
Lernpfad
Containerisierung und Virtualisierung mit Docker und Kubernetes
13 Std.
Ich habe echt viel Zeit damit verbracht, Docker-Container in Entwicklungs- und Produktionsumgebungen manuell zu verwalten. Nicht passende Konfigurationen, abweichende Zustände und die Unsicherheit, ob meine lokale Einrichtung mit der Produktion übereinstimmte, haben jede Bereitstellung erschwert. Als ich den Docker-Anbieter von Terraform entdeckt habe, hat sich alles verändert.
In diesem Tutorial zeige ich dir, wie du Terraform mit Docker integrierst, um eine reproduzierbare, versionskontrollierte Infrastruktur zu erstellen. Du lernst, wie du Container bereitstellst, Netzwerke und Volumes verwaltest, Ressourcenbeschränkungen umsetzt und den Status in deinem Team aufrechterhältst.
Egal, ob du Build-Server verwaltest oder Microservices orchestrierst – schnapp dir dein Terminal und lass uns gemeinsam die Art und Weise verändern, wie du mit der Docker-Infrastruktur umgehst.
Wenn du noch keine Erfahrung mit Docker hast, empfehle ich dir, mit unserem Kurs „Einführung in Docker“ zu beginnen.
Terraform ist ein Tool für Infrastructure-as-Code, das den Lebenszyklus von Ressourcen über einen deklarativen Workflow verwaltet. Anstatt einzelne Docker-Befehle auszuführen, legst du den gewünschten Zustand der Infrastruktur in Konfigurationsdateien fest. Terraform macht dann einen Plan-Anwenden-Löschen-Zyklus durch: Es rechnet die nötigen Änderungen aus, zeigt eine Vorschau und macht sie erst nach der Freigabe.
Der Terraform Docker-Provid-er ist die Übersetzungsschicht zwischen dem HashiCorp Configuration Language (HCL)-Code und der Docker-API. Wenn du in einer Konfiguration „ resource “docker_container" “ schreibst, macht der Anbieter aus dieser Angabe die passenden Docker-API-Aufrufe. Durch diese Abstraktion kannst du Docker-Ressourcen mit dem gleichen Workflow verwalten, den du auch für die Cloud-Infrastruktur benutzt.
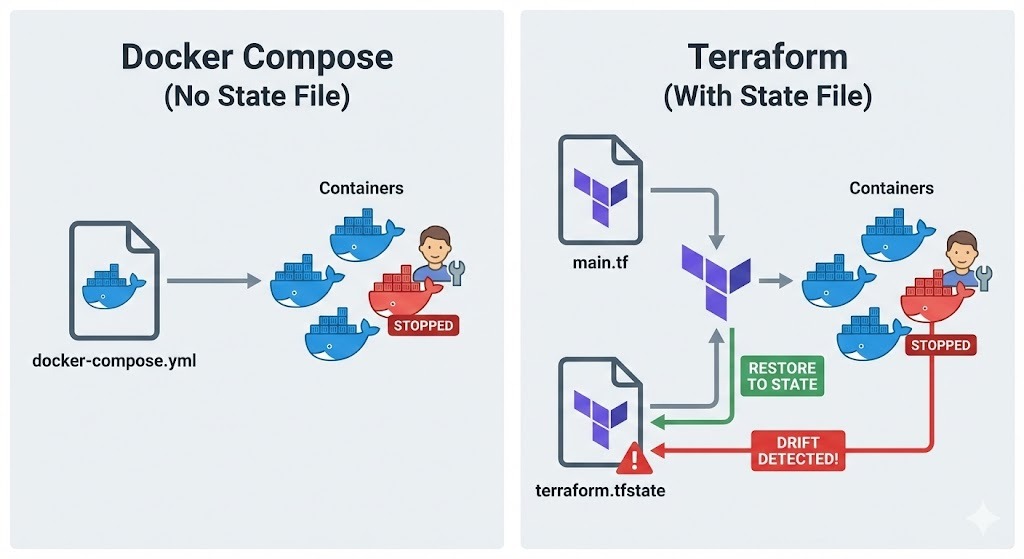
Hier unterscheidet sich Terraform von Docker Compose.
Compose verwaltet Container zwar über einen projektbasierten Ansatz mit YAML-Dateien, aber es gibt keine Statusdatei, die nachverfolgt, was wirklich da ist.
Terraform hingegen speichert jede Ressource, die es erstellt, in „ terraform.tfstate “, sodass es Abweichungen zwischen meiner Konfiguration und der Realität erkennen kann. Wenn jemand einen Container manuell ändert, merkt Terraform das und kann ihn wieder in den vorher festgelegten Zustand bringen.
Dieser Ansatz ist in verschiedenen Situationen super:
Bevor wir uns mit den Terraform-Konfigurationen beschäftigen, checken wir mal, ob die benötigten Tools installiert und richtig eingerichtet sind.
Schau erst mal nach, ob die Docker Engine auf deinem Rechner läuft.
Linux: Frag mal bei docker ps
macOS oder Windows: Stell sicher, dass Docker Desktop installiert ist und läuft.
Der Terraform-Anbieter braucht Zugriff auf den Docker-Daemon. Du musst also sicherstellen, dass dein Benutzer die Berechtigung hat, auf den Unix-Socket unter /var/run/docker.sock unter Linux oder die Named Pipe unter Windows zuzugreifen.
Als Nächstes installierst du die Terraform-CLI von der offiziellen Website von HashiCorp. Die Installation von Terraform hängt vomBetriebssystem ab:
Linux: Lade das passende Paket runter oder nutze den Paketmanager deiner Distribution.
macOS: Benutz Homebrew. Installiere zuerst den HashiCorp-Tap mit dem Befehl „ brew tap hashicorp/tap “ und dann Terraform mit dem Befehl „ brew install hashicorp/tap/terraform “.
Windows: Lade die Binärdatei von hashicorp.com runter und füge sie zu deinem PATH hinzu oder nutze Chocolatey: choco install terraform.
Nach der Installation überprüfe, ob alles richtig läuft, indem du „ terraform version “ startest.
Nachdem Docker und Terraform überprüft wurden, geht's jetzt darum, die Projektdateien so zu organisieren, dass sie leicht zu pflegen sind.
Terraform-Projekte profitieren von einem klaren und strukturierten Ansatz. Normalerweise mache ich ein eigenes Verzeichnis für mein Terraform-Projekt und starte die Versionskontrolle:
mkdir terraform-docker-project
cd terraform-docker-project
git initVersionskontrolle ist für Infrastructure-as-Code echt wichtig. Jede Änderung an der Docker-Infrastruktur sollte nachverfolgt, überprüft und rückgängig gemacht werden können. Normalerweise füge ich die Arbeitsverzeichnis- und Statusdateien von Terraform zurDatei „“ oder „ .gitignore “ hinzu,um sie aus der Versionskontrolle rauszuhalten:
.terraform/
*.tfstate
*.tfstate.backup
.terraform.lock.hclZum Schluss erstelle ich eine leere Datei namens „ main.tf “, in der ich meine Infrastruktur festlegen werde. Diese Datei enthält die Konfiguration des Anbieters und die Ressourcendefinitionen.
Nachdem die Projektstruktur fertig ist, ist es Zeit, den Docker-Anbieter einzurichten und mit der Definition der Ressourcen zu beginnen.
Zuerst fügen wir die Provider-Konfiguration zu „ main.tf “ hinzu:
terraform {
required_providers {
docker = {
source = "kreuzwerker/docker"
version = "~> 3.0"
}
}
}
provider "docker" {
host = "unix:///var/run/docker.sock"
}Der Block „ required_providers “ sagt Terraform, wo es das Provider-Plugin runterladen soll. Mit Versionsbeschränkungen (~> 3.0) kannst du kleinere Versions-Updates machen und gleichzeitig größere Änderungen vermeiden. Für entfernte Docker-Hosts kannst du den Parameter „ host “ in etwas wie „ tcp://192.168.1.100:2376 “ ändern.
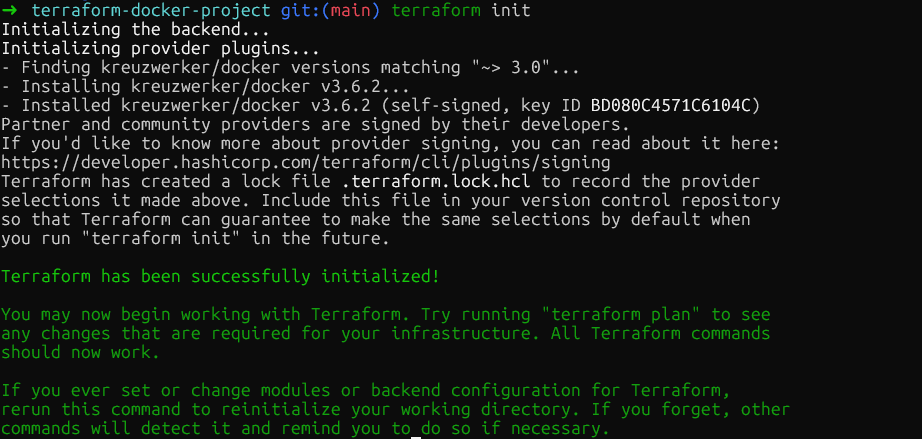
Jetzt starte mal „ terraform init “ im Stammverzeichnis des Projekts. Damit wird das Docker-Provider-Plugin runtergeladen und in „ .terraform/providers/ “ gespeichert. Der Befehl zeigt die genaue installierte Version an, und Terraform erstellt eine Sperrdatei, um sicherzustellen, dass alle in meinem Team die gleiche Provider-Version haben.
Nachdem der Anbieter eingerichtet ist, musst du als Nächstes die Container-Images festlegen. Bevor du Container erstellst, musst du die Images verwalten, die sie verwenden werden. Dazu musst du eine Image-Ressource definieren:
resource "docker_image" "nginx" {
name = "nginx:1.29"
keep_locally = true
}Füge diese Ressource direkt nach dem Provider-Block ein. Der Parameter „ keep_locally “ ist wichtig, weil er verhindert, dass Terraform das Image löscht, wenn ich „ terraform destroy “ ausführe. Das ist praktisch, wenn mehrere Container dasselbe Image nutzen oder wenn ich zwischengespeicherte Images zwischen den Bereitstellungen behalten will.
Für Produktionsbereitstellungen solltest du Images anhand ihres SHA256-Digests fixieren, um Unveränderlichkeit sicherzustellen:
resource "docker_image" "nginx" {
name = "nginx@sha256:b60f25eb5acdd79172de1a289891d9cfe4fc3669daddeeb68619240cbe839d9f"
}Der Digest kann aus der Container-Registrierung geholt werden. Bilder für Docker Hub wie nginx findest du auf der offiziellen Docker-Website im Abschnitt „Tags“. Digests sorgen dafür, dass immer genau dieselbe Image-Binärdatei eingesetzt wird, auch wenn jemand einneues Image mit demselben Tag hochlädt.
Sobald die Bilder definiert sind, geht's weiter mit dem Erstellen von Containern, die auf sie verweisen:
resource "docker_container" "web" {
name = "nginx-web"
image = docker_image.nginx.image_id
ports {
internal = 80
external = 8080
}
env = [
"NGINX_HOST=example.com",
"NGINX_PORT=80"
]
}Das Bild wird über docker_image.nginx.image_id referenziert. Das führt zu einer versteckten Abhängigkeit, weil Terraform erst dann versucht, den Container zu erstellen, wenn das Image da ist. Der Block „ ports ” verbindet den internen Port 80 des Containers mit dem Port 8080 meines Hosts, was docker run -p 8080:80 entspricht.
Umgebungsvariablen werden als Zeichenfolgen in die Liste „ env “ aufgenommen. Terraform baut den Container neu auf, wenn sich irgendwelche Parameter ändern, damit die laufende Infrastruktur immer mit der Konfiguration übereinstimmt.
Jetzt mal „ terraform plan “ ausführen, um zu sehen, was Terraform erstellen wird, und dann „ terraform apply “, um die Infrastruktur bereitzustellen. Terraform macht das Image und den Container. Du kannst das überprüfen, indem du die Ressource in Docker Desktop checkst oder „ docker ps “ im Terminal ausführst.
Jetzt, wo du einen einfachen Container am Laufen hast und den grundlegenden Ablauf verstehst, lass uns die Infrastruktur mit produktionsreifen Funktionen erweitern. Die nächsten Abschnitte bauen auf dieser Grundlage auf und bringen Netzwerke, dauerhaften Speicher und Ressourcenbeschränkungen mit rein, die alle für echte Einsätze wichtig sind.
Um die Kommunikation zwischen Containern zu ermöglichen und gleichzeitig die Isolation zu wahren, ist es wichtig, eigene Netzwerke einzurichten. So machst du isolierte Netzwerke, um die Konnektivität von Containern zu regeln. Füge die folgende Ressource zur Datei „ main.tf “ hinzu:
resource "docker_network" "app_network" {
name = "application_net"
driver = "bridge"
}Jetzt füge einen zweiten Container hinzu, der dieses Netzwerk nutzt. Füge das hier nach dem Container „ web ” ein:
resource "docker_container" "api" {
name = "api-server"
image = docker_image.nginx.image_id
networks_advanced {
name = docker_network.app_network.name
}
}Dadurch wird ein eigenes Bridge-Netzwerk erstellt und der Container „ api “ daran angeschlossen. Container im selben Netzwerk können über ihre Containernamen als Hostnamen miteinander reden, was super für Microservices-Architekturen ist.
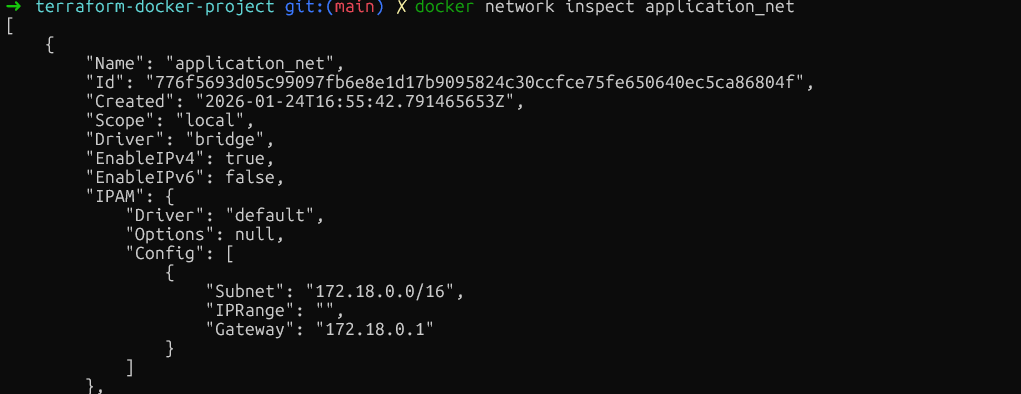
Überprüfe die Netzwerkisolierung, indem du „ docker network inspect application_net “ ausführst und sicherstellst, dass nur die gewünschten Container verbunden sind. Stell sicher, dass du diesen Befehl ausführst, nachdem du die Ressourcen mit terraform plan und terraform apply erstellt hast.
Nachdem das Netzwerk für die Kommunikation zwischen Containern eingerichtet ist, ist der nächste wichtige Punkt die Datenpersistenz.
Für Daten, die nach einem Neustart des Containers noch da sein sollen, füge Volume-Ressourcen hinzu. Füge das hier vor den Container-Definitionen ein:
resource "docker_volume" "db_data" {
name = "postgres_data"
}Jetzt füge einen Datenbankcontainer hinzu, der dieses Volume nutzt:
resource "docker_container" "database" {
name = "postgres"
image = "postgres:15"
env = [
"POSTGRES_PASSWORD=mysecretpassword"
]
volumes {
volume_name = docker_volume.db_data.name
container_path = "/var/lib/postgresql/data"
}
}Solche verwalteten Volumes werden von Docker erstellt und verwaltet und im Datenverzeichnis von Docker gespeichert. Um Konfigurationsdateien vom Host zu teilen, benutze Bind-Mounts, indem du host_path statt volume_name angibst.
volumes {
host_path = "/opt/app/config"
container_path = "/etc/app/config"
read_only = true
}Nachdem man sichergestellt hat, dass die Daten beim Neustart des Containers erhalten bleiben, ist es genauso wichtig, zu verhindern, dass ein einzelner Container die Systemressourcen für sich beansprucht.
Neben der Speicherung ist es für die Stabilität des Systems echt wichtig, zu kontrollieren, wie viel CPU und Speicher jeder Container verbrauchen darf. Um zu verhindern, dass Container zu viele Ressourcen verbrauchen, solltest du Ressourcenbeschränkungen einrichten.
Während man bei Docker einige Ressourcenbeschränkungen direkt vor Ort aktualisieren kann, muss man bei Terraform wegen seines deklarativen Modells oft den Container austauschen, damit der Zustand mit deiner Konfiguration übereinstimmt. Um Ausfallzeiten während dieses Austauschs zu vermeiden, nutzen wir die Lebenszyklusregel „ create_before_destroy “.
Wichtig: Wir müssen das Argument „fixed- name ” entfernen, um Namenskonflikte beim Ersetzen zu vermeiden. Eine Möglichkeit ist, stattdessen das Argument „ name_prefix “ zu verwenden.
resource "docker_container" "api" {
name_prefix = "api-server-"
image = docker_image.nginx.image_id
memory = 512
cpu_shares = 1024
networks_advanced {
name = docker_network.app_network.name
}
lifecycle {
create_before_destroy = true
}
}Der Parameter „ memory “ begrenzt den Arbeitsspeicher in Megabyte. Der Parameter „ cpu_shares “ funktioniert anders. Das ist ein relativer Wert, der benutzt wird, wenn es zu CPU-Konflikten kommt. Ein Container mit 1024 Anteilen kriegt doppelt so viel CPU-Zeit wie einer mit 512 Anteilen, aber nur, wenn der Host ausgelastet ist.
Für feste CPU-Beschränkungen kannst du auch „ cpu_set “ nutzen, um Container an bestimmte CPU-Kerne zu binden:
cpu_set = "0,1"
}Überprüfe diese Einschränkungen, indem du „ docker inspect background-worker --format='{{.HostConfig.Memory}} {{.HostConfig.CpuShares}} “ ausführst und sicherstellst, dass die Werte für „Memory“ und „NanoCpus“ mit der Konfiguration übereinstimmen.
Auch hier musst du, wie oben beschrieben, zuerst die Befehle „ terraform plan “ und „ terraform apply “ ausführen, um die Ressourcen zu erstellen.
Im Moment hat die Datei „ main.tf “ die Konfiguration des Providers, ein Image, ein Netzwerk, ein Volume und drei Container mit verschiedenen Konfigurationen.
Wenn die Infrastruktur wächst, werden fest programmierte Werte unflexibel. In diesem Abschnitt wird gezeigt, wie du die Konfiguration mit Variablen, Modulen und der richtigen Handhabung geheimer Daten wiederverwendbar machst.
Der erste Schritt, um Konfigurationen flexibel zu machen, ist, fest programmierte Werte in Variablen zu packen, die man einfach ändern kann, ohne den Hauptcode anzufassen. Dazu kannst du einfach eine neue Datei namens „ variables.tf “ im selben Verzeichnis anlegen:
variable "web_port" {
description = "External port for web container"
type = number
default = 8080
validation {
condition = var.web_port > 1024 && var.web_port < 65535
error_message = "Port must be between 1024 and 65535."
}
}Jetzt musst du den Web-Container in ` main.tf ` anpassen, damit er diese Variable benutzt:
resource "docker_container" "web" {
name = "nginx-web"
image = docker_image.nginx.image_id
ports {
internal = 80
external = var.web_port
}
env = [
"NGINX_HOST=example.com",
"NGINX_PORT=80"
]
}Der Validierungsblock verhindert die Verwendung privilegierter Ports. Um den Standardwert zu überschreiben, mach eine Datei namens „ terraform.tfvars “:
web_port = 9000Wenn du „ terraform apply “ ausführst, liest Terraform die Werte automatisch aus dieser Datei. Du kannst die Werte auch über die Befehlszeile übergeben: terraform apply -var="web_port=9000".
Variablen lösen das Problem fest codierter Werte, aber was ist, wenn du dasselbe Muster mehrmals komplett mit allen Ressourcen bereitstellen musst?
Hier zeigen Module ihre Stärken. Stell dir ein Modul wie einen Bauplan vor, der all diese einzelnen Teile in einem einzigen Paket zusammenfasst, sodass du diese ganze komplexe Konfiguration als eine Einheit „ausstempeln“ kannst.
Mach zuerst eine Verzeichnisstruktur für das Modul:
mkdir -p modules/web-appErstell jetzt die Datei „ modules/web-app/variables.tf “ und füge Folgendes hinzu:
variable "environment" {
description = "Environment name"
type = string
}
variable "port" {
description = "External port"
type = number
}Als Nächstes machst du eine Hauptdatei namens „ modules/web-app/main.tf ” mit dieser Ressource:
resource "docker_container" "app" {
name = "app-${var.environment}"
image = var.image_id
ports {
internal = 80
external = var.port
}
}Zum Schluss machst du eine Ausgabedatei namens „outputs.file“ ( modules/web-app/outputs.tf), die hauptsächlich dazu dient, den gewünschten Wert nach dem Ausführen von „ terraform apply “ im Terminal anzuzeigen:
output "container_ip" {
value = docker_container.app.network_data[0].ip_address
description = "IP address of the application container"
}Nachdem du die Moduldefinitionen hinzugefügt hast, starte „ terraform init “, um die Module zu installieren, und dann „ terraform apply “, um beide Container aus derselben Vorlage zu erstellen. Du solltest alle Ressourcen im Docker Desktop sehen können.
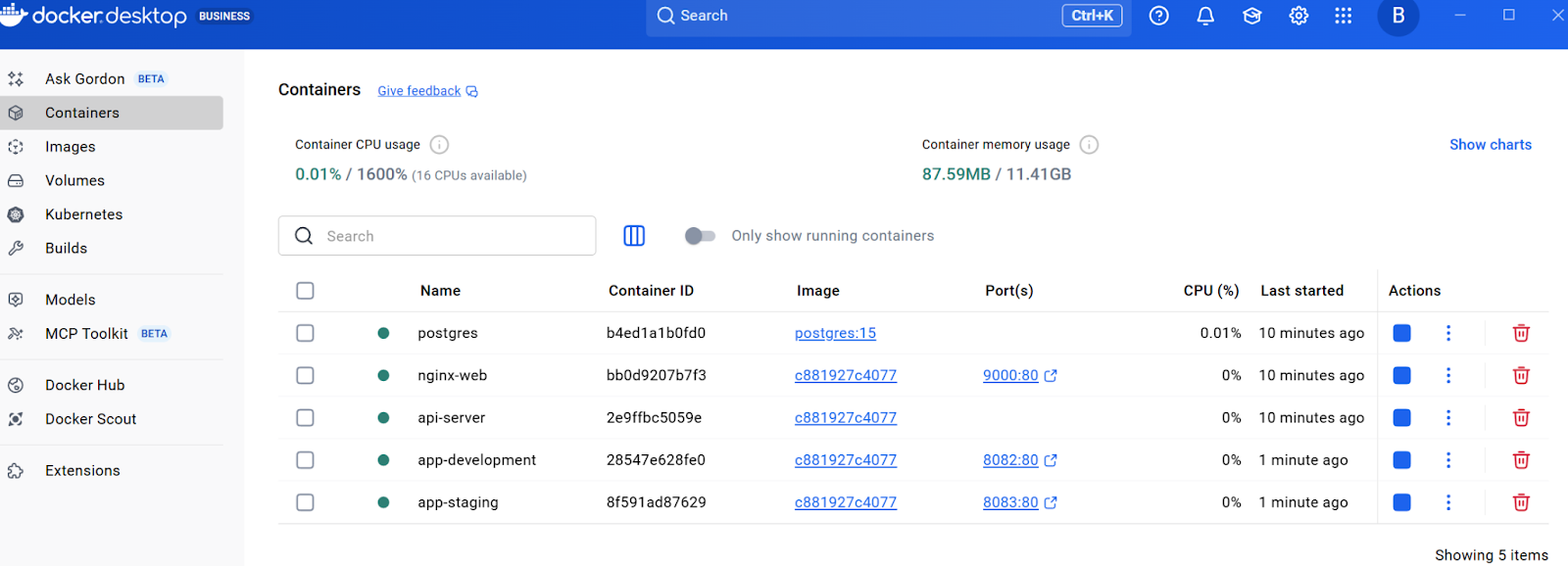 Mit wiederverwendbaren Infrastrukturmustern, die durch Module festgelegt werden, gibt es noch einen weiteren wichtigen Aspekt des Konfigurationsmanagements: den sicheren Umgang mit sensiblen Informationen wie Passwörtern und API-Schlüsseln.
Mit wiederverwendbaren Infrastrukturmustern, die durch Module festgelegt werden, gibt es noch einen weiteren wichtigen Aspekt des Konfigurationsmanagements: den sicheren Umgang mit sensiblen Informationen wie Passwörtern und API-Schlüsseln.
Heikle Werte, wie Datenbank-Passwörter, sollten nicht fest programmiert werden. Stattdessen kannst du die Datei „ variables.tf “ nehmen und „ sensitive = true “ einstellen:
variable "db_password" {
description = "Database root password"
type = string
sensitive = true
}Jetzt musst du den Datenbankcontainer in ` main.tf ` anpassen, damit er auf das Datenbankpasswort verweist:
resource "docker_container" "database" {
name = "postgres"
image = "postgres:15"
env = [
"POSTGRES_PASSWORD=${var.db_password}"
]
volumes {
volume_name = docker_volume.db_data.name
container_path = "/var/lib/postgresql/data"
}
}Anstatt das Passwort in „ terraform.tfvars “ zu speichern und fest zu codieren, leg es als Umgebungsvariable fest:
export TF_VAR_db_password="your-secure-password"
terraform applyDas Flag „ sensitive = true “ verhindert, dass Terraform den Wert in der Konsolenausgabe anzeigt.
Diese Werte werden aber im Klartext in der Datei „ terraform.tfstate “ gespeichert. Um sicherzugehen, dass diese Datei sicher ist, können wir sie mit Remote-Backends und Verschlüsselung schützen. Schauen wir mal, wie das geht.
Dieser Abschnitt behandelt die Mechanismen und Automatisierungsabläufe, die für Produktionsbereitstellungen wichtig sind. Bevor du die Automatisierung einrichtest, solltest du aber wissen, wie Terraform deine Infrastruktur über seine Statusdatei im Blick behält.
Der Status ist die Grundlage für die Fähigkeit von Terraform, die Infrastruktur zu verwalten. Die Datei „ terraform.tfstate “ ordnet die Konfiguration den echten Docker-Container-IDs und Ressourcenattributen zu. Wenn du „ terraform apply “ ausführst, vergleicht Terraform diesen Zustand mit der Konfiguration und berechnet die minimal erforderlichen Änderungen.
Schau dir den aktuellen Status mit „ terraform show “ an, das alle verwalteten Ressourcen anzeigt. Für Teams bringen lokale Statusdateien Probleme, Konflikte und das Risiko von Datenverlusten mit sich. Die Lösung sind Remote-Backends.
Für Docker-basierte Arbeitsabläufe ohne Cloud-Infrastrukturist die kostenlose Stufe „ “ von Terraform Cloud genau das Richtige. Füge einen Backend-Block zum Abschnitt „ terraform “ in „ main.tf “ hinzu:
terraform {
required_providers {
docker = {
source = "kreuzwerker/docker"
version = "~> 3.0"
}
}
backend "remote" {
organization = "your-org-name"
workspaces {
name = "docker-infrastructure"
}
}
}Mach dir ein kostenlosesKonto auf der Terraform-Website. en, mach mal terraform login, um dich mit dem bereitgestellten Token zu authentifizieren, und dann terraform init, um den Status zu migrieren. Das sorgt für eine Statusverriegelung in einem Remote-Arbeitsbereich und Teamzusammenarbeit ohne Cloud-Infrastruktur.
Man kann aber auch ein Remote-Backendbei Cloud-Anbietern wie AWS oder GCPeinrichten.
Nachdem die Statusverwaltung eingerichtet und remote gespeichert wurde, ist die Infrastruktur bereit für die Zusammenarbeit im Team. Der letzte Schritt ist, den Bereitstellungsprozess über CI/CD-Pipelines zu automatisieren, damit die Änderungen einheitlich und überprüfbar sind.
Mach zuerst die Datei „ .github/workflows/terraform.yml “ an:
name: Terraform Docker Deploy
on:
pull_request:
branches: [main]
push:
branches: [main]
jobs:
terraform:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
- name: Setup Terraform
uses: hashicorp/setup-terraform@v3
- name: Terraform Init
run: terraform init
- name: Terraform Plan
if: github.event_name == 'pull_request'
run: terraform plan
- name: Terraform Apply
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
run: terraform apply -auto-approveDieser Workflow führt bei jedem Pull-Request „ terraform plan “ aus und zeigt den Reviewern, welche Änderungen an der Infrastruktur passieren werden. Wenn Änderungen in den Hauptzweig übernommen werden, läuft automatisch „ terraform apply “ ab, damit jede Änderung an der Infrastruktur denselben Überprüfungsprozess durchläuft wie Code-Änderungen.
Auch wenn man alles sorgfältig einrichtet, kann es Probleme geben. Wenn man die üblichen Probleme kennt und weiß, wann man Alternativen in Betracht ziehen sollte, kann man bessere architektonische Entscheidungen treffen.
Der häufigste Fehler unter Linux ist „Zugriff verweigert“, wenn man versucht, eine Verbindung zum Docker-Socket herzustellen. Das passiert, wenn der Benutzer keine Berechtigung hat, auf /var/run/docker.sock zuzugreifen. Füge den Benutzer zur Gruppe „ docker ” hinzu, um das Problem zu beheben:
sudo usermod -aG docker $USERDann logg dich aus und wieder ein.
Unter Windows mit WSL2 gibt's Verbindungsprobleme, weil der Socket-Pfad anders ist. Stell sicher, dass die Einstellung „Daemon auf tcp://localhost:2375 ohne TLS freigeben” in Docker Desktop aktiviert ist, und aktualisiere dann den Anbieter unter main.tf:
provider "docker" {
host = "tcp://localhost:2375"
}Bei privaten Docker-Registern solltest du die Authentifizierung zum Provider-Block hinzufügen, die Anmeldedaten als Variablen festlegen und sie über Umgebungsvariablen einstellen, um Probleme durch Hardcoding zu vermeiden.
hclprovider "docker" {
host = "unix:///var/run/docker.sock"
registry_auth {
address = "registry.mycompany.com"
username = var.registry_username
password = var.registry_password
}
}Neben der Fehlerbehebung ist es auch wichtig zu wissen, wann andere Tools für deinen speziellen Anwendungsfall besser geeignet sind als Terraform.
Kubernetes hat echt viel mehr coole Funktionen für die Orchestrierung :
Für komplizierte Multi-Node-Implementierungen mit hohen Verfügbarkeitsanforderungen ist Kubernetes die bessere Wahl. Terraform kann die Kubernetes-Infrastruktur bereitstellen, während Helm oderKubernetes-Manifeste die Anwendungsbereitstellung übernehmen.
Ansible ist super beim Konfigurationsmanagement in Containern. Während Terraform die Infrastruktur bereitstellt, kümmert sich Ansible um die Softwarekonfiguration und die Installation von Paketen. Die beiden Tools arbeiten oft zusammen: Terraform macht Docker-Container, und dann richtet Ansible die Anwendungen ein, die darin laufen.
Für einfache lokaleEntwicklungsumgebungen ist Docker Compose immer noch die beste Wahl. Terraform ist super für reproduzierbare Bereitstellungen in verschiedenen Umgebungenund wenn man es mit anderen Infrastrukturkomponenten verbinden muss.
Um dir bei der Entscheidung zu helfen, welche du nehmen sollst, hab ich die wichtigstenUnterschiede in dieser Tabelle zusammengefasst:
|
Werkzeug |
Kernkompetenzen |
Bester Anwendungsfall |
Vergleich mit Terraform |
|
Kubernetes |
Ausgeklügelte Orchestrierung (Selbstheilung, fortschrittliche Planung, Lastenausgleich). |
Komplexe Multi-Node-Bereitstellungen, die hohe Verfügbarkeit brauchen. |
Ergänzend: Terraform kümmert sich um die Infrastruktur (den Cluster), während Kubernetes die Bereitstellung der Anwendung regelt. |
|
Ansible |
Konfigurationsmanagement, Paketinstallation und Softwareeinrichtung. |
Die Software und die Konfiguration in den Containern verwalten. |
Ergänzend: Terraform baut die Docker-Container auf und Ansible macht die Anwendungen fertig, die darin laufen. |
|
Docker Compose |
Einfaches, pragmatisches Projektmanagement. |
Einfache lokale Entwicklungsumgebungen. |
Alternative: Compose ist einfacher für die lokale Entwicklung, aber Terraform ist besser für reproduzierbare Bereitstellungen in verschiedenen Umgebungen. |
Wenn du nach einem Tool suchst, das Docker ersetzen kann, schau dirunseren Leitfaden zu den besten Docker-Alternativen an.
Durch die Integration von Docker in das Lebenszyklusmanagement von Terraform werden Container-Bereitstellungen von manuellen Verfahren zu reproduzierbaren, versionskontrollierten Infrastrukturen. In diesem Tutorial habe ich gezeigt, wie man Schritt für Schritt eine komplette Infrastruktur aufbaut, angefangen mit einem Anbieter und einem einzelnen Container, und dann nach und nach Netzwerk, Speicher, Variablen, Module und Automatisierung hinzufügt.
Der Hauptunterschied ist, dass Terraform das Bereitstellen, Erstellen, Aktualisieren und Löschen von Ressourcen anhand einer deklarativen Konfiguration macht. Für die komplette Orchestrierung mit automatischer Skalierung und Selbstheilung braucht man Tools wie Kubernetes oder Docker Swarm. Terraform kann diese Orchestratoren bereitstellen, ersetzt sie aber nicht.
Als Nächstes solltest du dir die offizielle Terraform Registry-Dokumentation für den Docker-Anbieter anschauen, um erweiterte Ressourcenoptionen wie Docker-Dienste für Swarm, Geheimnisverwaltung und Plugin-Konfigurationen zu finden.
Wenn du praktische Erfahrungen mit Containern sammeln möchtest, empfehle ich dir, dich für unseren interaktiven Lernpfad „Containerisierung und Virtualisierung mit Docker und Kubernetes” anzumelden.
Docker-Kurse
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Tutorial
Satyabrata Pal
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
