
Cursus
Chercheur en apprentissage automatique en Python
85 h
La réduction de la dimensionnalité est une technique puissante d'apprentissage automatique et d'analyse des données qui consiste à transformer des données de haute dimension en un espace de dimension inférieure tout en conservant autant d'informations importantes que possible. Les données à haute dimension font référence à des ensembles de données comportant un grand nombre de caractéristiques ou de variables, ce qui peut poser des problèmes importants pour les modèles d'apprentissage automatique.
Dans ce tutoriel, nous allons apprendre pourquoi nous devrions utiliser la réduction de la dimensionnalité, les types de techniques de réduction de la dimensionnalité, et comment appliquer ces techniques à un simple ensemble de données d'images. Nous visualiserons également les données dans l'espace 2D et comparerons les images dans un espace de dimension inférieure.
Si vous êtes novice dans le domaine de l'apprentissage automatique et que vous souhaitez maîtriser les concepts de l'apprentissage automatique, suivez le cours d'apprentissage automatique. Devenez un scientifique de l'apprentissage automatique en Python et travaillez pour devenir un scientifique de l'apprentissage automatique.
Image par l'auteur
Les données à haute dimension, bien que riches en informations, contiennent souvent des caractéristiques redondantes ou non pertinentes. Cela peut entraîner plusieurs problèmes :
La réduction de la dimensionnalité permet de résoudre ces problèmes en simplifiant les données tout en conservant les caractéristiques les plus importantes. Cela permet non seulement d'améliorer les performances du modèle, mais aussi de faciliter l'interprétation et la visualisation des données.
Les techniques de réduction de la dimensionnalité peuvent également être classées selon qu'elles supposent une structure linéaire ou non linéaire des données.
Les méthodes linéaires supposent que les données se trouvent dans un sous-espace linéaire. Ces techniques sont efficaces sur le plan informatique et fonctionnent bien lorsque la structure des données est intrinsèquement linéaire.
Voici quelques exemples :
Suivez le cours Analyse en composantes principales (ACP) en Python pour apprendre à extraire des informations de données sans supervision en utilisant les jeux de données Breast Cancer et CIFAR-10.
Les méthodes non linéaires sont utilisées lorsque les données se situent sur un collecteur non linéaire. Ces techniques sont mieux adaptées à la saisie de structures complexes dans les données.
Voici quelques exemples :
Les techniques de réduction de la dimensionnalité peuvent être classées en deux catégories : Sélection et extraction des caractéristiques.
La sélection des caractéristiques consiste à identifier et à conserver uniquement les caractéristiques les plus pertinentes de l'ensemble de données. Ce processus ne transforme pas les données, mais sélectionne un sous-ensemble des caractéristiques originales.
Les méthodes les plus courantes sont les suivantes :
L'extraction de caractéristiques, également appelée projection de caractéristiques, transforme les données dans un espace de dimension inférieure en créant de nouvelles caractéristiques qui sont des combinaisons des caractéristiques originales. Cette approche est particulièrement utile lorsque les caractéristiques originales sont fortement corrélées ou redondantes.
Les méthodes d'extraction de caractéristiques les plus répandues sont les suivantes :
Dans ce guide, nous allons apprendre à appliquer des techniques de réduction de la dimensionnalité en Python.
Nous commencerons par importer les paquets Python nécessaires et par charger le jeu de données sur les chiffres à partir de sklearn.datasets.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
# Load the digits dataset
digits = load_digits()
X = digits.data # shape (1797, 64)
y = digits.target # labels for digits (0 through 9)
print("Data shape:", X.shape)
print("Labels shape:", y.shape)Cet ensemble de données contient 1 797 images en niveaux de gris de chiffres manuscrits (0-9), chacun étant représenté par une image 8x8 (64 pixels). Les données sont aplaties en un vecteur de caractéristiques à 64 dimensions pour chaque image.
Data shape: (1797, 64)
Labels shape: (1797,)Nous allons maintenant visualiser quelques échantillons de l'ensemble de données pour mieux comprendre. À l'aide de Matplotlib, nous afficherons des images qui ont été remodelées pour retrouver leur format de grille 8x8 d'origine.
def plot_digits(images, labels, n_rows=2, n_cols=5):
fig, axes = plt.subplots(n_rows, n_cols, figsize=(10, 4))
axes = axes.ravel()
for i in range(n_rows * n_cols):
axes[i].imshow(images[i].reshape(8, 8), cmap='gray')
axes[i].set_title(f"Label: {labels[i]}")
axes[i].axis('off')
plt.tight_layout()
plt.show()
plot_digits(X, y)Comme nous pouvons le voir, il affiche une grille d'images montrant l'aspect des chiffres en niveaux de gris de 0 à 9.

Le t-SNE est une technique populaire de réduction de la dimensionnalité qui permet de visualiser des données à haute dimension en 2D ou en 3D. Elle est particulièrement efficace pour préserver les structures locales des données.
Lisez le blog Introduction à t-SNE : Réduction de la dimensionnalité non linéaire et visualisation des données pour apprendre à visualiser des données à haute dimension dans un espace à faible dimension à l'aide d'une technique de réduction de la dimensionnalité non linéaire.
Avant d'appliquer t-SNE, nous mettons les données à l'échelle à l'aide de StandardScaler pour normaliser les valeurs des caractéristiques.
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)Ensuite, nous sélectionnons un sous-ensemble de 500 échantillons pour un calcul plus rapide et nous exécutons l'algorithme t-SNE sur ce sous-ensemble.
Voici les arguments de la fonction TSNE avec une explication :
n_samples = 500
X_sub = X_scaled[:n_samples]
y_sub = y[:n_samples]
tsne = TSNE(n_components=2,
perplexity=30,
n_iter=1000,
random_state=42)
X_tsne = tsne.fit_transform(X_sub)
print("t-SNE result shape:", X_tsne.shape)La réduction de la dimensionnalité a été un succès, puisque nous avons maintenant 500 échantillons, chacun représenté en 2 dimensions.
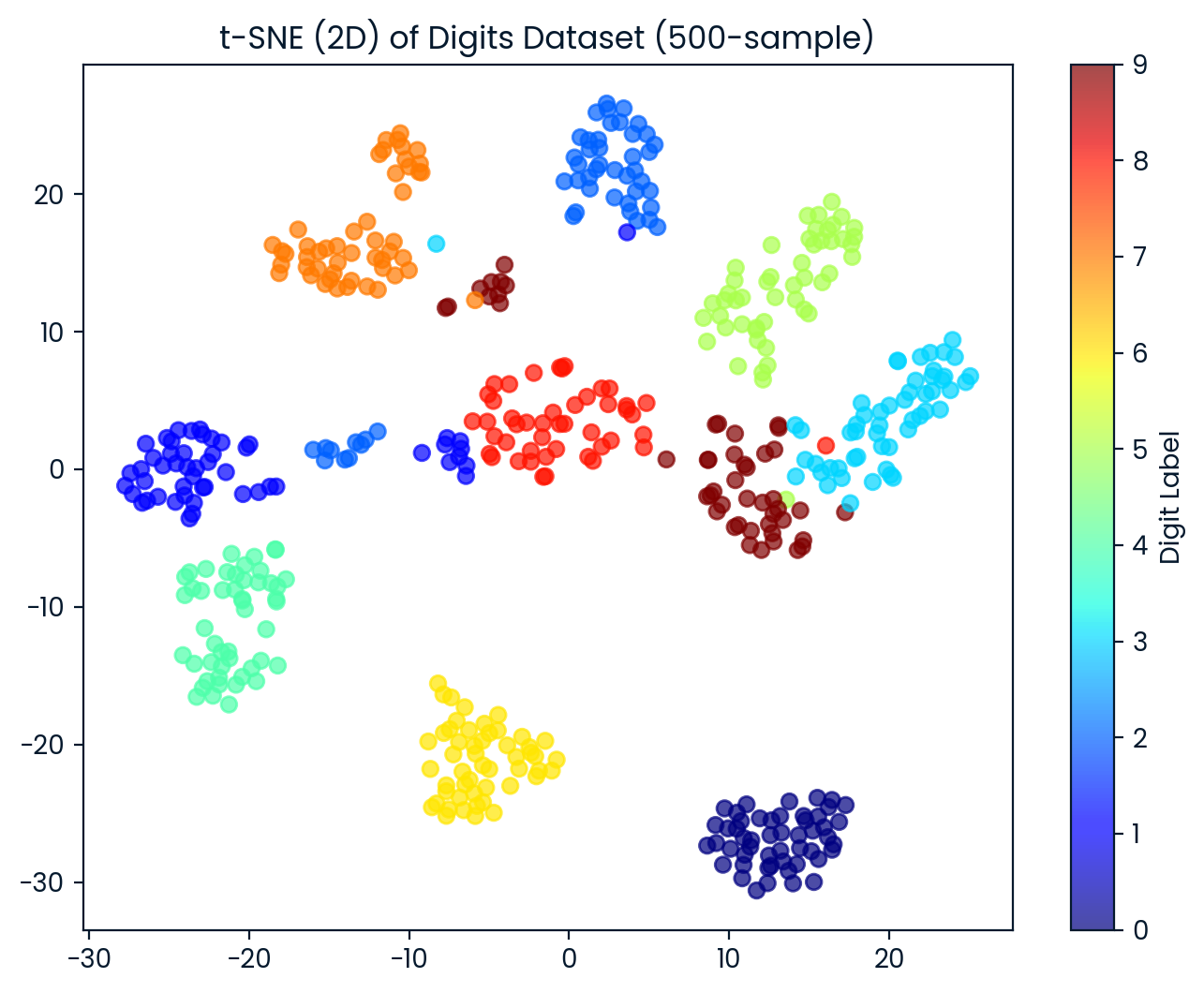
t-SNE result shape: (500, 2)Nous visualisons maintenant l'ensemble de données t-SNE en 2D. Chaque point est coloré en fonction de l'étiquette du chiffre, ce qui nous permet d'observer à quel point t-SNE sépare les différentes classes de chiffres.
plt.figure(figsize=(8, 6))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1],
c=y_sub, cmap='jet', alpha=0.7)
plt.colorbar(scatter, label='Digit Label')
plt.title('t-SNE (2D) of Digits Dataset (500-sample)')
plt.show()La méthode t-SNE a permis de séparer les chiffres en 10 groupes distincts, avec un certain chevauchement entre les groupes.
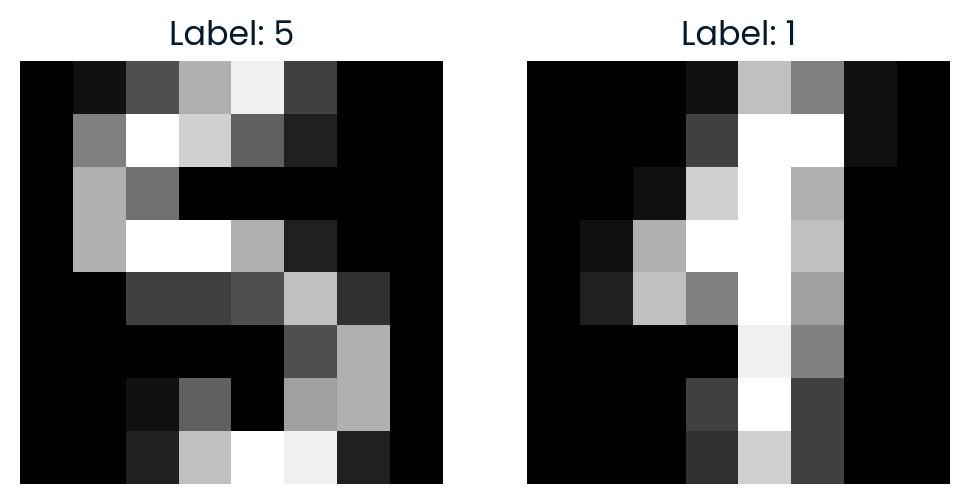
Pour explorer davantage l'espace t-SNE, nous sélectionnons au hasard deux points et calculons la distance euclidienne entre eux dans l'espace t-SNE 2D. Nous allons également visualiser les images pour voir à quel point elles sont similaires.
import random
idx1, idx2 = random.sample(range(X_tsne.shape[0]), 2)
point1, point2 = X_tsne[idx1], X_tsne[idx2]
dist_tsne = np.linalg.norm(point1 - point2)
print(f"Comparing images #{idx1} and #{idx2}")
print(f"Distance in t-SNE space: {dist_tsne:.4f}")
print(f"Label of image #{idx1}: {y_sub[idx1]}")
print(f"Label of image #{idx2}: {y_sub[idx2]}")
# Plot the original images
fig, axes = plt.subplots(1, 2, figsize=(6, 3))
axes[0].imshow(X[idx1].reshape(8, 8), cmap='gray')
axes[0].set_title(f"Label: {y_sub[idx1]}")
axes[0].axis('off')
axes[1].imshow(X[idx2].reshape(8, 8), cmap='gray')
axes[1].set_title(f"Label: {y_sub[idx2]}")
axes[1].axis('off')
plt.show()La distance dans l'espace t-SNE reflète le degré de dissemblance des deux images dans la représentation réduite en 2D.
Comparing images #291 and #90
Distance in t-SNE space: 35.7666
Label of image #291: 5
Label of image #90: 1
Si vous avez des difficultés à exécuter le code ci-dessus, veuillez vérifier l'espace de travail de Espace de travail DataLab pour obtenir de l'aide.
La réduction de la dimensionnalité joue un rôle crucial dans les applications du monde réel en améliorant l'efficacité, la précision et l'interprétabilité des modèles d'apprentissage automatique, ainsi qu'en permettant une meilleure visualisation et analyse des ensembles de données complexes.
Dans ce tutoriel, nous avons exploré le concept de réduction de la dimensionnalité, son objectif, ses méthodes et ses types. Enfin, nous avons appris à utiliser la technique t-SNE pour transformer les données d'images en un espace de moindre dimension pour la visualisation et l'analyse.
Prenez la Réduction de la dimensionnalité en Python pour comprendre le concept de réduction de la dimensionnalité de vos données et maîtriser les techniques pour le faire en Python.
Les meilleurs cours de DataCamp
Cursus
Cursus
Cours