrage aktivierenFalse: Caching komplett umgehen, auch wenn der Anbieter es unterstützt (praktisch für sensible Daten oder zeitkritische Inhalte, bei denen du sichergehen willst, dass sie immer aktuell sind)Nur Anthropic und Gemini unterstützen im Moment das Prompt-Caching. Wenn du „ auto_cache ” mit anderen Anbietern benutzt, wird es ohne Fehler stillschweigend auf die normale Verarbeitung zurückfallen.
Caching funktioniert am besten, wenn du lange Systemaufforderungen hast, die bei allen Anfragen gleich bleiben. Dokumentations-Bots und Programmierhelfer sind gute Beispiele dafür. FAQ-Bots und Kundensupport-Systeme profitieren auch, wenn Leute ähnliche Fragen stellen. Wissensdatenbanken mit großen Referenzdokumenten, die sich nicht ändern, sind ein weiterer starker Anwendungsfall.
Überspringe das Caching, wenn jede Anfrage neue Daten braucht. Wetter-Apps und Aktienkurse gehören dazu. Personalisierte Empfehlungen mit für jeden Nutzer individuellen Aufforderungen bringen keinen Vorteil. Echtzeitüberwachung und Live-Feeds ändern sich zu oft, um von Caching zu profitieren.
Dieses Beispiel zeigt einen Chatbot für die Dokumentation einer Python-Bibliothek. Die Systemaufforderung enthält die komplette API-Referenz. Die Leute stellen verschiedene Fragen, aber die Systemaufforderung bleibt immer gleich:
# Simulate a long API documentation string
long_api_documentation = """
Python AsyncIO Library Reference:
- asyncio.run(): Execute async functions
- asyncio.create_task(): Schedule coroutines
- asyncio.gather(): Run multiple tasks
... (this continues for 5,000+ tokens)
"""
# First request - cache miss, pays full price
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "How do I authenticate?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 5,247 (full processing)Die zweite Anfrage mit derselben Systemaufforderung landet im Cache:
# Second request - cache hit, reduced cost
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "What are rate limits?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 312 (only new content processed, 5,000 tokens served from cache)Cache-Lese-Gebühren sparen 50 bis 90 % der Kosten für zwischengespeicherte Teile.
Schau dir deine Cache-Trefferquote im Requesty-Dashboard im Bereich „Analytics“ an. Wenn der Wert unter 40 % liegt, ändern sich deine Eingabeaufforderungen zu oft, um vom Caching zu profitieren.
Such nach Mustern, bei denen du Systemaufforderungen standardisieren oder variable Inhalte stattdessen in Benutzermeldungen auspacken kannst. Das Dashboard zeigt dir auch deine Gesamteinsparungen durch Caching, aufgeschlüsselt nach Anbieter und Modell, sodass du genau sehen kannst, wo sich deine Optimierungsbemühungen auszahlen.
Dein Dashboard ist im Moment fast leer. Du hast ein paar Testanfragen gemacht und vielleicht 0,10 $ ausgegeben. Es gibt noch nicht viel zu analysieren. Hier erfährst du, was du jetzt einrichten solltest und was später nützlich sein wird, wenn du in die Produktion gehst.
Ausgabengrenzen festzulegen ist auch beim Testen eine gute Idee. Geh in deinem Dashboard zum Abschnitt „API-Schlüssel“, klick auf deinen Schlüssel und such nach „API-Limits“. Leg ein monatliches Budget von 5 Dollar fest. Requesty schickt dir eine Benachrichtigung, wenn du 50 %, 75 % und 90 % von diesem Limit erreicht hast. Für mehr Sicherheit kannst du ein Nutzungslimit festlegen, das alle Anfragen stoppt, sobald du das Limit erreicht hast. Das verhindert Unfälle beim Testen und schützt dich in der Produktion.
Wenn du mehr nutzt, verfolgt Requesty fünf wichtige Kennzahlen:
Nach ein paar Wochen mit echtem Datenverkehr zeigen diese Kennzahlen Muster, die dir bei der Optimierung helfen. Nutze das Dashboard, um teure Workflows zu finden und auf günstigere Modelle umzusteigen, wiederholte Abfragen zu erkennen und Caching mit „ auto_cache: true “ zu aktivieren sowie Failover-Muster zu überwachen, um deine Fallback-Ketten anzupassen. Ein Chatbot für die Dokumentation hat die Kosten von 500 auf 200 Dollar pro Monat gesenkt, indem er Caching aktiviert hat, nachdem das Dashboard gezeigt hat, dass 70 % der Anfragen gleich waren.
Überwachung, Skalierung und bewährte Verfahren für den Betrieb werden wichtig, wenn du vom Prototyp zur Produktion übergehst. LLMOps kümmert sich um den ganzen Lebenszyklus der Verwaltung großer Sprachmodelle in Produktionsumgebungen ab, einschließlich Strategien zur Kostenoptimierung, die die integrierten Analysen von Requesty ergänzen.
Du hast gelernt, wie Requesty als einheitliches Gateway zu über 300 KI-Modellen über eine einzige API funktioniert. Die Einrichtung ist einfach: Installiere das OpenAI SDK, richte es auf die Basis-URL von Requesty aus, und schon bist du verbunden. Von da an sorgt Streaming für schnelle Antworten, Failover-Ketten halten alles am Laufen, auch wenn mal ein Anbieter ausfällt, und Caching kann deine Kosten halbieren, wenn du wiederholte Anfragen bearbeitest.
Die Entscheidung zwischen Requesty, LiteLLM und OpenRouter hängt davon ab, was dir wichtig ist. Wenn du eine verwaltete Infrastruktur mit automatischen Failovers und integrierten Analysen brauchst, übernimmt Requesty die Komplexität für dich. Teams, die sich mit Selbsthosting auskennen und eine detaillierte Kontrolle wünschen, können den Open-Source-Ansatz von LiteLLM. OpenRouter bietet einen einfachen einheitlichen Zugang , wenn du mit der manuellen Modellauswahl klarkommst und keine fortgeschrittenen Routing-Richtlinien brauchst.
Fang damit an, eine Fallback-Kette mit drei Modellen von verschiedenen Anbietern einzurichten, und schalte dann das Caching für Anfragen mit wiederholten Systemaufforderungen frei. Für anspruchsvollere Anwendungsfälle schau dir mal die Argumentationsfähigkeiten von Claude Sonnet 4 oder die LLMOps-Verfahren für Produktionsbereitstellungen an.
Die besten DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal