Kurs
Python für Fortgeschrittene
4 Std.
1.4M
Die Sentiment-Analyse ist eine Technik, mit der man den emotionalen Ton oder die Stimmung in einem Text bestimmen kann. Dabei werden die im Text verwendeten Wörter und Sätze analysiert, um die zugrundeliegende Stimmung zu ermitteln, egal ob sie positiv, negativ oder neutral ist.
Die Sentiment-Analyse hat eine Vielzahl von Anwendungsmöglichkeiten, wie z.B. Social Media Monitoring, Kundenfeedback-Analyse und Marktforschung.
Eine der größten Herausforderungen bei der Stimmungsanalyse ist die der menschlichen Sprache innewohnende Komplexität. Textdaten enthalten oft Sarkasmus, Ironie und andere Formen der bildlichen Sprache, die mit herkömmlichen Methoden schwer zu interpretieren sind.
Die jüngsten Fortschritte in der Verarbeitung natürlicher Sprache (NLP) und im maschinellen Lernen haben es jedoch möglich gemacht, große Mengen an Textdaten mit einem hohen Maß an Genauigkeit einer Stimmungsanalyse zu unterziehen.
Es gibt verschiedene Möglichkeiten, Textdaten einer Stimmungsanalyse zu unterziehen, mit unterschiedlichem Grad an Komplexität und Genauigkeit. Zu den gebräuchlichsten Methoden gehören ein lexikonbasierter Ansatz, ein auf maschinellem Lernen (ML) basierender Ansatz und ein auf vortrainierten Transformern basierender Deep-Learning-Ansatz. Schauen wir uns die einzelnen Punkte genauer an:
Bei dieser Art der Analyse, wie z.B. dem NLTK Vader Sentiment Analyzer, werden eine Reihe von vordefinierten Regeln und Heuristiken verwendet, um das Sentiment eines Textes zu bestimmen. Diese Regeln basieren in der Regel auf lexikalischen und syntaktischen Merkmalen des Textes, wie z. B. dem Vorhandensein positiver oder negativer Wörter und Phrasen.
Die lexikonbasierte Analyse ist zwar relativ einfach zu implementieren und zu interpretieren, aber sie ist möglicherweise nicht so genau wie ML-basierte oder transformierte Ansätze, vor allem wenn es um komplexe oder mehrdeutige Textdaten geht.
Bei diesem Ansatz wird ein Modell trainiert, um die Stimmung eines Textes auf der Grundlage einer Reihe von gelabelten Trainingsdaten zu erkennen. Diese Modelle können mit einer Vielzahl von ML-Algorithmen trainiert werden, darunter Entscheidungsbäume, Support Vector Machines (SVMs) und neuronale Netze.
ML-basierte Ansätze können genauer sein als regelbasierte Analysen, vor allem wenn es um komplexe Textdaten geht, aber sie erfordern eine größere Menge an gelabelten Trainingsdaten und können rechenintensiver sein.
Bei einem auf Deep Learning basierenden Ansatz, wie er bei BERT und GPT-4 zum Einsatz kommt, werden vortrainierte Modelle verwendet, die auf großen Mengen von Textdaten trainiert wurden. Diese Modelle verwenden komplexe neuronale Netze, um den Kontext und die Bedeutung des Textes zu kodieren. Dadurch erreichen sie bei einer Vielzahl von NLP-Aufgaben, einschließlich der Stimmungsanalyse, die höchste Genauigkeit. Diese Modelle erfordern jedoch erhebliche Rechenressourcen und sind möglicherweise nicht für alle Anwendungsfälle geeignet.
Die Wahl des Ansatzes hängt von den spezifischen Bedürfnissen und Beschränkungen des jeweiligen Projekts ab.
Um die NLTK-Bibliothek zu verwenden, musst du eine Python-Umgebung auf deinem Computer haben. Der einfachste Weg, Python zu installieren, ist, die Anaconda Distribution herunterzuladen und zu installieren. Diese Distribution kommt mit der Python 3-Basisumgebung und anderen Extras wie Jupyter Notebook. Du musst auch nicht die NLTK-Bibliothek installieren, da sie mit NLTK und vielen anderen nützlichen Bibliotheken vorinstalliert ist.
Wenn du Python ohne eine Distribution installieren möchtest, kannst du Python direkt von python.org herunterladen und installieren. In diesem Fall musst du NLTK installieren, sobald deine Python-Umgebung fertig ist.
Um die NLTK-Bibliothek zu installieren, öffne das Kommandoterminal und gib ein:
pip install nltkEs ist erwähnenswert, dass NLTK auch einige zusätzliche Daten benötigt, die heruntergeladen werden müssen, bevor es effektiv genutzt werden kann. Zu diesen Daten gehören vortrainierte Modelle, Korpora und andere Ressourcen, die NLTK für verschiedene NLP-Aufgaben verwendet. Um diese Daten herunterzuladen, führst du den folgenden Befehl im Terminal oder in deinem Python-Skript aus:
import nltk
nltk.download('all')Die Textvorverarbeitung ist ein entscheidender Schritt bei der Durchführung der Sentimentanalyse, denn sie hilft dabei, die Textdaten zu bereinigen und zu normalisieren, damit sie leichter analysiert werden können. Die Vorverarbeitung umfasst eine Reihe von Techniken, die dabei helfen, die rohen Textdaten in eine Form umzuwandeln, die du für die Analyse verwenden kannst. Einige gängige Verfahren zur Textvorverarbeitung sind Tokenisierung, Stoppwortentfernung, Stemming und Lemmatisierung.
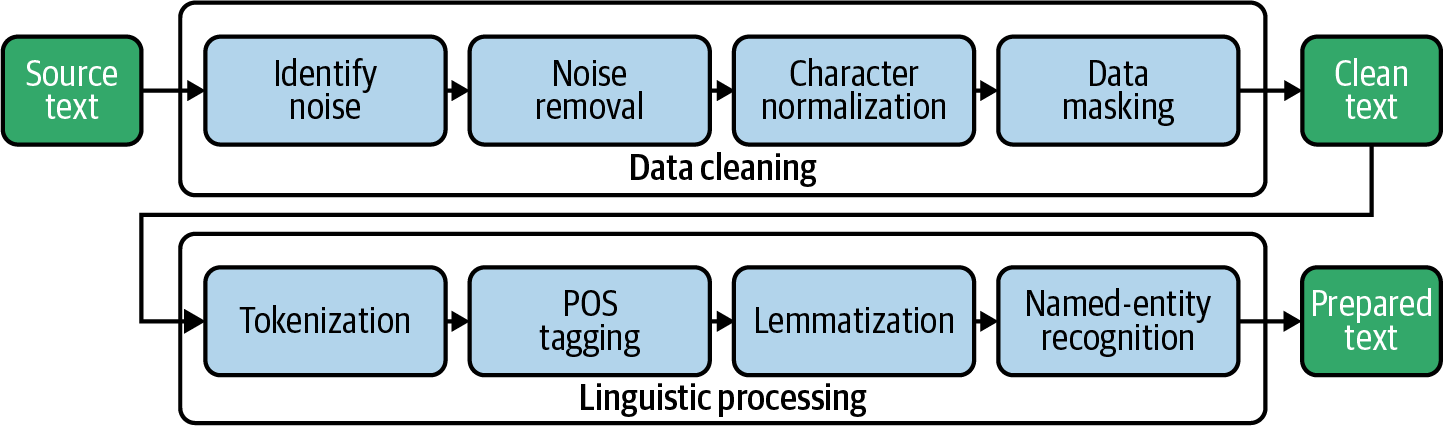
Die Tokenisierung ist ein Schritt der Textvorverarbeitung in der Stimmungsanalyse, bei dem der Text in einzelne Wörter oder Token zerlegt wird. Dies ist ein wichtiger Schritt bei der Analyse von Textdaten, da er dazu beiträgt, einzelne Wörter aus dem Rohtext herauszulösen, damit dieser leichter zu analysieren und zu verstehen ist. Die Tokenisierung wird in der Regel mit der in NLTK eingebauten Funktion word_tokenize durchgeführt, die den Text in einzelne Wörter und Satzzeichen aufteilen kann.
Das Entfernen von Stoppwörtern ist ein wichtiger Schritt bei der Textvorverarbeitung in der Stimmungsanalyse. Dabei werden häufige und irrelevante Wörter entfernt, die wahrscheinlich nicht viel Stimmung vermitteln. Stoppwörter sind Wörter, die in einer Sprache sehr häufig vorkommen und keine große Bedeutung haben, wie z.B. "und", "das", "von" und "es". Diese Wörter können Rauschen verursachen und die Analyse verfälschen, wenn sie nicht entfernt werden.
Durch das Entfernen von Stoppwörtern ist es wahrscheinlicher, dass die verbleibenden Wörter im Text die geäußerte Stimmung wiedergeben. Dies kann dazu beitragen, die Genauigkeit der Stimmungsanalyse zu verbessern. NLTK bietet eine eingebaute Liste von Stoppwörtern für verschiedene Sprachen, mit der du diese Wörter aus den Textdaten herausfiltern kannst.
Stemming und Lemmatisierung sind Techniken, mit denen Wörter auf ihre Stammformen reduziert werden. Beim Stemming werden die Suffixe von Wörtern entfernt, wie z.B. "ing" oder "ed", um sie auf ihre Grundform zu reduzieren. Zum Beispiel würde das Wort "springen" in "springen" umgewandelt werden.
Bei der Lemmatisierung hingegen werden Wörter auf der Grundlage ihrer Wortart auf ihre Grundform reduziert. Zum Beispiel würde das Wort "sprang" zu "springen" lemmatisiert werden, aber das Wort "springen" würde zu "springen" lemmatisiert werden, da es ein Partizip Präsens ist.
Mehr über Stemming und Lemmatisierung erfährst du in unserem Tutorial zu Stemming und Lemmatisierung in Python.
Das Bag-of-Words-Modell ist eine Technik, die in der natürlichen Sprachverarbeitung (NLP) verwendet wird, um Textdaten als eine Reihe von numerischen Merkmalen darzustellen. In diesem Modell wird jedes Dokument oder Textstück als "Tasche" von Wörtern dargestellt, wobei jedes Wort im Text durch ein separates Merkmal oder eine Dimension im resultierenden Vektor repräsentiert wird. Der Wert jedes Merkmals wird dadurch bestimmt, wie oft das entsprechende Wort im Text vorkommt.
Das Bag-of-Words-Modell ist in der NLP nützlich, weil es uns ermöglicht, Textdaten mit Algorithmen des maschinellen Lernens zu analysieren, die normalerweise numerische Eingaben erfordern. Indem wir Textdaten als numerische Merkmale darstellen, können wir maschinelle Lernmodelle trainieren, um Texte zu klassifizieren oder Stimmungen zu analysieren.
Das Beispiel im nächsten Abschnitt verwendet das NLTK Vader-Modell für die Stimmungsanalyse des Amazon-Kundendatensatzes. In diesem Beispiel müssen wir diesen Schritt nicht durchführen, weil die NLTK Vader API Text als Eingabe akzeptiert und keine numerischen Vektoren. Wenn du jedoch ein überwachtes maschinelles Lernmodell zur Vorhersage der Stimmung erstellen würdest (vorausgesetzt, du hast beschriftete Daten), müsstest du den verarbeiteten Text in ein Bag-of-Words-Modell umwandeln, bevor du das maschinelle Lernmodell trainierst.
Um eine Stimmungsanalyse mit NLTK in Python durchzuführen, müssen die Textdaten zunächst mit Techniken wie Tokenisierung, Stoppwortentfernung und Stemming oder Lemmatisierung vorverarbeitet werden. Nachdem der Text vorverarbeitet wurde, übergeben wir ihn an den Vader Sentiment Analyzer, um die Stimmung des Textes zu analysieren (positiv oder negativ).
Zuerst importieren wir die notwendigen Bibliotheken für die Text- und Stimmungsanalyse, wie pandas für die Datenverarbeitung, nltk für die natürliche Sprachverarbeitung und SentimentIntensityAnalyzer für die Stimmungsanalyse.
Anschließend laden wir den gesamten NLTK-Korpus (eine Sammlung von Sprachdaten) mit nltk.download() herunter.
Sobald die Umgebung eingerichtet ist, laden wir mit pd.read_csv() einen Datensatz mit Amazon-Rezensionen. Dadurch wird ein DataFrame-Objekt in Python erstellt, das wir zur Analyse der Daten verwenden können. Wir werden den Inhalt des DataFrames mit df anzeigen.
# import libraries
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# download nltk corpus (first time only)
import nltk
nltk.download('all')
# Load the amazon review dataset
df = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/amazon.csv')
df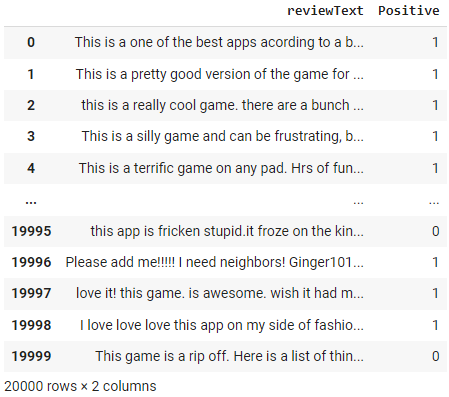
Erstellen wir eine Funktion preprocess_text, in der wir zuerst die Dokumente mit der Funktion word_tokenize aus NLTK tokenisieren, dann entfernen wir Stufenwörter mit dem Modul stepwords aus NLTK und schließlich lemmatisieren wir die filtered_tokens mit WordNetLemmatizer aus NLTK.
# create preprocess_text function
def preprocess_text(text):
# Tokenize the text
tokens = word_tokenize(text.lower())
# Remove stop words
filtered_tokens = [token for token in tokens if token not in stopwords.words('english')]
# Lemmatize the tokens
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
# Join the tokens back into a string
processed_text = ' '.join(lemmatized_tokens)
return processed_text
# apply the function df
df['reviewText'] = df['reviewText'].apply(preprocess_text)
df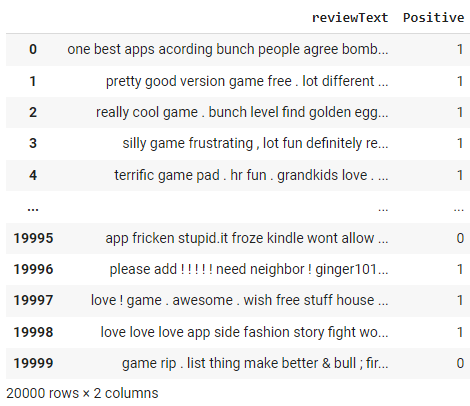
Beachte die Änderungen in der Spalte "Überprüfungstext" als Ergebnis der Funktion preprocess_text, die wir im obigen Schritt angewendet haben.
Zuerst initialisieren wir ein Sentiment Intensity Analyzer Objekt aus der nltk.sentiment.vader Bibliothek.
Als Nächstes definieren wir eine Funktion namens get_sentiment, die einen Textstring als Eingabe benötigt. Die Funktion ruft die Methode polarity_scores des Analyzer-Objekts auf, um ein Wörterbuch mit Stimmungsbewertungen für den Text zu erhalten, das eine Bewertung für positive, negative und neutrale Stimmungen enthält.
Die Funktion prüft dann, ob der positive Wert größer als 0 ist und gibt in diesem Fall einen Sentiment-Wert von 1 zurück, andernfalls eine 0. Das bedeutet, dass jeder Text mit einer positiven Punktzahl als positiv eingestuft wird und jeder Text mit einer nicht-positiven Punktzahl als negativ eingestuft wird.
Schließlich wenden wir die Funktion get_sentiment mit der Methode apply auf die Spalte reviewText des DataFrame df an. Dadurch wird eine neue Spalte mit dem Namen sentiment im DataFrame erstellt, in der die Stimmungsbewertung für jede Rezension gespeichert wird. Anschließend zeigen wir den aktualisierten DataFrame mit df an.
# initialize NLTK sentiment analyzer
analyzer = SentimentIntensityAnalyzer()
# create get_sentiment function
def get_sentiment(text):
scores = analyzer.polarity_scores(text)
sentiment = 1 if scores['pos'] > 0 else 0
return sentiment
# apply get_sentiment function
df['sentiment'] = df['reviewText'].apply(get_sentiment)
df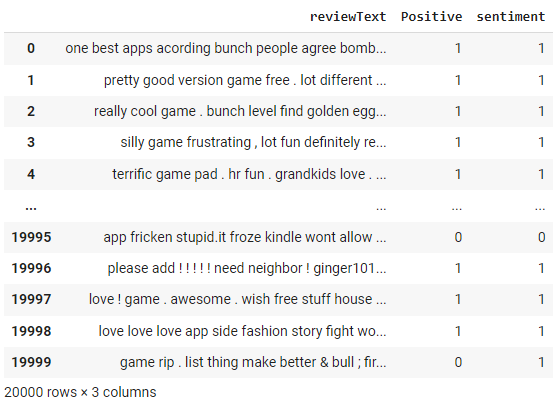
Der NLTK Sentiment Analyzer liefert einen Wert zwischen -1 und +1. In der obigen Funktion get_sentiment haben wir einen Schwellenwert von 0 verwendet. Alles, was über 0 liegt, wird als 1 (also positiv) eingestuft. Da wir die tatsächlichen Kennzeichnungen haben, können wir die Leistung dieser Methode bewerten, indem wir eine Konfusionsmatrix erstellen.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(df['Positive'], df['sentiment']))Ausgabe:
[[ 1131 3636]
[ 576 14657]]Wir können auch den Einstufungsbericht überprüfen:
from sklearn.metrics import classification_report
print(classification_report(df['Positive'], df['sentiment']))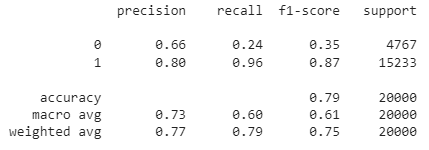
Wie du siehst, liegt die Gesamtgenauigkeit dieses regelbasierten Stimmungsanalysemodells bei 79 %. Da es sich um gelabelte Daten handelt, kannst du auch versuchen, ein ML-Modell zu erstellen, um herauszufinden, ob ein ML-basierter Ansatz zu einer besseren Genauigkeit führt.
Schau dir das komplette Notizbuch im Datacamp-Arbeitsbereich an.
NLTK ist eine leistungsstarke und flexible Bibliothek zur Durchführung von Sentiment-Analysen und anderen Aufgaben der natürlichen Sprachverarbeitung in Python. Mit NLTK können wir Textdaten vorverarbeiten, sie in ein Bag-of-Words-Modell umwandeln und mit dem Sentiment-Analyzer von Vader eine Stimmungsanalyse durchführen.
In diesem Tutorial haben wir die Grundlagen der NLTK-Sentimentanalyse kennengelernt, einschließlich der Vorverarbeitung von Textdaten, der Erstellung eines Bag-of-Words-Modells und der Durchführung der Sentimentanalyse mit NLTK Vader. Wir haben auch die Vorteile und Grenzen der NLTK-Sentiment-Analyse diskutiert und Vorschläge für weitere Lektüre und Erkundungen gegeben.
Insgesamt ist NLTK ein leistungsfähiges und weit verbreitetes Werkzeug für die Durchführung von Sentiment-Analysen und anderen Aufgaben der natürlichen Sprachverarbeitung in Python. Wenn du die in diesem Lernprogramm vorgestellten Techniken und Werkzeuge beherrschst, kannst du wertvolle Einblicke in die Stimmung von Textdaten gewinnen und diese Erkenntnisse nutzen, um datengestützte Entscheidungen in einer Vielzahl von Anwendungen zu treffen.
Wenn du lernen willst, wie du NLP auf reale Daten wie TED-Talks, Artikel und Filmkritiken anwenden kannst, indem du Python-Bibliotheken und -Frameworks wie NLTK, scikit-learn, spaCy und SpeechRecognition verwendest, schau dir die folgenden Ressourcen an:
Es bietet eine solide Grundlage für die Verarbeitung und Analyse von Textdaten mit Python. Egal, ob du neu im NLP bist oder deine Kenntnisse erweitern möchtest, dieser Kurs wird dich mit den Werkzeugen und dem Wissen ausstatten, um unstrukturierte Daten in wertvolle Erkenntnisse zu verwandeln.
Python-Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.