Cours
Python intermédiaire
4 h
1.4M
L'analyse des sentiments est une technique utilisée pour déterminer la tonalité émotionnelle ou le sentiment exprimé dans un texte. Il s'agit d'analyser les mots et les phrases utilisés dans le texte pour identifier le sentiment sous-jacent, qu'il soit positif, négatif ou neutre.
L'analyse des sentiments a un large éventail d'applications, notamment la surveillance des médias sociaux, l'analyse du retour d'information des clients et les études de marché.
L'un des principaux défis de l'analyse des sentiments est la complexité inhérente au langage humain. Les données textuelles contiennent souvent du sarcasme, de l'ironie et d'autres formes de langage figuratif qui peuvent être difficiles à interpréter à l'aide des méthodes traditionnelles.
Toutefois, les progrès récents en matière de traitement du langage naturel (NLP) et d'apprentissage automatique ont permis d'effectuer une analyse des sentiments sur de grands volumes de données textuelles avec un degré élevé de précision.
Il existe plusieurs façons d'effectuer une analyse des sentiments sur des données textuelles, avec des degrés de complexité et de précision variables. Les méthodes les plus courantes comprennent une approche basée sur le lexique, une approche basée sur l'apprentissage machine (ML) et une approche d'apprentissage profond basée sur un transformateur pré-entraîné. Examinons chacun d'entre eux plus en détail :
Ce type d'analyse, comme l'analyseur de sentiment NLTK Vader, consiste à utiliser un ensemble de règles et d'heuristiques prédéfinies pour déterminer le sentiment d'un morceau de texte. Ces règles sont généralement basées sur des caractéristiques lexicales et syntaxiques du texte, telles que la présence de mots et de phrases positifs ou négatifs.
Bien que l'analyse basée sur le lexique puisse être relativement simple à mettre en œuvre et à interpréter, elle peut ne pas être aussi précise que les approches basées sur le ML ou sur la transformation, en particulier lorsqu'il s'agit de données textuelles complexes ou ambiguës.
Cette approche consiste à former un modèle pour identifier le sentiment d'un texte sur la base d'un ensemble de données de formation étiquetées. Ces modèles peuvent être formés à l'aide d'un large éventail d'algorithmes de ML, notamment les arbres de décision, les machines à vecteurs de support (SVM) et les réseaux neuronaux.
Les approches basées sur les ML peuvent être plus précises que les analyses basées sur les règles, en particulier lorsqu'il s'agit de données textuelles complexes, mais elles nécessitent une plus grande quantité de données d'apprentissage étiquetées et peuvent être plus coûteuses en termes de calcul.
Une approche basée sur l'apprentissage profond, comme on l'a vu avec BERT et GPT-4, implique l'utilisation de modèles pré-entraînés formés sur des quantités massives de données textuelles. Ces modèles utilisent des réseaux neuronaux complexes pour encoder le contexte et le sens du texte, ce qui leur permet d'atteindre une précision de pointe dans un large éventail de tâches NLP, y compris l'analyse des sentiments. Toutefois, ces modèles nécessitent d'importantes ressources informatiques et peuvent ne pas être adaptés à tous les cas d'utilisation.
Le choix de l'approche dépendra des besoins et des contraintes spécifiques du projet en question.
Pour utiliser la bibliothèque NLTK, vous devez disposer d'un environnement Python sur votre ordinateur. La manière la plus simple d'installer Python est de télécharger et d'installer la distribution Anaconda. Cette distribution est livrée avec l'environnement de base Python 3 et d'autres cloches et sifflets, notamment Jupyter Notebook. Vous n'avez pas non plus besoin d'installer la bibliothèque NLTK, car elle est préinstallée avec NLTK et de nombreuses autres bibliothèques utiles.
Si vous choisissez d'installer Python sans aucune distribution, vous pouvez directement télécharger et installer Python à partir de python.org. Dans ce cas, vous devrez installer NLTK une fois que votre environnement Python sera prêt.
Pour installer la bibliothèque NLTK, ouvrez le terminal de commande et tapez :
pip install nltkIl convient de noter que NLTK nécessite également le téléchargement de certaines données supplémentaires avant de pouvoir être utilisé efficacement. Ces données comprennent des modèles pré-entraînés, des corpus et d'autres ressources que NLTK utilise pour effectuer diverses tâches de NLP. Pour télécharger ces données, exécutez la commande suivante dans le terminal ou dans votre script Python :
import nltk
nltk.download('all')Le prétraitement du texte est une étape cruciale de l'analyse des sentiments, car il permet de nettoyer et de normaliser les données textuelles, ce qui facilite leur analyse. L'étape de prétraitement implique une série de techniques qui permettent de transformer les données textuelles brutes en une forme utilisable pour l'analyse. Parmi les techniques courantes de prétraitement du texte figurent la tokenisation, la suppression des mots vides, le stemming et la lemmatisation.
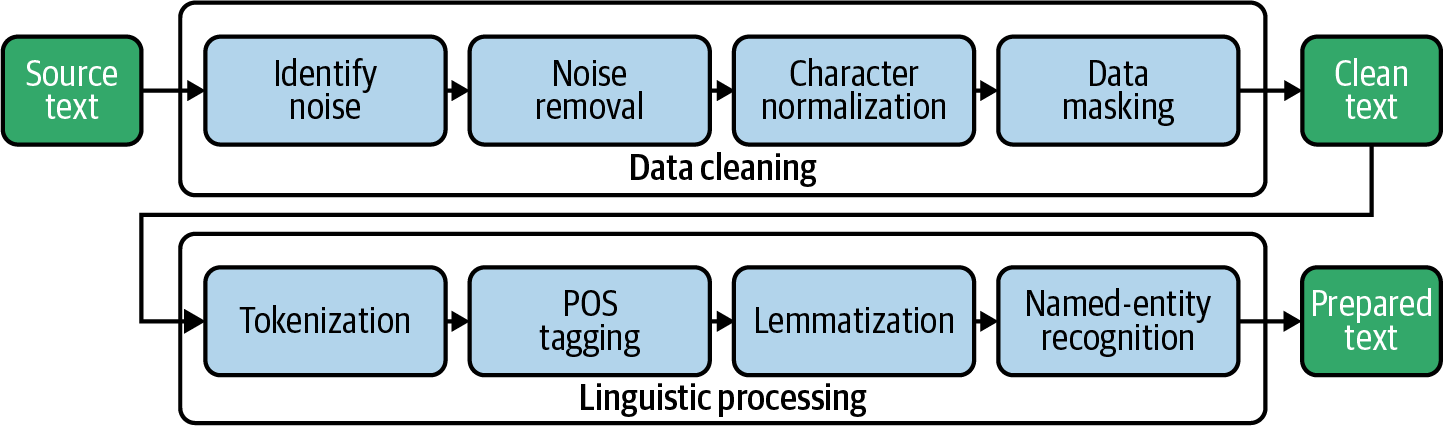
La tokenisation est une étape de prétraitement du texte dans l'analyse des sentiments qui consiste à décomposer le texte en mots individuels ou tokens. Il s'agit d'une étape essentielle dans l'analyse des données textuelles, car elle permet de séparer les mots individuels du texte brut, ce qui facilite l'analyse et la compréhension. La tokenisation est généralement effectuée à l'aide de la fonction intégrée word_tokenize de NLTK, qui peut découper le texte en mots individuels et en signes de ponctuation.
La suppression des mots vides est une étape cruciale du prétraitement du texte dans l'analyse des sentiments. Elle consiste à supprimer les mots courants et non pertinents qui ne sont pas susceptibles de véhiculer un sentiment particulier. Les "stop words" sont des mots très courants dans une langue et qui n'ont pas beaucoup de sens, comme "and", "the", "of" et "it". Ces mots peuvent causer du bruit et fausser l'analyse s'ils ne sont pas supprimés.
En supprimant les mots vides, les mots restants dans le texte sont plus susceptibles d'indiquer le sentiment exprimé. Cela peut contribuer à améliorer la précision de l'analyse des sentiments. NLTK fournit une liste intégrée de mots vides pour plusieurs langues, qui peut être utilisée pour filtrer ces mots à partir des données textuelles.
Le stemming et la lemmatisation sont des techniques utilisées pour réduire les mots à leur forme racine. Le stemming consiste à supprimer les suffixes des mots, tels que "ing" ou "ed", pour les réduire à leur forme de base. Par exemple, le mot "jumping" sera dérivé en "jump".
La lemmatisation, quant à elle, consiste à réduire les mots à leur forme de base en fonction de leur partie du discours. Par exemple, le mot "jumped" serait lemmatisé en "jump", mais le mot "jumping" serait lemmatisé en "jumping" puisqu'il s'agit d'un participe présent.
Pour en savoir plus sur le stemming et la lemmatisation, consultez notre tutoriel Stemming et lemmatisation en Python.
Le modèle du sac de mots est une technique utilisée dans le traitement du langage naturel (NLP) pour représenter les données textuelles sous la forme d'un ensemble de caractéristiques numériques. Dans ce modèle, chaque document ou morceau de texte est représenté comme un "sac" de mots, chaque mot du texte étant représenté par une caractéristique ou une dimension distincte dans le vecteur résultant. La valeur de chaque caractéristique est déterminée par le nombre de fois que le mot correspondant apparaît dans le texte.
Le modèle du sac de mots est utile en NLP car il nous permet d'analyser des données textuelles à l'aide d'algorithmes d'apprentissage automatique, qui nécessitent généralement des données numériques. En représentant les données textuelles sous forme de caractéristiques numériques, nous pouvons former des modèles d'apprentissage automatique pour classer les textes ou analyser les sentiments.
L'exemple de la section suivante utilise le modèle NLTK Vader pour l'analyse des sentiments sur l'ensemble de données des clients d'Amazon. Dans cet exemple particulier, nous n'avons pas besoin d'effectuer cette étape car l'API Vader de NLTK accepte du texte en entrée au lieu de vecteurs numériques, mais si vous construisiez un modèle d'apprentissage automatique supervisé pour prédire les sentiments (en supposant que vous disposiez de données étiquetées), vous devriez transformer le texte traité en un modèle de sac de mots avant d'entraîner le modèle d'apprentissage automatique.
Pour effectuer une analyse des sentiments à l'aide de NLTK en Python, les données textuelles doivent d'abord être prétraitées à l'aide de techniques telles que la tokenisation, la suppression des mots vides et le stemming ou la lemmatisation. Une fois le texte prétraité, nous le transmettons à l'analyseur de sentiment Vader pour analyser le sentiment du texte (positif ou négatif).
Tout d'abord, nous importerons les bibliothèques nécessaires à l'analyse de texte et à l'analyse des sentiments, telles que pandas pour le traitement des données, nltk pour le traitement du langage naturel et SentimentIntensityAnalyzer pour l'analyse des sentiments.
Nous téléchargerons ensuite l'ensemble du corpus NLTK (une collection de données linguistiques) à l'aide de nltk.download().
Une fois l'environnement mis en place, nous allons charger un ensemble de données de commentaires Amazon à l'aide de pd.read_csv(). Cela créera un objet DataFrame dans Python que nous pourrons utiliser pour analyser les données. Nous allons afficher le contenu du DataFrame à l'aide de df.
# import libraries
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# download nltk corpus (first time only)
import nltk
nltk.download('all')
# Load the amazon review dataset
df = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/amazon.csv')
df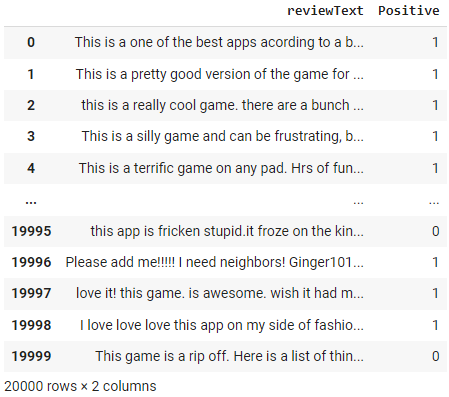
Créons une fonction preprocess_text dans laquelle nous commençons par tokeniser les documents à l'aide de la fonction word_tokenize de NLTK, puis nous supprimons les mots en escalier à l'aide du module stepwords de NLTK et enfin, nous lemmatisons le filtered_tokens à l'aide du module WordNetLemmatizer de NLTK.
# create preprocess_text function
def preprocess_text(text):
# Tokenize the text
tokens = word_tokenize(text.lower())
# Remove stop words
filtered_tokens = [token for token in tokens if token not in stopwords.words('english')]
# Lemmatize the tokens
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
# Join the tokens back into a string
processed_text = ' '.join(lemmatized_tokens)
return processed_text
# apply the function df
df['reviewText'] = df['reviewText'].apply(preprocess_text)
df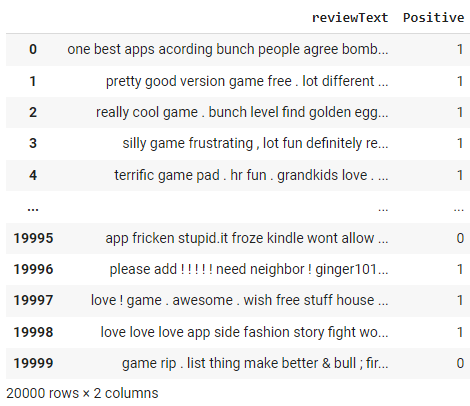
Remarquez les modifications apportées à la colonne "texte de révision" par la fonction preprocess_text que nous avons appliquée à l'étape précédente.
Tout d'abord, nous allons initialiser un objet Sentiment Intensity Analyzer à partir de la bibliothèque nltk.sentiment.vader.
Ensuite, nous allons définir une fonction appelée get_sentiment qui prend une chaîne de texte en entrée. La fonction appelle la méthode polarity_scores de l'objet analyseur pour obtenir un dictionnaire des scores de sentiment pour le texte, qui comprend un score pour le sentiment positif, négatif et neutre.
La fonction vérifie alors si le score positif est supérieur à 0 et renvoie un score de sentiment de 1 si c'est le cas, et de 0 sinon. Cela signifie que tout texte ayant un score positif sera classé comme ayant un sentiment positif, et tout texte ayant un score non positif sera classé comme ayant un sentiment négatif.
Enfin, nous appliquerons la fonction get_sentiment à la colonne reviewText du DataFrame df à l'aide de la méthode apply. Cette opération crée une nouvelle colonne appelée sentiment dans le DataFrame, qui stocke la note de sentiment pour chaque avis. Nous afficherons ensuite le DataFrame mis à jour à l'aide de df.
# initialize NLTK sentiment analyzer
analyzer = SentimentIntensityAnalyzer()
# create get_sentiment function
def get_sentiment(text):
scores = analyzer.polarity_scores(text)
sentiment = 1 if scores['pos'] > 0 else 0
return sentiment
# apply get_sentiment function
df['sentiment'] = df['reviewText'].apply(get_sentiment)
df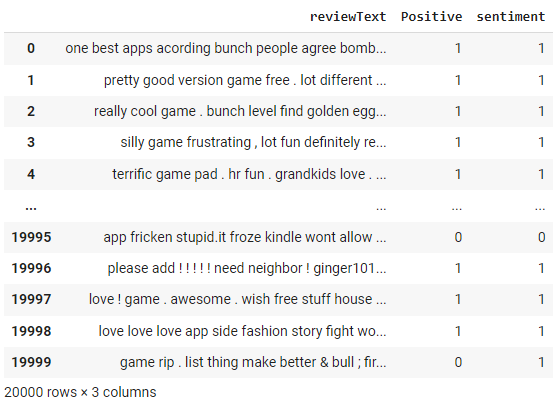
L'analyseur de sentiment NLTK renvoie une note comprise entre -1 et +1. Nous avons utilisé un seuil de coupure de 0 dans la fonction get_sentiment ci-dessus. Tout ce qui est supérieur à 0 est classé 1 (c'est-à-dire positif). Comme nous disposons d'étiquettes réelles, nous pouvons évaluer les performances de cette méthode en construisant une matrice de confusion.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(df['Positive'], df['sentiment']))Sortie:
[[ 1131 3636]
[ 576 14657]]Nous pouvons également consulter le rapport de classification :
from sklearn.metrics import classification_report
print(classification_report(df['Positive'], df['sentiment']))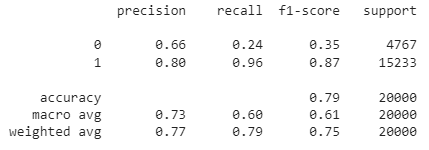
Comme vous pouvez le constater, la précision globale de ce modèle d'analyse des sentiments basé sur des règles est de 79 %. Comme il s'agit de données étiquetées, vous pouvez également essayer de construire un modèle ML pour évaluer si une approche basée sur le ML permet d'obtenir une meilleure précision.
Consultez le carnet de notes complet sur l'espace de travail de DataCamp.
NLTK est une bibliothèque puissante et flexible permettant d'effectuer des analyses de sentiments et d'autres tâches de traitement du langage naturel en Python. NLTK permet de prétraiter les données textuelles, de les convertir en un modèle de sac de mots et d'effectuer une analyse des sentiments à l'aide de l'analyseur de sentiments de Vader.
Dans ce tutoriel, nous avons exploré les bases de l'analyse des sentiments avec NLTK, notamment le prétraitement des données textuelles, la création d'un modèle de sac de mots et l'analyse des sentiments avec NLTK Vader. Nous avons également discuté des avantages et des limites de l'analyse de sentiments NLTK et suggéré des pistes de lecture et d'exploration.
Dans l'ensemble, NLTK est un outil puissant et largement utilisé pour réaliser des analyses de sentiments et d'autres tâches de traitement du langage naturel en Python. En maîtrisant les techniques et les outils présentés dans ce tutoriel, vous pouvez obtenir des informations précieuses sur le sentiment des données textuelles et les utiliser pour prendre des décisions fondées sur des données dans un large éventail d'applications.
Si vous souhaitez apprendre à appliquer le TAL à des données du monde réel, notamment des TED talks, des articles et des critiques de films, à l'aide de bibliothèques et de frameworks Python, notamment NLTK, scikit-learn, spaCy et SpeechRecognition, consultez les ressources ci-dessous :
Il fournit une base solide pour le traitement et l'analyse de données textuelles à l'aide de Python. Que vous soyez novice en matière de PNL ou que vous cherchiez à développer vos compétences, ce cours vous fournira les outils et les connaissances nécessaires pour convertir des données non structurées en informations précieuses.
Cours de Python
Cours
Cours
Cours