
programa
Desarrollar aplicaciones con LangChain
9 h
Tu aplicación de IA funciona muy bien con OpenAI hasta que las facturas alcanzan los 2000 dólares al mes. Añades Anthropic para mejorar el razonamiento y Google para ahorrar costes, y ahora estás haciendo malabarismos con tres API diferentes, cada una con su propia facturación y supervisión. Cuando OpenAI deja de funcionar, tu aplicación deja de funcionar. Cuando alcanzas los límites de frecuencia, tus usuarios ven errores. Necesitas un enfoque más fiable.
Requesty resuelve este problema proporcionando una pasarela unificada con conmutaciones automáticas por error y herramientas de optimización de costes. Configura tus cadenas de conmutación por error y tus preferencias de almacenamiento en caché una vez en el panel de control, y todas las solicitudes de API utilizarán esas políticas automáticamente.
Cuando un proveedor deja de funcionar, Requesty cambia a tu modelo de respaldo. Al habilitar el almacenamiento en caché en proveedores compatibles como Anthropic, reduces los costes de las consultas repetitivas.
En este tutorial, voy a explicar las funciones principales de Requesty. Comenzaré con llamadas API básicas a través de la puerta de enlace unificada y la transmisión de respuestas. A continuación, configuraremos conmutaciones automáticas por error para garantizar el tiempo de actividad, habilitaremos el almacenamiento en caché del proveedor para reducir los costes cuando se repitan las consultas y utilizaremos el panel de análisis para supervisar el gasto y optimizar tu uso. Estas funciones funcionan igual tanto si estás creando tu primer prototipo de IA como si estás implementando sistemas de producción a gran escala.
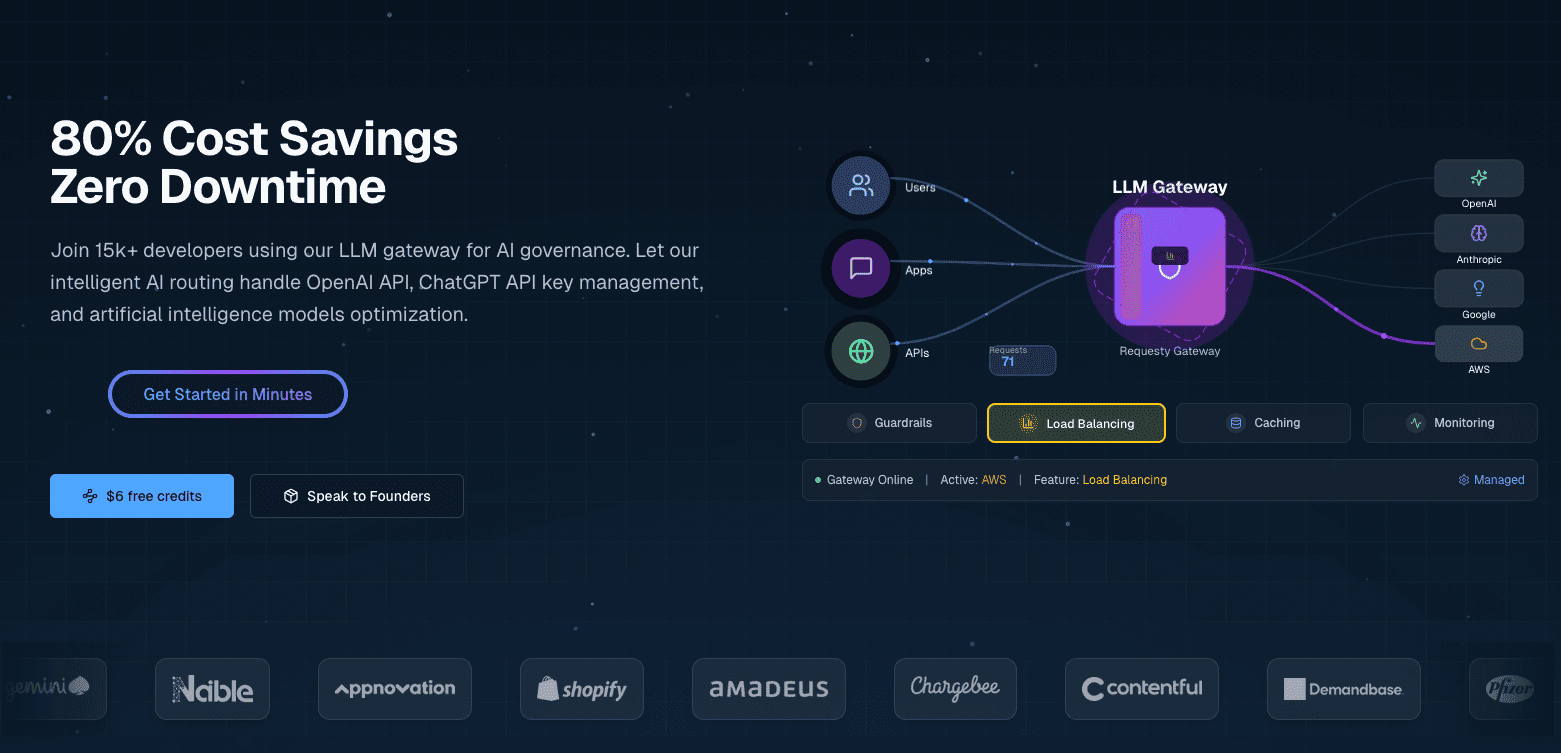
Requesty es una pasarela LLM unificada que te conecta con más de 300 modelos de proveedores como OpenAI, Anthropic, Google, Meta y AWS a través de una única API. Es un servicio gestionado, por lo que no necesitas alojar nada tú mismo.
Requesty configura las políticas de enrutamiento a través de un panel de control en lugar de código o archivos de configuración. Configuras cadenas de conmutación por error, pesos de equilibrio de carga y preferencias de almacenamiento en caché a través de una interfaz web, y estas políticas se aplican automáticamente a todas las solicitudes de API.
La configuración basada en el panel de control permite:
Estas capacidades se combinan con políticas de enrutamiento flexibles (cadenas de respaldo, equilibrio de carga, optimización de la latencia), medidas de seguridad integradas para la información de identificación personal (PII) y la inyección rápida, y un seguimiento detallado de los costes.
OpenRouter proporciona un acceso unificado similar a múltiples LLM, pero con enrutamiento básico y sin panel de control analítico. LiteLLM ofrece características similares, pero requiere autoalojamiento y configuración manual de YAML para las políticas de enrutamiento. Requesty se sitúa entre ambos como un servicio gestionado con configuración basada en paneles de control.
Si utilizas sistemas empresariales con requisitos estrictos de tiempo de actividad, el SLA del 99,99 % es importante. Cuando tu aplicación deja de funcionar, estás perdiendo dinero. Las funciones de seguridad integradas, como la supresión de información de identificación personal y la detección inmediata de inyecciones, te permiten cumplir los requisitos normativos sin necesidad de crear estos sistemas por tu cuenta. Los equipos que operan bajo el RGPD pueden habilitar el alojamiento en la UE para mantener los datos en las jurisdicciones adecuadas.
Los equipos de desarrollo que crean aplicaciones de IA para producción evitan la dependencia de un único proveedor cambiando de proveedor mediante la configuración, en lugar de reescribir el código. Las conmutaciones automáticas por error significan que no es necesario crear una infraestructura de fiabilidad personalizada.
Los proyectos con presupuestos ajustados se benefician del almacenamiento en caché de los proveedores y del equilibrio de carga estratégico. En lugar de escribir tú mismo la lógica de optimización, configuras las políticas una sola vez y dejas que Requesty se encargue de reducir los costes.
Configura tu entorno de desarrollo. Esto lleva unos 5 minutos y abarca los paquetes de Python, la clave API y la configuración básica.
Necesitarás tener instalado Python 3.7 o una versión más reciente en tu sistema. Verifica tu versión:
import sys
print(f"Python {sys.version_info.major}.{sys.version_info.minor}")Instala los paquetes necesarios utilizando pip o uv:
pip install openai python-dotenv
# or with uv: uv add openai python-dotenvNecesitas el paquete openai para interactuar con la API de Requesty. El paquete python-dotenv gestiona las variables de entorno de forma segura.
Crea una cuenta en Requesty en app.requesty.ai. Una vez que hayas iniciado sesión, ve a la sección Claves API y genera una nueva clave. Copia esta clave para la autenticación. No olvides añadir también algunos dólares a tu cuenta.
Almacena tu clave API en un archivo .env en el directorio de tu proyecto:
REQUESTY_API_KEY=your_api_key_hereEsto mantiene tus credenciales fuera de tu código y hace que sea más seguro compartir tu proyecto sin revelar secretos.
Comprueba que todo funciona cargando tus variables de entorno y verificando que la clave API es accesible:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
api_key = os.getenv("REQUESTY_API_KEY")
# Check your setup
if api_key:
print("✓ API key loaded")
client = OpenAI(
api_key=api_key,
base_url="https://router.requesty.ai/v1"
)
print("✓ Client configured")
else:
print("✗ API key not found")Si ves ambas marcas de verificación, estás listo para realizar tu primera solicitud.
Una vez configurado tu entorno y con la clave API lista, puedes realizar tu primera llamada API. Requesty funciona como un sustituto directo del SDK de OpenAI. Si ya has utilizado OpenAI anteriormente, esto te resultará familiar. La única diferencia es dirigir a tu cliente al enrutador de Requesty.
A continuación te explicamos cómo configurar tu cliente:
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("REQUESTY_API_KEY"),
base_url="https://router.requesty.ai/v1"
)El parámetro base_url es el que dirige tus solicitudes a través de Requesty en lugar de directamente a OpenAI. Puedes probarlo con una llamada a GPT-5:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(response.choices[0].message.content)Salida:
Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.El parámetro del modelo utiliza el formato provider/model-name. Aquí está openai/gpt-5, que accede al último modelo de OpenAI con capacidades de razonamiento nativas y un rendimiento mejorado en tareas de codificación y matemáticas. A excepción del formato del modelo y la URL base, el SDK funciona de manera idéntica al de OpenAI.
Nota: Cada llamada a la API tiene un costo. Requesty añade un recargo del 5 % al precio base del proveedor, por lo que GPT-5 cuesta un poco más a través de Requesty que llamando directamente a OpenAI. Estás pagando por la fiabilidad, las capacidades de conmutación por error y el panel de control unificado. Controla tu uso a través del panel de control de Requesty para realizar un seguimiento de los gastos.
El objeto de respuesta contiene metadatos útiles que van más allá del contenido del mensaje:
print(f"Model used: {response.model}")
print(f"Total tokens: {response.usage.total_tokens}")
print(f"Response: {response.choices[0].message.content}")Salida:
Model used: gpt-5-2025-08-07
Total tokens: 108
Response: Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.El recuento de tokens te ayuda a realizar un seguimiento de los costes, ya que el precio suele ser por token.
Cambia a un proveedor diferente modificando el nombre del modelo:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(f"Claude says: {response.choices[0].message.content}")Salida:
Claude says: Recursion is a programming technique where a function calls itself to solve a problem by breaking it down into smaller, similar subproblems until it reaches a base case that stops the repetition.Claude 4 ofrece ventanas de contexto ampliadas y un razonamiento mejorado que lo hacen especialmente eficaz para el análisis de código complejo. Todos los modelos disponibles siguen el mismo patrón de proveedor/nombre de modelo:
# OpenAI GPT-4o
model = "openai/gpt-4o"
# Anthropic Claude
model = "anthropic/claude-sonnet-4"
Wrap your API calls in error handling before moving to production:
try:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error: {e}")Esto detecta tiempos de espera de red, claves API no válidas o modelos no disponibles sin que se bloquee la aplicación.
Cuando solicitas una respuesta larga, la pantalla se congela durante varios segundos mientras el modelo genera miles de tokens. Entonces todo se derrumba de golpe.
Los usuarios miran fijamente una pantalla en blanco, preguntándose si está pasando algo.
El streaming resuelve este problema enviando fragmentos de respuesta a medida que el modelo los genera, de modo que los usuarios ven aparecer las palabras progresivamente, al igual que en chatGPT. Esto hace que las aplicaciones parezcan más receptivas, especialmente en el caso de respuestas más largas, como explicaciones, generación de código o escritura creativa.
Para habilitar la transmisión en Requesty, configura el parámetro stream en True:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[
{"role": "user", "content": "Explain recursion like I'm five years old"}
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)La respuesta fluye palabra por palabra:
Okay! Imagine you have a big basket of toys, and you're trying to find your favorite teddy bear.
But instead of looking through the whole basket all at once, you call your little sibling and say,
"Can you look in here and find my teddy bear? If you see more baskets inside, ask someone else to help in the same way!" …El parámetro ` stream=True ` cambia la respuesta de un único objeto a un iterador que genera fragmentos. Cada fragmento contiene una parte del texto en delta.content. El parámetro end="" evita los saltos de línea entre fragmentos, y flush=True fuerza la visualización inmediata en lugar del almacenamiento en búfer.
Las aplicaciones de producción a menudo necesitan tanto la experiencia de transmisión como el texto completo para el registro o el análisis. Una función auxiliar se encarga de ambas cosas:
def stream_and_capture(model, messages):
"""Stream response to user while capturing complete text."""
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
complete_text = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
text = chunk.choices[0].delta.content
complete_text += text
print(text, end="", flush=True)
print() # Final newline
return complete_text
# Use it
full_response = stream_and_capture(
"anthropic/claude-sonnet-4",
[{"role": "user", "content": "Write a haiku about debugging code at 3 AM"}]
)
print(f"\nCaptured {len(full_response)} characters")Salida:
Blinking cursor waits
Coffee cold, eyes burning red,
One missing bracket.
Captured 74 charactersEl streaming no siempre es la opción adecuada. Para respuestas breves o resultados estructurados, como datos JSON, las solicitudes normales son más sencillas y rápidas, ya que la sobrecarga que supone el procesamiento de fragmentos supera las ventajas que ofrece para la experiencia del usuario.
Las transmisiones pueden fallar a mitad de camino debido a problemas de red, límites de velocidad o interrupciones del proveedor. Envuelve tu código de streaming en un manejo básico de errores:
try:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "Explain quantum entanglement in one sentence"}],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
except Exception as e:
print(f"\nError: {e}")Si una secuencia falla, detectas el error y puedes volver a intentarlo manualmente o recurrir a un modelo diferente.
Las aplicaciones de producción no pueden permitirse tiempos de inactividad. Cuando OpenAI alcanza los límites de frecuencia durante las horas punta, tus usuarios ven errores. Cuando Anthropic sufre una interrupción del servicio, tu chatbot deja de funcionar. Estos fallos son inevitables cuando dependes de proveedores externos.
Requesty gestiona esto mediante conmutaciones automáticas por error. Cuando tu modelo principal falla, Requesty cambia a tu modelo de respaldo en menos de 50 milisegundos.
Un sistema de conmutación por error detecta cuándo tu modelo principal no está disponible y redirige tu solicitud a un modelo de respaldo sin necesidad de realizar cambios en tu código. La detección se produce automáticamente cuando un proveedor devuelve un error, alcanza los límites de frecuencia o agota el tiempo de espera. A continuación, Requesty envía tu solicitud al siguiente modelo de la cadena configurada.
Requesty garantiza un tiempo de actividad del 99,99 % a través de este sistema. Eso supone un máximo de 4 minutos de inactividad al mes, en comparación con las horas que podrías perder si utilizas un único proveedor sin opciones de copia de seguridad.
Hay tres tipos de políticas que controlan el funcionamiento de las conmutaciones por error:
La mayoría de los equipos comienzan con Fallback Chain porque es predecible. Obtienes tu modelo preferido cuando está disponible y copias de seguridad automáticas cuando no lo está.
La configuración de las conmutaciones por error se realiza en el panel de control de Requesty. Ve a la sección Claves API y haz clic en Políticas. Crea una nueva política de cadena de respaldo. Verás un formulario en el que podrás añadir modelos por orden de preferencia.
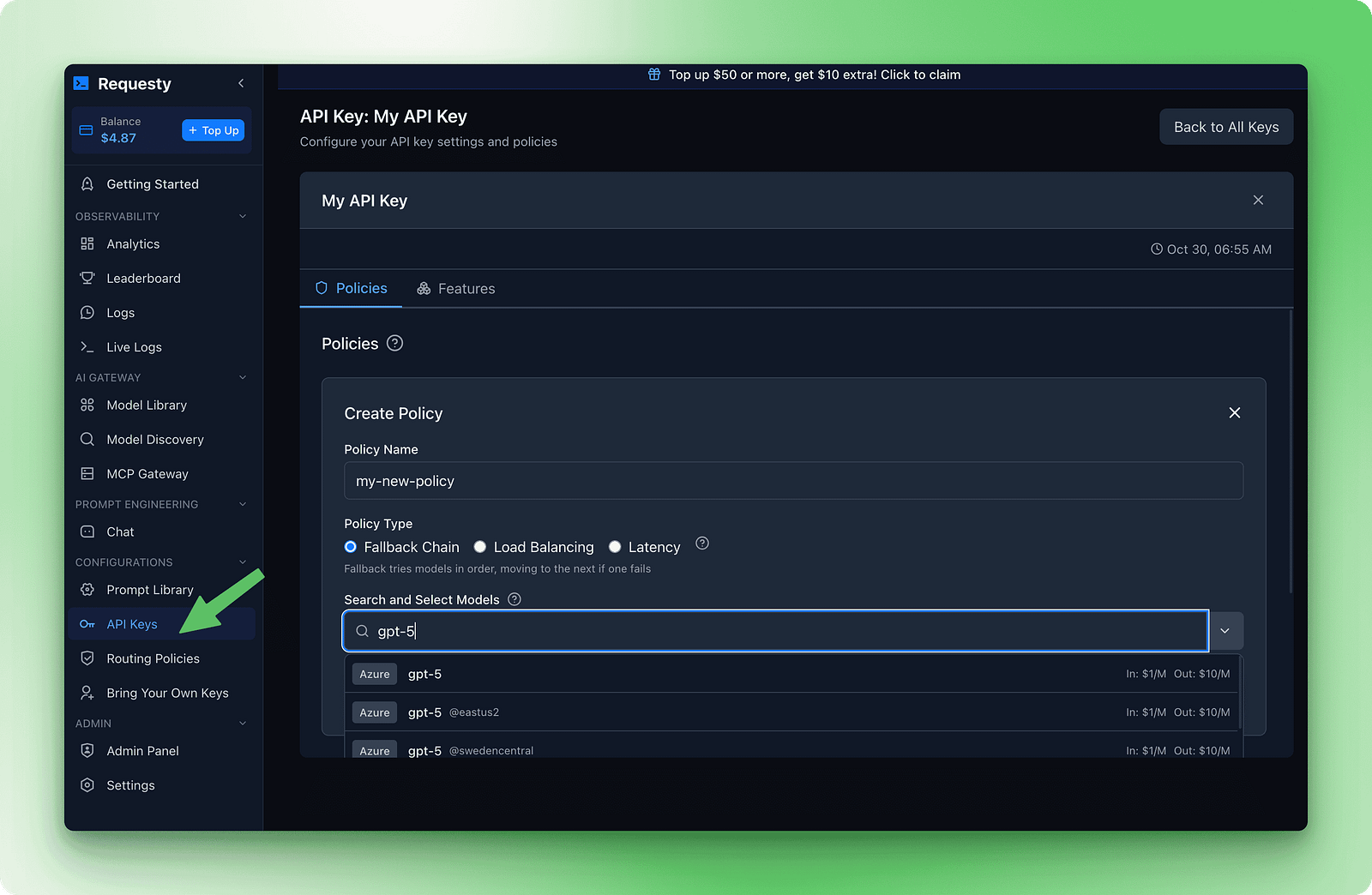
Aquí tienes un ejemplo de cadena que equilibra calidad, coste y disponibilidad:
1. openai/gpt-5
2. anthropic/claude-sonnet-4
3. deepseek/deepseek-r1:gratis
Esta cadena prueba primero GPT-5 porque es rápido y eficaz. Si eso falla, prueba Claude Sonnet 4 para obtener una calidad similar. Si los dos modelos premium no funcionan, se recurre a DeepSeek R1, que es gratuito y casi siempre está disponible.
Una vez que guardes esta política y la adjuntes a tu clave API, las conmutaciones por error se producirán sin cambios en el código:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Explain how DNS works"}]
)
print(f"Model used: {response.model}")
print(response.choices[0].message.content)El campo « response.model » muestra qué modelo ha gestionado realmente tu solicitud. El panel de control realiza un seguimiento de la frecuencia de conmutación por error para que puedas ver cuándo se están utilizando los modelos de respaldo.
Salida:
Model used: gpt-5-2025-08-07
DNS (Domain Name System) translates human-readable website addresses like "google.com" into IP addresses (like 142.250.80.46) that computers use to locate and connect to servers. This translation happens through a hierarchical system of DNS servers that cache and distribute this information globally for fast lookups.Si todos los modelos de tu cadena fallan, Requesty devuelve un error después de probar cada uno de ellos. Recibirás una respuesta de error API estándar indicando que no hay modelos disponibles. Esto es poco frecuente, pero posible durante cortes generalizados.
Hay algunas pautas que resultan útiles a la hora de crear cadenas de conmutación por error:
openai/gpt-5 y openai/gpt-4o en tu cadena, es posible que ambos dejen de funcionar durante una interrupción del servicio de OpenAI. Combina proveedores para obtener una mayor fiabilidad.Mientras que LiteLLM requiere configuración YAML para las conmutaciones por error, Requesty lo gestiona todo a través de políticas del panel de control.
Ejecutar la misma consulta una y otra vez cuesta dinero. Si tienes un chatbot de documentación que responde repetidamente a las mismas preguntas, o un asistente de codificación con el mismo mensaje del sistema para cada solicitud, estás pagando el precio completo cada vez. El almacenamiento en caché soluciona este problema reutilizando las partes de las indicaciones que no cambian.
Algunos proveedores admiten el almacenamiento en caché inmediato de forma nativa. Anthropic y Gemini te permiten almacenar en caché las partes que no han cambiado de tus indicaciones y reutilizarlas en diferentes solicitudes. Esto reduce los costes cuando tienes patrones repetidos, ya que solo pagas el precio completo por las piezas nuevas.
Cuando envías una solicitud con un mensaje del sistema largo, el proveedor almacena ese mensaje en su caché. En la siguiente solicitud con el mismo mensaje del sistema, lo recuperan de la caché en lugar de procesarlo de nuevo. Pagas una tarifa reducida por lectura de caché en lugar de los costes totales de procesamiento.
Pasa auto_cache en el campo extra_body con un objeto requesty anidado:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": "You are a helpful documentation assistant. You answer questions about Python's asyncio library based on the official docs. Be concise and include code examples."},
{"role": "user", "content": "How do I create a basic event loop?"}
],
extra_body={
"requesty": {
"auto_cache": True
}
}
)
print(response.choices[0].message.content)El mensaje del sistema permanece igual en todas las solicitudes. Con auto_cache: True, Anthropic lo almacena en caché después de la primera solicitud. Las solicitudes posteriores reutilizan la pregunta almacenada en caché y solo procesan la pregunta del usuario.
El parámetro de almacenamiento en caché acepta tres valores:
True: Habilitar el almacenamiento en caché para esta solicitudFalse: Omite explícitamente el almacenamiento en caché incluso si el proveedor lo admite (útil para datos confidenciales o contenido sensible al tiempo en el que deseas garantizar un procesamiento actualizado).Solo Anthropic y Gemini admiten actualmente el almacenamiento en caché de indicaciones. El uso de auto_cache con otros proveedores volverá silenciosamente al procesamiento normal sin errores.
El almacenamiento en caché funciona mejor cuando tienes indicaciones del sistema largas que permanecen iguales en todas las solicitudes. Los bots de documentación y los asistentes de codificación son buenos ejemplos. Los bots de preguntas frecuentes y los sistemas de atención al cliente también se benefician cuando los usuarios hacen preguntas similares. Las bases de conocimiento con documentos de referencia extensos que no cambian son otro caso de uso muy interesante.
Omite el almacenamiento en caché cuando cada solicitud requiera datos actualizados. Las aplicaciones meteorológicas y los precios de las acciones entran en esta categoría. Las recomendaciones personalizadas con indicaciones únicas para cada usuario no serán beneficiosas. La supervisión en tiempo real y las transmisiones en directo cambian con demasiada frecuencia como para beneficiarse del almacenamiento en caché.
Este ejemplo muestra un chatbot de documentación para una biblioteca de Python. El sistema muestra toda la referencia de la API. Los usuarios hacen diferentes preguntas, pero el mensaje del sistema sigue siendo el mismo:
# Simulate a long API documentation string
long_api_documentation = """
Python AsyncIO Library Reference:
- asyncio.run(): Execute async functions
- asyncio.create_task(): Schedule coroutines
- asyncio.gather(): Run multiple tasks
... (this continues for 5,000+ tokens)
"""
# First request - cache miss, pays full price
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "How do I authenticate?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 5,247 (full processing)La segunda solicitud con el mismo mensaje del sistema accede a la caché:
# Second request - cache hit, reduced cost
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "What are rate limits?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 312 (only new content processed, 5,000 tokens served from cache)Las tarifas de lectura de caché reducen los gastos entre un 50 % y un 90 % para las partes almacenadas en caché.
Comprueba tu tasa de aciertos de caché en el panel de control de Requesty, en la sección «Analytics» (Análisis). Si es inferior al 40 %, tus indicaciones cambian con demasiada frecuencia como para beneficiarse del almacenamiento en caché.
Busca patrones en los que puedas estandarizar las indicaciones del sistema o extraer contenido variable en mensajes de usuario. El panel de control también muestra el ahorro total obtenido gracias al almacenamiento en caché, desglosado por proveedor y modelo, para que puedas ver exactamente dónde están dando sus frutos tus esfuerzos de optimización.
Tu panel de control está casi vacío en este momento. Has realizado algunas solicitudes de prueba y has gastado unos 0,10 $. Aún no hay mucho que analizar. En esta sección se muestra lo que debes configurar ahora y lo que te resultará útil más adelante, cuando pases a la fase de producción.
Establecer límites de gasto es una buena práctica, incluso para realizar pruebas. Ve a la sección Claves API en tu panel de control, haz clic en tu clave y busca «Límites API». Establece un límite presupuestario mensual de 5 dólares. Requesty te avisará cuando alcances el 50 %, el 75 % y el 90 % de ese límite. Para una protección más estricta, establece un límite de uso que detenga todas las solicitudes cuando alcances el límite. Esto evita accidentes durante las pruebas y te protege durante la producción.
A medida que aumenta tu uso, Requesty programa cinco métricas clave:
Tras unas semanas de tráfico de producción, estas métricas muestran patrones que te ayudan a optimizar. Utiliza el panel de control para encontrar flujos de trabajo costosos y cambiar a modelos más económicos, detectar consultas repetidas y habilitar el almacenamiento en caché con auto_cache: true, y supervisar los patrones de conmutación por error para ajustar tus cadenas de respaldo. Un chatbot de documentación redujo los costes de 500 a 200 dólares al mes al habilitar el almacenamiento en caché después de que el panel de control mostrara que el 70 % de las consultas eran idénticas.
El monitoreo, el escalado y las mejores prácticas operativas se vuelven fundamentales a medida que pasas del prototipo a la producción. LLMOps cubre todo el ciclo de vida de la gestión de grandes modelos lingüísticos en entornos de producción, incluidas estrategias de optimización de costes que complementan los análisis integrados de Requesty.
Has aprendido cómo funciona Requesty como puerta de enlace unificada a más de 300 modelos de IA a través de una única API. La configuración es sencilla: instala el SDK de OpenAI, dirígelo a la URL base de Requesty y ya estarás conectado. A partir de ahí, el streaming ofrece respuestas progresivas, las cadenas de conmutación por error garantizan el tiempo de actividad incluso cuando fallan los proveedores, y el almacenamiento en caché puede reducir tus costes a la mitad cuando gestionas solicitudes repetidas.
La elección entre Requesty, LiteLLM y OpenRouter depende de tus prioridades. Si necesitas una infraestructura gestionada con conmutaciones automáticas por error y análisis integrados, Requesty se encarga de la complejidad por ti. Los equipos que se sientan cómodos con el autoalojamiento y deseen un control granular pueden utilizar el enfoque de código abierto de LiteLLM. OpenRouter proporciona acceso unificado básico cuando te sientes cómodo con la selección manual de modelos y no necesitas políticas de enrutamiento avanzadas.
Comienza por configurar una cadena de respaldo con tres modelos de diferentes proveedores y, a continuación, habilita el almacenamiento en caché de las solicitudes con avisos repetidos del sistema. Para casos de uso más sofisticados, explora las capacidades de razonamiento de Claude Sonnet 4 o aplica las prácticas de LLMOps para implementaciones de producción.
Los mejores cursos de DataCamp
programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Ryan Ong
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita

