Kurs
Einführung in Natural Language Processing mit Python
4 Std.
141K
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) verbessert die Art und Weise, wie Menschen und Computer miteinander kommunizieren, indem sie maschinelles Lernen einsetzt, um die Struktur und Bedeutung des Textes zu erkennen. Mit Anwendungen zur Verarbeitung natürlicher Sprache können Unternehmen ihre Produktivität steigern und Kosten senken, indem sie Texte analysieren und aussagekräftigere Informationen extrahieren, um das Kundenerlebnis zu verbessern.
Wir können nicht behaupten, dass wir oft über die Feinheiten unserer Sprache nachdenken. Es ist ein intuitives Verhalten, das sich auf semantische Hinweise wie Wörter, Zeichen oder Bilder stützt, um Informationen und Bedeutung zu vermitteln. Manchmal heißt es, dass das Erlernen einer Sprache im Jugendalter einfacher ist, weil es ein wiederholbares Verhalten ist, das man sich antrainieren kann, ähnlich wie das Laufen. Außerdem folgen Sprachen keinen strengen Regeln und haben viele Ausnahmen.
Der Spracherwerb, der für Menschen ganz natürlich ist, ist für Computer extrem komplex, weil es viele unstrukturierte Daten, keine strengen Regeln und keine konkrete Perspektive oder einen Kontext gibt. Dennoch verlassen sich die Menschen zunehmend auf Computersysteme, um zu kommunizieren und Aufgaben zu erledigen. Aus diesem Grund gewinnen maschinelles Lernen (ML) und künstliche Intelligenz (KI) so viel Aufmerksamkeit und Popularität. Die Verarbeitung natürlicher Sprache folgt der Entwicklung der KI. Obwohl diese beiden Begriffe Bilder von futuristischen Robotern heraufbeschwören mögen, gibt es bereits einfache Anwendungen der natürlichen Sprachverarbeitung im Alltag.
NLP ist eine Komponente der KI, die sich darauf konzentriert, die menschliche Sprache zu verstehen, wie sie geschrieben und/oder gesprochen wird. Dafür werden spezielle Computerprogramme entwickelt. Ein typischer Computer benötigt Anweisungen, die in einer sehr präzisen, abgegrenzten, strukturierten und eindeutigen Programmiersprache übermittelt werden. Leider ist die natürliche menschliche Sprache ungenau, zweideutig und verwirrend. Um ein Programm in die Lage zu versetzen, die Bedeutung von Wörtern zu verstehen, müssen Algorithmen eingesetzt werden, die in der Lage sind, die Bedeutung und Struktur zu analysieren, um die Wörter verständlich zu machen, bestimmte Bezüge zu erkennen und dann die Sprache zu erzeugen.
NLP-Algorithmen führen verschiedene syntaktische und semantische Analysen durch, um die Bedeutung von Sätzen auf der Grundlage von grammatikalischen Regeln zu bewerten. Sie tun dies, indem sie:
Zu den gängigen NLP-Techniken gehören:
NLP wird in einer Vielzahl von Anwendungen eingesetzt. Hier sind einige der am häufigsten vorkommenden Bereiche.
Nachrichtenfilter sind eine der ersten grundlegenden Online-Anwendungen zur Verarbeitung natürlicher Sprache. Die Technik wurde zunächst zur Erstellung von Spam-Filtern verwendet, um unerwünschte Nachrichten anhand bestimmter Wörter oder Phrasen zu identifizieren. Mit der Weiterentwicklung der natürlichen Sprachverarbeitung haben sich auch die Filter weiterentwickelt.
Eine der häufigsten und neuesten Anwendungen dieser Technik ist die Klassifizierung von E-Mails in Gmail. Dieses System kann eine E-Mail anhand ihres Inhalts in drei Kategorien (Haupt-, Soziale Netzwerke oder Werbung) einteilen. So können Gmail-Nutzer/innen ihren Posteingang besser verwalten, um wichtige E-Mails schnell einsehen und beantworten zu können.
Intelligente Assistenten wie Siri (Apple) und Alexa (Amazon) nutzen die Spracherkennung, um Sprachmuster zu erkennen, daraus eine Bedeutung abzuleiten und eine sinnvolle Antwort vorzuschlagen. Heute scheint es normal zu sein, Siri eine Frage zu stellen und zu erwarten, dass sie uns versteht und eine passende Antwort gibt. Genauso gewöhnen wir uns daran, täglich mit Siri oder Alexa über unseren Thermostat, die Beleuchtung, das Auto usw. zu interagieren.
Wir erwarten von Assistenten wie Alexa und Siri, dass sie kontextbezogene Hinweise aufgreifen, um uns im Alltag zu helfen und bestimmte Aufgaben zu erfüllen (z. B. das Bestellen von Waren). Wir freuen uns sogar über ihre lustigen Antworten oder wenn sie uns von sich selbst erzählen. Unsere Interaktionen werden persönlicher, je besser sie uns kennenlernen. Im Artikel der New York Times heißt es: "Warum wir bald in der Welt von Alexa leben werden": "Eine große Veränderung steht bevor. Alexa wird höchstwahrscheinlich die dritte große Verbraucherplattform in diesem Jahrzehnt werden."
Suchmaschinen nutzen die Verarbeitung natürlicher Sprache, um relevante Ergebnisse anzuzeigen, die auf ähnlichem Suchverhalten oder der Absicht der Nutzer/innen basieren. So kann jeder finden, was er braucht, ohne besondere Fähigkeiten zu haben.
Wenn du zum Beispiel eine Suchanfrage eingibst, zeigt dir Google beliebte verwandte Suchanfragen an, aber es kann auch die allgemeine Bedeutung deiner Anfrage über den genauen Wortlaut hinaus erkennen. Wenn du eine Flugnummer in Google eingibst, erfährst du ihren Status. Du bekommst einen Aktienbericht, wenn du ein Aktiensymbol eingibst. Wenn du eine mathematische Gleichung eingibst, bekommst du einen Taschenrechner. Deine Suche kann eine Vielzahl von Ergebnissen liefern, weil die verwendete Technik zur Verarbeitung natürlicher Sprache eine mehrdeutige Anfrage mit einer bestimmten Entität verknüpft, um nützliche Ergebnisse zu liefern.
Funktionen wie Autokorrektur, Autovervollständigung und intuitive Eingaben sind auf unseren Smartphones heute so selbstverständlich, dass wir sie für selbstverständlich halten. Die automatische Eingabe und die intuitive Eingabe sind mit Suchmaschinen vergleichbar, da sie sich auf das Getippte verlassen, um das Ende eines Wortes oder Satzes vorzuschlagen. Die Autokorrektur ändert manchmal sogar einige Wörter, um die Gesamtbedeutung deiner Nachricht zu verbessern.
Außerdem entwickeln sich diese Funktionen mit dir weiter. Zum Beispiel passt sich das intuitive Tippen mit der Zeit an deine spezifischen Wendungen an. Das führt manchmal zu einem lustigen Nachrichtenaustausch, bei dem die Sätze komplett auf intuitiven Eingaben basieren. Das Ergebnis kann überraschend persönlich und informativ sein und hat manchmal sogar die Aufmerksamkeit der Medien auf sich gezogen.
Wenn deine Fremdsprachenübung voller grammatikalischer Fehler ist, wird deine Lehrerin oder dein Lehrer wahrscheinlich wissen, dass du mit Hilfe der Technologie zur Verarbeitung natürlicher Sprache geschummelt hast. Leider eignen sich viele Sprachen nicht für eine direkte Übersetzung, weil sie unterschiedliche Satzkonstruktionen haben, die manchmal von Übersetzungsdiensten übersehen werden. Aber diese Systeme haben einen langen Weg hinter sich.
Dank der natürlichen Sprachverarbeitung bieten Online-Übersetzungstools genauere und grammatikalisch korrekte Übersetzungen. Daher sind sie äußerst nützlich, wenn du mit jemandem kommunizieren musst, der deine Sprache nicht spricht. Wenn du einen fremden Text übersetzen musst, können diese Tools sogar die Sprache des Textes erkennen, der zur Übersetzung eingegeben wird.
Wenn du bei einigen Unternehmen anrufst, haben die meisten von uns wahrscheinlich schon einmal die Ansage gehört: "Dieses Gespräch kann zu Schulungszwecken aufgezeichnet werden". Diese Aufzeichnungen können zwar zu Trainingszwecken verwendet werden (z. B. um einen Austausch mit einem verärgerten Kunden zu analysieren), werden aber normalerweise in einer Datenbank gespeichert, damit ein System zur Verarbeitung natürlicher Sprache lernen und wachsen kann. Automatisierte Systeme leiten Kundenanrufe an einen Agenten oder Online-Chatbot weiter, der relevante Informationen zur Beantwortung ihrer Anfragen liefert. Diese Technik zur Verarbeitung natürlicher Sprache wird bereits von vielen Unternehmen eingesetzt, darunter auch von großen Telefongesellschaften.
Die digitale Telefonanruftechnologie ermöglicht es einem Computer auch, die menschliche Stimme zu imitieren. So ist es möglich, automatisierte Anrufe zu planen, um einen Termin in der Werkstatt oder beim Friseur zu vereinbaren.
Funktionen für natürliche Sprache sind jetzt in analytische Arbeitsabläufe integriert. In der Tat bieten immer mehr BI-Anbieter eine natürlichsprachliche Schnittstelle für ihre Datenvisualisierungen an. Eine intelligentere visuelle Kodierung ermöglicht es zum Beispiel, die bestmögliche Visualisierung für eine bestimmte Aufgabe vorzuschlagen, je nach Semantik der Daten. Jeder kann die Daten mit natürlichsprachlichen Aussagen oder Fragmenten von Fragen erkunden, deren Schlüsselwörter interpretiert und verstanden werden.
Das Erforschen von Daten mit Hilfe von Sprache macht die Daten zugänglicher und öffnet die Analytik für das gesamte Unternehmen über den üblichen Kreis von IT-Analysten und Entwicklern hinaus.
Bei der Textanalyse werden unstrukturierte Textdaten mithilfe verschiedener linguistischer, statistischer und maschineller Lernverfahren in analysierbare Daten umgewandelt.
Die Stimmungsanalyse kann für Marken eine gewaltige Herausforderung sein (vor allem bei einem großen Kundenstamm). Ein auf natürlicher Sprachverarbeitung basierendes Tool kann jedoch typischerweise Kundeninteraktionen (wie z. B. Kommentare oder Bewertungen in sozialen Medien oder sogar Erwähnungen von Markennamen) untersuchen, um herauszufinden, was sie sind. Anschließend können Marken diese Interaktionen analysieren, um die Wirksamkeit ihrer Marketingkampagnen zu bewerten oder die Entwicklung von Kundenproblemen zu verfolgen. Sie können dann entscheiden, wie sie reagieren oder ihren Service verbessern, um ein besseres Erlebnis zu bieten.
Die Verarbeitung natürlicher Sprache trägt ebenfalls zur Textanalyse bei, indem sie Schlüsselwörter extrahiert und Muster oder Trends in unstrukturierten Textdaten identifiziert. Was sind die wichtigsten NLP-Modelle?
NLP gibt es zwar schon seit einiger Zeit, aber die jüngsten Fortschritte sind bemerkenswert, vor allem mit dem Aufkommen von Transformator-basierten Modellen und groß angelegten Sprachmodellen, die von führenden Technologieunternehmen entwickelt wurden. Einige der fortschrittlichsten Modelle sind:
Transformatorbasierte Modelle:
Große Sprachmodelle (LLMs):
In diesem Lernprogramm schauen wir uns genauer an, wie BERT für NLP eingesetzt wird.
BERT, das Akronym steht für "Bidirectional Encoder Representations from Transformers" und ist ein Modell, das von Google AI veröffentlicht wurde. Diese innovative Technik basiert auf der Verarbeitung natürlicher Sprache (NLP).
Der Algorithmus nutzt im Wesentlichen maschinelles Lernen und künstliche Intelligenz, um die Anfragen von Internetnutzern zu verstehen. So versucht es, ihre Suchabsichten zu interpretieren, d.h. die natürliche Sprache, die sie verwenden.
In diesem Sinne wird das BERT mit persönlichen Sprachassistenten wie Google Home in Verbindung gebracht. Das Tool basiert nicht mehr auf jedem vom Nutzer eingegebenen Wort, sondern berücksichtigt den gesamten Ausdruck und den Kontext, in dem er steht. Dies geschieht, um die Ergebnisse zu verfeinern. Sie ist effizienter bei der Bearbeitung komplexer Suchen, unabhängig vom verwendeten Medium.
Konkret ermöglicht BERT der Suchmaschine, :
Für andere Anwendungen wird der BERT in :
Der Einfluss von Google BERT auf die längsten Suchanfragen, die auf natürliche Weise eingegeben werden, würde also etwa 10% betragen.
Die Verarbeitung natürlicher Sprache konzentriert sich auf die Analyse der vom Benutzer eingegebenen Wörter. Das Schlüsselwort, seine Vorgänger und seine Nachfolger werden untersucht, um die Anfrage besser zu verstehen. Das ist das Prinzip der Analyse, das die "Transformatoren" anwenden.
Der Algorithmus ist besonders effektiv bei Longtail-Suchen, bei denen Präpositionen die Bedeutung beeinflussen. Auf der anderen Seite sind die Auswirkungen auf generische Suchanfragen weniger wichtig, da diese von Google bereits gut verstanden werden. Die anderen Verstehenswerkzeuge bleiben also funktionsfähig.
Egal, ob die Anfrage ungeordnet oder präzise formuliert ist, die Suchmaschine kann sie trotzdem verarbeiten. Aber für mehr Effizienz ist es besser, angemessenere Begriffe zu verwenden.
Der Kontext spielt eine wichtige Rolle bei der Analyse des BERT. Maschinelle Übersetzung und sprachliche Modellierung werden optimiert. Auch bei der Erstellung von Qualitätstexten sind deutliche Verbesserungen zu verzeichnen.
Um dieses Modell zu verwenden, importieren wir zunächst die notwendigen Bibliotheken und Pakete, wie hier gezeigt:
Als Nächstes laden wir den Large Movie Review Dataset herunter, entpacken ihn und erkunden die Struktur des Verzeichnisses.
Um ein beschriftetes tf.data.Dataset zu erstellen, verwenden wir die Funktion text_dataset_from_directory wie unten gezeigt. Als Nächstes erstellen wir ein Validierungsset, indem wir die Trainingsdaten im Verhältnis 80:20 aufteilen, indem wir das Argument validation_split verwenden.
Es ist wichtig, dass du bei der Verwendung von validation_split einen Zufallswert angibst, damit sich die Validierungs- und Trainingssplits nicht überschneiden.
Im nächsten Schritt wählst du aus, welches BERT-Modell du aus dem Tensorflow Hub laden und feinabstimmen möchtest. Du kannst den hub.KerasLayer verwenden, um dein feinabgestimmtes Modell zusammenzustellen. Dann probieren wir das Preprocessing-Modell an einem Text aus und sehen uns die Ausgabe an.
Als Nächstes erstellst du ein einfaches Modell, das aus dem Vorverarbeitungsmodell, dem BERT-Modell, das du in den vorherigen Schritten ausgewählt hast, einer dichten Schicht und einer Dropout-Schicht besteht.
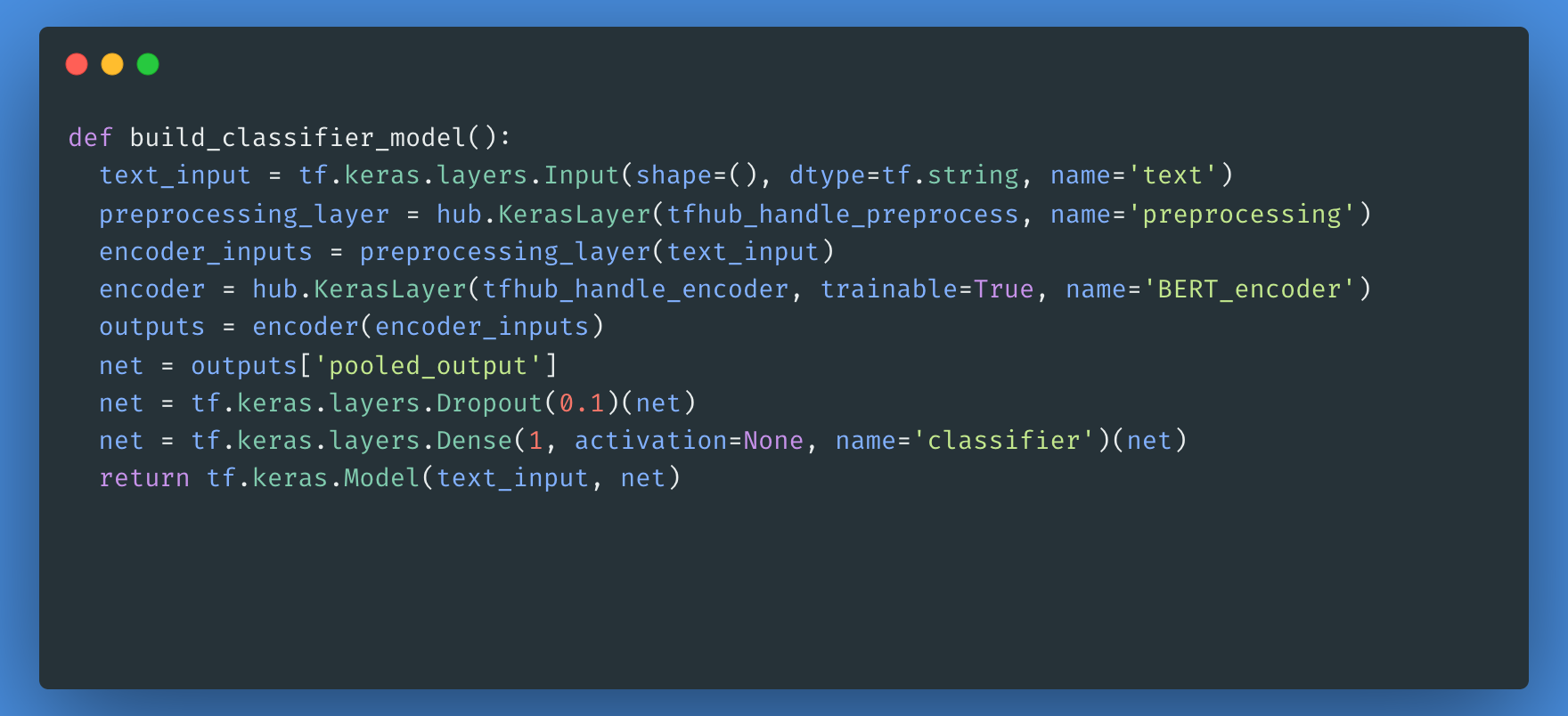
Jetzt kannst du überprüfen, ob dein Modell mit der Ausgabe des Preprocessing-Modells läuft.

Die Verlustfunktion ist hier ein notwendiger Schritt. Wir entscheiden uns für die Verlustfunktion losses.BinaryCrossentropy, da wir es mit einem binären Klassifikationsproblem zu tun haben.

Für die Feinabstimmung verwenden wir denselben Optimierer, mit dem BERT ursprünglich trainiert wurde: den "Adaptive Moments" (Adam). Dieser Optimierer minimiert den Vorhersageverlust und führt eine Regularisierung durch Gewichtsabnahme durch, die auch als AdamW bekannt ist.

Mit dem classifier_model, das du zuvor erstellt hast, kannst du das Modell mit dem Verlust, der Metrik und dem Optimierer kompilieren.

Beachte, dass dein Modell je nach Komplexität des von dir gewählten BERT-Modells mehr oder weniger Zeit zum Trainieren benötigt.

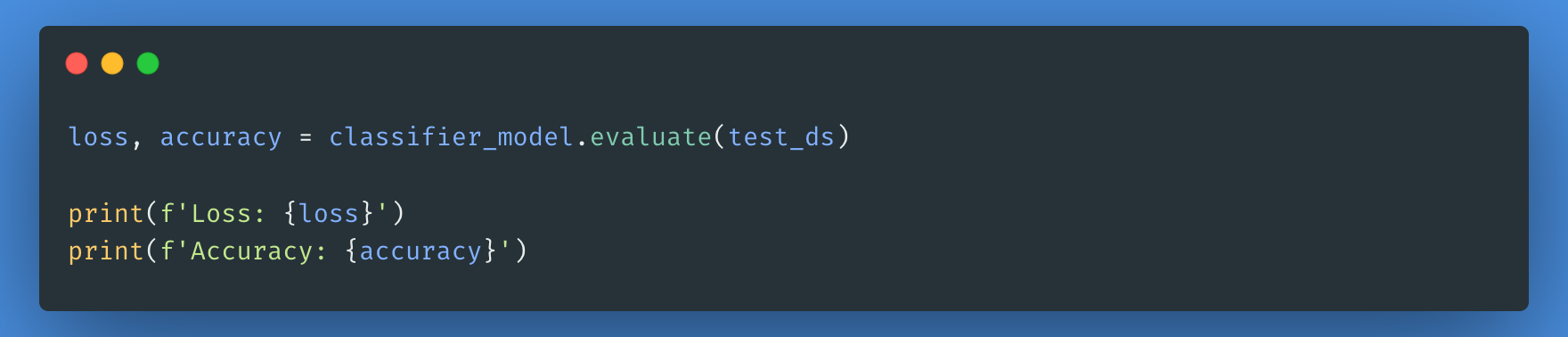
Jetzt bewerten wir, wie unser Modell abgeschnitten hat, indem wir den Verlust und die Genauigkeit des Modells überprüfen.
Du kannst das History-Objekt verwenden, wenn du den Verlust und die Genauigkeit für Trainings- und Validierungssets aufzeichnen möchtest:
Alle oben genannten Schritte werden in diesem Notizbuch beschrieben. Du kannst die obigen Schritte üben und den Code ausführen, um die Ergebnisse für jedes BERT-Modell in der Liste zu sehen.
Die Verarbeitung natürlicher Sprache ist in der digitalen Welt bereits gut etabliert. Seine Anwendungen werden sich vervielfachen, wenn Unternehmen und Branchen seine Vorteile entdecken und es übernehmen. Während der Mensch bei komplexeren Kommunikationsproblemen weiterhin unverzichtbar sein wird, wird die natürliche Sprachverarbeitung unser alltäglicher Verbündeter sein, der zunächst kleinere Aufgaben bewältigt und automatisiert und dann mit fortschreitender Technologie immer komplexere Aufgaben übernimmt.
Wenn du mehr darüber erfahren möchtest, wie NLP funktioniert und wie du es nutzen kannst, schau dir unseren Kurs Deep Learning für NLP in Python an.
Lerne mehr über NLP mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
