
Programa
Desenvolvimento de aplicativos com LangChain
9 h
Seu aplicativo de IA funciona super bem com o OpenAI até que as contas cheguem a US$ 2.000 por mês. Você adiciona o Anthropic para melhorar o raciocínio e o Google para economizar custos, e agora está lidando com três APIs diferentes, cada uma com faturamento e monitoramento separados. Quando o OpenAI fica fora do ar, seu aplicativo para de funcionar. Quando você atinge os limites de taxa, seus usuários veem erros. Você precisa de uma abordagem mais confiável.
O Requesty resolve isso oferecendo um gateway unificado com failovers automáticos e ferramentas de otimização de custos. Configure suas cadeias de failover e preferências de cache uma vez no painel e, então, todas as solicitações de API usarão essas políticas automaticamente.
Quando um provedor fica fora do ar, o Requesty muda para o seu modelo de backup. Quando você ativa o cache em provedores compatíveis, como o Anthropic, você reduz os custos com consultas repetitivas.
Neste tutorial, vou falar sobre as principais funcionalidades do Requesty. Vou começar com chamadas API básicas através do gateway unificado e streaming de resposta. Depois, vamos configurar failovers automáticos pra garantir o tempo de atividade, ativar o cache do provedor pra reduzir custos quando as consultas se repetirem e usar o painel de análise pra monitorar os gastos e otimizar o uso. Esses recursos funcionam da mesma forma, seja você criando seu primeiro protótipo de IA ou implementando sistemas de produção em grande escala.
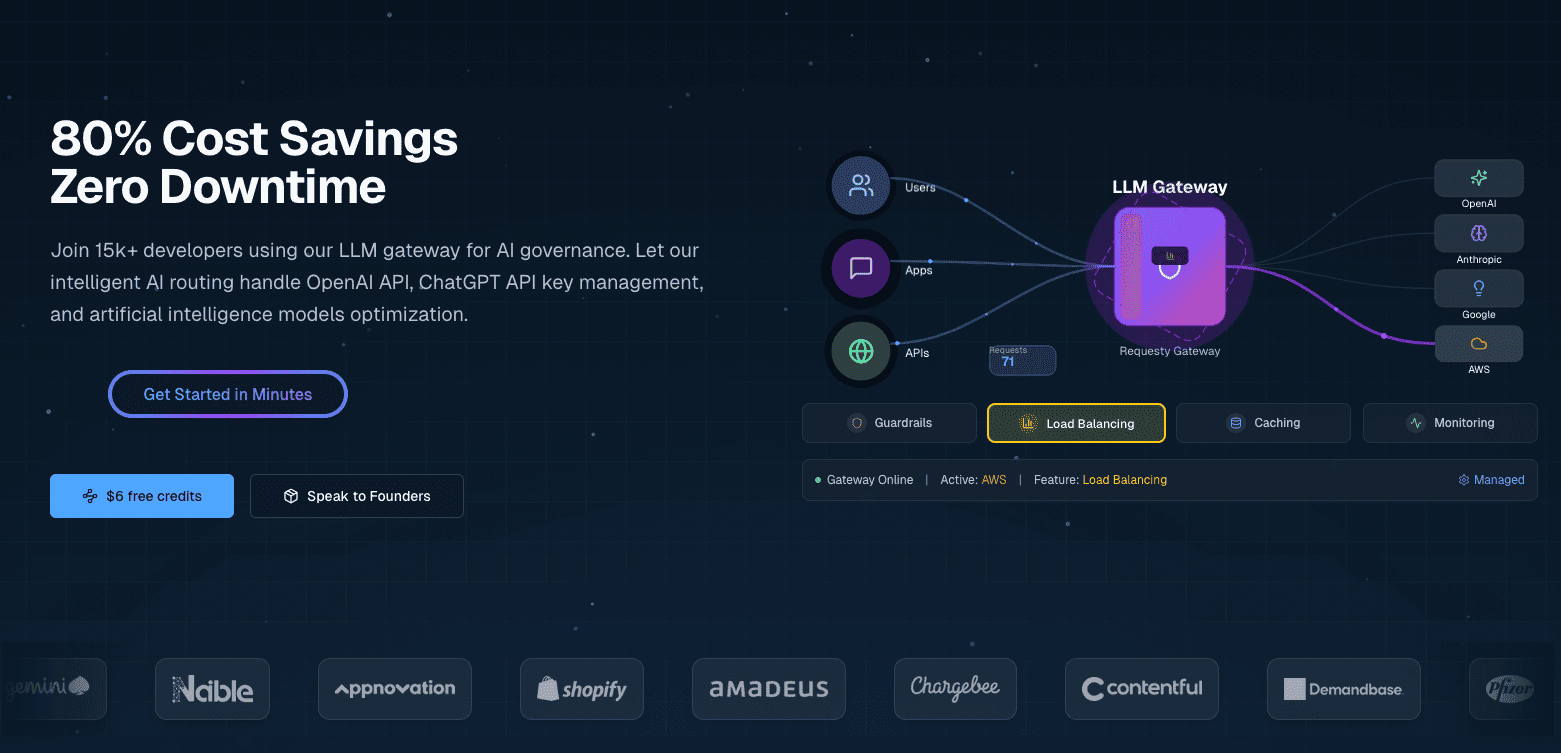
O Requesty é um gateway LLM unificado que te conecta a mais de 300 modelos de fornecedores como OpenAI, Anthropic, Google, Meta e AWS por meio de uma única API. É um serviço gerenciado, então você não precisa hospedar nada por conta própria.
O Requesty configura políticas de roteamento por meio de um painel, em vez de código ou arquivos de configuração. Você configura cadeias de failover, pesos de balanceamento de carga e preferências de cache por meio de uma interface web, e essas políticas se aplicam automaticamente a todas as solicitações de API.
A configuração baseada no painel permite:
Esses recursos se juntam a políticas de roteamento flexíveis (cadeias de fallback, balanceamento de carga, otimização de latência), proteções de segurança integradas para PII e injeção imediata, além de acompanhamento detalhado dos custos.
O OpenRouter oferece acesso unificado parecido a vários LLMs, mas com roteamento básico e sem painel de análise. O LiteLLM oferece recursos parecidos, mas precisa de hospedagem própria e configuração manual do YAML para as políticas de roteamento. O Requesty fica entre esses dois, como um serviço gerenciado com configuração baseada em painel.
Se você está usando sistemas empresariais com requisitos rigorosos de tempo de atividade, o SLA de 99,99% é importante. Quando seu aplicativo fica fora do ar, você está perdendo dinheiro. Recursos de segurança integrados, como supressão de informações pessoais identificáveis e detecção rápida de injeção, lidam com os requisitos de conformidade sem que você precise criar esses sistemas por conta própria. As equipes que seguem o GDPR podem usar hospedagem na UE para manter os dados nas jurisdições certas.
As equipes de desenvolvimento que criam aplicativos de IA de produção evitam ficar presas a um único fornecedor, trocando de provedor por meio da configuração, em vez de reescrever o código. Os failovers automáticos significam que você não precisa criar uma infraestrutura de confiabilidade personalizada.
Projetos que se preocupam com o orçamento se beneficiam do cache do provedor e do balanceamento estratégico de carga. Em vez de escrever você mesmo a lógica de otimização, você configura as políticas uma vez e deixa o Requesty cuidar da redução de custos.
Configure seu ambiente de desenvolvimento. Isso leva cerca de 5 minutos e abrange os pacotes Python, a chave API e a configuração básica.
Você vai precisar do Python 3.7 ou mais recente instalado no seu sistema. Confira a sua versão:
import sys
print(f"Python {sys.version_info.major}.{sys.version_info.minor}")Instale os pacotes necessários usando pip ou uv:
pip install openai python-dotenv
# or with uv: uv add openai python-dotenvVocê precisa do pacote openai para interagir com a API do Requesty. O pacote python-dotenv lida com variáveis de ambiente de forma segura.
Crie uma conta Requesty em app.requesty.ai. Depois de fazer login, vá até a seção Chaves API e crie uma nova chave. Copie essa chave para autenticação. Não esqueça de colocar um pouco de dinheiro na sua conta também.
Guarde sua chave API em um arquivo .env no diretório do seu projeto:
REQUESTY_API_KEY=your_api_key_hereIsso mantém suas credenciais fora do seu código e torna mais seguro compartilhar seu projeto sem expor segredos.
Verifique se tudo está funcionando carregando suas variáveis de ambiente e conferindo se a chave da API está acessível:
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
api_key = os.getenv("REQUESTY_API_KEY")
# Check your setup
if api_key:
print("✓ API key loaded")
client = OpenAI(
api_key=api_key,
base_url="https://router.requesty.ai/v1"
)
print("✓ Client configured")
else:
print("✗ API key not found")Se você vir as duas marcas de seleção, tá pronto pra fazer sua primeira solicitação.
Com seu ambiente configurado e a chave da API pronta, você pode fazer sua primeira chamada à API. O Requesty funciona como um substituto direto para o SDK da OpenAI. Se você já usou o OpenAI antes, isso vai parecer familiar. A única diferença é direcionar seu cliente para o roteador da Requesty.
Veja como configurar seu cliente:
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("REQUESTY_API_KEY"),
base_url="https://router.requesty.ai/v1"
)Esse parâmetro base_url é o que encaminha suas solicitações através do Requesty, em vez de diretamente para o OpenAI. Você pode testar isso com uma chamada para o GPT-5:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(response.choices[0].message.content)Resultado:
Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.O parâmetro do modelo usa o formato provider/model-name. Aqui está openai/gpt-5, que dá acesso ao modelo mais recente da OpenAI com capacidades de raciocínio nativas e desempenho aprimorado em tarefas de codificação e matemática. Além do formato do modelo e da URL base, o SDK funciona igualzinho ao da OpenAI.
Nota: Cada chamada à API custa dinheiro. A Requesty adiciona uma marcação de 5% ao preço base do provedor, então o GPT-5 sai um pouco mais caro pelo Requesty do que se você ligasse direto para a OpenAI. Você está pagando pela confiabilidade, recursos de failover e painel unificado. Monitore seu uso pelo painel do Requesty para programar os gastos.
O objeto de resposta tem metadados úteis além do conteúdo da mensagem:
print(f"Model used: {response.model}")
print(f"Total tokens: {response.usage.total_tokens}")
print(f"Response: {response.choices[0].message.content}")Resultado:
Model used: gpt-5-2025-08-07
Total tokens: 108
Response: Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.A contagem de tokens ajuda você a acompanhar os custos, já que o preço é normalmente por token.
Mude para um provedor diferente alterando o nome do modelo:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(f"Claude says: {response.choices[0].message.content}")Resultado:
Claude says: Recursion is a programming technique where a function calls itself to solve a problem by breaking it down into smaller, similar subproblems until it reaches a base case that stops the repetition.O Claude 4 oferece janelas de contexto ampliadas e raciocínio aprimorado, o que o torna especialmente bom para análises complexas de código. Todos os modelos disponíveis seguem o mesmo padrão de nome do provedor/modelo:
# OpenAI GPT-4o
model = "openai/gpt-4o"
# Anthropic Claude
model = "anthropic/claude-sonnet-4"
Wrap your API calls in error handling before moving to production:
try:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error: {e}")Isso detecta tempos limite de rede, chaves API inválidas ou modelos indisponíveis sem travar seu aplicativo.
Quando você faz uma solicitação para uma resposta longa, a tela congela por alguns segundos enquanto o modelo gera milhares de tokens. Então tudo cai de uma vez.
Os usuários ficam olhando para uma tela em branco, se perguntando se algo está acontecendo.
O streaming resolve isso enviando pedaços de resposta conforme o modelo os gera, então os usuários veem as palavras aparecerem aos poucos, igual no chatGPT. Isso faz com que os aplicativos pareçam mais responsivos, principalmente para respostas mais longas, como explicações, geração de código ou escrita criativa.
Para habilitar o streaming no Requesty, defina o parâmetro stream como True:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[
{"role": "user", "content": "Explain recursion like I'm five years old"}
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)A resposta vem palavra por palavra:
Okay! Imagine you have a big basket of toys, and you're trying to find your favorite teddy bear.
But instead of looking through the whole basket all at once, you call your little sibling and say,
"Can you look in here and find my teddy bear? If you see more baskets inside, ask someone else to help in the same way!" …O parâmetro ` stream=True ` muda a resposta de um único objeto para um iterador que gera blocos. Cada bloco tem um trecho de texto em delta.content. O parâmetro ` end="" ` evita que haja novas linhas entre os blocos, e ` flush=True ` força a exibição imediata em vez do armazenamento em buffer.
As aplicações de produção muitas vezes precisam tanto da experiência de streaming quanto do texto completo para registro ou análise. Uma função auxiliar cuida das duas coisas:
def stream_and_capture(model, messages):
"""Stream response to user while capturing complete text."""
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
complete_text = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
text = chunk.choices[0].delta.content
complete_text += text
print(text, end="", flush=True)
print() # Final newline
return complete_text
# Use it
full_response = stream_and_capture(
"anthropic/claude-sonnet-4",
[{"role": "user", "content": "Write a haiku about debugging code at 3 AM"}]
)
print(f"\nCaptured {len(full_response)} characters")Resultado:
Blinking cursor waits
Coffee cold, eyes burning red,
One missing bracket.
Captured 74 charactersStreaming nem sempre é a melhor opção. Para respostas curtas ou resultados estruturados, como dados JSON, as solicitações regulares são mais simples e rápidas, já que o custo de processar blocos supera a vantagem da experiência do usuário.
As transmissões podem falhar no meio do caminho por causa de problemas de rede, limites de taxa ou falhas do provedor. Envolva seu código de streaming em um tratamento básico de erros:
try:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "Explain quantum entanglement in one sentence"}],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
except Exception as e:
print(f"\nError: {e}")Se um fluxo falhar, você detecta o erro e pode tentar novamente manualmente ou recorrer a um modelo diferente.
As aplicações de produção não podem se dar ao luxo de ficar paradas. Quando a OpenAI atinge os limites de taxa durante os horários de pico, seus usuários veem erros. Quando o Anthropic fica fora do ar, seu chatbot para de funcionar. Essas falhas são inevitáveis quando você depende de fornecedores externos.
O Requesty cuida disso com failovers automáticos. Quando seu modelo principal falha, o Requesty muda para o seu backup em menos de 50 milissegundos.
Um sistema de failover detecta quando seu modelo principal não está disponível e redireciona sua solicitação para um modelo de backup sem precisar mexer no seu código. A detecção rola automaticamente quando um provedor dá erro, atinge os limites de taxa ou fica fora do tempo. O Requesty então encaminha sua solicitação para o próximo modelo na sua cadeia configurada.
A Requesty garante 99,99% de tempo de atividade por meio desse sistema. Isso dá um máximo de 4 minutos de inatividade por mês, comparado com potencialmente horas se você estiver usando um único provedor sem opções de backup.
Três tipos de políticas controlam como as failovers funcionam:
A maioria das equipes começa com a cadeia de fallback porque é previsível. Você recebe o modelo que preferir quando estiver disponível e backups automáticos quando não estiver.
A configuração dos failovers é feita no painel do Requesty. Vá até a seção Chaves de API e clique em Políticas. Crie uma nova política de cadeia de fallback. Você vai ver um formulário onde pode adicionar modelos na ordem de preferência.
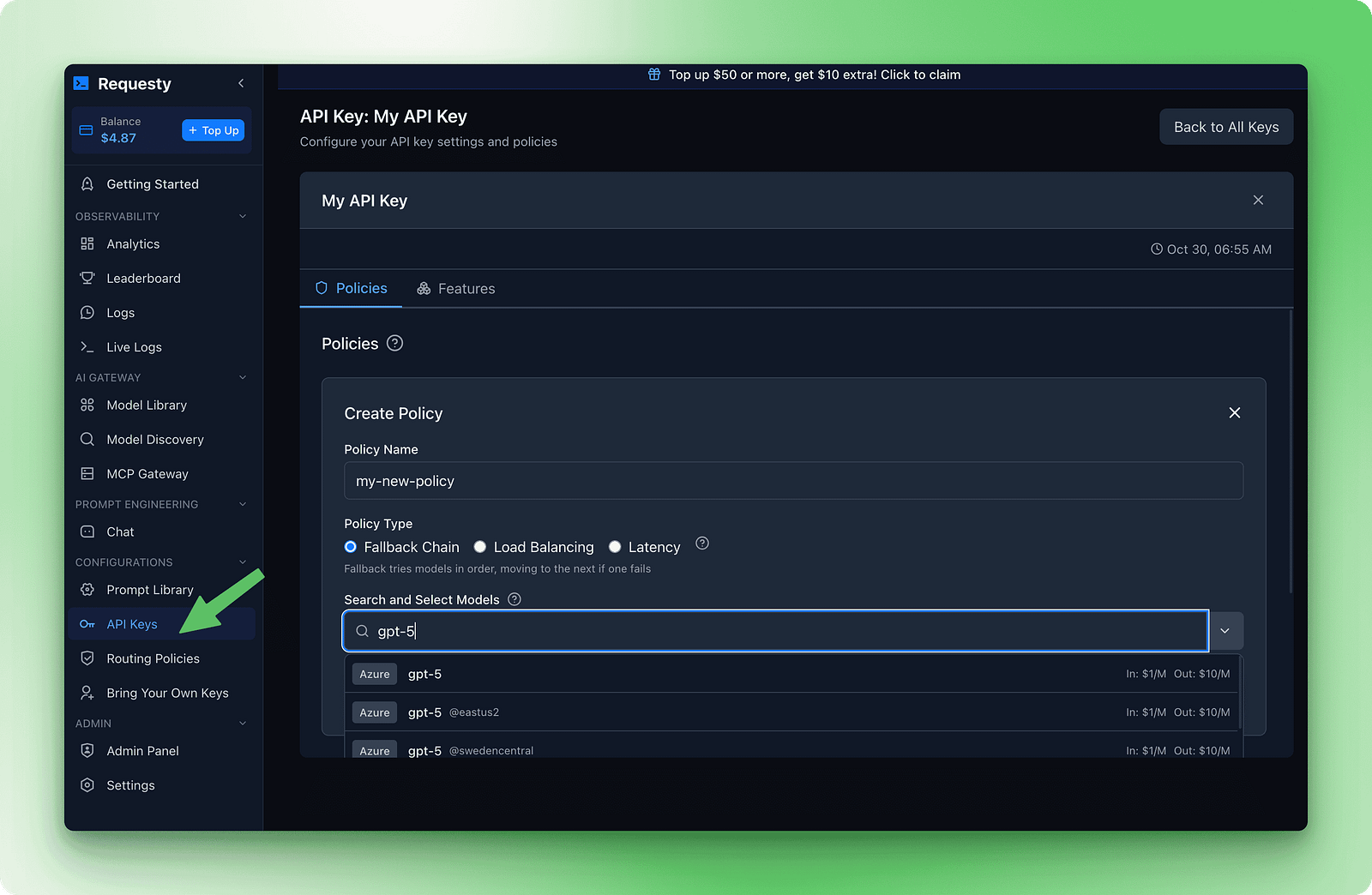
Aqui está um exemplo de cadeia que equilibra qualidade, custo e disponibilidade:
1. openai/gpt-5
2. anthropic/claude-sonnet-4
3. deepseek/deepseek-r1:grátis
Essa cadeia tenta primeiro o GPT-5 porque é rápido e eficiente. Se isso não der certo, ele tenta o Claude Sonnet 4 pra ver se a qualidade é parecida. Se os dois modelos premium estiverem fora do ar, ele volta pro DeepSeek R1, que é de graça e quase sempre tá disponível.
Depois de salvar essa política e anexá-la à sua chave API, as failovers acontecem sem alterações no código:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Explain how DNS works"}]
)
print(f"Model used: {response.model}")
print(response.choices[0].message.content)O campo “ response.model ” mostra qual modelo realmente processou sua solicitação. O painel programa a frequência de failover para que você possa ver quando os modelos de backup estão sendo usados.
Resultado:
Model used: gpt-5-2025-08-07
DNS (Domain Name System) translates human-readable website addresses like "google.com" into IP addresses (like 142.250.80.46) that computers use to locate and connect to servers. This translation happens through a hierarchical system of DNS servers that cache and distribute this information globally for fast lookups.Se todos os modelos da sua cadeia falharem, o Requesty vai mostrar um erro depois de tentar cada um deles. Você vai receber uma resposta padrão de erro da API indicando que não havia modelos disponíveis. Isso é raro, mas pode acontecer durante interrupções generalizadas.
Algumas dicas são úteis na hora de criar cadeias de failover:
openai/gpt-5 e openai/gpt-4o na sua cadeia, ambos podem ficar fora do ar durante uma interrupção da OpenAI. Misture fornecedores para ter mais confiança.Enquanto o LiteLLM precisa de configuração YAML para failovers, o Requesty cuida de tudo por meio de políticas do painel.
Executar a mesma consulta várias vezes custa dinheiro. Se você tem um chatbot de documentação que responde às mesmas perguntas repetidamente ou um assistente de codificação com o mesmo prompt do sistema para cada solicitação, você está pagando o preço total todas as vezes. O cache resolve isso reutilizando partes dos seus prompts que não mudam.
Alguns provedores oferecem suporte nativo ao cache imediato. O Anthropic e o Gemini permitem que você armazene em cache partes inalteradas de seus prompts e as reutilize em várias solicitações. Isso reduz os custos quando você tem padrões repetidos, porque você só paga o preço total pelas peças novas.
Quando você manda uma solicitação com um prompt longo do sistema, o provedor guarda esse prompt no cache dele. Na próxima solicitação com o mesmo prompt do sistema, eles recuperam da cache em vez de processá-la novamente. Você paga uma taxa reduzida de leitura do cache em vez dos custos totais de processamento.
Passe auto_cache no campo extra_body com um objeto requesty aninhado:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": "You are a helpful documentation assistant. You answer questions about Python's asyncio library based on the official docs. Be concise and include code examples."},
{"role": "user", "content": "How do I create a basic event loop?"}
],
extra_body={
"requesty": {
"auto_cache": True
}
}
)
print(response.choices[0].message.content)O prompt do sistema continua o mesmo em todas as solicitações. Com auto_cache: True, a Anthropic armazena em cache após a primeira solicitação. As solicitações seguintes reutilizam o prompt armazenado em cache e processam apenas a pergunta do usuário.
O parâmetro de cache aceita três valores:
True: Ativar cache para esta solicitaçãoFalse: Ignore explicitamente o cache, mesmo que o provedor ofereça suporte a ele (útil para dados confidenciais ou conteúdo sensível ao tempo, nos quais você deseja garantir um processamento atualizado).Só a Anthropic e a Gemini suportam atualmente o cache de prompts. Usar auto_cache com outros provedores vai voltar silenciosamente ao processamento normal sem erros.
O cache funciona melhor quando você tem prompts longos do sistema que permanecem os mesmos em todas as solicitações. Os bots de documentação e os assistentes de codificação são bons exemplos. Os bots de perguntas frequentes e os sistemas de suporte ao cliente também se beneficiam quando os usuários fazem perguntas parecidas. Bases de conhecimento com documentos de referência grandes que não mudam são outro caso de uso bem legal.
Pule o cache quando cada solicitação precisar de dados novos. Aplicativos de previsão do tempo e cotações da bolsa de valores se encaixam nessa categoria. Recomendações personalizadas com sugestões exclusivas para cada usuário não vão trazer benefícios. O monitoramento em tempo real e as transmissões ao vivo mudam com muita frequência para se beneficiar do cache.
Esse exemplo mostra um chatbot de documentação para uma biblioteca Python. O prompt do sistema inclui toda a referência da API. Os usuários fazem perguntas diferentes, mas o sistema continua com a mesma mensagem:
# Simulate a long API documentation string
long_api_documentation = """
Python AsyncIO Library Reference:
- asyncio.run(): Execute async functions
- asyncio.create_task(): Schedule coroutines
- asyncio.gather(): Run multiple tasks
... (this continues for 5,000+ tokens)
"""
# First request - cache miss, pays full price
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "How do I authenticate?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 5,247 (full processing)A segunda solicitação com o mesmo prompt do sistema acessa o cache:
# Second request - cache hit, reduced cost
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "What are rate limits?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 312 (only new content processed, 5,000 tokens served from cache)As taxas de leitura do cache reduzem as despesas em 50 a 90% para as partes armazenadas em cache.
Dá uma olhada na taxa de acertos do cache no painel do Requesty, na seção Análises. Se estiver abaixo de 40%, suas solicitações estão mudando com muita frequência para aproveitar o cache.
Procure padrões nos quais você possa padronizar os prompts do sistema ou extrair conteúdo variável para mensagens do usuário. O painel também mostra suas economias totais com o cache, divididas por provedor e modelo, pra você ver exatamente onde seus esforços de otimização estão valendo a pena.
Seu painel tá quase vazio agora. Você fez algumas solicitações de teste, gastou talvez US$ 0,10. Ainda não tem muito o que analisar. Essa seção mostra o que você precisa configurar agora e o que vai ser útil mais tarde, quando você passar para a produção.
Definir limites de gastos é uma boa prática, mesmo para testes. Vá até a seção Chaves API no seu painel, clique na sua chave e procure por “Limites API”. Defina um limite de orçamento mensal de US$ 5. O Requesty vai te avisar quando chegar a 50%, 75% e 90% desse limite. Para uma proteção mais rigorosa, defina um limite de uso que interrompa todas as solicitações quando você atingir o limite. Isso evita acidentes durante os testes e protege você na produção.
Conforme você usa mais, o Requesty programa cinco métricas importantes:
Depois de algumas semanas de tráfego de produção, essas métricas mostram padrões que ajudam você a otimizar. Use o painel para encontrar fluxos de trabalho caros e mudar para modelos mais baratos, identificar consultas repetidas e habilitar o cache com auto_cache: true, além de monitorar padrões de failover para ajustar suas cadeias de fallback. Um chatbot de documentação reduziu os custos de US$ 500 para US$ 200 por mês, ativando o cache depois que o painel mostrou que 70% das consultas eram iguais.
Monitoramento, dimensionamento e melhores práticas operacionais se tornam essenciais à medida que você passa do protótipo para a produção. O LLMOps cobre todo o ciclo de vida da gestão de grandes modelos de linguagem em ambientes de produção, incluindo estratégias de otimização de custos que complementam a análise integrada do Requesty.
Você aprendeu como o Requesty funciona como um gateway unificado para mais de 300 modelos de IA por meio de uma única API. A configuração é simples: instale o SDK OpenAI, aponte-o para a URL base do Requesty e você estará conectado. A partir daí, o streaming oferece respostas progressivas, as cadeias de failover garantem o tempo de atividade mesmo quando os provedores falham e o cache pode reduzir seus custos pela metade ao lidar com solicitações repetidas.
A escolha entre Requesty, LiteLLM e OpenRouter depende das suas prioridades. Se você precisa de uma infraestrutura gerenciada com failovers automáticos e análises integradas, o Requesty cuida da complexidade para você. Equipes que se sentem à vontade com hospedagem própria e querem um controle mais detalhado podem usar o a abordagem de código aberto do LiteLLM. O OpenRouter oferece acesso básico unificado quando você se sente confortável com a seleção manual de modelos e não precisa de políticas de roteamento avançadas.
Comece configurando uma cadeia de fallback com três modelos de diferentes provedores e, em seguida, habilite o cache em solicitações com prompts repetidos do sistema. Para casos de uso mais sofisticados, dá uma olhada no as capacidades de raciocínio do Claude Sonnet 4 ou aplique práticas LLMOps para implantações de produção.
Cursos mais populares do DataCamp
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Ryan Ong

