Lernpfad
Llama-Grundlagen
4 Std.
DeepSeek hat gerade DeepSeek-R1angekündigt , den nächsten Schritt in seiner Arbeit an schlussfolgernden Modellen. Es ist ein Upgrade von ihrem früheren DeepSeek-R1-Lite-Vorschau und zeigt, dass sie es ernst meinen mit der Konkurrenz von OpenAIs o1.
Mit OpenAI plant die Veröffentlichung von o3 noch in diesem Jahr zu veröffentlichen, ist klar, dass der Wettbewerb bei den Argumentationsmodellen zunimmt. Auch wenn DeepSeek in einigen Bereichen etwas hinterherhinkt, macht es sein Open-Source-Charakter zu einer überzeugenden Option für die KI-Community.
In diesem Blog werde ich die wichtigsten Funktionen von DeepSeek-R1, den Entwicklungsprozess, die destillierten Modelle, den Zugang, die Preise und den Vergleich mit den Modellen von OpenAI erläutern.
DeepSeek-R1 ist ein Open-Source Argumentationsmodell das von DeepSeek, einem chinesischen KI-Unternehmen, entwickelt wurde, um Aufgaben zu lösen, die logische Schlussfolgerungen, mathematische Problemlösungen und Entscheidungsfindung in Echtzeit erfordern.
Was Argumentationsmodelle wie DeepSeek-R1 und o1 von OpenAI von herkömmlichen Sprachmodellen unterscheidet, ist ihre Fähigkeit zu zeigen, wie sie zu einer Schlussfolgerung gekommen sind.

Mit DeepSeek-R1 kannst du seine Logik nachvollziehen, was es einfacher macht, sein Ergebnis zu verstehen und ggf. in Frage zu stellen. Diese Fähigkeit verschafft Argumentationsmodellen einen Vorteil in Bereichen, in denen Ergebnisse erklärbar sein müssen, wie in der Forschung oder bei komplexen Entscheidungen.
Was DeepSeek-R1 besonders wettbewerbsfähig und attraktiv macht, ist sein Open-Source-Charakter. Im Gegensatz zu proprietären Modellen können Entwickler und Forscher sie innerhalb bestimmter technischer Grenzen (z. B. Ressourcenbedarf) erforschen, verändern und einsetzen.
In diesem Abschnitt erkläre ich dir, wie DeepSeek-R1 entwickelt wurde, beginnend mit seinem Vorgänger, DeepSeek-R1-Zero.
DeepSeek-R1 begann mit R1-Zero, einem Modell, das vollständig durch Verstärkungslernen. Dieser Ansatz ermöglichte es ihr zwar, starke Argumentationsfähigkeiten zu entwickeln, hatte aber auch große Nachteile. Die Ausgaben waren oft schwer zu lesen, und das Modell vermischte manchmal Sprachen in seinen Antworten. Diese Einschränkungen machten R1-Zero für reale Anwendungen weniger praktisch.
Der Rückgriff auf reines Reinforcement Learning führte zu Ergebnissen, die zwar logisch fundiert, aber schlecht strukturiert waren. Ohne die Anleitung durch überwachte Daten hatte das Modell Schwierigkeiten, seine Überlegungen effektiv zu vermitteln. Das war ein Hindernis für Nutzer, die Klarheit und Präzision bei den Ergebnissen brauchten.
Um diese Probleme zu lösen, hat DeepSeek bei der Entwicklung von R1 eine Änderung vorgenommen und Verstärkungslernen mit überwachter Feinabstimmung kombiniert. Bei diesem hybriden Ansatz wurden kuratierte Datensätze einbezogen, was die Lesbarkeit und Kohärenz des Modells verbessert. Probleme wie Sprachvermischung und fragmentiertes Denken wurden deutlich reduziert, was das Modell für den praktischen Einsatz besser geeignet macht.
Wenn du mehr über die Entwicklung von DeepSeek-R1 erfahren möchtest, empfehle ich dir die Lektüre des Release Paper.
Destillation in der KI ist der Prozess, bei dem aus größeren Modellen kleinere, effizientere Modelle erstellt werden, die einen Großteil ihrer Argumentationskraft bewahren und gleichzeitig den Rechenaufwand reduzieren. DeepSeek wandte diese Technik an, um eine Reihe von destillierten Modellen aus R1 zu erstellen, die die Architekturen Qwen und Llama nutzen.
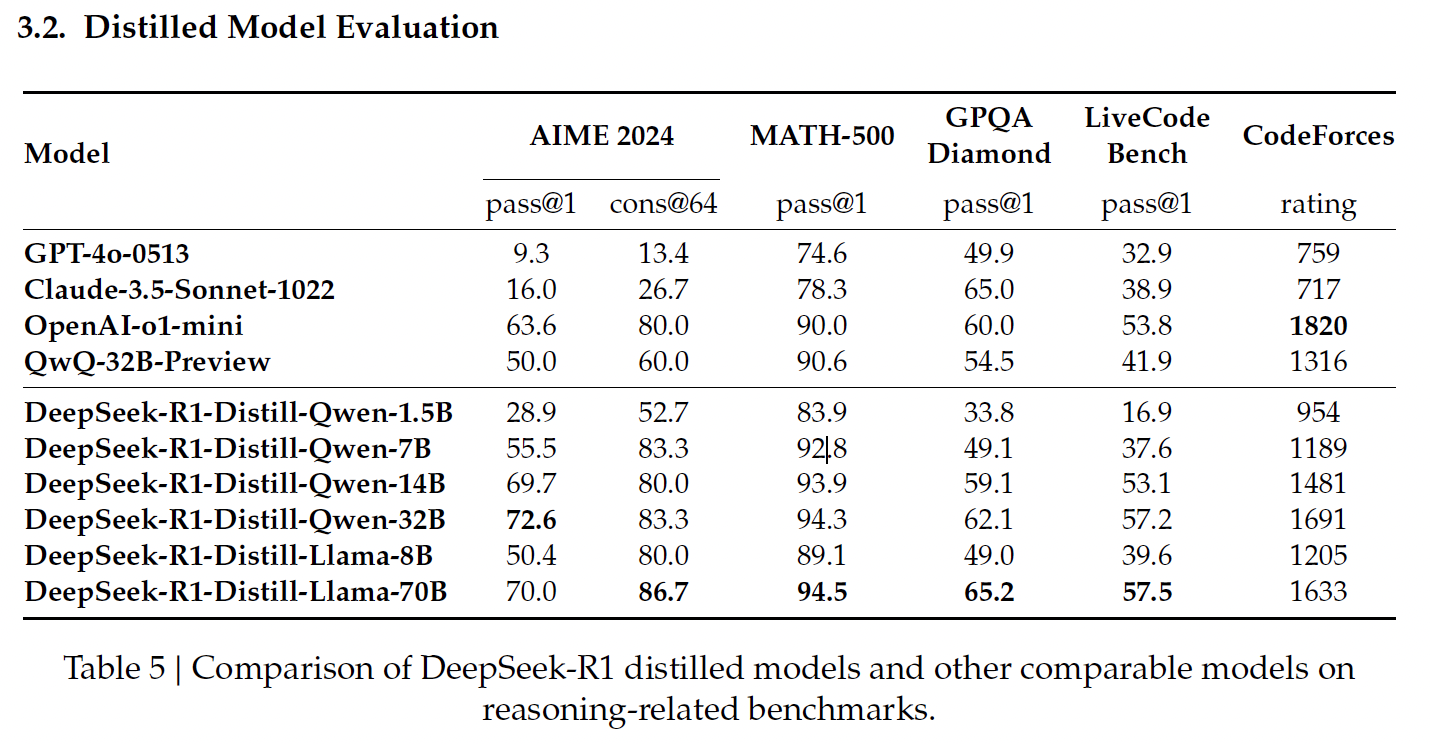
Quelle: DeepSeek's Veröffentlichungspapier
Die Qwen-basierten destillierten Modelle von DeepSeek konzentrieren sich auf Effizienz und Skalierbarkeit und bieten ein ausgewogenes Verhältnis zwischen Leistung und Rechenaufwand.
Dies ist das kleinste destillierte Modell, das 83,9% auf MATH-500 erreicht. MATH-500 prüft die Fähigkeit, mathematische Probleme auf Highschool-Niveau mit logischem Denken und mehrstufigen Lösungen zu lösen. Dieses Ergebnis zeigt, dass das Modell trotz seiner kompakten Größe grundlegende mathematische Aufgaben gut bewältigt.
Im LiveCodeBench (16,9 %), einem Benchmark zur Bewertung der Programmierfähigkeiten, fällt die Leistung jedoch deutlich ab, was seine begrenzten Fähigkeiten bei Programmieraufgaben verdeutlicht.
Qwen-7B glänzt bei MATH-500 mit 92,8 %, was seine starken Fähigkeiten im mathematischen Denken unter Beweis stellt. Auch beim GPQA Diamond (49,1 %), der das Beantworten von Sachfragen bewertet, schneidet er recht gut ab, was darauf hindeutet, dass er eine gute Balance zwischen mathematischem und sachlichem Denken hat.
Seine Leistung bei LiveCodeBench (37,6 %) und CodeForces (1189 Punkte) lässt jedoch vermuten, dass er für komplexe Programmieraufgaben weniger geeignet ist.
Dieses Modell schneidet bei MATH-500 gut ab (93,9%), was seine Fähigkeit widerspiegelt, komplexe mathematische Probleme zu bewältigen. Sein Ergebnis von 59,1 % im GPQA Diamond zeigt auch, dass er im Bereich des sachlichen Denkens kompetent ist.
Seine Leistung im LiveCodeBench (53,1 %) und bei CodeForces (1481 Punkte) zeigt, dass es bei kodierungs- und programmierspezifischen Denkaufgaben noch Steigerungspotenzial gibt.
Das größte Qwen-basierte Modell erreicht die höchste Punktzahl unter seinen Mitbewerbern beim AIME 2024 (72,6%), der fortgeschrittenes mathematisches Denken in mehreren Schritten bewertet. Auch bei MATH-500 (94,3 %) und GPQA Diamond (62,1 %) schneidet er hervorragend ab und beweist damit seine Stärke im mathematischen und sachlichen Denken.
Seine Ergebnisse bei LiveCodeBench (57,2 %) und CodeForces (1691 Punkte) deuten darauf hin, dass er zwar vielseitig ist, aber im Vergleich zu Modellen, die auf das Programmieren spezialisiert sind, noch nicht für Programmieraufgaben optimiert ist.
DeepSeeks Llama-basierte destillierte Modelle legen den Schwerpunkt auf hohe Leistung und fortschrittliche Denkfähigkeiten, die sich besonders bei Aufgaben auszeichnen, die mathematische und faktische Präzision erfordern.
Llama-8B schneidet gut bei MATH-500 (89,1 %) und angemessen bei GPQA Diamond (49,0 %) ab, was darauf hindeutet, dass es in der Lage ist, mathematisches und sachliches Denken zu beherrschen. Allerdings schneidet es bei Programmier-Benchmarks wie LiveCodeBench (39,6 %) und CodeForces (1205 Punkte) schlechter ab, was seine Einschränkungen bei programmierbezogenen Aufgaben im Vergleich zu Qwen-basierten Modellen deutlich macht.
Das größte destillierte Modell, Llama-70B, liefert mit 94,5 % die beste Leistung aller destillierten Modelle in MATH-500 und erreicht eine starke Punktzahl von 86,7 % in AIME 2024, was es zu einer hervorragenden Wahl für fortgeschrittenes mathematisches Denken macht.
Auch im LiveCodeBench (57,5 %) und bei CodeForces (1633 Punkte) schneidet er gut ab, was darauf hindeutet, dass er bei Codierungsaufgaben kompetenter ist als die meisten anderen Modelle. In diesem Bereich ist er gleichauf mit OpenAIs o1-mini oder GPT-4o.
Du kannst auf DeepSeek-R1 über zwei Hauptmethoden zugreifen: die webbasierte DeepSeek-Chat-Plattform und die DeepSeek-API, so dass du die Option wählen kannst, die deinen Bedürfnissen am besten entspricht.
Die DeepSeek-Chat-Plattform bietet eine unkomplizierte Möglichkeit, mit DeepSeek-R1 zu interagieren. Um darauf zuzugreifen, kannst du entweder direkt auf die Chat-Seite oder auf der Homepage auf Jetzt startenStartseite.

Nach der Registrierung kannst du den "Deep Think"-Modus auswählen, um die Schritt-für-Schritt-Denkfähigkeiten von Deepseek-R1 zu erleben.
Um DeepSeek-R1 in deine Anwendungen zu integrieren, bietet die DeepSeek API einen programmatischen Zugang.
Um loszulegen, musst du einen API-Schlüssel erhalten, indem du dich auf der DeepSeek-Plattform.
Die API ist mit dem Format von OpenAI kompatibel, sodass die Integration einfach ist, wenn du mit den Tools von OpenAI vertraut bist. Weitere Anweisungen findest du in der DeepSeek's API Dokumentation.
Ab dem 21. Januar 2025 ist die Nutzung der Chat-Plattform kostenlos, allerdings mit einer täglichen Obergrenze von 50 Nachrichten im "Deep Think"-Modus. Diese Einschränkung macht es ideal für den leichten Einsatz oder die Erkundung.
Die API bietet zwei Modelle:deepseek-chat (DeepSeek-V3) und deepseek-reasoner (DeepSeek-R1) - mit der folgenden Preisstruktur (pro 1 Mio. Token):
|
MODELL |
KONTEXTLÄNGE |
MAX COT TOKENS |
MAX. OUTPUT TOKEN |
1M TOKEN EINGANGSPREIS (CACHE HIT) |
1M TOKEN EINGANGSPREIS (CACHE MISS) |
1M TOKEN AUSGANGSPREIS |
|
deepseek-chat |
64K |
- |
8K |
$0.07 $0.014 |
$0.27 $0.14 |
$1.10 $0.28 |
|
deepseek-reasoner |
64K |
32K |
8K |
$0.14 |
$0.55 |
$2.19 |
Quelle: Die Preisseite von DeepSeek
Um sicherzustellen, dass du über die aktuellsten Preisinformationen verfügst und weißt, wie du die Kosten für CoT (Chain-of-Thought)-Überlegungen berechnen kannst, besuche DeepSeek's Preisseite.
DeepSeek-R1 konkurriert in mehreren Benchmarks direkt mit OpenAI o1 und erreicht oder übertrifft OpenAIs o1.
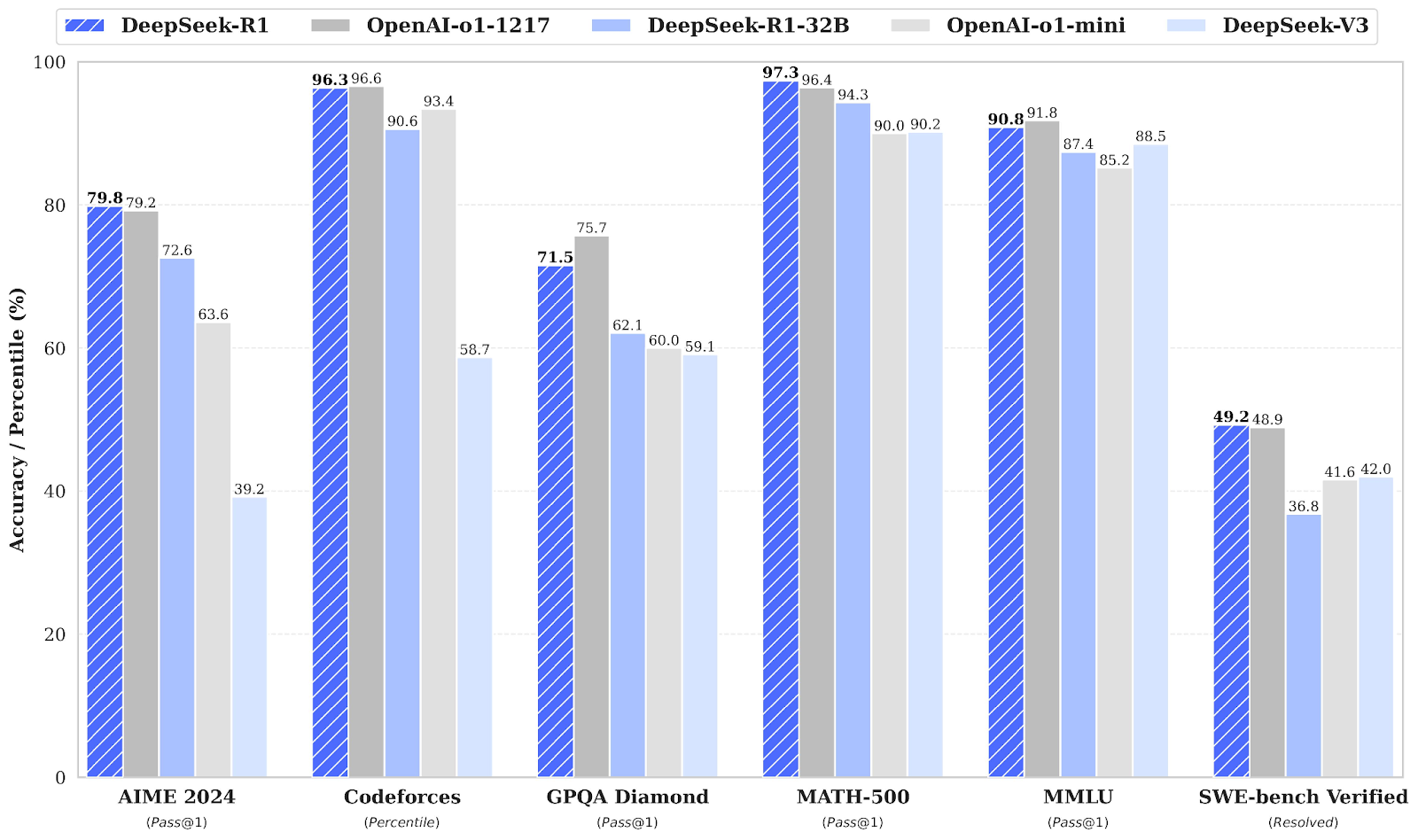
Quelle: DeepSeek's Veröffentlichungspapier
In den Mathematik-Benchmarks zeigt DeepSeek-R1 eine starke Leistung. Beim AIME 2024, der fortgeschrittenes mathematisches Denken in mehreren Schritten bewertet, liegt DeepSeek-R1 mit 79,8 % knapp vor OpenAI o1-1217 mit 79,2 %.
Bei MATH-500 liegt DeepSeek-R1 mit beeindruckenden 97,3 % an der Spitze und übertrifft OpenAI o1-1217 mit 96,4 % knapp. Dieser Benchmark testet Modelle für verschiedene mathematische Probleme auf Highschool-Niveau, die detailliertes Denken erfordern.
Der Codeforces-Benchmark bewertet die Codierungs- und algorithmischen Schlussfolgerungsfähigkeiten eines Modells, dargestellt als Prozentrang im Vergleich zu menschlichen Teilnehmern. OpenAI o1-1217 führt mit 96,6 %, während DeepSeek-R1 sehr konkurrenzfähige 96,3 % erreicht, mit nur einem kleinen Unterschied.
Der SWE-bench Verified Benchmark bewertet das logische Denken bei Softwareentwicklungsaufgaben. DeepSeek-R1 schneidet mit einer Punktzahl von 49,2 % sehr gut ab und liegt damit knapp vor OpenAI o1-1217 mit 48,9 %. Dieses Ergebnis macht DeepSeek-R1 zu einem starken Konkurrenten bei speziellen Aufgaben wie der Software-Verifikation.
Beim Faktenwissen misst der GPQA Diamond die Fähigkeit, Fragen zum Allgemeinwissen zu beantworten. DeepSeek-R1 erreicht 71,5 % und liegt damit hinter OpenAI o1-1217, das 75,7 % erreicht. Dieses Ergebnis unterstreicht den leichten Vorteil von OpenAI o1-1217 bei Aufgaben zum logischen Denken.
Bei MMLU, einem Benchmark, der verschiedene Disziplinen umfasst und das Multitasking-Sprachverständnis bewertet, liegt OpenAI o1-1217 mit 91,8 % leicht vor DeepSeek-R1, der 90,8 % erreicht hat.
DeepSeek-R1 ist ein starker Konkurrent im Bereich der logischen KI und liegt gleichauf mit OpenAIs o1. OpenAIs o1 mag zwar einen leichten Vorsprung bei der Programmierung und beim Faktenwissen haben, aber ich denke, dass DeepSeek-R1 aufgrund seines Open-Source-Charakters und des kostengünstigen Zugangs eine attraktive Option ist.
Während sich OpenAI auf die Veröffentlichung von o3 vorbereitet, freue ich mich darauf zu sehen, wie dieser wachsende Wettbewerb die Zukunft der Argumentationsmodelle gestaltet. Im Moment ist DeepSeek-R1 eine überzeugende Alternative.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
