
Cursus
Développement d’applications avec LangChain
9 h
Votre application d'IA fonctionne parfaitement avec OpenAI jusqu'à ce que la facture mensuelle atteigne 2 000 $. Vous ajoutez Anthropic pour améliorer votre raisonnement et Google pour réduire vos coûts, et vous vous retrouvez désormais à gérer trois API différentes, chacune avec une facturation et une surveillance distinctes. Lorsque OpenAI est indisponible, votre application cesse de fonctionner. Lorsque vous atteignez les limites de débit, vos utilisateurs rencontrent des erreurs. Il vous est nécessaire d'adopter une approche plus fiable.
Requesty résout ce problème en fournissant une passerelle unifiée avec des basculements automatiques et des outils d'optimisation des coûts. Veuillez configurer vos chaînes de basculement et vos préférences de mise en cache une fois dans le tableau de bord, puis chaque requête API utilisera automatiquement ces politiques.
Lorsqu'un fournisseur rencontre des difficultés, Requesty bascule vers votre modèle de secours. Lorsque vous activez la mise en cache sur des fournisseurs pris en charge tels qu'Anthropic, vous réduisez les coûts liés aux requêtes répétitives.
Dans ce tutoriel, je vais vous présenter les fonctionnalités principales de Requesty. Je commencerai par les appels API de base via la passerelle unifiée et le streaming des réponses. Ensuite, nous configurerons des basculements automatiques pour garantir la disponibilité, activerons la mise en cache du fournisseur afin de réduire les coûts lorsque les requêtes se répètent, et utiliserons le tableau de bord analytique pour surveiller les dépenses et optimiser votre utilisation. Ces fonctionnalités fonctionnent de la même manière, que vous développiez votre premier prototype d'IA ou que vous déployiez des systèmes de production à grande échelle.
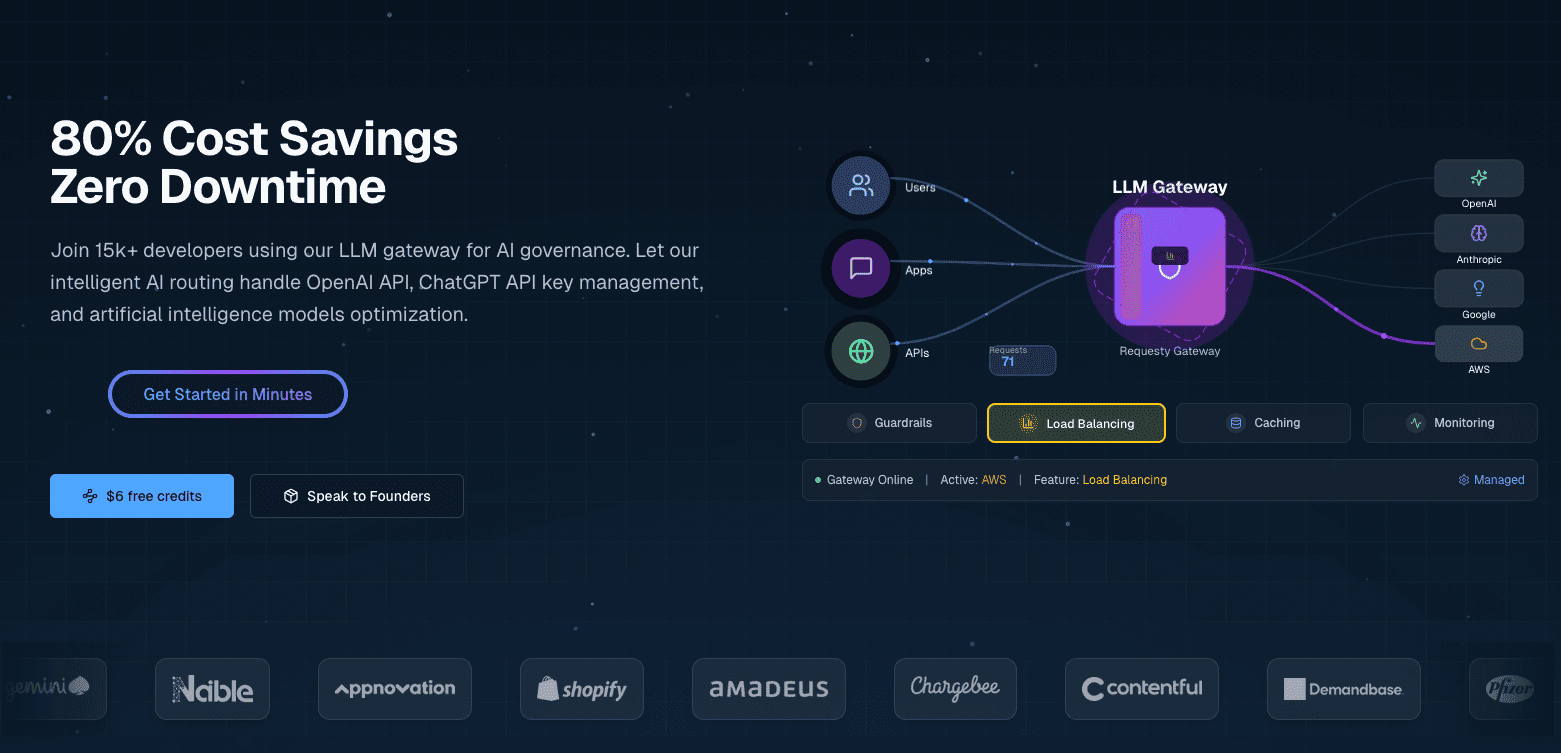
Requesty est une passerelle LLM unifiée qui vous connecte à plus de 300 modèles provenant de fournisseurs tels que OpenAI, Anthropic, Google, Meta et AWS via une seule API. Il s'agit d'un service géré, vous n'avez donc pas besoin d'héberger quoi que ce soit vous-même.
Requesty configure les politiques de routage via un tableau de bord plutôt que par le biais de code ou de fichiers de configuration. Vous configurez les chaînes de basculement, les pondérations de répartition de charge et les préférences de mise en cache via une interface Web, et ces politiques s'appliquent automatiquement à toutes les requêtes API.
La configuration via le tableau de bord permet :
Ces fonctionnalités s'associent à des politiques de routage flexibles (chaînes de secours, équilibrage de charge, optimisation de la latence), à des garde-fous de sécurité intégrés pour les informations personnelles identifiables et l'injection rapide, ainsi qu'à un suivi détaillé des coûts.
OpenRouter offre un accès unifié similaire à plusieurs LLM, mais avec un routage de base et sans tableau de bord analytique. LiteLLM offre des fonctionnalités comparables, mais nécessite un hébergement autonome et une configuration YAML manuelle pour les politiques de routage. Requesty se positionne entre les deux en tant que service géré avec une configuration pilotée par un tableau de bord.
Si vous exploitez des systèmes d'entreprise soumis à des exigences strictes en matière de disponibilité, le SLA de 99,99 % est essentiel. Lorsque votre application est indisponible, vous subissez des pertes financières. Les fonctionnalités de sécurité intégrées, telles que la suppression des informations personnelles identifiables et la détection rapide des injections, permettent de répondre aux exigences de conformité sans avoir à développer ces systèmes vous-même. Les équipes soumises au RGPD peuvent opter pour un hébergement dans l'UE afin de conserver les données dans les juridictions appropriées.
Les équipes de développement qui créent des applications d'IA de production évitent la dépendance vis-à-vis d'un fournisseur en changeant de fournisseur via la configuration plutôt qu'en réécrivant le code. Grâce aux basculements automatiques, il n'est pas nécessaire de développer une infrastructure de fiabilité personnalisée.
Les projets soucieux de leur budget bénéficient de la mise en cache des fournisseurs et de l'équilibrage stratégique de la charge. Au lieu de rédiger vous-même la logique d'optimisation, vous configurez les politiques une seule fois et laissez Requesty se charger de la réduction des coûts.
Veuillez configurer votre environnement de développement. Cette procédure prend environ 5 minutes et couvre les paquets Python, la clé API et la configuration de base.
Vous devrez disposer de Python 3.7 ou d'une version plus récente installée sur votre système. Veuillez vérifier votre version :
import sys
print(f"Python {sys.version_info.major}.{sys.version_info.minor}")Veuillez installer les paquets requis à l'aide de pip ou uv :
pip install openai python-dotenv
# or with uv: uv add openai python-dotenvVous avez besoin du package openai pour interagir avec l'API de Requesty. Le package python-dotenv gère les variables d'environnement de manière sécurisée.
Veuillez créer un compte Requesty à l'adresse app.requesty.ai. Une fois connecté, veuillez vous rendre dans la section Clés API et générer une nouvelle clé. Veuillez copier cette clé pour l'authentification. Veuillez également penser à ajouter des dollars à votre compte.
Veuillez enregistrer votre clé API dans un fichier .env situé dans le répertoire de votre projet :
REQUESTY_API_KEY=your_api_key_hereCela permet de ne pas inclure vos identifiants dans votre code et rend le partage de votre projet plus sécurisé, sans exposer de secrets.
Veuillez vérifier que tout fonctionne correctement en chargeant vos variables d'environnement et en vous assurant que la clé API est accessible :
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
api_key = os.getenv("REQUESTY_API_KEY")
# Check your setup
if api_key:
print("✓ API key loaded")
client = OpenAI(
api_key=api_key,
base_url="https://router.requesty.ai/v1"
)
print("✓ Client configured")
else:
print("✗ API key not found")Si vous voyez les deux coches, vous êtes prêt à effectuer votre première demande.
Une fois votre environnement configuré et votre clé API prête, vous pouvez effectuer votre premier appel API. Requesty fonctionne comme un remplacement direct du SDK OpenAI. Si vous avez déjà utilisé OpenAI, cela vous semblera familier. La seule différence consiste à diriger votre client vers le routeur de Requesty.
Voici comment configurer votre client :
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
api_key=os.getenv("REQUESTY_API_KEY"),
base_url="https://router.requesty.ai/v1"
)Le paramètre base_url permet de rediriger vos requêtes via Requesty plutôt que directement vers OpenAI. Vous pouvez le tester en appelant GPT-5 :
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(response.choices[0].message.content)Résultat :
Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.Le paramètre du modèle utilise le format provider/model-name. Il s'agit ici d' openai/gpt-5, qui accède au dernier modèle d'OpenAI doté de capacités de raisonnement natives et des performances améliorées dans les tâches de codage et de mathématiques. À l'exception du format du modèle et de l'URL de base, le SDK fonctionne de manière similaire à celui d'OpenAI.
Remarque: Chaque appel API a un coût. Requesty ajoute une majoration de 5 % au prix de base du fournisseur, de sorte que GPT-5 coûte légèrement plus cher via Requesty que si vous contactiez directement OpenAI. Vous payez pour la fiabilité, les capacités de basculement et le tableau de bord unifié. Veuillez surveiller votre utilisation via le tableau de bord Requesty afin de suivre vos dépenses.
L'objet de réponse contient des métadonnées utiles qui vont au-delà du simple contenu du message :
print(f"Model used: {response.model}")
print(f"Total tokens: {response.usage.total_tokens}")
print(f"Response: {response.choices[0].message.content}")Résultat :
Model used: gpt-5-2025-08-07
Total tokens: 108
Response: Recursion is a technique where a function solves a problem by calling itself on smaller inputs until it reaches a base case.Le nombre de jetons vous permet de suivre les coûts, car les prix sont généralement fixés par jeton.
Veuillez changer de fournisseur en modifiant le nom du modèle :
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "user", "content": "Explain recursion in one sentence"}
]
)
print(f"Claude says: {response.choices[0].message.content}")Résultat :
Claude says: Recursion is a programming technique where a function calls itself to solve a problem by breaking it down into smaller, similar subproblems until it reaches a base case that stops the repetition.Claude 4 propose des fenêtres contextuelles étendues et un raisonnement amélioré qui le rendent particulièrement performant pour l'analyse de code complexe. Tous les modèles disponibles suivent le même modèle fournisseur/nom de modèle :
# OpenAI GPT-4o
model = "openai/gpt-4o"
# Anthropic Claude
model = "anthropic/claude-sonnet-4"
Wrap your API calls in error handling before moving to production:
try:
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Hello!"}]
)
print(response.choices[0].message.content)
except Exception as e:
print(f"Error: {e}")Cela permet de détecter les délais d'attente réseau, les clés API non valides ou les modèles indisponibles sans provoquer de plantage de votre application.
Lorsque vous soumettez une requête nécessitant une réponse longue, l'écran se fige pendant quelques secondes pendant que le modèle génère des milliers de tokens. Ensuite, tout se déverse d'un seul coup.
Les utilisateurs observent un écran vide, se demandant si quelque chose se passe.
Le streaming résout ce problème en envoyant des morceaux de réponse au fur et à mesure que le modèle les génère, de sorte que les utilisateurs voient les mots apparaître progressivement, tout comme avec chatGPT. Cela rend les applications plus réactives, en particulier pour les réponses plus longues telles que les explications, la génération de code ou l'écriture créative.
Pour activer le streaming dans Requesty, veuillez définir le paramètre stream sur True:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[
{"role": "user", "content": "Explain recursion like I'm five years old"}
],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)La réponse est transmise mot à mot :
Okay! Imagine you have a big basket of toys, and you're trying to find your favorite teddy bear.
But instead of looking through the whole basket all at once, you call your little sibling and say,
"Can you look in here and find my teddy bear? If you see more baskets inside, ask someone else to help in the same way!" …Le paramètre stream=True modifie la réponse d'un objet unique en un itérateur qui produit des blocs. Chaque fragment contient un élément de texte dans delta.content. Le paramètre end="" empêche les sauts de ligne entre les blocs, et flush=True force l'affichage immédiat au lieu de la mise en mémoire tampon.
Les applications de production nécessitent souvent à la fois l'expérience du streaming et le texte complet à des fins de journalisation ou d'analyse. Une fonction d'aide gère les deux :
def stream_and_capture(model, messages):
"""Stream response to user while capturing complete text."""
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
complete_text = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
text = chunk.choices[0].delta.content
complete_text += text
print(text, end="", flush=True)
print() # Final newline
return complete_text
# Use it
full_response = stream_and_capture(
"anthropic/claude-sonnet-4",
[{"role": "user", "content": "Write a haiku about debugging code at 3 AM"}]
)
print(f"\nCaptured {len(full_response)} characters")Résultat :
Blinking cursor waits
Coffee cold, eyes burning red,
One missing bracket.
Captured 74 charactersLe streaming n'est pas toujours la solution la plus appropriée. Pour les réponses courtes ou les sorties structurées telles que les données JSON, les requêtes régulières sont plus simples et plus rapides, car la charge supplémentaire liée au traitement des blocs l'emporte sur les avantages en termes d'expérience utilisateur.
Les flux peuvent échouer en cours de route en raison de problèmes réseau, de limites de débit ou de pannes chez le fournisseur. Enveloppez votre code de streaming dans une gestion d'erreurs de base :
try:
response = client.chat.completions.create(
model="openai/gpt-4o",
messages=[{"role": "user", "content": "Explain quantum entanglement in one sentence"}],
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
except Exception as e:
print(f"\nError: {e}")Si un flux échoue, vous détectez l'erreur et pouvez réessayer manuellement ou revenir à un autre modèle.
Les applications de production ne peuvent pas se permettre de temps d'arrêt. Lorsque OpenAI atteint ses limites de débit pendant les heures de pointe, vos utilisateurs rencontrent des erreurs. En cas de panne d'Anthropic, votre chatbot cesse de fonctionner. Ces défaillances sont inévitables lorsque l'on dépend de fournisseurs externes.
Requesty gère cela grâce à des basculements automatiques. En cas de défaillance de votre modèle principal, Requesty bascule vers votre modèle de secours en moins de 50 millisecondes.
Un système de basculement détecte lorsque votre modèle principal n'est pas disponible et redirige votre requête vers un modèle de secours sans nécessiter aucune modification de votre code. La détection se produit automatiquement lorsqu'un fournisseur renvoie une erreur, atteint les limites de débit ou dépasse le délai d'attente. Requesty achemine ensuite votre requête vers le modèle suivant dans votre chaîne configurée.
Requesty assure une disponibilité de 99,99 % grâce à ce système. Cela représente environ 4 minutes d'indisponibilité par mois au maximum, contre plusieurs heures potentiellement si vous utilisez un seul fournisseur sans options de sauvegarde.
Trois types de politiques régissent le fonctionnement des basculements :
La plupart des équipes commencent par la chaîne de secours, car elle est prévisible. Vous recevez le modèle de votre choix lorsqu'il est disponible et des sauvegardes automatiques lorsqu'il ne l'est pas.
La configuration des basculements s'effectue dans le tableau de bord Requesty. Veuillez vous rendre dans la section Clés API, puis cliquer sur Politiques. Veuillez créer une nouvelle stratégie de chaîne de secours. Vous verrez un formulaire dans lequel vous pourrez ajouter des modèles par ordre de préférence.
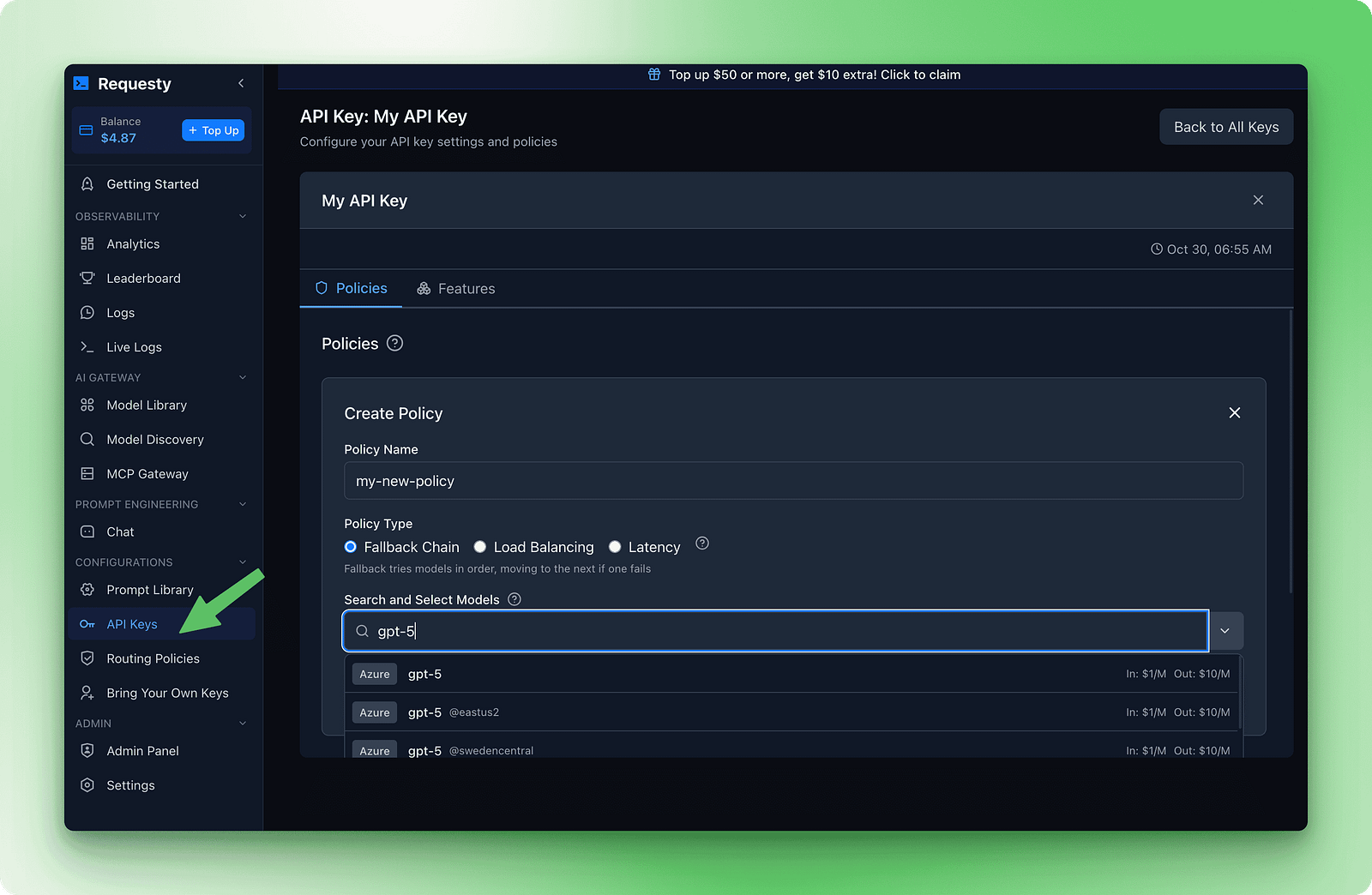
Voici un exemple de chaîne qui équilibre qualité, coût et disponibilité :
1. openai/gpt-5
2. anthropic/claude-sonnet-4
3. deepseek/deepseek-r1 : gratuit
Cette chaîne teste d'abord GPT-5 car il est rapide et performant. Si cela échoue, il tente Claude Sonnet 4 pour une qualité similaire. Si les deux modèles premium sont indisponibles, le système se rabat sur DeepSeek R1, qui est gratuit et presque toujours disponible.
Une fois cette politique enregistrée et associée à votre clé API, les basculements s'effectuent sans modification du code :
response = client.chat.completions.create(
model="openai/gpt-5",
messages=[{"role": "user", "content": "Explain how DNS works"}]
)
print(f"Model used: {response.model}")
print(response.choices[0].message.content)Le champ « response.model » (Modèle de traitement) indique quel modèle a traité votre demande. Le tableau de bord suit la fréquence des basculements afin que vous puissiez voir quand les modèles de secours sont utilisés.
Résultat :
Model used: gpt-5-2025-08-07
DNS (Domain Name System) translates human-readable website addresses like "google.com" into IP addresses (like 142.250.80.46) that computers use to locate and connect to servers. This translation happens through a hierarchical system of DNS servers that cache and distribute this information globally for fast lookups.Si tous les modèles de votre chaîne échouent, Requesty renvoie une erreur après avoir essayé chacun d'entre eux. Vous recevrez une réponse d'erreur API standard indiquant qu'aucun modèle n'était disponible. Ceci est peu fréquent, mais peut se produire lors de pannes généralisées.
Quelques lignes directrices sont utiles lors de la création de chaînes de basculement :
openai/gpt-5 et openai/gpt-4o à votre chaîne, les deux pourraient être indisponibles en cas de panne d'OpenAI. Combinez plusieurs fournisseurs pour une meilleure fiabilité.Alors que LiteLLM nécessite une configuration manuelle configuration YAML pour les basculements, Requesty gère tout via les politiques du tableau de bord.
Exécuter la même requête à plusieurs reprises engendre des coûts. Si vous disposez d'un chatbot de documentation qui répond de manière répétée aux mêmes questions, ou d'un assistant de codage qui utilise la même invite système pour chaque demande, vous payez le prix fort à chaque fois. La mise en cache résout ce problème en réutilisant les parties de vos invites qui ne changent pas.
Certains fournisseurs prennent en charge la mise en cache rapide de manière native. Anthropic et Gemini vous permettent de mettre en cache les parties inchangées de vos invites et de les réutiliser dans différentes requêtes. Cela permet de réduire les coûts lorsque vous avez des modèles répétitifs, car vous ne payez le prix plein que pour les nouvelles pièces.
Lorsque vous envoyez une requête avec une invite système longue, le fournisseur stocke cette invite dans son cache. Lors de la demande suivante avec la même invite système, ils la récupèrent à partir du cache au lieu de la traiter à nouveau. Vous payez des frais réduits pour la lecture du cache au lieu des frais de traitement complets.
Veuillez transmettre auto_cache dans le champ extra_body avec un objet requesty imbriqué:
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": "You are a helpful documentation assistant. You answer questions about Python's asyncio library based on the official docs. Be concise and include code examples."},
{"role": "user", "content": "How do I create a basic event loop?"}
],
extra_body={
"requesty": {
"auto_cache": True
}
}
)
print(response.choices[0].message.content)L'invite du système reste identique pour toutes les requêtes. Avec l'option ` auto_cache: True`, Anthropic met en cache la requête après la première demande. Les requêtes suivantes réutilisent l'invite mise en cache et ne traitent que la question de l'utilisateur.
Le paramètre de mise en cache accepte trois valeurs :
True: Veuillez activer la mise en cache pour cette requête.False: Contourner explicitement la mise en cache même si le fournisseur la prend en charge (utile pour les données sensibles ou le contenu sensible au facteur temps pour lequel vous souhaitez garantir un traitement récent).Seuls Anthropic et Gemini prennent actuellement en charge la mise en cache instantanée. L'utilisation de auto_cache avec d'autres fournisseurs entraînera un retour silencieux au traitement normal sans erreur.
La mise en cache est particulièrement efficace lorsque vous avez des invites système longues qui restent identiques d'une requête à l'autre. Les robots de documentation et les assistants de codage en sont de bons exemples. Les robots FAQ et les systèmes d'assistance à la clientèle tirent également profit des questions similaires posées par les utilisateurs. Les bases de connaissances contenant des documents de référence volumineux qui ne changent pas constituent un autre cas d'utilisation pertinent.
Ignorer la mise en cache lorsque chaque requête nécessite des données actualisées. Les applications météo et les cours boursiers relèvent de cette catégorie. Les recommandations personnalisées avec des suggestions spécifiques à chaque utilisateur ne seront pas avantageuses. La surveillance en temps réel et les flux en direct changent trop fréquemment pour tirer profit de la mise en cache.
Cet exemple présente un chatbot de documentation pour une bibliothèque Python. L'invite du système inclut l'intégralité de la référence API. Les utilisateurs posent différentes questions, mais l'invite du système reste la même :
# Simulate a long API documentation string
long_api_documentation = """
Python AsyncIO Library Reference:
- asyncio.run(): Execute async functions
- asyncio.create_task(): Schedule coroutines
- asyncio.gather(): Run multiple tasks
... (this continues for 5,000+ tokens)
"""
# First request - cache miss, pays full price
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "How do I authenticate?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 5,247 (full processing)La deuxième requête avec la même invite système accède au cache :
# Second request - cache hit, reduced cost
response = client.chat.completions.create(
model="anthropic/claude-sonnet-4",
messages=[
{"role": "system", "content": long_api_documentation},
{"role": "user", "content": "What are rate limits?"}
],
extra_body={"requesty": {"auto_cache": True}}
)
print(f"Tokens: {response.usage.total_tokens}")
# Output: Tokens: 312 (only new content processed, 5,000 tokens served from cache)Les frais de lecture du cache permettent de réduire les dépenses de 50 à 90 % pour les parties mises en cache.
Veuillez vérifier votre taux de réussite du cache dans le tableau de bord Requesty, dans la section « Analytics ». Si ce chiffre est inférieur à 40 %, vos invites changent trop fréquemment pour que la mise en cache soit efficace.
Recherchez les modèles permettant de standardiser les invites du système ou d'extraire le contenu variable dans les messages utilisateur. Le tableau de bord affiche également vos économies totales réalisées grâce à la mise en cache, ventilées par fournisseur et par modèle, afin que vous puissiez voir exactement où vos efforts d'optimisation portent leurs fruits.
Votre tableau de bord est actuellement presque vide. Vous avez effectué quelques demandes tests, dépensé environ 0,10 $. Il n'y a pas encore grand-chose à analyser. Cette section vous indique les paramètres à configurer dès maintenant et ceux qui vous seront utiles ultérieurement lorsque vous passerez en production.
Il est recommandé de fixer des limites de dépenses, même à titre expérimental. Veuillez vous rendre dans la section Clés API de votre tableau de bord, cliquer sur votre clé et rechercher « Limites API ». Veuillez définir un seuil budgétaire mensuel de 5 $. Requesty vous alertera lorsque vous atteindrez 50 %, 75 % et 90 % de cette limite. Pour une protection plus stricte, veuillez définir une limite d'utilisation qui bloquera toutes les demandes une fois cette limite atteinte. Cela permet d'éviter les incidents pendant les tests et vous protège pendant la production.
Au fur et à mesure que votre utilisation augmente, Requesty suit cinq indicateurs clés :
Après quelques semaines de trafic de production, ces indicateurs révèlent des tendances qui vous aideront à optimiser votre site. Veuillez utiliser le tableau de bord pour identifier les workflows coûteux et passer à des modèles plus économiques, repérer les requêtes répétées et activer la mise en cache avec auto_cache: true, et surveiller les modèles de basculement afin d'ajuster vos chaînes de secours. Un chatbot dédié à la documentation a permis de réduire les coûts de 500 $ à 200 $ par mois en activant la mise en cache après que le tableau de bord ait indiqué que 70 % des requêtes étaient identiques.
La surveillance, la mise à l'échelle et les meilleures pratiques opérationnelles deviennent essentielles lorsque vous passez du prototype à la production. LLMOps couvre l'ensemble du cycle de vie de la gestion des grands modèles linguistiques dans les environnements de production, y compris les stratégies d'optimisation des coûts qui complètent les analyses intégrées de Requesty.
Vous avez découvert comment Requesty fonctionne en tant que passerelle unifiée vers plus de 300 modèles d'IA via une seule API. La configuration est simple : installez le SDK OpenAI, pointez-le vers l'URL de base de Requesty, et vous êtes connecté. À partir de là, le streaming fournit des réponses progressives, les chaînes de basculement garantissent la disponibilité même en cas de défaillance des fournisseurs, et la mise en cache peut réduire vos coûts de moitié lorsque vous traitez des demandes répétées.
Le choix entre Requesty, LiteLLM et OpenRouter dépend de vos priorités. Si vous avez besoin d'une infrastructure gérée avec basculement automatique et analyses intégrées, Requesty gère la complexité pour vous. Les équipes à l'aise avec l'auto-hébergement et souhaitant un contrôle granulaire peuvent utiliser l'approche open source de LiteLLM. OpenRouter offre un accès unifié de base si vous êtes à l'aise avec la sélection manuelle des modèles et n'avez pas besoin de politiques de routage avancées.
Commencez par configurer une chaîne de secours avec trois modèles provenant de différents fournisseurs, puis activez la mise en cache des requêtes avec des invites système répétées. Pour des cas d'utilisation plus complexes, veuillez explorer les capacités de raisonnement de Claude Sonnet 4 ou appliquez les pratiques pratiques LLMOps pour les déploiements en production.
Meilleurs cours DataCamp
Cursus
Cours
Cours