
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Ich habe ewig damit verbracht, mich durch die AWS-Konsole zu klicken, EC2-Instanzen manuell zu starten, Sicherheitsgruppen einzurichten und dabei natürlich Fehler gemacht, deren Behebung ewig gedauert hat. Kommt dir das bekannt vor? Du erstellst eine Instanz in der falschen Verfügbarkeitszone, vergisst, eine Ressource zu kennzeichnen, oder verbringst einen Nachmittag damit, die genaue Konfiguration, die du letzten Monat erstellt hast, neu zu erstellen, weil du die Schritte nicht dokumentiert hast.
Die manuelle Bereitstellung von Infrastruktur ist nicht nur nervig, sondern auch fehleranfällig, nicht skalierbar und schwer zu überprüfen. Da kommt Terraform ins Spiel und verändert alles. Stell dir vor, du könntest deine ganze AWS-Infrastruktur in Textdateien festlegen, die du automatisch versionieren, überprüfen und bereitstellen kannst. Du musst nicht mehr durch Dutzende von Bildschirmen klicken. Keine Diskussionen mehr mit deinem Team über „aber auf meinem Rechner hat es funktioniert“.
In diesem Tutorial zeige ich dir, wie du die AWS-Infrastruktur mit Terraform automatisieren kannst, und zwar anhand eines Beispiels aus der Praxis: Bereitstellung einer EC2-Instanz mit einem automatisch gebootstrappten SSM-Agenten (Systems Manager). Am Ende wirst du die Grundlagen von Infrastructure as Code verstehen und über funktionierenden Code verfügen, den du sofort in deinem eigenen AWS-Konto einsetzen kannst.
Wenn du neu bei AWS bist, solltest du einen unserer Kurse besuchen, zum Beispiel „AWS Concepts“oder Einführung in AWS Boto in Pythonoder AWS-Sicherheit und Kostenmanagement.
Terraform ist ein Open-Source-Tool für Infrastructure as Code (IaC) von HashiCorp, mit dem du Cloud-Ressourcen mit der HashiCorp Configuration Language (HCL) definieren, bereitstellen und verwalten kannst.
Anstatt dich durch Cloud-Konsolen zu klicken oder Bash-Skripte zu schreiben, sagst du einfach in Konfigurationsdateien, welche Infrastruktur du willst, und Terraform kümmert sich um die Details, um das hinzukriegen. Dieser Wechsel von einer imperativen zu einer deklarativen Infrastruktur ist echt eine grundlegende Veränderung in der Art, wie wir über Cloud-Ressourcen denken.
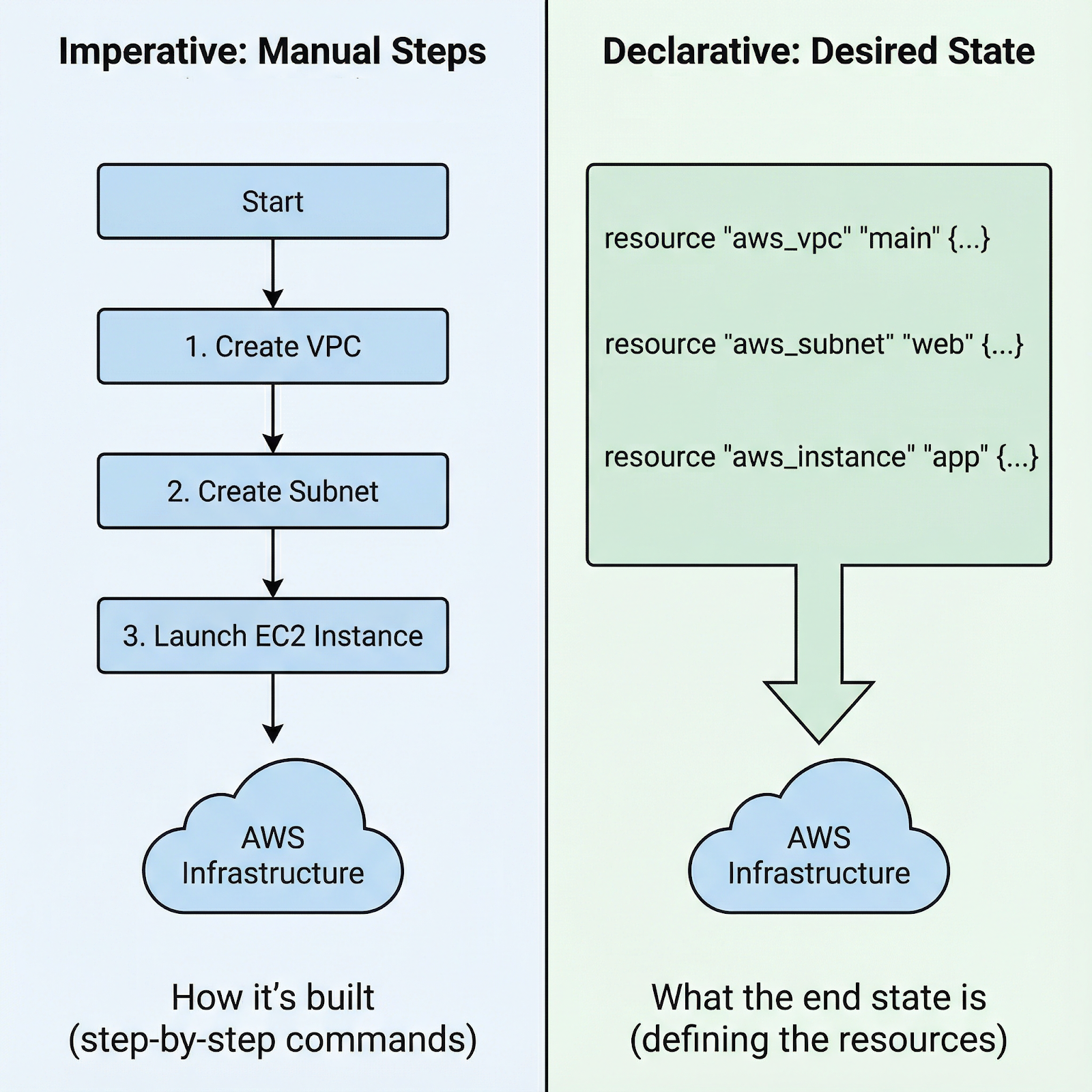
Imperativer vs. deklarativer Ansatz zum Starten einer AWS EC2-Instanz
Bei imperativen Ansätzen schreibst du Schritt-für-Schritt-Anweisungen: „Erstelle zuerst diese Sicherheitsgruppe, warte dann, bis sie da ist, starte dann diese Instanz mit dieser Sicherheitsgruppe, füge dann dieses Volume hinzu und erstelle dann diese Tags.“ Du bist dafür verantwortlich, dass alles genau in der richtigen Reihenfolge läuft und dass bei jedem Schritt keine Fehler passieren.
Mit dem deklarativen Ansatz von Terraform legst du einfach den Endzustand fest: Ich brauche eine EC2-Instanz „ ” mit diesen Spezifikationen, die mit dieser Sicherheitsgruppe verbunden ist und diese Tags hat. Terraform checkt Abhängigkeiten, findet die richtige Reihenfolge und macht den Plan fertig. Wenn was schiefgeht, weiß Terraform genau, wo es aufgehört hat.
Warum sollte man sich speziell für Terraform für AWS entscheiden?
Bevor du dich mit der praktischen Konfiguration beschäftigst, solltest du drei wichtige Konzepte verstehen, die die Grundlage von Terraform bilden:
Nachdem wir uns über die Grundlagen klar geworden sind, machen wir deine Umgebung bereit, um mit dem Aufbau der eigentlichen Infrastruktur loszulegen.
Bevor du Terraform-Code schreibst, musst du die CLI installieren und die AWS-Anmeldedaten einrichten. Ich erkläre dir beides.
Die Installation von Terraform hängt vom Betriebssystem ab:
Auf macOS nimmst du Homebrew: Installier zuerst den HashiCorp-Tap mit „ brew tap hashicorp/tap “ und dann Terraform mit „ brew install hashicorp/tap/terraform “.
Unter Windows kannst du die Binärdatei von hashicorp.com runterladen und zu deinem PATH hinzufügen oder Chocolatey verwenden: choco install terraform.
Unter Linux kannst du das passende Paket runterladen oder den Paketmanager deiner Distribution nutzen.
Nach der Installation überprüfe, ob alles richtig läuft, indem du „ terraform version “ startest.
Um die AWS-Anmeldedaten einzurichten, brauchst du ein AWS-Konto, einen Zugriffsschlüssel und ein Geheimnis von IAM. Benutze niemals dein Root-Konto. Mach lieber einen IAM-Benutzer mit programmatischem Zugriff und den richtigen Berechtigungen (AdministratorAccess). Der Standardansatz nutzt die AWS-Anmeldedaten-Datei unter ~/.aws/credentials:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEYDu kannst auch die Umgebungsvariablen setzen: AWS_ACCESS_KEY_ID und AWS_SECRET_ACCESS_KEY. Für Produktionsumgebungen solltest du lieber IAM-Rollen verwenden, die mit EC2-Instanzen oder CI/CD-Systemen verbunden sind, statt Anmeldedaten, die ewig gültig sind.
Wenn du überlegst, ein anderes Ökosystem als das von Amazon zu nutzen, oder einfach nur einen guten Überblick über die Unterschiede zwischen den „großen Drei“ bekommen möchtest, empfehle ich dir, diesen Vergleich der Dienste von AWS, Azure und GCP für Data Science und KI zu lesen.
Jetzt, wo wir die Grundlagen haben, lass uns was Konkretes machen: eine EC2-Instanz, die den SSM-Agent beim Start automatisch installiert.
Terraform-Projekte profitieren von einem klaren und strukturierten Ansatz. Erstell drei Dateien: main.tf für Ressourcendefinitionen, variables.tf für Eingaben und outputs.tf für Werte, die du nach der Bereitstellung brauchst. Diese Trennung sorgt dafür, dass dein Code übersichtlich und pflegbar bleibt.
aws-terraform
├── main.tf
├── output.tf
└── variables.tfHier ist der Grund, warum das wichtig ist: Wenn Projekte größer werden, wird es echt schwierig, alles in einer einzigen Datei zu verwalten. Mit Variablen kannst du denselben Code in verschiedenen Umgebungen (Entwicklung, Staging, Produktion) wiederverwenden, indem du die Eingaben änderst. Die Ausgaben liefern dir die Werte, die du brauchst, wie zum Beispiel Instanz-IDs oder IP-Adressen, ohne dass du manuell in der AWS-Konsole suchen musst.
Jetzt bauen wir die Infrastruktur auf: eine EC2-Instanz mit vorinstalliertem SSM-Agent. Füge in der Datei „ main.tf “ die folgende Konfiguration hinzu:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
}
provider "aws" {
region = "eu-central-1"
}
data "aws_ami" "amazon_linux" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["amazon"]
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.amazon_linux.id
instance_type = "t2.micro"
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
user_data = <<-EOF
#!/bin/bash
cd /tmp
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
EOF
tags = {
Name = "TerraformWebServer"
}
}
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2-ssm-profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_iam_role" "ssm_role" {
name = "ec2-ssm-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "ssm_policy" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}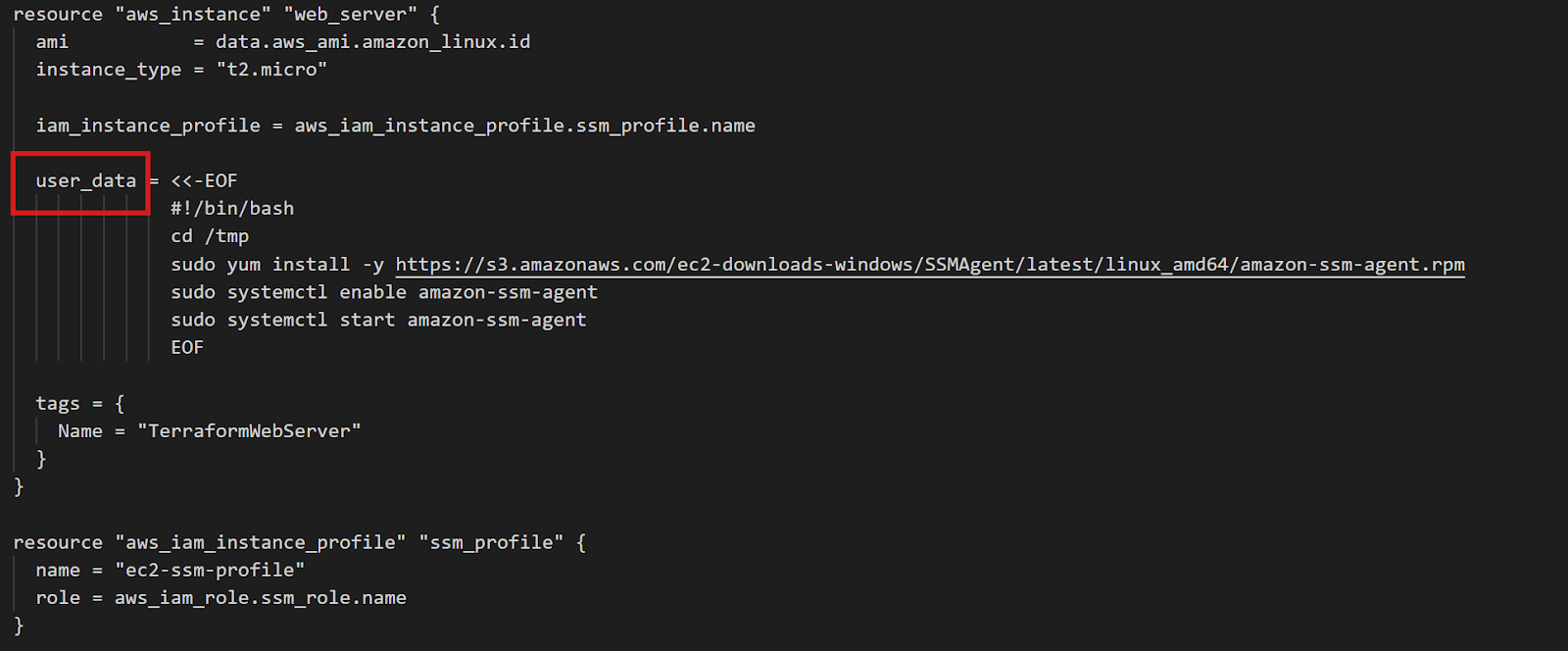
Terraform-Konfiguration für EC2-Instanzen
Der Block „ data “ fragt AWS nach der aktuellsten Amazon Linux 2 AMI. Die Filter sorgen dafür, dass du den richtigen Bildtyp bekommst, und „ owners = ["amazon"] ” stellt sicher, dass du offizielle Amazon AMIs verwendest. Dieser Ansatz funktioniert in allen Regionen ohne Änderungen – Terraform findet automatisch die richtige regionale AMI.
Der entscheidende Teil ist „ user_data “: ein Shell-Skript, das beim ersten Start der Instanz ausgeführt wird. Dieses Skript lädt den SSM-Agenten runter, installiert ihn und sorgt dafür, dass er automatisch startet. Die IAM-Rolle gibt SSM die Berechtigungen, die es braucht, um die Instanz zu verwalten.
Das gleiche Muster funktioniert für jeden Agenten. Willst du CloudWatch für Protokolle und Metriken? Ändere einfach das Skript „ user_data “, um stattdessen den CloudWatch-Agenten zu installieren. Das Prinzip bleibt dasselbe: Sag einfach, was installiert werden soll, und Terraform sorgt dafür, dass es auf jeder Instanz passiert.
Für die Datei „ output.tf “ kannst du zum Beispiel die Instanz-ID hinzufügen. Sobald du dann alle Terraform-Befehle ausgeführt hast, die ich im nächsten Kapitel behandle, wird der Wert im Terminal angezeigt.
output "instance_id" {
description = "EC2 instance ID for SSM connection"
value = aws_instance.web_server.id
}Nachdem du deine Konfiguration geschrieben hast, hat der Terraform-Workflow drei Befehle. Zuerst lädt der folgende Befehl das AWS-Anbieter-Plugin runter und macht dein Verzeichnis fertig:
terraform init
terraform init
Zweitens zeigt „ terraform plan “ genau, was Terraform erstellen, ändern oder löschen wird. Mit dieser Vorschau kannst du Fehler erkennen, bevor du echte Änderungen machst:
terraform plan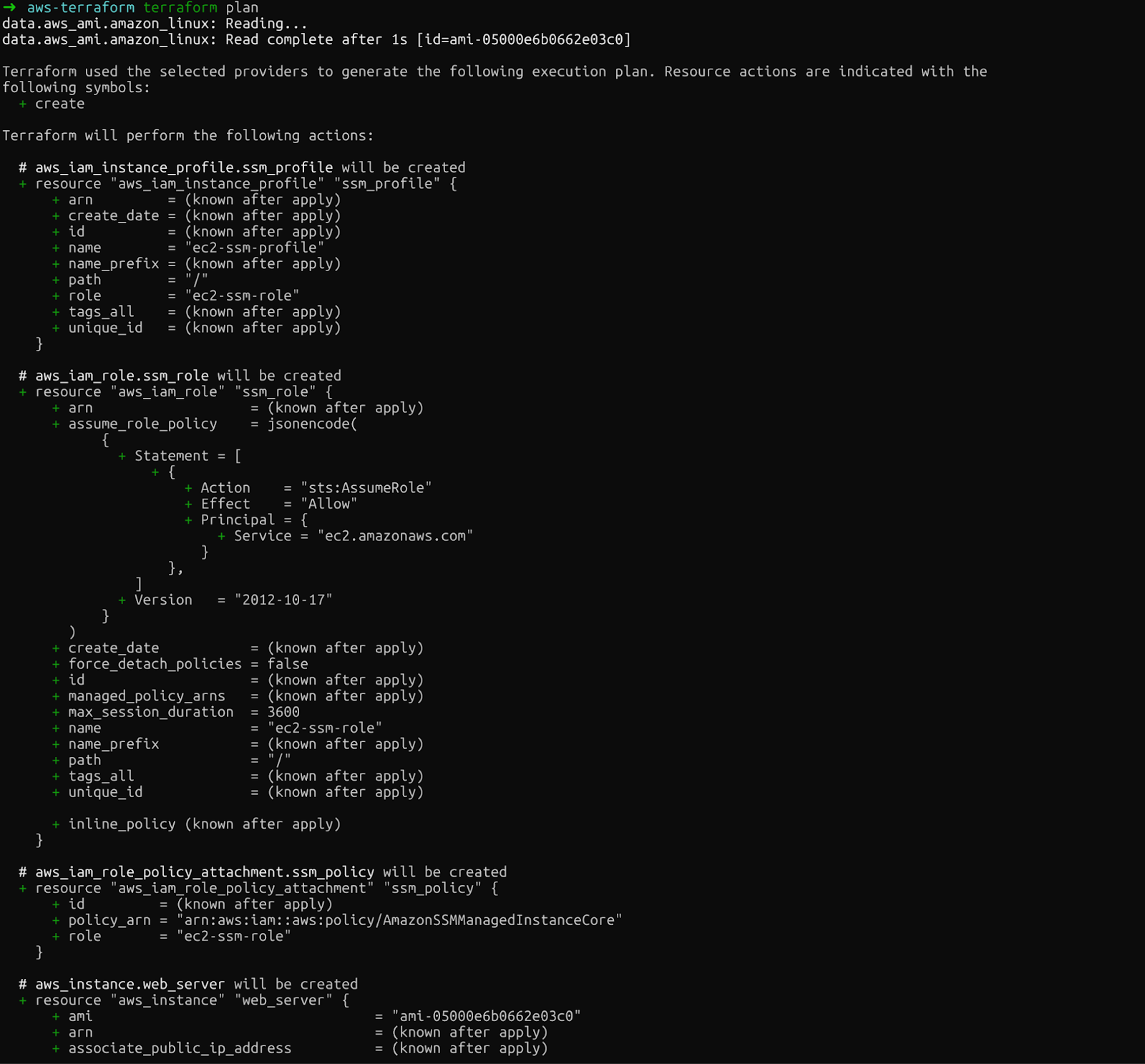
Terraform-Plan
Schau dir die Ausgabe genau an. Du siehst die EC2-Instanz, die IAM-Rolle, das Instanzprofil und die Richtlinienanbindung, die Terraform erstellen wird.
Schließlich führt „ terraform apply “ die Änderungen aus. Terraform fragt dich, ob du das wirklich machen willst, bevor es weitergeht. Gib nach dem Ausführen dieses Befehls „yes“ ein:
terraform apply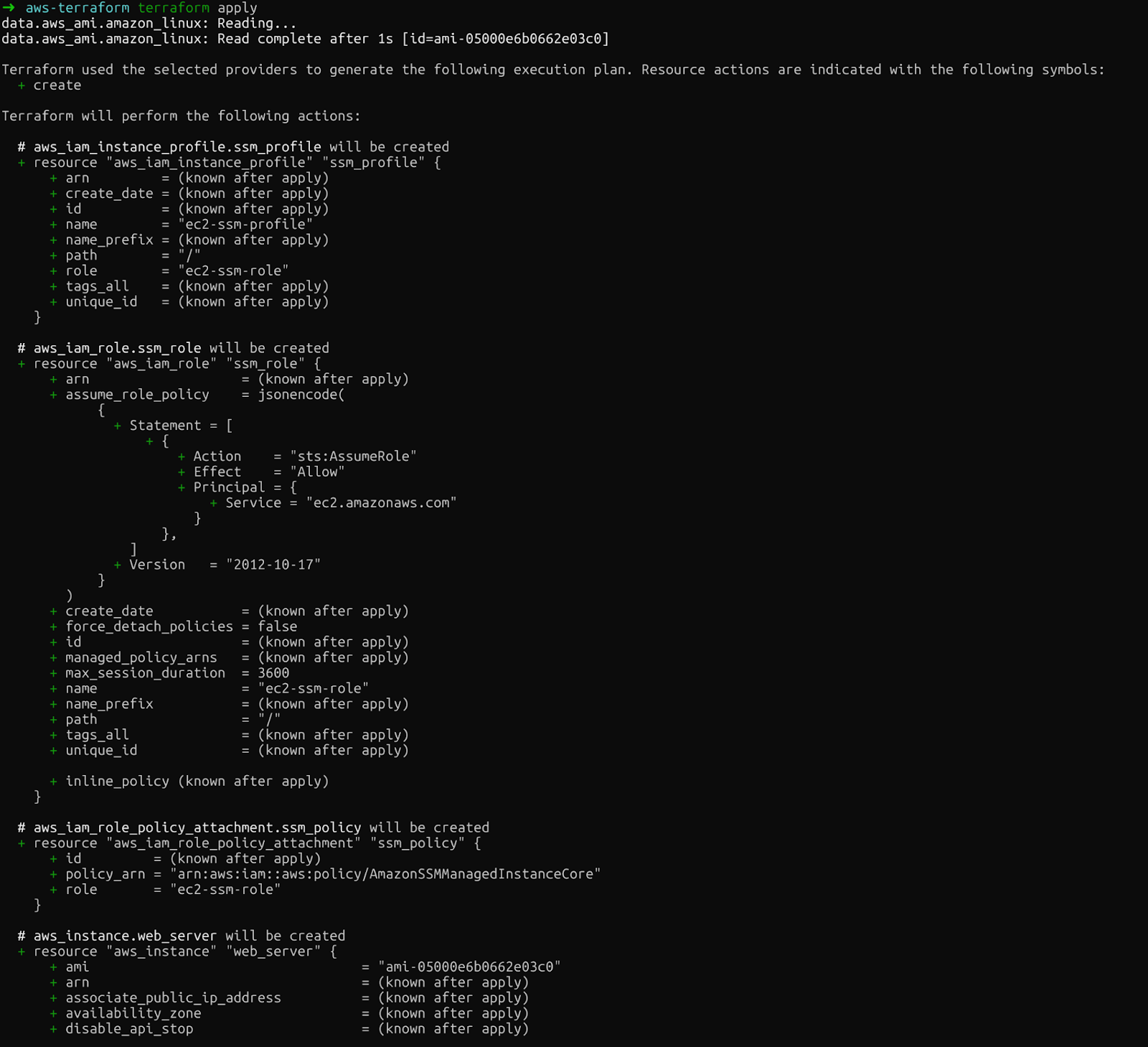
terraform anwenden
Wenn alles klappt, siehst du die folgende Meldung, sobald die Ressourcen erstellt wurden.
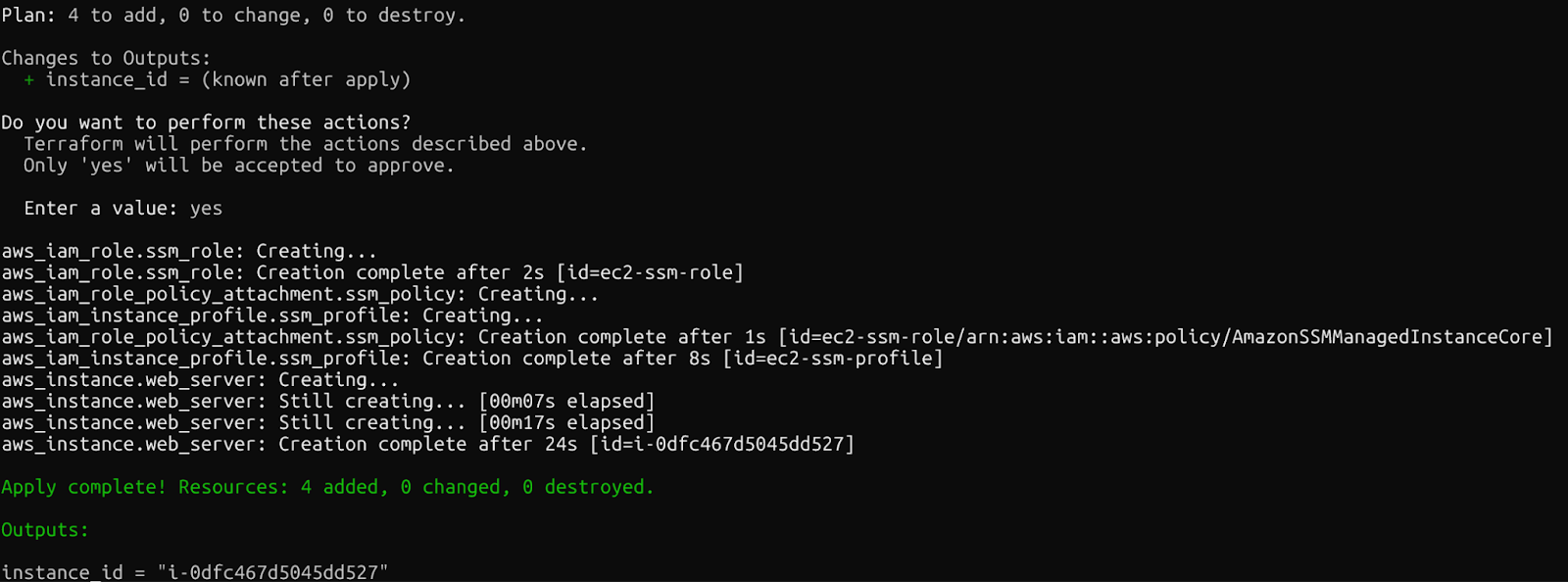
Bestätigung: Terraform-Ressourcen erstellt
Innerhalb weniger Minuten hast du eine laufende EC2-Instanz mit konfiguriertem SSM, auf die du ohne SSH-Schlüssel zugreifen kannst. Schau mal in der AWS-Konsole nach, um die neu erstellten Ressourcen zu sehen.
Nachdem du die oben genannten Befehle ausgeführt hast, findest du im Verzeichnis eine neue Datei namens „ terraform.tfstate “. Die Statusdatei von Terraform ordnet deine Konfiguration den echten AWS-Ressourcen zu. Schauen wir uns diese Datei mal an, um zu sehen, was drinsteht.
Die Statusdatei hat alle Infos zu deiner eingesetzten Infrastruktur: Ressourcen-IDs, IP-Adressen und Abhängigkeiten. Terraform vergleicht diesen Zustand mit deiner Konfiguration und dem tatsächlichen Zustand von AWS, um zu entscheiden, welche Maßnahmen zu ergreifen sind. Verlierst du die Statusdatei, verliert Terraform den Überblick über alles, was es erstellt hat.
Es ist gefährlich, den Status auf deinem Laptop zu speichern. Wenn dein Computer abstürzt, geht der Status verloren. Wenn mehrere Teammitglieder an derselben Infrastruktur arbeiten, führen widersprüchliche lokale Zustände zu Datenkorruption. Die Lösung: Remote-Zustandsspeicherung.
Wenn du dich genauer mit S3 und EFS beschäftigen willst, schau dir dieses AWS-Speicher-Tutorial an.
Das S3-Backend von Terraform speichert den Status an einem zentralen, dauerhaften Ort, auf den dein ganzes Team zugreifen kann. Erstell zuerst einen S3-Bucket:
aws s3api create-bucket \
--bucket datacamp-terraform-state \
--region eu-central-1 \
--create-bucket-configuration LocationConstraint=eu-central-1
aws s3api put-bucket-versioning \
--bucket datacamp-terraform-state \
--versioning-configuration Status=EnabledDie Versionierung ist super wichtig: Sie hilft dir, nach Problemen wieder auf frühere Versionen zurückzugreifen.
Jetzt fügst du die Backend-Konfiguration zu deinem Terraform-Code hinzu:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
backend "s3" {
bucket = "datacamp-terraform-state"
key = "terraform.tfstate"
region = "eu-central-1"
use_lockfile = true
}
}Mach nochmal „ terraform init “, um deinen lokalen Status nach S3 zu verschieben. Terraform fragt dich nach einer Bestätigung, bevor die Statusdatei verschoben wird.
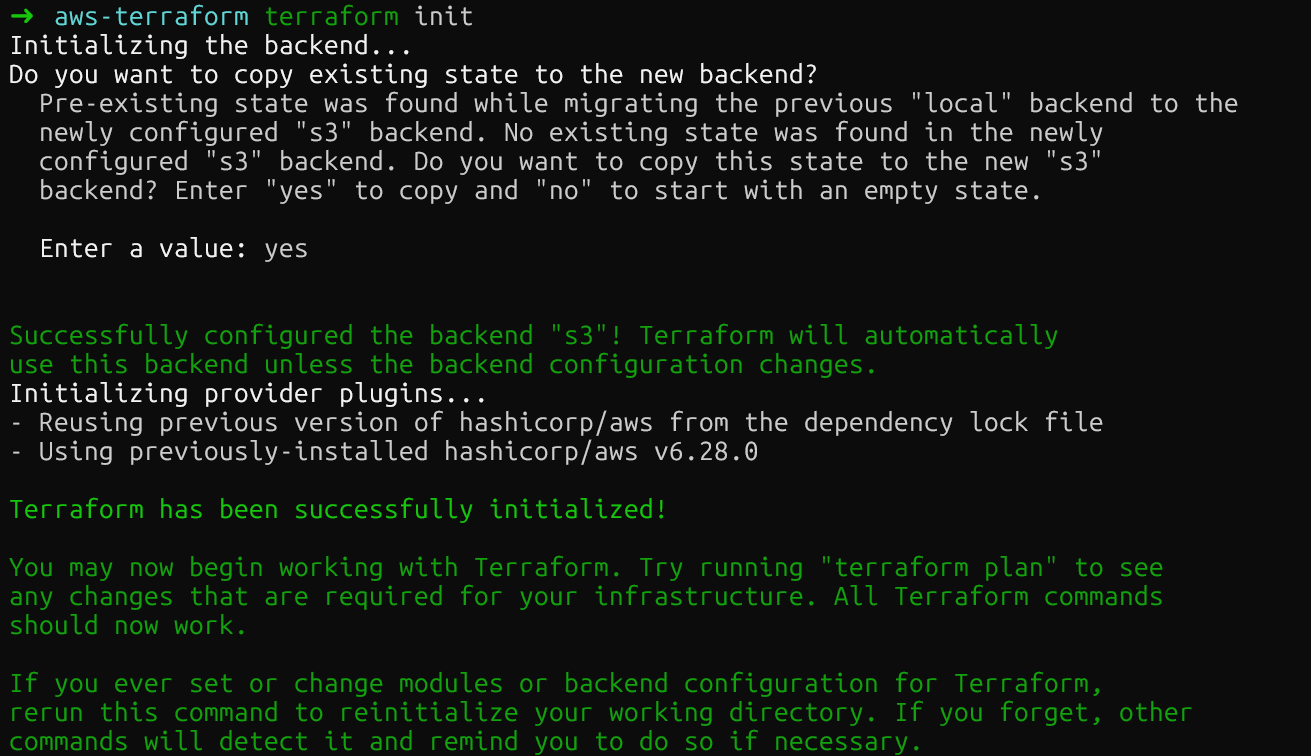
Terraform S3 Remote-Backend
Nachdem du den Befehl ausgeführt hast, sollte der S3-Bucket die neue Statusdatei haben. Du kannst das in der AWS-Konsole checken.
Du hast bestimmt schon gesehen, dass wir den folgenden Befehl zur Datei „ main.tf “ hinzugefügt haben: use_lockfile = true . Diese Einstellung aktiviert die neueste Funktion von Terraform: native S3-Status-Sperrung. Früher brauchte man eine eigene DynamoDB-Tabelle für die Sperrung.
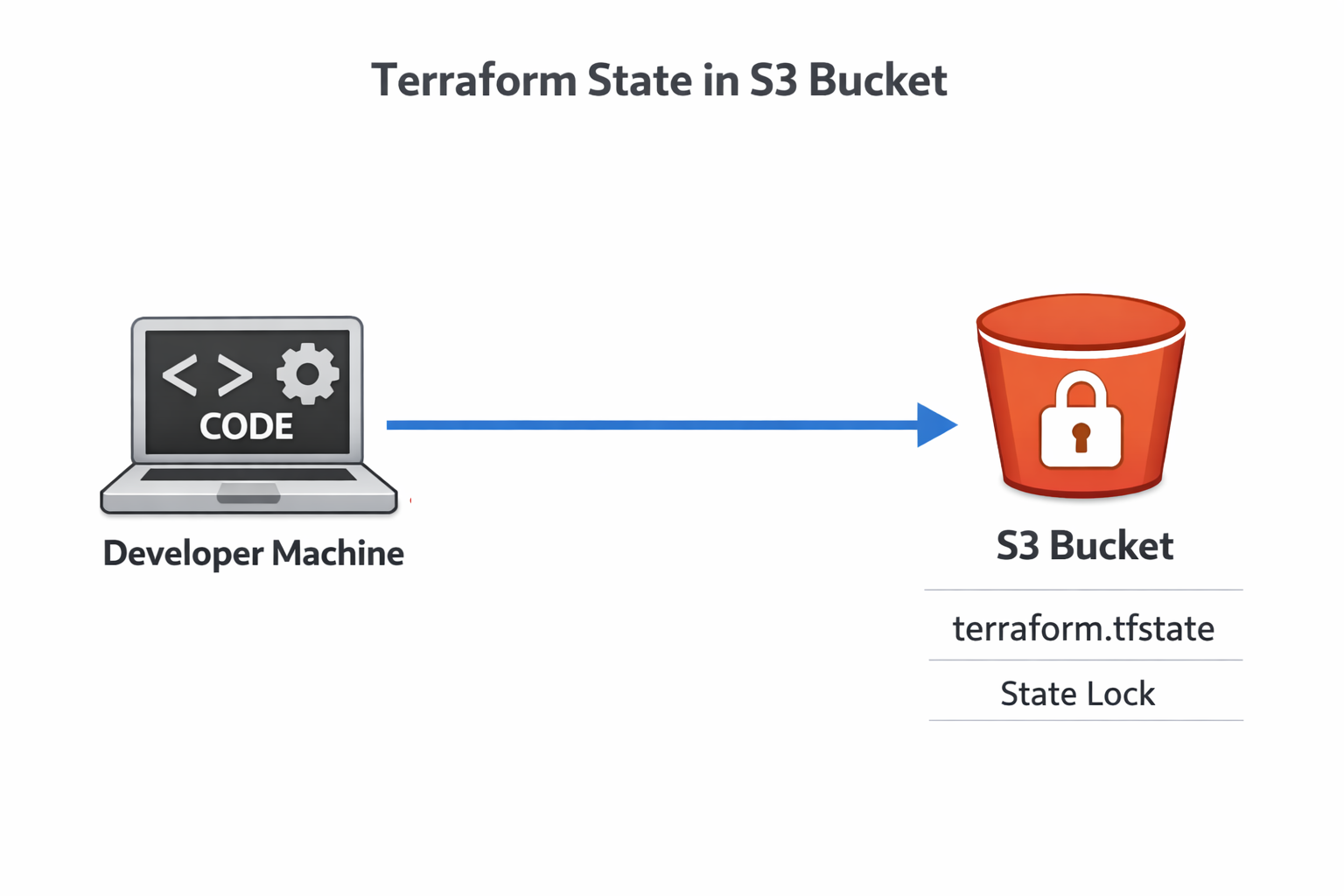
Terraform-Sperrzustand
Durch diese Vereinfachung sparst du dir einen ganzen AWS-Dienst in deiner Infrastruktur, bekommst aber trotzdem den gleichen Schutz vor Race Conditions. Mehrere Ingenieure können sicher an der Infrastruktur arbeiten, weil sie wissen, dass immer nur die Änderungen einer Person gleichzeitig übernommen werden.
Wenn deine Infrastruktur wächst, werden fest programmierte Werte und kopierter Code zu einem Albtraum bei der Wartung. Das variable System und die Module von Terraform lösen dieses Problem.
Vorher haben wir die Datei „ variables.tf “ erstellt. Jetzt kannst du die Werte, die vorher in „ main.tf “ fest programmiert waren, in diese neue Datei verschieben, die unsere Variablen enthalten wird:
variable "aws_region" {
description = "AWS region for resources"
type = string
default = "eu-central-1"
}
variable "instance_type" {
description = "EC2 instance type"
type = string
default = "t2.micro"
}Jetzt verweise auf die Variablen in deinen Ressourcen in der Datei „ main.tf “:
provider "aws" {
region = var.aws_region
}
resource "aws_instance" "web_server" {
instance_type = var.instance_type
# ... rest of configuration
tags = {
Environment = var.environment
}
}Beachte, dass AWS S3-Buckets einzigartig sind, sodass du keine Variablen in der Region im Parameter „ backend “ von „ main.tf “ verwenden kannst. Hier musst du deine fest codierte Region wie “eu-central-1” anstelle von var.region_aws behalten.
Jetzt, wo unsere Variablen definiert sind, kannst du auch verschiedene Umgebungen festlegen, wie zum Beispiel Entwicklung oder Produktion, wo die Variablen unterschiedlich sein können. Dazu machst du neue Dateien mit der Endung „ .tfvars “.
Du kannst zum Beispiel eine Datei „ terraform-dev.tfvars “ für die Entwicklung und eine Datei „ terraform-prod.tfvars “ für die Produktion erstellen:
Entwicklung:
aws_region = "eu-central-1"
instance_type = "t2.micro"Produktion:
aws_region = "eu-central-1"
instance_type = "t3.medium"Dann kannst du die App in den verschiedenen Umgebungen bereitstellen, indem du die passende Datei angibst:
terraform apply -var-file="terraform-dev.tfvars”Variablen lösen das Problem der umgebungsspezifischen Werte, aber wie sieht es mit der Duplizierung ganzer Infrastrukturmuster aus? Da sind Module echt wichtig.
Module packen Ressourcen in wiederverwendbare Teile. Am besten nutzt man Module, indem man einen speziellen Ordner erstellt. Du kannst zum Beispiel eine Verzeichnisstruktur wie diese erstellen:
modules/
ec2-with-ssm/
main.tf
variables.tf
outputs.tfDu kannst die zuvor erstellte Datei „ variables.tf “ in den Modulordner verschieben (oder eine neue erstellen). Die wichtigste Änderung ist in der Datei „ main.tf “. Das im Modul soll unsere Ressourcen haben. Also wird alles von der AMI bis zum Ende der Datei dorthin verschoben:
data "aws_ami" "amazon_linux" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["amazon"]
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.amazon_linux.id
instance_type = var.instance_type
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
user_data = <<-EOF
#!/bin/bash
cd /tmp
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
EOF
tags = {
Name = "TerraformWebServer"
}
}
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2-ssm-profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_iam_role" "ssm_role" {
name = "ec2-ssm-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "ssm_policy" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}Um diese Änderung zu ersetzen, behältst du den Rest der Datei bei, fügst aber einen Modulparameter hinzu, der auf das spezifische Modul verweist.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
backend "s3" {
bucket = "datacamp-terraform-state"
key = "terraform.tfstate"
region = "eu-central-1"
use_lockfile = true
}
}
provider "aws" {
region = var.aws_region
}
module "web_server" {
source = "./modules/ec2-with-ssm"
instance_type = var.instance_type
}Wenn du jetzt die Befehle „ init “, „ plan “ und „ apply “ mit diesen Einstellungen ausführst, werden dieselben Ressourcen wie zuvor bereitgestellt. Der Unterschied ist, dass du mit Modulen Infrastrukturen mit ähnlichen Konfigurationen starten kannst, die wiederverwendet werden können. Sie sind super wichtig, um Terraform über einfache Projekte hinaus zu erweitern.
Jetzt kommen wir zu einem anderen wichtigen Thema: Sicherheit.
Der Infrastrukturcode braucht genauso strenge Sicherheitsmaßnahmen wie der Anwendungscode. Deshalb ist es echt wichtig, deine Terraform-Bereitstellungen zu schützen.
Speichere niemals Geheimnisse in Git. Ever. Benutze AWS Secrets Manager für sensible Werte. Du kannst dafür die folgende Ressource in Terraform nutzen:
resource "aws_secretsmanager_secret" "example" {
name = "example"
}Für umgebungsspezifische Geheimnisse kannst du Umgebungsvariablen mit dem Präfix „ TF_VAR_ “ verwenden.
Du kannst zum Beispiel „ variable "aws_access_key" {} “ in der Datei „ variables.tf “ verwenden und es im Terminal mit „ export TF_VAR_aws_access_key= “ exportieren. Terraform lädt diese automatisch als Variablenwerte, ohne sie im Code anzuzeigen.
Ein weiteres wichtiges Thema bei der Konfiguration ist die Drift. Das passiert, wenn jemand die Infrastruktur über die AWS-Konsole oder die CLI ändert und Terraform dabei umgeht. Führ regelmäßig „ terraform plan “ aus, um Abweichungen zu erkennen. Der Planausdruck zeigt Ressourcen, die zwar vorhanden sind, aber nicht zu deiner Konfiguration passen.
Wenn es zu Abweichungen kommt, hast du zwei Möglichkeiten: Entweder du passt deinen Terraform-Code an die Realität an oder du führst „ terraform apply “ aus, um die Infrastruktur wieder in den gewünschten Zustand zu bringen. Die richtige Entscheidung hängt davon ab, ob die manuelle Änderung absichtlich war.
Schließlich ist es auch wichtig, alle Ressourcen zu entfernen, sobald wir wissen, dass wir sie nicht mehr brauchen, um unnötige Kosten zu vermeiden. Du kannst die Ressourcen mit dem folgenden Befehl bereinigen:
terraform destroySchau dir den Vernichtungsplan genau an. Terraform löscht alle Ressourcen, die es erstellt hat. Für die Produktion solltest du überlegen, „ terraform destroy -target “ zu nutzen, um bestimmte Ressourcen zu entfernen, statt alles.
Du hast den grundlegenden Arbeitsablauf von Terraform kennengelernt: Infrastruktur in Code definieren, Änderungen mit „ plan “ in der Vorschau anzeigen, sie mit „ apply “ anwenden und alles mit der Statusverwaltung verfolgen. Wir haben die EC2-Bereitstellung mit automatischer Agenteninstallation abgedeckt, den Status mit nativer Sperrung nach S3 verschoben, mit Variablen und Modulen skaliert und die Infrastruktur mit Geheimnisverwaltung gesichert.
Behandle Infrastrukturcode genauso streng wie Anwendungscode. Benutz Versionskontrolle, mach Code-Reviews bei Änderungen und test alles erst mal in Umgebungen, die nicht in der Produktion sind. CI/CD-Pipelines können die Infrastrukturverwaltung ( terraform apply) automatisieren, sodass Infrastruktur-Updates genauso reibungslos laufen wie die Bereitstellung von Anwendungen.
Dein nächster Schritt: Schau dir GitHub Actions oder GitLab CI an, um Terraform automatisch auszuführen, wenn du Code pushst. Dieser „Infrastructure as Code“-Ansatz, zusammen mit Automatisierung, verändert, wie Teams Cloud-Ressourcen verwalten, indem manuelle Konsolenarbeit durch eine zuverlässige, wiederholbare und versionskontrollierte Infrastruktur ersetzt wird.
Ich empfehle, auf diesem Wissen aufzubauen und dich für den AWS Cloud Practitioner (CLF-C02) Teilnehmen an einem Lernpfad, wo du alles lernst, was du für die CLF-C02-Zertifizierung von Amazon brauchst.
AWS-Kurse
Lernpfad
Kurs
Kurs
Blog
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Matt Crabtree