Course
Intermediate Python
4 hr
1.4M
Sentiment analysis is a technique used to determine the emotional tone or sentiment expressed in a text. It involves analyzing the words and phrases used in the text to identify the underlying sentiment, whether it is positive, negative, or neutral.
Sentiment analysis has a wide range of applications, including social media monitoring, customer feedback analysis, and market research.
One of the main challenges in sentiment analysis is the inherent complexity of human language. Text data often contains sarcasm, irony, and other forms of figurative language that can be difficult to interpret using traditional methods.
However, recent advances in natural language processing (NLP) and machine learning have made it possible to perform sentiment analysis on large volumes of text data with a high degree of accuracy.
There are several ways to perform sentiment analysis on text data, with varying degrees of complexity and accuracy. The most common methods include a lexicon-based approach, a machine learning (ML) based approach, and a pre-trained transformer-based deep learning approach. Let’s look at each in more detail:
This type of analysis, such as the NLTK Vader sentiment analyzer, involves using a set of predefined rules and heuristics to determine the sentiment of a piece of text. These rules are typically based on lexical and syntactic features of the text, such as the presence of positive or negative words and phrases.
While lexicon-based analysis can be relatively simple to implement and interpret, it may not be as accurate as ML-based or transformed-based approaches, especially when dealing with complex or ambiguous text data.
This approach involves training a model to identify the sentiment of a piece of text based on a set of labeled training data. These models can be trained using a wide range of ML algorithms, including decision trees, support vector machines (SVMs), and neural networks.
ML-based approaches can be more accurate than rule-based analysis, especially when dealing with complex text data, but they require a larger amount of labeled training data and may be more computationally expensive.
A deep learning-based approach, as seen with BERT and GPT-4, involve using pre-trained models trained on massive amounts of text data. These models use complex neural networks to encode the context and meaning of the text, allowing them to achieve state-of-the-art accuracy on a wide range of NLP tasks, including sentiment analysis. However, these models require significant computational resources and may not be practical for all use cases.
The choice of approach will depend on the specific needs and constraints of the project at hand.
To use the NLTK library, you must have a Python environment on your computer. The easiest way to install Python is to download and install the Anaconda Distribution. This distribution comes with the Python 3 base environment and other bells and whistles, including Jupyter Notebook. You also do not need to install the NLTK library, as it comes pre-installed with NLTK and many other useful libraries.
If you choose to install Python without any distribution, you can directly download and install Python from python.org. In this case, you will have to install NLTK once your Python environment is ready.
To install NLTK library, open the command terminal and type:
pip install nltkIt's worth noting that NLTK also requires some additional data to be downloaded before it can be used effectively. This data includes pre-trained models, corpora, and other resources that NLTK uses to perform various NLP tasks. To download this data, run the following command in terminal or your Python script:
import nltk
nltk.download('all')Text preprocessing is a crucial step in performing sentiment analysis, as it helps to clean and normalize the text data, making it easier to analyze. The preprocessing step involves a series of techniques that help transform raw text data into a form you can use for analysis. Some common text preprocessing techniques include tokenization, stop word removal, stemming, and lemmatization.
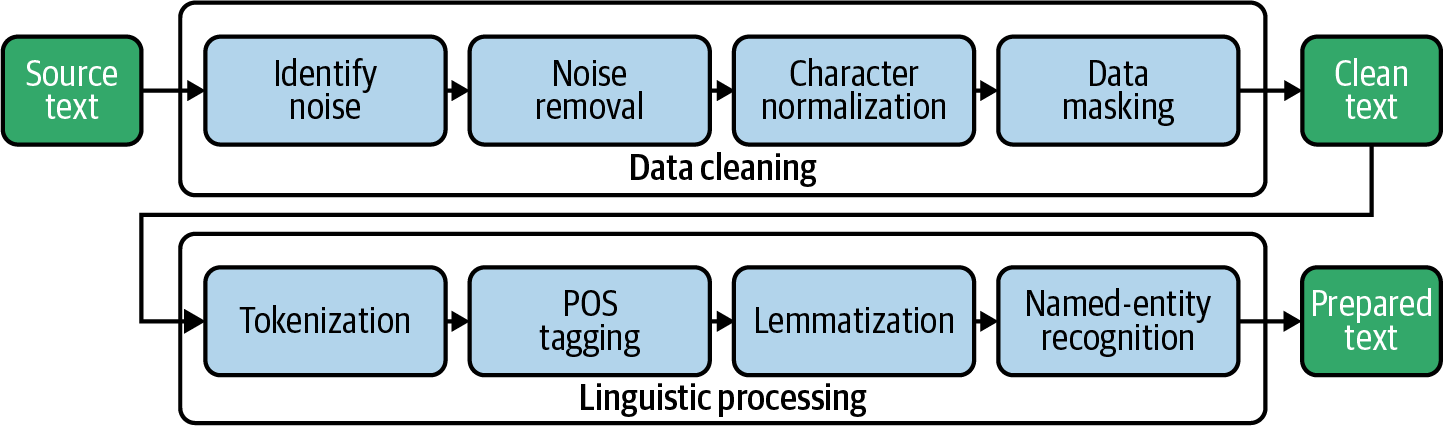
Tokenization is a text preprocessing step in sentiment analysis that involves breaking down the text into individual words or tokens. This is an essential step in analyzing text data as it helps to separate individual words from the raw text, making it easier to analyze and understand. Tokenization is typically performed using NLTK's built-in word_tokenize function, which can split the text into individual words and punctuation marks.
Stop word removal is a crucial text preprocessing step in sentiment analysis that involves removing common and irrelevant words that are unlikely to convey much sentiment. Stop words are words that are very common in a language and do not carry much meaning, such as "and," "the," "of," and "it." These words can cause noise and skew the analysis if they are not removed.
By removing stop words, the remaining words in the text are more likely to indicate the sentiment being expressed. This can help to improve the accuracy of the sentiment analysis. NLTK provides a built-in list of stop words for several languages, which can be used to filter out these words from the text data.
Stemming and lemmatization are techniques used to reduce words to their root forms. Stemming involves removing the suffixes from words, such as "ing" or "ed," to reduce them to their base form. For example, the word "jumping" would be stemmed to "jump."
Lemmatization, however, involves reducing words to their base form based on their part of speech. For example, the word "jumped" would be lemmatized to "jump," but the word "jumping" would be lemmatized to "jumping" since it is a present participle.
To learn more about stemming and lemmatization, check out our Stemming and Lemmatization in Python tutorial.
The bag of words model is a technique used in natural language processing (NLP) to represent text data as a set of numerical features. In this model, each document or piece of text is represented as a "bag" of words, with each word in the text represented by a separate feature or dimension in the resulting vector. The value of each feature is determined by the number of times the corresponding word appears in the text.
The bag of words model is useful in NLP because it allows us to analyze text data using machine learning algorithms, which typically require numerical input. By representing text data as numerical features, we can train machine learning models to classify text or analyze sentiments.
The example in the next section will use the NLTK Vader model for sentiment analysis on the Amazon customer dataset. In this particular example, we do not need to perform this step because the NLTK Vader API accepts text as an input instead of numeric vectors, but if you were building a supervised machine learning model to predict sentiment (assuming you have labeled data), you would have to transform the processed text into a bag of words model before training the machine learning model.
To perform sentiment analysis using NLTK in Python, the text data must first be preprocessed using techniques such as tokenization, stop word removal, and stemming or lemmatization. Once the text has been preprocessed, we will then pass it to the Vader sentiment analyzer for analyzing the sentiment of the text (positive or negative).
First, we’ll import the necessary libraries for text analysis and sentiment analysis, such as pandas for data handling, nltk for natural language processing, and SentimentIntensityAnalyzer for sentiment analysis.
We’ll then download all of the NLTK corpus (a collection of linguistic data) using nltk.download().
Once the environment is set up, we will load a dataset of Amazon reviews using pd.read_csv(). This will create a DataFrame object in Python that we can use to analyze the data. We'll display the contents of the DataFrame using df.
# import libraries
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# download nltk corpus (first time only)
import nltk
nltk.download('all')
# Load the amazon review dataset
df = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/amazon.csv')
df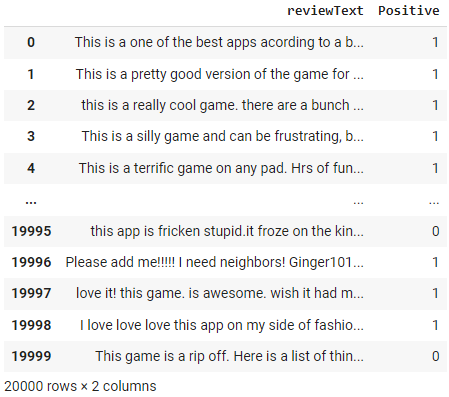
Let’s create a function preprocess_text in which we first tokenize the documents using word_tokenize function from NLTK, then we remove step words using stepwords module from NLTK and finally, we lemmatize the filtered_tokens using WordNetLemmatizer from NLTK.
# create preprocess_text function
def preprocess_text(text):
# Tokenize the text
tokens = word_tokenize(text.lower())
# Remove stop words
filtered_tokens = [token for token in tokens if token not in stopwords.words('english')]
# Lemmatize the tokens
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
# Join the tokens back into a string
processed_text = ' '.join(lemmatized_tokens)
return processed_text
# apply the function df
df['reviewText'] = df['reviewText'].apply(preprocess_text)
df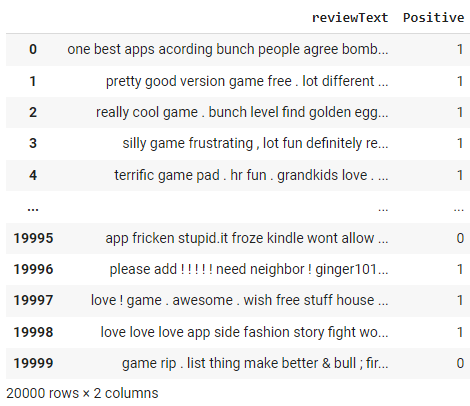
Notice the changes in the "review text" column as a result of the preprocess_text function that we applied in the above step.
First, we’ll initialize a Sentiment Intensity Analyzer object from the nltk.sentiment.vader library.
Next, we’ll define a function called get_sentiment that takes a text string as its input. The function calls the polarity_scores method of the analyzer object to obtain a dictionary of sentiment scores for the text, which includes a score for positive, negative, and neutral sentiment.
The function will then check whether the positive score is greater than 0 and returns a sentiment score of 1 if it is, and a 0 otherwise. This means that any text with a positive score will be classified as having a positive sentiment, and any text with a non-positive score will be classified as having a negative sentiment.
Finally, we’ll apply the get_sentiment function to the reviewText column of the df DataFrame using the apply method. This creates a new column called sentiment in the DataFrame, which stores the sentiment score for each review. We’ll then display the updated DataFrame using df.
# initialize NLTK sentiment analyzer
analyzer = SentimentIntensityAnalyzer()
# create get_sentiment function
def get_sentiment(text):
scores = analyzer.polarity_scores(text)
sentiment = 1 if scores['pos'] > 0 else 0
return sentiment
# apply get_sentiment function
df['sentiment'] = df['reviewText'].apply(get_sentiment)
df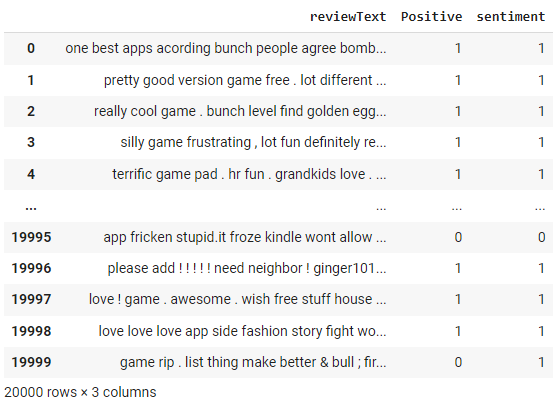
The NLTK sentiment analyzer returns a score between -1 and +1. We have used a cut-off threshold of 0 in the get_sentiment function above. Anything above 0 is classified as 1 (meaning positive). Since we have actual labels, we can evaluate the performance of this method by building a confusion matrix.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(df['Positive'], df['sentiment']))Output:
[[ 1131 3636]
[ 576 14657]]We can also check the classification report:
from sklearn.metrics import classification_report
print(classification_report(df['Positive'], df['sentiment']))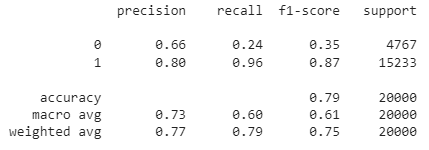
As you can see, the overall accuracy of this rule-based sentiment analysis model is 79%. Since this is labeled data, you can also try to build a ML model to evaluate if an ML-based approach will result in better accuracy.
Check out the full notebook on the Datacamp workspace.
NLTK is a powerful and flexible library for performing sentiment analysis and other natural language processing tasks in Python. By using NLTK, we can preprocess text data, convert it into a bag of words model, and perform sentiment analysis using Vader's sentiment analyzer.
Through this tutorial, we have explored the basics of NLTK sentiment analysis, including preprocessing text data, creating a bag of words model, and performing sentiment analysis using NLTK Vader. We have also discussed the advantages and limitations of NLTK sentiment analysis, and provided suggestions for further reading and exploration.
Overall, NLTK is a powerful and widely used tool for performing sentiment analysis and other natural language processing tasks in Python. By mastering the techniques and tools presented in this tutorial, you can gain valuable insights into the sentiment of text data and use these insights to make data-driven decisions in a wide range of applications.
If you want to learn how to apply NLP to real-world data, including TED talks, articles, and movie reviews, using Python libraries and frameworks, including NLTK, scikit-learn, spaCy, and SpeechRecognition, check out the resources below:
It provides a strong foundation for processing and analyzing text data using Python. Whether you're new to NLP or looking to expand your skills, this course will equip you with the tools and knowledge to convert unstructured data into valuable insights.
Python Courses
Course
Course
Course
Tutorial
Sayak Paul
Tutorial
Kurtis Pykes
Tutorial
Avinash Navlani
Tutorial
Duong Vu
Tutorial
Hugo Bowne-Anderson
code-along
Justin Saddlemyer
