
Lernpfad
Wissenschaftler für maschinelles Lernen in Python
85 Std.
Die Dimensionalitätsreduktion ist eine leistungsstarke Technik des maschinellen Lernens und der Datenanalyse, bei der es darum geht, hochdimensionale Daten in einen niedrigdimensionalen Raum umzuwandeln und dabei so viele wichtige Informationen wie möglich zu erhalten. Hochdimensionale Daten sind Datensätze mit einer großen Anzahl von Merkmalen oder Variablen, die für Modelle des maschinellen Lernens eine große Herausforderung darstellen können.
In diesem Tutorium lernen wir, warum wir die Dimensionalitätsreduktion nutzen sollten, welche Arten von Dimensionalitätsreduktionstechniken es gibt und wie wir diese Techniken auf einen einfachen Bilddatensatz anwenden. Wir werden die Daten auch im 2D-Raum visualisieren und die Bilder im niederdimensionalen Raum vergleichen.
Wenn du neu im Bereich des maschinellen Lernens bist und die Konzepte des maschinellen Lernens beherrschen willst, dann nimm den Werde ein Machine Learning Scientist in Python Lernpfad und arbeite darauf hin, ein Machine Learning Scientist zu werden.
Bild vom Autor
Hochdimensionale Daten sind zwar reich an Informationen, enthalten aber oft redundante oder irrelevante Merkmale. Das kann zu verschiedenen Problemen führen:
Die Dimensionalitätsreduktion löst diese Probleme, indem sie die Daten vereinfacht und gleichzeitig die wichtigsten Merkmale beibehält. Das verbessert nicht nur die Leistung des Modells, sondern macht die Daten auch einfacher zu interpretieren und zu visualisieren.
Techniken zur Dimensionalitätsreduzierung können auch danach klassifiziert werden, ob sie von einer linearen oder nichtlinearen Struktur in den Daten ausgehen.
Lineare Methoden gehen davon aus, dass die Daten in einem linearen Unterraum liegen. Diese Techniken sind rechenintensiv und funktionieren gut, wenn die Datenstruktur von Natur aus linear ist.
Hier sind einige Beispiele:
Folgen Sie der Principal Component Analysis (PCA) in Python Tutorial, um zu lernen, wie man Informationen aus Daten ohne Aufsicht extrahiert, indem man den Brustkrebs- und CIFAR-10-Datensatz verwendet.
Nichtlineare Methoden werden eingesetzt, wenn die Daten auf einer nichtlinearen Mannigfaltigkeit liegen. Diese Techniken sind besser geeignet, um komplexe Strukturen in den Daten zu erfassen.
Hier sind einige Beispiele:
Techniken zur Dimensionalitätsreduzierung lassen sich grob in zwei Typen unterteilen: Merkmalsauswahl und Merkmalsextraktion.
Bei der Merkmalsauswahl geht es darum, nur die relevantesten Merkmale aus dem Datensatz herauszufiltern und zu behalten. Bei diesem Verfahren werden die Daten nicht umgewandelt, sondern es wird eine Teilmenge der ursprünglichen Merkmale ausgewählt.
Zu den gängigen Methoden gehören:
Bei der Merkmalsextraktion, die auch als Merkmalsprojektion bezeichnet wird, werden die Daten in einen niedrigdimensionalen Raum transformiert, indem neue Merkmale erstellt werden, die Kombinationen der ursprünglichen Merkmale sind. Dieser Ansatz ist besonders nützlich, wenn die ursprünglichen Merkmale stark korreliert oder redundant sind.
Zu den beliebten Methoden der Merkmalsextraktion gehören:
In diesem Leitfaden lernst du, wie du in Python Techniken zur Dimensionalitätsreduktion anwendest.
Zunächst importieren wir die notwendigen Python-Pakete und laden den Digits-Datensatz von sklearn.datasets.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
# Load the digits dataset
digits = load_digits()
X = digits.data # shape (1797, 64)
y = digits.target # labels for digits (0 through 9)
print("Data shape:", X.shape)
print("Labels shape:", y.shape)Dieser Datensatz enthält 1.797 Graustufenbilder von handgeschriebenen Ziffern (0-9), die jeweils als 8x8-Bilder (64 Pixel) dargestellt werden. Die Daten werden in einen 64-dimensionalen Merkmalsvektor für jedes Bild umgewandelt.
Data shape: (1797, 64)
Labels shape: (1797,)Wir werden nun ein paar Beispiele aus dem Datensatz visualisieren, um ein besseres Verständnis zu bekommen. Mit Matplotlib werden wir Bilder anzeigen, die in ihr ursprüngliches 8x8-Rasterformat zurückverwandelt wurden.
def plot_digits(images, labels, n_rows=2, n_cols=5):
fig, axes = plt.subplots(n_rows, n_cols, figsize=(10, 4))
axes = axes.ravel()
for i in range(n_rows * n_cols):
axes[i].imshow(images[i].reshape(8, 8), cmap='gray')
axes[i].set_title(f"Label: {labels[i]}")
axes[i].axis('off')
plt.tight_layout()
plt.show()
plot_digits(X, y)Wie wir sehen können, zeigt es ein Raster von Bildern an, die zeigen, wie die Ziffern in Graustufen von 0 bis 9 aussehen.

t-SNE ist ein beliebtes Verfahren zur Dimensionalitätsreduktion, um hochdimensionale Daten in 2D oder 3D zu visualisieren. Sie ist besonders effektiv, wenn es darum geht, lokale Strukturen in den Daten zu erhalten.
Lies den Blog Einführung in t-SNE: Nichtlineare Dimensionalitätsreduktion und Datenvisualisierung um zu lernen, wie man hochdimensionale Daten in einem niedrigdimensionalen Raum mit Hilfe einer nichtlinearen Dimensionalitätsreduktionstechnik visualisiert.
Bevor wir t-SNE anwenden, skalieren wir die Daten mit StandardScaler, um die Merkmalswerte zu normalisieren.
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)Dann wählen wir eine Teilmenge von 500 Stichproben für eine schnellere Berechnung aus und lassen den t-SNE-Algorithmus auf dieser Teilmenge laufen.
Hier sind die Argumente der Funktion TSNE mit Erklärung:
n_samples = 500
X_sub = X_scaled[:n_samples]
y_sub = y[:n_samples]
tsne = TSNE(n_components=2,
perplexity=30,
n_iter=1000,
random_state=42)
X_tsne = tsne.fit_transform(X_sub)
print("t-SNE result shape:", X_tsne.shape)Die Dimensionalitätsreduktion war erfolgreich, denn wir haben jetzt 500 Proben, die jeweils in 2 Dimensionen dargestellt werden.
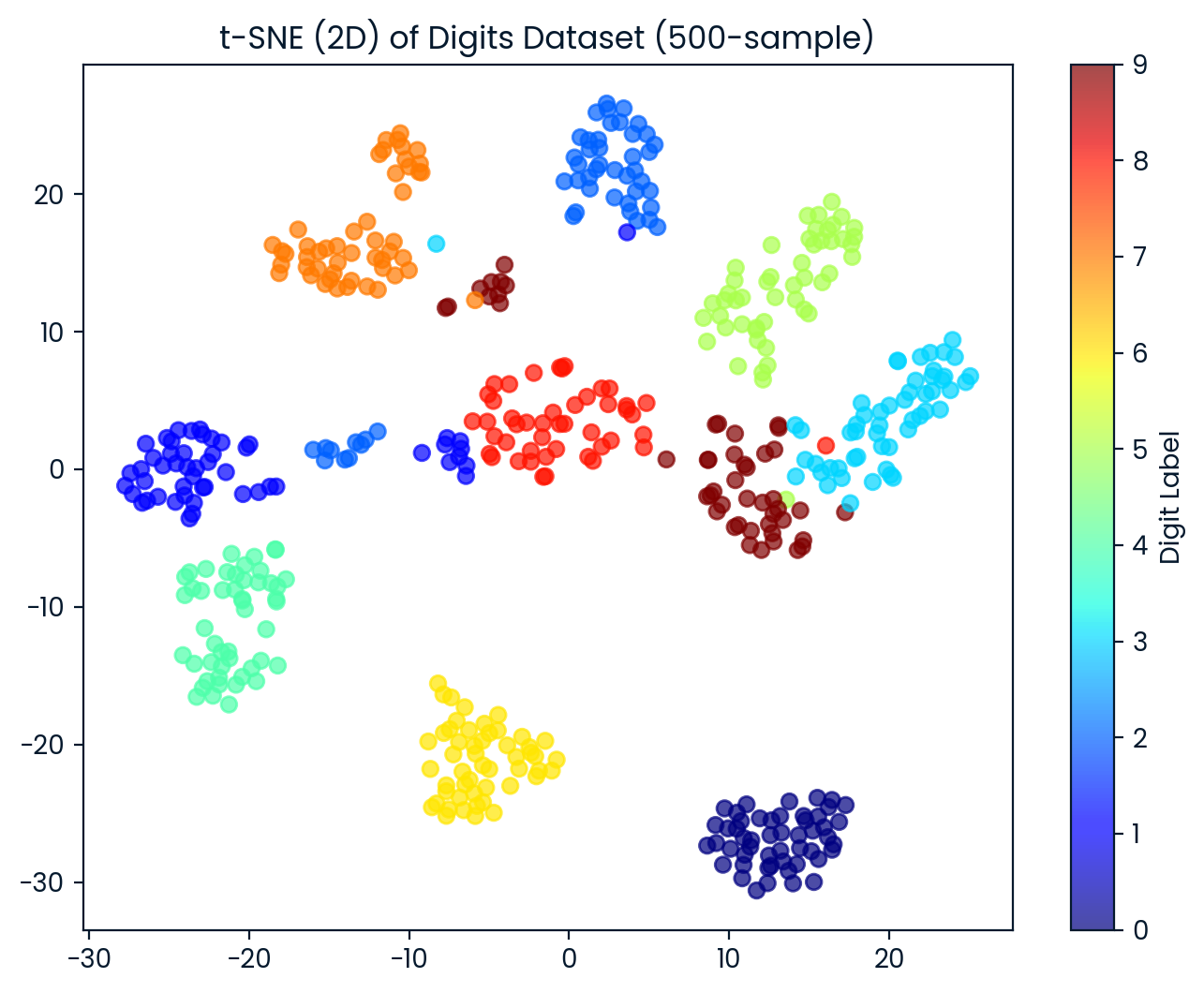
t-SNE result shape: (500, 2)Wir visualisieren nun den 2D t-SNE-Datensatz. Jeder Punkt wird anhand seiner Ziffernbezeichnung eingefärbt. So können wir beobachten, wie gut t-SNE die verschiedenen Ziffernklassen trennt.
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1],
c=y_sub, cmap='jet', alpha=0.7)
plt.colorbar(scatter, label='Digit Label')
plt.title('t-SNE (2D) of Digits Dataset (500-sample)')
plt.show()Der t-SNE teilte die Ziffern effektiv in 10 verschiedene Gruppen ein, wobei es zwischen den Gruppen einige Überschneidungen gab.
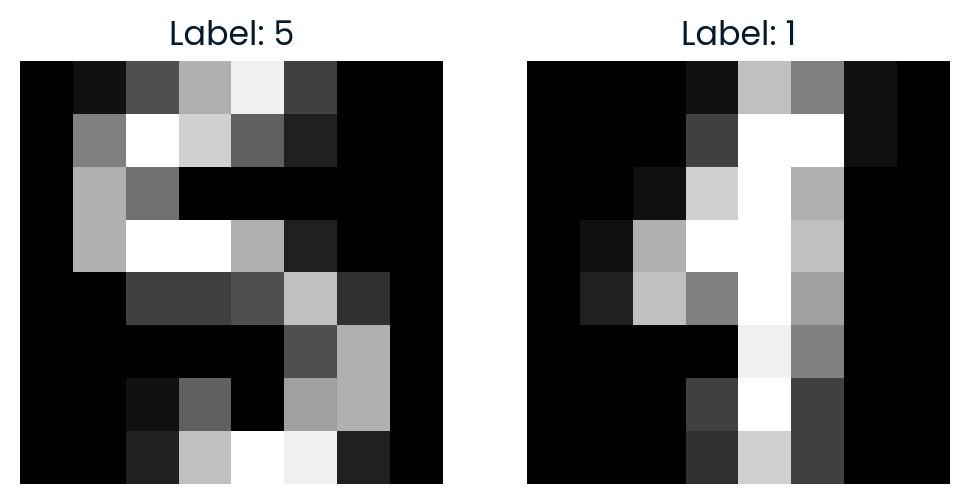
Um den t-SNE-Raum weiter zu erkunden, wählen wir zufällig zwei Punkte aus und berechnen den euklidischen Abstand zwischen ihnen im 2D t-SNE-Raum. Wir werden die Bilder auch visualisieren, um zu sehen, wie ähnlich sie sind.
import random
idx1, idx2 = random.sample(range(X_tsne.shape[0]), 2)
point1, point2 = X_tsne[idx1], X_tsne[idx2]
dist_tsne = np.linalg.norm(point1 - point2)
print(f"Comparing images #{idx1} and #{idx2}")
print(f"Distance in t-SNE space: {dist_tsne:.4f}")
print(f"Label of image #{idx1}: {y_sub[idx1]}")
print(f"Label of image #{idx2}: {y_sub[idx2]}")
# Plot the original images
fig, axes = plt.subplots(1, 2, figsize=(6, 3))
axes[0].imshow(X[idx1].reshape(8, 8), cmap='gray')
axes[0].set_title(f"Label: {y_sub[idx1]}")
axes[0].axis('off')
axes[1].imshow(X[idx2].reshape(8, 8), cmap='gray')
axes[1].set_title(f"Label: {y_sub[idx2]}")
axes[1].axis('off')
plt.show()Der Abstand im t-SNE-Raum zeigt, wie unähnlich die beiden Bilder in der reduzierten 2D-Darstellung sind.
Comparing images #291 and #90
Distance in t-SNE space: 35.7666
Label of image #291: 5
Label of image #90: 1
Wenn du Probleme hast, den obigen Code auszuführen, überprüfe bitte den DataLab-Arbeitsbereich für weitere Hilfe.
Die Dimensionalitätsreduktion spielt in realen Anwendungen eine entscheidende Rolle, da sie die Effizienz, Genauigkeit und Interpretierbarkeit von Machine-Learning-Modellen verbessert und eine bessere Visualisierung und Analyse komplexer Datensätze ermöglicht.
In diesem Tutorium haben wir das Konzept der Dimensionalitätsreduktion, ihren Zweck, ihre Methoden und Arten kennengelernt. Schließlich haben wir gelernt, wie man die t-SNE-Technik einsetzt, um Bilddaten für die Visualisierung und Analyse in einen niedrigdimensionalen Raum zu transformieren.
Nimm die Dimensionalitätsreduktion in Python um das Konzept der Dimensionalitätsreduktion in deinen Daten zu verstehen und die Techniken dafür in Python zu beherrschen.
Top DataCamp Kurse
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
