
Lernpfad
Containerisierung und Virtualisierung mit Docker und Kubernetes
13 Std.
Podmanist die direkteste Herausforderung für den Architekturansatz von Docker.
Bild 1 – Podman-Startseite
Red Hat hat es extra entwickelt, um das Daemon-basierte Sicherheitsmodell von Docker anzugehen und gleichzeitig mit den bestehenden Arbeitsabläufen kompatibel zu bleiben.
Wenn du einen genaueren Vergleich zwischen Docker und Podman brauchst, findest du in unserem Blogbeitrag heraus, welche Containerisierungsplattform die richtige für dich ist.
Der größte Unterschied zwischen Podman und Docker ist, dass Podman den Daemon- us komplettweglässt. Anstatt Befehle über einen zentralen Dienst zu leiten, nutzt Podman ein Fork-Exec-Modell, bei dem jeder Container als direkter untergeordneter Prozess des Benutzers läuft, der ihn gestartet hat. Das heißt, es gibt keinen dauerhaften Hintergrunddienst, keinen Single Point of Failure und keinen Daemon auf Root-Ebene, der deine Container verwaltet.
Diese Architektur passt super zu systemd, dem Standard-Dienstmanager von Linux. Du kannst systemd-Unit-Dateien direkt aus Podman-Containern erstellen, damit deine Container beim Booten automatisch starten, bei Fehlern neu starten und in die Systemprotokollierung integriert werden. Das ist viel übersichtlicher als die separate Orchestrierungsebene von Docker.
Podman hält sich komplett an die OCI-Standards, sodass es die gleichen Container-Images wie Docker ohne Änderungen ausführt. Die Laufzeitumgebung nutzt die gleichen zugrunde liegenden Technologien – „ runc “ für die Containerausführung und verschiedene Speichertreiber für die Bildverwaltung –, verpackt sie aber anders.
Der Rootless-Betrieb ist das herausragende Sicherheitsfeature von Podman. Wenn du Container mit Podman ausführst, laufen sie unter deinem Benutzerkonto und brauchen keine Root-Rechte. Das geht über die Zuordnung des Benutzernamensraums, wo der Root-Benutzer des Containers deiner nicht privilegierten Benutzer-ID auf dem Hostsystem zugeordnet wird.
Dadurch wird der Angriffsvektor beseitigt, bei dem ein Container-Ausbruch das ganze Host-System gefährden könnte. Selbst wenn ein Angreifer aus dem Container rauskommt, hat er immer noch nur die Berechtigungen deines Benutzers und keinen Root-Zugriff auf den Rechner.
Auf Red Hat Enterprise Linux- und Fedora-Systemen ist Podman eng mit SELinux (Security-Enhanced Linux) verbunden. SELinux hat strenge Zugriffskontrollen, die festlegen, worauf Container auf dem Host-System zugreifen dürfen, selbst wenn sie gehackt werden. Das sorgt für mehrere Sicherheitsebenen – Benutzernamensräume verhindern, dass jemand zu viele Rechte bekommt, während SELinux den Zugriff auf Dateisysteme ohne Erlaubnis stoppt.
In Unternehmen werden diese Funktionen oft mit zusätzlichen Tools für Sicherheitsscans und die Durchsetzung von Richtlinien kombiniert, um umfassende Verteidigungsstrategien zu schaffen.
Podman bleibt mit Docker CLI kompatibel, weil es den Befehl „ podman “ hat, der die gleichen Argumente wie „ docker “ versteht. Du kannst einen Alias (alias docker=podman) erstellen, und die meisten vorhandenen Skripte funktionieren dann ohne Änderungen. Dadurch läuft die Migration von Docker viel reibungsloser als der Wechsel zu komplett anderen Toolchains.
Die Podman Desktop GUI ist eine Alternative zu Docker Desktop für Entwickler, die lieber mit grafischen Oberflächen arbeiten. Es umfasst Container-Management, Funktionen zur Image-Erstellung und Kubernetes-Integration für die lokale Entwicklung. Die Desktop-App kann sich mit entfernten Podman-Instanzen verbinden und hat ähnliche Funktionen wie das Dashboard von Docker Desktop.
Für Kubernetes-Workflows kann Podman aus laufenden Containern Kubernetes-YAML-Manifeste erstellen und unterstützt die Pod-Verwaltung – also das Ausführen mehrerer Container, die sich Netzwerk und Speicher teilen, ähnlich wie bei Kubernetes-Pods.
Die Windows-Unterstützung ist immer noch die größte Einschränkung von Podman. Podman Machine macht zwar Windows durch Virtualisierung kompatibel, aber es läuft nicht so reibungslos wie die WSL2-Integration von Docker Desktop. Windows-Entwickler könnten die Einrichtung etwas komplizierter finden.
Rootless Networking kann die Leistung beeinträchtigen. Ohne Root-Rechte kann Podman keine Bridge-Netzwerke direkt erstellen, deshalb nutzt es User-Mode-Networking (slirp4netns), was zu einer zusätzlichen Latenz führt. Bei Entwicklungsaufgaben fällt das kaum auf, aber bei Netzwerk-Apps mit hohem Durchsatz kann es zu Leistungseinbußen kommen.
Docker Compose ist über podman-compose kompatibel, aber es hat nicht alle Funktionen von Docker Compose.. Komplexe Compose-Dateien müssen vielleicht angepasst werden, und einige erweiterte Netzwerkfunktionen werden im Rootless-Modus nicht unterstützt. Teams, die viel in Docker Compose-Workflows investiert haben, sollten vor der Migration gründlich testen.
Wie unterscheidet sich Docker Compose von Kubernetes? Unser detaillierter Vergleich gibt dir einen Überblick.
Während Podman auf Docker-Kompatibilität setzt, konzentrieren sich CRI-O und containerd speziell auf Kubernetes-Produktionsumgebungen. Diese Laufzeiten lassen unnötige Funktionen weg, um sie für koordinierte Workloads zu optimieren.
Jeder Entwickler sollte diese Unterschiede zwischen Docker und Kubernetes kennen.
CRI-O wurde von Grund auf entwickelt, um die Container-Laufzeit-Schnittstelle (CRI) von Kubernetes zu implementieren.

Bild 2 – CRI-O-Startseite
Es hat nur das, was Kubernetes braucht – keine Image-Erstellung, keine Volume-Verwaltung über das für Pods erforderliche Maß hinaus und keine eigenständige Container-Verwaltung. Dieser fokussierte Ansatz sorgt für weniger Speicherbedarf und schnellere Startzeiten im Vergleich zu Docker.
Die Ressourceneffizienz der Laufzeitumgebung kommt von ihrem minimalistischen Design. CRI-O hat keinen Daemon mit vielen APIs oder Hintergrunddiensten. Es startet Container, kümmert sich um ihren Lebenszyklus nach den Vorgaben von Kubernetes und hält sich dann raus. Das macht es super für Umgebungen mit begrenzten Ressourcen oder große Installationen, wo jedes Megabyte Speicher wichtig ist.
CRI-O unterstützt jede OCI-kompatible Laufzeitumgebung als Low-Level-Executor. Standardmäßig ist „ runc “ eingestellt, aber du kannst auch Alternativen wie „ crun “ (in C geschrieben für bessere Leistung) oder „ gVisor “ (für verbesserte Isolation) verwenden, ohne deine Kubernetes-Konfiguration zu ändern. Dank dieser Flexibilität kannst du bestimmte Sicherheits- oder Leistungsanforderungen auf Laufzeitebene optimieren.
Das Projekt hält sich strikt an die Release-Zyklen von Kubernetes, damit neue Features und Sicherheitsupdates immer zu deinen Cluster-Versionen passen.
Containerd fing als Laufzeitumgebung von Docker an, bevor es ein eigenständiges Projekt unter der Cloud Native Computing Foundation wurde.

Bild 3 – Containerd-Startseite
Docker nutzt intern immer noch containerd, aber du kannst es direkt ausführen, um die zusätzlichen Ebenen und den Overhead von Docker zu vermeiden.
Die Architektur dreht sich um eine Shim-API, die stabile Schnittstellen für die Containerverwaltung bietet. Jeder Container kriegt seinen eigenen Shim-Prozess, der den Lebenszyklus des Containers eigenständig regelt. Wenn der Haupt-Containerd-Daemon neu startet, laufen die Container einfach weiter, ohne dass es zu Unterbrechungen kommt – das ist echt wichtig für Produktions-Workloads, die keine Ausfallzeiten vertragen.
Dieses Design macht containerd super stabil für lang laufende Unternehmensanwendungen. Die Shim-Architektur macht auch Sachen wie Live-Migration und Updates ohne Ausfallzeiten möglich, bei denen du die Laufzeitumgebung upgraden kannst, ohne dass laufende Container davon betroffen sind.
Containerd hat eine eingebaute Bildverwaltung, Snapshots für effiziente Layer-Speicherung und Plugin-Systeme, um die Funktionen zu erweitern. Große Cloud-Anbieter wie AWS EKS, Google GKE und Azure AKS nutzen containerd als Standard-Laufzeitumgebung, weil die Architektur für den Produktionsbetrieb ausgelegt ist.
Hier ist ein Vergleich dieser Laufzeiten für Kubernetes-Bereitstellungen in der Produktion:
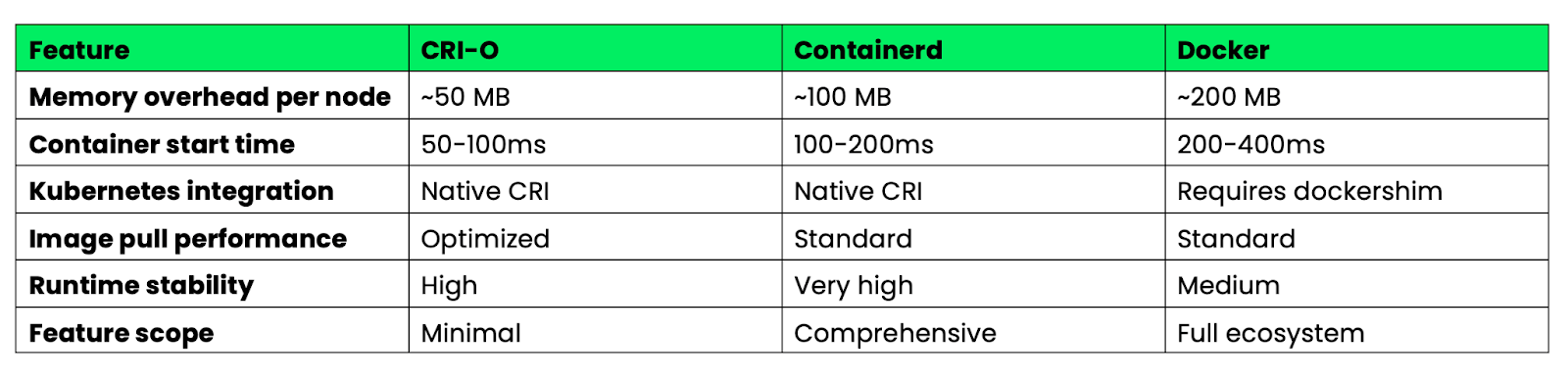
Bild 4 – Leistungsmerkmale von Docker, CRI-O und Containerd
CRI-O punktet mit minimalem Design bei Ressourceneffizienz und Startgeschwindigkeit. Containerd bietet die beste Balance zwischen Funktionen und Stabilität für Unternehmensumgebungen. Docker hat die meisten Funktionen, aber auch mehr Aufwand, der in Kubernetes-Umgebungen nicht nötig ist.
Bei Kubernetes-Clustern für die Produktion machen sowohl CRI-O als auch containerd die Docker-Kompatibilitätsschicht überflüssig, was die Komplexität verringert und die Leistung im Vergleich zu Docker-basierten Setups verbessert.
Während hochrangige Laufzeitumgebungen wie Podman und containerd sich um die Verwaltung von Images und APIs kümmern, konzentrieren sich niedrigrangige Laufzeitumgebungen nur auf die Ausführung von Containern. Diese Tools sind die Basis, auf der die meisten Containerisierungsplattformen laufen.
runC ist die Referenzimplementierung der OCI-Laufzeitspezifikation „ “ – es ist das klassische Beispiel dafür, wie Container eigentlich laufen sollten. Die meisten Container-Plattformen nutzen runC als ihre Ausführungs-Engine, zum Beispiel Docker, containerd, CRI-O und Podman. Wenn du einen Container mit einem dieser Tools startest, kümmert sich wahrscheinlich runC um die eigentliche Prozess-Erstellung und -Isolierung.
Die Laufzeitumgebung macht die grundlegenden Container-Primitive: Sie erstellt Linux-Namespaces für die Isolierung, richtet cgroups für Ressourcenbeschränkungen ein und konfiguriert Sicherheitskontexte. Es ist in Go geschrieben und soll einfach, zuverlässig und spezifikationskonform sein, statt mit vielen Funktionen vollgepackt.
runC ist super für eingebettete Systeme und benutzerdefinierte Container-Stacks, wo du vorhersehbares Verhalten und möglichst wenige Abhängigkeiten brauchst. Da es nur die Ausführung von Containern übernimmt, kannst du darauf spezialisierte Containerplattformen aufbauen, ohne unnötige Komplexität zu übernehmen. IoT-Geräte, Edge-Computing-Plattformen und maßgeschneiderte Orchestrierungssysteme nutzen oft direkt runC, statt höhere Laufzeitumgebungen.
Das Tool ist ein Befehlszeilenprogramm, das OCI-Bundle-Spezifikationen liest und entsprechend Container erstellt. Das macht es super, um es in bestehende Systeme einzubauen oder eigene Container-Management-Tools zu entwickeln.
Youki reimplemiertdie OCI-Laufzeitspezifikation in Rust und legt dabei den Fokus auf Speichersicherheit und Leistung. Die Rust-Implementierung beseitigt ganze Klassen von Sicherheitslücken, die C- und Go-Laufzeiten beeinträchtigen können, und verbessert gleichzeitig die Startzeiten von Containern durch eine bessere Speicherverwaltung und reduzierten Overhead.
Benchmarks zeigen, dass Youki Container in vielen Fällen schneller startet als runC, auch wenn die genaue Verbesserung je nach Arbeitslast unterschiedlich ist. Diese Verbesserung kommt von Rusts Nullkosten-Abstraktionen und effizienteren Speicherzuweisungsmustern. Bei Anwendungen, die viele kurzlebige Container erstellen und löschen, können diese Verbesserungen der Startzeit echt wichtig sein.
Youki ist komplett kompatibel mit der OCI-Laufzeitspezifikation, sodass es auf den meisten Containerplattformen als Ersatz für runC verwendet werden kann. Docker Engine, containerd und andere High-Level-Laufzeitumgebungen können Youki ohne Änderungen an ihrer Konfiguration oder ihren APIs nutzen.
Die Laufzeit ist super für Workloads, bei denen es auf Leistung ankommt, wie serverlose Funktionen, CI/CD-Pipelines mit vielen Container-Builds und Microservices-Architekturen mit häufigen Skalierungsereignissen. Die schnelleren Startzeiten bedeuten in diesen Fällen direkt weniger Wartezeit beim Kaltstart und eine bessere Nutzung der Ressourcen.
Youki hat auch Funktionen wie cgroup v2-Optimierung und verbesserte Rootless-Container-Unterstützung, die das Typsystem von Rust nutzen, um Konfigurationsfehler beim Kompilieren zu vermeiden.
Nicht jede Containerisierung muss sich auf einzelne Anwendungen konzentrieren – manchmal muss man ganze Betriebssysteme in Containern ausführen. LXC und LXD bieten Containerisierung auf Systemebene, die sich total von Dockers anwendungsorientiertem Ansatz unterscheidet.
LXC (Linux Containers)macht Container, die sich wie komplette Linux-Systeme verhalten und nicht wie isolierte Anwendungsprozesse.
Bild 5 – LXC-Startseite
Jeder LXC-Container hat sein eigenes Init-System, kann mehrere Dienste hosten und bietet eine komplette Userspace-Umgebung, die man kaum von einer virtuellen Maschine unterscheiden kann.
Dieser Ansatz eignet sich besonders für ältere Workloads, die nicht für die Containerisierung konzipiert wurden. Apps, die auf /etc schreiben, Systemdienste ausführen oder mit der ganzen Dateisystemhierarchie interagieren sollen, laufen in LXC-Containern ohne Probleme. Du kannst ganze Serverkonfigurationen in LXC verschieben, ohne die Anwendungen für Microservices-Architekturen umbauen zu müssen.
LXC-Container nutzen den Host-Kernel, bieten aber eine stärkere Isolierung als Anwendungscontainer. Jeder Container kriegt seinen eigenen Netzwerkstack, Prozessbaum und Dateisystem-Namespace, was eine VM-ähnliche Isolierung schafft, ohne den Aufwand von Hardware-Virtualisierung.
LXD, jetzt unter Canonical als „“ bekannt, erweitert LXC um eine leistungsstarke Verwaltungsebene. LXD bietet REST-APIs, Bildverwaltung und coole Funktionen wie Live-Migration zwischen Hosts. Du kannst laufende Container ohne Ausfallzeiten zwischen physischen Maschinen verschieben, ähnlich wie bei VMware vMotion, aber mit Containern.
Dank Hardware-Passthrough-Funktionen können LXD-Container direkt auf GPUs, USB-Geräte und andere Hardware zugreifen. Das macht es super für Aufgaben, die speziellen Hardwarezugriff brauchen, während die Vorteile von Containern wie Dichte und schnelle Bereitstellung erhalten bleiben.
LXD unterstützt auch Clustering, sodass du mehrere Hosts als eine logische Einheit mit automatischer Platzierung und Failover-Funktionen verwalten kannst.
Hier siehst du, wie sich Systemcontainer und Anwendungscontainer in wichtigen Punkten unterscheiden:
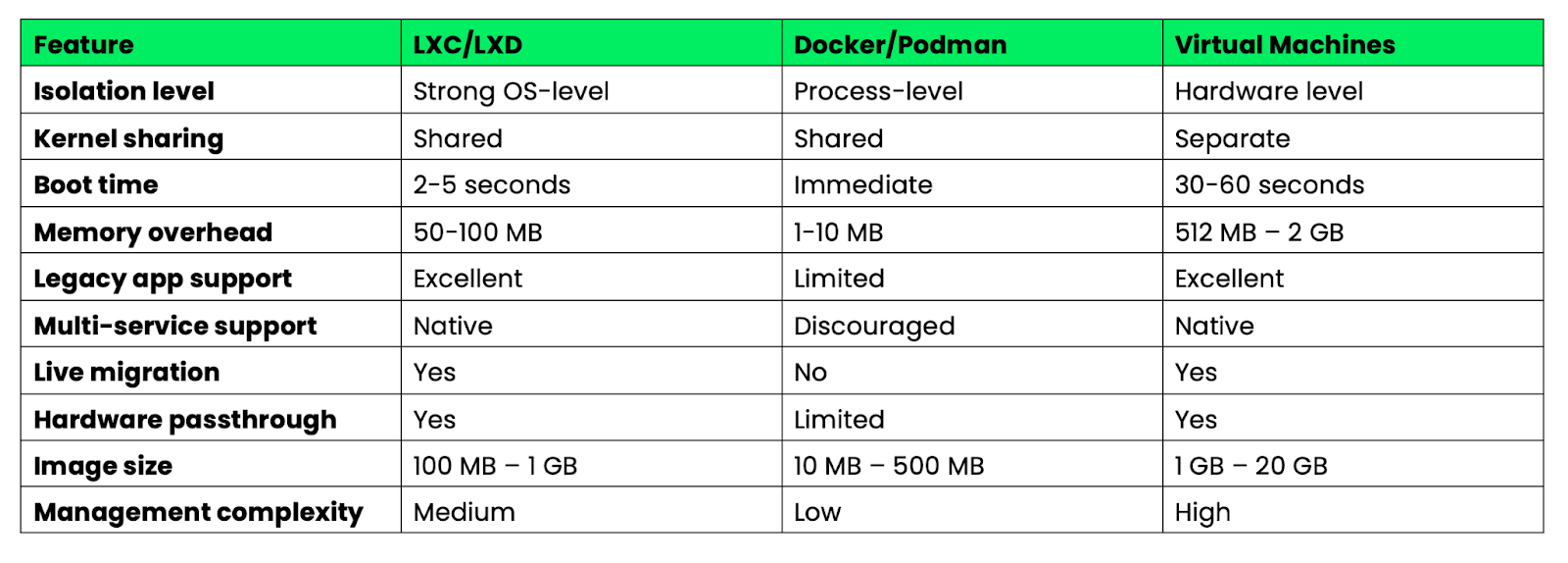
Bild 6 – Docker vs. LXC vs. Virtuelle Maschinen – Überblick über die wichtigsten Eigenschaften
Systemcontainer schließen die Lücke zwischen leichten Anwendungscontainern und schweren virtuellen Maschinen. Die sind super, wenn du VM-ähnliche Funktionen mit der Effizienz von Containern brauchst oder wenn du alte Anwendungen migrierst, die sich nicht einfach in Microservices aufteilen lassen.
Die Entscheidung zwischen System- und Anwendungscontainern hängt eher von deinen Arbeitslastmerkmalen und betrieblichen Anforderungen ab als von der technischen Überlegenheit – sie lösen unterschiedliche Probleme im Bereich der Containerisierung.
Sicherheit hat sich in modernen Container-Laufzeitumgebungen von einem nachträglichen Gedanken zu einem zentralen Designprinzip entwickelt. Heutige Plattformen setzen auf umfassende Verteidigungsstrategien, die davon ausgehen, dass Container angegriffen werden, und konzentrieren sich darauf, den Schaden zu begrenzen.
Rootless-Container beseitigen das größte Sicherheitsrisiko bei herkömmlichen Docker-Bereitstellungen – den Root-Daemon. Podman hat diesen Ansatz eingeführt, indem Container komplett mit Benutzerrechten laufen und Linux-Benutzernamensräume nutzen, um den Root-Benutzer des Containers einer nicht privilegierten Benutzer-ID auf dem Hostsystem zuzuordnen.
Die Umsetzung nutzt untergeordnete Benutzer- und Gruppen-ID-Bereiche (/etc/subuid und /etc/subgid), die es Benutzern ohne Sonderrechte ermöglichen, isolierte Namespaces zu erstellen. Wenn ein Containerprozess denkt, dass er als root (UID 0) läuft, ordnet der Kernel das deiner echten Benutzer-ID (z. B. UID 1000) auf dem Host zu. Selbst wenn ein Angreifer aus dem Container entkommt, kann er die Berechtigungen deines Benutzers nicht überschreiten.
Containerd hat ähnliche Rootless-Funktionen über seinen Rootless-Modus eingebaut, der die gleichen Techniken zum Zuordnen von Benutzernamenräumen nutzt. Die Laufzeitumgebung kann Container starten, Images verwalten und Netzwerke handhaben, ohne Root-Rechte auf dem Host-System zu brauchen.
Kubernetes unterstützt jetzt nativ den rootless-Betrieb durchdas Kubernetes-in-Rootless-Docker (KIND) -Projekct und die Integration von rootless containerd. Das heißt, ganze Kubernetes-Cluster können ohne Root-Rechte laufen, was die Angriffsfläche für Multi-Tenant-Umgebungen und Edge-Bereitstellungen, wo traditionelle Sicherheitsmodelle nicht funktionieren, echt verringert.
Die Auswirkungen auf die Sicherheit gehen über die Verhinderung von Privilegieneskalationen hinaus. Rootless-Container können keine privilegierten Ports (unter 1024) nutzen, nicht auf die meisten Dateisysteme „ /proc ” und „ /sys ” zugreifen und keine Vorgänge ausführen, die Kernel-Fähigkeiten brauchen. Das schafft natürliche Grenzen, die mögliche Sicherheitslücken eindämmen.
Moderne Laufzeitumgebungen haben eBPF (extended Berkeley Packet Filter) eingebaut, um Sicherheitsrichtlinien in Echtzeit durchzusetzen, was über die üblichen Zugriffskontrollen hinausgeht. eBPF-Programme laufen im Kernel-Bereich und können Systemaufrufe in Echtzeit überwachen, filtern oder ändern, was eine ganz neue Transparenz und Kontrolle über das Container-Verhalten ermöglicht.
Seccomp-Profile (Secure Computing) nutzen BPF, um Systemaufrufe auf Kernel-Ebene zu filtern. Anstatt Containern Zugriff auf alle über 300 Linux-Systemaufrufe zu geben, legen seccomp-Profile genau fest, welche Aufrufe erlaubt sind. Das Standard-Seccomp-Profil von Docker blockiert potenziell gefährliche Systemaufrufe, während benutzerdefinierte Profile je nach Anwendungsanforderungen noch restriktiver sein können.
Die erweiterte eBPF-Integration macht es möglich, das Verhalten in Echtzeit zu beobachten. Tools wie Falco nutzen eBPF-Programme, um komisches Container-Verhalten zu erkennen – wie ungewöhnliche Netzwerkverbindungen, überraschende Dateizugriffsmuster oder Versuche, gesperrte Systemaufrufe zu nutzen. Diese Erkennungen laufen in Echtzeit und mit minimalem Performance-Overhead, weil die Überwachung im Kernel-Bereich stattfindet.
Die Durchsetzung von Netzwerkrichtlinien über eBPF ermöglicht eine detaillierte Verkehrssteuerung auf Paketebene. Cilium, ein beliebtes Kubernetes CNI, nutzt eBPF, um Netzwerkrichtlinien umzusetzen, die den Datenverkehr nicht nur nach IP-Adressen und Ports, sondern auch nach Protokollen der Anwendungsschicht filtern können. Das heißt, du kannst direkt im Kernel Richtlinien wie „HTTP-GET-Anfragen an /api/v1/users zulassen, aber POST-Anfragen blockieren” erstellen.
Die eBPF-basierte Sicherheit macht auch eine containerorientierte Überwachung möglich, die die Beziehungen zwischen Prozessen, Containern und Kubernetes-Pods versteht. Herkömmliche Überwachungs-Tools sehen einzelne Prozesse, aber eBPF-Programme können Systemaufrufe mit Container-Metadaten verknüpfen, um kontextbezogene Sicherheitsinformationen zu liefern.
Diese Funktionen machen Sicherheit nicht mehr nur zu reaktiven Patches, sondern zu proaktiver Durchsetzung von Richtlinien, bei der verdächtiges Verhalten automatisch blockiert wird, bevor es Schaden anrichten kann.
Die Container-Performance ist super wichtig, wenn du Hunderte oder Tausende von Containern in deiner Infrastruktur laufen hast. Schauen wir uns mal Strategien an, die den Ressourcenaufwand und die Startverzögerung minimieren.
Die Kaltstartzeit – also die Zeit zwischen der Anforderung eines Containers und dem Zeitpunkt, zu dem er für den Datenverkehr bereit ist – beeinflusst direkt die Benutzererfahrung und die Ressourceneffizienz. Es gibt jetzt Techniken, die diese Verzögerungen in verschiedenen Laufzeitarchitekturen minimieren.
Vorgefertigte Images sparen Downloadzeit, weil oft genutzte Container-Images auf den Knoten zwischengespeichert werden. Kubernetes DaemonSets können wichtige Images schon mal runterladen, während Registries wie Harbor die Replikation von Images an Edge-Standorte unterstützen. Mit dieser Technik kann man die Kaltstartzeit für zwischengespeicherte Bilder von Sekunden auf Millisekunden verkürzen.
Die Optimierung der Bildebene reduziert die Menge an Daten, die übertragen und extrahiert werden müssen. Mehrstufige Builds machen die endgültigen Bilder kleiner, während Tools wie „dive“ dabei helfen, unnötige Ebenen zu erkennen. Distroless-Images von Google machen Paketmanager und shell überflüssig, was die Image-Größen oft deutlich reduziert.
Lazy Loading mit Projekten wie Stargz lässt „ “-Container starten, bevor das ganze Image runtergeladen ist. Die Laufzeitumgebung holt nur die Dateien, die für den ersten Start gebraucht werden, und lädt weitere Ebenen nach Bedarf runter. Dadurch kann die Kaltstartzeit bei großen Bildern von mehreren Sekunden auf unter 1 Sekunde reduziert werden.
Die Laufzeitoptimierung „ “ hängt von der jeweiligen Implementierung ab. Youkis Rust-Implementierung läuft dank besserem Speichermanagement schneller als runC. Crun, geschrieben in C, schafft ähnliche Verbesserungen, indem es den Overhead der Garbage Collection von Go bei der Erstellung von Containern vermeidet.
Die Snapshot-Freigabe- -Funktion in containerd ermöglicht es mehreren Containern, schreibgeschützte Dateisystem-Snapshots gemeinsam zu nutzen, wodurch sowohl Speicherplatz als auch Speicherbedarf reduziert werden. Wenn du mehrere Container aus demselben Image startest, musst du nur die beschreibbaren Ebenen separat zuweisen.
Optimierung des Init-Prozesses kann die Startzeit verkürzen, indem man leichte Init-Systeme wie tini nutzt oder die Startsequenzen der Anwendungen so plant, dass die Initialisierungsarbeit minimiert wird.
Der Speicherbedarf ist bei den verschiedenen Container-Laufzeiten unterschiedlich, und diese Unterschiede werden in Umgebungen mit begrenzten Ressourcen oder bei Bereitstellungen mit hoher Dichte echt kritisch.
Der Overhead der Laufzeit-Baseline unterscheiden sich stark:
Die Deduplizierung von Image-Layern spart Speicherplatz, wenn mehrere Container aus verwandten Images ausgeführt werden. Container-Laufzeiten nutzen Copy-on-Write-Dateisysteme, bei denen gemeinsam genutzte Ebenen den Speicher nur einmal für alle Container belegen. Ein Cluster, der viele Container aus ähnlichen Basis-Images ausführt, kann durch Deduplizierung echt viel Speicher sparen.
Die Optimierung der Speicherzuordnung in modernen Laufzeitumgebungen reduziert die Nutzung des residenten Speichers. Tools wie crun führen ausführbare Dateien direkt vom Speicher aus, anstatt sie in den Arbeitsspeicher zu laden, wodurch der Speicherbedarf für Container mit großen Binärdateien reduziert wird.
Die Cgroup-Speicherabrechnung gibt dir genaue Kontrolle über die Speichergrenzen von Containern, aber verschiedene Laufzeiten gehen unterschiedlich mit Speicherbelastung um. Manche Laufzeitumgebungen holen unter Druck mehr Speicher zurück, während andere genauere Berichte zur Speicherauslastung für Entscheidungen zur automatischen Skalierung liefern.
Der Rootless-Memory-Overhead- us tauscht ein bisschen Effizienz gegen mehr Sicherheit ein. Rootless-Container brauchen zusätzliche Prozesse für die Verwaltung des Benutzernamensraums und die Vernetzung, was im Vergleich zum Rootful-Betrieb normalerweise mehr Aufwand bedeutet.
Die Entscheidung zwischen Laufzeitumgebungen hängt oft davon ab, wie man Speichereffizienz und Funktionsanforderungen gegeneinander abwägt. CRI-O sorgt für wenig Overhead bei Kubernetes-Workloads, während Podman ein bisschen Effizienz für mehr Sicherheit und Kompatibilität eintauscht.
Die beste Container-Laufzeitumgebung ist nutzlos, wenn sie nicht zu deinem Entwicklungs-Workflow passt. Docker-Alternativen haben Tools, die in bestimmten Situationen oft besser sind als die Entwicklererfahrung von Docker.
Die lokale Kubernetes-Entwicklung hat sich von Minikubes Ansatz mit virtuellen Maschinen zu effizienteren Lösungen entwickelt, die direkt in Container-Laufzeiten integriert sind. Die Wahl der lokalen Umgebung hat einen großen Einfluss auf die Entwicklungsgeschwindigkeit und den Ressourcenverbrauch.
Kind (Kubernetes in Docker) baut Kubernetes-Cluster mit Containerknoten statt mit virtuellen Maschinen auf. Die Einrichtung dauert normalerweise 1–2 Minuten und braucht pro Knoten ein bisschen Speicherplatz. Kind funktioniert mit jeder Docker-kompatiblen Laufzeitumgebung, sodass du es mit Podman (kind create cluster --runtime podman) für die rootless Kubernetes-Entwicklung nutzen kannst.
K3s bietet eine schlanke Option, die eine komplette Kubernetes-Distribution mit minimalem Speicherverbrauch laufen lässt. Es läuft schnell und hat integrierten Speicher, Netzwerkfunktionen und Ingress-Controller. K3s funktioniert super mit containerd und läuft auch auf Entwicklungsrechnern mit wenig Ressourcen.
MicroK8s von Canonical ist ein guter Mittelweg mit nicht so viel Speicherbedarf und modularen Add-ons. Es lässt sich gut mit containerd integrieren und bietet produktionsähnliche Funktionen ohne den Aufwand einer virtuellen Maschine. Die Startzeit ist für einen kompletten Cluster okay.
Rancher Desktop verbindet K3s mit Containerd- oder Dockerd-Backends und bietet so eine Alternative zu Docker Desktop, die weniger Ressourcen verbraucht. Es hat eine eingebaute Bildscannerfunktion und ist mit dem Kubernetes-Dashboard verbunden.
Podman-Pods bieten eine coole Alternative – du kannst Multi-Container-Anwendungen mit dem Pod-Konzept von Podman entwickeln, das dem Verhalten von Kubernetes-Pods ähnelt. Mach Kubernetes YAML direkt aus laufenden Pods mit „ podman generate kube “ und schaff so einen nahtlosen Weg von der lokalen Entwicklung bis zur Cluster-Bereitstellung.
Traditionelle Docker-basierte CI/CD-Pipelines stoßen in containerisierten Umgebungen an Grenzen, wo die Ausführung von Docker-in-Docker Sicherheits- und Leistungsprobleme mit sich bringt. Moderne Alternativen bieten bessere Möglichkeiten, Container-Images in CI-Systemen zu erstellen und zu pushen.
Buildah -Excel-s in CI-Umgebungen, weil es keinen Daemon und keine Root-Rechte braucht. Du kannst OCI-konforme Images mit shell-Skripten erstellen, die besser überprüfbar sind als Dockerfiles. Der Skriptansatz von Buildah ermöglicht die dynamische Erstellung von Images auf Basis von CI-Variablen und eignet sich daher super für komplexe Build-Prozesse, die bedingte Logik brauchen.

Bild 7 – Buildah-Startseite
Zum Vergleich: Traditionelle Dockerfiles nutzen deklarative Anweisungen:
FROM alpine:latest
RUN apk add --no-cache nodejs npm
COPY package.json /app/
WORKDIR /appBuildah nutzt imperative shell-Befehle, die Variablen und bedingte Logik enthalten können:
# Buildah scripting approach with CI integration
buildah from alpine:latest
buildah run $container apk add --no-cache nodejs npm
buildah copy $container package.json /app/
buildah config --workingdir /app $container
buildah commit $container myapp:${CI_COMMIT_SHA}Dank dieser Flexibilität beim Scripting kannst du Basisimages dynamisch auswählen, Pakete basierend auf Branch-Namen installieren oder Build-Schritte anhand von CI-Umgebungsvariablen anpassen – Funktionen, die in herkömmlichen Dockerfiles komplexe Workarounds erfordern.
Kaniko löst das Problem „“ und „Docker-in-Docker“, indem es Images komplett im Userspace innerhalb eines Containers erstellt. Es läuft in Kubernetes-Pods, ohne dass privilegierter Zugriff oder ein Docker-Daemon nötig sind. Kaniko funktioniert super in GitLab CI- und Jenkins X-Pipelines, wo Sicherheitsrichtlinien privilegierte Container verhindern.
Das Tool holt Basis-Images, macht die Anweisungen aus der Dockerfile einzeln und schickt die Ergebnisse direkt in die Registries. Die Erstellungszeiten sind ähnlich wie bei Docker, aber mit viel besserer Sicherheit in orchestrierten Umgebungen.
Nerdctl bietet Docker-CLI-Kompatibilität ( ) für containerd, was es zu einem super Ersatz für Docker in CI-Systemen macht. Es unterstützt die gleichen Befehle zum Erstellen, Pushen und Pullen wie Docker, nutzt aber containerd als Backend. Dadurch wird der Docker-Daemon entfernt, während die gewohnten Arbeitsabläufe beibehalten werden.
Nerdctl hat coole Funktionen wie Lazy Pulling und verschlüsselte Images, die die CI-Performance verbessern können. Für Teams, die containerd in der Produktion nutzen, sorgt nerdctl für Konsistenz zwischen CI- und Laufzeitumgebungen.
Leistungsvergleich in CI-Pipelines:
Die Entscheidung hängt von deinen Sicherheitsanforderungen, der vorhandenen Infrastruktur und den Leistungsanforderungen ab. Kaniko läuft am besten in Kubernetes-Umgebungen, wo Sicherheit wichtig ist, während Buildah super ist, wenn du komplexe Build-Logik brauchst, die in Dockerfiles schwer auszudrücken ist.
Für Container-Implementierungen in Unternehmen reicht es nicht, nur die richtige Laufzeitumgebung auszuwählen – du brauchst Plattformen, die Compliance, Governance und Multi-Cluster-Operationen in großem Maßstab abdecken. Die Container-Alternativen, die du auswählst, müssen mit den Unternehmensmanagement-Tools zusammenarbeiten und die gesetzlichen Anforderungen erfüllen.
Um Container über mehrere Cluster, Clouds und Edge-Standorte hinweg zu verwalten, braucht man ausgeklügelte Orchestrierungsplattformen, die über das einfache Kubernetes hinausgehen. Unternehmenslösungen bieten zentralisierte Verwaltung, Durchsetzung von Richtlinien und einheitliche Abläufe in verschiedenen Umgebungen.
Red Hat OpenShift macht Kubernetes zu einer „ “ mit Container-Laufzeitoptionen, die auf Unternehmen zugeschnitten sind. OpenShift nutzt standardmäßig CRI-O, weil es im Vergleich zu Docker-basierten Bereitstellungen sicherer ist und die Ressourcen besser nutzt. Die Plattform hat integrierte Funktionen für das Scannen von Images, die Durchsetzung von Richtlinien und Entwickler-Workflows, die immer gleich funktionieren, egal ob du AWS, Azure oder eine lokale Infrastruktur nutzt.

Bild 8 – Startseite von Red Hat OpenShift
Das Multi-Cluster-Management von OpenShift kümmert sich um die Standardisierung der Laufzeitumgebungen über verschiedene Umgebungen hinweg. Du kannst festlegen, dass alle Cluster CRI-O mit bestimmten Sicherheitsrichtlinien nutzen, damit das Verhalten immer gleich ist, egal ob die Container in Entwicklungs-, Staging- oder Produktionsumgebungen laufen.
Rancher bietet mit „“ eine einheitliche Oberfläche für die Verwaltung von Kubernetes-Clustern, egal welche Container-Laufzeitumgebung dahintersteckt. Rancher unterstützt Cluster, die mit Docker, containerd oder CRI-O laufen, sodass du Laufzeiten nach und nach migrieren kannst, ohne den Betrieb zu stören. Die Plattform bietet zentrale Überwachung, Datensicherung und Sicherheitsscans für alle verwalteten Cluster.
Bild 9 – Rancher-Startseite
Der Ansatz von Rancher ist super, wenn du gemischte Umgebungen hast – manche Cluster nutzen vielleicht containerd wegen der Performance, während andere CRI-O wegen der Sicherheit verwenden. Die Managementebene macht diese Unterschiede unsichtbar und bietet gleichzeitig einheitliche Betriebswerkzeuge.
Die Mirantis Kubernetes Engine ist für Docker-Umgebungen in Unternehmen gedacht, kann aber auch für containerd-basierte Bereitstellungen genutzt werden. Die Plattform bietet Unternehmenssupport, Sicherheitsoptimierung und Compliance-Tools, die über verschiedene Container-Laufzeiten hinweg funktionieren.
Bild 10 – Mirantis-Startseite
Diese Plattformen machen Schluss mit der ganzen Komplexität beim Betrieb verschiedener Container-Laufzeiten in deiner Infrastruktur und sorgen gleichzeitig für zentrale Governance und Sicherheitsrichtlinien.
In Unternehmensumgebungen muss man oft Vorschriften wie FIPS 140-2, SOC 2 oder DSGVO einhalten, was sich direkt auf die Auswahl und Konfiguration der Container-Laufzeitumgebung auswirkt. Bei der Compliance geht's nicht nur um die Laufzeit selbst – sie umfasst auch Image-Registries, Sicherheitsscans und Audit-Protokollierung.
Die FIPS-Validierung (Federal Information Processing Standards) braucht Kryptografiemodule, die den Sicherheitsstandards der Regierung entsprechen. Nicht alle Container-Laufzeiten unterstützen FIPS-validierte Kryptografie-Bibliotheken. Red Hat Enterprise Linux hat FIPS-konforme Versionen von CRI-O und Podman, während man bei normalen Docker-Installationen oft noch was extra einstellen muss, um FIPS-konform zu sein.
Die FIPS-Konformität betrifft die Bildsignatur, die TLS-Kommunikation und die verschlüsselte Speicherung. Containerplattformen müssen FIPS-validierte Kryptografie-Bibliotheken für alle Sicherheitsvorgänge nutzen, vom Abrufen von Images bis zum Aufbau von Netzwerkverbindungen zwischen Containern.
Die DSGVO-Konformitäts en beeinflussen, wie Containerplattformen mit personenbezogenen Daten in Protokollen, Metriken und Bildmetadaten umgehen. Container-Registries für Unternehmen wie Harbor, Quay und AWS ECR bieten Funktionen wie Kontrollen zur Datenresidenz, Audit-Protokollierung und automatisierte Richtlinien zur Datenaufbewahrung.
Container-Laufzeiten müssen Compliance-Funktionen unterstützen, wie zum Beispiel:
Die SOC 2-Konformität erfordert nachweisbare Sicherheitskontrollen in den Bereichen Zugriffsverwaltung, Systemüberwachung und Datenschutz. Containerplattformen müssen mit Identitätsanbietern von Unternehmen zusammenarbeiten, detaillierte Prüfpfade bieten und die automatische Durchsetzung von Sicherheitsrichtlinien unterstützen.
Moderne Container-Laufzeitumgebungen wie CRI-O und containerd bieten eine bessere Compliance-Grundlage als Docker, weil sie detailliertere Sicherheitskontrollen, bessere Audit-Protokollierung und eine klarere Trennung zwischen Laufzeitkomponenten und Verwaltungsschnittstellen bieten.
Die Einhaltung der Vorschriften gilt auch für die Sicherheit der Lieferkette – es muss sichergestellt werden, dass Container-Images aus vertrauenswürdigen Quellen stammen und nicht manipuliert wurden. Tools wie Sigstore und in-toto bieten eine kryptografische Überprüfung der Herkunft von Container-Images, während Zulassungscontroller dafür sorgen können, dass nur signierte, gescannte Images in Produktionsclustern laufen.
Die Containerisierung entwickelt sich immer weiter, weg von den klassischen Linux-Containern und hin zu neuen Ausführungsmodellen und Beobachtungsparadigmen. Diese neuen Technologien versprechen, grundlegende Einschränkungen der aktuellen Containerarchitekturen zu lösen.
WebAssembly (WASM) entwickelt sich zu einer coolen Alternative zu den üblichen OCI-Containern für bestimmte Aufgaben. Anders als Container, die den ganzen Benutzerbereich eines Betriebssystems verpacken, bietet WebAssembly eine leichte, sandboxbasierte Ausführungsumgebung, die auf verschiedenen Architekturen mit nahezu nativer Geschwindigkeit läuft.
WASM-Module starten viel schneller als herkömmliche Container und sind daher super für serverlose Funktionen und Edge-Computing, wo die Kaltstartzeit direkt die Benutzererfahrung beeinflusst. Ein WebAssembly-Modul kann viel mehr Anfragen abwickeln als ein Container mit längeren Initialisierungszeiten.
Das Sicherheitsmodell ist total anders als bei Containern. WebAssembly bietet kapazitätsbasierte Sicherheit, bei der Module nur auf explizit gewährte Ressourcen zugreifen können. Es gibt keine gemeinsame Kernel-Oberfläche wie bei herkömmlichen Containern – WASM-Module laufen in einer Sandbox-Umgebung, die viele Arten von Sicherheitslücken verhindert.
Container-Laufzeiten fangen an, WebAssembly-Workloads direkt zu unterstützen. Wasmtime verbindet „ “ mit „containerd“ als Laufzeit-Shim, sodass du WASM-Module mit Standard-Kubernetes-YAML bereitstellen kannst. Das heißt, du kannst traditionelle Container und WebAssembly-Workloads im selben Cluster mischen, je nachdem, was die Performance- und Sicherheitsanforderungen erfordern.
Der Kompromiss ist die Reife des Ökosystems. WebAssembly hat im Vergleich zu Containern nur begrenzte Sprachunterstützung – Rust, C/C++ und AssemblyScript funktionieren gut, während Sprachen wie Python und Java zusätzliche Laufzeit-Layer brauchen, die die Leistungsvorteile verringern.
WASM ist super für Rechenaufgaben, serverlose Funktionen und Edge-Computing, aber noch nicht so weit, Container für komplexe Anwendungen zu ersetzen, die eine umfassende Betriebssystemintegration brauchen.
eBPF (extended Berkeley Packet Filter) verändert die Beobachtbarkeit von Containern, indem es Einblicke auf Kernel-Ebene bietet, ohne dass man die Anwendung ändern oder Sidecar-Container einsetzen muss. Anders als bei der herkömmlichen Überwachung, die sich auf von Anwendungen exportierte Metriken stützt, beobachten eBPF-Programme Systemaufrufe, Netzwerkverkehr und Kernel-Ereignisse in Echtzeit.
Container-bewusste Überwachung durch eBPF verbindet Low-Level-Systemereignisse mit höheren Container- und Kubernetes-Metadaten. Tools wie Pixie und Cilium Hubble von T-ndir genau zeigen, welche HTTP-Anfragen zwischen bestimmten Pods laufen, einschließlich der Latenz der Anfragen, der Überprüfung der Nutzlast und der Fehlerraten, und das alles, ohne dass du deine Anwendungen ändern musst.
Dieser Ansatz gibt dir einen super Einblick in die Kommunikationsmuster von Microservices. Du kannst Servicekarten automatisch erstellen, indem du die tatsächlichen Netzwerkflüsse beobachtest, anstatt dich auf statische Konfigurationen zu verlassen. Wenn ein Dienst anfängt, mit einer neuen Abhängigkeit zu kommunizieren, merken die eBPF-basierten Tools das sofort und aktualisieren die Diensttopologie in Echtzeit.
Leistungsprofilierung von über eBPF zeigt Engpässe auf Containerebene auf. Anstatt zu raten, warum ein Pod langsam ist, kannst du genau sehen, welche Systemaufrufe Zeit kosten, auf welche Dateien zugegriffen wird und wie sich die Netzwerklatenz auf die Anwendungsleistung auswirkt. Diese Daten werden ständig gesammelt, und das mit minimalem Aufwand, normalerweise mit weniger als 1 % CPU-Auslastung.
Sicherheitsüberwachungs s profitieren von der Fähigkeit von eBPF, ungewöhnliche Verhaltensmuster zu erkennen. Anstatt Protokolle nach einem Vorfall zu checken, können eBPF-Programme verdächtige Systemaufrufe, unerwartete Netzwerkverbindungen oder Dateizugriffsmuster erkennen, sobald sie passieren. Das ermöglicht eine Echtzeit-Bedrohungserkennung, die die Container-Grenzen und die Identität der Kubernetes-Workloads im Blick hat.
Die Integration zwischen eBPF und Container-Laufzeiten wird immer besser. Cilium bietet eBPF-basierte Netzwerke für Kubernetes, die schneller und besser zu beobachten sind als herkömmliche CNI-Plugins. Falco nutzt eBPF für die Sicherheitsüberwachung während der Laufzeit, die den Container-Kontext von Haus aus versteht.
Dieser Trend zur Beobachtbarkeit auf Kernel-Ebene ist eine echte Veränderung von der Black-Box-Überwachung hin zu vollständiger Systemtransparenz, wodurch Containerumgebungen standardmäßig besser debugbar und sicherer werden.
Bei der Wahl der richtigen Docker-Alternative geht's nicht darum, einen einzigen Ersatz zu finden, sondern darum, die Tools an die spezifischen Anwendungsfälle in deinen Entwicklungs- und Produktionsumgebungen anzupassen. Das Containerisierungs-Ökosystem hat sich zu einer Reihe von Lösungen entwickelt, die in verschiedenen Szenarien echt gut sind.
Für Entwickler bietet Podman dank seiner Kompatibilität mit der Docker-CLI den reibungslosesten Migrationspfad und sorgt gleichzeitig durch rootless Betrieb für höchste Sicherheit. Wenn du viel in Docker Desktop-Workflows investiert hast, bietet Rancher Desktop mit containerd ähnliche Funktionen bei besserer Ressourceneffizienz. Teams, die komplexe CI/CD-Pipelines aufbauen, können von der Flexibilität der Skripte von Buildah oder dem sicheren, daemonfreien Ansatz von Kaniko profitieren.
Im Produktionsmaßstab bieten, containerd und CRI-O eine bessere Leistung und Ressourceneffizienz als Docker Engine. Containerd ist super für Unternehmensumgebungen, die Stabilität und viele Funktionen brauchen, während CRI-O die effizienteste Option für Kubernetes-basierte Bereitstellungen ist. Für Edge-Computing oder eingebettete Systeme bieten leichte Laufzeitumgebungen wie runC oder Youki den minimalen Overhead, den man für ressourcenbeschränkte Umgebungen braucht.
Sicherheitsbewusste Unternehmen sollten rootless Runtimes wie Podman oder rootless containerd bevorzugen. Die Kombination aus Isolierung des Benutzer-Namespace, eBPF-basierter Überwachung und reduzierter Angriffsfläche bietet einen umfassenden Schutz, den herkömmliche Docker-Bereitstellungen nicht bieten können. Für regulierte Branchen solltest du sicherstellen, dass die von dir gewählte Laufzeitumgebung FIPS-konform ist und sich in die Audit-Protokollierungssysteme deines Unternehmens einbinden lässt.
Ein hybrider Ansatz klappt in der Praxis oft am besten. Nutze Podman für die lokale Entwicklung, um von Rootless-Sicherheit und Docker-Kompatibilität zu profitieren. Mach deine Produktions-Workloads auf Containerd oder CRI-O, um die Kubernetes-Integration und Leistung zu optimieren. Benutz spezielle Tools wie Buildah für CI/CD-Pipelines, wo Sicherheit und Flexibilität wichtiger sind als Kompatibilität.
Suchst du Ideen für Docker- und Containerisierungsprojekte? Diese 10 helfen dir beim Einstieg.
Für die Zukunft sind WebAssembly und eBPF die nächste Stufe in der Containerisierungs. Die schnellen Startzeiten und die starken Sicherheitsgarantien von WebAssembly werden wahrscheinlich bei serverlosen und Edge-Computing-Workloads die Oberhand gewinnen. Die Beobachtbarkeit auf Kernel-Ebene von eBPF verändert schon jetzt, wie wir containerisierte Anwendungen überwachen und sichern. Diese Technologien werden die herkömmlichen Container nicht komplett ersetzen, aber sie werden neue Kategorien von Workloads schaffen, bei denen die aktuellen Einschränkungen von Containern nicht mehr gelten.
Der Schlüssel liegt darin, flexibel zu bleiben, während diese Technologien ausgereift werden, und zu verstehen, dass die beste Containerisierungsstrategie mehrere Tools kombiniert, anstatt sich auf eine einzige Lösung zu verlassen.
Wenn du mehr über Docker, Containerisierung, Virtualisierung und Kubernetes erfahren möchtest, sind diese Kurse der perfekte nächste Schritt:
Lerne mit diesen Kursen mehr über Docker!
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree