
Kurs
Datenvisualisierung in Google Sheets
4 Std.
45.8K
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Beginnen wir mit den gebräuchlichsten Datendiagrammen, die in vielen Bereichen weit verbreitet sind und in den meisten Python-Datenvisualisierungsbibliotheken erstellt werden können (mit Ausnahme einiger sehr eng spezialisierter Bibliotheken).
Ein Balkendiagramm ist die gebräuchlichste Datenvisualisierung, um die numerischen Werte kategorischer Daten darzustellen und verschiedene Kategorien miteinander zu vergleichen. Die Kategorien werden durch rechteckige Balken gleicher Breite dargestellt, deren Höhe (bei vertikalen Balkendiagrammen) oder Länge (bei horizontalen Balkendiagrammen) proportional zu den Zahlenwerten ist, denen sie entsprechen.
Um ein einfaches Balkendiagramm in Matplotlib zu erstellen, verwenden wir die Funktion matplotlib.pyplot.bar(), wie folgt:
# Data preparation
penguins_grouped = penguins[['species', 'bill_length_mm']].groupby('species').mean().reset_index()
# Creating a bar chart
plt.bar(penguins_grouped['species'], penguins_grouped['bill_length_mm'])
plt.title('Average penguin bill length by species')
plt.show()
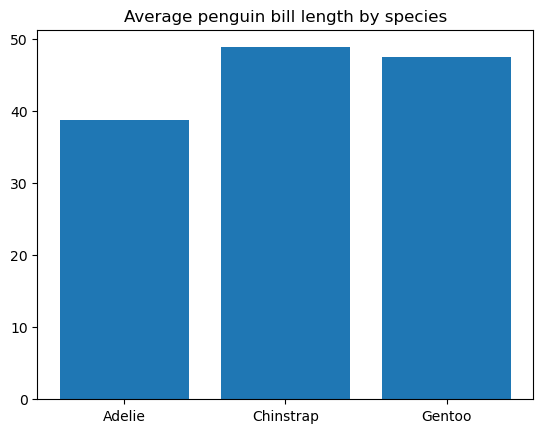
Wir können die Breite und Farbe der Balken, die Breite und Farbe der Balkenränder, die Beschriftung der Balken mit Häkchen, das Füllen der Balken mit Mustern usw. weiter anpassen.
Wenn du wissen willst, wie du mit Matplotlib arbeitest, wirf einen Blick auf unser Matplotlib Cheat Sheet: Plotten in Python.
Ein Liniendiagramm ist eine Art von Datendiagramm, das den Verlauf einer Variablen von links nach rechts entlang der X-Achse durch Datenpunkte zeigt, die durch gerade Liniensegmente verbunden sind. In der Regel wird die Veränderung einer Variable im Laufe der Zeit aufgezeichnet. Tatsächlich werden Liniendiagramme häufig zur Visualisierung von Zeitreihen verwendet, wie im Tutorial zu Matplotlib-Zeitreihen-Liniendiagrammen beschrieben.
Wir können ein einfaches Liniendiagramm in matplotlib erstellen, indem wir die Funktion matplotlib.pyplot.plot() verwenden, wie folgt:
# Data preparation
flights_grouped = flights[['year', 'passengers']].astype({'year': 'string'}).groupby('year').sum().reset_index()
# Creating a line plot
plt.plot(flights_grouped['year'], flights_grouped['passengers'])
plt.title('Total number of passengers by year')
plt.show()
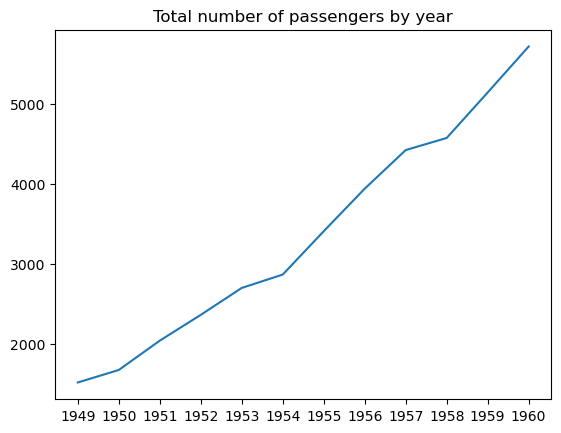
Es ist möglich, die Linienbreite, den Stil, die Farbe und die Transparenz anzupassen, Markierungen hinzuzufügen und zu verändern usw.
Das Tutorial zu Liniendiagrammen in MatplotLib mit Python enthält weitere Erklärungen und Beispiele, wie man ein Liniendiagramm in MatplotLib erstellt und anpasst. Um zu erfahren, wie du einen Liniendiagramm in Seaborn erstellst und anpasst, lies Python Seaborn Line Plot Tutorial: Datenvisualisierungen erstellen.
Ein Streudiagramm ist eine Art der Datenvisualisierung, bei der die Beziehungen zwischen zwei Variablen in Form von Datenpunkten auf der Koordinatenebene aufgetragen werden. Diese Art von Datendiagramm wird verwendet, um zu prüfen, ob die beiden Variablen miteinander korrelieren, wie stark diese Korrelation ist und ob es in den Daten verschiedene Cluster gibt.
Der folgende Code zeigt, wie du mit der Funktion matplotlib.pyplot.scatter() ein einfaches Streudiagramm in matplotlib erstellen kannst:
# Creating a scatter plot
plt.scatter(penguins['bill_length_mm'], penguins['bill_depth_mm'])
plt.title('Penguin bill length vs. bill depth')
plt.show()
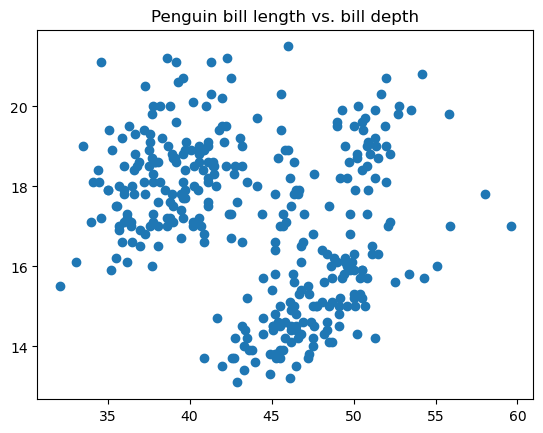
Wir können die Punktgröße, den Stil, die Farbe, die Transparenz, die Randbreite, die Randfarbe usw. anpassen.
In diesem Tutorial erfährst du mehr über Streudiagramme (und nicht nur!): Daten entmystifiziert: Datenvisualisierungen, die Zusammenhänge erfassen.
Ein Histogramm ist eine Art von Datendiagramm, das die Häufigkeitsverteilung der Werte einer numerischen Variable darstellt. Es unterteilt die Daten in Wertebereichsgruppen, die Bins genannt werden, zählt die Anzahl der Punkte, die zu jedem Bin gehören, und zeigt jedes Bin als vertikalen Balken an, wobei die Höhe proportional zum Zählwert für dieses Bin ist. Ein Histogramm kann als eine besondere Art von Balkendiagramm betrachtet werden, nur dass die benachbarten Balken ohne Lücken aneinandergefügt werden, da die Bins kontinuierlich sind.
Wir können ein einfaches Histogramm in Matplotlib mit der Funktion matplotlib.pyplot.hist() erstellen:
# Creating a histogram
plt.hist(penguins['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
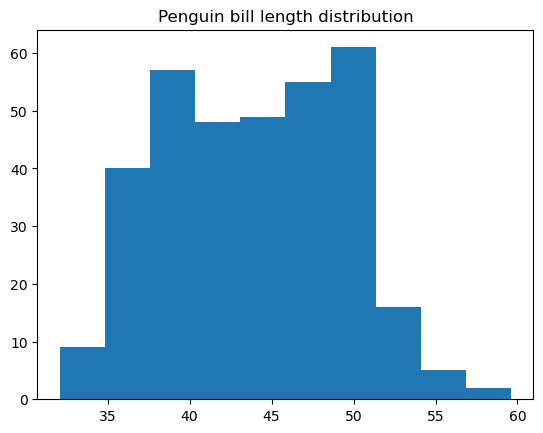
Es ist möglich, viele Dinge in dieser Funktion anzupassen, z. B. die Farbe und den Stil des Histogramms, die Anzahl der Bins, die Bin-Ränder, den unteren und oberen Bereich der Bins, ob das Histogramm regelmäßig oder kumulativ ist, usw.
In der Anleitung zum Erstellen eines Histogramms mit Plotly kannst du eine andere Möglichkeit kennenlernen, ein Histogramm in Python zu erstellen.
Ein Boxplot ist ein Datendiagramm, das eine Reihe von fünf deskriptiven Statistiken der Daten zeigt: die Minimal- und Maximalwerte (ohne Ausreißer), den Median und das erste und dritte Quartil. Optional kann er auch den Mittelwert anzeigen. Ein Boxplot ist die richtige Wahl, wenn du nur an diesen Statistiken interessiert bist, ohne die tatsächliche Verteilung der Daten zu untersuchen.
Im Tutorial zu 11 Datenvisualisierungstechniken für jeden Anwendungsfall mit Beispielen findest du unter anderem genauere Erklärungen dazu, welche Art von statistischen Informationen du aus einem Boxplot gewinnen kannst.
Mit der Funktion matplotlib.pyplot.boxpot() können wir in matplotlib ein einfaches Boxplot erstellen, siehe unten:
# Data preparation
penguins_cleaned = penguins.dropna()
# Creating a box plot
plt.boxplot(penguins_cleaned['bill_length_mm'])
plt.title('Penguin bill length distribution')
plt.show()
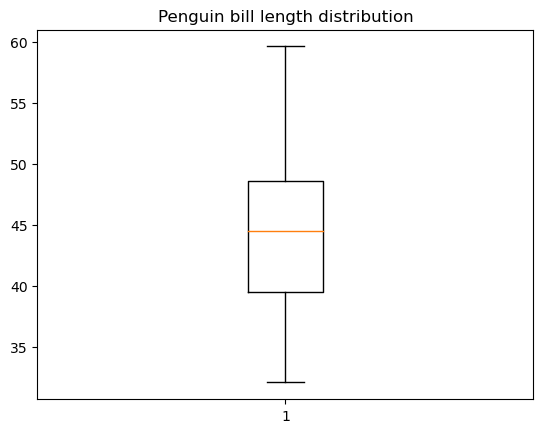
Es gibt viele Möglichkeiten, ein Boxplot anzupassen: die Breite und Ausrichtung der Box, die Position der Box und der Whisker, die Sichtbarkeit und der Stil der verschiedenen Boxplot-Elemente usw.
Um mit dieser Funktion ein Boxplot zu erstellen, müssen wir zunächst sicherstellen, dass die Daten keine fehlenden Werte enthalten. Im obigen Beispiel haben wir die fehlenden Werte aus den Daten entfernt, bevor wir sie gezeichnet haben. Zum Vergleich: Die Seaborn-Bibliothek hat diese Einschränkung nicht und behandelt fehlende Werte hinter den Kulissen, wie unten beschrieben:
# Creating a box plot
sns.boxplot(data=penguins, y='bill_length_mm')
plt.title('Penguin bill length distribution')
plt.show()
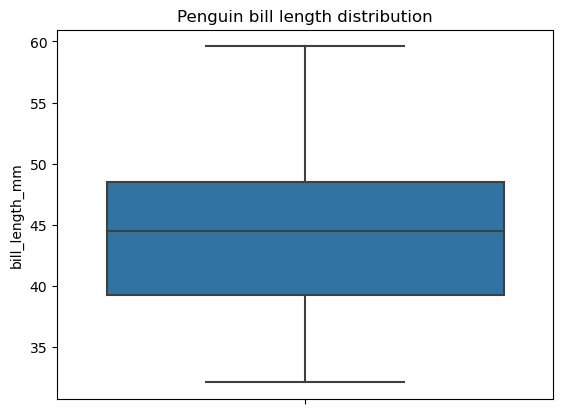
Ein Tortendiagramm ist eine Art der Datenvisualisierung, die durch einen in Sektoren unterteilten Kreis dargestellt wird, wobei jeder Sektor einer bestimmten Kategorie der kategorialen Daten entspricht und der Winkel jedes Sektors den Anteil dieser Kategorie am Ganzen widerspiegelt. Im Gegensatz zu Balkendiagrammen sollen Tortendiagramme die Kategorien darstellen, die das Ganze ausmachen, z.B. die Passagiere eines Schiffes.
Kreisdiagramme haben einige Nachteile:
Daher sollten Kreisdiagramme sparsam und mit Vorsicht verwendet werden.
Um ein einfaches Tortendiagramm in Matplotlib zu erstellen, müssen wir die Funktion matplotlib.pyplot.pie() wie folgt anwenden:
# Data preparation
titanic_grouped = titanic.groupby('class')['pclass'].count().reset_index()
# Creating a pie chart
plt.pie(titanic_grouped['pclass'], labels=titanic_grouped['class'])
plt.title('Number of passengers by class')
plt.show()
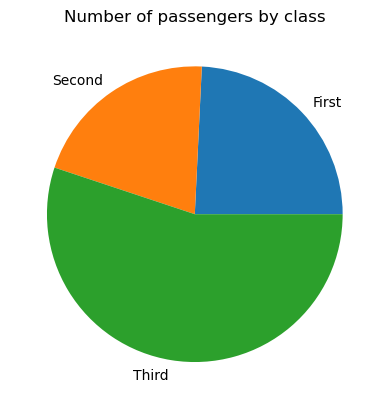
Bei Bedarf können wir unser Kreisdiagramm anpassen: die Farben der Keile ändern, einen Versatz zu einigen (meist sehr kleinen) Keilen hinzufügen, den Kreisradius ändern, das Format der Beschriftungen anpassen, einige oder alle Keile mit Mustern füllen, usw.
In diesem Abschnitt werden wir verschiedene erweiterte Datendiagramme untersuchen. Einige von ihnen stellen eine ausgefallene Variante der gängigen Arten von Datenvisualisierungen dar, die wir im vorherigen Abschnitt betrachtet haben, andere sind einfach eigenständige Typen.
Während ein gewöhnliches Balkendiagramm dazu verwendet wird, die numerischen Werte einer kategorialen Variable nach Kategorie darzustellen, dient ein gruppiertes Balkendiagramm demselben Zweck, allerdings für zwei kategoriale Variablen. Grafisch bedeutet das, dass wir mehrere Gruppen von Balken haben, wobei jede Gruppe mit einer bestimmten Kategorie einer Variablen und jeder Balken dieser Gruppen mit einer bestimmten Kategorie der zweiten Variablen verbunden ist. Gruppierte Balkendiagramme funktionieren am besten, wenn die zweite Variable nicht mehr als drei Kategorien hat. Im umgekehrten Fall werden sie zu voll und damit weniger hilfreich.
Wie ein gewöhnliches Balkendiagramm können wir auch ein gruppiertes Balkendiagramm mit Matplotlib erstellen. Die Seaborn-Bibliothek bietet jedoch mit der Funktion seaborn.barplot() eine bequemere Möglichkeit, solche Plots zu erstellen. Schauen wir uns ein Beispiel für die Erstellung eines einfachen gruppierten Balkendiagramms für die Schnabellänge von Pinguinen mit zwei kategorialen Variablen an: Art und Geschlecht.
# Creating a grouped bar chart
sns.barplot(data=penguins, x='species', y='bill_length_mm', hue='sex')
plt.title('Penguin bill length by species and sex')
plt.show()
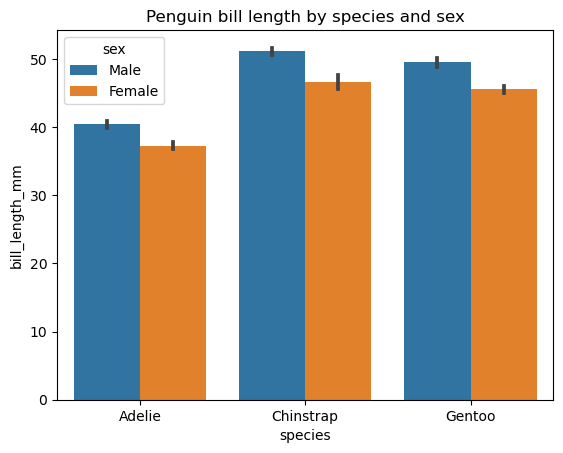
Die zweite kategoriale Variable wird durch den Parameter hue eingeführt. Andere optionale Parameter dieser Funktion ermöglichen es, die Ausrichtung, Breite und Farbe der Balken, die Reihenfolge der Kategorien, den statistischen Schätzer usw. zu ändern.
Um tiefer in das Plotten mit Seaborn einzutauchen, solltest du den folgenden Kurs besuchen: Intermediate Data Visualization with Seaborn.
Ein gestapeltes Flächendiagramm ist eine Erweiterung eines gewöhnlichen Flächendiagramms (das einfach ein Liniendiagramm ist, bei dem der Bereich unterhalb der Linie gefärbt oder mit einem Muster gefüllt ist) mit mehreren übereinander gestapelten Bereichen, die jeweils einer bestimmten Variable entsprechen. Solche Diagramme sind nützlich, wenn wir sowohl den Gesamtfortschritt einer Reihe von Variablen als auch den individuellen Beitrag jeder Variablen zu diesem Fortschritt verfolgen müssen. Wie Liniendiagramme spiegeln auch gestapelte Flächendiagramme in der Regel die Veränderung von Variablen im Laufe der Zeit wider.
Es ist wichtig, die wichtigste Einschränkung von gestapelten Bereichsdiagrammen zu beachten: Sie helfen vor allem dabei, den allgemeinen Trend zu erfassen, aber nicht die genauen Werte für die gestapelten Bereiche.
Um ein einfaches gestapeltes Flächendiagramm in Matplotlib zu erstellen, verwenden wir die matplotlib.pyplot.stackplot Funktion, wie unten dargestellt:
# Data preparation
flights_grouped = flights.groupby(['year', 'month']).mean().reset_index()
flights_49_50 = pd.DataFrame(list(zip(flights_grouped.loc[:11, 'month'].tolist(), flights_grouped.loc[:11, 'passengers'].tolist(), flights_grouped.loc[12:23, 'passengers'].tolist())), columns=['month', '1949', '1950'])
# Creating a stacked area chart
plt.stackplot(flights_49_50['month'], flights_49_50['1949'], flights_49_50['1950'], labels=['1949', '1950'])
plt.title('Number of passengers in 1949 and 1950 by month')
plt.legend()
plt.show()
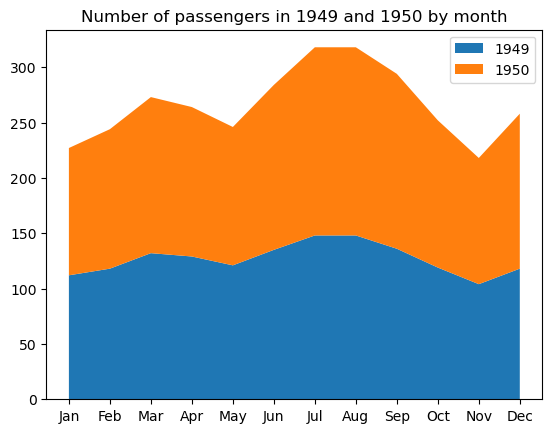
Einige anpassbare Eigenschaften dieser Art von Diagramm sind die Farben der Flächen, die Transparenz, die Füllmuster, die Linienbreite, der Stil, die Farbe, die Transparenz usw.
Im Abschnitt über gängige Arten von Datendiagrammen haben wir einen Kastentopf als eine Art der Datenvisualisierung definiert, die eine Reihe von fünf deskriptiven Statistiken der Daten zeigt. Manchmal möchten wir diese Statistiken für jede Kategorie einer kategorialen Variable getrennt anzeigen und vergleichen. In solchen Fällen müssen wir mehrere Boxen auf der gleichen Plotfläche darstellen, was wir mit der Funktion seaborn.boxplot() ganz einfach tun können, wie folgt:
# Creating multiple box plots
sns.boxplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
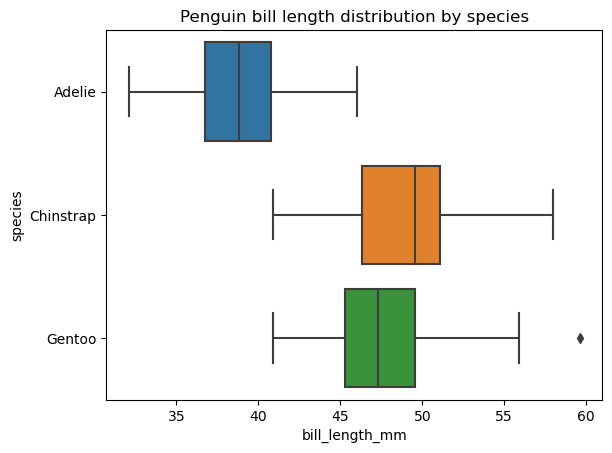
Es ist möglich, die Reihenfolge der Box-Plots, ihre Ausrichtung, Farbe, Transparenz, Breite und die Eigenschaften der verschiedenen Elemente zu ändern, eine weitere kategoriale Variable auf der Plotfläche hinzuzufügen, usw.
Ein Violindiagramm ähnelt einem Boxdiagramm und zeigt dieselben Gesamtstatistiken der Daten an, mit dem Unterschied, dass es auch die Verteilungsform für diese Daten anzeigt. Wie bei Box Plots können wir einen einzelnen Violin Plot für die interessierenden Daten erstellen oder, was häufiger vorkommt, mehrere Violin Plots, jeweils für eine separate Kategorie einer kategorialen Variable.
Seaborn bietet mehr Möglichkeiten zum Erstellen und Anpassen von Geigenplots als matplotlib. Um ein einfaches Geigenbild in Seaborn zu erstellen, müssen wir die Funktion seaborn.violinplot() anwenden, wie unten beschrieben:
Creating a violin plot
sns.violinplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
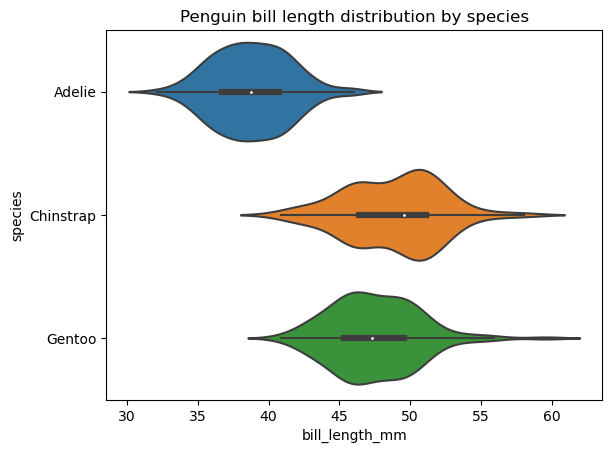
Wir können die Reihenfolge der Geigen, ihre Ausrichtung, Farbe, Transparenz, Breite und die Eigenschaften ihrer verschiedenen Elemente ändern, die Verteilung über die extremen Datenpunkte hinaus erweitern, eine weitere kategoriale Variable auf der Plotfläche hinzufügen, die Art und Weise auswählen, wie die Datenpunkte im Inneren der Geige dargestellt werden, usw.
Eine Heatmap ist eine tabellenartige Datenvisualisierung, bei der jeder numerische Datenpunkt auf der Grundlage einer ausgewählten Farbskala und entsprechend der Größe des Datenpunkts innerhalb des Datensatzes dargestellt wird. Die Hauptidee hinter diesen Diagrammen ist es, potenzielle heiße und kalte Stellen in den Daten zu veranschaulichen, die besondere Aufmerksamkeit erfordern könnten.
In vielen Fällen müssen die Daten vorverarbeitet werden, bevor eine Heatmap für sie erstellt werden kann. Das bedeutet in der Regel, dass die Daten bereinigt und normalisiert werden müssen.
Der folgende Code zeigt, wie du eine einfache Heatmap (nach der notwendigen Datenvorverarbeitung) mit der Funktion seaborn.heatmap() erstellst:
# Data preparation
from sklearn import preprocessing
car_crashes_cleaned = car_crashes.drop(labels='abbrev', axis=1).iloc[0:10]
min_max_scaler = preprocessing.MinMaxScaler()
car_crashes_normalized = pd.DataFrame(min_max_scaler.fit_transform(car_crashes_cleaned.values), columns=car_crashes_cleaned.columns)
# Creating a heatmap
sns.heatmap(car_crashes_normalized, annot=True)
plt.title('Car crash heatmap for the first 10 car crashes')
plt.show()
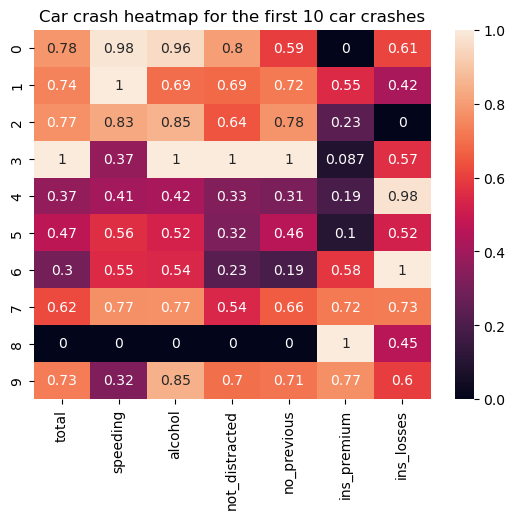
Zu den möglichen Anpassungen gehören die Auswahl einer Farbkarte, die Festlegung der Ankerwerte, die Formatierung von Anmerkungen, die Anpassung der Trennlinien, die Anwendung einer Maske usw.
Zum Schluss wollen wir noch einen Blick auf einige selten genutzte oder sogar weniger bekannte Arten von Datenvisualisierungen werfen. Viele von ihnen haben mindestens eine Entsprechung unter den bekannteren Arten von Diagrammen. In einigen besonderen Fällen können diese unkonventionellen Datenvisualisierungen jedoch effizienter sein als die üblichen Darstellungen.
Ein Stemplot ist praktisch eine andere Art, ein Balkendiagramm darzustellen, nur dass er statt aus festen Balken aus dünnen Linien mit (optionalen) Markierungen auf jedem von ihnen besteht. Auch wenn ein Stammdiagramm wie eine überflüssige Variante eines Balkendiagramms aussieht, ist es doch die bessere Alternative, wenn es darum geht, viele Kategorien zu visualisieren. Der Vorteil von Stammdiagrammen gegenüber Balkendiagrammen ist, dass sie ein besseres Verhältnis von Daten zu Tinte und damit eine bessere Lesbarkeit haben.
Um ein einfaches Stammdiagramm in matplotlib zu erstellen, verwenden wir die Funktion matplotlib.pyplot.stem(), wie folgt:
# Data preparation
fmri_grouped = fmri.groupby('subject')[['subject', 'signal']].max()
# Creating a stem plot
plt.stem(fmri_grouped['subject'], fmri_grouped['signal'])
plt.title('FMRI maximum signal by subject')
plt.show()
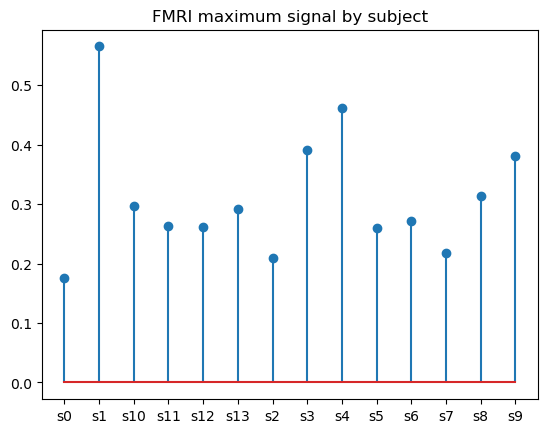
Wir können mit den optionalen Parametern der Funktion spielen, um die Stammausrichtung zu ändern und die Eigenschaften von Stamm, Grundlinie und Markierung anzupassen.
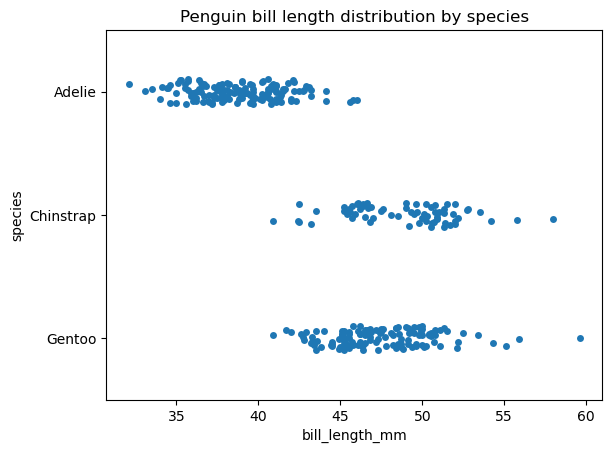
Diese beiden sehr ähnlichen Arten der Datenvisualisierung können als eine Implementierung eines Streudiagramms für eine kategoriale Variable betrachtet werden: Sowohl Streifen- als auch Schwarmdiagramme zeigen das Innere der Datenverteilung an, einschließlich der Stichprobengröße und der Position der einzelnen Datenpunkte, aber ohne beschreibende Statistiken. Der Hauptunterschied zwischen diesen Diagrammen besteht darin, dass sich die Datenpunkte in einem Streifendiagramm überschneiden können, während dies in einem Schwarmdiagramm nicht der Fall ist. In einem Schwarmdiagramm werden die Datenpunkte stattdessen entlang der kategorialen Achse ausgerichtet.
Beachte, dass sowohl Streifen- als auch Schwarmdiagramme nur für relativ kleine Datensätze hilfreich sind.
Hier siehst du, wie du mit der Funktion seaborn.stripplot() einen Streifenplan erstellen kannst:
# Creating a strip plot
sns.stripplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
Erstellen wir nun ein Schwarmdiagramm mit der Funktion seaborn.swarmplot() für die gleichen Daten und beobachten wir den Unterschied:
# Creating a swarm plot
sns.swarmplot(data=penguins, x='bill_length_mm', y='species')
plt.title('Penguin bill length distribution by species')
plt.show()
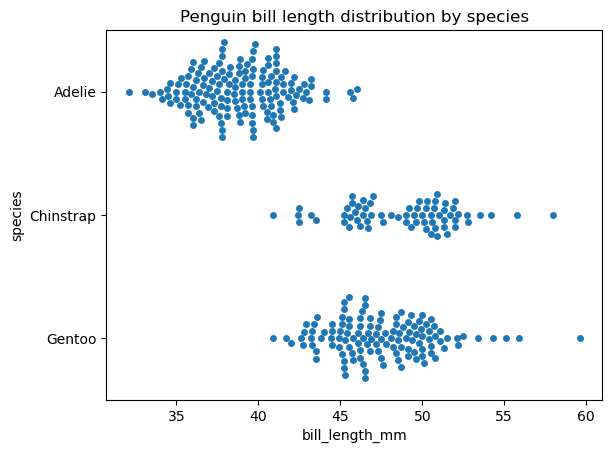
Die Funktionen seaborn.stripplot() und seaborn.swarmplot() haben eine sehr ähnliche Syntax. Einige anpassbare Eigenschaften in beiden Funktionen sind die Reihenfolge und die Ausrichtung des Plots sowie die Eigenschaften der Marker, wie z. B. Stil, Größe, Farbe, Transparenz usw. Es ist erwähnenswert, dass die Regulierung der Marker-Transparenz dazu beiträgt, das Problem der Punktüberlappung in einem Streifenplot teilweise zu lösen.
Eine Baumkarte ist eine Art von Datendiagramm, mit dem die numerischen Werte der kategorialen Daten nach Kategorie als eine Reihe von Rechtecken innerhalb eines rechteckigen Rahmens dargestellt werden, wobei die Fläche jedes Rechtecks proportional zum Wert der entsprechenden Kategorie ist. Von ihrem Zweck her sind Baumdiagramme identisch mit Balken- und Kreisdiagrammen. Wie Kreisdiagramme sollen sie vor allem die Kategorien darstellen, die das Ganze ausmachen. Baumdiagramme können effektiv und überzeugend aussehen, wenn es bis zu zehn Kategorien gibt, die sich in ihren Zahlenwerten deutlich unterscheiden.
Die Nachteile von Baumdiagrammen sind denen von Kreisdiagrammen sehr ähnlich:
Wir sollten diese Punkte im Hinterkopf behalten und Treemaps nur sparsam und nur dann einsetzen, wenn sie am besten funktionieren.
Um eine Baumkarte in Python zu erstellen, müssen wir zuerst die Squarify-Bibliothek installieren und importieren: pip install squarify, dann import squarify. Der folgende Code erstellt eine einfache Baumstruktur:
import squarify
# Data preparation
diamonds_grouped = diamonds[['cut', 'price']].groupby('cut').mean().reset_index()
# Creating a treemap
squarify.plot(sizes=diamonds_grouped['price'], label=diamonds_grouped['cut'])
plt.title('Average diamond price by cut')
plt.show()
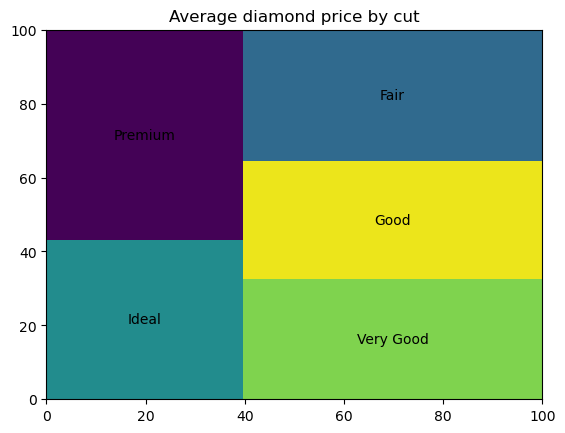
Wir können die Farben und die Transparenz der Rechtecke anpassen, sie mit Mustern füllen, die Eigenschaften der Rechteckkanten anpassen, einen kleinen Abstand zwischen den Rechtecken einfügen und die Eigenschaften des Beschriftungstextes einstellen.
Es gibt noch eine andere Möglichkeit, eine Baumkarte in Python zu erstellen - mit Hilfe der Plotly-Bibliothek. Mehr darüber erfährst du im Lernprogramm Was ist Datenvisualisierung? Ein Leitfaden für Data Scientists.
Eine Wortwolke ist eine Art der Textdatenvisualisierung, bei der die Schriftgröße jedes Wortes der Häufigkeit seines Auftretens in einem Eingabetext entspricht. Die Verwendung von Wortwolken hilft dabei, die wichtigsten Wörter in einem Text zu finden.
Wortwolken sind zwar immer ein Blickfang und intuitiv verständlich für jede Art von Zielgruppe, aber wir sollten uns über einige Einschränkungen dieser Art von Datendiagrammen im Klaren sein:
Eine interessante und weniger bekannte Anwendung von Wortwolken ist, dass wir sie nicht anhand der Worthäufigkeit, sondern anhand eines beliebigen anderen Attributs, das jedem Wort zugeordnet ist, erstellen können. Wir können zum Beispiel ein Wörterbuch mit Ländern erstellen, jedem Land den Wert seiner Bevölkerung zuweisen und diese Daten anzeigen.
Um eine Wortwolke in Python zu erstellen, müssen wir eine spezielle Wortwolken-Bibliothek verwenden. Zuerst müssen wir sie installieren (pip install wordcloud), dann die Klasse WordCloud und die Stoppwörter importieren: from wordcloud import WordCloud, STOPWORDS. Der folgende Code erzeugt eine einfache Wortwolke:
from wordcloud import WordCloud, STOPWORDS
text = 'cat cat cat cat cat cat dog dog dog dog dog panda panda panda panda koala koala koala rabbit rabbit fox'
# Creating a word cloud
wordcloud = WordCloud().generate(text)
plt.imshow(wordcloud)
plt.title('Words by their frequency in the text')
plt.axis('off')
plt.show()

Es ist möglich, die Abmessungen einer Wortwolke anzupassen, ihre Hintergrundfarbe zu ändern, eine Farbkarte für die Anzeige von Wörtern zuzuweisen, horizontale Wörter gegenüber vertikalen zu bevorzugen, die maximale Anzahl der angezeigten Wörter zu begrenzen, die Liste der Stoppwörter zu aktualisieren, die Schriftgrößen zu begrenzen, Wortkollokationen zu berücksichtigen, die Reproduzierbarkeit der Grafik sicherzustellen usw.
Wenn du mehr über Wortwolken in Python erfahren möchtest, findest du hier eine gute Lektüre: Erzeugen von Wortwolken in Python Tutorial. Du kannst auch eine kostenlose Vorlage verwenden, um die Erstellung dieser Art von Datenvisualisierungen zu üben: Vorlage: Erstelle eine Wortwolke.
Beginne deine Reise zur Datenvisualisierung noch heute!
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui
Tutorial
Moez Ali

