Curso
Python intermediário
4 h
1.4M
A análise de sentimentos é uma técnica usada para identificar o tom emocional ou sentimento expresso em um texto. Envolve a análise das palavras e frases usadas no texto para identificar o sentimento subjacente, seja ele positivo, negativo ou neutro.
A análise de sentimentos tem uma ampla gama de aplicações, como monitoramento de redes sociais, análise de comentários de clientes e pesquisa de mercado.
Um dos principais desafios da análise de sentimentos é a complexidade inerente da linguagem humana. Os dados de textos geralmente contêm sarcasmo, ironia e outras formas de linguagem figurativa que podem ser difíceis de interpretar usando métodos tradicionais.
No entanto, os recentes avanços no processamento de linguagem natural (PLN) e no machine learning tornaram possível realizar a análise de sentimentos em grandes volumes de dados de texto com um alto grau de precisão.
Há várias maneiras de realizar a análise de sentimentos em dados de textos, com diferentes graus de complexidade e precisão. Os métodos mais comuns incluem uma abordagem baseada no léxico, uma abordagem baseada em machine learning (ML) e uma abordagem de aprendizado profundo baseada em um transformador pré-treinado. Vamos examinar cada um deles em mais detalhes.
Esse tipo de análise, como o analisador de sentimentos NLTK Vader, envolve o uso de um conjunto de heurísticas e regras predefinidas para determinar o sentimento de um texto. Essas regras geralmente se baseiam em características léxicas e sintáticas do texto, como a presença de palavras e frases positivas ou negativas.
Embora a análise baseada no léxico possa ser relativamente simples de implementar e interpretar, pode não ser tão precisa quanto as abordagens baseadas em ML ou transformadores, especialmente ao lidar com dados de textos complexos ou ambíguos.
Essa abordagem envolve o treinamento de um modelo para identificar o sentimento de um texto com base em um conjunto de dados de treinamento rotulados. Esses modelos podem ser treinados usando uma ampla gama de algoritmos de ML (Machine Learning, aprendizado de máquina), como árvores de decisão, máquinas de vetores de suporte (SVMs) e redes neurais.
As abordagens baseadas em ML podem ser mais precisas do que a análise baseada em regras, especialmente ao lidar com dados de textos complexos, mas exigem uma quantidade maior de dados de treinamento rotulados e podem ser mais caras do ponto de vista computacional.
Uma abordagem baseada em aprendizado profundo, como visto no BERT e no GPT-4, envolve o uso de modelos pré-treinados com grandes quantidades de dados de textos. Esses modelos usam redes neurais complexas para codificar o contexto e o significado do texto, permitindo que atinjam a precisão mais avançada em uma ampla gama de tarefas de PLN, incluindo a análise de sentimentos. No entanto, esses modelos exigem recursos computacionais expressivos e podem não ser práticos para todos os casos de uso.
A escolha da abordagem depende das necessidades e restrições específicas do projeto em questão.
Para usar a biblioteca NLTK, você precisa ter um ambiente Python no computador. A maneira mais fácil de instalar o Python é fazer o download e instalar a distribuição Anaconda. Essa distribuição vem com o ambiente básico do Python 3 e outros recursos, incluindo o Jupyter Notebook. Você também não precisa instalar a biblioteca NLTK, pois ela vem pré-instalada com o NLTK e muitas outras bibliotecas úteis.
Caso opte por instalar o Python sem nenhuma distribuição, pode fazer o download e instalar o Python diretamente no site python.org. Nesse caso, você terá de instalar o NLTK quando o ambiente Python estiver pronto.
Para instalar a biblioteca NLTK, abra o terminal de comando e digite:
pip install nltkVale a pena observar que o NLTK também exige o download de alguns dados complementares para que você possa usá-lo com eficiência. Esses dados incluem modelos pré-treinados, corpora e outros recursos que o NLTK usa para executar várias tarefas de PLN. Para baixar esses dados, execute o seguinte comando no terminal ou em seu script Python:
import nltk
nltk.download('all')O pré-processamento de textos é uma etapa crucial na execução da análise de sentimentos, pois ajuda a limpar e normalizar os dados de textos, facilitando a análise. A etapa de pré-processamento envolve uma série de técnicas que ajudam a transformar dados de textos brutos em um formato que pode ser usado para análise. Algumas técnicas comuns de pré-processamento de textos incluem tokenização, remoção de palavras irrelevantes (stop words), stemming e lematização.
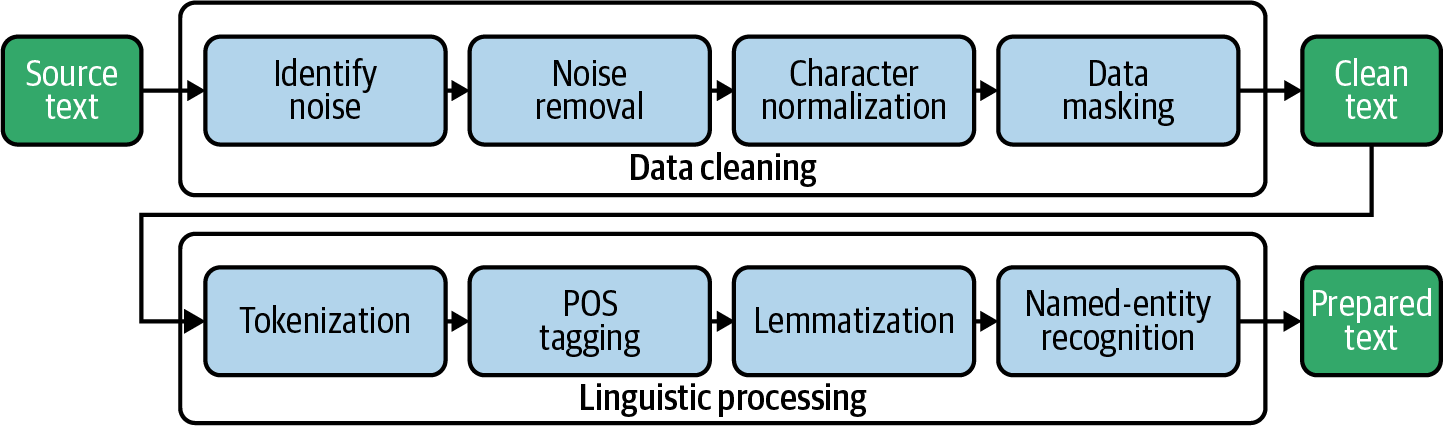
A tokenização é uma etapa de pré-processamento de textos na análise de sentimentos que envolve a divisão do texto em tokens ou palavras individuais. Essa é uma etapa essencial na análise de dados de textos, pois ajuda a separar palavras individuais do texto bruto, facilitando a análise e a compreensão. Normalmente, a tokenização é realizada usando a função integrada do NLTK word_tokenize, capaz de dividir o texto em palavras individuais e sinais de pontuação.
A remoção de palavras irrelevantes (stop words) é uma etapa crucial de pré-processamento de textos na análise de sentimentos que envolve a remoção de palavras comuns e sem importância que provavelmente não transmitem muito sentimento. Palavras irrelevantes são palavras muito comuns em um idioma e que não têm muito significado, como "e", "o" e "de". Essas palavras podem causar ruído e distorcer a análise se não forem removidas.
Ao remover as palavras irrelevantes, as palavras restantes no texto têm maior probabilidade de indicar o sentimento que está sendo expresso. Isso pode ajudar a melhorar a precisão da análise de sentimentos. O NLTK fornece uma lista integrada de palavras irrelevantes para vários idiomas, que pode ser usada para filtrar essas palavras dos dados de textos.
Stemming e lematização são técnicas usadas para reduzir as palavras à sua raiz. O stemming envolve a remoção dos sufixos das palavras, como "ing" ou "ed", para reduzi-las à sua forma básica. Por exemplo: a palavra "jumping" seria derivada de "jump".
A lematização, no entanto, envolve a redução de palavras à sua forma básica segundo sua classe gramatical. Por exemplo: a palavra "jumped" seria lematizada para "jump", mas a palavra "jumping" seria lematizada para "jumping", pois está no gerúndio.
Para saber mais sobre stemming e lematização, confira nosso tutorial Stemming e lematização em Python.
O modelo bag of words (saco de palavras) é uma técnica usada no processamento de linguagem natural (PLN) para representar dados de textos como um conjunto de recursos numéricos. Nesse modelo, cada documento ou texto é representado como um "saco" de palavras, com cada palavra no texto representada por um atributo (feature) ou dimensão separada no vetor resultante. O valor de cada atributo é determinado pelo número de vezes que a palavra correspondente aparece no texto.
O modelo bag of words é útil em PLN porque nos permite analisar dados de textos usando algoritmos de machine learning, que normalmente exigem entrada numérica. Ao representar dados de textos como atributos numéricos, podemos treinar modelos de machine learning para classificar textos ou analisar sentimentos.
O exemplo da próxima seção usa o modelo NLTK Vader para análise de sentimentos no conjunto de dados de clientes da Amazon. Neste exemplo específico, não precisamos executar essa etapa porque a API NLTK Vader aceita textos como entrada em vez de vetores numéricos, mas, se você estivesse criando um modelo de machine learning supervisionado para prever sentimentos (supondo que você tenha dados rotulados), teria que transformar os textos processados em um modelo bag of words antes de treinar o modelo de machine learning.
Para realizar a análise de sentimentos usando o NLTK em Python, primeiro os dados do texto devem ser pré-processados usando técnicas como tokenização, remoção de palavras irrelevantes e stemming ou lematização. Depois que o texto é pré-processado, nós o passamos para o analisador de sentimentos Vader para analisar o sentimento do texto (positivo ou negativo).
Primeiro, importamos as bibliotecas necessárias para análise de textos e análise de sentimentos, como pandas para manipulação de dados, nltk para processamento de linguagem natural e SentimentIntensityAnalyzer para análise de sentimentos.
Em seguida, fazemos o download de todo o corpus (coleção de dados linguísticos) do NLTK usando nltk.download().
Depois que o ambiente está configurado, carregamos um conjunto de dados de avaliações da Amazon usando pd.read_csv(). Isso cria um objeto DataFrame no Python que pode ser usado para analisar os dados. Vamos exibir o conteúdo do DataFrame usando df.
# import libraries
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# download nltk corpus (first time only)
import nltk
nltk.download('all')
# Load the amazon review dataset
df = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/amazon.csv')
df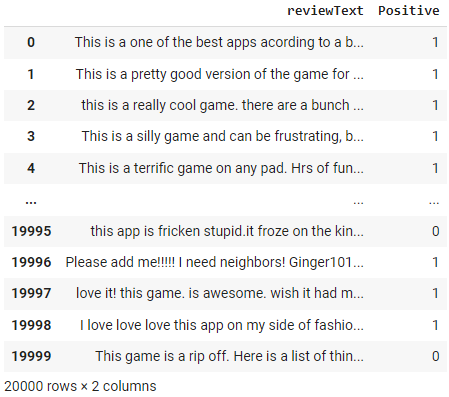
Vamos criar uma função preprocess_text na qual primeiro tokenizamos os documentos usando a função word_tokenize do NLTK, depois removemos as palavras irrelevantes usando o módulo stepwords do NLTK e, por fim, lematizamos filtered_tokens usando o WordNetLemmatizer do NLTK.
# create preprocess_text function
def preprocess_text(text):
# Tokenize the text
tokens = word_tokenize(text.lower())
# Remove stop words
filtered_tokens = [token for token in tokens if token not in stopwords.words('english')]
# Lemmatize the tokens
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
# Join the tokens back into a string
processed_text = ' '.join(lemmatized_tokens)
return processed_text
# apply the function df
df['reviewText'] = df['reviewText'].apply(preprocess_text)
df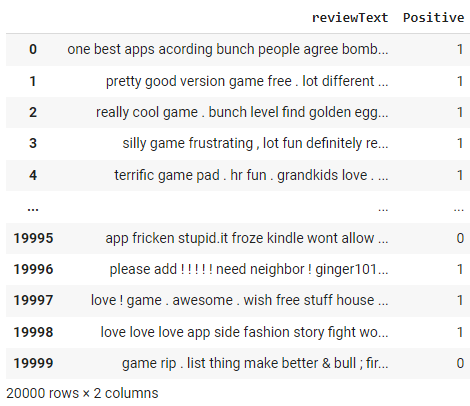
Observe as alterações na coluna "review text" como resultado da função preprocess_text que aplicamos na etapa acima.
Primeiro, inicializamos um objeto Sentiment Intensity Analyzer da biblioteca nltk.sentiment.vader.
Em seguida, definimos uma função chamada get_sentiment que recebe uma string de texto como entrada. A função chama o método polarity_scores do objeto analisador para obter um dicionário de pontuações de sentimento para o texto, que inclui uma pontuação para sentimento positivo, negativo e neutro.
A função verifica se a pontuação positiva é maior que 0 e retorna uma pontuação de sentimento igual a 1 quando é, e igual a 0 caso contrário. Isso significa que qualquer texto com uma pontuação positiva será classificado como tendo um sentimento positivo, e qualquer texto com uma pontuação não positiva será classificado como tendo um sentimento negativo.
Por fim, aplicamos a função get_sentiment à coluna reviewText do DataFrame df usando o método apply. Isso cria uma nova coluna chamada sentiment no DataFrame, que armazena a pontuação de sentimento de cada avaliação. Em seguida, exibimos o DataFrame atualizado usando df.
# initialize NLTK sentiment analyzer
analyzer = SentimentIntensityAnalyzer()
# create get_sentiment function
def get_sentiment(text):
scores = analyzer.polarity_scores(text)
sentiment = 1 if scores['pos'] > 0 else 0
return sentiment
# apply get_sentiment function
df['sentiment'] = df['reviewText'].apply(get_sentiment)
df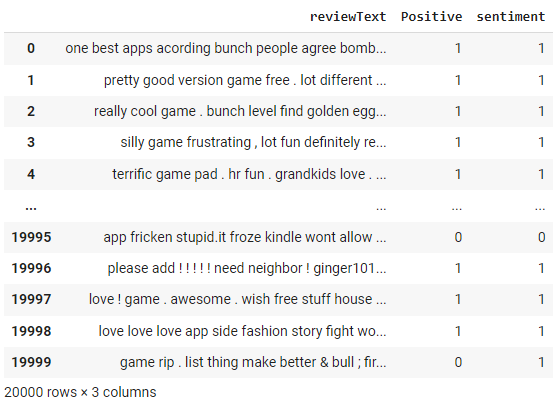
O analisador de sentimentos do NLTK retorna uma pontuação entre -1 e +1. Usamos um limite de corte de 0 na função get_sentiment acima. Qualquer valor acima de 0 é classificado como 1 (ou seja, positivo). Como temos rótulos reais, podemos avaliar o desempenho desse método criando uma matriz de confusão.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(df['Positive'], df['sentiment']))Saída:
[[ 1131 3636]
[ 576 14657]]Você também pode verificar o relatório de classificação:
from sklearn.metrics import classification_report
print(classification_report(df['Positive'], df['sentiment']))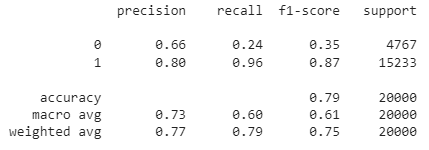
Como você pode ver, a precisão geral desse modelo de análise de sentimentos baseado em regras é de 79%. Como esses dados são rotulados, você também pode tentar criar um modelo de ML para avaliar se uma abordagem baseada em ML resulta em melhor precisão.
Confira o notebook completo no espaço de trabalho do DataCamp.
O NLTK é uma biblioteca avançada e flexível para fazer análises de sentimentos e outras tarefas de processamento de linguagem natural em Python. Usando o NLTK, podemos pré-processar dados de textos, convertê-los em um modelo bag of words e realizar a análise de sentimentos usando o analisador de sentimentos do Vader.
Neste tutorial, analisamos os conceitos básicos da análise de sentimentos do NLTK, incluindo o pré-processamento de dados de textos, a criação de um modelo bag of words e a realização da análise de sentimentos usando o NLTK Vader. Também discutimos as vantagens e limitações da análise de sentimentos do NLTK e apresentamos sugestões para leitura e análise complementares.
Em geral, o NLTK é uma ferramenta eficaz e muito usada para realizar análise de sentimentos e outras tarefas de processamento de linguagem natural em Python. Ao dominar as técnicas e ferramentas apresentadas neste tutorial, você pode extrair informações valiosas sobre o sentimento nos dados de textos e usá-las para tomar decisões orientadas por dados em uma ampla gama de aplicações.
Se quiser aprender a aplicar o PLN a dados reais, incluindo palestras TED, artigos e resenhas de filmes, usando bibliotecas e estruturas Python, como NLTK, scikit-learn, spaCy e SpeechRecognition, confira os recursos abaixo:
Apresenta uma base sólida para processar e analisar dados de textos usando Python. Não importa se você é iniciante em PLN ou se deseja expandir suas habilidades, este curso disponibiliza as ferramentas e conhecimentos para converter dados não estruturados em insights valiosos.
Cursos de Python
Curso
Curso
Curso
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan