
Kurs
Fortgeschrittene Datenvisualisierung mit Seaborn
4 Std.
75K
Heatmaps sind eine beliebte Technik zur Datenvisualisierung, bei der verschiedene Ebenen der Datengröße farblich dargestellt werden, so dass du schnell Muster und Anomalien in deinem Datensatz erkennen kannst.
Mit der Seaborn-Bibliothek kannst du ganz einfach hochgradig angepasste Visualisierungen deiner Daten erstellen, wie z. B. Liniendiagramme, Histogramme und Heatmaps. Du kannst dir auch unser Tutorial über die verschiedenen Arten von Datendiagrammen und deren Erstellung in Python ansehen.
Halte unseren Seaborn-Spickzettel bereit, damit du bei der Erstellung und Anpassung von Datenvisualisierungen mit der Seaborn-Bibliothek schnell nachschlagen kannst.

In diesem Tutorial erfährst du, was Seaborn Heatmaps sind, wann du sie verwenden kannst und wie du sie erstellst und an deine Bedürfnisse anpasst.
Heatmaps ordnen die Daten in einem Raster an, wobei verschiedene Farben oder Schattierungen die unterschiedlichen Ausmaße der Daten anzeigen.
Die visuelle Natur von Heatmaps ermöglicht die sofortige Erkennung von Mustern, wie z.B. Clustern, Trends und Anomalien. Das macht Heatmaps zu einem effektiven Werkzeug für die explorative Datenanalyse.
Hier ist ein Beispiel für eine Seaborn Heatmap:
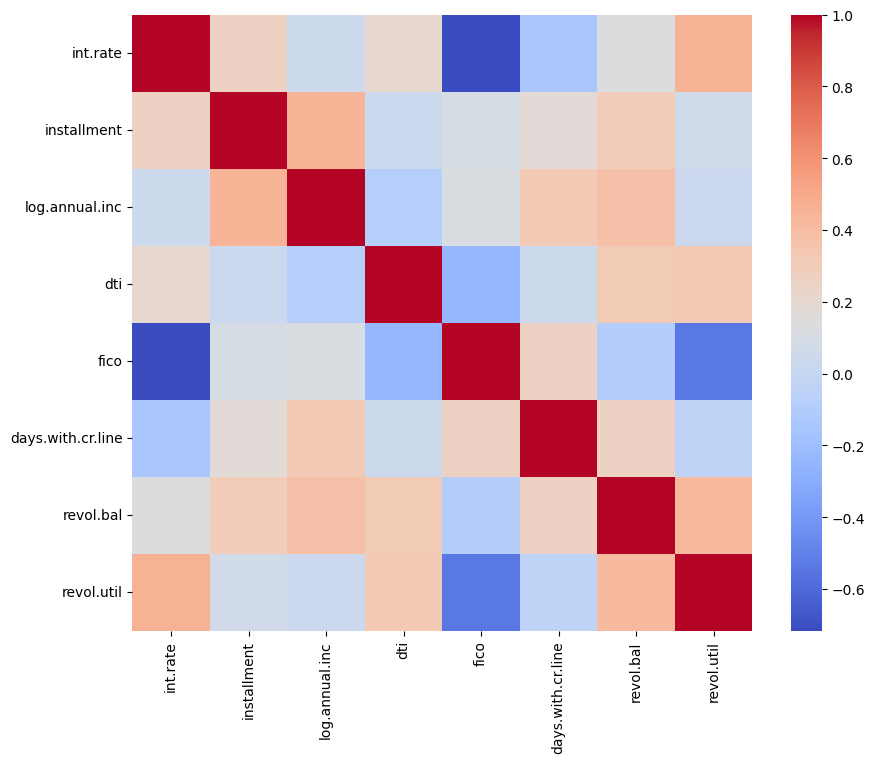
Die Entscheidung, eine Heatmap zu verwenden, hängt von deinen Anforderungen und der Art deines Datensatzes ab. Heatmaps eignen sich in der Regel am besten für Datensätze, bei denen du Werte als Farben darstellen kannst, z. B. kontinuierliche oder diskrete numerische Daten. Du kannst sie aber auch für kategoriale Daten verwenden, die quantifiziert oder zusammengefasst wurden (z. B. Zählungen, Durchschnittswerte).
Wenn der Datensatz extreme Ausreißer enthält oder sehr spärlich ist, ist eine Heatmap ohne Vorverarbeitung oder Normalisierung möglicherweise nicht so effektiv. Text, Bilder und andere unstrukturierte Daten eignen sich ebenfalls nicht direkt für Heatmaps, es sei denn, du wandelst die Daten zunächst in ein strukturiertes, numerisches Format um.
Heatmaps eignen sich hervorragend, um die Korrelationsmatrix zwischen mehreren Variablen zu visualisieren. So kannst du auf einen Blick erkennen, ob die Variablen hoch korreliert oder umgekehrt korreliert sind.
Heatmaps sind auch nützlich, um Daten über zwei Dimensionen hinweg visuell zu vergleichen, z. B. verschiedene Zeiträume oder Kategorien. Bei der Analyse geografischer Daten können Heatmaps die Dichte oder Intensität von Ereignissen in einem räumlichen Layout darstellen, z. B. die Bevölkerungsdichte oder Kriminalitätsschwerpunkte in einer Stadt.
Für dieses Tutorial verwenden wir einen Datensatz mit Informationen über Kredite, die auf DataLab, dem KI-fähigen Daten-Notizbuch von DataCamp, verfügbar sind. Der Code für dieses Lernprogramm ist auch in einer entsprechenden DataLab-Arbeitsmappe verfügbar.
In DataLab sind alle wichtigen Bibliotheken bereits bequem installiert und können importiert werden. Um mehr zu erfahren, haben wir einen Artikel über die besten Python-Bibliotheken für Data Science.
Wir werden diese Bibliotheken für diesen Lehrgang verwenden:
# Import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsWenn du dich mit Python nicht auskennst und für dieses Tutorial schnell auf den neuesten Stand kommen musst, schau dir unseren Kurs Einführung in Python an.
Wenn du mehr über die Bibliotheken erfahren möchtest, die wir in diesem Lernprogramm verwenden, kannst du auch diese Kurse besuchen:
Achte darauf, dass deine Daten in einem Matrixformat vorliegen, in dem Zeilen und Spalten verschiedene Dimensionen darstellen (z. B. Zeiträume, Variablen, Kategorien). Jede Zelle in der Matrix sollte den Wert enthalten, den du visualisieren willst.
Bevor du eine Heatmap verwendest, solltest du zwei wichtige Datenbereinigungsaufgaben durchführen: fehlende Werte behandeln und Ausreißer entfernen.
Wenn du mit fehlenden Werten umgehst, kannst du sie mit einem statistischen Maß (Mittelwert, Median) auffüllen, sie interpolieren oder sie weglassen, wenn sie nicht signifikant sind. Was die Ausreißer angeht, so kannst du sie je nach Analyse entfernen oder ihre Werte anpassen.
In unserem Darlehensdatensatz gab es keine fehlenden Werte, aber wir haben einige Ausreißer identifiziert, die wir entfernen wollten. Im DataLab-Notizbuch findest du den vollständigen Code, wie wir das gemacht haben.
Wenn dein Datensatz eine große Bandbreite an Werten umfasst, solltest du ihn skalieren oder normalisieren. Dadurch können die Farben der Heatmap relative Unterschiede genauer darstellen. Zu den gängigen Methoden gehören die Min-Max-Skalierung und die Z-Score-Normalisierung.
Bei kontinuierlichen Daten, die kategorisiert werden müssen, solltest du eine Diskretisierung in Bins oder Kategorien in Betracht ziehen, um eine aussagekräftigere Heatmap-Darstellung zu erhalten.
Um seaborn.heatmap() zu verwenden, musst du normalerweise eine Matrix von Daten übergeben. Dann kannst du die Parameter anpassen, um deine Heatmaps je nach deinen Anforderungen zu gestalten.
data: Der zu visualisierende Datensatz, der in Form einer Matrix vorliegen muss.cmap: Legt die Farbkarte für die Heatmap fest. Seaborn unterstützt verschiedene Farbpaletten, darunter sequentielle, divergierende und qualitative Schemata.annot: Wenn du True wählst, wird der Wert in jeder Zelle auf der Heatmap vermerkt.fmt: Wenn annot True ist, bestimmt fmt den String-Formatierungscode für die Annotation der Daten. Zum Beispiel 'd' für ganze Zahlen und '.2f' für Fließkommazahlen mit zwei Nachkommastellen.linewidths: Legt die Breite der Linien fest, die jede Zelle unterteilen sollen. Ein größerer Wert erhöht den Abstand zwischen den Zellen.linecolor: Legt die Farbe der Linien fest, die jede Zelle unterteilen, wenn linewidths größer als 0 ist.cbar: Ein boolescher Wert, der angibt, ob ein Farbbalken gezeichnet werden soll. Der Farbbalken dient als Referenz für die Zuordnung von Datenwerten zu Farben.vmin und vmax: Diese Parameter definieren den Datenbereich, den die Farbkarte abdeckt.center: Legt den Wert fest, bei dem die Farbkarte zentriert werden soll, wenn unterschiedliche Farbschemata verwendet werden.square: Die Einstellung True sorgt dafür, dass die Zellen der Heatmap quadratisch sind.xticklabels und yticklabels: Kontrolliere die Beschriftungen, die auf den x- und y-Achsen angezeigt werden.Wir werden eine Heatmap erstellen, die den Korrelationskoeffizienten zwischen den einzelnen numerischen Variablen in unseren Daten zeigt. Wir halten die Heatmap vorerst einfach und passen sie im nächsten Abschnitt weiter an.
# Calculate the correlation matrix
correlation_matrix = filtered_df.corr()
# Create the heatmap
plt.figure(figsize = (10,8))
sns.heatmap(correlation_matrix, cmap = 'coolwarm')
plt.show()
Wenn du die Farbe deiner Heatmap anpasst, ist sie leichter zu lesen und fällt in Berichten und Präsentationen mehr ins Auge.
Seaborn und Matplotlib bieten eine große Auswahl an integrierten Farbkarten. Experimentiere mit Farbkarten ("Blues", "coolwarm", "viridis" usw.), um eine zu finden, die die Struktur und die Muster deiner Daten effektiv hervorhebt. Verwende sequentielle Farbkarten für Daten mit einer natürlichen Reihenfolge von niedrig bis hoch, divergierende Farbkarten für Daten mit einem kritischen Mittelwert und qualitative Farbkarten für kategoriale Daten.
Du bist jedoch nicht auf die Standardfarbkarten und -optionen von Seaborn beschränkt. Du kannst mit Matplotlib benutzerdefinierte Farbkarten erstellen und zusätzliche Anpassungsoptionen wie die Transparenz festlegen.
Mit den Einstellungen vmin und vmax kannst du den Bereich deiner Daten festlegen, den die Farbkarte abdeckt. So kannst du den Kontrast verstärken und dich auf bestimmte Bereiche konzentrieren, die von Interesse sind.
Bei divergierenden Farbkarten gibst du mit dem Parameter center den Mittelwert an. Dadurch wird sichergestellt, dass der Farbkontrast um einen kritischen Wert herum verankert ist.
Wir passen die Farbpalette unserer Heatmap an und verankern die Farben, indem wir die Minimal-, Maximal- und Mittelwerte angeben.
# Customize heatmap colors
plt.figure(figsize = (10,8))
sns.heatmap(correlation_matrix, cmap = 'viridis', vmin = -1, vmax = 1, center = 0)
plt.show()
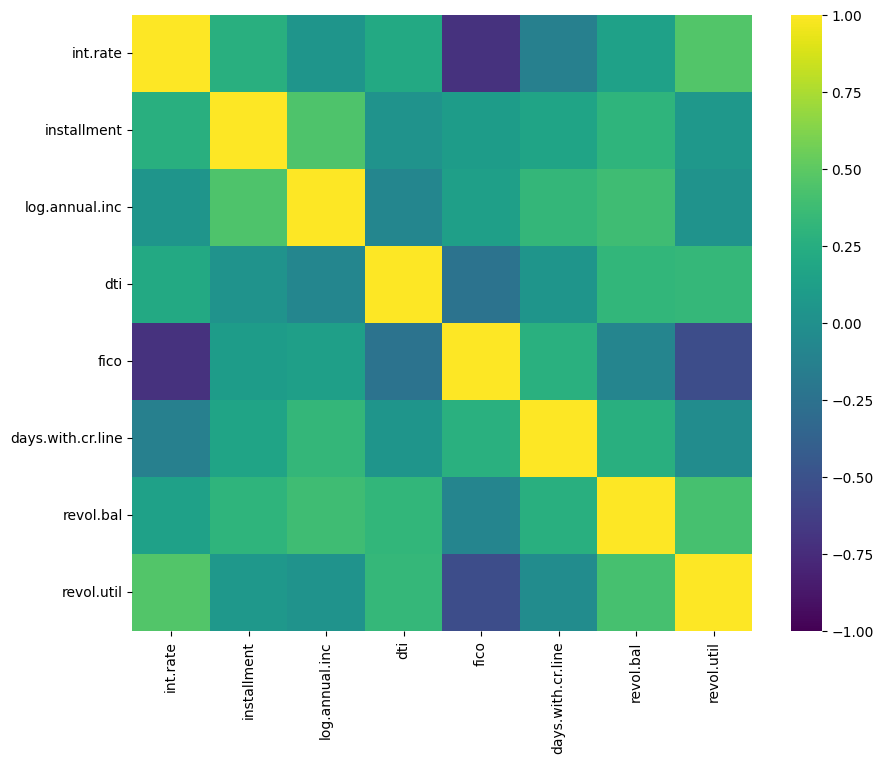
Bei der Datenbeschriftung werden Beschriftungen in jede Zelle eingefügt, die numerische Werte oder Text enthalten können. Anmerkungen machen es einfacher, Heatmaps schnell zu lesen und zu interpretieren, ohne dass du die Werte anhand der Legende herausfinden musst.
Um Anmerkungen zu aktivieren, setze den Parameter annot auf True. Dadurch werden die Datenwerte in jeder Zelle der Heatmap angezeigt.
Mit dem Parameter fmt kannst du den Text der Anmerkungen formatieren. Verwende zum Beispiel 'd' für die Formatierung von Ganzzahlen und '.2f' für Fließkommazahlen, die mit zwei Nachkommastellen angezeigt werden.
Obwohl die Heatmap-Funktion von Seaborn keine direkte Anpassung von Texteigenschaften wie z. B. der Schriftgröße über den Parameter annot ermöglicht, kannst du diese Eigenschaften mit rcParams von Matplotlib global anpassen.
# Create an annotated heatmap
plt.figure(figsize = (10,8))
plt.rcParams.update({'font.size': 12})
sns.heatmap(correlation_matrix, cmap = 'viridis', vmin = -1, vmax = 1, center = 0, annot=True, fmt=".2f", square=True, linewidths=.5)
plt.show()
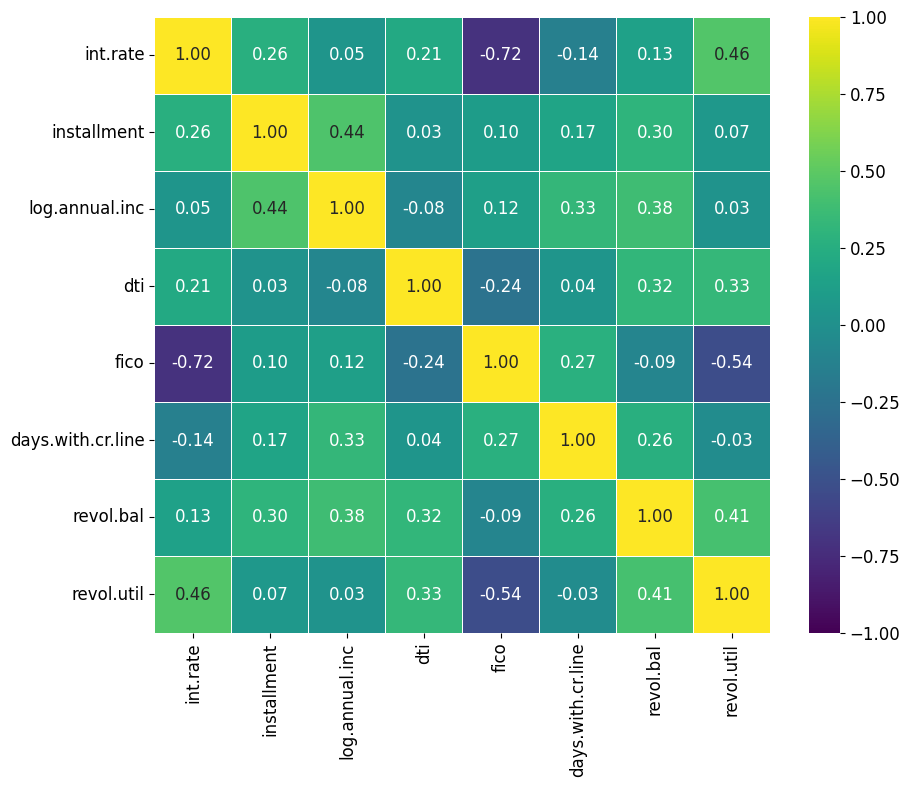
Der Parameter annot kann auch eine array-ähnliche Struktur akzeptieren, die die gleiche Form wie deine Daten hat. Das ist ein toller Trick, mit dem du Anmerkungen hinzufügen kannst, die andere Informationen enthalten als die, die in den Zellenfarben angezeigt werden. Hier ist ein Beispiel, wie du das anwenden kannst:
# Example of alternative annotations
annot_array = np.round(data*100, decimals=2)
sns.heatmap(data, annot=annot_array, fmt='s')Datenmaskierung ist eine Technik, mit der bestimmte Datenpunkte unter bestimmten Bedingungen selektiv hervorgehoben oder ausgeblendet werden können. Dies kann dazu beitragen, die Aufmerksamkeit auf bestimmte Bereiche von Interesse oder Muster innerhalb des Datensatzes zu lenken.
Zuerst musst du eine boolesche Maske erstellen, die die gleiche Form hat wie deine Datenmatrix. Die Maske sollte True (oder False) für die Datenpunkte lauten, die du ausblenden (oder anzeigen) möchtest. Da die Korrelationsmatrix symmetrisch ist, können wir mit der Funktion numpy's triu eine Dreiecksmaske erstellen, die nur den oberen Teil unserer Heatmap abdeckt.
# Create a mask using numpy's triu function
mask = np.triu(np.ones_like(correlation_matrix, dtype=bool))Verwende den Parameter mask der Funktion seaborn.heatmap(), um deine Maske anzuwenden. Die Datenpunkte, die True in der Maske entsprechen, werden ausgeblendet.
# Create a masked heatmap
plt.figure(figsize = (10,8))
plt.rcParams.update({'font.size': 12})
sns.heatmap(correlation_matrix, cmap = 'viridis', vmin = -1, vmax = 1, center = 0, annot=True, fmt=".2f", square=True, linewidths=.5, mask = mask)
plt.show()
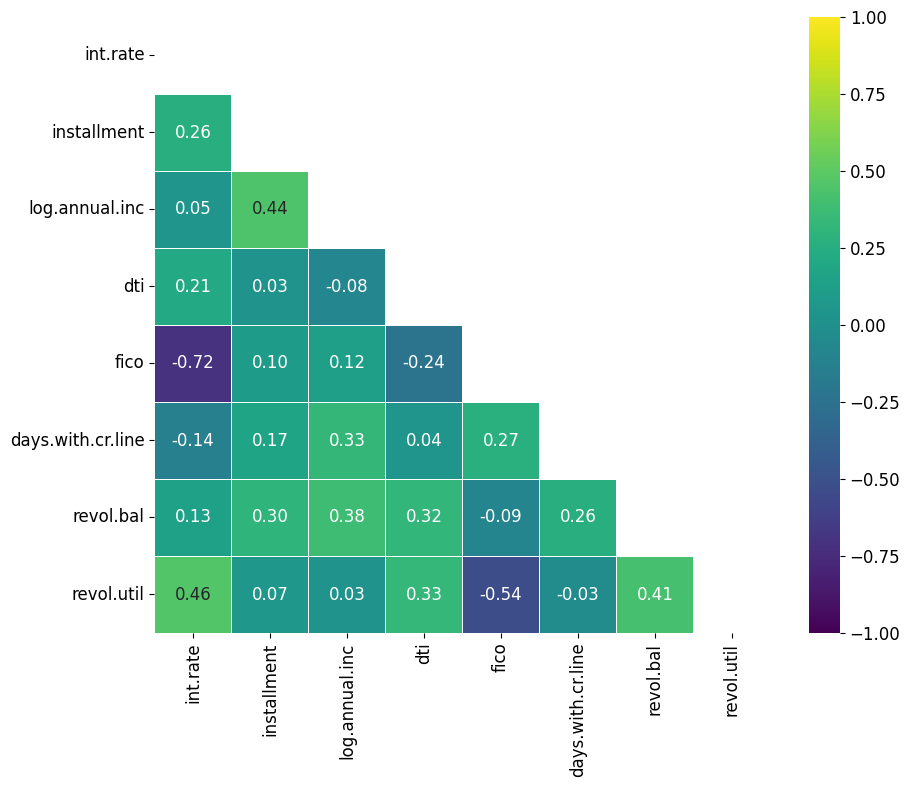
Wenn du dich an diese Best Practices hältst, kannst du mit Heatmaps von Seaborn auffällige Visualisierungen für deine Berichte und Präsentationen erstellen.
Hier sind fünf Best Practices, die du bei der Verwendung von Heatmaps von Seaborn beachten solltest:
Die Farbpalette, die du wählst, wirkt sich direkt darauf aus, wie deine Daten wahrgenommen werden. Verschiedene Farbschemata können Muster in deinen Daten hervorheben oder verschleiern.
Verwende sequenzielle Farbpaletten für Daten, die von niedrig zu hoch verlaufen, und divergierende Farbpaletten für Daten mit einem aussagekräftigen Mittelpunkt. Seaborn bietet mit dem Parameter cmap verschiedene Optionen, mit denen du das Farbschema an deinen Datensatz anpassen kannst.
Fehlende Daten können Lücken in deiner Heatmap verursachen, die den Betrachter in die Irre führen können.
Lege vor dem Plotten eine Strategie für den Umgang mit fehlenden Daten fest. Je nach Bedeutung der fehlenden Werte, kannst du sie entweder ergänzen oder ganz entfernen.
Alternativ können fehlende Daten mit einer bestimmten Farbe oder einem Muster dargestellt werden, ohne den Betrachter in die Irre zu führen.
Daten mit großen Abweichungen oder Ausreißern können die Visualisierung verzerren und es schwierig machen, festzustellen, ob die Daten Muster enthalten.
Normalisiere oder skaliere deine Daten, um sicherzustellen, dass die Heatmap die Unterschiede innerhalb des Datensatzes genau widerspiegelt. Je nach Beschaffenheit deiner Daten können Techniken wie Min-Max-Skalierung, Z-Score-Normalisierung oder sogar Log-Transformationen von Vorteil sein.
Anmerkungen können zwar wertvolle Details hinzufügen, indem sie genaue Werte anzeigen, aber wenn du deine Heatmap mit Anmerkungen überfüllst, kann sie schwer zu lesen sein, besonders bei großen Datensätzen.
Beschränke Anmerkungen auf wichtige Datenpunkte oder verwende sie in kleineren Heatmaps.
Das Standard-Seitenverhältnis und die Standard-Größe passen vielleicht nicht zu deinem Datensatz, was zu zerquetschten Zellen oder einer beengten Darstellung führt, die Muster verdeckt.
Passe die Größe und das Seitenverhältnis deiner Heatmap an, um sicherzustellen, dass jede Zelle deutlich sichtbar und das Gesamtmuster leicht zu erkennen ist.
Die Heatmap-Funktion von Seaborn ermöglicht eine auffällige Visualisierung von Datenmustern und ist besonders nützlich für die Darstellung von Korrelationen zwischen numerischen Variablen.
Es ist jedoch wichtig, die besten Praktiken zu befolgen. Dazu gehören die Wahl der richtigen Farbpalette, der sorgfältige Umgang mit fehlenden Daten, die richtige Skalierung der Daten, die sparsame Verwendung von Anmerkungen und die Anpassung der Abmessungen der Heatmap.
Hast du Lust, in die Seaborn-Bibliothek einzutauchen? Unser Kurs Einführung in die Datenvisualisierung mit Seaborn ist ideal für Anfänger. Wenn du schon fortgeschrittener bist, kannst du dein Wissen in unserem Kurs Datenvisualisierung mit Seaborn für Fortgeschrittene vertiefen.
Beginne deine Seaborn-Reise noch heute!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
